App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Interposer Strategie - Zen, Fiji, HBM und Logic ICs
- Ersteller Complicated
- Erstellt am
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
Da der neue Cache nur dieselbe Fläche belegt wie der schon vorhandene Cache und dabei doppelt so viele Zellen aufbringt, muss die neue Library der Knaller sein. Da stellt sich die Frage, warum AMD die nicht auch für das Chiplet selbst verwendet.
MfG
MfG
Pinnacle Ridge
Vice Admiral Special
- Mitglied seit
- 04.03.2017
- Beiträge
- 528
- Renomée
- 7
Vielleicht verwendet AMD die dann bei kommenden Chips eh.
Captn-Future
Moderation DC, P3DN Vize-Kommandant
- Mitglied seit
- 16.08.2004
- Beiträge
- 8.430
- Renomée
- 313
- Standort
- VIP Lounge
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- QMC, Simap
- Lieblingsprojekt
- QMC
- Meine Systeme
- X4 940 BE
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- Intel Xeon E3-1230v2
- Mainboard
- GA-Z77-UD3
- Kühlung
- Thermalright Macho Rev. A
- Speicher
- 16 GB Kingston blue
- Grafikprozessor
- Gigabyte GTX 660
- Display
- HP ZR2440w 1920x1200
- SSD
- Samsung SSD 830 256 GB
- HDD
- WD Blue 1 TB
- Optisches Laufwerk
- LG GSA-H10N
- Gehäuse
- LianLi V1000 Silber
- Netzteil
- Cougar SE400
- Betriebssystem
- Windows 7
- Webbrowser
- FireFox
Interessant wir das Verfahren doch erst, wenn zu je 2 Compute-Dies rechts und links ein Cache-Stapel von 4x32 MB in der Mitte auftürmt. Gerüchten zufolge soll der zusätzliche Cache aus 2 Lagen a 32MB bestehen die auf dem gleichgroßen On-Die-Cache aufgesetzt werden. Das "normale" Die soll deutlich dicker sein, daher die krumme Anzahl an Cache.
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Laut Ian Cutress hat AMD gesagt, dass das nicht geht, da die Libraries sehr Cache-spezifisch sind.. Da stellt sich die Frage, warum AMD die nicht auch für das Chiplet selbst verwendet
Imo sind Sram-Zellen auch die Sachen, die am besten skalieren, deswegen werden die ja auch immer bei den Spezifikationen der Nodes angegeben.
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
Ich bin zu wenig Library Experte (=gar nicht), aber warum kann man die nicht mischen?
Sind diese Libraries mit Kochrezepten der Herstellung verbunden, die da z.B. sagen: jetzt wird eine Schicht Kupfer aufgedampft anstatt dass eine Schicht von irgendwas weg geätzt wird? Und deshalb kann man das auf einem Wafer nicht mischen?
MfG
Sind diese Libraries mit Kochrezepten der Herstellung verbunden, die da z.B. sagen: jetzt wird eine Schicht Kupfer aufgedampft anstatt dass eine Schicht von irgendwas weg geätzt wird? Und deshalb kann man das auf einem Wafer nicht mischen?
MfG
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Patent: DATA FLOW IN A DISTRIBUTED GRAPHICS PROCESSING UNIT ARCHITECTURE
Wenn ich das auf die schnelle so richtig verstehe: Das Bridge Chiplet enthält einen Shared L3 Cache, über welchen die GPU-Chiplets Informationen austauschen können. Das Memory-IO ist auf den GPU-Chiplets und skaliert deshalb mit deren Anzahl.
Via Reddit
Wenn ich das auf die schnelle so richtig verstehe: Das Bridge Chiplet enthält einen Shared L3 Cache, über welchen die GPU-Chiplets Informationen austauschen können. Das Memory-IO ist auf den GPU-Chiplets und skaliert deshalb mit deren Anzahl.
Via Reddit
Impergator
Lieutnant
- Mitglied seit
- 03.04.2014
- Beiträge
- 77
- Renomée
- 9
- Mein Laptop
- HP Envy x360, Ryzen 5 4500U
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 3700X
- Mainboard
- ASRock Fatal1ty B450 Gaming K4
- Speicher
- 2 * 8GB Corsair Vengeance 3000MHz
- Grafikprozessor
- Gigabyte R9-285 Windforce
- SSD
- PNY XLR8 CS3030 M.2 NVMe SSD 500GB
- Gehäuse
- Cooler Master HAF 912 PLUS Midi Tower schwarz
- Webbrowser
- Vivaldi
Es gibt neue Details zum V3D-Stacking: Es braucht gar keinen "glue" mehr, denn die Chips werden einfach aufeinander gelegt. Den Rest erledigen dann wohl die Van-der-Waals-Kräfte, also quasi kaltverschweißen.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Okay, so wirklich bewusst wurde mir das bisher nicht wie revolutionär das eigentlich ist, aber hier gab es auch schon etwas dazu:

 fuse.wikichip.org
fuse.wikichip.org
AMD 3D Stacks SRAM Bumplessly
AMD recently unveiled 3D V-Cache, their first 3D-stacked technology-based product. Leapfrogging contemporary 3D bonding technologies, AMD jumped directly into advanced packaging with direct bonding and an order of magnitude higher wire density.
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.884
- Renomée
- 39
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Wie das erklärt wird, wird der Core Die um 95% abgeschliffen und dann der stakt L3 mit zwei Profilen einfach draufgelegt. Da kann man gespannt sein wie die Wärmeleitfähigkeit ist. Strukturbrüche bei der Kühler Montage oder beim Transport?
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
TSMC Verfahren für SoIC Stacking:
 3dfabric.tsmc.com
3dfabric.tsmc.com

3dfabric.tsmc.com

Die Anwendung bei RDNA3 wird vermutet.
TSMC-SoIC® - Taiwan Semiconductor Manufacturing Company Limited
TSMC-SoIC™ services include custom manufacture of semiconductors, memory chips, wafers, integrated circuits, product research, custom design and testing for new product development, and technology consultation services regarding electrical and electronic products, semiconductors, semiconductor systems, semiconductor cell libraries, wafers, and integrated circuits.
What is SoIC?
SoIC is a key technology pillar to advance the field of heterogeneous chiplets integration with reduced size, increased performance. It features ultra-high-density-vertical stacking for high performance, low power, and min RLC (resistance-inductance-capacitance). SoIC integrates active and passive chips into a new integrated-SoC system, which is electrically identical to native SoC, to achieve better form factor and performance.
The key features of SoIC technology include:
- Enables the heterogeneous integration (HI) of known good dies (KGDs) with different chip sizes, functionalities and wafer node technologies.
(a) SoC before chip partition; (b), (c), (d) Variant partitioned chiplets and re-integrated schemes enabled by SoIC technology
TSMC-SoIC® - Taiwan Semiconductor Manufacturing Company Limited
TSMC SoIC-WoW technology realize heterogeneous and homogeneous 3D silicon integration through wafer stacking process. The tight bonding pitch and thin TSV enable minimum parasitic for better performance, lower power and latency as well as smaller form factor. WoW is suitable for high yielding nodes and the same die size applications or design, it even supports integration with 3rd party wafer.
Die Anwendung bei RDNA3 wird vermutet.
Zuletzt bearbeitet:
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Das Schaubild b) entspricht den Zen3D V-Cache Lösungen. Die TSMC Darstellungen zeigen keine Lösung, mit der zwei gleiche GPU Dies mit einem weiteren Memory Die als Brücke verknüpft werden. Bei RDNA3 wäre deshalb meine Erwartungshaltung der Cache ist im Interposer und die GPU Dies werden auf dieser Basis verknüpft, statt dass ein Die zwei andere Dies überspannt. Das hätte vielleicht den Vorteil, dass die hitzigen hochtaktenden Chips etwas räumlichen Abstand bekommen könnten. Oder der Memory Die liegt genau zwischen den GPU-Dies, die Lanes zur Anbindung müssten dann Spiegelverkehrt angeordnet sein. Ich wüsste aber nicht ob das beim Cache-Design stören würde.
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Bei RDNA3 wäre deshalb meine Erwartungshaltung der Cache ist im Interposer und die GPU Dies werden auf dieser Basis verknüpft, statt dass ein Die zwei andere Dies überspannt. Das hätte vielleicht den Vorteil, dass die hitzigen hochtaktenden Chips etwas räumlichen Abstand bekommen könnten. Oder der Memory Die liegt genau zwischen den GPU-Dies, die Lanes zur Anbindung müssten dann Spiegelverkehrt angeordnet sein. Ich wüsste aber nicht ob das beim Cache-Design stören würde.
Das ist ja das Schöne, es wird bei den GPUs und auch bei den CPUs in Zukunft nicht nur spannend von der Performance, sondern auch von den technischen Lösungen.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
AMDs Patent gibt hier glaube ich eine gute Antwort:
Hier ist wohl das "active bridge-chiplet" der entscheidende Faktor.
https://www.freepatentsonline.com/y2021/0097013.html
https://www.computerbase.de/2021-04/gpus-im-chiplet-design-amd-patente-bringen-den-cache-ins-spiel/
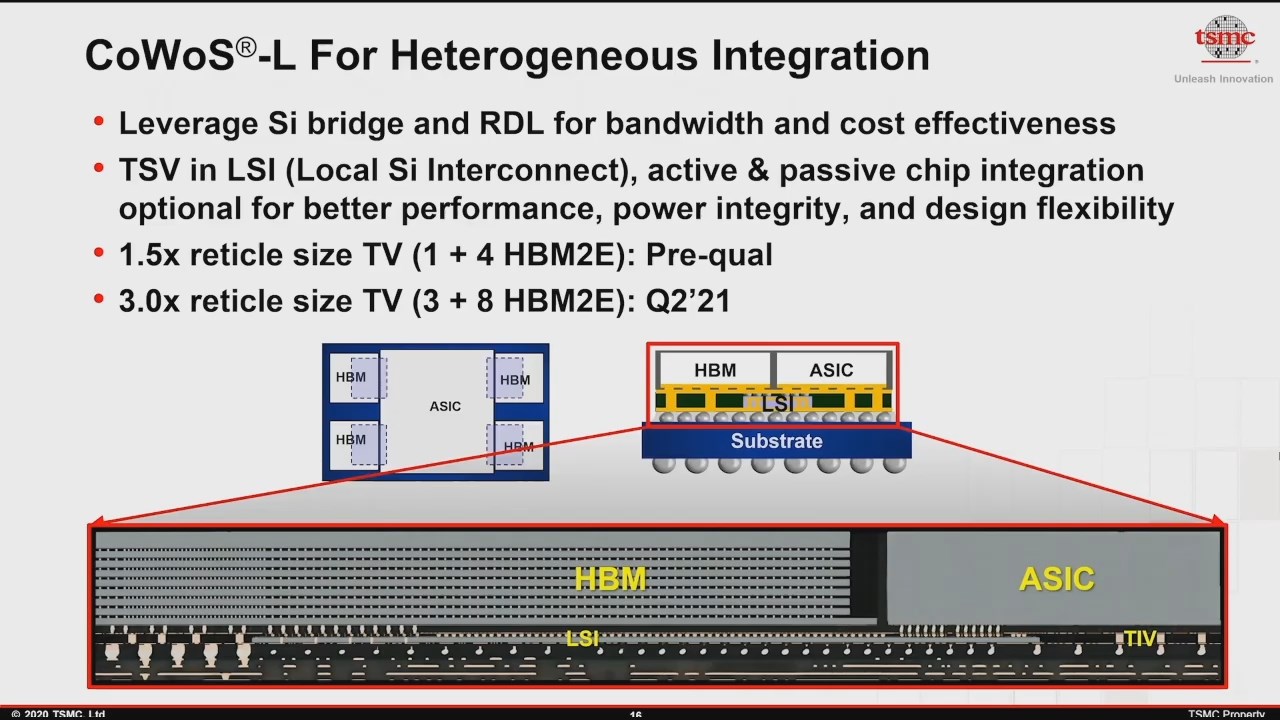
Ich denke hier ist das von AMD angewandte Packaging-Verfahren von TSMC beschrieben:
https://www.anandtech.com/Show/Inde...age=1&slug=tsmcs-version-of-emib-lsi-3dfabric

Aus dem Startbeitrag eine Tabelle über Yieldraten bei der Herstellung von aktiven/passiven Interposern. Mit dem Wafer-On-Wafer Verfahren kann hier sicherlich noch mehr rausgeholt werden")

Passive Bridge:
Aktive Bridge:
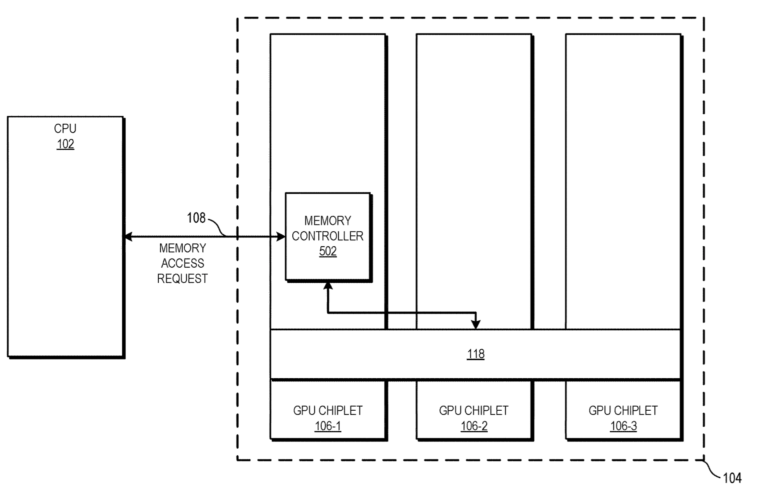
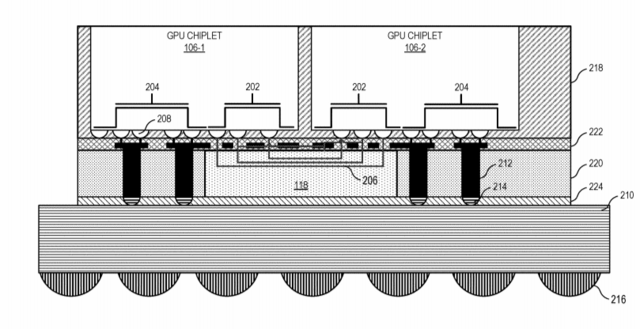
Active Bridge: 118
Hier ist wohl das "active bridge-chiplet" der entscheidende Faktor.
https://www.freepatentsonline.com/y2021/0097013.html
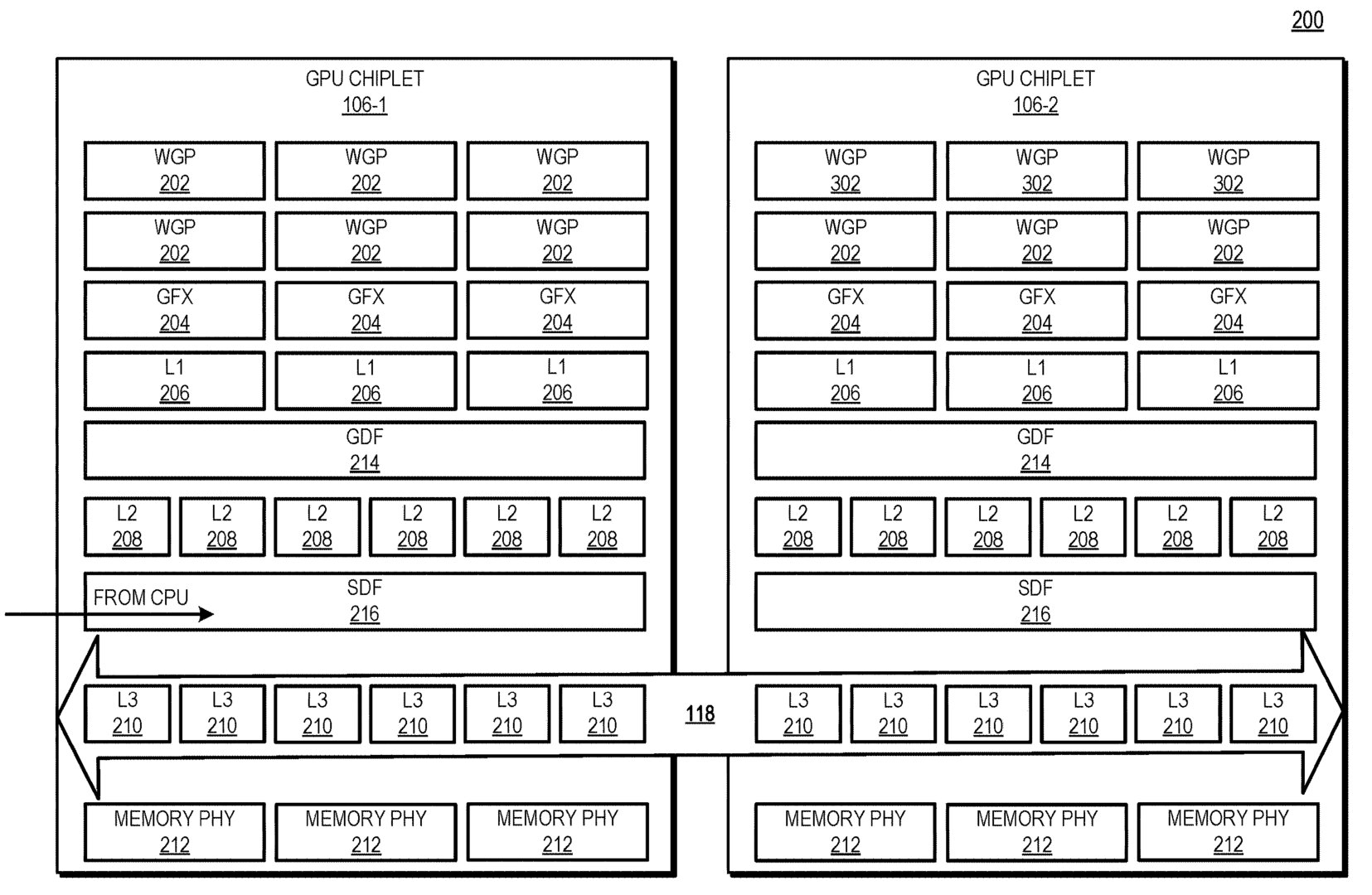
Accordingly, as discussed herein, an active bridge chiplet deploys monolithic GPU functionality using a set of interconnected GPU chiplets in a manner that makes the GPU chiplet implementation appear as a traditional monolithic GPU from a programmer model/developer perspective. The scalable data fabric of one GPU chiplet is able to access the lower level cache(s) on the active bridge chiplet in nearly the same time as to access the lower level cache on its same chiplet, and thus allows the GPU chiplets to maintain cache coherency without requiring additional inter-chiplet coherency protocols. This low-latency, inter-chiplet cache coherency in turn enables the chiplet-based system to operate as a monolithic GPU from the software developer's perspective, and thus avoids chiplet-specific considerations on the part of a programmer or developer.
https://www.computerbase.de/2021-04/gpus-im-chiplet-design-amd-patente-bringen-den-cache-ins-spiel/
Die "Active Bride´" ist unter den Chiplets verbaut wie ein Interposer.Der Cache wandert auf die Brücke
Die Besonderheit der „Active Bridge“ besteht darin, dass der L3-Speicher direkt auf der Brückenverbindung und nicht mehr auf dem entsprechenden GPU-Chiplet untergebracht werden soll. Das erklärt auch die aktive Auslegung der Brücke.
Zudem ist die Größe des L3-Cache damit durch die Größe der „Active Bridge“ beliebig skalierbar und ermöglicht Lösungen für Systeme respektive GPUs und Beschleunigern mit wenigen (1 bis 2) oder vielen (3 und mehr) GPU-Chiplets.
Der L3-Cache ist damit auch von der Hitzeentwicklung und dem Stromverbrauch der GPU-Chiplets entkoppelt. Ob der Cache damit tatsächlich besser gekühlt werden kann oder einfach die dezentrale Hitzeentwicklung von Vorteil ist, geht aus der Patentschrift indes nicht hervor.
Ich denke hier ist das von AMD angewandte Packaging-Verfahren von TSMC beschrieben:
https://www.anandtech.com/Show/Inde...age=1&slug=tsmcs-version-of-emib-lsi-3dfabric
InFO is TSMC’s fan-out packaging technology, where a silicon die from a wafer is picked out and placed on a carrier wafer, upon which the further bigger structures such as the copper RDL (Redistribution layer), and later the carrier substrate is built upon.
TSMC’s variant of InFO with integration of an LSI is called InFO-L or InFO-LSI, and follows a similar structure with the new addition of it integrating this new local silicon interconnect intermediary chip for communication between two chips.
Aus dem Startbeitrag eine Tabelle über Yieldraten bei der Herstellung von aktiven/passiven Interposern. Mit dem Wafer-On-Wafer Verfahren kann hier sicherlich noch mehr rausgeholt werden
Passive Bridge:
Aktive Bridge:
Active Bridge: 118
Zuletzt bearbeitet:
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.884
- Renomée
- 39
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Den Cache kann man anscheinend sehr gut stapeln der braucht so gut wie nichts. Das sah zu Phenom Zeiten noch anders aus. Da waren zwischen Athlon mit deaktivierten L3 und dem normalen Phenom Welten im Verbrauch.
╭── Power Consumption ──────────────────────────┬────────────────────────────────────────────────╮
│ Total Core Power Sum │ 76.132 W │
│ VDDCR_SOC Power │ 17.879 W │
│ GMI2_VDDG Power │ 6.211 W │
│ L3 Logic Power │ 0.719 W + 0.723 W │
│ │ + 0.401 W + 0.398 W = 2.241 W │
│ L3 VDDM Power │ 0.362 W + 0.362 W │
│ │ + 0.361 W + 0.360 W = 1.444 W │
│ │ │
│ VDDIO_MEM Power │ 8.112 W │
│ IOD_VDDIO_MEM Power │ 0.000 W │
│ DDR_VDDP Power │ 4.799 W │
│ VDD18 Power │ 0.800 W │
│ │ │
│ Calculated Thermal Output │ 117.620 W │
├── Additional Reports ─────────────────────────┼────────────────────────────────────────────────┤
│ SoC Power (SVI2) │ 1.124 V | 15.903 A | 17.879 W │
│ Core Power (SVI2) │ 1.256 V | 83.018 A | 104.297 W │
│ Core Power (SMU) │ 104.297 W │
│ Socket Power (SMU) │ 132.087 W │
╰───────────────────────────────────────────────┴────────────────────────────────────────────────╯
╭── Power Consumption ──────────────────────────┬────────────────────────────────────────────────╮
│ Total Core Power Sum │ 76.132 W │
│ VDDCR_SOC Power │ 17.879 W │
│ GMI2_VDDG Power │ 6.211 W │
│ L3 Logic Power │ 0.719 W + 0.723 W │
│ │ + 0.401 W + 0.398 W = 2.241 W │
│ L3 VDDM Power │ 0.362 W + 0.362 W │
│ │ + 0.361 W + 0.360 W = 1.444 W │
│ │ │
│ VDDIO_MEM Power │ 8.112 W │
│ IOD_VDDIO_MEM Power │ 0.000 W │
│ DDR_VDDP Power │ 4.799 W │
│ VDD18 Power │ 0.800 W │
│ │ │
│ Calculated Thermal Output │ 117.620 W │
├── Additional Reports ─────────────────────────┼────────────────────────────────────────────────┤
│ SoC Power (SVI2) │ 1.124 V | 15.903 A | 17.879 W │
│ Core Power (SVI2) │ 1.256 V | 83.018 A | 104.297 W │
│ Core Power (SMU) │ 104.297 W │
│ Socket Power (SMU) │ 132.087 W │
╰───────────────────────────────────────────────┴────────────────────────────────────────────────╯
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
Ich finde es auch gerade sehr spannend, was uns die Modularisierung mit unterschiedlichen Herstellungsprozessen so bringt. Wir stehen mit AMDs Chiplet Technologie ja erst ganz am Anfang. Immerhin wissen wir, dass AMD angreift und früher als z.B. Intel auf den Zug aufgesprungen ist.
Aber man sollte nicht mehr denken, dass es monolithische SoCs zu entwickeln gibt. Gerade wird kolportiert, Intel wolle bei TSMC den 3nm Prozess nutzen. Da geht es m.E. eben nicht mehr um einen SoC sondern z.B. um Chiplets, die erst im Package mit z.B. SRAM, 3dXPoint, einer Photonic-Anbindung und dergleichen ihr Potential entfalten.
Richtig spannend ist es ja im GPU Bereich, welche Konzepte das Rennen machen.
Lassen wir uns überraschen.
MfG
Aber man sollte nicht mehr denken, dass es monolithische SoCs zu entwickeln gibt. Gerade wird kolportiert, Intel wolle bei TSMC den 3nm Prozess nutzen. Da geht es m.E. eben nicht mehr um einen SoC sondern z.B. um Chiplets, die erst im Package mit z.B. SRAM, 3dXPoint, einer Photonic-Anbindung und dergleichen ihr Potential entfalten.
Richtig spannend ist es ja im GPU Bereich, welche Konzepte das Rennen machen.
Lassen wir uns überraschen.
MfG
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Den Cache kann man anscheinend sehr gut stapeln der braucht so gut wie nichts. Das sah zu Phenom Zeiten noch anders aus. Da waren zwischen Athlon mit deaktivierten L3 und dem normalen Phenom Welten im Verbrauch.
Denke auch dass die Cache-Technologien von AMD eine der wichtigsten Säulen für den Erfolg darstellen.
Vor Zen war man mit den Cache-Latenzen immer hinter Intel zurück. Man musste sich immer zwischen schnellen kleineren Caches oder gleichgrosse langsamere Caches entscheiden. Für Gaming, bzw. Latenz-kritische Anwendungen ein entscheidender Nachteil. Mittlerweile hat man zunächst mit Intel bei den Latenzen und Cachegrössen gleichgezogen und dann deutlich überhohlt. (Ich vermute z.B. bei Ur-Vega auf GloFo war der Cache zu klein, die V56 hatte oft die gleiche Leistung wie V64 weil der Shared Cache schon zu klein war, RDNA hat das Problem mit DCUs und zus. L1 gelöst, RDNA2 mit InfinityCache weiter optimiert).
Die Ursache liegt dabei stets in der Fertigungstechnologie, was dort möglich ist. Mit 3D Stapeln beim Cache kann der neuerdings immens gross werden ohne dabei langsamer zu werden. Über IF ist auch der verteilte Cache im McM immer noch schneller als ein RAM Zugriff über einen MemoryController.
Man kann AMD nur wünschen auch weiterhin ein glückliches Händchen zu haben um mit den fortschrittlichste Fertigungstechnologien die jeweils optimalen Kombinationen zu finden.
Eines der Hauptproblem der CPUs vor Zen war der fehlende Micro-Op-Cache. Ohne diesen mussten die Instruktionen ständig wieder aus dem L1 gelesen und aufwändig dekodiert werden. Die Latenzen der Caches sind auch bei Zen, Zen+, Zen2 und Zen3 nicht berauschend.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Berauschend nicht, entscheidend ist, dass man trotz und mit der Grösse der Caches an Intel vorbei gezogen ist.

 www.anandtech.com
www.anandtech.com
 www.anandtech.com
www.anandtech.com

das war mit Nachteilen in der Fertigung zuvor nicht möglich. Bei GPUs zeichnet sich ein ähnliches Bild wobei der direkte Vergleich ungleich schwieriger ist.
AMD Ryzen 9 5980HS Cezanne Review: Ryzen 5000 Mobile Tested
AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
das war mit Nachteilen in der Fertigung zuvor nicht möglich. Bei GPUs zeichnet sich ein ähnliches Bild wobei der direkte Vergleich ungleich schwieriger ist.
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 985
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS PRIME X370-PRO
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Hier geht es zwar um AMD, aber es passt thematisch ganz gut dazu. Intel gewährt einen Einblick in Fab 42:

 www.computerbase.de
www.computerbase.de
Fab 42: Intel gewährt seltenen Blick hinter die Kulissen
Das US-Magazin CNET bekam die Möglichkeit, einen seltenen Blick in Intels Fab 42 in Arizona zu werfen und liefert interessante Fotos.
www.computerbase.de
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Aus dem Whitepaper:

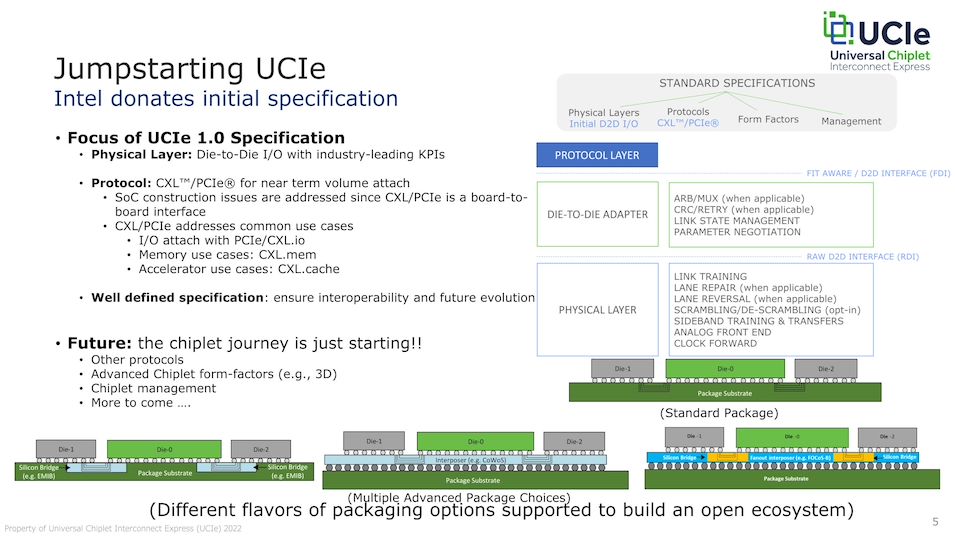

Die ganze Präsentation bei Anandtech: https://www.anandtech.com/Gallery/Album/8123#1
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
AMD Patent für GPUs mit aktivem Interposer veröffentlicht:
 www.freepatentsonline.com
Es gibt eine Zusammenfassung in beyond3D: https://forum.beyond3d.com/threads/...urs-and-discussion.62092/page-93#post-2267467
www.freepatentsonline.com
Es gibt eine Zusammenfassung in beyond3D: https://forum.beyond3d.com/threads/...urs-and-discussion.62092/page-93#post-2267467

 forum.beyond3d.com
forum.beyond3d.com
DIE STACKING FOR MODULAR PARALLEL PROCESSORS - ADVANCED MICRO DEVICES, INC.
<div p-id="p-0001">A multi-die parallel processor semiconductor package includes a first base IC die including a first plurality of virtual compute dies 3D stacked on top of the first base IC die. A f
www.freepatentsonline.com
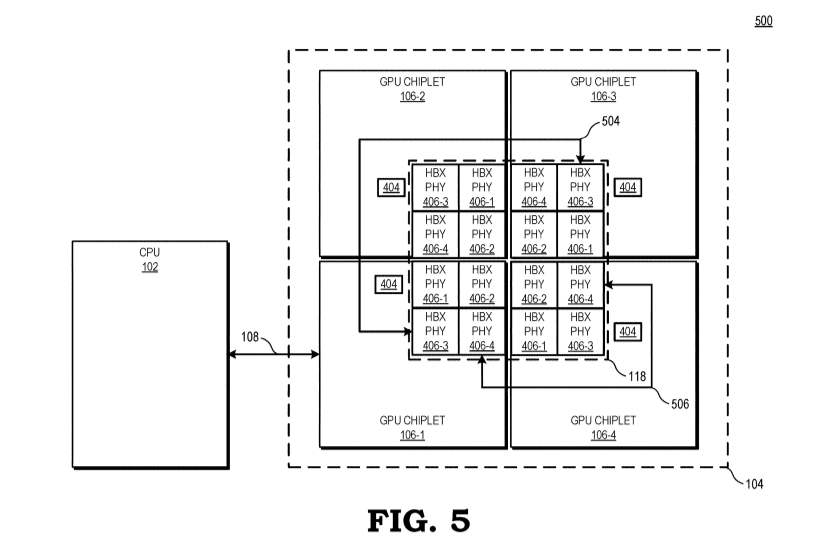
So we have:
- active interposer die (AID)
- shader engine die (SED)
- multimedia and I/O die (MID)
- graphics complex die (GCD)
AMD: RDNA 3 Speculation, Rumours and Discussion
The diagrams are now available, e.g.: In this diagram each AID features: cache (610) command processor (606) GDDR PHY (614) stacked upon each AID are shader engine dies and the AIDs are connected by bridge chiplets. The Multimedia and IO Die (708) is shown as a separate chiplet mounted on...
forum.beyond3d.com
In this diagram each AID features:
- cache (610)
- command processor (606)
- GDDR PHY (614)

Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Co-Prozessor Dispatching für GPU Workloads - Technologie für MCM-GPUs mit Multi-GCDs

Dies soll weniger Platz einnehmen als der bisherige Re-Order Buffer bei RDNA2, könnte allerdings auch rein für CDNA genutzt werden.
Siehe Einleitung Patent im PDF: https://patentimages.storage.googleapis.com/bd/95/52/54cd3dc8932312/US20210216368A1.pdf
Siehe https://www.angstronomics.com/p/amds-rdna-3-graphics?s=31
US20210216368A1 - Hardware accelerated dynamic work creation on a graphics processing unit - Google Patents
A processor core is configured to execute a parent task that is described by a data structure stored in a memory. A coprocessor is configured to dispatch a child task to the at least one processor core in response to the coprocessor receiving a request from the parent task concurrently with the...
patents.google.com
- The processing system 100 includes a graphics processing unit (GPU) 115 that is configured to render images for presentation on a display 120. For example, the GPU 115 can render objects to produce values of pixels that are provided to the display 120, which uses the pixel values to display an image that represents the rendered objects. Some embodiments of the GPU 115 can also be used for general purpose computing. In the illustrated embodiment, the GPU 115 implements multiple processing elements (also referred to as compute units) 125 that are configured to execute instructions concurrently or in parallel. The GPU 115 also includes an internal (or on-chip) memory 130 that includes a local data store (LDS), as well as caches, registers, or buffers utilized by the processing elements 125. The internal memory 130 stores data structures that describe parent tasks executing on one or more of the processing elements 125. In the illustrated embodiment, the GPU 115 communicates with the memory 105 over the bus 110. However, some embodiments of the GPU 115 communicate with the memory 105 over a direct connection or via other buses, bridges, switches, routers, and the like. The GPU 115 can execute instructions stored in the memory 105 and the GPU 115 can store information in the memory 105 such as the results of the executed instructions. For example, the memory 105 can store a copy 135 of instructions from a program code that is to be executed by the GPU 115.
- The processing system 100 also includes a central processing unit (CPU) 140 that is connected to the bus 110 and can therefore communicate with the GPU 115 and the memory 105 via the bus 110. In the illustrated embodiment, the CPU 140 implements multiple processing elements (also referred to as processor cores) 143 that are configured to execute instructions concurrently or in parallel. The CPU 140 can execute instructions such as program code 145 stored in the memory 105 and the CPU 140 can store information in the memory 105 such as the results of the executed instructions. The CPU 140 is also able to initiate graphics processing by issuing draw calls to the GPU 115.
Dies soll weniger Platz einnehmen als der bisherige Re-Order Buffer bei RDNA2, könnte allerdings auch rein für CDNA genutzt werden.
Siehe Einleitung Patent im PDF: https://patentimages.storage.googleapis.com/bd/95/52/54cd3dc8932312/US20210216368A1.pdf
Ob das RDNA-tauglich ist, ist noch nicht sicher. Möglicherweise steckt es aber auch hinter dem OREO-Feature bei RDNA3This invention was made with Government support under PathForward Project with Lawrence Livermore National Security (Prime Contract No. DE - AC52
07NA27344, Subcontract No. B620717 ) awarded by DOE . The Government has certain rights in this invention.
Siehe https://www.angstronomics.com/p/amds-rdna-3-graphics?s=31
One of the features in the RDNA 3 graphics pipeline is OREO: Opaque Random Export Order, which is just one of the many area saving techniques. With gfx10, the pixel shaders run out-of-order, where the outputs go into a Re-Order Buffer before moving to the rest of the pipeline in-order. With OREO, the next step (blend) can now receive and execute operations in any order and export to the next stage in-order. Thus, the ROB can be replaced with a much smaller skid buffer, saving area.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.

AMD Lays The Path To Zettascale Computing: Talks CPU & GPU Performance Plus Efficiency Trends, Next-Gen Chiplet Packaging & More
AMD talked about the future of computing, laying out its CPU & GPU trends in terms of efficiency & performance during ISSCC 2023.
Whitepaper UCIe
Die ganze Präsentation bei Anandtech: https://www.anandtech.com/Gallery/Album/8123#1
Zuletzt bearbeitet:
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
@Complicated
Bitte nach Möglichkeit keine Bilder fremder Webseiten per Link einfach einfügen. Bei Slides, deren IP eh nicht bei den Webseiten liegt, lieber diese kopieren und in das Posting einfügen.
Die ISSCC Slides gibt es komplett bei uns:
Bitte nach Möglichkeit keine Bilder fremder Webseiten per Link einfach einfügen. Bei Slides, deren IP eh nicht bei den Webseiten liegt, lieber diese kopieren und in das Posting einfügen.
Die ISSCC Slides gibt es komplett bei uns:
ISSCC 2023: AMD - Innovation for the Next Decade of Compute Efficiency - Planet 3DNow!
Auf Planet 3DNow! gibt es alle wichtigen Informationen fr AMD-User: News, Downloads, Support, Tests
www.planet3dnow.de
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 495
- Antworten
- 0
- Aufrufe
- 557
- Antworten
- 0
- Aufrufe
- 950
- Antworten
- 0
- Aufrufe
- 1K