App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD präsentiert "Bulldozer" und "Bobcat" auf der Hot Chips
- Ersteller Dr@
- Erstellt am
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
<img src="http://vg04.met.vgwort.de/na/0b52664e099645c896122d33ef5f3a9c" width="1" height="1" alt="">
Am heutigen letzten Tag der alljährlich stattfindenden "Hot Chips"-Konferenz präsentiert AMD in zwei Vorträgen weitere Details zu den beiden neuen leistungsfähigen und sparsamen x86 Mikroarchitekturen. Dem voraus gingen viele Ankündigungen, Details und Spekulationen, wie sie in unserem kürzlich erschienenen Bulldozer-Preview-Artikel bereits ausführlich behandelt werden.
Die nun vorgestellten Details zum "Bulldozer" klären einige offene Fragen und helfen, sich ein genaueres Bild von dessen Fähigkeiten zu machen, lassen aber dennoch Vieles im Dunkeln. Hier möchte AMD laut Aussage von John Fruehe dem Wettbewerber keine Vorteile durch eine zu frühe Bekanntgabe genauer Architekturmerkmale verschaffen.
In der folgenden Folie wird verdeutlicht, auf welche Zielmärkte die beiden neu entwickelten x86 Prozessorkerne ausgerichtet sind:

Demnach soll der erste Grundbaustein - das "Bulldozer"-Modul - die Märkte der Mainstream Notebooks über Desktops bis hin zu Servern abdecken. Das entspricht den mittleren bis oberen Leistungsklassen. So ein Modul, von dem es eins oder mehrere in zukünftigen Prozessoren geben wird, soll System und Software gegenüber als zwei Kerne erscheinen. Es dient also nur als Baustein bei der Entwicklung und nicht als logische Einheit, welche dem Benutzer sichtbar wird. Der "Bobcat"-Kern ist für Märkte von sparsamen oder physisch kleinen Prozessoren gedacht. Das entspricht also den unteren bis teilweise mittleren Leistungsklassen.
Auf den folgenden Seiten wollen wir uns nun die beiden neuen x86 Mikroarchitekturen etwas genauer ansehen.
[BREAK=Bulldozer]
<img src="http://vg04.met.vgwort.de/na/0b52664e099645c896122d33ef5f3a9c" width="1" height="1" alt="">
Zur Architektur des "Bulldozers" selbst war zu erfahren, dass ein wesentliches Ziel bei der Entwicklung ein hoher Durchsatz bei gleichzeitig hoher Energieeffizienz des Designs war. Schließlich bedeutet eine deutlich höhere Leistung pro Watt bei unveränderter TDP bzw. ACP auch eine entsprechend höhere Rechenleistung. Zudem sollen Befehlssatzerweiterungen wie AVX helfen, die Leistungsfähigkeit des Designs weiter zu erhöhen. Schließlich sollen Prozessoren auf Basis der "Bulldozer"-Architektur im neuen 32nm-SOI-Prozess von GlobalFoundries mit HKMG (High-k-Metal-Gate) hergestellt werden, welcher neben der Strukturverkleinerung vor allem Leistungssteigerungen und einen niedrigeren Energieverbrauch auf der Transistorebene mit sich bringen wird. Wie schon bei "Llano" auf der ISSCC 2010 gesagt wurde, bietet die Verwendung eines SOI-Prozesses gegenüber einem Bulk-Prozess sogar Vorteile bei der Umsetzung des Power-Gatings (Abschaltung der Energieversorgung für ganze Kerne oder nur Teile davon), da keine speziellen Transistoren oder zusätzliche Prozessschritte notwendig sind. Durch das Power-Gating kann die Leakage um den Faktor 10 gegenüber der bisherigen Implementierung in den K10 Prozessoren reduziert werden, wo lediglich die Unterbrechung des Taktsignals (Clock Gating) zur Reduktion der dynamischen Leakage möglich ist.
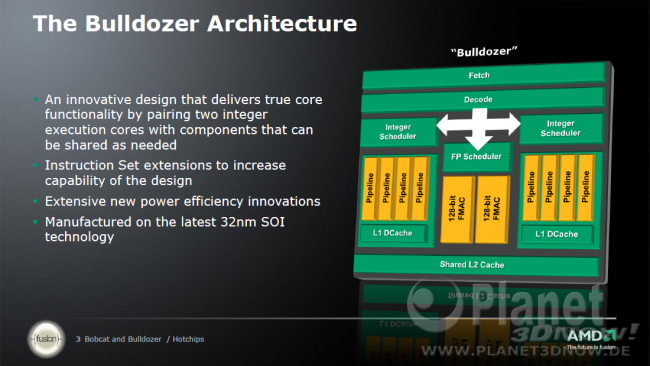
Auf den nächsten beiden Folien möchte AMD die Vorteile des "Bulldozer"-Designs verdeutlichen. Zuerst werden auf einer Folie Simultaneous Multithreading (SMT, von Intel "Hyperthreading" genannt) und Chip Multiprocessing (CMP, was alle Mehrkern-CPUs von AMD und anderen Herstellern sind) miteinander verglichen. SMT wird dabei als eine Art Zusammenführung zweier Fahrspuren dargestellt. Die beiden ausgeführten Threads müssen sich die verfügbaren Ressourcen (z.B. Ausführungseinheiten) teilen. Allerdings ist dieses Verfahren platzsparend. CMP stellt dagegen jedem Thread einen eigenen Kern zur Verfügung, was die Beibehaltung der zweiten Fahrspur symbolisieren soll. Dieser "Brute Force"-Ansatz erhöht den Platz- und Energiebedarf jedoch deutlich. Ineffizienzen bei der Nutzung von Ressourcen die von allen Kernen geteilt werden müssen (z.B. Wartezyklen bei einem Zugriff auf den Hauptspeicher), können nicht durch einen zweiten Thread verwendet werden.

Auf der zweiten Folie vergleicht AMD nun das Verfahren der "Bulldozer"-Architektur mit SMT. Während AMD den Begriff "Clustered Multithreading" nicht mehr benutzt, stand es aber schon 2005 auf einer Folie des "Bulldozer"-Chefentwicklers Chuck Moore als "Cluster-based Multithreading". Deshalb soll auch hier der Begriff CMT verwendet werden. Im Vergleich zu SMT ist hier deutlich zu erkennen, dass durch die Bereitstellung zusätzlicher Ressourcen an Stellen, wo es zu Engpässen (z.B. im L1-Daten-Cache oder bei den Ausführungseinheiten) kommen kann, eben diese vermieden werden können. Das erfolgt im Wesentlichen durch den zweiten Integer-Kern.

Das gemeinsame Nutzen von Einheiten des Prozessors, wie Fetch, Decode, FPU oder der Level-2-Caches, spart zuerst natürlich Transistoren (damit Die-Fläche und schließlich Kosten), reduziert damit aber auch den Energieverbrauch gegenüber einem "kompletten" zweiten Kern. Weiterhin können diese Einheiten je nach Bedarf der beiden angebundenen Kerne mehr für den einen, mehr für den anderen oder ausgeglichen für beide Kerne arbeiten. Im Falle eines einzigen Threads, welcher auf einem Modul läuft, stünden alle sonst gemeinsam genutzten Einheiten vollständig dem aktiven Kern zur Verfügung.
Einheiten, die bei der Nutzung durch zwei Threads zu starken Leistungseinbrüchen geführt hätten, wurden in diesem Architekturkonzept einfach dupliziert. Das ganze Design ist dadurch ausgewogen, Flaschenhälse sollen nicht existieren. Die zusätzliche Fläche der duplizierten Einheiten (der zweite Integer-Kern) beträgt laut John Fruehe von AMD etwa 12,5% gegenüber einem Modul-Design mit nur einem Kern.
AMD hat auch ein paar Details zu den Einheiten des Moduls verraten. Zum Beispiel soll es pro 4-way Out-of-Order Integer-Kern eine Integer-MAC-Einheit geben (für einige XOP/AVX-Integer-Befehle), begleitet von AGUs und ALUs. Demnach werden Integer-SIMD-Befehle wahrscheinlich auf den Integer-Kernen ausgeführt, während Floating-Point-SIMD-Befehle von der FPU ausgeführt werden. So würde bei Integer-SIMD-Code (z.B. in vielen Codecs) jeder Kern ungestört rechnen können, während die FPU möglicherweise vollständig abgeschaltet wird. Hier ist auch die energieeffiziente Mehrfachverwendung von Schaltungen vorstellbar (z.B. Teile der ALU für SIMD-Operationen).
Die dargestellten 128-bit FMAC-Einheiten werden laut AMD je von einer weiteren Einheit ergänzt, welche für andere Floating-Point-Operationen zuständig ist. Diese Befehle könnten z.B. Shuffle/Permute-Operationen sein. Deshalb kann die FPU eines Moduls wohl auch bis zu vier Befehle pro Takt (je bis zu 128-bit) ausführen, was von Chuck Moore bereits im November verraten wurde. Die FMAC-Einheiten werden nicht in der Lage sein, statt eines FMAC-Befehls gleichzeitig einen FADD- und einen FMUL-Befehl auszuführen.
Schließlich verriet AMD noch Details zum Energiemanagement. Ein Prozessor mit "Bulldozer"-Architektur ist in der Lage, die Auslastung einzelner Komponenten zu ermitteln und die verfügbaren Energieressourcen für eine effiziente Ausführung umzuverteilen, um z.B. einen Kern höher zu takten. So ähnlich wurde bereits in unserem Preview-Artikel spekuliert. Sollte nur ein Thread auf einem Modul laufen, würde der ungenutzte Kern komplett abgeschaltet werden und der andere entsprechend des Energiespielraums höher getaktet.

In der nächsten Folie ist dargestellt, wie die Module genutzt werden, um mit weiteren Komponenten einen 8-Kern-Prozessor zu bilden. Es wird hervorgehoben, dass die Modulstruktur nach außen für das Betriebssystem, die Software und den Anwender nicht sichtbar sein wird. Die Modulstruktur erlaubt AMD jedoch, mit diesem Architekturbaustein schneller und effizienter verschiedene Prozessoren zu entwickeln, die auf ganz bestimmte Erfordernisse abgestimmt sind.

Es wird deutlich, dass die "Bulldozer"-Architektur eine wirkliche Neuentwicklung darstellt und ein hohes Potenzial in den geplanten Märkten besitzen könnte. Wie auch schon kürzlich bekanntgegeben wurde, soll ein "Interlagos"-Prozessor für Server mit seinen 16 Kernen bei vergleichbarer Leistungsaufnahme ca. 50% mehr Leistung erreichen können als ein 12-kerniger "Magny-Cours"-Prozessor. "Interlagos" wird voraussichtlich auch der erste Prozessor mit der "Bulldozer"-Architektur sein.

[BREAK=Bobcat]
<img src="http://vg09.met.vgwort.de/na/c276ab3bf52b408299fd192479a8e3e8" width="1" height="1" alt="">
Während der "Bulldozer" in erster Linie auf den Servermarkt und den High-End Desktopmarkt abzielt, hat AMD für den Notebook-, Netbook- sowie Nettopmarkt mit dem Low-Power x86-Kern "Bobcat“ erstmals von Grund auf eine eigene Mikroarchitektur entwickelt, die einzig auf die Bedürfnisse dieser Märkte abgestimmt ist. Weil sich der zweite Fusion-Prozessor "Llano“ um ein paar Monate verzögert, wird der "Ontario“ nicht nur der Prozessor sein, in dem der "Bobcat“-Kern Premiere feiert, sondern auch der erste kaufbare Vertreter der lang angekündigten Fusion-Prozessorfamilie von AMD. Der "Ontario“ wird im 40nm Prozess des Auftragsherstellers TSMC gefertigt.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10827"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10827&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Bei der Entwicklung des "Bobcat“ hat sich AMD zum Ziel gesetzt, einen kleinen, effizienten Low-Power x86 Kern zu erschaffen, der aber trotzdem eine gute Performance liefert und zudem synthetisierbar sein soll, sodass durch die Verwendung entsprechender Tools dieser Kern auf relativ einfache Art und Weise in kundenspezifische Designs integrierbar ist. Zudem soll dieser Design-Ansatz den Wechsel zwischen unterschiedlichen Fabs und Prozessen stark vereinfachen und damit beschleunigen.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10828"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10828&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Entstanden ist ein Out-of-Order x86-Kern, der - entsprechende Anpassungen bei Takt und Spannung vorausgesetzt - sogar bis unter ein Watt Leistungsaufnahme skalierbar sein soll. Dabei will der kleinere x86-Riese 90% der Leistung eines heutigen Mainstream-Prozessors erreichen, wobei nur die Hälfe der Die-Fläche dazu benötigt wird. Was genau unter Mainstream zu verstehen ist, will AMD aber auch weiterhin nicht genauer spezifizieren. Als Anhaltspukt wurde aber die heutige K10 Architektur benannt, und erst zur Produktvorstellung will man hier konkreter werden.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10829"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10829&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Der "Bobcat“-Kern kann bis zu zwei Befehle pro Takt dekodieren und an die Recheneinheiten absetzen. Sowohl die Berechnungen als auch die Speicherzugriffe erfolgen Out-of-Order und sollen zusammen mit der Unterstützung von AMD64, SSE1, SSE2 und SSE3 sowie einer verbesserten Sprungvorhersage (Branch-Prediction) zur Vermeidung unnötiger Wartezyklen, für die versprochene Leistung sorgen. Um die Balance zur Die-Größe und Leistungsaufnahme halten zu können, wurden die beiden L1-Caches auf jeweils 32 KiB verkleinert. Außerdem sollen nicht benötigte Einheiten durch Clock-Gating und Power-Gating abgeschaltet werden können.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10830"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10830&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Weil sich der zweite Fusion-Prozessor "Llano“ wegen Problemen mit der Ausbeute des 32nm HKMG Prozesses bei GlobalFoundries um ein paar Monate verzögert, wird der "Ontario“ – in den bis zu zwei x86 "Bobcat“ Kerne sowie ein DirectX 11 Grafikkern integriert sind - als erste APU (Accelerated Processing Unit) von AMD auf den Markt kommen. Ende diesen Jahres soll die Produktion bei TSMC hochfahren, sodass im ersten Quartal 2011 die ersten Systeme der Partner verfügbar werden. Sowohl über die Anbindung des GPU-Kerns (SIMD Engine Array) an die Northbridge als auch über die Anbindung an den Hauptspeicher hüllt sich AMD auch weiterhin in Schweigen. Beide sollen aber breit genug sein um genügend Bandbreite bereitzustellen.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10831"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10831&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Abschließend werden nochmals die wichtigsten Punkte aus Sicht des Unternehmens zusammengefasst.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10832"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10832&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
[BREAK=Fazit]
<img src="http://vg09.met.vgwort.de/na/c276ab3bf52b408299fd192479a8e3e8" width="1" height="1" alt="">
Auch wenn es zu den Themen, für die sich wohl die meisten interessieren dürften, keine neuen Information gibt, deuten die bisherigen Informationen zumindest auf sehr wettbewerbsfähige Architekturen hin. Konkrete Angaben zur TDP, Benchmarks, dem verbauten GPU-Kern sowie dessen Anbindung gab es nicht. Diese Daten will das Unternehmen erst zur Präsentation der Produkte veröffentlichen. "Bulldozer" und "Bobcat" machen einen wirklich durchdachten und ausbalancierten Eindruck. Die Analyse vieler Anwendungen und die Neuentwicklung von Grund auf bot die Chance, beide Architekturen auf die Bedürfnisse im jeweiligen Marktsegment optimal anzupassen.
Mit dem "Bobcat"-Kern verfügt man endlich über eine eigene Architektur, die nicht nur über den Preis mit dem Atom-Prozessor von Intel konkurrieren kann, sondern auch in anderen Kenngrößen wie Die-Größe und Leistungsaufnahme. Zudem will AMD mit dem "Bobcat" eine höhere Effizienz dank des Out-of-Order-Designs erreicht haben, um so ausreichend Leistung für Alltagsaufgaben anbieten zu können. Außerdem soll das Design so flexibel angelegt sein, dass es sich leicht auf Kundenwünsche sowie andere Fertigungsprozesse (auch bei unterschiedlichen Foundries) anpassen lässt und AMD damit eine sehr große Flexibilität für zukünftige Produkte gibt.
Der "Bulldozer" zielt hingegen auf ein völlig anderes Marktsegment ab. Er soll für AMD die Leistungskrone zurückerobern. Ob dies auch gelingen wird, muss sich jedoch erst noch zeigen, schließlich hat AMD hier Einiges aufzuholen. Wie groß der Leistungssprung ausfallen wird, dürfte nicht zuletzt davon abhängen, wie gut der Balanceakt zwischen gemeinsam genutzten und getrennten Funktionseinheiten wirklich gelungen ist sowie der Abstimmung der Turbo-Funktionalität. Eine erste Analyse wird der "Interlagos" mit 12 und 16 Kernen erlauben, der nächstes Jahr den "Magny-Cours“ auf der AMD Opteron 6000 Plattform ablösen soll.
<center><object width="640" height="385"><param name="movie" value="http://www.youtube.com/v/VIs1CxuUrpc&rel=0&border=1&color1=0x2b405b&color2=0x6b8ab6&hl=de_DE&feature=player_embedded&fs=1"></param><param name="allowFullScreen" value="true"></param><param name="allowScriptAccess" value="always"></param><embed src="http://www.youtube.com/v/VIs1CxuUrpc&rel=0&border=1&color1=0x2b405b&color2=0x6b8ab6&hl=de_DE&feature=player_embedded&fs=1" type="application/x-shockwave-flash" allowfullscreen="true" allowScriptAccess="always" width="640" height="385"></embed></object></center>
<img src="http://vg09.met.vgwort.de/na/53d3ccaddb7b4f3e937634eb78bed119" width="1" height="1" alt="">
Am heutigen letzten Tag der alljährlich stattfindenden "Hot Chips"-Konferenz präsentiert AMD in zwei Vorträgen weitere Details zu den beiden neuen leistungsfähigen und sparsamen x86 Mikroarchitekturen. Dem voraus gingen viele Ankündigungen, Details und Spekulationen, wie sie in unserem kürzlich erschienenen Bulldozer-Preview-Artikel bereits ausführlich behandelt werden.
Die nun vorgestellten Details zum "Bulldozer" klären einige offene Fragen und helfen, sich ein genaueres Bild von dessen Fähigkeiten zu machen, lassen aber dennoch Vieles im Dunkeln. Hier möchte AMD laut Aussage von John Fruehe dem Wettbewerber keine Vorteile durch eine zu frühe Bekanntgabe genauer Architekturmerkmale verschaffen.
In der folgenden Folie wird verdeutlicht, auf welche Zielmärkte die beiden neu entwickelten x86 Prozessorkerne ausgerichtet sind:
Demnach soll der erste Grundbaustein - das "Bulldozer"-Modul - die Märkte der Mainstream Notebooks über Desktops bis hin zu Servern abdecken. Das entspricht den mittleren bis oberen Leistungsklassen. So ein Modul, von dem es eins oder mehrere in zukünftigen Prozessoren geben wird, soll System und Software gegenüber als zwei Kerne erscheinen. Es dient also nur als Baustein bei der Entwicklung und nicht als logische Einheit, welche dem Benutzer sichtbar wird. Der "Bobcat"-Kern ist für Märkte von sparsamen oder physisch kleinen Prozessoren gedacht. Das entspricht also den unteren bis teilweise mittleren Leistungsklassen.
Auf den folgenden Seiten wollen wir uns nun die beiden neuen x86 Mikroarchitekturen etwas genauer ansehen.
[BREAK=Bulldozer]
<img src="http://vg04.met.vgwort.de/na/0b52664e099645c896122d33ef5f3a9c" width="1" height="1" alt="">
Zur Architektur des "Bulldozers" selbst war zu erfahren, dass ein wesentliches Ziel bei der Entwicklung ein hoher Durchsatz bei gleichzeitig hoher Energieeffizienz des Designs war. Schließlich bedeutet eine deutlich höhere Leistung pro Watt bei unveränderter TDP bzw. ACP auch eine entsprechend höhere Rechenleistung. Zudem sollen Befehlssatzerweiterungen wie AVX helfen, die Leistungsfähigkeit des Designs weiter zu erhöhen. Schließlich sollen Prozessoren auf Basis der "Bulldozer"-Architektur im neuen 32nm-SOI-Prozess von GlobalFoundries mit HKMG (High-k-Metal-Gate) hergestellt werden, welcher neben der Strukturverkleinerung vor allem Leistungssteigerungen und einen niedrigeren Energieverbrauch auf der Transistorebene mit sich bringen wird. Wie schon bei "Llano" auf der ISSCC 2010 gesagt wurde, bietet die Verwendung eines SOI-Prozesses gegenüber einem Bulk-Prozess sogar Vorteile bei der Umsetzung des Power-Gatings (Abschaltung der Energieversorgung für ganze Kerne oder nur Teile davon), da keine speziellen Transistoren oder zusätzliche Prozessschritte notwendig sind. Durch das Power-Gating kann die Leakage um den Faktor 10 gegenüber der bisherigen Implementierung in den K10 Prozessoren reduziert werden, wo lediglich die Unterbrechung des Taktsignals (Clock Gating) zur Reduktion der dynamischen Leakage möglich ist.
Auf den nächsten beiden Folien möchte AMD die Vorteile des "Bulldozer"-Designs verdeutlichen. Zuerst werden auf einer Folie Simultaneous Multithreading (SMT, von Intel "Hyperthreading" genannt) und Chip Multiprocessing (CMP, was alle Mehrkern-CPUs von AMD und anderen Herstellern sind) miteinander verglichen. SMT wird dabei als eine Art Zusammenführung zweier Fahrspuren dargestellt. Die beiden ausgeführten Threads müssen sich die verfügbaren Ressourcen (z.B. Ausführungseinheiten) teilen. Allerdings ist dieses Verfahren platzsparend. CMP stellt dagegen jedem Thread einen eigenen Kern zur Verfügung, was die Beibehaltung der zweiten Fahrspur symbolisieren soll. Dieser "Brute Force"-Ansatz erhöht den Platz- und Energiebedarf jedoch deutlich. Ineffizienzen bei der Nutzung von Ressourcen die von allen Kernen geteilt werden müssen (z.B. Wartezyklen bei einem Zugriff auf den Hauptspeicher), können nicht durch einen zweiten Thread verwendet werden.
Auf der zweiten Folie vergleicht AMD nun das Verfahren der "Bulldozer"-Architektur mit SMT. Während AMD den Begriff "Clustered Multithreading" nicht mehr benutzt, stand es aber schon 2005 auf einer Folie des "Bulldozer"-Chefentwicklers Chuck Moore als "Cluster-based Multithreading". Deshalb soll auch hier der Begriff CMT verwendet werden. Im Vergleich zu SMT ist hier deutlich zu erkennen, dass durch die Bereitstellung zusätzlicher Ressourcen an Stellen, wo es zu Engpässen (z.B. im L1-Daten-Cache oder bei den Ausführungseinheiten) kommen kann, eben diese vermieden werden können. Das erfolgt im Wesentlichen durch den zweiten Integer-Kern.
Das gemeinsame Nutzen von Einheiten des Prozessors, wie Fetch, Decode, FPU oder der Level-2-Caches, spart zuerst natürlich Transistoren (damit Die-Fläche und schließlich Kosten), reduziert damit aber auch den Energieverbrauch gegenüber einem "kompletten" zweiten Kern. Weiterhin können diese Einheiten je nach Bedarf der beiden angebundenen Kerne mehr für den einen, mehr für den anderen oder ausgeglichen für beide Kerne arbeiten. Im Falle eines einzigen Threads, welcher auf einem Modul läuft, stünden alle sonst gemeinsam genutzten Einheiten vollständig dem aktiven Kern zur Verfügung.
Einheiten, die bei der Nutzung durch zwei Threads zu starken Leistungseinbrüchen geführt hätten, wurden in diesem Architekturkonzept einfach dupliziert. Das ganze Design ist dadurch ausgewogen, Flaschenhälse sollen nicht existieren. Die zusätzliche Fläche der duplizierten Einheiten (der zweite Integer-Kern) beträgt laut John Fruehe von AMD etwa 12,5% gegenüber einem Modul-Design mit nur einem Kern.
AMD hat auch ein paar Details zu den Einheiten des Moduls verraten. Zum Beispiel soll es pro 4-way Out-of-Order Integer-Kern eine Integer-MAC-Einheit geben (für einige XOP/AVX-Integer-Befehle), begleitet von AGUs und ALUs. Demnach werden Integer-SIMD-Befehle wahrscheinlich auf den Integer-Kernen ausgeführt, während Floating-Point-SIMD-Befehle von der FPU ausgeführt werden. So würde bei Integer-SIMD-Code (z.B. in vielen Codecs) jeder Kern ungestört rechnen können, während die FPU möglicherweise vollständig abgeschaltet wird. Hier ist auch die energieeffiziente Mehrfachverwendung von Schaltungen vorstellbar (z.B. Teile der ALU für SIMD-Operationen).
Die dargestellten 128-bit FMAC-Einheiten werden laut AMD je von einer weiteren Einheit ergänzt, welche für andere Floating-Point-Operationen zuständig ist. Diese Befehle könnten z.B. Shuffle/Permute-Operationen sein. Deshalb kann die FPU eines Moduls wohl auch bis zu vier Befehle pro Takt (je bis zu 128-bit) ausführen, was von Chuck Moore bereits im November verraten wurde. Die FMAC-Einheiten werden nicht in der Lage sein, statt eines FMAC-Befehls gleichzeitig einen FADD- und einen FMUL-Befehl auszuführen.
Schließlich verriet AMD noch Details zum Energiemanagement. Ein Prozessor mit "Bulldozer"-Architektur ist in der Lage, die Auslastung einzelner Komponenten zu ermitteln und die verfügbaren Energieressourcen für eine effiziente Ausführung umzuverteilen, um z.B. einen Kern höher zu takten. So ähnlich wurde bereits in unserem Preview-Artikel spekuliert. Sollte nur ein Thread auf einem Modul laufen, würde der ungenutzte Kern komplett abgeschaltet werden und der andere entsprechend des Energiespielraums höher getaktet.
In der nächsten Folie ist dargestellt, wie die Module genutzt werden, um mit weiteren Komponenten einen 8-Kern-Prozessor zu bilden. Es wird hervorgehoben, dass die Modulstruktur nach außen für das Betriebssystem, die Software und den Anwender nicht sichtbar sein wird. Die Modulstruktur erlaubt AMD jedoch, mit diesem Architekturbaustein schneller und effizienter verschiedene Prozessoren zu entwickeln, die auf ganz bestimmte Erfordernisse abgestimmt sind.
Es wird deutlich, dass die "Bulldozer"-Architektur eine wirkliche Neuentwicklung darstellt und ein hohes Potenzial in den geplanten Märkten besitzen könnte. Wie auch schon kürzlich bekanntgegeben wurde, soll ein "Interlagos"-Prozessor für Server mit seinen 16 Kernen bei vergleichbarer Leistungsaufnahme ca. 50% mehr Leistung erreichen können als ein 12-kerniger "Magny-Cours"-Prozessor. "Interlagos" wird voraussichtlich auch der erste Prozessor mit der "Bulldozer"-Architektur sein.
[BREAK=Bobcat]
<img src="http://vg09.met.vgwort.de/na/c276ab3bf52b408299fd192479a8e3e8" width="1" height="1" alt="">
Während der "Bulldozer" in erster Linie auf den Servermarkt und den High-End Desktopmarkt abzielt, hat AMD für den Notebook-, Netbook- sowie Nettopmarkt mit dem Low-Power x86-Kern "Bobcat“ erstmals von Grund auf eine eigene Mikroarchitektur entwickelt, die einzig auf die Bedürfnisse dieser Märkte abgestimmt ist. Weil sich der zweite Fusion-Prozessor "Llano“ um ein paar Monate verzögert, wird der "Ontario“ nicht nur der Prozessor sein, in dem der "Bobcat“-Kern Premiere feiert, sondern auch der erste kaufbare Vertreter der lang angekündigten Fusion-Prozessorfamilie von AMD. Der "Ontario“ wird im 40nm Prozess des Auftragsherstellers TSMC gefertigt.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10827"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10827&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Bei der Entwicklung des "Bobcat“ hat sich AMD zum Ziel gesetzt, einen kleinen, effizienten Low-Power x86 Kern zu erschaffen, der aber trotzdem eine gute Performance liefert und zudem synthetisierbar sein soll, sodass durch die Verwendung entsprechender Tools dieser Kern auf relativ einfache Art und Weise in kundenspezifische Designs integrierbar ist. Zudem soll dieser Design-Ansatz den Wechsel zwischen unterschiedlichen Fabs und Prozessen stark vereinfachen und damit beschleunigen.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10828"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10828&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Entstanden ist ein Out-of-Order x86-Kern, der - entsprechende Anpassungen bei Takt und Spannung vorausgesetzt - sogar bis unter ein Watt Leistungsaufnahme skalierbar sein soll. Dabei will der kleinere x86-Riese 90% der Leistung eines heutigen Mainstream-Prozessors erreichen, wobei nur die Hälfe der Die-Fläche dazu benötigt wird. Was genau unter Mainstream zu verstehen ist, will AMD aber auch weiterhin nicht genauer spezifizieren. Als Anhaltspukt wurde aber die heutige K10 Architektur benannt, und erst zur Produktvorstellung will man hier konkreter werden.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10829"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10829&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Der "Bobcat“-Kern kann bis zu zwei Befehle pro Takt dekodieren und an die Recheneinheiten absetzen. Sowohl die Berechnungen als auch die Speicherzugriffe erfolgen Out-of-Order und sollen zusammen mit der Unterstützung von AMD64, SSE1, SSE2 und SSE3 sowie einer verbesserten Sprungvorhersage (Branch-Prediction) zur Vermeidung unnötiger Wartezyklen, für die versprochene Leistung sorgen. Um die Balance zur Die-Größe und Leistungsaufnahme halten zu können, wurden die beiden L1-Caches auf jeweils 32 KiB verkleinert. Außerdem sollen nicht benötigte Einheiten durch Clock-Gating und Power-Gating abgeschaltet werden können.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10830"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10830&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Weil sich der zweite Fusion-Prozessor "Llano“ wegen Problemen mit der Ausbeute des 32nm HKMG Prozesses bei GlobalFoundries um ein paar Monate verzögert, wird der "Ontario“ – in den bis zu zwei x86 "Bobcat“ Kerne sowie ein DirectX 11 Grafikkern integriert sind - als erste APU (Accelerated Processing Unit) von AMD auf den Markt kommen. Ende diesen Jahres soll die Produktion bei TSMC hochfahren, sodass im ersten Quartal 2011 die ersten Systeme der Partner verfügbar werden. Sowohl über die Anbindung des GPU-Kerns (SIMD Engine Array) an die Northbridge als auch über die Anbindung an den Hauptspeicher hüllt sich AMD auch weiterhin in Schweigen. Beide sollen aber breit genug sein um genügend Bandbreite bereitzustellen.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10831"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10831&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
Abschließend werden nochmals die wichtigsten Punkte aus Sicht des Unternehmens zusammengefasst.
<center><a href="http://www.planet3dnow.de/photoplog/index.php?n=10832"><img src="http://www.planet3dnow.de/photoplog/file.php?n=10832&w=l" border="1" alt="Bobcat x86 Architektur"></a></center>
[BREAK=Fazit]
<img src="http://vg09.met.vgwort.de/na/c276ab3bf52b408299fd192479a8e3e8" width="1" height="1" alt="">
Auch wenn es zu den Themen, für die sich wohl die meisten interessieren dürften, keine neuen Information gibt, deuten die bisherigen Informationen zumindest auf sehr wettbewerbsfähige Architekturen hin. Konkrete Angaben zur TDP, Benchmarks, dem verbauten GPU-Kern sowie dessen Anbindung gab es nicht. Diese Daten will das Unternehmen erst zur Präsentation der Produkte veröffentlichen. "Bulldozer" und "Bobcat" machen einen wirklich durchdachten und ausbalancierten Eindruck. Die Analyse vieler Anwendungen und die Neuentwicklung von Grund auf bot die Chance, beide Architekturen auf die Bedürfnisse im jeweiligen Marktsegment optimal anzupassen.
Mit dem "Bobcat"-Kern verfügt man endlich über eine eigene Architektur, die nicht nur über den Preis mit dem Atom-Prozessor von Intel konkurrieren kann, sondern auch in anderen Kenngrößen wie Die-Größe und Leistungsaufnahme. Zudem will AMD mit dem "Bobcat" eine höhere Effizienz dank des Out-of-Order-Designs erreicht haben, um so ausreichend Leistung für Alltagsaufgaben anbieten zu können. Außerdem soll das Design so flexibel angelegt sein, dass es sich leicht auf Kundenwünsche sowie andere Fertigungsprozesse (auch bei unterschiedlichen Foundries) anpassen lässt und AMD damit eine sehr große Flexibilität für zukünftige Produkte gibt.
Der "Bulldozer" zielt hingegen auf ein völlig anderes Marktsegment ab. Er soll für AMD die Leistungskrone zurückerobern. Ob dies auch gelingen wird, muss sich jedoch erst noch zeigen, schließlich hat AMD hier Einiges aufzuholen. Wie groß der Leistungssprung ausfallen wird, dürfte nicht zuletzt davon abhängen, wie gut der Balanceakt zwischen gemeinsam genutzten und getrennten Funktionseinheiten wirklich gelungen ist sowie der Abstimmung der Turbo-Funktionalität. Eine erste Analyse wird der "Interlagos" mit 12 und 16 Kernen erlauben, der nächstes Jahr den "Magny-Cours“ auf der AMD Opteron 6000 Plattform ablösen soll.
<center><object width="640" height="385"><param name="movie" value="http://www.youtube.com/v/VIs1CxuUrpc&rel=0&border=1&color1=0x2b405b&color2=0x6b8ab6&hl=de_DE&feature=player_embedded&fs=1"></param><param name="allowFullScreen" value="true"></param><param name="allowScriptAccess" value="always"></param><embed src="http://www.youtube.com/v/VIs1CxuUrpc&rel=0&border=1&color1=0x2b405b&color2=0x6b8ab6&hl=de_DE&feature=player_embedded&fs=1" type="application/x-shockwave-flash" allowfullscreen="true" allowScriptAccess="always" width="640" height="385"></embed></object></center>
<img src="http://vg09.met.vgwort.de/na/53d3ccaddb7b4f3e937634eb78bed119" width="1" height="1" alt="">
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 493
- Antworten
- 0
- Aufrufe
- 2K
- Antworten
- 4
- Aufrufe
- 611