App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD RDNA2 / Navi-2 und "Bignavi"
- Ersteller BavarianRealist
- Erstellt am
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.883
- Renomée
- 39
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Ein paar Daten mit denen man rumspeckulieren kann.
5700xt 1700 MHz bei 0,85 Volt 130 Watt Boardpower max. bei Einstein@home pulsar
3090 um die 1700MHz bei 0,9 Volt 350 Watt Boradpower (der 8auer mit Shuntmod über 2000MHz bei 500 Watt)
Wenn Big Navi die doppelte größe von Navi hat kommt das mit den um die 300 Watt gut hin.
Auf jeden Fall braucht man Chips mit guter Güte um das zu realisieren.
5700xt 1700 MHz bei 0,85 Volt 130 Watt Boardpower max. bei Einstein@home pulsar
3090 um die 1700MHz bei 0,9 Volt 350 Watt Boradpower (der 8auer mit Shuntmod über 2000MHz bei 500 Watt)
Wenn Big Navi die doppelte größe von Navi hat kommt das mit den um die 300 Watt gut hin.
Auf jeden Fall braucht man Chips mit guter Güte um das zu realisieren.
Zuletzt bearbeitet:
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
MLID Big Navi Leak Video *Could be Maxwell Moment"
AMD hätte absichtlich viele Fake Informationen in Treibern und bei AIB Partner platziert.
(von mir vereinfacht) - seine Info:
ProSumer N21 - 250W, 80CU, 2.2GHz, 32GB GDDR6, 256bit, 3090/Quadro6000 Niveau (Q1/2021, 2k-3k$)
TopGamer N21 - 250W-300W, 72+CU, 2.3GHz, 16GB GDDR6, 256bit, >3080 Niveau (Thanksgiving 26.Nov.2020, 550-700$)
HighGamer N21 - 200W-250W, 60+CU, 2.3GHz, 16GB GDDR6, 256bit, >3070 Niveau (Dec.2020, 450-600$)
InfinityCache ist eher ein grooser Cache-Pool OnDie ähnlich wie bei Zen.
überwiegend spekulativ
UpperMid N22 - 160W-200W, 40 CU, 2.5GHz, 12GB GDDR6, 192bit (Jan.2021, 380-450$)
LowerMid N22 - 150W-180W, 32+CU, xGHz, 6/12GB GDDR6, 192bit (später, 300-380$)
Professional N22 - 155W, 36CU, 10GB GDDR6, 160bit
überwiegend spekulativ
EntryFamily N23 - 90W-150W, 24+ CU, 2.3GHz, 8GB GDDR6, 128bit (Q2/2021, 180-280$)
1080p @144Hz Gaming
Um auf das Cache-Thema zurückzukommen. MLID zitiert einige Quellen für einen Shared L1 Cache für alle CUs. Dieser würde gemäss Quellen je nach Pipeline-Stage bzw. Softwareanforderung dynamisch zwischen Shared und Private für die angehängten CUs wechseln können. Instruktionen, die weniger Latenz-Sensitiv sind könnten die Cache-Objekte dann ein einziges Mal für alle CUs vorhalten, statt dass die L1 Caches das gleiche Objekt vorhalten. Damit soll gemäss Paper rund 22% bis zu 52% mehr Performance, Faktor 2.3 bei Deep Learning, bis zu 49% mehr Energieeffizienz bei hoher Datenreplikation möglich sein.
(mein Take) Übersetzt aus der RDNA1 Grafik würde eine Art Infinity Fabric Protokoll notwendig sein um aus separaten L1 Caches einen gemeinsamen kohärenten Cache zu erstellen, der wie der L3 bei Zen CCX verteilt ist und via IF abgeglichen wird (das IF-Clock Tuning Thema via RAM der Zen1 Gen).

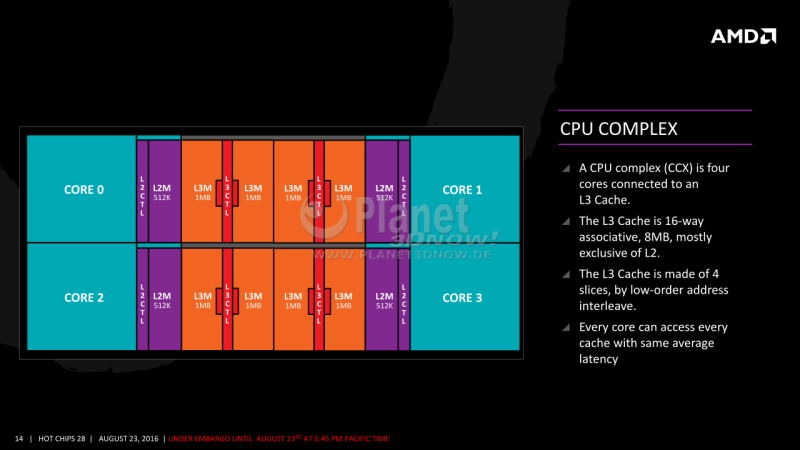
Was der neue Cache aber genau ist und warum RGT den als Infinity Cache bezeichnet hat ist weiterhin Spekulation. Gesichert scheint nur, dass hier viel Neues zu erwarten ist, was die 256bit Speicheranbindung ermöglicht.
Habe gerade noch nachgelesen, der RDNA1 L1 Cache ist zumindest schon per Shader Array vereinheitlicht
AMD hätte absichtlich viele Fake Informationen in Treibern und bei AIB Partner platziert.
(von mir vereinfacht) - seine Info:
ProSumer N21 - 250W, 80CU, 2.2GHz, 32GB GDDR6, 256bit, 3090/Quadro6000 Niveau (Q1/2021, 2k-3k$)
TopGamer N21 - 250W-300W, 72+CU, 2.3GHz, 16GB GDDR6, 256bit, >3080 Niveau (Thanksgiving 26.Nov.2020, 550-700$)
HighGamer N21 - 200W-250W, 60+CU, 2.3GHz, 16GB GDDR6, 256bit, >3070 Niveau (Dec.2020, 450-600$)
InfinityCache ist eher ein grooser Cache-Pool OnDie ähnlich wie bei Zen.
überwiegend spekulativ
UpperMid N22 - 160W-200W, 40 CU, 2.5GHz, 12GB GDDR6, 192bit (Jan.2021, 380-450$)
LowerMid N22 - 150W-180W, 32+CU, xGHz, 6/12GB GDDR6, 192bit (später, 300-380$)
Professional N22 - 155W, 36CU, 10GB GDDR6, 160bit
überwiegend spekulativ
EntryFamily N23 - 90W-150W, 24+ CU, 2.3GHz, 8GB GDDR6, 128bit (Q2/2021, 180-280$)
1080p @144Hz Gaming
Doppelposting wurde automatisch zusammengeführt:
Um auf das Cache-Thema zurückzukommen. MLID zitiert einige Quellen für einen Shared L1 Cache für alle CUs. Dieser würde gemäss Quellen je nach Pipeline-Stage bzw. Softwareanforderung dynamisch zwischen Shared und Private für die angehängten CUs wechseln können. Instruktionen, die weniger Latenz-Sensitiv sind könnten die Cache-Objekte dann ein einziges Mal für alle CUs vorhalten, statt dass die L1 Caches das gleiche Objekt vorhalten. Damit soll gemäss Paper rund 22% bis zu 52% mehr Performance, Faktor 2.3 bei Deep Learning, bis zu 49% mehr Energieeffizienz bei hoher Datenreplikation möglich sein.
(mein Take) Übersetzt aus der RDNA1 Grafik würde eine Art Infinity Fabric Protokoll notwendig sein um aus separaten L1 Caches einen gemeinsamen kohärenten Cache zu erstellen, der wie der L3 bei Zen CCX verteilt ist und via IF abgeglichen wird (das IF-Clock Tuning Thema via RAM der Zen1 Gen).
Was der neue Cache aber genau ist und warum RGT den als Infinity Cache bezeichnet hat ist weiterhin Spekulation. Gesichert scheint nur, dass hier viel Neues zu erwarten ist, was die 256bit Speicheranbindung ermöglicht.
Habe gerade noch nachgelesen, der RDNA1 L1 Cache ist zumindest schon per Shader Array vereinheitlicht
The graphics L1 cache is shared across a group of dual compute units and can satisfy many data requests, reducing the data that is transmitted across the chip thereby boosting performance and improving power consumption. In addition, the intermediate graphics L1 cache improves scalability and simplifies the design of the L2 cache. ...
In the GCN architecture, the globally L2 cache was responsible for servicing all misses from the per-core L1 caches, requests from the geometry engines and pixel back-ends, and any other memory requests. In contrast, the RDNA graphics L1 centralizes all caching functions within each shader array. Accesses from any of the L0 caches (instruction, scalar, or vector data) proceed to the graphics L1. In addition, the graphics L1 also services requests from the associated pixel engines in the shader array.The graphics L1 cache is a read-only cache that is backed by the globally shared graphics L2; a write to any line in the graphics L1 will invalidate that line and hit in the L2 or memory. There is an explicit bypass control mode so that shaders can avoid putting data in the graphics L1.
Zuletzt bearbeitet:
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.369
- Renomée
- 9.694
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
von mir vereinfacht) - seine Info:
ProSumer N21 - 250W, 80CU, 2.2GHz, 32GB GDDR6, 256bit, 3090/Quadro6000 Niveau (Q1/2021, 2k-3k$)
TopGamer N21 - 250W-300W, 72+CU, 2.3GHz, 16GB GDDR6, 256bit, >3080 Niveau (Thanksgiving 26.Nov.2020, 550-700$)
HighGamer N21 - 200W-250W, 60+CU, 2.3GHz, 16GB GDDR6, 256bit, >3070 Niveau (Dec.2020, 450-600$)
InfinityCache ist eher ein grooser Cache-Pool OnDie ähnlich wie bei Zen.
überwiegend spekulativ
UpperMid N22 - 160W-200W, 40 CU, 2.5GHz, 12GB GDDR6, 192bit (Jan.2021, 380-450$)
LowerMid N22 - 150W-180W, 32+CU, xGHz, 6/12GB GDDR6, 192bit (später, 300-380$)
Professional N22 - 155W, 36CU, 10GB GDDR6, 160bit
überwiegend spekulativ
EntryFamily N23 - 90W-150W, 24+ CU, 2.3GHz, 8GB GDDR6, 128bit (Q2/2021, 180-280$)
1080p @144Hz Gaming
Danke für die Zusammenfassung. Ich sehe allerdings Moore's Law is Dead etwas kritisch.
Er behauptet ja auch, AMD würde gezielt Falschinformationen streuen. Warum sollen seine dann richtig sein?
Ich hab das vor ein paar Monaten mal aus Scherz zu jemanden auf Twitter geschrieben, aber eigentlich müsste es mal ein Gegengewicht zu den ganzen Leakern geben, indem man gezielt für alle eine Datenbank mit den Leaks führt und dann nach nem Jahr oder dem Launch des betreffenden Produktes diese noch mal bewertet.
Interessanter weil weniger konkret, aber mit Rückblenden auf AMD-Aussagen finde ich dagegen das Video von Not an Apple Fan:
Das einzige was er konkret nennt sind die 80 CUs und unter anderem die Aussagen von AMDs Wang über die Effizienzsprünge und die Ansage von Multi-GHz Takten.
Außerdem gibt er noch mal zu bedenken, dass Big Navi erstmal nur als AMD-Referenzdesign kommt, auf dass die AIBs nur ihre Aufkleber drauf pappen.
Abschliessend noch etwas von Frank Azor, der im Mai auch noch mal angekündigt hat, dass man mit RDNA2 zu Nvidia zumindest aufschliessen will und der Bang dann mit RDNA3 kommt.
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.883
- Renomée
- 39
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Navi mal 2 davon gehen viele aus, ob AMD dann auch noch die Shader, wie Nvidia, massiv erhöht ist fraglich. Wenn das auch so ein großer Chip wird gibt es die selben Probleme. Ein bisschen an der Spannung gedreht und das Ding haut hab Richtung 500 Watt.
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.840
- Renomée
- 2.807
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken

- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Dieser Spekulationsmarathon ist nicht mehr mein Fall, da werden zig Säue (gerade beim Speicherinterface) mehrmals durch das Dorf getrieben (nicht hier) - bin froh wenn das bald ein Ende hat.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Er sagt vor allem Paul von Red Gaming Tech ist "unbelievable accurate... might be AMD employee" und "will release CPUs first so the GPUs won't be bottlenecked"Interessanter weil weniger konkret, aber mit Rückblenden auf AMD-Aussagen finde ich dagegen das Video von Not an Apple Fan:
Das einzige was er konkret nennt sind die 80 CUs und unter anderem die Aussagen von AMDs Wang über die Effizienzsprünge und die Ansage von Multi-GHz Takten.
Wie auch immer. Wenn ich mir RDNA1 Methoden für die ersten 50% Steigerung ansehe und dann eine Evolution suchen müsste, dann ist viel besserer/grössere Cache die naheliegende Konklusion. Nach dem Motto was bei RDNA1 richtig war kann bei RDNA2 noch besser werden. Ein unerwartet schmales SI wäre dann sicherlich ein Mitnahmeeffekt für Powersavings.
Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Wir wissen ja, dass Navi 23 eine 32 CU Konfiguration hat. Insofern muten 24 hier etwas seltsam an.überwiegend spekulativ
EntryFamily N23 - 90W-150W, 24+ CU, 2.3GHz, 8GB GDDR6, 128bit (Q2/2021, 180-280$)
1080p @144Hz Gaming
Ich weiß, da steht 24+, dennoch …
Gozu
Vice Admiral Special
- Mitglied seit
- 19.02.2017
- Beiträge
- 521
- Renomée
- 70
- Mein Laptop
- Asus ROG Zephyrus G14 2022 (GA402RJ-L8116W) / HP 15s-eq1158ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 5900
- Mainboard
- AsRock B550 Phantom Gaming Velocita
- Kühlung
- Coolermaster MASTERLIQUID 120
- Speicher
- 2x 16GB HyperX KHX3733C19D4/16GX 3733-19
- Grafikprozessor
- AsRock RX 6800 Phantom Gaming D 16G
- Display
- 27 " iiyama G-Master GB2760QSU WQHD
- HDD
- 2x WDC WD10EADS-11P8B1
- Optisches Laufwerk
- TSSTcorp CDDVDW SH-2
- Gehäuse
- CoolerMaster HAF XB
- Netzteil
- Enermax EDT1250EWT
- Maus
- Rocat Kova
- Betriebssystem
- Windows 10 Professional x64, Manjaro
- Webbrowser
- Iron
- Internetanbindung
- ▼1000 MBit ▲50 MBit
Weil er nur Infos raus gibt, wo er mehrere Bestätigungen hat. Laut eigenen Aussagen hat er ja Informanten in der höheren Etage bei AMD, bei Tier 1 Partnern (Sapphire & Co die nur für AMD fertigen) und Tier 2 Partnern (ASUS und Co die auch für NVIDIA fertigen).Danke für die Zusammenfassung. Ich sehe allerdings Moore's Law is Dead etwas kritisch.
Er behauptet ja auch, AMD würde gezielt Falschinformationen streuen. Warum sollen seine dann richtig sein?
Auch bei NVIDIA lag er ja die letzten Monate nur richtig:
- Dass die Turing Karten quasi wertlos werden, weil Ampere soviel Mehrleistung zum niedrigen Preis bieten
- Dass die Founders Edition Karten nicht verfügbar sein werden, weil die Produktion erst im August gestartet wurde und der Hersteller des Kühlers nicht mit der Produktion nachkommt
Verglichen mit Adored TV und Red Gaming Tech die wirklich alles raushauen ist der wirklich Gold wert. Gut, seine Broken Silicon Podcasts dauern 2 Stunden und mehr, aber sind wirlich informativ.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Ja, ich habe in der Übersicht immer nur die untere Grenze genannt, die maximale obere +Grenze ergibt sich durch den nächst grösseren Chip. In seinem Video spricht er von 24-32 CUs und erklärt die untere/obere Grenze, vermutet absichtliche Limitierung des N23 via Bandbreite bzw. Cache weil die CUs ohnehin viel zu klein wären um bei kleinen Chips über CUs noch zu segmentieren... wenn N22 wirklich max 40CU sind käme N23 mit 32CU aber tatsächlich relativ gross für ein separates Design.Wir wissen ja, dass Navi 23 eine 32 CU Konfiguration hat. Insofern muten 24 hier etwas seltsam an.
Ich weiß, da steht 24+, dennoch …
RDNA1 N10 hatte 20 DualCU in 4 Arrays je 5. Bei N14 sind es 12 DualCU in 2 Arrays je 6.
3 Arrays je 5 wären 15 DualCU bzw. 30CU. Eine 32er Grösse würde bei den Rechenbeispielen nur mit 4 oder 8 DualCUs im Array möglich werden. Das wäre aber ein extremer Sprung zu einem max 40CU. Dort ist eine Array Basis von 5 DualCUs einfacher.
Woher wissen wir die 32CUs bei Navi 23? Vielleicht gestreute Fehlinformation oder verworfene Samples, vielleicht sind andererseits die 40CUs von N22 falsch. Vielleicht will RDNA2 die Arrays ganz in eins verschmelzen oder die neue Basis wäre tatsächlich 4 DualCUs je Array, der Trend würde nach meiner Vermutung aber eher in mehr Kerne an einem L1 Segment sein. ...up in the air...
PS: falls Du des Englischen nicht so mächtig bist, die roten Texte zu den Specs will er als gesicherte Info via mehrere gute Quellen bestätigt wissen, alles was er in den Übersichten in weissem Text schreibt ist von ihm spekulative Ableitung aus *seinen Fakten* + sinnvolle Interpretation der Mengenlage an Informationen...
PPS: ich fände ein N22 mit 48CUs auch logischer bei dem grossen Abstand zu N21 mit min 60CUs. Er lässt die 40CUs noch in weissem Text.
Zuletzt bearbeitet:
Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Woher wissen wir die 32CUs bei Navi 23? Vielleicht gestreute Fehlinformation oder verworfene Samples, vielleicht sind andererseits die 40CUs von N22 falsch. Vielleicht will RDNA2 die Arrays ganz in eins verschmelzen oder die neue Basis wäre tatsächlich 4 DualCUs je Array, der Trend würde nach meiner Vermutung aber eher in mehr Kerne an einem L1 Segment sein. ...up in the air...
Die Informationen die da stehen stammen aus der Firmware von AMD Treibern zu MacOS und Linux. Das ist ziemlich safe. Kannst du im Zweifelsfall auch selbst nachprüfen.
Wesentlich sicherer als irgendeiner der hier genannten Youtuber jemals irgendwas präsentieren könnte.
Klar, prinzipiell könnte AMD gezielt falsche Firmware Dateien verbreiten, aber auch das würde wohl einen Shitstorm nach sich ziehen, wenn Leute dann irgendwann versuchen diese Treiber mit den GPUs zu nutzen und Probleme haben.
Kann ich mir nicht jedenfalls nicht vorstellen.
Meine Einschätzung zu Navi 23 ist, dass es sich hierbei um einen auf mobile Anwendungen optimierten Chip handelt. Daher genügt ein 128 Bit Speicherinterface, aber man spendiert lieber ein paar CU mehr, damit man ihn bei geringerer Taktrate laufen lassen kann, d.h. näher am Sweetspot.
Eine bessere Erklärung dafür habe ich ehrlich gesagt nicht. Hab ich auch auf 3DCenter schon genau so geäußert direkt nachdem die Chipdaten veröffentlicht wurden.
Ich kann auch nicht einschätzen, ob MLID oder sonst wer richtige Infos hat oder nur Blödsinn verzapft. Aber mein Eindruck bislang war, dass die alle nur nebulös vor sich hinreden, aber stetig behaupten sie hätten exklusive Informationen die sie aber aus ungenannten Gründen noch zurückhalten oder so extrem vage halten, dass man nix daraus herleiten kann.
Und wenn dann mal was konkretes kommt, dann bezieht es sich wieder eher auf andere Leaks, wie eben den Post auf Reddit.
Abgesehen davon: ich halte es für wesentlich wahrscheinlicher, dass Leute wie MLID gezielt mit falschen Informationen gefüttert werden als dass AMD gezielt falsche Firmwares und Treiber verbreitet …
JCDenton
Grand Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 4.970
- Renomée
- 143
- Standort
- Altona
- Details zu meinem Desktop
- Prozessor
- i7 3770 stock
- Mainboard
- ASrock Z77 Extreme4
- Kühlung
- BQ! Pure Rock Slim
- Speicher
- 16GB Crucial Ballistics DDR-1600
- Grafikprozessor
- Sapphire RX570 8GB Pulse 1284Mhz@1050mV
- Display
- 24" Fujitsu P24W-6 1920*1200
- SSD
- Crucial MX100 128GB, MX500 500GB
- HDD
- Seagate/Samsung HD103SJ 1000GB
- Optisches Laufwerk
- DVD, I guess? xD
- Soundkarte
- SB Audigy 2 ZS
- Gehäuse
- Sharkoon Nightfall U3
- Netzteil
- BQ! System Power B9 450W
- Tastatur
- Logitech G413
- Maus
- Sharkoon FireGlider Black
MLID Big Navi Leak Video *Could be Maxwell Moment"
Möchte von AMD keine Wunderdinge mehr erwarten, dafür waren sie jetzt zu lange der Underdog. Aber ein RV770 Moment, als sie es innerhalb eines Jahres schafften, den katastrophalen R600 zu retten, das wär doch was

E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Die Tabelle kannte ich noch nicht. Soweit ich das sehe hat MLID nichts anderes als bestätigt angegeben, der Rest ist in der Tabelle genauer, er hat sich hier nicht festgelegt sondern streut Zweifel.Die Informationen die da stehen stammen aus der Firmware von AMD Treibern zu MacOS und Linux. Das ist ziemlich safe. Kannst du im Zweifelsfall auch selbst nachprüfen.
Wesentlich sicherer als irgendeiner der hier genannten Youtuber jemals irgendwas präsentieren könnte.
Klar, prinzipiell könnte AMD gezielt falsche Firmware Dateien verbreiten, aber auch das würde wohl einen Shitstorm nach sich ziehen, wenn Leute dann irgendwann versuchen diese Treiber mit den GPUs zu nutzen und Probleme haben.
Was mich an dem finalen Status dieser Beta-Treiber zweifeln lässt ist die bereits enthaltene RDNA3 Info und keinerlei Hinweise auf ein anderes Cache Design, am Ende doch nur Platzhalter?
Die unbekannten Zusatzparameter haben vielleicht mit RT zu tun, als Light ohne RT...
Aber wo soll da der Cache herkommen das SI zu entlasten?
Abschliessend noch etwas von Frank Azor, der im Mai auch noch mal angekündigt hat, dass man mit RDNA2 zu Nvidia zumindest aufschliessen will und der Bang dann mit RDNA3 kommt.
Das erwarte ich eigentlich auch so. Der Rückstand war groß - den zu "egalisieren" wird schon ein großer Erfolg sein. RDNA3 wird dann MCM ?!

Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Klar, im Sinne von "das was da steht hab ich eh schon immer aus meinen Quellen gewusst". Kennen wir mittlerweile.Die Tabelle kannte ich noch nicht. Soweit ich das sehe hat MLID nichts anderes als bestätigt angegeben, der Rest ist in der Tabelle genauer, er hat sich hier nicht festgelegt sondern streut Zweifel.
So wie ich das sehe hat AMD die typischen Leaker offensichtlich trocken gelegt.
Die sind aber davon abhängig, weil das Klicks bringt. Entsprechend labert man halt nebulös vor sich hin und sagt bei halbwegs sicheren Infos, dass das das ist was man eh schon immer gewusst hat.
Schau dir doch mal die Datenlage bzgl. Zen 3 an … da ist praktisch nichts. Weniger als eine Woche vor Release.
Und das was wir zu Zen 3 wissen (8C CCX, 32MB Cache) wissen wir von AMD selbst auf Grund des versehentlich veröffentlichten Vortrags vor einem Jahr.
Kann man nicht vollständig ausschließen, aber warum dann überhaupt hinzufügen.Was mich an dem finalen Status dieser Beta-Treiber zweifeln lässt ist die bereits enthaltene RDNA3 Info und keinerlei Hinweise auf ein anderes Cache Design, am Ende doch nur Platzhalter?
AMD hat wohl nicht damit gerechnet, dass jemand die discovery Binary entschlüsselt.
Hat ja auch ne ganze Weile gedauert, laut dem Typen der das gemacht hat stehen die Daten zu Navi 2x auch schon in einem Treiber aus dem letzten Jahr so drin.
bzgl. Cache: sowas muss da nicht unbedingt drinnen stehen. Muss nicht mal unbedingt im Code enthalten sein, da die Logik vermutlich so wie bei den CPUs in der Hardware selbst enthalten ist.
Ist natürlich nicht auszuschließen, dass man im Treiber darauf hin optimieren kann, aber davon haben wir bislang nichts gesehen.
Doppelposting wurde automatisch zusammengeführt:
So zumindest die Spekulation. Ich würde mich aber da noch nicht zu sehr darauf versteifen.RDNA3 wird dann MCM ?!
Es gab genau ein Gerücht das das angedeutet hat und bislang wurde nichts sonst aus dem Gerücht bisher bestätigt. Also abwarten.
")
Zudem, wenn man den Treiberdaten glaubt, dann ist Navi 31 weitgehend identisch zu Navi 21.
Würde in meinen Augen bedeuten, dass man evtl. Navi 21 in 5nm shrinkt (sowie evtl. ein paar Optimierungen vornimmt).
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Meine Spekulkation ist derzeit, dass AMD den in den Texturprozessoren vorhandenen größeren Cache für Hybrid-Raytracing bei deaktiviertem RT als Cache für normales Rendering verwenden kann. AMD Hybrid-RT-Patent schreibt davon eine FFU für RT nutzen zu können mit einem eigenen Datachannel, der paralelle zur TXT verläuft und auch davon, dass man diese umgehen kann mit "programable state machine"Aber wo soll da der Cache herkommen das SI zu entlasten?


Möglicherweise lässt sich sogar hier ein Wechsel von Frame zu Frame durch die Spieleentwickler nutzen zwischen RT on und RT off...das wäre mal etwas, wenn RT nicht komplett für jeden Frame neu gemacht werden muss, sondern die Daten teilweise über mehrere Frames hinweg nicht neu berechnet werden müssen.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
@Takte von RDNA2:
Wenn in Sonys PS5-SoCs von allen SoCs 36 von 40 CUs (also 90%) 2,23Ghz bei auch noch begrenzter TDP erreichen müssen, und das Ganze schon deutlich früher festgelegt werden musste, als AMD sollten auch in AMDs GPUs mindestens 90% der funktionierenden CUs mindestens 2,23Ghz schaffen. Hinzu kommt: AMD kann bis zuletzt selektieren, weitere CUs deaktivieren und auch eine höhere TDP zulassen...
...wo wäre es dann ungewöhnlich, wenn Navi21-GPUs auch mindestens 2,2Ghz im Boost erreichen, selektierte aber weit darüber takten?
Für realistisch halte ich, dass AMDs Navi21-Referenz-Design mindestens 2,2Ghz Boost macht und die späteren Custom-Designs weit mehr...mehr als 2,4Ghz...gar 2,5Ghz?
Wenn das neue Cache-Design tatsächlich soviel IPC-Steigerung bringt, dann dürfte RDNA2s IPC womöglich >20% IPC-Steigerung gegenüber RDNA1 haben und womöglich auch noch 25% höhere Takte....
Wenn in Sonys PS5-SoCs von allen SoCs 36 von 40 CUs (also 90%) 2,23Ghz bei auch noch begrenzter TDP erreichen müssen, und das Ganze schon deutlich früher festgelegt werden musste, als AMD sollten auch in AMDs GPUs mindestens 90% der funktionierenden CUs mindestens 2,23Ghz schaffen. Hinzu kommt: AMD kann bis zuletzt selektieren, weitere CUs deaktivieren und auch eine höhere TDP zulassen...
...wo wäre es dann ungewöhnlich, wenn Navi21-GPUs auch mindestens 2,2Ghz im Boost erreichen, selektierte aber weit darüber takten?
Für realistisch halte ich, dass AMDs Navi21-Referenz-Design mindestens 2,2Ghz Boost macht und die späteren Custom-Designs weit mehr...mehr als 2,4Ghz...gar 2,5Ghz?
Wenn das neue Cache-Design tatsächlich soviel IPC-Steigerung bringt, dann dürfte RDNA2s IPC womöglich >20% IPC-Steigerung gegenüber RDNA1 haben und womöglich auch noch 25% höhere Takte....
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Die Informationen die da stehen stammen aus der Firmware von AMD Treibern zu MacOS und Linux. Das ist ziemlich safe. Kannst du im Zweifelsfall auch selbst nachprüfen.
Ich habe versucht mir ein Bild zu den Tabellen aus den Treiberdaten zu machen und werde aus wesentlichen Teilen der Information nicht ganz schlau, mal auf die unklaren Unterschiede bezogen. Mir ist ja einiges an Abkürzungs-Chinesisch geläufig, aber wofür stehen die folgenden Parameter, kann das jemand aufschlüsseln?
- num_tccs (Texture Channel CacheS?)
- num_sc_per_sh (Shader Cluster per Shader Hub?)
- num_packer_per_sc (Gruppierung von CUs im Shader Cluster, also künftig QuadCU statt DualCU?)
- num_gl2a (Good Luck Anti Aliasing?)
Zuletzt bearbeitet:
Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Bei tccs liegst du richtig. Im Normalfall ist das auch gleich der Anzahl an Speicherkanälen, allerdings gibt es Beispiele bei denen sich mehrere Speicherkanäle einen Cache teilen.
Bei der XBox One war es wohl im Verhältnis 1:1.5, bei Arcturus dürfte es vermutlich 1:2 sein.
SC als shader cluster könnte auch stimmen, aber sicher bin ich mir da nicht.
Zu gl2a konnte ich auch noch nichts finden, das kommt im Code nur als Abkürzung vor.
Bei num_tccs und auch einigen anderen der Parameter muss man noch berücksichtigen, dass das immer das Maximum angibt. Die eigentliche Zahl wird dann aus dem VBIOS ausgelesen (->atomfirmware.h).
Ist aber für die Diskussion die wir hier um die Chips führen nicht weiter wichtig.
Bei der XBox One war es wohl im Verhältnis 1:1.5, bei Arcturus dürfte es vermutlich 1:2 sein.
SC als shader cluster könnte auch stimmen, aber sicher bin ich mir da nicht.
Zu gl2a konnte ich auch noch nichts finden, das kommt im Code nur als Abkürzung vor.
Bei num_tccs und auch einigen anderen der Parameter muss man noch berücksichtigen, dass das immer das Maximum angibt. Die eigentliche Zahl wird dann aus dem VBIOS ausgelesen (->atomfirmware.h).
Ist aber für die Diskussion die wir hier um die Chips führen nicht weiter wichtig.
Oi!Olli
Grand Admiral Special
- Mitglied seit
- 24.12.2006
- Beiträge
- 16.409
- Renomée
- 780
- Mein Laptop
- HP Elitebook 8760W
- Details zu meinem Desktop
- Prozessor
- Ryzen R7 5800X3D
- Mainboard
- Asus B 550 Strix F Wifi
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x 32 GB Kingston FURY DIMM DDR4 3600
- Grafikprozessor
- XFX Speedster MERC 310 Radeon RX 7900 XT Black Edition
- Display
- Acer Predator XB253QGP
- SSD
- Samsung 980 Pro 2 TB, Samsung 970 Evo Plus 2 TB
- HDD
- Samsung TB, 2x2 TB 1x3 TB 1x8 TB
- Optisches Laufwerk
- GH-22NS50
- Soundkarte
- Soundblaster Recon 3d
- Gehäuse
- Raijintek Zofos Evo Silent
- Netzteil
- BeQuiet Straight Power 750 Platinum
- Betriebssystem
- Windows 10 Pro
- Webbrowser
- Opera 101 (der Browser aktualisiert sich natürlich immer)
- Verschiedenes
- X-Box One Gamepad, MS Sidewinder Joystick
Ich bin ja auf den Preis gespannt. Ich hab 800 € zurück gelegt für CPU und GPU
Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Also:
- num_tccs (Texture Channel CacheS?)
- num_sc_per_sh (Shader Cluster per Shader Hub?)
- num_packer_per_sc (Gruppierung von CUs im Shader Cluster, also künftig QuadCU statt DualCU?)
- num_gl2a (Good Luck Anti Aliasing?)
SH ist Shader Array.
GL2A ist das was bei Vega TCA war (steht so in pal). Leider hab ich auch keine Ahnung was TCA bedeutet. xD
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Shader Hive würde mir eingängier sein.... aber in den Slides für RDNA Developer wird es auch als Array bezeichnet. Wenn ein SC per SH bei RDNA =1 ist könnte damit der L1 Shader Cache gemeint sein. Der ist zumindest 1 je SH in NAVI gemäss Blockdarstellungen.Also:
SH ist Shader Array.
GL2A ist das was bei Vega TCA war (steht so in pal). Leider hab ich auch keine Ahnung was TCA bedeutet. xD
Etwas ungewöhnlich wirkt im Wechsel zu RDNA2 die Halbierung der Anzahl Render Backends an, sowie umgekehrt die Verdoppelung der "Packer" je SC.
TC war bei AMD eigentlich immer Synonym für Textrue Cache L1, GL2A könnte dann für Global L2 Addressing, Array oder Access stehen.
Berniyh
Grand Admiral Special
- Mitglied seit
- 29.11.2005
- Beiträge
- 5.206
- Renomée
- 218
Haben wir im 3DC inzwischen aufgelöst. GL2A steht für "GL2 Arbiter". Das sagt mir zwar auch nicht sonderlich viel und "GL2" ist damit immer noch nicht geklärt, aber egal …Shader Hive würde mir eingängier sein.... aber in den Slides für RDNA Developer wird es auch als Array bezeichnet. Wenn ein SC per SH bei RDNA =1 ist könnte damit der L1 Shader Cache gemeint sein. Der ist zumindest 1 je SH in NAVI gemäss Blockdarstellungen.Also:
SH ist Shader Array.
GL2A ist das was bei Vega TCA war (steht so in pal). Leider hab ich auch keine Ahnung was TCA bedeutet. xD
Etwas ungewöhnlich wirkt im Wechsel zu RDNA2 die Halbierung der Anzahl Render Backends an, sowie umgekehrt die Verdoppelung der "Packer" je SC.
TC war bei AMD eigentlich immer Synonym für Textrue Cache L1, GL2A könnte dann für Global L2 Addressing, Array oder Access stehen.

TCA ist die Entsprechung dazu auf Vega und ist wohl "tightly coupled accelerator".
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.369
- Renomée
- 9.694
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Haben wir im 3DC inzwischen aufgelöst. GL2A steht für "GL2 Arbiter". Das sagt mir zwar auch nicht sonderlich viel und "GL2" ist damit immer noch nicht geklärt, aber egal …
Dazu von coelacanth
AMDGPU関連用語略称まとめ | Coelacanth's Dream
Er hat eh einige nette Sammlungen auch zu AMD CPUs Dali, Pollock usw.
Ähnliche Themen
- Antworten
- 728
- Aufrufe
- 50K
- Antworten
- 2K
- Aufrufe
- 132K
- Antworten
- 92
- Aufrufe
- 8K