App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD RDNA 3 - Chiplet NAVI - NAVI 3X
- Ersteller E555user
- Erstellt am
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Anfang Mai 2021 sind vermehrt Spekulationen um RNDA3 aufgetaucht.
Ich eröffne das Thema zu RDNA3 mit einem Video von Tom von MLID, der seine Informationen und Hinweise der letzten Monate zusammenfasst.
Man wird sehen welche Informationen tatsächlich relevant sind. Im Video werden bis zu 40% mehr Leistung im Vergleich zum aktuellen RDNA Topmodell in Aussicht gestellt, bei den Roadmap-Folien war die Zielsetzung offensichtlich die Leistung der ersten Generation RDNA respektive der NAVI um Faktor 3x zu erhöhen, oder wie Eiernacken aufklärt, dass es sich um die Ziffern der künftigen Chipvarianten handelt, wie bereits bei Navi 21, 22, 24...


Die Roadmap-News Diskussion
Ich eröffne das Thema zu RDNA3 mit einem Video von Tom von MLID, der seine Informationen und Hinweise der letzten Monate zusammenfasst.
Man wird sehen welche Informationen tatsächlich relevant sind. Im Video werden bis zu 40% mehr Leistung im Vergleich zum aktuellen RDNA Topmodell in Aussicht gestellt, bei den Roadmap-Folien war die Zielsetzung offensichtlich die Leistung der ersten Generation RDNA respektive der NAVI um Faktor 3x zu erhöhen, oder wie Eiernacken aufklärt, dass es sich um die Ziffern der künftigen Chipvarianten handelt, wie bereits bei Navi 21, 22, 24...
Die Roadmap-News Diskussion
Div. Forenbeiträge der VergangenheitNews - Neue AMD-Roadmaps: Zen 3, Zen 4, Navi 2x und Navi 3x
Im Rahmen des Financial Analyst Day 2020 hat AMD einige neue Roadmaps herausgegeben, die allerdings gerade bei den Desktop-Prozessoren nichts grundlegendes Neues offenbaren. Für 2020 kann man sich darauf einstellen, dass alle neuen Technologien — sei es nun Zen 3 oder die nächste Generation Navi...forum.planet3dnow.de
Prognose-Board: Wie geht es bei AMD weiter? Entwicklungen / Strategien / Maßnahmen, die AMD betreffen bzw. die AMD treffen könnte
Kommt immer darauf an welchen Antrieb die Entwickler bekommen. Wenn man mit Mining Geld verdienen kann ist der sehr groß und der Treiber für Vega wurde sehr schnell auf Linux angepasst das alles sauber läuft. Meine Navi1 ist bei Einstein sogar schneller als die Vega56 obwohl sie 16 CU weniger...
Zuletzt bearbeitet:
eiernacken1983
Admiral Special
- Mitglied seit
- 18.06.2020
- Beiträge
- 1.659
- Renomée
- 1.061
- Aktuelle Projekte
- MW@H; TN Grid, Einstein@Home
- Lieblingsprojekt
- MW@H
- Meine Systeme
- 3990X+2 x Radeon VII; 3950X + Radeon VII; 5950X + 5700XT; 3950X + Vega 64
- BOINC-Statistiken

- Folding@Home-Statistiken
- Details zu meinem Desktop
- Prozessor
- Ryzen 9 5950X
- Mainboard
- Gigabyte X570 Aorus Pro
- Kühlung
- Noctua NH-D15
- Speicher
- 4 x 8 GB G.Skill @ 3600 Cl16
- Grafikprozessor
- RX 5700XT Anniversary Edition
- Betriebssystem
- Windows 10
Nee. Das X in "3X" ist Platzhalter für die Sub-Bezeichnung der großen Chips (Navi 30) und der kleineren Chips Navi 31, 32 und was auch immer noch kommen mag.Im Video werden bis zu 40% mehr Leistung im Vergleich zum aktuellen RDNA Topmodell in Aussicht gestellt, bei den Roadmap-Folien war die Zielsetzung offensichtlich die Leistung der ersten Generation RDNA respektive der NAVI um Faktor 3x zu erhöhen.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Hier die MLID Punkte (11:50), die er in rot geschrieben als gesicherte Info ansieht:
- RNDA3 hat einen I/O Die als Chiplet mindestens ein Compute Chiplet - in einigen Modellen der Designphase
- Man ist zuversichtlich, dass RDNA3 60-80% mehr Performance als RDNA2 bieten kann
- AMD hat öffentlich das Ziel +50% Performance pro Watt vs. RDNA2 ausgegeben
- Eine theoretische RX7900XT sollte mindestens 40% besser als die RX6900XT sein
- Die optimistischste Annahme war bislang potentiell doppelte Performance zu RNDA2
- RayTracing & Gemoetry Leistung soll eine deutliche Steigerung per Dual CU aufweisen
- Im Vergleich zum Zen/Ryzen werden grössere Leistungseinbussen durch das Chiplet-Design erwartet
- AMD hat wiederholt bestätigt man glaubt man könne mit RNDA3 (vs. Nvidia bezügl. TopPerformance) gewinnen
Zuletzt bearbeitet:
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Da RDNA3 in 5nm kommen und die 5nm-Wafer exorbitant teuer sein sollen, lohnt es sich hier noch mehr als bei den CPUs, möglichst Vieles in ein getrenntes I/O-Die in einem älteren Prozess (7nm oder sogar 10nm oder 12nm+ bei GF?) auszulagern, um Kosten zu sparen. Zumal sich das bei den GPUs noch stärker auswirken wird, weil sich hier noch mehr Ram-Controller auf dem Die finden, die schon lange nicht mehr viel von den kleinen Strukturen haben und somit immer mehr teure Fläche unsinnig verbrauchen. Auch die Video-Einheiten werden wohl raus wandern.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Ich denke die Kosten bei 5nm haben ähnliche Entwicklung wie die vorherigen Generationen. Am Ende ist das wahrscheinlich auf Menge der Chips in ähnlichen Regionen und nur die einmaligen Kosten zum Design können das bei zu kleinen Stückzahlen zu teuer machen. Es wird in der Produktion wohl schneller gute Yields geben als 7nm.
Die grosse Frage, die sich mir stellt ist, wie viel Bandbreite zwischen den Chiplets zur Verfügung gestellt wird und wie AMD den Bedarf mit Caches in Grenzen hält bzw organisiert.
PS5 soll auch einen Shrink in Design haben... Evtl. kann AMD Optimierungen im Design zwischen den ähnlichen RDNA Produkten austauschen bzw. wiederverwenden.
Die grosse Frage, die sich mir stellt ist, wie viel Bandbreite zwischen den Chiplets zur Verfügung gestellt wird und wie AMD den Bedarf mit Caches in Grenzen hält bzw organisiert.
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Ich denke das ein entscheidener Punkt auch die Chip Ausbeute sein wird.
Kleine Chips sind von Angang an billiger zu produzieren weil sie einfach von Anfang an eine höhere Ausbeute besitzen da die Chance ganz einfach geringer ist das ein Defekt an der falschen Stelle ihn unbrauchbar macht oder einschränkt. Ein doppelt so großer Chip wäre dann z.B. unbrauchbar, bei einem halb so großen Chip vielleicht nur einer von beiden. Bricht man das jetzt noch auf 1/4 der Größe runter geht die Ausbeute natürlich entsprechend rauf.
Das ließe sich dann auch noch auf die Teildefekte übertragen. Damit ist für mich auch klar warum gerade nvidias Monster Chips so gern in gestutzer Form auf den Desktop Markt kamen. Zu viel Fläche bei der Fehler zu Teildefekten führen können und so am Ende kaum voll funktionstüchtige GPUs rauskommen, welche man wiederum für den professionellen Markt benötigt. Wenn sich die Fertigungsprozesse dann mit der Zeit eingearbeitet haben und die Anzahl an defekten sinkt nimmt natürlich auch die Anzahl der voll funktionstüchtiger Chips zu und noch komplexere Designs lassen sich dann überhaupt erst produzieren.
Kleine Chips sind von Angang an billiger zu produzieren weil sie einfach von Anfang an eine höhere Ausbeute besitzen da die Chance ganz einfach geringer ist das ein Defekt an der falschen Stelle ihn unbrauchbar macht oder einschränkt. Ein doppelt so großer Chip wäre dann z.B. unbrauchbar, bei einem halb so großen Chip vielleicht nur einer von beiden. Bricht man das jetzt noch auf 1/4 der Größe runter geht die Ausbeute natürlich entsprechend rauf.
Das ließe sich dann auch noch auf die Teildefekte übertragen. Damit ist für mich auch klar warum gerade nvidias Monster Chips so gern in gestutzer Form auf den Desktop Markt kamen. Zu viel Fläche bei der Fehler zu Teildefekten führen können und so am Ende kaum voll funktionstüchtige GPUs rauskommen, welche man wiederum für den professionellen Markt benötigt. Wenn sich die Fertigungsprozesse dann mit der Zeit eingearbeitet haben und die Anzahl an defekten sinkt nimmt natürlich auch die Anzahl der voll funktionstüchtiger Chips zu und noch komplexere Designs lassen sich dann überhaupt erst produzieren.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Das mit der Chipausbeute bzw. Yields ist mehr oder weniger immer die gleiche Story.
Wichtig ist nur bei allen Unkenrufen zu 5nm und weniger, dass wir bereits bei 10nm und 7nm Warnungen zu Kosten pro Chip hatten, die sich kaum in der Realität manifestiert hatten, am Ende waren es hauptsächlich Probleme bei Intel die verallgemeinert wurden.
Bei dem Bild von D.Nenny aus dem SemiWiki Forum ergibt sich eine High Volume Manufacturing Übergangsphase gemäss ASML bei 0.1 Def. per qcm und das soll per August 2020 bereits erreicht worden sein (vermutl. für Apple). Eine andere Folie zeigt im zittierten Forum den HVM start schon 1Q früher bei etwas höheren Defects.
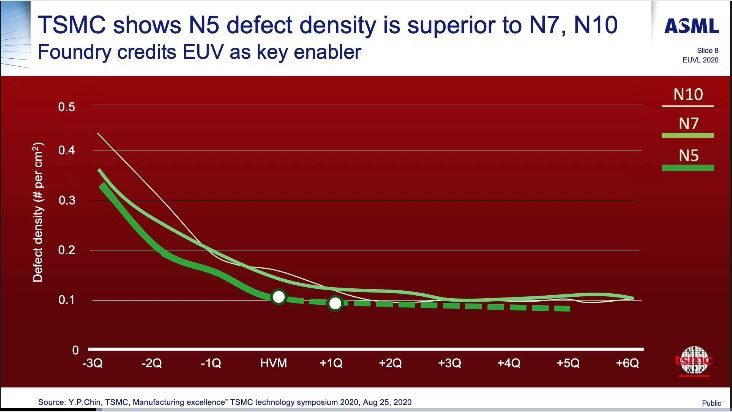
Wichtig ist nur, dass die Wafer noch weniger Defects aufweisen werden als mit 7nm (mehr EUV hat weniger Prozesschritte insgesamt) und das bei einem Ramp-Up mit grösseren GPU-Chiplets zu Einsparungen in Time2Market gegenüber 7nm führen sollte, bzw. sehr frühem HVM und damit geringeren Gesamtkosten.
Ich kenne jetzt die Apple 5nm Chipgrössen nicht. Sollten wirklich die RDNA3 CUs und der Rest einer GPU auf zwei Chiplets aufgeteilt werden würde der Compute Chiplet rund 2/3 des Platzbedarfs mitnehmen und in der 5nm Fertigung grob noch die Hälfte der Fläche eines akutellen Navi21 aufweisen. Auch das würde für gute Ausbeute in der Produktion sprechen. Beim Binning und SKU Zusammenstellung ergeben sich dann tatsächlich Möglichkeiten wie bei Ryzen: Einbussen bei Latenz und Fertigungsauwand mit Interposer, Gewinne bei Ausbeute pro Wafer und Takt bei kleineren Chiplets mit Binning-Optimierung für wenige Spitzenmodelle.
Allerdings wären bereits bei einem simplen Shrink von RDNA2 auch schon wesentliche Zugewinne beim Yield erzielbar, zusätzlich noch Takt. Es wird spannend werden wie AMD das Design letztlich festlegt, sicherlich wird man unterschiedliche Varianten testen. Bei Zen waren es zunächst vollständige SoC als Kombination, erst im zweiten Chiplet-Design mit separatem I/O Chiplet. Ich denke die Eigenschaften bzw. Anforderungen eines IF-Cache könnten hier massgebend sein. Man hätte den IF-Cache nicht für RDNA2 einführen müssen, es hätte konservativer bleiben können mit kleineren Die-Grössen ohne diesen Cache. Mit Blick auf Chiplet-CU war der IF-Cache nach meiner Einschätzung ein Schlüsselelement, das man schrittweise etablieren wollte.
Wichtig ist nur bei allen Unkenrufen zu 5nm und weniger, dass wir bereits bei 10nm und 7nm Warnungen zu Kosten pro Chip hatten, die sich kaum in der Realität manifestiert hatten, am Ende waren es hauptsächlich Probleme bei Intel die verallgemeinert wurden.
Bei dem Bild von D.Nenny aus dem SemiWiki Forum ergibt sich eine High Volume Manufacturing Übergangsphase gemäss ASML bei 0.1 Def. per qcm und das soll per August 2020 bereits erreicht worden sein (vermutl. für Apple). Eine andere Folie zeigt im zittierten Forum den HVM start schon 1Q früher bei etwas höheren Defects.
Wichtig ist nur, dass die Wafer noch weniger Defects aufweisen werden als mit 7nm (mehr EUV hat weniger Prozesschritte insgesamt) und das bei einem Ramp-Up mit grösseren GPU-Chiplets zu Einsparungen in Time2Market gegenüber 7nm führen sollte, bzw. sehr frühem HVM und damit geringeren Gesamtkosten.
Ich kenne jetzt die Apple 5nm Chipgrössen nicht. Sollten wirklich die RDNA3 CUs und der Rest einer GPU auf zwei Chiplets aufgeteilt werden würde der Compute Chiplet rund 2/3 des Platzbedarfs mitnehmen und in der 5nm Fertigung grob noch die Hälfte der Fläche eines akutellen Navi21 aufweisen. Auch das würde für gute Ausbeute in der Produktion sprechen. Beim Binning und SKU Zusammenstellung ergeben sich dann tatsächlich Möglichkeiten wie bei Ryzen: Einbussen bei Latenz und Fertigungsauwand mit Interposer, Gewinne bei Ausbeute pro Wafer und Takt bei kleineren Chiplets mit Binning-Optimierung für wenige Spitzenmodelle.
Allerdings wären bereits bei einem simplen Shrink von RDNA2 auch schon wesentliche Zugewinne beim Yield erzielbar, zusätzlich noch Takt. Es wird spannend werden wie AMD das Design letztlich festlegt, sicherlich wird man unterschiedliche Varianten testen. Bei Zen waren es zunächst vollständige SoC als Kombination, erst im zweiten Chiplet-Design mit separatem I/O Chiplet. Ich denke die Eigenschaften bzw. Anforderungen eines IF-Cache könnten hier massgebend sein. Man hätte den IF-Cache nicht für RDNA2 einführen müssen, es hätte konservativer bleiben können mit kleineren Die-Grössen ohne diesen Cache. Mit Blick auf Chiplet-CU war der IF-Cache nach meiner Einschätzung ein Schlüsselelement, das man schrittweise etablieren wollte.
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.883
- Renomée
- 39
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Was ich so mitbekommen habe ist die Rede von 2x80 CU und 1xI/O Chiplets. Eine Fertigung für die ganze Bandbreite von Low bis HighEnd Grafikkarten.
Ich sehe da eher das Problem mit Microrucklern bei Zwei getrennten Chips. Ob man das endgültig gelöst hat?
Ich sehe da eher das Problem mit Microrucklern bei Zwei getrennten Chips. Ob man das endgültig gelöst hat?
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Ich denke die Microruckler waren eine Folge von Alternate Frame Rendering. Von der CPU bzw. Treiber wurden vollständige Bilder alternativ auf die eine oder andere GPU als Job vergeben inkl. doppeltem VRAM-Management. Wenn eine GPU schneller mit dem Bild fertig war als die andere (Temp./Volt/VRAM-Updates) haben diese Bilder auf der Zeitachse keine regelmässigen Abstände.
Bei einer Chiplet-GPU, die nach aussen nur als einheitliches Device sichtbar wird, ist die Jobverteilung bei der GPU, alle Verzögerungen sollten dann innerhalb eines Frames über eine Rerndersequenz hinweg gleichmässig auftreten. Entweder weil die Jobverteilung und Last gleichmässig ist oder sogar der Takt auf allen Chiplets gesynct wird. Ein gemeinsamer LL-Cache sollte dem auch entgegen wirken, d.h. die GPUs werden nicht zu unterschiedlicher Zeit im VRAM mit Updates druch die CPU versorgt, sondern teilen den Speicher und die Verzögerungen, die dort verursacht werden. Evtl. müsste der Speicherzugriff auf unterschiedliche Segmente gleich langsam stattfinden, damit es nicht zu Varianzen kommt wenn von Frame zu Frame die gleichen Jobs plötzlich von unterschiedlichen Chiplets berechnet werden.
Da die GPUs nicht durch eine CPU im Treiber synchronisiert werden sondern auf einem Interposer direkt das besorgen können müsste das m.M. nach zu verhindern sein.
(Vermutlich waren bei Mixed Rendering Setups auf Basis von DX12 oder Vulkan die Microruckler schon kein Problem mehr. Dort lassen sich gezielt Render-Targets auf einer GPU berechnen und auf der nächsten dann nach Übergabe der Zwischenergebnisse der Rest. Bevor der Frame ausgegeben wird kann erstere GPU schon wieder Vorberechnungen zum folgenden Frame machen. Die Jobverteilung erfolgt in der Engine, nicht im Treiber.)
Man hat schon bei GCN unterschiedlichen L1-Cache und Performance je Shader Engine via shared L2 synchronisiert. Die Aufgabe wäre also unterschiedlichen L2 eines CU-Chiplet durch einen LL IF-Cache synchron zu halten. Es müssten ähnliche Methoden im Scheduling angewendet werden.
Am Ende könnte die Verzögerung je Berechnung je Shader Engine grösser ausfallen während die Anzahl der Shader sich verdoppelt. Dann sehen wir evtl. Rückschritte in kleinen Auflösungen als Mindest-Frametime bzw. eine Art FPS-Mauer während sehr grosse Auflösungen profitieren.
PS: Microruckler durch SAM zu verhindern wäre noch eine interessante sehr theroretische Diskussion, die man mit einem AMD-Spezialisten führen könnte. Nach meiner Info schliesst sich X-Fire und RX-6000 aus.
Bei einer Chiplet-GPU, die nach aussen nur als einheitliches Device sichtbar wird, ist die Jobverteilung bei der GPU, alle Verzögerungen sollten dann innerhalb eines Frames über eine Rerndersequenz hinweg gleichmässig auftreten. Entweder weil die Jobverteilung und Last gleichmässig ist oder sogar der Takt auf allen Chiplets gesynct wird. Ein gemeinsamer LL-Cache sollte dem auch entgegen wirken, d.h. die GPUs werden nicht zu unterschiedlicher Zeit im VRAM mit Updates druch die CPU versorgt, sondern teilen den Speicher und die Verzögerungen, die dort verursacht werden. Evtl. müsste der Speicherzugriff auf unterschiedliche Segmente gleich langsam stattfinden, damit es nicht zu Varianzen kommt wenn von Frame zu Frame die gleichen Jobs plötzlich von unterschiedlichen Chiplets berechnet werden.
Da die GPUs nicht durch eine CPU im Treiber synchronisiert werden sondern auf einem Interposer direkt das besorgen können müsste das m.M. nach zu verhindern sein.
(Vermutlich waren bei Mixed Rendering Setups auf Basis von DX12 oder Vulkan die Microruckler schon kein Problem mehr. Dort lassen sich gezielt Render-Targets auf einer GPU berechnen und auf der nächsten dann nach Übergabe der Zwischenergebnisse der Rest. Bevor der Frame ausgegeben wird kann erstere GPU schon wieder Vorberechnungen zum folgenden Frame machen. Die Jobverteilung erfolgt in der Engine, nicht im Treiber.)
Man hat schon bei GCN unterschiedlichen L1-Cache und Performance je Shader Engine via shared L2 synchronisiert. Die Aufgabe wäre also unterschiedlichen L2 eines CU-Chiplet durch einen LL IF-Cache synchron zu halten. Es müssten ähnliche Methoden im Scheduling angewendet werden.
Am Ende könnte die Verzögerung je Berechnung je Shader Engine grösser ausfallen während die Anzahl der Shader sich verdoppelt. Dann sehen wir evtl. Rückschritte in kleinen Auflösungen als Mindest-Frametime bzw. eine Art FPS-Mauer während sehr grosse Auflösungen profitieren.
PS: Microruckler durch SAM zu verhindern wäre noch eine interessante sehr theroretische Diskussion, die man mit einem AMD-Spezialisten führen könnte. Nach meiner Info schliesst sich X-Fire und RX-6000 aus.
Zuletzt bearbeitet:
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Wilde Spekulationen in den 3DCenter News zusammengefasst
Gerüchteküche: Kommen AMDs Navi 33, 32, 31 Grafikchips tatsächlich mit 80, 120, 160 Shader-Clustern? | 3DCenter.org
Mitten in der Zeit der Launches von GeForce RTX 3080 Ti & 3070 Ti gab es eine Reihe von kleineren Leaks samt Gedankenspielen zum grundsätzlichen Aufbau der Navi-3X-Chipreihe. Zuletzt gab es hierzu eine Meldung vom 9. Juni, welche Navi 33 alswww.3dcenter.org
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Und es brodelt mal wieder die Gerüchteküche.

 www.computerbase.de
www.computerbase.de
RDNA-3-Gerüchte: Mit AMD Navi 31 stehen ein Umbruch und 15.360 Shader an
Die Gerüchte zu AMDs kommender RDNA-3-Generation werden immer konkreter. Und es zeichnen sich größere Umbauten bei der Next-Gen-GPU an.
www.computerbase.de
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Also bei der HD 7970 war es so, das mit CrossfireX auch das FramePacing aktiviert wurde.Was ich so mitbekommen habe ist die Rede von 2x80 CU und 1xI/O Chiplets. Eine Fertigung für die ganze Bandbreite von Low bis HighEnd Grafikkarten.
Ich sehe da eher das Problem mit Microrucklern bei Zwei getrennten Chips. Ob man das endgültig gelöst hat?
Daher kann es keine µ-Ruckler gegeben haben, es sei den:
1. der System Timer war zu langsam um alle Anfragen Rechtzeitig zu bedienen.
2. Strom Spitzen, das Netzteil konnte nicht mit der Last umgehen.
Mehr Möglichkeiten gibt es m.M.n. nicht für µRuckler in der heutigen Zeit, schon gar nicht auf einem SoC verbaut.
")
- Mitglied seit
- 25.05.2002
- Beiträge
- 29.374
- Renomée
- 1.572

Irrer Leistungssprung: RX 7600 XT soll so schnell sein wie RX 6900 XT
Die kommende Einsteigerklasse von AMD soll einem Leak zufolge bereits so leistungsstark sein wie das aktuelle Flaggschiff RX 6900 XT.
 www.gamestar.de
www.gamestar.de
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
AMD Interposer Strategie - Zen, Fiji, HBM und Logic ICs
Da der neue Cache nur dieselbe Fläche belegt wie der schon vorhandene Cache und dabei doppelt so viele Zellen aufbringt, muss die neue Library der Knaller sein. Da stellt sich die Frage, warum AMD die nicht auch für das Chiplet selbst verwendet. MfG
Accordingly, as discussed herein, an active bridge chiplet deploys monolithic GPU functionality using a set of interconnected GPU chiplets in a manner that makes the GPU chiplet implementation appear as a traditional monolithic GPU from a programmer model/developer perspective. The scalable data fabric of one GPU chiplet is able to access the lower level cache(s) on the active bridge chiplet in nearly the same time as to access the lower level cache on its same chiplet, and thus allows the GPU chiplets to maintain cache coherency without requiring additional inter-chiplet coherency protocols. This low-latency, inter-chiplet cache coherency in turn enables the chiplet-based system to operate as a monolithic GPU from the software developer's perspective, and thus avoids chiplet-specific considerations on the part of a programmer or developer.ACTIVE BRIDGE CHIPLET WITH INTEGRATED CACHE - ADVANCED MICRO DEVICES, INC.
<div p-id="p-0001">A chiplet system includes a central processing unit (CPU) communicably coupled to a first GPU chiplet of a GPU chiplet array. The GPU chiplet array includes the first GPU chiplet cowww.freepatentsonline.com
Möglicherweise CDNA2 mit passiver Bridge:
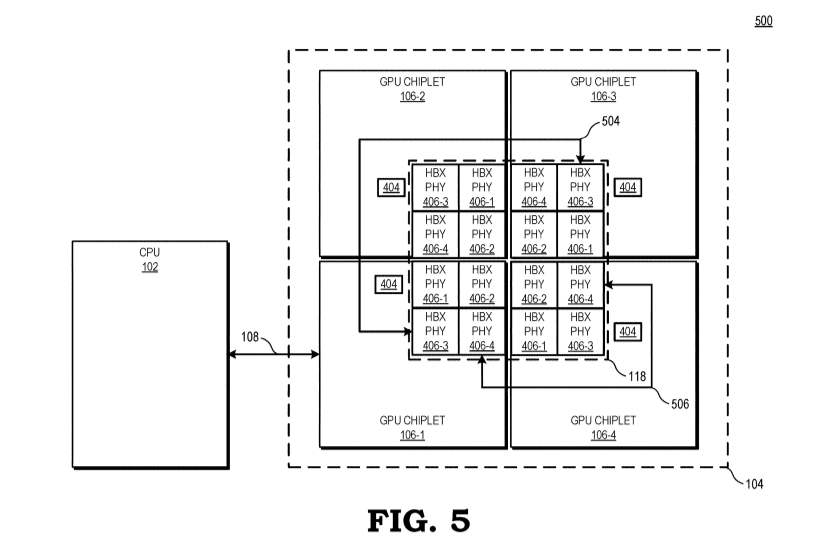
Aufbau mit aktiver Bridge mit einem primären GCD zur Anbindung an CPU/Speicher, möglicherweise RDNA3:
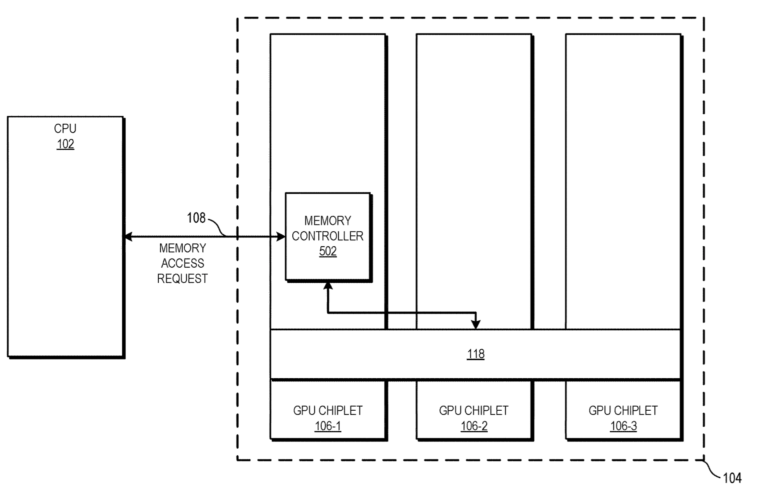
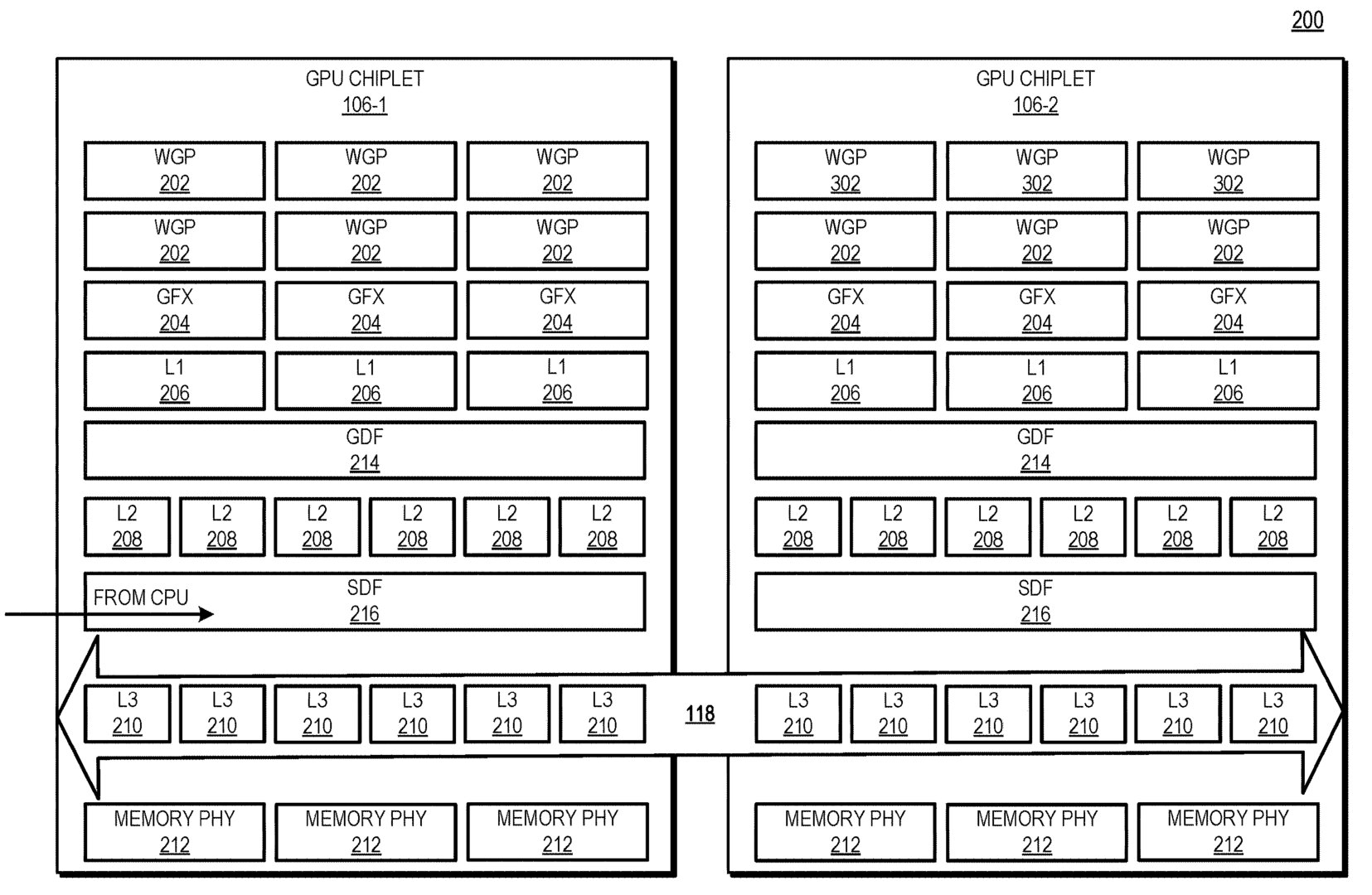
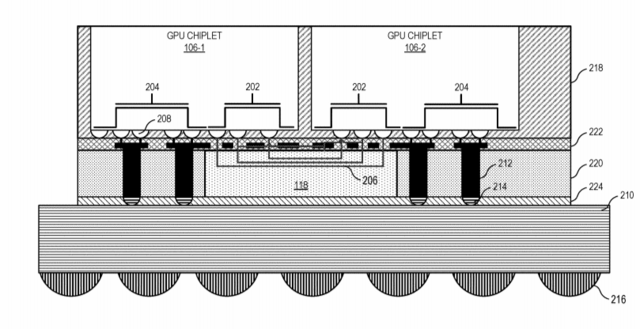

GPUs im Chiplet-Design: AMD-Patente bringen den Cache ins Spiel
Zwei neue Patente von AMD, ein mögliches Chiplet-Design von GPUs betreffend, bringen eine „Active Bridge“ und den Cache ins Spiel.
www.computerbase.de
Der Cache wandert auf die Brücke
Die Besonderheit der „Active Bridge“ besteht darin, dass der L3-Speicher direkt auf der Brückenverbindung und nicht mehr auf dem entsprechenden GPU-Chiplet untergebracht werden soll. Das erklärt auch die aktive Auslegung der Brücke.
Zudem ist die Größe des L3-Cache damit durch die Größe der „Active Bridge“ beliebig skalierbar und ermöglicht Lösungen für Systeme respektive GPUs und Beschleunigern mit wenigen (1 bis 2) oder vielen (3 und mehr) GPU-Chiplets.
Der L3-Cache ist damit auch von der Hitzeentwicklung und dem Stromverbrauch der GPU-Chiplets entkoppelt. Ob der Cache damit tatsächlich besser gekühlt werden kann oder einfach die dezentrale Hitzeentwicklung von Vorteil ist, geht aus der Patentschrift indes nicht hervor.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Es sind diverse Varianten möglich, von daher spannend wie es weitergeht bei RDNA vs. CDNA.
Interessant war z.B dass man bei CDNA nicht auf die DualCU gesetzt hat, RDNA aber dennoch im Pro Bereich für Medienproduktion positioniert wurde.
Je nach Workload könnten künftig auch TripleCU oder QuadCU mit gemeinsamen L1 Cache eine Möglichkeit darstellen um Effizienter zu werden was offensichtlich bei reinem Compute noch nicht im Fokus stand. AMD hat sich bei CPUs auch lange gegen SMT entschieden. Bei Konsolen kann sich das in der Praxis bislang auch nicht etablieren. Ich denke am Ende ist das eine Frage der Software was verlangt wird.
Bei McM GPU sollten unterschiedliche Taktraten für die Dies oder gar Shader Units möglich werden, ähnlich wie bei den CPUs, bislang hatte man uns bei GPU immer nur einen globalen Takt ausgegeben, der gemeinsame IF Cache müsste zumindest wie bei CPU eine eigene Taktdomäne werden.
Interessant war z.B dass man bei CDNA nicht auf die DualCU gesetzt hat, RDNA aber dennoch im Pro Bereich für Medienproduktion positioniert wurde.
Je nach Workload könnten künftig auch TripleCU oder QuadCU mit gemeinsamen L1 Cache eine Möglichkeit darstellen um Effizienter zu werden was offensichtlich bei reinem Compute noch nicht im Fokus stand. AMD hat sich bei CPUs auch lange gegen SMT entschieden. Bei Konsolen kann sich das in der Praxis bislang auch nicht etablieren. Ich denke am Ende ist das eine Frage der Software was verlangt wird.
Bei McM GPU sollten unterschiedliche Taktraten für die Dies oder gar Shader Units möglich werden, ähnlich wie bei den CPUs, bislang hatte man uns bei GPU immer nur einen globalen Takt ausgegeben, der gemeinsame IF Cache müsste zumindest wie bei CPU eine eigene Taktdomäne werden.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
@E555user
Ich wäre vorsichtig mit den CPU Vergleichen denn SMT ist primär dafür gut bei schlecht optimierter Software brach liegende Ressourcen durch den/die zusätzlichen Threads dennoch nutzen zu können. SMT schafft also keine zusätzliche Rechenleistung sondern macht nur brach liegende Rechenleistung des Kerns nutzbar.
Da aber gerade bei den Konsolen sehr auf Software Optimierung geachtet wird um möglichst viel Leistung aus der Hardware kitzeln zu können dürfte dieser Vorteil praktisch verpuffen und der größte negativ Effekt zum tragen kommen. Die Threads müssen sich die Ressourcen des Kerns teilen und graben sich so gern mal gegenseitig das Wasser ab. Schlecht für hoch optimierte Software.
Ich wäre vorsichtig mit den CPU Vergleichen denn SMT ist primär dafür gut bei schlecht optimierter Software brach liegende Ressourcen durch den/die zusätzlichen Threads dennoch nutzen zu können. SMT schafft also keine zusätzliche Rechenleistung sondern macht nur brach liegende Rechenleistung des Kerns nutzbar.
Da aber gerade bei den Konsolen sehr auf Software Optimierung geachtet wird um möglichst viel Leistung aus der Hardware kitzeln zu können dürfte dieser Vorteil praktisch verpuffen und der größte negativ Effekt zum tragen kommen. Die Threads müssen sich die Ressourcen des Kerns teilen und graben sich so gern mal gegenseitig das Wasser ab. Schlecht für hoch optimierte Software.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Dennoch sind AFAIK die beiden aktuellen Konsolen CPU mit SMT und AMD bemüht sich schon seit längerem mit Async Compute bei GPUs ähnliche Problemstellungen zu lösen.
Auch bei SMT will man kein Cache Trashing sondern bestenfalls mit gleichem Algo und Konstanten bzw. relativ stabilen Variablen weiterrechnen während der andere Thread auf aktualisierte Daten wartet. Bei Rendern oder Codecs auf CPU skaliert das idR gut mit vielen Threads die untereinander Abhängigkeiten haben die eigentliche Optimierung aber dennoch im massiven MT liegt.
Auch bei SMT will man kein Cache Trashing sondern bestenfalls mit gleichem Algo und Konstanten bzw. relativ stabilen Variablen weiterrechnen während der andere Thread auf aktualisierte Daten wartet. Bei Rendern oder Codecs auf CPU skaliert das idR gut mit vielen Threads die untereinander Abhängigkeiten haben die eigentliche Optimierung aber dennoch im massiven MT liegt.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Ich sehe SMT eher als Gegenmaßnahme für schlechter Programmierqualität und für die Abarbeitung von wenig leistungsfordernen Hintergrundthreads.
Bei den GPUs sollte man nicht vergessen wo CDNA zum Einsatz kommt, bei reinen Compute Beschleunigern die wohl meist mit entsprechend optimierter Software bedient werden. Mit der Grafikberechnung an sich haben die nicht viel zu tuen.
RDNA setzt aber wiederum genau dort wo CDNA endet und bei den entsprechenden mixed workloads und mäßig optimierter Software dürfte sich jene Ausrichtung der Architektur wiederum bezahlt machen.
Bei den GPUs sollte man nicht vergessen wo CDNA zum Einsatz kommt, bei reinen Compute Beschleunigern die wohl meist mit entsprechend optimierter Software bedient werden. Mit der Grafikberechnung an sich haben die nicht viel zu tuen.
RDNA setzt aber wiederum genau dort wo CDNA endet und bei den entsprechenden mixed workloads und mäßig optimierter Software dürfte sich jene Ausrichtung der Architektur wiederum bezahlt machen.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Ich denke genau das Gegenteil ist der Fall.
Hyperthreding funktionierte die ersten Jahre ohne Codeoptimierungen überhaupt nicht und in Windows passieren da eher Katastrophen durch mangelndes Thread Alignment, was selbst noch bei Zen zu suboptimalen Ergebnissen führte, allein weil der Cache Zugriff nicht lokal war. Das sieht man mit oder ohne SMT, erst Zen3 mit 8 Cores am gemeinsamen Cache verhindert über die 16T am gemeinsamen riesigen Datenpool diese Art Scheduling-Katastrophen fast vollständig. Aber optimiert wäre wenn auch jew. der L1 und L2 nicht durch SMT Cachelines verlieren würde.
Im Gegensatz zu Gaming und Medienbearbeitung hat man im Compute auf CDNA ganz wenige Wechsel von Algorithmen die eine unterschiedliche Auslastung begründen. Offensichtlich sah man bei typischen Compute Aufgaben auch keinen Vorteil in der Halbierung der Wavefront Size sondern mehr Effizienz in 64er Waves, auf einen shared L1 in DualCUs muss letztlich optimiert werden. Bei GCN und CDNA scheinen die wenigen KB global Datashare für Compute zu genügen, den Vorteil eines Shared Cache bei 32er DualCU sieht man dort nicht, evtl sind auch die Double Floats damit zu ineffizient. Die Annahme muss aber sein, dass man hier meist keine gleichen Daten bei den Ops verarbeitet und der gemeinsame Cache erst bei ganzen Shader Clustern Vorteile bringt.
Nachtrag weils so unübersichtlich bei RDNA ist
Eine GCN CDNA CU hat 64KB Local Data Share, RDNA auch, aber als DualCU zusammen 128KB shared.
Bei GCN CDNA gibt es einen 16KB L1 je CU bei den Textureinheiten bzw Load Store Units, bei RDNA auch, aber neu wird noch ein L1 für je 5 DualCU von 128KB hinzugefügt. D.h. L1 in der CU und L1 Shared für 10 CUs, dann erst Shared L2 von 4MB über alle CUs.
GCN4/5 hat auch 4MB L2, CDNA hat dann 8MB L2.
Das HW Scheduling berücksichtigt SE von 20 CUs RDNA und 15 CUs CDNA,
Bei RDNA optimiert man für 2->10->[20->]full Die CUs
Bei CDNA optimiert man für 1->[15->30->]full Die CUs->multi GPU
Hyperthreding funktionierte die ersten Jahre ohne Codeoptimierungen überhaupt nicht und in Windows passieren da eher Katastrophen durch mangelndes Thread Alignment, was selbst noch bei Zen zu suboptimalen Ergebnissen führte, allein weil der Cache Zugriff nicht lokal war. Das sieht man mit oder ohne SMT, erst Zen3 mit 8 Cores am gemeinsamen Cache verhindert über die 16T am gemeinsamen riesigen Datenpool diese Art Scheduling-Katastrophen fast vollständig. Aber optimiert wäre wenn auch jew. der L1 und L2 nicht durch SMT Cachelines verlieren würde.
Im Gegensatz zu Gaming und Medienbearbeitung hat man im Compute auf CDNA ganz wenige Wechsel von Algorithmen die eine unterschiedliche Auslastung begründen. Offensichtlich sah man bei typischen Compute Aufgaben auch keinen Vorteil in der Halbierung der Wavefront Size sondern mehr Effizienz in 64er Waves, auf einen shared L1 in DualCUs muss letztlich optimiert werden. Bei GCN und CDNA scheinen die wenigen KB global Datashare für Compute zu genügen, den Vorteil eines Shared Cache bei 32er DualCU sieht man dort nicht, evtl sind auch die Double Floats damit zu ineffizient. Die Annahme muss aber sein, dass man hier meist keine gleichen Daten bei den Ops verarbeitet und der gemeinsame Cache erst bei ganzen Shader Clustern Vorteile bringt.
Nachtrag weils so unübersichtlich bei RDNA ist
Eine GCN CDNA CU hat 64KB Local Data Share, RDNA auch, aber als DualCU zusammen 128KB shared.
Bei GCN CDNA gibt es einen 16KB L1 je CU bei den Textureinheiten bzw Load Store Units, bei RDNA auch, aber neu wird noch ein L1 für je 5 DualCU von 128KB hinzugefügt. D.h. L1 in der CU und L1 Shared für 10 CUs, dann erst Shared L2 von 4MB über alle CUs.
GCN4/5 hat auch 4MB L2, CDNA hat dann 8MB L2.
Das HW Scheduling berücksichtigt SE von 20 CUs RDNA und 15 CUs CDNA,
Bei RDNA optimiert man für 2->10->[20->]full Die CUs
Bei CDNA optimiert man für 1->[15->30->]full Die CUs->multi GPU
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
HTT funktionierte damals ähnlich "gut" wie heute nur fehlte damals am Anfang die Priorisierung auf einen Thread und der zweite wurde damit wie ein vollständiger Kern behandelt. Im Ergebnis fraßen sich dann beide Threads die Rechenzeit weg. Das juckt nicht weiter wenn beide am gleichen "Problem" arbeiten aber sehr wohl wenn sie von unterschiedlichen Programmen genutzt werden. Das sich daran recht wenig geändert hat kannst du z.B. im DC Bereich sehr schön erkennen. Schalte SMT ein und die Rechenzeit der Singlecore WUs erhöht sich erheblich, nur das jetzt eben doppelt so viele laufen und dadurch am Ende meist mehr rauskommt.
Der nächste Punkt ist das es schon seit zig Jahren ein Problem ist alle Kerne/Threads von den Programmen vernünftig genutzt werden und entsprechend viel Rechenleistung brach liegt. Ein Problem das man seinerzeit bei den Singlecores eher selten hatte und entsprechend stark wirkte sich damals auch die gegenseitige Behinderung der Threads aus. Aus dem gleichen Grund wäre dann auch das viel Beschworene 4 fach SMT ein Rohrkrepierer weil sich dann 4 Threads um die Recheneinheiten kloppen müssen.
Wenn "Codeoptimierung" hingegen bedeuten soll den die Rechenwerke des Kerns von einem Thread möglichst ineffizient zu nutzen damit für einen weiteren möglichst viel Freiraum übrig bleibt dann kann das hingegen durchaus hinkommen. Damals wäre das dann einfach nur eine schlechte Programmierqualität bzw. mangelhafter Software Optimierung gewesen und genau das wovon ich schrieb.
Im übrigen benötigst du für die SMT Nutzung die gleichen Voraussetzung wie bei weiteren Kernen. Ist der Multicore Support des Programms nicht fähig die weiteren Threads (egal ob CMT, SMT oder ein weiterer Kern) zu nutzen bringen sie absolut garnichts.
Im GPU Bereich sehe ich das deutlich einfacher als du.
CDNA ist eine Weiterentwicklung der GCN Architektur der z.B. die Grafikberechnung gestrichen wurde, also der Part der bei GCN mit steigender Komplexität erhebliche Probleme bekam die Rechenleistung in Frameraten umzusetzen. Ich gehe mal davon aus dass das auch der Grund war warum der Einheitenausbau bei GCN seit Fiji stagnierte und man vor allem auf Taktsteigerung setzte. Ich vermute das die Archietektur hier einfach am Ende war.
Der Compute Bereich hatte hier eher weniger Probleme damit und genau darauf wurde CDNA dann auch reduziert.
RDNA übernahm dann wiederum den Marktbereich der Grafikberechnung aber schwächelte dafür etwas im Compute Bereich.
Damit gibt es bei RDNA und CDNA kaum berührungspunkte weil beide Architekturen ganz einfach unterschiedliche Marktsegmente bedienen.
Der nächste Punkt ist das es schon seit zig Jahren ein Problem ist alle Kerne/Threads von den Programmen vernünftig genutzt werden und entsprechend viel Rechenleistung brach liegt. Ein Problem das man seinerzeit bei den Singlecores eher selten hatte und entsprechend stark wirkte sich damals auch die gegenseitige Behinderung der Threads aus. Aus dem gleichen Grund wäre dann auch das viel Beschworene 4 fach SMT ein Rohrkrepierer weil sich dann 4 Threads um die Recheneinheiten kloppen müssen.
Wenn "Codeoptimierung" hingegen bedeuten soll den die Rechenwerke des Kerns von einem Thread möglichst ineffizient zu nutzen damit für einen weiteren möglichst viel Freiraum übrig bleibt dann kann das hingegen durchaus hinkommen. Damals wäre das dann einfach nur eine schlechte Programmierqualität bzw. mangelhafter Software Optimierung gewesen und genau das wovon ich schrieb.
Im übrigen benötigst du für die SMT Nutzung die gleichen Voraussetzung wie bei weiteren Kernen. Ist der Multicore Support des Programms nicht fähig die weiteren Threads (egal ob CMT, SMT oder ein weiterer Kern) zu nutzen bringen sie absolut garnichts.
Im GPU Bereich sehe ich das deutlich einfacher als du.
CDNA ist eine Weiterentwicklung der GCN Architektur der z.B. die Grafikberechnung gestrichen wurde, also der Part der bei GCN mit steigender Komplexität erhebliche Probleme bekam die Rechenleistung in Frameraten umzusetzen. Ich gehe mal davon aus dass das auch der Grund war warum der Einheitenausbau bei GCN seit Fiji stagnierte und man vor allem auf Taktsteigerung setzte. Ich vermute das die Archietektur hier einfach am Ende war.
Der Compute Bereich hatte hier eher weniger Probleme damit und genau darauf wurde CDNA dann auch reduziert.
RDNA übernahm dann wiederum den Marktbereich der Grafikberechnung aber schwächelte dafür etwas im Compute Bereich.
Damit gibt es bei RDNA und CDNA kaum berührungspunkte weil beide Architekturen ganz einfach unterschiedliche Marktsegmente bedienen.
Maverick-F1
Grand Admiral Special
Naja - ganz so "einfach" ist das mit der Optimierung der SW auch nicht immer:
Wenn Programm sehr speicherintensiv ist, und Ergebnisse ggf. auch noch voneinander abhängen, dann ist nunmal leider häufig Warten auf Daten vom RAM (oder noch schlimmer vom Massenspeicher) angesagt. Da spielt HT/SMT dann seine Stärke aus, wenn noch weitere Programme / Aufgaben laufen...
Nicht immer kann alles in Prozessor-Caches aufgefangen werden...
Da werden die neuen "Cache-gepimpten" Ryzens im Winter interessant - Programme, die sich damit stark beschleunigen lassen, fallen dann genau in die genannte Kategorie...
Wenn Programm sehr speicherintensiv ist, und Ergebnisse ggf. auch noch voneinander abhängen, dann ist nunmal leider häufig Warten auf Daten vom RAM (oder noch schlimmer vom Massenspeicher) angesagt. Da spielt HT/SMT dann seine Stärke aus, wenn noch weitere Programme / Aufgaben laufen...
Nicht immer kann alles in Prozessor-Caches aufgefangen werden...
Da werden die neuen "Cache-gepimpten" Ryzens im Winter interessant - Programme, die sich damit stark beschleunigen lassen, fallen dann genau in die genannte Kategorie...
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Das beliebte Totschlagargument zum Thema Multithreading mal wieder bei dem wie üblich nicht auf den prozentualen Anteil des beschriebenen Szenarios auf die Gesammtperfürmance eingegangen wird und offensichtlich komplett übersehen wurde das es beim SMT Thema komplett nutzlos ist, eben weil das Programm nicht parallel auf dem zweiten Thread des Kerns weiter arbeiten könnte. 
Noch nutzloser ist es bei massiv parallelisierten Architekturen wie einer GPU.
Noch nutzloser ist es bei massiv parallelisierten Architekturen wie einer GPU.
Maverick-F1
Grand Admiral Special
Puh - das war ein langer Satz - den ich nicht ganz verstanden habe...
Warum soll das ein "Totschlagargument" sein? Solche Szenarien gibt es durchaus - auch wenn die afaik inzwischen in der Minderzahl sind..
Und genau dann kann ein anderes Programm (mit ggf. geringeren Speicheranforderungen) via SMT auf demselben Core weiterlaufen, solange Programm 1 auf diesem auf Daten warten muss...
Das soll fehlende MT-Optimierungen nicht entschuldigen...
Warum soll das ein "Totschlagargument" sein? Solche Szenarien gibt es durchaus - auch wenn die afaik inzwischen in der Minderzahl sind..
Und genau dann kann ein anderes Programm (mit ggf. geringeren Speicheranforderungen) via SMT auf demselben Core weiterlaufen, solange Programm 1 auf diesem auf Daten warten muss...
Das soll fehlende MT-Optimierungen nicht entschuldigen...
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.330
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Weil es das Standard Argument seit dem Aufkommen des Multithreadings im Desktop Bereich ist um mangelhaftes oder gar fehlendes Multithreading bei den Programmen zu rechtfertigen, natürlich ohne zu berücksichtigen wie hoch der zwingend erforderliche Anteil solcher Szenarien und damit der Einfluß auf die letztendliche Performance ist. Anders ausgedrückt, warum sollte man sich als Kunde mit so einer Umsetzung abfinden wenn es z.B. lediglich 0,5% des Codes bzw. der CPU Laufzeit betrifft und auf die restlichen 99,5% parallelisierbaren Code verzichten?
Wie von Zauberhand sind wir dennoch dort angelangt wo wir heute sind, auch wenn die Software Entwicklung dennoch um Jahre hinter der Hardware Entwicklung hinterher hinkt.
Richtig lustig und absurd war diese Argumentation bei der Rechtfertigung des fehlenden Multithreadings beim CPU Fallback vom GPU Physx.
Programme parallel auszuführen ist Aufgabe des Multitaskings und ändert nichts am grundsätzlichen Problem das die Ausführungseinheiten des Kerns geteilt werden müssen. Je nach Priorisierung bekommt ein Programm so viel Laufzeit wie es nutzen kann und das andere vom zusätzlichen virtuellen Kern eben die Reste oder es wird relativ gleichmäßig aufgeteilt und beide Programme laufen entsprechend langsamer als eines. Eben je nachdem wie schlecht das Programm den Kern nutzen kann und entsprechend viel Rechenleistung liegen läßt.
Ach ich klinke mich hier wieder aus....
Wie von Zauberhand sind wir dennoch dort angelangt wo wir heute sind, auch wenn die Software Entwicklung dennoch um Jahre hinter der Hardware Entwicklung hinterher hinkt.
Richtig lustig und absurd war diese Argumentation bei der Rechtfertigung des fehlenden Multithreadings beim CPU Fallback vom GPU Physx.
Programme parallel auszuführen ist Aufgabe des Multitaskings und ändert nichts am grundsätzlichen Problem das die Ausführungseinheiten des Kerns geteilt werden müssen. Je nach Priorisierung bekommt ein Programm so viel Laufzeit wie es nutzen kann und das andere vom zusätzlichen virtuellen Kern eben die Reste oder es wird relativ gleichmäßig aufgeteilt und beide Programme laufen entsprechend langsamer als eines. Eben je nachdem wie schlecht das Programm den Kern nutzen kann und entsprechend viel Rechenleistung liegen läßt.
Doppelposting wurde automatisch zusammengeführt:
Ach ich klinke mich hier wieder aus....
Zuletzt bearbeitet:
Maverick-F1
Grand Admiral Special
Ok, jetzt hab' ich's denke ich verstanden.
Meine Aussage sollte dieser Kritik ja auch gar nicht widersprechen (an der Optimierung zu sparen, spart halt leider Programmieraufwand und damit Geld für den Entwickler![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]") ), sondern nur darlegen, dass es tatsächlich auch mal nicht nur am Code selbst liegen kann, wenn Einheiten schlecht ausgelastet sind.
), sondern nur darlegen, dass es tatsächlich auch mal nicht nur am Code selbst liegen kann, wenn Einheiten schlecht ausgelastet sind.
Als Kunde kann man das natürlich nur sehr schwer nachweisen...
Meine Aussage sollte dieser Kritik ja auch gar nicht widersprechen (an der Optimierung zu sparen, spart halt leider Programmieraufwand und damit Geld für den Entwickler
), sondern nur darlegen, dass es tatsächlich auch mal nicht nur am Code selbst liegen kann, wenn Einheiten schlecht ausgelastet sind.Als Kunde kann man das natürlich nur sehr schwer nachweisen...
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 486
- Antworten
- 1K
- Aufrufe
- 70K
- Antworten
- 17
- Aufrufe
- 2K
- Antworten
- 728
- Aufrufe
- 50K
- Antworten
- 8
- Aufrufe
- 1K