App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Zen - 14nm, 8 Kerne, 95W TDP & DDR4?
- Ersteller UNRUHEHERD
- Erstellt am
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Das ist lediglich eine Roadmap für mobile Geräte. Und 4 Kerne mit maximal 35W ist schon recht ordentlich. Man sollte nicht vergessen, da stehen bei Carrizo zwar auch 4 "Kerne", aber es sind in Wirklichkeit halt nur zwei vollwertige Kerne bzw zwei verarbeitende Pipelines bei den bisherigen Bulldozer APUs. Nur mal zum Vergleich, Carrizo hat insgesamt 22 Pipes für Ausführungseinheiten, Bristol Ridge hingegen hätte 36 Pipes für Ausführungseinheiten. So eine Bristol Ridge APU sollte also trotz gleicher nomineller Kernanzahl deutlichst schneller werden. Bei maximaler Auslastung vielleicht sogar bis zu doppelt so schnell, wenn die Taktraten passen. 8 Zen Kerne bei maximal 35W wäre totaler Overkill. Schliesslich gibt's auch noch eine iGPU, die mit Strom versorgt werden will.8 Kern-APU hätte ich schon gedacht, und eventuell 16 Kern ohne APU als Option für Workstations. FM3 scheint wieder ein recht kleiner Sockel zu werden.
Gab es denn schon mal Roadmaps mit Bristol Ridge? Meines Wissens nicht. Bisher waren das doch alles nur Gerüchte. Insofern würde ich nicht ausschliessen, dass Bristol Ridge doch bereits Zen Kerne an Bord hat.Hübsch ... nur blöd dass Bristol Ridge noch in 28nm und mit Excavator-Kernen kommt ... Zen in APUs gibts dagegen erst 2017 mit "Raven Ridge" ... kleiner Fehler in dem bunten Bildchen")
Und was genau stört dich dran? Der 14nm Prozess von Samsung/Glofo scheint nach bisherigen Infos besser zu werden als der 16nm Prozess von TSMC. Zudem läuft die 14nm Fertigung bei Samsung/Glofo bereits und sollte nächstes Jahr auch ausreichend gute Yields liefern können. Von der 16nm Fertigung bei TSMC hört man im Moment recht wenig.Was mich an der Roadmap stört ist, dass demnach nur noch der Samsung/GloFo FinFet-Prozess zum Einsatz kommt. Von TSMC i.e. "16nm" ist keine Rede mehr (gut könnte für die GPUs noch in Frage kommen).
Nee, damit ist schon ein Kern gemeint und nicht ein Cluster. Wobei ich davon ausgehe, dass bei Basilisk das gleiche Die wie bei Bristol Ridge zum Einsatz kommt und lediglich Kerne deaktiviert werden. Die TDP jedenfalls spricht dafür. Interessant ist allerdings die K12 basierte Styx APU. Das könnte in der Tat ein natives 2-Kern Design werden. Womöglich gibt es solche 4-Kern Cluster bei K12 nicht oder sie sind dort anders aufgebaut.Ja guckt doch mal genau hin: bei den kleinen Einstiegs APUs steht "up to 2 "zen" CPU Cores" - bis zu zwei ZEN Kerne. Also wird es auch Modelle mit einem "ZEN"-Kern geben und das wird ja wohl kaum ein logischer Kern also Thread sein. Kann es also sein, dass da mit ZEN-Kern so ein Cluster gemeint ist? Oder SMT inbegriffen.
Naja, letztes Jahr hat Lisa Su höchstpersönlich auch verlauten lassen, dass man dabei sei, diverse Designs für 20nm vorzubereiten. Siehst du irgendwas von 20nm? Ich bisher nicht. Also ich könnte mir schon vorstellen, dass man 20nm bis auf Amur überspringt und sofort auf 14nm geht.Also die Roadmap ist mit Sicherheit ein Fake. Ende 2015 stoppt AMD alle Fertigungsprozesse ausser 14nm? Kaum, nachdem sie erst mitgeteilt haben 28nm noch lange in bestimmten Segemnten zu nutzen.
Denkst du nicht, dass es gerade deshalb langsam mal Zeit wird für einen radikalen Schritt? Von 32nm Bulldozer auf 28nm Bulldozer ist kein solcher Schritt. Von 32nm Bulldozer auf 14nm Zen hingegen schon. Ich meine, die Ressourcen, die man seit einigen Jahren spart, indem das 4M Bulldozer Design nicht weiterentwickelt wird, müssen ja irgendwo anders hingeflossen sein.Kleine Erinnerung .. AMDs Spitzenprodukt wird in 32nm hergestellt und wir haben 2015 ...
Die Effizienzverbesserungen sind schon auf Kernebene passiert. Nur weniger durch mehr Performance (+5% IPC), sondern vielmehr durch Energieeinsparung (-40%). AMD braucht aber im Grunde beides für 2016. Daher war mir das mit dem Carrizo Desktop Aufguss auch immer etwas suspekt. Zumal bei höheren Taktraten bzw höheren Leistungsklassen der Effizienzvorteil gegenüber Kaveri verlorengeht. Und das kann man auch nicht einfach mal mit einem neuen Stepping ändern. Und viel besser dürfte die 28nm Fertigung auch nicht mehr werden.Die Effizienzverbesserungen bei Carrizo scheinen mir auch eher nicht auf "Kerneebene" plaziert zu sein, sondern dass man diese dann auch direkt in einem neuen Design verwenden kann (und nicht nochmal entwickeln muss).
Houston2603
Gesperrt
- Mitglied seit
- 21.11.2010
- Beiträge
- 123
- Renomée
- 1
Und was genau stört dich dran? Der 14nm Prozess von Samsung/Glofo scheint nach bisherigen Infos besser zu werden als der 16nm Prozess von TSMC. Zudem läuft die 14nm Fertigung bei Samsung/Glofo bereits und sollte nächstes Jahr auch ausreichend gute Yields liefern können. Von der 16nm Fertigung bei TSMC hört man im Moment recht wenig.
Wie lautet denn die Aktuelle Info dazu? (Sorry wenn ich hier so rein platze, will dir nix
") )
)Die letzte die ich gesehen hatte ( gut was her ) waren 30% bei den Yields.
Nur weiß ich nicht mehr, ob das bullshit war, oder wirklich so.
Haste da nen Link für mich
") ?
?Edit: Sprache ist egal, falls das ne Rolle spielt.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Natürlich .. deshalb wird die 32nm Vishera-CPU mit den Uralt-Piledriverkernen durch den 14nm Zen ersetzt.Denkst du nicht, dass es gerade deshalb langsam mal Zeit wird für einen radikalen Schritt? Von 32nm Bulldozer auf 28nm Bulldozer ist kein solcher Schritt. Von 32nm Bulldozer auf 14nm Zen hingegen schon. Ich meine, die Ressourcen, die man seit einigen Jahren spart, indem das 4M Bulldozer Design nicht weiterentwickelt wird, müssen ja irgendwo anders hingeflossen sein.
Bei den APUs haben wir dagegen eine ganz andere Situatuation, Carrizo ist im Vergleich zu Vishera toppaktuell:
1. Flexible Spannungseinstellungen und ondie-Sensorik
2. HDLibs (-> kleines Die -> billig)
3. 28nm bulk statt 32 SOI (-> billig und kleiner)
4. Excavatorkerne statt Piledriver (Zwei Generationen Unterschied)
Carrizo hielte also locker noch ein Jahr durch, erst recht mit DDR4-Speicher. Dessen Technik ist noch lange nicht so angegraut wie die FXe jetzt. Wozu also ersetzen? Der soll erstmal seine Entwicklungskosten einspielen
Ja, das ist so wahrscheinlich wie Llano Bulldozerkerne hatte...Gab es denn schon mal Roadmaps mit Bristol Ridge? Meines Wissens nicht. Bisher waren das doch alles nur Gerüchte. Insofern würde ich nicht ausschliessen, dass Bristol Ridge doch bereits Zen Kerne an Bord hat.
Das mag schon stimmen, aber es geht nicht darum was AMD "bräuchte", sonder darum was AMD "kann". Wünsch-Dir-Was gibts nicht, AMD hat begrenzte Ressourcen und die müssen sie entsprechend nutzen. Ne Zen-APU 2016 wäre schön, aber ich glaub nicht dran. Dazu hatte AMD in letzter Zeit erstens schon genügend Probleme (z.B. bei Kaveri und damals wurde keine CPU parallel entwickelt), außerdem ist es einfach gang und gäbe eine komplett neue Architektur erstmal nur mit einem Chip zu testen.Die Effizienzverbesserungen sind schon auf Kernebene passiert. Nur weniger durch mehr Performance (+5% IPC), sondern vielmehr durch Energieeinsparung (-40%). AMD braucht aber im Grunde beides für 2016. Daher war mir das mit dem Carrizo Desktop Aufguss auch immer etwas suspekt. Zumal bei höheren Taktraten bzw höheren Leistungsklassen der Effizienzvorteil gegenüber Kaveri verlorengeht. Und das kann man auch nicht einfach mal mit einem neuen Stepping ändern. Und viel besser dürfte die 28nm Fertigung auch nicht mehr werden.
Kämen CPU und APU gleichzeitig, geht man das hohe Risiko ein gleich zwei Schrottchips samt Schrottmasken zu haben. Das macht doch freiwillig keiner, das finanzielle Risiko ist viel zu groß, erst recht wenn man so "volle" Kassen wie AMD hat. Wenn doch, so wär das für mich "suspekt". Ein Desktop-Carrizo ist dagegen viel wahrscheinlicher. Oder anders gesagt:
Lieber den Carrizo in der Hand als Zen auf dem Dach
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Das war zB eine der Infos bzw eines der Gerüchte. Gibt halt verschiedene Indikatoren. ZB Nvidia soll für Pascal auch auf 14nm Samsung setzen und nicht auf 16nm TSMC. BoMbY hatte ja schon einen Link gepostet, der den aktuellen Stand kurz zusammenfasst.Wie lautet denn die Aktuelle Info dazu? (Sorry wenn ich hier so rein platze, will dir nix
Die letzte die ich gesehen hatte ( gut was her ) waren 30% bei den Yields.
Naja, so grundlegend anders ist die Situation aber auch nicht. Halt 28nm statt 32nm, Excavator statt Piledriver (+15-25% IPC?) und verbesserte Stromspartechniken. Und Carrizo ist erst mal nur für bis zu 35W TDP vorgesehen. Verständlich, wenn das Modul ab etwa 20W gegenüber Steamoller an Takt verliert. Bis 35W für die gesamte APU mögen die Effizienzverbesserungen schon recht beachtlich sein. Aber oberhalb scheinen sie deutlich abzunehmen. Wie soll man da brauchbare Desktop Updates für 2016 zusammenbasteln? 65/95W Carrizo Desktop Prozessoren sind bisher jedenfalls nicht bestätigt. Und ich würde sie auch nicht erwarten, weil ich zumindest CPU-seitig kaum Verbesserungspotenzial gegenüber Kaveri sehe. Der Kaveri Refresh legt ja auch noch etwas an Takt nach und liegt damit fast wieder auf Richland Niveau. Einzig die Carrizo iGPU würde einige nette Verbesserungen mitbringen, wie aktualisierte UVD/VCE Einheiten und vollständigen HSA 1.0 Support. Das ist insgesamt aber einfach zu wenig. Eine 4-Kern Zen APU hätte da ganz andere Möglichkeiten. Zusammen mit einer 768 oder 1024 Shader GCN 2.0 iGPU und HBM2 wäre das ein richtiges Brett. Der würde Retail weggehen wie warme Semmeln, wenn Zen hält, was er verspricht. Und selbst OEMs kämen da kaum drumherum, trotz Intel Diktatur.Natürlich .. deshalb wird die 32nm Vishera-CPU mit den Uralt-Piledriverkernen durch den 14nm Zen ersetzt.
Bei den APUs haben wir dagegen eine ganz andere Situatuation, Carrizo ist im Vergleich zu Vishera toppaktuell:
Zu HDL, sicherlich bringt das einiges. Carrizo ist trotzdem etwa 250 mm² gross. So klein ist das Die also auch nicht. Ein 4-Kern Zen wäre sicherlich mit 150-200 mm² machbar. Das sollte mit 14nm FinFET zwar immer noch teurer sein. Allerdings nicht mehr ganz so deutlich wie bei gleicher Grösse. Und für ein besseres Produkt könnte man auch mehr verlangen. Die ASPs würden steigen und höhere Kosten könnten besser kompensiert werden.
Du meinst von etwa Mitte 2016 bis etwa Mitte 2017? 1H 2017 heisst es dann womöglich 28nm Bulk Carrizo vs 10nm FinFET Cannonlake. Und selbst Skylake dürfte bis dahin schon einiges gegenüber den aktuellen Core-Eiern zulegen. Irgendwie habe ich da deutliche Zweifel, dass Carrizo locker durchhalten würde. Ein Desktop Carrizo würde eigentlich nur Sinn machen, wenn man ihn noch in diesem Jahr bringt. Und am besten gestern als am 31.12.Carrizo hielte also locker noch ein Jahr durch
Zuletzt bearbeitet:
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.033
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
Carizzo kommt ja demnächst bzw. dürfte schon testweise an Notebookhersteller rausgehen. Wenn Zen dann Jahresmitte '16 kommt, dann war das doch ein ganzes Jahr für Carizzo. Falls die 14-nm-Fertigung oder der einzelne Chip sich dann unvorhergesehen noch um einige Monate verzögern sollte, kann Carizzo das noch abfangen. Und AMD ist glaube ich auch einfach froh, BD so schnell wie möglich wegschmeißen zu können.
Zudem, egal wie gut Zen wird, allein durch die 14-nm-Fertigung wird jeder neue Chip zwangsläufig ein Quantensprung ggü. dem 28-nm-Carizzo, also gibt es dann keinen Grund, noch daran festzuhalten.
Und wie schon jemand gesagt hat, die diversen Verbesserungen in Carizzo sind ja allgemeiner Natur (feinstufige Takt- und Spannungsregelung), Carizzo war also sozusagen nur eine Übung für die nächsten Chips, d.h. da muß sich nicht etwas amortisieren, bevor man es wegwerfen kann. AMD klatscht inzwischen ein Chipdesign relativ schnell und automatisiert zusammen, es muß nur festgelegt werden, welche vorhandene IP-Bausteine darin enthalten sein sollen. Damit werden auch schnelle Wechsel durchaus sinnvoll umsetzbar.
Zudem, egal wie gut Zen wird, allein durch die 14-nm-Fertigung wird jeder neue Chip zwangsläufig ein Quantensprung ggü. dem 28-nm-Carizzo, also gibt es dann keinen Grund, noch daran festzuhalten.
Und wie schon jemand gesagt hat, die diversen Verbesserungen in Carizzo sind ja allgemeiner Natur (feinstufige Takt- und Spannungsregelung), Carizzo war also sozusagen nur eine Übung für die nächsten Chips, d.h. da muß sich nicht etwas amortisieren, bevor man es wegwerfen kann. AMD klatscht inzwischen ein Chipdesign relativ schnell und automatisiert zusammen, es muß nur festgelegt werden, welche vorhandene IP-Bausteine darin enthalten sein sollen. Damit werden auch schnelle Wechsel durchaus sinnvoll umsetzbar.
Kämen CPU und APU gleichzeitig, geht man das hohe Risiko ein gleich zwei Schrottchips samt Schrottmasken zu haben. Das macht doch freiwillig keiner, das finanzielle Risiko ist viel zu groß, erst recht wenn man so "volle" Kassen wie AMD hat. Wenn doch, so wär das für mich "suspekt". Ein Desktop-Carrizo ist dagegen viel wahrscheinlicher. Oder anders gesagt:
Lieber den Carrizo in der Hand als Zen auf dem Dach
Du sprichst von 2 Masken - wieso?
Wie läuft das ab mit dem Interposer? Muss der gleich Teil der Maske sein?
Weil wenn nicht, gibt es eigentlich nur eine Maske - und zwar die für den Zenkern/Unit (= 4 Kerne?) selbst. Dann noch die GPU Maske [aber das ist bekanntes Terrain - da wohl die GNC Architektur von Fiji kommt... Und die ist ja in den letzten Zügen zum Release].
Das fertige Produkt wird dann per Interposer "zusammengesteckt"...
Vorteil: Es gibt ja zwei Arten, wie man Produkte sortieren muss im Umfeld CPU/GPU.
Zum einen die (Teil-) defekten. Damit werden die kleinen CPUs/GPUs realisiert. Zum anderen habe ich aber auch die Chips die über den Bereich der Taktfrequenz entweder in Fehler laufen oder z viel Spannung benötigen. => daraus baut man dann die, die mit wenig Spannung und Takt laufen => ergo evt. für den Moblenbereich lohnen...
und zu letzt. 1 Jahr sollte langen eine weitere Maske zu bringen - und von der ersten zu "lernen".
Was mich etwas hoffen lässt, ist das Samsungs Prozess anscheinend schon recht gut geht. Und GloBo nutzt doch auch diesen Prozess. Vielleicht hat AMD diesmal einfach nur Glück gehabt und alles Gute kommt auf einmal...
Na ja abwarten.. so lange ist es jetzt nicht mehr hin...
P.S.: Noch ein Denkfehler.. Wenn ich selbst nicht daran glaube, das ein Produkt seine Entwicklungkosten einspielt - dann ist es völlig richtig früh dieses Projekt zu Grabe zu tragen. Und wie schon erwähnt. Die Forschung war ja nicht für die Katze... Sie kann auf den neuen Produkten genutzt werden und dort zu Umsatz führen....
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Wenn ich das richtig verstehe meint Josh Walrath von PcPer, für die Zens ohne GPU würde sich anbieten die mit LPE zu fertigen.
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.033
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
@Novasun: Nein, HBM (was eine Interposer-Konstruktion erfordert) kriegen wohl nur die richtig fetten GPUs, die so einen extremen Bandbreitenbedarf haben. Und eben dieses monströse Server-Teil. Aber die APUs und CPUs für die normalen Rechner werden wohl normale monolithische Dies sein, also sowas wie wir bisher immer haben. HBM-RAM wäre dafür zwar nett, aber übertrieben, und einfach zu teuer. Wenn man sich überlegt, daß die GPUs dann die bandbreitenschonende Kompression wie bei Tonga bekommen und mit DDR4 sowieso mehr Bandbreite zur Verfügung steht, dann sollte das erstmal reichen, um eine größere iGPU versorgen zu können. Bei Kaveri merkt man ja auch, daß zwar 2100er RAM gut ist, aber es darüber auch nur noch wenig Leistungszuwachs gibt, wenn man die Bandbreite noch beliebig weiter steigert.
Und diese Sorgen wegen den Masken, verabschiedet Euch mal davon. Das war vor Jahren noch ein Problem, weil die handgeschnitzt waren, sprich da saßen Leute und haben die Leiterbahnen gemalt. Aber AMD geht ja dazu über, diese Abläufe sehr stark zu automatisieren. Damit wird es dann relativ einfach, eine neue Maske zu erstellen. Viel Arbeit fließt da rein, diese Automatisierungsprogramme zu optimieren, aber der einzelne Chip ist recht fix zusammengebastelt. Nur so können sie ja überhaupt Custom-Chips anbieten, da kommt dann ein Kunde und will einen Spezialchip in relativ kleiner Auflage und evtl. noch eigener IP mit drin, sowas wäre früher unmöglich (bzw. unbezahlbar) gewesen.
--- Update ---
Das wäre schön, aber glaube ich nicht. AMD hat ja gesagt, sie wollen mit möglichst wenigen verschiedenen Fertigungsprozessen auskommen. Automatisiert eine neue Maske für einen anders geschnittenen Chip im gleichen Fertigungsprozeß zu erstellen ist sicherlich viel einfacher als die kritischen Stellen dann noch an einen anderen Prozeß anzupassen, das wäre echt eine Heidenarbeit.
Außerdem, selbst in dem Fertigungsprozeß, in dem Kaveri gefertigt wird, der ja nicht auf viel Takt ausgelegt ist, schaffen sie 4 GHz. Zen sollte bei deutlich besserer IPC gar nicht mehr Takt benötigen, um auf mehr Leistung zu kommen. Dazu kommt noch der Shrink, was per se schon die mögliche Taktfrequenz erhöht. Also ich mache mir da keine Sorgen (angenommen, Zen ist wirklich gut), wenn aus ökonomischen Erwägungen heraus die reine 8-Kern-CPU für den Performance-Markt auch in dem "normalen" 14-nm-Prozeß gefertigt werden muß.
Und diese Sorgen wegen den Masken, verabschiedet Euch mal davon. Das war vor Jahren noch ein Problem, weil die handgeschnitzt waren, sprich da saßen Leute und haben die Leiterbahnen gemalt. Aber AMD geht ja dazu über, diese Abläufe sehr stark zu automatisieren. Damit wird es dann relativ einfach, eine neue Maske zu erstellen. Viel Arbeit fließt da rein, diese Automatisierungsprogramme zu optimieren, aber der einzelne Chip ist recht fix zusammengebastelt. Nur so können sie ja überhaupt Custom-Chips anbieten, da kommt dann ein Kunde und will einen Spezialchip in relativ kleiner Auflage und evtl. noch eigener IP mit drin, sowas wäre früher unmöglich (bzw. unbezahlbar) gewesen.
--- Update ---
Wenn ich das richtig verstehe meint Josh Walrath von PcPer, für die Zens ohne GPU würde sich anbieten die mit LPE zu fertigen.
Das wäre schön, aber glaube ich nicht. AMD hat ja gesagt, sie wollen mit möglichst wenigen verschiedenen Fertigungsprozessen auskommen. Automatisiert eine neue Maske für einen anders geschnittenen Chip im gleichen Fertigungsprozeß zu erstellen ist sicherlich viel einfacher als die kritischen Stellen dann noch an einen anderen Prozeß anzupassen, das wäre echt eine Heidenarbeit.
Außerdem, selbst in dem Fertigungsprozeß, in dem Kaveri gefertigt wird, der ja nicht auf viel Takt ausgelegt ist, schaffen sie 4 GHz. Zen sollte bei deutlich besserer IPC gar nicht mehr Takt benötigen, um auf mehr Leistung zu kommen. Dazu kommt noch der Shrink, was per se schon die mögliche Taktfrequenz erhöht. Also ich mache mir da keine Sorgen (angenommen, Zen ist wirklich gut), wenn aus ökonomischen Erwägungen heraus die reine 8-Kern-CPU für den Performance-Markt auch in dem "normalen" 14-nm-Prozeß gefertigt werden muß.
y33H@
Admiral Special
- Mitglied seit
- 16.05.2011
- Beiträge
- 1.768
- Renomée
- 10
Er stellt das als Fakt dar: "These will be manufactured on 14nm FinFET LPE".Wenn ich das richtig verstehe meint Josh Walrath von PcPer, für die Zens ohne GPU würde sich anbieten die mit LPE zu fertigen.
In den Comments meinte dann einer, wenn schon 14nmFF, dann LPP und Josh gibt ihm Recht ...
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Naja .. das ist jetzt aber Wortklauberei. Von mir aus nicht "grundlegend", aber mind. "deutlich". Das sind immerhin schon 3 Faktoren, Prozess, Kernarchitektur und Chiparchitektur. Recht viel mehr Parameter gibts nicht, anhand derer man ein Produkt als "neu" oder "alt" klassifizieren könnte, d.h. in allen Parametern ist Carrizo vorne, es ist definitiv kein altes Design.Naja, so grundlegend anders ist die Situation aber auch nicht. Halt 28nm statt 32nm, Excavator statt Piledriver (+15-25% IPC?) und verbesserte Stromspartechniken.
Jo, deswegen heißt der neue Chip auch nicht mehr CarrizoUnd Carrizo ist erst mal nur für bis zu 35W TDP vorgesehen.
Das hatte Novacius auf der letzten Seite schon angesprochen, ich kopier mal meine Antwort rein:Verständlich, wenn das Modul ab etwa 20W gegenüber Steamoller an Takt verliert.
http://www.planet3dnow.de/vbulletin...95W-TDP-DDR4?p=5004736&viewfull=1#post5004736Das mit der Effizienz ist die Kurve ohne AVFS. Die Kurve mit AVFS hört bei ~23W auf, ist aber immer noch flacher .. also da mach ich mir keine Sorgen, bis 2016 kann man auch wieder die üblichen Prozess-Verbesserungen miteinkalkulieren und durch DDR4 spart man auch wieder ein paar Milliwatt beim DRAM-Kontroller.
Ja, aber AMD ist dafür bekannt gleiche Dies unter fünf verschiedenen Codenamen quer über die Roadmaps zu verstreuen. Außerdem siehe oben, die Effizienz-Kurve ist so schlecht nicht, und selbst wenn - interessiert die bei ~95W APUs niemanden.65/95W Carrizo Desktop Prozessoren sind bisher jedenfalls nicht bestätigt.
Was meinst DU nun mit "CPU-Seitig"? IPC? Na da werden die doppelten L1-Caches schon gut nachlegen, wer weiss, vielleicht hat AMD auch die interen Puffer vergrößert, viel ist ja noch nicht bekannt und bei einer Desktop-Version reden wir bekanntlich über eine mit DDR4, das legt schön GPU-Leistung nach.Und ich würde sie auch nicht erwarten, weil ich zumindest CPU-seitig kaum Verbesserungspotenzial gegenüber Kaveri sehe.
Jo richtig, aber das ist der gleiche Punkt wie beim letzten Posting, es geht nicht darum, was AMD "bräuchte", oder was wegging wie warme Semmeln, sondern darum was AMD imstande ist zu leisten.Eine 4-Kern Zen APU hätte da ganz andere Möglichkeiten. Zusammen mit einer 768 oder 1024 Shader GCN 2.0 iGPU und HBM2 wäre das ein richtiges Brett. Der würde Retail weggehen wie warme Semmeln, wenn Zen hält, was er verspricht. Und selbst OEMs kämen da kaum drumherum, trotz Intel Diktatur.
Gleichzeitig mit den ganzen Chips kommt auch ne neue DDR4-Plattform, die muss man auch erst wieder debuggen, alles gleichzeitig zu bringen wäre Selbstmord. Der logische Schritt ist ein früher Start des neuen DDR4-Sockels mit dem besten & bewährten Chip und das wäre im aktuellen Fall eben ein Carrizo-Derivat. Also FM3-Plattformstart im 1H/16 und dafür die ZEN-CPU im 2H/16, Upgrade durch ne ZEN-APU in 1H/17. So macht es Sinn und so melden es auch die Schweden.
Ja, die integrierte SB verzerrt die Flächeneinsparung halt etwas. Ändert nichts an der Verfügbarkeit und der Zuverlässigkeit. Notfalls könnte sich AMD für Bristol Ridge sogar noch ein extra Die leisten, das wäre immer noch wahrscheinlicher als ein 14nm APU-Die.Zu HDL, sicherlich bringt das einiges. Carrizo ist trotzdem etwa 250 mm² gross.
Jo, aber das ist nur wieder der gleiche Punkt ... schön wärs ohne Zweifel, aber könnte AMD es und was ist mit den Risiken von ZEN-Bugs?So klein ist das Die also auch nicht. Ein 4-Kern Zen wäre sicherlich mit 150-200 mm² machbar. Das sollte mit 14nm FinFET zwar immer noch teurer sein. Allerdings nicht mehr ganz so deutlich wie bei gleicher Grösse. Und für ein besseres Produkt könnte man auch mehr verlangen. Die ASPs würden steigen und höhere Kosten könnten besser kompensiert werden.
Siehe oben, im 1H/17 könnte auch die ZEN-APU kommen.Du meinst von etwa Mitte 2016 bis etwa Mitte 2017? 1H 2017 heisst es dann womöglich 28nm Bulk Carrizo vs 10nm FinFET Cannonlake.
Naja, 1Q-1H/16 reicht schon auch noch, da ist nicht soviel Unterschied, das halbe Jahr kann man ruhig noch abwarten, um dann 2016 mit billigeren DDR4-Preisen zu starten.Ein Desktop Carrizo würde eigentlich nur Sinn machen, wenn man ihn noch in diesem Jahr bringt. Und am besten gestern als am 31.12.
Ja so kann mans auch sehen, 28nm/Excavator als Absicherung ggü. Zen-Architekturbugs und gegen eventuelle 14nm Probleme.Carizzo kommt ja demnächst bzw. dürfte schon testweise an Notebookhersteller rausgehen. Wenn Zen dann Jahresmitte '16 kommt, dann war das doch ein ganzes Jahr für Carizzo. Falls die 14-nm-Fertigung oder der einzelne Chip sich dann unvorhergesehen noch um einige Monate verzögern sollte, kann Carizzo das noch abfangen.
Das mit dem Test ist sicher richtig, aber wenn Du so wie Du rechnest, dann gibts sind die Kosten für einen weiteren Einsatz bei ZERO/Null/Niente ... bei AMDs Kassenstand sicherlich kein kleines Argument.Und wie schon jemand gesagt hat, die diversen Verbesserungen in Carizzo sind ja allgemeiner Natur (feinstufige Takt- und Spannungsregelung), Carizzo war also sozusagen nur eine Übung für die nächsten Chips, d.h. da muß sich nicht etwas amortisieren, bevor man es wegwerfen kann. AMD klatscht inzwischen ein Chipdesign relativ schnell und automatisiert zusammen, es muß nur festgelegt werden, welche vorhandene IP-Bausteine darin enthalten sein sollen. Damit werden auch schnelle Wechsel durchaus sinnvoll umsetzbar.
Den Interposereinsatz erwarte ich nur bei den Opteronchips. Die Zen-APU wird dagegen wieder aus einem Guss. 4 Kerne mit 8 Threads reichen der APU ganz sicher, also nur ein Zen-Quad-Modul. Als 2. Die erwarte ich eine 8core-Zen-CPU die sich dann über die Interposer mit weiteren 8core-Zens oder GPU-Dies mit HBM zusammenschalten lässt.Du sprichst von 2 Masken - wieso?
Wie läuft das ab mit dem Interposer? Muss der gleich Teil der Maske sein?
Pure Spekulation, vor dem Hintergrund dass sich die Desktop-APU die DDR4-Kanäle mit der CPU teilt. Da braucht es viel Bandbreite die ich im Moment nur bei monolithischen Dies sehe. Off-Die-Interconnects sind lahm, egal welcher Einzige Möglichkeit wäre ein Stapeln von CPU und GPU-Dies und TSV-Verbindungen, aber das ist auch thermischer Sicht ne schlechte Idee, das klappt nur mit RAM.
Bei den Opteron-APUs wär das dagegen kein Problem, wenn der GPU-Part sein eigenes VRAM als HBM mitbringt, dadurch wird der Interconnect entlastet und der Legoansatz macht dann (viel) Sinn.
Das liegt nur am NB-Takt, der bei den APUs dann zu niedrig ist.Bei Kaveri merkt man ja auch, daß zwar 2100er RAM gut ist, aber es darüber auch nur noch wenig Leistungszuwachs gibt, wenn man die Bandbreite noch beliebig weiter steigert.
Oj ... da verwechselst Du jetzt Chip-Design mit Masken-Design .. das sind 2 Paar Schuhe. Masken sind immer noch sauteuer und mit Double-Pattering braucht man jetzt auch noch 2 pro Design ... vermutlich auch der Grund, wieso keiner 20nm nutzt, die Kosten sind genauso groß wie bei 14nm aber ohne Finfets hat man deutlich weniger Vorteile.Und diese Sorgen wegen den Masken, verabschiedet Euch mal davon. Das war vor Jahren noch ein Problem, weil die handgeschnitzt waren, sprich da saßen Leute und haben die Leiterbahnen gemalt. Aber AMD geht ja dazu über, diese Abläufe sehr stark zu automatisieren. Damit wird es dann relativ einfach, eine neue Maske zu erstellen. Viel Arbeit fließt da rein, diese Automatisierungsprogramme zu optimieren, aber der einzelne Chip ist recht fix zusammengebastelt. Nur so können sie ja überhaupt Custom-Chips anbieten, da kommt dann ein Kunde und will einen Spezialchip in relativ kleiner Auflage und evtl. noch eigener IP mit drin, sowas wäre früher unmöglich (bzw. unbezahlbar) gewesen.
Jo, einzige Frage wird sein, ob man die ZEN-CPU auf 4 GHz wird prügeln können, oder nichtAußerdem, selbst in dem Fertigungsprozeß, in dem Kaveri gefertigt wird, der ja nicht auf viel Takt ausgelegt ist, schaffen sie 4 GHz. Zen sollte bei deutlich besserer IPC gar nicht mehr Takt benötigen, um auf mehr Leistung zu kommen. Dazu kommt noch der Shrink, was per se schon die mögliche Taktfrequenz erhöht. Also ich mache mir da keine Sorgen (angenommen, Zen ist wirklich gut), wenn aus ökonomischen Erwägungen heraus die reine 8-Kern-CPU für den Performance-Markt auch in dem "normalen" 14-nm-Prozeß gefertigt werden muß.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Also für mich ist das definitiv nicht deutlich. Zumindest wenn wir hier über einen TDP Bereich von 65-95W sprechen. Aber gut, das ist wohl subjektiv. Bei 15-35W TDP würde ich durchaus zustimmen.Naja .. das ist jetzt aber Wortklauberei. Von mir aus nicht "grundlegend", aber mind. "deutlich".
"So schlecht nicht" reicht aber nun mal nicht, wenn man ein deutliches Update gegenüber Kaveri bieten will.Außerdem siehe oben, die Effizienz-Kurve ist so schlecht nicht
Performance und Leistungsaufnahme. Was sonst? Verrate mir doch mal, wie Carrizo mit 5% mehr IPC ein lohnenswertes CPU Update erhalten soll, wenn bei 95W TDP die Taktraten nicht erhöht werden können bzw vielleicht sogar um einige Prozent sinken. Eine ähnliche Geschichte hatten wir doch nun schon von Richland auf Kaveri. Vermutlich hat das AMD etwas unterschätzt. Kann mir nicht vorstellen, dass man den gleichen Fehler zweimal machen will.Was meinst DU nun mit "CPU-Seitig"?
Versteh mich nicht falsch. Mit einem Desktop Carrizo wäre sicherlich CPU- und GPU-seitig ein Update möglich wie von Richland auf Kaveri, eventuell sogar etwas mehr. Nur, inwiefern lohnt sich das denn noch, wenn man eben auch eine Zen APU vielleicht Mitte 2016 am Start haben könnte? Klar, wenn man davon ausgeht, dass so eine APU erst 2017 kommt, dann könnte man zumindest mit Carrizo noch 2016 überbrücken. Aber ich gehe davon aus, dass man Zen früher launchen will.
Ich fragte ja auch nur nach der CPU. Viel weiss man über die konkreten Verbesserungen noch nicht. Das ist richtig. Aber AMD hat zumindest 5% mehr IPC genannt. Und was völlig anderes ist sicherlich auch nicht zu erwarten. Ob es am Ende bei einem Benchmarkparcours 3% und bei einem anderen Benchmarkparcours 7% sind, geschenkt. Mal davon abgesehen, hat Carrizo eigentlich einen DDR4 Controller? Hab das gerade nicht auf dem Schirm. Carrizo besitzt ja Delta Color Compression. Da sollte auch mit DDR3 die GPU schon einiges zulegen. Mit HBM und mehr Shadern wäre trotzdem nochmal ein ganz anderer Leistungssprung möglich.IPC? Na da werden die doppelten L1-Caches schon gut nachlegen, wer weiss, vielleicht hat AMD auch die interen Puffer vergrößert, viel ist ja noch nicht bekannt und bei einer Desktop-Version reden wir bekanntlich über eine mit DDR4, das legt schön GPU-Leistung nach.
Also das kann und darf nun wirklich keine Ausrede sein. Man hatte lange genug Zeit. FM2(+) ist jetzt wie alt? 3 Jahre? AM3(+) ist noch deutlich älter. Da wird man wohl in der Lage sein, endlich eine neue Desktopplattform zu bringen. So oder so, das müsste man auch bei deinem DDR4 Carrizo.Jo richtig, aber das ist der gleiche Punkt wie beim letzten Posting, es geht nicht darum, was AMD "bräuchte", oder was wegging wie warme Semmeln, sondern darum was AMD imstande ist zu leisten.
Gleichzeitig mit den ganzen Chips kommt auch ne neue DDR4-Plattform, die muss man auch erst wieder debuggen, alles gleichzeitig zu bringen wäre Selbstmord.
Eine Zen APU Q2/3 und eine Zen CPU ein Quartal später würde auch Sinn machen. Von mir aus auch umgekehrt. Machbar ist das. Und bis dahin muss halt der Kaveri Refresh noch durchhalten.Der logische Schritt ist ein früher Start des neuen DDR4-Sockels mit dem besten & bewährten Chip und das wäre im aktuellen Fall eben ein Carrizo-Derivat. Also FM3-Plattformstart im 1H/16 und dafür die ZEN-CPU im 2H/16, Upgrade durch ne ZEN-APU in 1H/17. So macht es Sinn und so melden es auch die Schweden.
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Es ist natürlich optimistisch, 2016 drei bis vier Prozessoren (Summit Ridge (8-Kern Zen), Bristol Ridge (4-Kern Zen APU), Basilisk (2-Kern Zen APU, eventuell gleiches Die wie Bristol Ridge und Styx (ARM))) launchen zu wollen, aber man weiß ja eben nicht wirklich, was neben Kaveri und Nachfolger schon entwickelt wurde. Fakt ist eben auch, dass (grob) in den letzten beiden Jahren nur Kaveri und Carizzo gelauncht wurden(/werden) (sagen wir mal aus Sicht Ende 2015), womit man schon Entwicklungskapazitäten für anderes vermuten kann.Ne Zen-APU 2016 wäre schön, aber ich glaub nicht dran. Dazu hatte AMD in letzter Zeit erstens schon genügend Probleme (z.B. bei Kaveri und damals wurde keine CPU parallel entwickelt), [...]
Kämen CPU und APU gleichzeitig, geht man das hohe Risiko ein gleich zwei Schrottchips samt Schrottmasken zu haben.
Und um wieder einen Blick in die Vergangenheit zu wagen: Trinity (Q3 2012), Vishera (Q4 2012) und Kabini (Q3 2013) waren ebenfalls in einem Zeitfenster von nur grob einem Jahr. Aber klar, hier hatte man es jeweils "nur" mit überarbeiteten Architekturen zu tun und nur beim kleinen Kabini mit einem neuen Prozess, dafür aber bei Kabini erstmals GCN bei den APUs.
Nochmals: Es ist natürlich optimistisch, aber Zen-APU und CPU müssen ja nicht "gleichzeitig" kommen. Einer der beiden kann vermutlich schon 6 Monate Vorsprung haben, womit sich das mit den "Schrott-Masken" schon etwas einschränkt.
Wenn man jetzt als Realist sagen will, dass man davon ausgeht, dass sich einer der drei Chips (Summit, Bristol, Styx) ins Jahr 2017 hinein "verspätet", gehe ich damit schon konform, das macht aber deshalb die Roadmap nicht sonderlich unglaubwürdig ("Fake").
LG
Zuletzt bearbeitet:
In den Comments meinte dann einer, wenn schon 14nmFF, dann LPP und Josh gibt ihm Recht ...
Das war ich. Es macht keinen Sinn, dass LPE geeigneter sein soll.
G
Gast31082015
Guest
Wenn denn im September wirklich schon FM3 kommt, wäre das ausnahmsweise ja mal wieder ein Sockel mit echtem Aufrüstpotenzial von 2-8 Kernen.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ob unser Insider wohl schon kaltgestellt wurde, oder haben wir ihn nur vergrault?
Hübie
Grand Admiral Special
- Mitglied seit
- 25.06.2002
- Beiträge
- 3.037
- Renomée
- 83
- Mein Laptop
- Honor MagicBook Pro AMD Mystic Silver
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5800X3D @Wakü
- Mainboard
- ASUS ROG Strix B550-E Gaming
- Kühlung
- Mora3 @9*eLoops
- Speicher
- G.Skill Trident Z RGB 32GB DDR4-3600
- Grafikprozessor
- AMD Radeon RX 6800 XT @Wakü
- Display
- LC-M34-UWQHD-144-C (UWQHD)
- SSD
- Corsair 600p 1TB (System), Crucial MX500 2TB (Spiele), Crucial 2TB (Daten)
- Soundkarte
- Logitech G735
- Gehäuse
- be quiet! Dark Base Pro 900
- Netzteil
- be quiet! Dark Power 13 850W ATX 3.0
- Tastatur
- Logitech G915 TKL weiß
- Maus
- Logitech G Pro X weiß
- Betriebssystem
- Windows 11 x64 Professional + Updates
- Webbrowser
- Vivaldi
- Schau Dir das System auf sysprofile.de an
- Internetanbindung
- ▼70 MBit/s ▲50 MBit/s
wenn ich etwas mehr Zeit hab such ich die passenden Links raus wo's sehen kannst - Intel Kisten haben mehr Pagefaults (Seitenfehler) als AMD Kisten - kannste auch selbst testen: gugg mal im Taskermanager von Windows wie viele Seitenfehler du bei nem Intel-DDR3-System findest und wie viele bei AMD!
Also ein Seitenfehler tritt eigentlich nur auf wenn ein Programm auf einen Speicherbereich zugreift der nicht physisch im DRAM gespeichert ist. Ist also eher Softwaresache. Ich habe hier keinen AMD zum Vergleich, aber mein System produziert nur bei einigen Programmen permanent Seitenfehler. Kann an schlampiger Programmierung liegen (z. B. Steelseries-Software hat schon nach wenigen Minuten ~2 Mio Pagefaults) oder einfach an Windows' MMU die es nicht hinbekommt 16 GB auszunutzen bevor swapping statt findet.
Mich interessiert jetzt wirklich dein Link. Vielleicht reden wir gerade von zwei verschiedenen Dingen.
Ich hoffe ja das die APU`s auch HBM bekommen.
Denn im Gegensatz zu Opteron bin ich der Meinung, dass diese Bandbreite der GPU schon deutlich Beine macht. Und wenn ich es richtig verstanden habe, der Interposer ist doch schneller als die klassische Anbindung an den Arbeitsspeicher...
Boar.. jetzt soll AMD erst mal die 390 bringen - denn dann wissen wir mehr. Die 390x (oder 395 x2) soll ja ein Dual-GPU Brett werden mit Interposer... Dann wissen wir ja (mehr) was diese Verbindung im Stande ist zu leisten...
Denn im Gegensatz zu Opteron bin ich der Meinung, dass diese Bandbreite der GPU schon deutlich Beine macht. Und wenn ich es richtig verstanden habe, der Interposer ist doch schneller als die klassische Anbindung an den Arbeitsspeicher...
Boar.. jetzt soll AMD erst mal die 390 bringen - denn dann wissen wir mehr. Die 390x (oder 395 x2) soll ja ein Dual-GPU Brett werden mit Interposer... Dann wissen wir ja (mehr) was diese Verbindung im Stande ist zu leisten...
Seit wann hat Trinity GCN? Bei Trinity und Richland ist TeraScale 3 (VLIW4) verbaut.... bei Trinity erstmals GCN bei den APUs. ...
OT:
Was ist eigentlich mit Berlin?
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Nach den Roadmaps Leaks bezweifle ich mittlerweile, dass SMT verbaut wird.
Wenn die Kerne auf gute IPC ausgelegt sind und mit Intels Skylake Kernen mithalten kann, dürften Zen 4 Kerner gut mit den i5 konkurrieren.
Bei den 8 Kernern haben wir dann echte acht Kerne die den i7 die Rücklichter zeigen könnten.
Die Interposer Idee gefällt mir auch gut. Ein I/O Chip an den per Interconnect 2 Chips angebunden werden können: entweder 2 X 4 Kern ZEN oder 4 Kern ZEN + GPU.
Wieviel teurer wird eigentlich HBM im vergleich zu "normalem RAM" mit mehrlagigem Mainboard und Steckplätzen?
Für die 4 Kern APUs im normalem Desktop wären ja 8 GB fast überdimensioniert, für Office Laptops reichen doch eigentlich 4GB.
Vom Aufwand her, würde ein OEM doch lieber eine APU mit 4/8GB HBM verbauen. Am besten noch 128GB SSD mit auf den Interposer, spart die Wartungsklappe. Für günstige Systeme wär das doch optimal. Das HBM noch einen Geschwindigkeitsschub bringt ist ein Nebeneffekt und nicht das Hauptargument.
Wenn die Kerne auf gute IPC ausgelegt sind und mit Intels Skylake Kernen mithalten kann, dürften Zen 4 Kerner gut mit den i5 konkurrieren.
Bei den 8 Kernern haben wir dann echte acht Kerne die den i7 die Rücklichter zeigen könnten.
Die Interposer Idee gefällt mir auch gut. Ein I/O Chip an den per Interconnect 2 Chips angebunden werden können: entweder 2 X 4 Kern ZEN oder 4 Kern ZEN + GPU.
Wieviel teurer wird eigentlich HBM im vergleich zu "normalem RAM" mit mehrlagigem Mainboard und Steckplätzen?
Für die 4 Kern APUs im normalem Desktop wären ja 8 GB fast überdimensioniert, für Office Laptops reichen doch eigentlich 4GB.
Vom Aufwand her, würde ein OEM doch lieber eine APU mit 4/8GB HBM verbauen. Am besten noch 128GB SSD mit auf den Interposer, spart die Wartungsklappe. Für günstige Systeme wär das doch optimal. Das HBM noch einen Geschwindigkeitsschub bringt ist ein Nebeneffekt und nicht das Hauptargument.
insider2015
Cadet
- Mitglied seit
- 27.04.2015
- Beiträge
- 10
- Renomée
- 2
I won't post any more slides, wait for FAD
Hübie
Grand Admiral Special
- Mitglied seit
- 25.06.2002
- Beiträge
- 3.037
- Renomée
- 83
- Mein Laptop
- Honor MagicBook Pro AMD Mystic Silver
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5800X3D @Wakü
- Mainboard
- ASUS ROG Strix B550-E Gaming
- Kühlung
- Mora3 @9*eLoops
- Speicher
- G.Skill Trident Z RGB 32GB DDR4-3600
- Grafikprozessor
- AMD Radeon RX 6800 XT @Wakü
- Display
- LC-M34-UWQHD-144-C (UWQHD)
- SSD
- Corsair 600p 1TB (System), Crucial MX500 2TB (Spiele), Crucial 2TB (Daten)
- Soundkarte
- Logitech G735
- Gehäuse
- be quiet! Dark Base Pro 900
- Netzteil
- be quiet! Dark Power 13 850W ATX 3.0
- Tastatur
- Logitech G915 TKL weiß
- Maus
- Logitech G Pro X weiß
- Betriebssystem
- Windows 11 x64 Professional + Updates
- Webbrowser
- Vivaldi
- Schau Dir das System auf sysprofile.de an
- Internetanbindung
- ▼70 MBit/s ▲50 MBit/s
HBM Preise sind noch sehr inoffiziell und exklusiv als dass man diese direkt vergleichen könnte. 1 GBit DDR3-1333 DRAM kostet etwa 0,80-1,00€ nackt. Dazu kommen Menge, PCB, kleine Bauteile und Shipping / taxes. Bei HBM gehe ich nach Schätzungen von 10-15€ aus. Problem ist dass man überhaupt nicht weiß wie die "known good tsv rate" oder known good yieldrate der Interposer ist. Kann mich also auch stark täuschen und es tendiert in Wahrheit schon an die 20-Dollar-Marke
Edit: Damit meine ich jeweils einen Stack a 1 GB.
Edit: Damit meine ich jeweils einen Stack a 1 GB.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Gab es eigentlich mal eine Erklärung was genau mit "Interposer" gemeint ist?
Hier ein recht einfaches Schema:
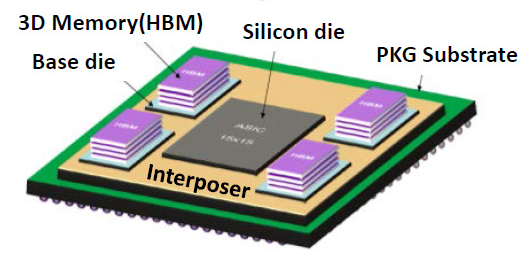
Dadurch das der GMI Bus viel kürzere Wege hat, als über North- und South-Bridge, sollten doch auch die Latenzen wesentlich geringer sein.
Wenn dann die CPU noch auf den HBM Speicher Zugreifen darf (Sony Playstation 4) sollte da ordentlich was bei rum kommen.

Hier ein recht einfaches Schema:
Dadurch das der GMI Bus viel kürzere Wege hat, als über North- und South-Bridge, sollten doch auch die Latenzen wesentlich geringer sein.
Wenn dann die CPU noch auf den HBM Speicher Zugreifen darf (Sony Playstation 4) sollte da ordentlich was bei rum kommen.
Ähnliche Themen
- Antworten
- 92
- Aufrufe
- 8K
- Antworten
- 14
- Aufrufe
- 935
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 3
- Aufrufe
- 2K