App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Bulldozer rollt an....
- Ersteller neax
- Erstellt am
- Status
- Für weitere Antworten geschlossen.
Shadowtrooper
Grand Admiral Special
- Mitglied seit
- 02.02.2009
- Beiträge
- 2.476
- Renomée
- 35
- Standort
- Krefeld
- Mein Laptop
- Lenovo ThinkPad E130 (i3 3217U)
- Details zu meinem Desktop
- Prozessor
- AMD Phenom II X4 955BE @3,6 GHz 1,375V
- Mainboard
- Gigabyte MA770T UD3P
- Kühlung
- EKL Groß Clockner
- Speicher
- 4*2GB DDR3 1333
- Grafikprozessor
- Gigabyte GTX 750 Ti Windforce OC
- Display
- HP Pavilion 22 Xi
- SSD
- 240GB Kingston HyperX
- HDD
- 3 TB Seagate 7200.14
- Optisches Laufwerk
- LG DVD Brenner
- Soundkarte
- Xonar DX+ AKG K 242 HD
- Gehäuse
- CM 690
- Netzteil
- Seasonic G-360
- Betriebssystem
- Win 7 Prof. 64Bit Sp1
- Webbrowser
- Chrome
Nö die werte sind schon richtig aber sie sagen nicht viel aus weil es noch zu viele Faktoren gibt die den vergleich zerstören:
-Betriebssystem (32bit Linux / 64Bit Windows)
-Seti Version
-evtl verbuggtes Bulldozer ES ( Jan 2011)
-Unbekannte Taktfrequenz auf beiden seiten
von daher bringt ein vergleich nicht viel. Jedenfalls hab ich mir noch ein paar andere Rechner mit dem selben WU Typ rausgesucht und die 34.000sec vom "Bulldozer" für diese WU sind ziemlich mies (die 23.000 für den C2D sehr durchschnittlich) muss aber aus oben genannten gründen noch nix heißen.
Alles was wir wissen ist das dieser eine Bulldozer der bei Seti rechnet und möglicherweise noch ein Fehlerbehaftetes Stepping hat eine ziemliche Krücke ist.
-Betriebssystem (32bit Linux / 64Bit Windows)
-Seti Version
-evtl verbuggtes Bulldozer ES ( Jan 2011)
-Unbekannte Taktfrequenz auf beiden seiten
von daher bringt ein vergleich nicht viel. Jedenfalls hab ich mir noch ein paar andere Rechner mit dem selben WU Typ rausgesucht und die 34.000sec vom "Bulldozer" für diese WU sind ziemlich mies (die 23.000 für den C2D sehr durchschnittlich) muss aber aus oben genannten gründen noch nix heißen.
Alles was wir wissen ist das dieser eine Bulldozer der bei Seti rechnet und möglicherweise noch ein Fehlerbehaftetes Stepping hat eine ziemliche Krücke ist.
Zuletzt bearbeitet:
firecracker1
Captain Special
- Mitglied seit
- 29.12.2007
- Beiträge
- 240
- Renomée
- 4
- Standort
- HH
- Details zu meinem Desktop
- Prozessor
- e8400@ 3600MhZ
- Mainboard
- Asus P5Q SE
- Kühlung
- ka
- Speicher
- 2x2GB Adata DDR2
- Grafikprozessor
- HD 6950 IceQ
- Display
- Samsung Syncm. XL2370 LED
- HDD
- 1x300GB Hitachi Deskstar1x 1TB externe
- Optisches Laufwerk
- Plextor DVD Brenner, LiteOn DVD Leselaufw.
- Soundkarte
- Audigy 4
- Gehäuse
- Sharkoon t9 Value red
- Netzteil
- Enermax 82+ 425Watt
- Betriebssystem
- Win 7 64 Bit
- Webbrowser
- Firefox
also was die leistung an geht sollte man nicht zuviel erwarten. das aktuell genannte "topmodel"l soll grad mal 320 dollar kosten also rund 230 euro und ich spekuliere mal, dass die leistung etwa dem i7 3,4ghz entsprechen wird.
allerdings wirbt amd ja damit, dass sie gut zu übertakten sind und ich denke mal übertaktet wird es preis/leistungstechnisch ganz schick und überbrücken gut die zeit, bis zum neuen sockel und der nächsten bulldozer generation wo es dann erst richtig los geht
spekulation!
allerdings wirbt amd ja damit, dass sie gut zu übertakten sind und ich denke mal übertaktet wird es preis/leistungstechnisch ganz schick und überbrücken gut die zeit, bis zum neuen sockel und der nächsten bulldozer generation wo es dann erst richtig los geht
spekulation!
Markus Everson
Grand Admiral Special
Nö die werte sind schon richtig aber sie sagen nicht viel aus weil es noch zu viele Faktoren gibt die den vergleich zerstören:
-Betriebssystem (32bit Linux / 64Bit Windows)
-Seti Version
-evtl verbuggtes Bulldozer ES ( Jan 2011)
-Unbekannte Taktfrequenz auf beiden seiten
Opteron 6274 ist OS6274WKTGGGU und hat 2,2 GHz
Laut Semiaccurate hat Orochi 315qmm
Zuletzt bearbeitet:
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.033
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
Mal angenommen, das stimmt, was lesen wir dann daraus?Laut Semiaccurate hat Orochi 315qmm
Barcelona war immerhin ein gutes Stück kleiner und schon zu groß, allerdings auf dem eh etwas unglücklichen 65nm-Prozeß, d.h. man kann nicht unbedingt nur aus der Diegröße automatisch Probleme mit der Taktskalierung folgern.
Andererseits baut AMD ja auch nicht einfach große Dies aus Spaß, d.h. alles was da drauf ist, hat auch seinen Sinn. Und meist heißt es ja "viel hilft viel".
Dritte Möglichkeit: Man sieht auf den Foto ja viele rosa Flächen zwischen den funktionalen Blöcken. Wenn das absichtlicher Leerraum ist, der für die Stromabschaltung benötigt wird, dann könnte man sich zwar fragen, ob so viel Flächenverbrauch wirklich nötig gewesen wäre (gerade in der Mitte ist so viel "leer", daß man auch gleich 12 oder 16 statt 8 MB L3 hätte hinballern können), andererseits wäre die Fläche aber neutral bzgl. Ausbeute und Wärmeentwicklung, d.h. die CPU verhielte sich im Grunde wie eine mit einer Fläche von 315 minus rosa.
Und schließlich bleibt auch die Möglichkeit, daß die 315 mm² schlicht eine Fehlinformation sind.

Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Letzte Woche war Hotchips23, vermutlich stammt die Folie davon.Und schließlich bleibt auch die Möglichkeit, daß die 315 mm² schlicht eine Fehlinformation sind.
Wobei er das dannaber auch hätte hinschreiben können
.
EDIT :
.
Ah hier gibts die hotchips Folien:
http://www.technic3d.com/news/hardw...lldozer-archtitektur-auf-der-hot-chips-23.htm
Keine mit der DIE Size Folie, aber anhand der Seitenzahlen sieht man, dass da Einiges fehlt.
Edit2:
Charlie meint hier, dass die DIE Folie offiziell wäre:
http://semiaccurate.com/forums/showpost.php?p=130189&postcount=261
Sollte also wirklich von hotchips23 stammen.
Ansonsten bisher nicht viel Neues.
Zuletzt bearbeitet:
Letzte Woche war Hotchips23, vermutlich stammt die Folie davon.
...
Ah hier gibts die hotchips Folien:
http://www.technic3d.com/news/hardw...lldozer-archtitektur-auf-der-hot-chips-23.htm
Keine mit der DIE Size Folie, aber anhand der Seitenzahlen sieht man, dass da Einiges fehlt.
Edit2:
Charlie meint hier, dass die DIE Folie offiziell wäre:
http://semiaccurate.com/forums/showpost.php?p=130189&postcount=261
Sollte also wirklich von hotchips23 stammen.
Ansonsten bisher nicht viel Neues.
Guckst Du auch hier!
Ja, richtig nicht viel Neues...
")
Markus Everson
Grand Admiral Special
Letzte Woche war Hotchips23, vermutlich stammt die Folie davon.
Wobei er das dannaber auch hätte hinschreiben können
.
EDIT :
.
Ah hier gibts die hotchips Folien:
http://www.technic3d.com/news/hardw...lldozer-archtitektur-auf-der-hot-chips-23.htm
Aus Folie 17 spekuliere ich auf 0,7V-1,4V und 5,5 GHz angepeilte Taktfrequenz
")
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Aus Folie 17 spekuliere ich auf 0,7V-1,4V und 5,5 GHz angepeilte Taktfrequenz
Sind das die Achsenbereiche? Wenn man sich die Fläche der Kurven anschaut, dann ist das max. im Bereich von 1,3V und ~4,4Ghz. Die Querlinien sollten im 400MHz Abstand kommen, wenn man davon ausgeht, dass der Anfang der Kennlinien bei 800Mhz liegt.
Aber viel Raum für Spekulation

Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Wenn man sich die Featureliste so anschaut, kann es eigentlich nie und nimmer sein dass BD einen Rückschritt bei der IPC gegenüber K10 macht, wie hier schon mehrfach spekuliert wurde.
Im Singlethread-Fall stehen 4 Decoder zur Verfügung um einen Int-Core zu füttern, dazu dann neue Branch Prediction, prefetcher, Branch Fusion...
Dann die OoO Loads und Stores, welche schon Core2 ordentlich dampf gemacht haben im blauen Lager...
Da ist auch der Verlust der einen ALU, die bei K10 sowieso zwei drittel Däumchen dreht, durchaus zu verschmerzen...
Da BDs Pipeline länger ist, als die von K10, müssten Threadwechsel BD mehr "wehtun" als K10, weil ersterer eben eine Hand voll Takte länger braucht bis die Pipeline wieder gefüllt ist, aber dafür stehen auch mehr kerne zur Verfügung um die Threads zu verteilen und der ganze Aufwand im Frontend muss ja auch für irgendwas gut sein...
Sogesehen können wir die ganzen bisherigen Benchmarks mal komplett in die Tonne treten....
AMD täte aber wirklich gut daran nun mal langsam konkreter zu werden was man zu erwarten hat, immerhin läuft die Zeit langsam davon... Und bei aller paranoja, reissen ein paar Wochen hin oder her auch nichts mehr raus in denen Intel einen Konter bringen könnte (wenn sie das mit SB schaffen, können sie es sowieso ab stichtag, und wenn sie Ivy Bridge dafür brauchen, ändert sich daran auch nichts wenn AMD 4 wochen vor Launch ein paar genauere Infos rausgibt...)
Also los AMD... fangt mal endlich an den Prinzen zu krönen, bevor es kein Königreich mehr für ihn gibt...
Im Singlethread-Fall stehen 4 Decoder zur Verfügung um einen Int-Core zu füttern, dazu dann neue Branch Prediction, prefetcher, Branch Fusion...
Dann die OoO Loads und Stores, welche schon Core2 ordentlich dampf gemacht haben im blauen Lager...
Da ist auch der Verlust der einen ALU, die bei K10 sowieso zwei drittel Däumchen dreht, durchaus zu verschmerzen...
Da BDs Pipeline länger ist, als die von K10, müssten Threadwechsel BD mehr "wehtun" als K10, weil ersterer eben eine Hand voll Takte länger braucht bis die Pipeline wieder gefüllt ist, aber dafür stehen auch mehr kerne zur Verfügung um die Threads zu verteilen und der ganze Aufwand im Frontend muss ja auch für irgendwas gut sein...
Sogesehen können wir die ganzen bisherigen Benchmarks mal komplett in die Tonne treten....
AMD täte aber wirklich gut daran nun mal langsam konkreter zu werden was man zu erwarten hat, immerhin läuft die Zeit langsam davon... Und bei aller paranoja, reissen ein paar Wochen hin oder her auch nichts mehr raus in denen Intel einen Konter bringen könnte (wenn sie das mit SB schaffen, können sie es sowieso ab stichtag, und wenn sie Ivy Bridge dafür brauchen, ändert sich daran auch nichts wenn AMD 4 wochen vor Launch ein paar genauere Infos rausgibt...)
Also los AMD... fangt mal endlich an den Prinzen zu krönen, bevor es kein Königreich mehr für ihn gibt...
Markus Everson
Grand Admiral Special
Wenn man sich die Featureliste so anschaut, kann es eigentlich nie und nimmer sein dass [...]
DejaVue? Haben wir das gleiche nicht auch schon beim Phenom I gelesen?
Womit ich nicht sagen will das Deine Hoffnung bayrisch wäre, sondern das die Featureliste eher ungeeignet ist um sowas zu beurteilen.
deadohiosky
Gesperrt
- Mitglied seit
- 13.07.2011
- Beiträge
- 1.624
- Renomée
- 26
Ich muss mich im Voraus dafür entschuldigen, dass ich etwas zu OBR poste:
PC Tuning CZ (also höchstwahrscheinlich u.a. OBR) hat auf Yt ein Video gepostet bei dem sie einen BD ES auf 6,4- 6,5 GHz übertaktet haben (natürlich mit F-Stickstoff)
http://www.xtremesystems.org/forums...-info-fans-!&p=4933064&viewfull=1#post4933064
Sollte die Bezeichnung des ES stimmen und die Aufschlüsselung die vor ein paar Monaten "geleakt" wurde, dann hat der Typ weiterhin nur ein B0 Sample, bzw. für diesen Test wurde nur ein B0 Sample verwandt.
PC Tuning CZ (also höchstwahrscheinlich u.a. OBR) hat auf Yt ein Video gepostet bei dem sie einen BD ES auf 6,4- 6,5 GHz übertaktet haben (natürlich mit F-Stickstoff)
http://www.xtremesystems.org/forums...-info-fans-!&p=4933064&viewfull=1#post4933064
Sollte die Bezeichnung des ES stimmen und die Aufschlüsselung die vor ein paar Monaten "geleakt" wurde, dann hat der Typ weiterhin nur ein B0 Sample, bzw. für diesen Test wurde nur ein B0 Sample verwandt.
Markus Everson
Grand Admiral Special
Ist die Eiterbeule also inzwischen von Photoshop auf Videonachbearbeitung umgestiegen...
Immer dran denken: Wer einmal faked, dem glaubt man nicht.
Immer dran denken: Wer einmal faked, dem glaubt man nicht.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
DejaVue? Haben wir das gleiche nicht auch schon beim Phenom I gelesen?
Womit ich nicht sagen will das Deine Hoffnung bayrisch wäre, sondern das die Featureliste eher ungeeignet ist um sowas zu beurteilen.
Damals hab ich hier nicht mitgelesen, das kann ich dir also nicht sagen.
Ich sage nur, dass OoO Loads/Stores, auch bekannt als "Memory Disambiguation" eines der Features war das dem Core 2 mächtig Beine gemacht hat und für um die 20% Performance gut sein soll.
Es ist ja nicht so als würde das Rad neu erfunden, sndern die Technologien sind bereits da, nur hat AMD sie noch nicht verbaut. Und wohlgemerkt, wir reden hier über ein Attribut der Mikroarchitektur als solcher, keinen Spielchen wie "erster nativer Quad-Core"...
Dass der K10 am lahmen Frontend verhungert ist kein Geheimnis. Und dass er in Sachen moderne Features der blauen konkurrenz inzwischne mächtig hinterher hinkt auch nicht. Deswegen seh ich es optimistisch dass man genau dort den Hebel angesetzt hat und die Schwachstellen ausgemerzt.
Und auch der K10 war/ist pro Takt schneller als ein K8...
Ich bin nur allergisch dagegen dass hier mehrfach aufgrund von völlig nichtssagenden "Benchmarks" und Aberglauben (2-ALUs) hinspekuliert wird dass BD pro takt sogar eienm K10 unterlegen wäre...
So dumm ist AMD nicht... sorry... aber da BD keine merkbar höheren Takte zu erzielen scheint als K10, wäre eine geringere IPC nichts anderes als sein Todesurteil. Mit sowas bräuchten sie sich garnicht erst am Markt blicken lassen...
Das ist alles was ich damit sagen wollte...
deadohiosky
Gesperrt
- Mitglied seit
- 13.07.2011
- Beiträge
- 1.624
- Renomée
- 26
@ME
Das ist ein screenshot aus dem Video, ich denke nicht dass da etwas im Video bearbeitet wurde. Möglich ist zwar alles aber so viel Kompetenz traue ich dem(/n) Typ(/en) nicht zu.
Das ist ein screenshot aus dem Video, ich denke nicht dass da etwas im Video bearbeitet wurde. Möglich ist zwar alles aber so viel Kompetenz traue ich dem(/n) Typ(/en) nicht zu.
Shadowtrooper
Grand Admiral Special
- Mitglied seit
- 02.02.2009
- Beiträge
- 2.476
- Renomée
- 35
- Standort
- Krefeld
- Mein Laptop
- Lenovo ThinkPad E130 (i3 3217U)
- Details zu meinem Desktop
- Prozessor
- AMD Phenom II X4 955BE @3,6 GHz 1,375V
- Mainboard
- Gigabyte MA770T UD3P
- Kühlung
- EKL Groß Clockner
- Speicher
- 4*2GB DDR3 1333
- Grafikprozessor
- Gigabyte GTX 750 Ti Windforce OC
- Display
- HP Pavilion 22 Xi
- SSD
- 240GB Kingston HyperX
- HDD
- 3 TB Seagate 7200.14
- Optisches Laufwerk
- LG DVD Brenner
- Soundkarte
- Xonar DX+ AKG K 242 HD
- Gehäuse
- CM 690
- Netzteil
- Seasonic G-360
- Betriebssystem
- Win 7 Prof. 64Bit Sp1
- Webbrowser
- Chrome
Das video zeigt ja auch nix warum sollte man das auch noch fälschen / bearbeiten? Er hat nen wahrscheinlich halb kaputtes B0 ES mit LN2 und 2,05V auf 30,5*210 Übertaktet und es verkraftet Last auf einem Kern... wie schnelle das teil dabei ist weiß man ja nicht mal und den takt konnte man unter diesen Bedingungen mit Phenom II auch schon gut erreichen.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Man sieht ja auch bei Bobcat, dass der bei Integer Workloads recht flott unterwegs ist (etwa K8 Niveau bei gleichem Takt), trotz lediglich 2 ALUs. Die zusätzliche Logik der Bulldozer Architektur im Vergleich zu Bobcat müsste also weniger bringen als seinerzeit K10 gegenüber K8, damit es einen Rückschritt bei der IPC gibt. Das erscheint mir einfach nicht realistisch zu sein.Wenn man sich die Featureliste so anschaut, kann es eigentlich nie und nimmer sein dass BD einen Rückschritt bei der IPC gegenüber K10 macht, wie hier schon mehrfach spekuliert wurde.
Im Singlethread-Fall stehen 4 Decoder zur Verfügung um einen Int-Core zu füttern, dazu dann neue Branch Prediction, prefetcher, Branch Fusion...
Dann die OoO Loads und Stores, welche schon Core2 ordentlich dampf gemacht haben im blauen Lager...
Da ist auch der Verlust der einen ALU, die bei K10 sowieso zwei drittel Däumchen dreht, durchaus zu verschmerzen...
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Guter Punkt.Man sieht ja auch bei Bobcat, dass der bei Integer Workloads recht flott unterwegs ist (etwa K8 Niveau bei gleichem Takt), trotz lediglich 2 ALUs. Die zusätzliche Logik der Bulldozer Architektur im Vergleich zu Bobcat müsste also weniger bringen als seinerzeit K10 gegenüber K8, damit es einen Rückschritt bei der IPC gibt. Das erscheint mir einfach nicht realistisch zu sein.
Würde auch noch bestätigen was schon mehrfach kommuniziert wurde, nämlich dass die praktisch erreichbare IPC die der ILP des codes hergibt, sowieso äußerst selten mehr als 2 ist, meistens sogar grade mal um 1,5.
Und solange es nicht mehr als 1,5 Befehle pro Takt gibt die unabhängig vo neinadner ausführbar sind, nutzt eine 3. ALU genau nichts. Deswegen lohnt sich HTT ja bei Intel... weil immer mindestens 1 ALU von den 3en Däumchen dreht und inzwischen einen anderen Thread bearbeiten kann....
Bobcat ist ein schönes Beispiel, weil er auch ein modernes Design ist, ohne viele K7/K8 Altlasten, aber mit physischem Registerfile und dergleichen Spielchen.
AMD ist also nicht zu dumm einen modernen, effizienten Out-Of-Order Core zu bauen... Sie haben es nur die letzten Jahre im Highend nicht getan weil sich eben alles auf BD konzentrierte.
Nebenbei, gibts eigentlich verlässliche Daten zum Transistorcount eines Bobcat im Vergleich zum K8? - beide haben eine 64Bit FPU, K8 hat ein ALU/AGU-Pärchen mehr... erreicht aber in der Praxis nicht so deutlich mehr Leistung....
Wäre mal interessant das gegenüber zu stellen.. .also um wie viel "intelligenter" ein Bobcat gebaut ist im verglich zum K8, um etwa die selbe Leistung zu erreichen...
(mit ggf. entsprechend weniger Transistoroverhead oder anderer Verteilung...)
Unter Umständen könnte man dort dann sehen dass und wieviel es am Ende mehr einbringt, in das Frontend zu investieren als in die rohe Anzahl an ALUs...
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
1,5 IPC ist sogar noch recht hoch gegriffen. Beim C2D lag man bei SPEC CPU2006 im Schnitt bei ~1.
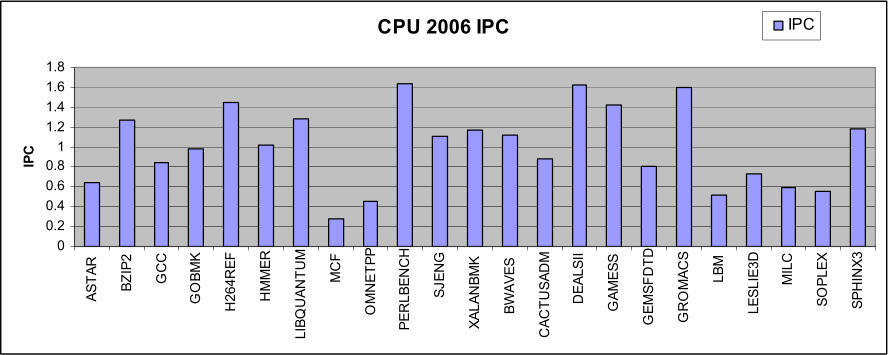
Seitdem sind sicherlich noch einige Prozent durch Nehalem und Sandy Bridge hinzugekommen. Interessant wird es, wenn man sich das Instruktionsprofil dazu anschaut.

Das meiste davon sind also Loads, Stores und Sprünge. Da 3 ALUs mit einem Thread voll auszulasten, ist in praxisnahen Anwendungen kaum möglich.

Seitdem sind sicherlich noch einige Prozent durch Nehalem und Sandy Bridge hinzugekommen. Interessant wird es, wenn man sich das Instruktionsprofil dazu anschaut.

Das meiste davon sind also Loads, Stores und Sprünge. Da 3 ALUs mit einem Thread voll auszulasten, ist in praxisnahen Anwendungen kaum möglich.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Und man liegt nicht ein einziges mal über 2, was bedeutet, die abwesenheit der des 3. ALU/AGU-Paares gegenüber K10, sollte einen int-core quasi garnicht bremsen.
Die wenigen Fälle wo das hier über 1,5 geht sind vernachlässigbar, zumal wie es hier mit Benchmarks zu tun haben. Realworld dürfte das Verhältnis noch mehr in Richtung Loads/Stores gehen, wenn man mal von Spezialfällen absieht. Deswegen ist Prefetching, Branch Prediction und große Caches ja auch so wichtig...
Die wenigen Fälle wo das hier über 1,5 geht sind vernachlässigbar, zumal wie es hier mit Benchmarks zu tun haben. Realworld dürfte das Verhältnis noch mehr in Richtung Loads/Stores gehen, wenn man mal von Spezialfällen absieht. Deswegen ist Prefetching, Branch Prediction und große Caches ja auch so wichtig...
mocad_tom
Admiral Special
- Mitglied seit
- 17.06.2004
- Beiträge
- 1.234
- Renomée
- 52
Was soll bitte diese Milchmädchen-Rechnung?Und man liegt nicht ein einziges mal über 2, was bedeutet, die abwesenheit der des 3. ALU/AGU-Paares gegenüber K10, sollte einen int-core quasi garnicht bremsen.
Die wenigen Fälle wo das hier über 1,5 geht sind vernachlässigbar, zumal wie es hier mit Benchmarks zu tun haben. Realworld dürfte das Verhältnis noch mehr in Richtung Loads/Stores gehen, wenn man mal von Spezialfällen absieht. Deswegen ist Prefetching, Branch Prediction und große Caches ja auch so wichtig...
Nur weil man !!!IM SCHNITT!!! nie über zwei liegt heisst das nicht, das 3 Issue Wide oder 4 Issue Wide für die Katze ist.
Sagen wir mal in 3% der Zeit kann man 4 Issue Wide voll auslasten und 10% der Zeit kann man 3 Issue Wide voll auslasten, dann arbeitet man in der Zeit deutlich schneller als wenn man nur ein 2 Issue Wide-Design zur Verfügung hat. Man muss ja über den Lauf hinweg kucken, was alles gemacht werden muss. Und wenn man dann im Mittel bei 1,8 liegt gibt es nunmal Phasen, wo man einen, zwei, drei, vier Issues auslasten kann.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Was soll bitte diese Milchmädchen-Rechnung?
Nur weil man !!!IM SCHNITT!!! nie über zwei liegt heisst das nicht, das 3 Issue Wide oder 4 Issue Wide für die Katze ist.
Sagen wir mal in 3% der Zeit kann man 4 Issue Wide voll auslasten und 10% der Zeit kann man 3 Issue Wide voll auslasten, dann arbeitet man in der Zeit deutlich schneller als wenn man nur ein 2 Issue Wide-Design zur Verfügung hat. Man muss ja über den Lauf hinweg kucken, was alles gemacht werden muss. Und wenn man dann im Mittel bei 1,8 liegt gibt es nunmal Phasen, wo man einen, zwei, drei, vier Issues auslasten kann.
dann ahst du in 10% der Fälle 1 von 100 befehlen schneller abgearbeitet und dafür drehen in 90% der fälle zigtausend Transistoren däumchen... und was sagt uns das über die Effizienz?
Wenn ich es schaffe ein 2-Issue wide design zu 80% ausgelastet zu halten, erreiche ich damit mehr wie wenn ich ein 3-Issue habe das zu 10% mal zur abwechslung mehr Arbeitet als das 2-Issue und dafür aufgrund des mieserablen Frontends die restliche Zeit däumchen dreht...
Ausserdem hab ich nicht gesagt dass das generell für die Katz ist... sondern nur dass es kein Argument dafür istt, dass BD pro kern langsamer sein muss als es K10 war! - Man kann mit 2 Issue sehr gut hinkommen, wenn die mittlere Auslastung stimmt!
Oder anders gesagt, anstatt 3-issue mit einem mäßigen Frontend und damit nicht grade idealer Auslastung zu fabrizieren sind die Transsitoren bei einem 2-Issue Design mit besserem Frontend und daher besserer Auslastung wesentlich intelligenter investiert.
Wie ich schon sagte ist genau das der Grund warum Intels HyperThreading überhaupt funktioniert... weil eben mindestens 1 ALU die meiste Zeit durch einen Thread nicht genügen ausgelastet werden kann, und daher Luft hat sich um einen Zweiten zu kümmern.
Auf der einen Seite hast du 3-Issue mit HTr, was im Single-Thread-Fall bei einem von was weiß der Geier wieviel Befehlen mal sein 3-Issue ausspielen kann, (was noch nichts darüber sagt wie viele Bubbles es im übrigen gibt, sonst wäre es im Mittel nicht unter 2)
Dafür kloppen sich bei 2 Threads die selbigen um die ALUs und stehlen einander Ressourcen.
Oder du hast im anderen Fall 2-Issue, doppelt ausgelegt (CMT)... wo 2 ALUs exklusiv einem Thread zur Verfügung stehen und es kommt eben bei einem von X befehlen dazu dass er warten muss, weil keine 3. ALU verfügbar ist...
Dafür kannst du den Scheduler einfacher auslegen und sparst an anderen Enden...
So viel schlechter klingt die letztere Option für mich nicht.
Und sorry, wenn ich 3 hab und im mittel nichtmal 2 auslasten kann, ist das eine mittlere Effizienz von nichtmal 66%... mag man davon halten was man will...
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Das hat auch niemand gesagt. Theoretisch hat ja jeder Bulldozer "Kern" das Potenzial von IPC 4. Die Frage ist letztendlich, wie sinnvoll 3 ALUs + 3 AGUs mit einer theoretischen IPC von 6 sind, wenn eben selbst in Extremsituationen eine IPC von kaum mehr als 2 erreicht werden kann. Wenn wir mal davon ausgehen, dass mit jeder Ausführungseinheit der Energiebedarf linear steigt. Macht es wirklich Sinn, dass ein Integer Cluster 50% mehr Energie braucht bei vielleicht 2-3% mehr IPC real?Nur weil man !!!IM SCHNITT!!! nie über zwei liegt heisst das nicht, das 3 Issue Wide oder 4 Issue Wide für die Katze ist.
y33H@
Admiral Special
- Mitglied seit
- 16.05.2011
- Beiträge
- 1.768
- Renomée
- 10
Die Werte in Fritzchess von corescn sind kaum weit weg von denen von OBR. Trotz 4,2-GHz-Turbo und B2-Stepping (was Retail kommen soll) "nur" auf Augenhöhe eines i7-2600K, in anderen Benches darunter. Der Unterschied zum X6 1100T ist angesichts der Architektur und angeblichen IPC-Steigerung damit sehr ernüchternd - oder aber alle Modelle, die im Umlauf sind (auch die B2, die nicht als ES erkannt werden), leiden an einem crappy BIOS oder dergleichen. Da würde AMD aber extrem dicht halten, denn in vier Wochen ist der Spuk wohl um.
EDIT
Und von wegen OBR - sieht das nach Fake aus? AMD sagte "mehr als 2x so schnell wie X6 1100" und was sehen wir hier - gleich mal 27 Prozent vor dem i7-2600K und fast 5x schneller als der X6.

EDIT
Und von wegen OBR - sieht das nach Fake aus? AMD sagte "mehr als 2x so schnell wie X6 1100" und was sehen wir hier - gleich mal 27 Prozent vor dem i7-2600K und fast 5x schneller als der X6.

Zuletzt bearbeitet:
Pirx
Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 1.234
- Renomée
- 11
- Standort
- Mädels auf Bäumen wachsen
- Mein Laptop
- Samsung NC20
- Details zu meinem Desktop
vielleicht wird die "AES-Einheit"(?) nicht mit gedrosselt
- Status
- Für weitere Antworten geschlossen.
Ähnliche Themen
- Antworten
- 91
- Aufrufe
- 8K
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 6
- Aufrufe
- 1K