App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Kaveri - der Trinity Nachfolger
- Ersteller FredD
- Erstellt am
Na klar pro Core. Bei BD kann ein Kern vier µOps in einem Rutsch (in einem Takt) erhalten.Aber nicht pro Core ...
Laut dem Software Optimization Guide gibt es bereits jetzt einen sogenannen Instruction Byte Buffer (der bei Jaguar offenbar nur noch Instruction Buffer heißt). AMD behauptet, daß der pro Thread 16 Einträge von jeweils 16 Byte großen Windows enthalten kann, also 256 Byte pro Core oder 512Byte insgesamt. Damit werden offenbar L1-I Cache-Misses (die vermutlich den L1-I-Prefetcher triggern) abgefedert bzw. Fetch und Decode entkoppelt. Die Erweiterung zu einem Loop-Buffer sollte eigentlich ziemlich straightforward sein. Aber eventuell kann nur die Hälfte des IB/PFB (der jetzt 32Byte Windows bekommt?) als Loop Buffer benutzt werden, keine Ahnung.Und dort steht dabei, dass der Puffer im L1I-Cache ist. Sollte dann beim Steamroller wohl ähnlich sein, AMD wird kaum das Rad 2x erfinden. Auf jeden Fall weisst es darauf hin, dass es kein µOp Puffer wird, sondern "nur" ein x86-Op-Puffer. Schade, aber besser als nichts und Steamroller bekommt immerhin 8 Einträge, also vermutlich 256 Byte. Weiss noch jemand wie groß das Ding beim Core2 war?(Und ich seh gerade, dass da ja auch was von einem IC-Prefetcher steht). Also wirds dann schon so sein.
Edit: Selbst gegoogelt, Agner Fog nennt für den Core2 4x16Byte = 64 Byte für den Loop Cache. Wäre dann bei AMD doppelt oder gar vierfach soviel (bei 1 Thread pro Modul, falls AMD das nicht fest partioniert hat). Hmm .. apropos .. das ist wohl der Nachteil dieser Anordnung ... der LoopCache muss für beide Threads herhalten ( Wobei ich mir jetzt nicht ganz sicher bin, waren die Queues im Front-End nicht immer doppelt für jeden Thread extra angelegt? Glaube mich dunkel zu erinnern ^^) Wie auch immer, danach warten dann dicke Decoder auf die Ops, aber die brauchen ja wieder extra Strom. Aber naja, wie gesagt, ganz sicher besser als nichts, und wenigstens etwas größer als Intel damalsIntel gab für die 4x16 Byte ein Äquivalent von 18 x86 Ops an. Das wären dann also ~36 im AMD-Fall, eventuell gar 72 im singlethread- oder extra-Queue-Fall. Klingt doch schon mal ganz ordentlich.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Das ist aber nicht das, was ich meine. Dort reden sie von einem gemeinsamen Frontend, das die Instruktionen eines Threads an beide Integer Cluster schicken kann. Also eher das berühmt berüchtigte Anti-Hyperthreading oder konkreter, SpMT.Das Patent dazu ist dies hier:
http://www.strutpatent.com/patent/0...llel-dispatch-and-method-thereof#!prettyPhoto
Dort kann man in den Drawings (spez. Fig. 5) den Ablauf sehen.
Dazu nochmal Genaueres. Bisher sieht es so aus:Bisher gibt es 2 FMA-Pipes und 2 SIMD-ALU-Pipes (Integer, Bitmanipulationen). Mit Steamroller gibt es dann nur noch 2 FMA-Pipes und eine zusätzliche SIMD-Pipeline, vermutlich werden die Instruktionen auch ein wenig umverteilt.
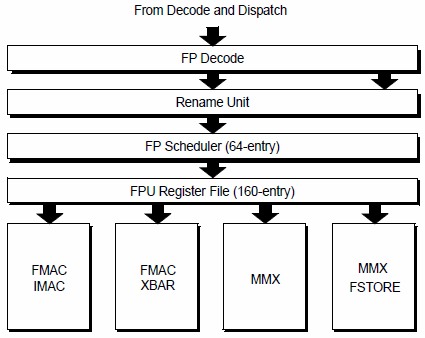
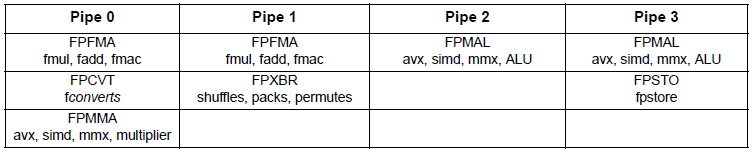
Mit Steamroller dann so:
Pipe 0 (FMA0)
|
Pipe 1 (FMA1)
|
Pipe 2 (FSTORE)
FPFMA (fmul, fadd, fmac) | FPFMA (fmul, fadd, fmac) | FPSTO (fpstore)
FPMAL (MMX/AVX/SIMD ALU [adds, bitops, cmps] | FPXBR (shuffles?, packs, permutes) | FPMAL (MMX/AVX/SIMD ALU [adds, bitops, cmps])
FPCVT (fconverts) | | FPSHUF (shuffles, packs?, permutes?)
FPMMA (MMX/AVX/SIMD INT multiplier) | |
Die einsame SIMD-ALU Einheit in Pipe2 wird in die Pipe0 integriert und die Store-Pipe bekommt eine zusätzliche Shuffle-Einheit, was immer die dann genau macht (eventuell, wird die bisherige XBR-Einheit aufgeteilt und kann in Steamroller keine shuffles mehr).
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Auch, aber die Dispatcher-Anbindung wird in weiteren Patenten von Sean Lie gezeigt, auch zum Zwecke des schnelleren Transfers von Dispatch Packets. Begründung: Die Leitungen sind sowieso da.Das ist aber nicht das, was ich meine. Dort reden sie von einem gemeinsamen Frontend, das die Instruktionen eines Threads an beide Integer Cluster schicken kann. Also eher das berühmt berüchtigte Anti-Hyperthreading oder konkreter, SpMT.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ja genau der IBB war das. Also für 2 Threads - gutNa klar pro Core. Bei BD kann ein Kern vier µOps in einem Rutsch (in einem Takt) erhalten.
Laut dem Software Optimization Guide gibt es bereits jetzt einen sogenannen Instruction Byte Buffer (der bei Jaguar offenbar nur noch Instruction Buffer heißt). AMD behauptet, daß der pro Thread 16 Einträge von jeweils 16 Byte großen Windows enthalten kann, also 256 Byte pro Core oder 512Byte insgesamt. Damit werden offenbar L1-I Cache-Misses (die vermutlich den L1-I-Prefetcher triggern) abgefedert bzw. Fetch und Decode entkoppelt. Die Erweiterung zu einem Loop-Buffer sollte eigentlich ziemlich straightforward sein. Aber eventuell kann nur die Hälfte des IB/PFB (der jetzt 32Byte Windows bekommt?) als Loop Buffer benutzt werden, keine Ahnung.
") Aber so ganz sicher bin ich mir noch nicht, wieso schreibt BSN was von nem "PFB" und schreibt nicht IBB?
Aber so ganz sicher bin ich mir noch nicht, wieso schreibt BSN was von nem "PFB" und schreibt nicht IBB? 
Naja nehmen wir mal an, es ist der IBB: Dann muss das so ausgesehen haben:
BDv1: 16x16byte je Threads
BDv2: 8x32byte je Threads // da der PFB bei BDv3 auf 16 erhöht wurde, müssen es bei BDv2 also 8 gewesen sein, würde auch dazu passen, dass die Einträge auf 32byte vergrößert wurden. Entweder das oder PFB != IBB
BDv3: 16x32byte je Threads // davon 8 als Loop-Cache
Ergo: 8x32 byte Loop-Cache pro Thread = 256 Byte = 72 Instruktionen (nach alter Intel Rechnung, 4x soviel wie Core2 (4x16 kByte))
Ich würde mal sagen, dass wir da zufrieden sein sollten, oder?
Edit:
Wie verträgt sich das eigentlich mit den Puffern nach dem Decoder? Die gibts ja auch:
www.anandtech.com/show/6201/amd-details-its-3rd-gen-steamroller-architectureAlthough AMD doesn’t like to call it a cache, Steamroller now features a decoded micro-op queue. As x86 instructions are decoded into micro-ops, the address and decoded op are both stored in this queue. Should a fetch come in for an address that appears in the queue, Steamroller’s front end will power down the decode hardware and simply service the fetch request out of the micro-op queue. This is similar in nature to Sandy Bridge’s decoded uop cache, however it is likely smaller. AMD wasn’t willing to disclose how many micro-ops could fit in the queue, other than to say that it’s big enough to get a decent hit rate.
Wieso macht man den Loop-Cache nicht dort?
Wobei ich mich auch frage, was da so neu sein soll, dass sind die die Dispatch-Puffer, die die Anandleute meinen, oder nicht?
http://www.realworldtech.com/bulldozer/5/After examining the instruction window, the decoders translate each x86 instruction into 1 or 2 macro-operations and place them into a queue for dispatching.
P.S: Googlesuche nach PFB bringt abgesehen von unserem Thread hier (und ähnlich) nichts verwertbares. Ist dann wohl ne BSN-eigene Abkürzung. Sowas nervt einfach nur, goldene NDA-PDFs in Amateurhänden ^^
Vielleicht, ist jetzt neu, dass auch die Adressen mit gespeichert werden, so dass man abfragen kann, ob eine Instruktion schon mal dekodiert wurde (war vlt. vorher nur ein FIFO?). Den Loop-Cache vor die Decoder zu verlegen macht man unter Umständen weil er dort nicht so groß sein muss wie wenn er hinter ihnen wäre und wenn die Instruktionen dann in dem OP-Buffer hinter dem Decoder liegen müssten diese ja trotzdem nicht nochmal dekodiert werden.Edit:
Wie verträgt sich das eigentlich mit den Puffern nach dem Decoder? Die gibts ja auch:
www.anandtech.com/show/6201/amd-details-its-3rd-gen-steamroller-architecture
Wieso macht man den Loop-Cache nicht dort?
Wobei ich mich auch frage, was da so neu sein soll, dass sind die die Dispatch-Puffer, die die Anandleute meinen, oder nicht?
http://www.realworldtech.com/bulldozer/5/
Ist jetzt aber reine Spekulation meinerseits.
Alter Sack
Lt. Commander
- Mitglied seit
- 10.03.2013
- Beiträge
- 143
- Renomée
- 0
- Standort
- Dennheritz
- Details zu meinem Desktop
- Prozessor
- A10-6700
- Mainboard
- Asrock FM A88X Extreme6+
- Kühlung
- Scythe Ninja II
- Speicher
- 8 GB DDR 3 1600 MHz
- Grafikprozessor
- APU
- Display
- 20" Samsung 1680x1050
- SSD
- Samssung Evo 840 256 GB
- HDD
- 1x 2 TB
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- Onboard
- Netzteil
- Be Quiet 400W, 80+ Gold
- Betriebssystem
- Win7 x 64, SP1
- Webbrowser
- Opera, Firefox
- Verschiedenes
- Mein Allround-PC, den ich bei Bedarf , durch eine HD7870 aufwerte.
Sorry, ich bin neu hier und habe bisher nur öfters mitgelesen.
Mit meinem Wissen ist´s auch nicht weit her.
Allerdings brennen mir einige Fragen unter den Nägeln.
- Wäre Stacked Memory auf dem APU-Gehäuse eine Möglichkeit? Normalen DDR3 -oder DDR4 Speicher könnte man für den Desktop ja sozusagen als L2-Ram anbinden.
- Warum hält AMD an diesem komplizierten Cache-Design fest und kopiert nicht das Intel-System? Hat das lizenzrechtliche Gründe?
- Weshalb kann ein Modul nicht als 1 Kern arbeiten? Dadurch würde die Single-Thread Schwäche behoben (mit Ausnahme der FP-Leistung).
- Warum ist tut sich bei den Cache-Latenzen nichts?
- Weshalb geht man nicht vom derart hochfrequenten Design ab, wo man doch mit GF und vorher der eigenen Fertigung, traditionell eine Schwachstelle hat?
VG
Mit meinem Wissen ist´s auch nicht weit her.
Allerdings brennen mir einige Fragen unter den Nägeln.
- Wäre Stacked Memory auf dem APU-Gehäuse eine Möglichkeit? Normalen DDR3 -oder DDR4 Speicher könnte man für den Desktop ja sozusagen als L2-Ram anbinden.
- Warum hält AMD an diesem komplizierten Cache-Design fest und kopiert nicht das Intel-System? Hat das lizenzrechtliche Gründe?
- Weshalb kann ein Modul nicht als 1 Kern arbeiten? Dadurch würde die Single-Thread Schwäche behoben (mit Ausnahme der FP-Leistung).
- Warum ist tut sich bei den Cache-Latenzen nichts?
- Weshalb geht man nicht vom derart hochfrequenten Design ab, wo man doch mit GF und vorher der eigenen Fertigung, traditionell eine Schwachstelle hat?
VG
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
@Alter Sack
Hab nur was grundsätzliches dazu zu sagen:
Man sollte immer bedenken, dass die Entwicklung eines Designs mehrere Jahre dauert. Als die Grundlagen zu BD gelegt wurden, ging man wohl davon aus, dass die Prozesstechnik entsprechende fortschritte macht: Schneller, weniger Verbrauch, höhere Transistordichte etc. Mit der Kriese 2009 traten verzögerungen bei den Fertigern ein. 32 nm gab es Probleme, 28nm läßt auf sich warten... Denke mal, ursprünglich hatte man schon mit höheren Frequenzen und geringeren Verbrauch bei BD gerechnet und PD schon für 22nm geplant.
Zudem kann man allgemein sagen, dass sich Logik schnell mit vielen Transistoren lösen läßt oder eben mit weniger Transistoren und dafür aber mehr Takte benötigt. Viele Transistoren erhöhen den Verbrauch, mehr Takt macht es langsamer. Es ist immer ein Abwägen, wo man die Prioritäten setzt.
Ebenso muß abgewogen werden, wo man Arbeitszeit investiert. Dazu muß man erst genau wissen, wieviel Mehrleistung eine Überarbeitung bringt und welche Nachteile die Überarbeitung dann hat. Es ist immer ein Abwägen. Daher, bei Fragen wie: Warum macht man jenes oder solches nicht: Die Probleme sind anderweitig größer bzw. andere Baustellen bringen mehr Performance als das angesprochene Problem.
Wieso kopiert man nicht...: Selbst wenn man die Patente nutzen darf, steht in den Patenten kein genauer Schaltplan. Da ist dann noch einiges reinzustecken, bis es so läuft, wie bei dem Original.
Dann noch generell zu Ingenieuren: Wenns nach denen geht, kommt ein Produkt erst auf den Markt, wenn es perfekt ist, also nie. Irgendwann wird für ein Projekt die Deadline gesetzt und wenn dann das neue nicht richtig funktioniert, wird das alte Bewärte verbaut und das neue kommt vielleicht in die nächste Revision.
Da wir nie erfahren, wieso der Projektleiter entsprechend entschieden hat und wie die aktuelle Prioritätenliste aussieht, können wir nur spekulieren und uns Aufregen über ( vermeintliche ) Fehlentscheidungen.
Hab nur was grundsätzliches dazu zu sagen:
Man sollte immer bedenken, dass die Entwicklung eines Designs mehrere Jahre dauert. Als die Grundlagen zu BD gelegt wurden, ging man wohl davon aus, dass die Prozesstechnik entsprechende fortschritte macht: Schneller, weniger Verbrauch, höhere Transistordichte etc. Mit der Kriese 2009 traten verzögerungen bei den Fertigern ein. 32 nm gab es Probleme, 28nm läßt auf sich warten... Denke mal, ursprünglich hatte man schon mit höheren Frequenzen und geringeren Verbrauch bei BD gerechnet und PD schon für 22nm geplant.
Zudem kann man allgemein sagen, dass sich Logik schnell mit vielen Transistoren lösen läßt oder eben mit weniger Transistoren und dafür aber mehr Takte benötigt. Viele Transistoren erhöhen den Verbrauch, mehr Takt macht es langsamer. Es ist immer ein Abwägen, wo man die Prioritäten setzt.
Ebenso muß abgewogen werden, wo man Arbeitszeit investiert. Dazu muß man erst genau wissen, wieviel Mehrleistung eine Überarbeitung bringt und welche Nachteile die Überarbeitung dann hat. Es ist immer ein Abwägen. Daher, bei Fragen wie: Warum macht man jenes oder solches nicht: Die Probleme sind anderweitig größer bzw. andere Baustellen bringen mehr Performance als das angesprochene Problem.
Wieso kopiert man nicht...: Selbst wenn man die Patente nutzen darf, steht in den Patenten kein genauer Schaltplan. Da ist dann noch einiges reinzustecken, bis es so läuft, wie bei dem Original.
Dann noch generell zu Ingenieuren: Wenns nach denen geht, kommt ein Produkt erst auf den Markt, wenn es perfekt ist, also nie. Irgendwann wird für ein Projekt die Deadline gesetzt und wenn dann das neue nicht richtig funktioniert, wird das alte Bewärte verbaut und das neue kommt vielleicht in die nächste Revision.
Da wir nie erfahren, wieso der Projektleiter entsprechend entschieden hat und wie die aktuelle Prioritätenliste aussieht, können wir nur spekulieren und uns Aufregen über ( vermeintliche ) Fehlentscheidungen.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
@Alter Sack
Stacked Memory wird früher oder später sicherlich kommen. Die Frage ist nur wann. Mit Kaveri wahrscheinlich noch nicht.
Welches komplizierte Cache-Design? Intels Cache-Design ist doch komplizierter aufgrund der 3 Level. Macht bei AMD Null Sinn. Mit 256 KB L2 kommst du nicht weit.")
Die Frage ergibt keinen Sinn. Du meinst vielleicht, warum kann ein Modul nicht alle seine Ressourcen einem Thread zur Verfügung stellen? Nun, theoretisch könnte es das. Die Frage ist nur, macht das Sinn? Geteilte Ressourcen erhöhen die Komplexität und können sich ab einem gewissen Punkt negativ auswirken. Bulldozer versucht deshalb den besten Mittelweg aus dedizierten und geteilten Einheiten pro Thread zu gehen. Das ist auch nicht die Problematik der singlethreaded Performance. Bulldozer ist 4-fach OoO und kann theoretisch 8 Ops pro Takt verarbeiten. Das ist ausreichend für gute singlethreaded Performance. Die Baustellen liegen eher an anderer Stelle.
Was meinst du? Sind denn schon Cache-Latenzen von Kaveri bekannt? Wäre mir neu.
Bulldozer ist kein Hochfrequenzdesign. Bitte nicht von dem immer mal wieder kolportierten Irrglauben verunsichern lassen. Bulldozer besitzt lediglich eine 20-30% besser taktbare Pipeline als K10. Und das war mMn auch die richtige Designentscheidung. Ich denke, AMD wird zukünftig weniger Taktprobleme als Intel bekommen. Vielleicht erinnert man sich noch an den Ur-K10 und wohin das führen kann.
Stacked Memory wird früher oder später sicherlich kommen. Die Frage ist nur wann. Mit Kaveri wahrscheinlich noch nicht.
Welches komplizierte Cache-Design? Intels Cache-Design ist doch komplizierter aufgrund der 3 Level. Macht bei AMD Null Sinn. Mit 256 KB L2 kommst du nicht weit.
Die Frage ergibt keinen Sinn. Du meinst vielleicht, warum kann ein Modul nicht alle seine Ressourcen einem Thread zur Verfügung stellen? Nun, theoretisch könnte es das. Die Frage ist nur, macht das Sinn? Geteilte Ressourcen erhöhen die Komplexität und können sich ab einem gewissen Punkt negativ auswirken. Bulldozer versucht deshalb den besten Mittelweg aus dedizierten und geteilten Einheiten pro Thread zu gehen. Das ist auch nicht die Problematik der singlethreaded Performance. Bulldozer ist 4-fach OoO und kann theoretisch 8 Ops pro Takt verarbeiten. Das ist ausreichend für gute singlethreaded Performance. Die Baustellen liegen eher an anderer Stelle.
Was meinst du? Sind denn schon Cache-Latenzen von Kaveri bekannt? Wäre mir neu.
Bulldozer ist kein Hochfrequenzdesign. Bitte nicht von dem immer mal wieder kolportierten Irrglauben verunsichern lassen. Bulldozer besitzt lediglich eine 20-30% besser taktbare Pipeline als K10. Und das war mMn auch die richtige Designentscheidung. Ich denke, AMD wird zukünftig weniger Taktprobleme als Intel bekommen. Vielleicht erinnert man sich noch an den Ur-K10 und wohin das führen kann.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Sehe ich mir die angeblichen Benches zur Grafik-Performance von Kabini/Temash an, dann dürfte das GDDR5-Interface für Kaveri eine logische Schlussfolgerung sein. Wenn die kleinen APUs schon mit einer so hohen GPU-Leistung aufwarten, dann könnte hier Kaveri eine neue Dimension werden. Notebooks mit Kaveri brauchen dann womöglich überhaupt keine Grakas mehr. Das spart den OEMs wieder viel Geld, weil man auf diese Komplexität komplett verzichten kann.
Es gefällt mir mehr und mehr, dass AMD sich endlich auf seine Stärken konzentriert und diese versucht in den Produkten umzusetzen. Womöglich stehen morgen AMD-CPUs/APUs in den Systemen für hohe Gaming-Performance. AMD muss das in allen seine Produkten nutzen
.
EDIT :
.
GDDR5 gibt es bereits am Markt als auch den Kontroller baut AMD längst für die Grakas. Gleichzeitig dürfte der Kontroller ähnlich den Grakas auch das "normale" DDR3-Interface bieten. Und da wäre es ja nur logisch, dass man auch DDR4 unterstützt, damit es genutzt werden kann, sobald es auf den Markt kommt. Weil aber DDR4 noch nicht da ist, setzt man wohl auf GDDR5. Flexibiliät ist hier Trumpf.
Es gefällt mir mehr und mehr, dass AMD sich endlich auf seine Stärken konzentriert und diese versucht in den Produkten umzusetzen. Womöglich stehen morgen AMD-CPUs/APUs in den Systemen für hohe Gaming-Performance. AMD muss das in allen seine Produkten nutzen
.
EDIT :
.
GDDR5 gibt es bereits am Markt als auch den Kontroller baut AMD längst für die Grakas. Gleichzeitig dürfte der Kontroller ähnlich den Grakas auch das "normale" DDR3-Interface bieten. Und da wäre es ja nur logisch, dass man auch DDR4 unterstützt, damit es genutzt werden kann, sobald es auf den Markt kommt. Weil aber DDR4 noch nicht da ist, setzt man wohl auf GDDR5. Flexibiliät ist hier Trumpf.
Alter Sack
Lt. Commander
- Mitglied seit
- 10.03.2013
- Beiträge
- 143
- Renomée
- 0
- Standort
- Dennheritz
- Details zu meinem Desktop
- Prozessor
- A10-6700
- Mainboard
- Asrock FM A88X Extreme6+
- Kühlung
- Scythe Ninja II
- Speicher
- 8 GB DDR 3 1600 MHz
- Grafikprozessor
- APU
- Display
- 20" Samsung 1680x1050
- SSD
- Samssung Evo 840 256 GB
- HDD
- 1x 2 TB
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- Onboard
- Netzteil
- Be Quiet 400W, 80+ Gold
- Betriebssystem
- Win7 x 64, SP1
- Webbrowser
- Opera, Firefox
- Verschiedenes
- Mein Allround-PC, den ich bei Bedarf , durch eine HD7870 aufwerte.
Erstmal danke ich Euch für die Antworten.
@ gruffi
Naja ich dachte, dass das teilweise inclusive design vllt. komplizierter ist,
als ein vollständig inklusives Design.
Aber auf Kaveri trifft das wohl eh nicht zu, wegen des fehlenden L3.
O.K. bei der Single-Thread- Performance lag ich wohl komplett daneben.
Bei den Latenzen ändert sich wohl laut den Gerüchten nichts.
Zumindest wurde nichts erwähnt, soweit ich das mitbekommen habe.
Hoffen wir das Beste.
VG
@ gruffi
Naja ich dachte, dass das teilweise inclusive design vllt. komplizierter ist,
als ein vollständig inklusives Design.
Aber auf Kaveri trifft das wohl eh nicht zu, wegen des fehlenden L3.
O.K. bei der Single-Thread- Performance lag ich wohl komplett daneben.
Bei den Latenzen ändert sich wohl laut den Gerüchten nichts.
Zumindest wurde nichts erwähnt, soweit ich das mitbekommen habe.
Hoffen wir das Beste.
VG
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Was heisst teilweise? Die Bobcat Architektur ab Kabini/Temash und die Bulldozer Architektur ab Trinity ist vollständig inklusive. Teilweise inklusive gibt's nur noch beim Serverdesign Orochi.Naja ich dachte, dass das teilweise inclusive design vllt. komplizierter ist,
als ein vollständig inklusives Design.
Dann bringe mal eine Quelle für diese Gerüchte. Bisher ist mir nichts zu Latenzen bekannt.Bei den Latenzen ändert sich wohl laut den Gerüchten nichts.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Stand auf Anandtech im Steamrollerartikel und bezog sich auf den L3 Cache. Die Gründe wären bekannt,aber AMD würde nichts daran ändern. Wundert auch nicht, der Grund ist der niedrige Takt, Intel hatte beim Nehalem in ner offiziellen Folie auch 52 Takte für ihren damaligen L3@2.133 MHz angegeben. Stromverbrauchsmäßig kann sich es intel nun seit Sandy leisten den Takt voll laufen zu lassen, AMD aber nicht, vielleicht ja bei 20nm.Dann bringe mal eine Quelle für diese Gerüchte. Bisher ist mir nichts zu Latenzen bekannt.
Aber wie schon öfters geschrieben ist es bei AMD fast egal, sie haben ja 2MB L2, nicht 256kB. Da ist der L3 nicht so wichtig und die 20Takte für den L2 sind noch ok.
Einziger Kritikpunkt meinerseits bleiben die TLBs, da sollten sie noch ne zusätzliche Schippe nachlegen. 96 ist doch ne schöne Zahl
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Naja, das ist ja hier im Thread nicht wirklich von Belang. Das kann man gerne beim Orochi Nachfolger diskutieren. Hier interessiert uns nur L2. Wobei selbst die L2 Latenz nicht so kritisch ist, weil mit den Daten 2 Threads gefüttert werden. Bei Intel ist es eben nur einer.Stand auf Anandtech im Steamrollerartikel und bezog sich auf den L3 Cache.
War SB nicht eher eine Ausnahme? Ich dachte, bei IB ist der L3-Takt wieder entkoppelt.Stromverbrauchsmäßig kann sich es intel nun seit Sandy leisten den Takt voll laufen zu lassen.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Jo dachte ich mir schon, dass es da eventuell ein Mißverständnis gab, deswegen hab ichs erwähnt.Naja, das ist ja hier im Thread nicht wirklich von Belang. Das kann man gerne beim Orochi Nachfolger diskutieren. Hier interessiert uns nur L2.
Ne, der läuft nachwievor mit voellem Coretakt, alles andere wäre stark verwunderlich, schließlich haben sie durch den Shrink auf 22nm noch bessere Stromspareigenschaften.War SB nicht eher eine Ausnahme? Ich dachte, bei IB ist der L3-Takt wieder entkoppelt.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
/offtopic
Ich denke da liegst du falsch. Habe es mir nochmal angeschaut. Der L3 ist tatsächlich abIB (?) SB-E wieder entkoppelt. Muss also nicht mit Kerntakt laufen, abhängig vom Energiebudget. Mit Haswell geht man sogar wieder BTTR, also mehr wie Nehalem. Mehr dazu hier. Scheinbar steigt die L3 Latenz sogar etwas mit Haswell. Dafür gibt's mehr Durchsatz.
Ich denke da liegst du falsch. Habe es mir nochmal angeschaut. Der L3 ist tatsächlich ab
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ich hatte nur geschrieben "voller Coretakt", nicht gleiche Taktdomäne Dass SandyE ne eigenen Taktbereich hat stimmt, aber der läuft halt trotzdem mit vollem Kerntakt, auch wenn er entkoppelt ist
Wie besagt, intel kann es sich leisten ... AMD könnte den L3 Takt technisch gesehen auch anheben, aber das zöge halt zuviel Energie.
Das mit Haswell ist interessant, ist ansonsten halt unpraktisch mit so ner GPU und dem L3-Zugriff ... AMD ist Schuld, die mit ihrer blöden APU-Idee ^^
Dass SandyE ne eigenen Taktbereich hat stimmt, aber der läuft halt trotzdem mit vollem Kerntakt, auch wenn er entkoppelt ist Wie besagt, intel kann es sich leisten ... AMD könnte den L3 Takt technisch gesehen auch anheben, aber das zöge halt zuviel Energie.
Das mit Haswell ist interessant, ist ansonsten halt unpraktisch mit so ner GPU und dem L3-Zugriff ... AMD ist Schuld, die mit ihrer blöden APU-Idee ^^
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Von vollem Kerntakt habe ich aber gar nichts geschrieben. Ich fragte lediglich, ob das nicht eher die Ausnahme war und der L3 mittlerweile wieder entkoppelt ist. Und du meintest daraufhin "Ne ...". Eben doch. Nix ne. SB (IB?) scheint lediglich die Ausnahme zu sein. Der L3 wird normalerweise entkoppelt und muss daher nicht mit Kerntakt laufen.
SB (IB?) scheint lediglich die Ausnahme zu sein. Der L3 wird normalerweise entkoppelt und muss daher nicht mit Kerntakt laufen.Locuza
Commodore Special
- Mitglied seit
- 03.03.2011
- Beiträge
- 351
- Renomée
- 3
Mal eine Frage an die Experten.
PCIe 2/3 stellt doch den Verbindunsbus zwischen CPU und GPU her, 8/16 GB/s je Richtung. (+ Hohe Latenzen)
Bei Kaveri wurde die Interkommunikation von CPU und GPU doch auf 256-Bit aufgebohrt?
Verwendet wird hier doch auch PCIe, aber wie hoch ist hier die Bandbreite und wie ist die Latenz einzuordnen?
Wegen der lokalen Nähe müsste sie doch deutlich besser sein, bloß kann man irgendwie abschätzen wie deutlich? (Trinity, Llano als Vergleichsmaßstab?)
Anhang anzeigen 27200
Das war beim Llano, also ist die Interkommunikation ~27 GB/s schnell zwischen GPU und CPU, während sie nur ~7 GB/s schafft bei PCIe2.
Edit: Wobei CPU und GPU doch über Onion kommunizieren bzw. den FCL ( Bei 650Mhz 10,4 GB/s je Richtung beim Llano. siehe real tech world)
http://www.realworldtech.com/fusion-llano/2/
Und genau dieser wird bei Kaveri 256-Bit breit sein, im Gegensatz zu den 128-Bit.
Würde in 20,8 GB/s resultieren (Bei 650Mhz)
Okay, die einzige Frage die ich bei dem Wirrwar habe, was wäre bei einer APU das Gegenstück von dem Flaschenhals PCIe3 am PC, welcher für die Kommunikation zwischen CPU und GPU sorgt?
PCIe 2/3 stellt doch den Verbindunsbus zwischen CPU und GPU her, 8/16 GB/s je Richtung. (+ Hohe Latenzen)
Bei Kaveri wurde die Interkommunikation von CPU und GPU doch auf 256-Bit aufgebohrt?
Verwendet wird hier doch auch PCIe, aber wie hoch ist hier die Bandbreite und wie ist die Latenz einzuordnen?
Wegen der lokalen Nähe müsste sie doch deutlich besser sein, bloß kann man irgendwie abschätzen wie deutlich? (Trinity, Llano als Vergleichsmaßstab?)
Anhang anzeigen 27200
Das war beim Llano, also ist die Interkommunikation ~27 GB/s schnell zwischen GPU und CPU, während sie nur ~7 GB/s schafft bei PCIe2.
Edit: Wobei CPU und GPU doch über Onion kommunizieren bzw. den FCL ( Bei 650Mhz 10,4 GB/s je Richtung beim Llano. siehe real tech world)
http://www.realworldtech.com/fusion-llano/2/
Und genau dieser wird bei Kaveri 256-Bit breit sein, im Gegensatz zu den 128-Bit.
Würde in 20,8 GB/s resultieren (Bei 650Mhz)
Okay, die einzige Frage die ich bei dem Wirrwar habe, was wäre bei einer APU das Gegenstück von dem Flaschenhals PCIe3 am PC, welcher für die Kommunikation zwischen CPU und GPU sorgt?
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Eine APU hat diesen Flaschenhals eben nicht (in der Endversion), Da es dieses verschieben zwischen CPU und GPU nicht gibt. Es gibt nur noch eine Anbindung direkt an den Speicher. Dort liegen die Daten und müssen nirgendwo hin verschoben werden da sowohl GPU als auch CPU diese Adresse ansprechen können und Daten lesen und schreiben können. Die Frage ist nicht ob man die Datenleitung breiter machen muss, sondern ob man einfach weniger Daten darüber verschicken muss.
HSAfähige GPUs werden auch PCIe als Flaschenhals haben und ansonsten ist die Engstelle eben die Speicheranbindung - daher ist dieser Schritt mit GDDR5 auch nicht so verkehrt.
HSAfähige GPUs werden auch PCIe als Flaschenhals haben und ansonsten ist die Engstelle eben die Speicheranbindung - daher ist dieser Schritt mit GDDR5 auch nicht so verkehrt.
hot
Admiral Special
- Mitglied seit
- 21.09.2002
- Beiträge
- 1.187
- Renomée
- 15
- Details zu meinem Desktop
- Prozessor
- AMD Phenom 9500
- Mainboard
- Asrock AOD790GX/128
- Kühlung
- Scythe Mugen
- Speicher
- 2x Kingston DDR2 1066 CL7 1,9V
- Grafikprozessor
- Leadtek Geforce 260 Extreme+
- Display
- Samsung 2432BW
- HDD
- Samsung HD403LJ, Samung SP1614C
- Optisches Laufwerk
- LG HL55B
- Soundkarte
- Realtek ALC890
- Gehäuse
- Zirco AX
- Netzteil
- Coba Nitrox 600W Rev.2
- Betriebssystem
- Vista x64 HP
- Webbrowser
- Firefox
Haswell entkoppelt den L3 wieder, nicht Ivy. Beim Ivy ist es AFAIK wie beim Sandy.
Und bei HSA könnte doch die GPU einfach wie eine CPU behandelt werden (außer, dass sie keine ist), also über CPU und GPU wird der gleiche Adressraum gelegt und PCIe dient als so ne Art NUMA-Konfiguration. Damit könnte die CPU den Grafikspeicher nutzen und die Grafikkarte den Hauptspeicher.
Und bei HSA könnte doch die GPU einfach wie eine CPU behandelt werden (außer, dass sie keine ist), also über CPU und GPU wird der gleiche Adressraum gelegt und PCIe dient als so ne Art NUMA-Konfiguration. Damit könnte die CPU den Grafikspeicher nutzen und die Grafikkarte den Hauptspeicher.
Zuletzt bearbeitet:
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Hatte AMD nicht angedeutet, dass die Inter-Kommunikation bei den neuen APUs zwischen CPU- und GPU-Part eher an HyperTransport angelehnt ist?...
Bei Kaveri wurde die Interkommunikation von CPU und GPU doch auf 256-Bit aufgebohrt?
Verwendet wird hier doch auch PCIe, aber wie hoch ist hier die Bandbreite und wie ist die Latenz einzuordnen?
...
Das dürfte die Latenzen zwischen beiden Kernkomponenten nochmals gegenüber PCI-Express verkürzen, also verbessern. Wobei ich anmerken will, dass der Schritt von PCI-Express 2.0 auf die Version 3.0 sicherlich auch die Latenzen verbessert.
MFG Bobo(2013)
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@gruffi:
Hast recht, hatte die Frage fälschlicherweise nur auf die taktfrage reduziert, da bei gleichem Takt trotz Entkopplung nicht soviel Leistung verloren geht. Die ~5 Takte würde ich unter den Tisch fallen lassen, aber jetzt ist ja alles klar
Ansonsten, Querposting aus dem Kabini-THread zu den Loop-Puffern. Die sind laut Fam16h PDF im l1-Instruktioncache:
@Bobo:
PCIe2 zu 3 brauchte außerdem eher ne Verschlechterung der Latenz, da sie auf 128b/130b Codierung umgestiegen sind. Das heißt, das man erstmal 130bit am Stück übertragen muss, bevor man weiss was drinsteht. War zuvor mit 8/10bit viel besser, aber das brachte halt viel Overhead mit sich. Halt der übliche Kuh-Handel.
Bin mal gespannt, ob es das ominöse Hypertransport 4.0 wirklich gibt, das wäre eventuell doch die beste Lösung.
Hast recht, hatte die Frage fälschlicherweise nur auf die taktfrage reduziert, da bei gleichem Takt trotz Entkopplung nicht soviel Leistung verloren geht. Die ~5 Takte würde ich unter den Tisch fallen lassen, aber jetzt ist ja alles klar
Ansonsten, Querposting aus dem Kabini-THread zu den Loop-Puffern. Die sind laut Fam16h PDF im l1-Instruktioncache:
The loop buffer is composed of four32-byte chunks and is essentially a subset of the
instruction cache.
Ist jetzt die Frage, wie das bei Steamroller gelöst ist, ob es da ähnlich gelöst ist. Falls ja frag ich mich, ob es im gemeinsamen Instruktionscache dann 2 Bereich für die Loop-Puffer gibt, oder nur einer. Einer wäre wohl ziemlich doof, denn wie soll man ne Schleife erkennen, wenn andauernd andere Zufallsinstruktions des 2. Threads dazwischenfunken
@Bobo:
Hab ich nicht mitbekommen, wo sollte das gewesen sein? Nur die 256bit standen halt bei BSN.Hatte AMD nicht angedeutet, dass die Inter-Kommunikation bei den neuen APUs zwischen CPU- und GPU-Part eher an HyperTransport angelehnt ist?
PCIe2 zu 3 brauchte außerdem eher ne Verschlechterung der Latenz, da sie auf 128b/130b Codierung umgestiegen sind. Das heißt, das man erstmal 130bit am Stück übertragen muss, bevor man weiss was drinsteht. War zuvor mit 8/10bit viel besser, aber das brachte halt viel Overhead mit sich. Halt der übliche Kuh-Handel.
Bin mal gespannt, ob es das ominöse Hypertransport 4.0 wirklich gibt, das wäre eventuell doch die beste Lösung.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Hatte AMD nicht angedeutet, dass die Inter-Kommunikation bei den neuen APUs zwischen CPU- und GPU-Part eher an HyperTransport angelehnt ist?
Das dürfte die Latenzen zwischen beiden Kernkomponenten nochmals gegenüber PCI-Express verkürzen, also verbessern. Wobei ich anmerken will, dass der Schritt von PCI-Express 2.0 auf die Version 3.0 sicherlich auch die Latenzen verbessert.
MFG Bobo(2013)
Was die Latenzen in den unterschiedlichen Szenarien betrifft, ist HT klar überlegen.
Zumindest nach eigener Methodik, siehe auch S.10 des pdfs http://www.hypertransport.org/docs/wp/Low_Latency_Final.pdf
.
EDIT :
.
Zugegeben, der Vergleich (link) ist total überholt, nachdem beide Protokolle über je 2 Revisionen erfahren haben. Aktuellere Vergleiche konnte ich bisher nicht ausfindig machen.
Man könnte noch die Kosten/Nutzen Frage stellen Hypertransport müsste AMD weiterentwickeln und PciE brauchen Sie auch.
Da stellt sich die Frage nach dem Vorteil gegenüber dem Nutzen.
E: Ich sehe grade an HT entwickeln HP,IBM und andere mit dann stellt sich nur die Frage nach den Aufwand der Implementierung 2 verschiedener Protokolle ob das Design dadurch komplexer wird.
Da stellt sich die Frage nach dem Vorteil gegenüber dem Nutzen.
E: Ich sehe grade an HT entwickeln HP,IBM und andere mit dann stellt sich nur die Frage nach den Aufwand der Implementierung 2 verschiedener Protokolle ob das Design dadurch komplexer wird.
Ähnliche Themen
- Antworten
- 638
- Aufrufe
- 141K
- Antworten
- 12
- Aufrufe
- 6K
- Antworten
- 0
- Aufrufe
- 44K