App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Nach DDR4: HBM - HighBandwidthMemory - bald auch in CPUs/APUs? Speicher(RAM) der/mit Zukunft?
- Ersteller TNT
- Erstellt am
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
AMD ist übrigens im HMC Konsortium vertreten und auch im HBM Konsortium. Intel und Nvidia sind bisher in beiden nicht vertreten. Intel ist "lediglich" als Anteilseigner am Jointventure beteiligt und muss so als Nichtmitglied keine eigenen Entwicklungen die auf HMC basieren offen legen. Und SkHynix als HBM Erfinder (mit AMD zusammen) ist Developermitglied bei HMC.
Diese Thematik hatte ich mal hier im März zusammengefasst:
http://www.planet3dnow.de/vbulletin...HBM-Speicher?p=4993746&viewfull=1#post4993746
Diese Thematik hatte ich mal hier im März zusammengefasst:
http://www.planet3dnow.de/vbulletin...HBM-Speicher?p=4993746&viewfull=1#post4993746
Zuletzt bearbeitet:
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Interessante Folie, die Teile eines bereits geposteten Foliensatzes zitiert. So wie das aussieht, ändert sich an der Latenz tRC erstmal nichts gegenüber GDDR5, bei einem 4-er Stapel der ersten HBM Generation. Übrigens, einen 8er Stapel könnten wir evtl. schon mit Fiji sehen.Hier ab Seite 14 die Latenzwerte im vergleich und ab da folgend die Details zu Single Bank refresh und die Datenbus optmierungen mit Dual Command Interface
http://www.hotchips.org/wp-content/...Bandwidth-Kim-Hynix-Hot Chips HBM 2014 v7.pdf
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Details aus einer neuen Quelle:
http://www.computerbase.de/forum/showthread.php?t=1475118&p=17380969#post17380969
http://www.computerbase.de/forum/showthread.php?t=1475118&p=17380969#post17380969
Der Vergleich DDR4 zu HBM2 ist sehr interessant. Besonderen Dank für diesen Link, den kannte ich noch nicht.Im Netz sind Folien von Hynix dazu. Hab noch mal nachgelesen: Von DDR4 zu HBM2 soll sich die Latenz um 60% verringern.
Siehe Seite 13: http://www.memcon.com/pdfs/proceedings2014/NET104.pdf
Auf Seite 25 und 26 wird wunderbar gezeigt woduch die Latenz so enorm verringert werden kann. Und auch wie die Auslastung enorm effizienter wird.
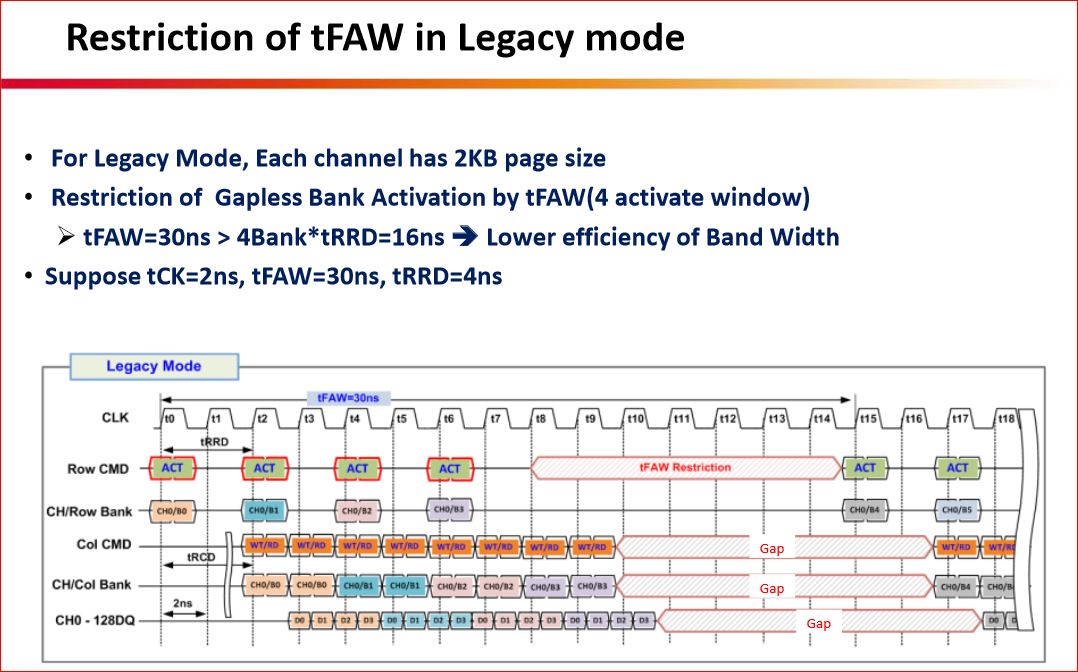

Details aus einer neuen Quelle:
http://www.computerbase.de/forum/showthread.php?t=1475118&p=17380969#post17380969
Das PDF hatte ich schon verlinkt im ersten Post =>
'Interessante Links zu Dokumenten etc.'
- oder ist es etwas neues?
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ja das it es - wäre geschickter wenn du mal all die Spoiler-Tags im Eröffnungsbeitrag raus nimmst, dann kann man URLs und Quellen einfacher abgleichen.
Ich finde diese Tags zudem sehr störend und klicke diese nicht an wenn ich nicht keinen konreten Anlass habe.
Ich finde diese Tags zudem sehr störend und klicke diese nicht an wenn ich nicht keinen konreten Anlass habe.
Ja das it es - wäre geschickter wenn du mal all die Spoiler-Tags im Eröffnungsbeitrag raus nimmst, dann kann man URLs und Quellen einfacher abgleichen.
Ich finde diese Tags zudem sehr störend und klicke diese nicht an wenn ich nicht keinen konreten Anlass habe.
Richtig - Du hast recht - aber in der Annahme, dass da noch mehr geben wird... aber gut, ich habe ein paar Links nun sichtbar gemacht...
") !
!Danke fuer den Hinweis,
TNT
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich mache das meisten so, dass ich unten am Ende "Quellen:" schreibe und alle Quellen, auch die im Text verlinkten, nochmals kommentarlos aufliste. So hat man eine Übersicht die deutlich weniger PLatz einnimmt als die Spoiler Abstände. Da lassen sich auch einfach zusätzliche Quellen aus den Forenkommentaren dazu setzen.
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
Im 3dcenter Forum postet einer gerade, dass zumindest ein (8GB-fähiger) Dual-Link-Interposer mit einigen hundert Dollars extrem teuer sei. Sofern sich das auch nur ansatzweise auf den normalen Single-Link-Interposer übertragen lässt, erübrigen sich meine Träume von einer Lowcost-APU mit HBM.
MfG
MfG
Im 3dcenter Forum postet einer gerade, dass zumindest ein (8GB-fähiger) Dual-Link-Interposer mit einigen hundert Dollars extrem teuer sei. Sofern sich das auch nur ansatzweise auf den normalen Single-Link-Interposer übertragen lässt, erübrigen sich meine Träume von einer Lowcost-APU mit HBM.
MfG
Hoppela - das ist mal ein 'Aufpreis' !
Sind das die wahren Kosten oder der Mehrpreis, den das Marketing glaubt verlangen zu koennen?
TNT
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ja so wie Nvidias FPGAs in GSync Monitoren 700,- $ das Stück kosten. AMD hat schon Interposer vor Jahren genutzt für MCM Packages. Da würde ich mir mal weniger Kopf machen. Und vor allem nicht wegen einem zusätzlichen Speicherblock.
Also wenn man den Gerüchte derzeit folgt im Internet ist alles was AMD so auf ihren Folien vermeldet haben exorbitant teuer und praktisch unbezahlbar. Ist schon seltsam wenn da plötzlich jedes einzelne Pipifax Bauteil um Dimensionen teurer geschrieben wird.
Also wenn man den Gerüchte derzeit folgt im Internet ist alles was AMD so auf ihren Folien vermeldet haben exorbitant teuer und praktisch unbezahlbar. Ist schon seltsam wenn da plötzlich jedes einzelne Pipifax Bauteil um Dimensionen teurer geschrieben wird.
...
Also wenn man den Gerüchte derzeit folgt im Internet ist alles was AMD so auf ihren Folien vermeldet haben exorbitant teuer und praktisch unbezahlbar. Ist schon seltsam wenn da plötzlich jedes einzelne Pipifax Bauteil um Dimensionen teurer geschrieben wird.
Wenn die Kosten wirklich in diesen Dimensionen liegen - kombiniert mit dem 4/8GB Limt - kann es gut als Begruendung herhalten, dass NV erst einmal bis HBM V2 'abwartet'.
Gut - aber es ist nur ein Geruecht.. bisher..
TNT
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Das ist doch völliger Schmarrn. Da schreibt einer irgendwas und schon wird Alarm geschlagen.
")
Houston2603
Gesperrt
- Mitglied seit
- 21.11.2010
- Beiträge
- 123
- Renomée
- 1
Ist der auch... der selbe, der im selben .it Forum behauptete, bei ihm ginge FreeSync mit nem Beta Treiber, vom letzten Jahr... der verzählt nen quatsch zusammen, dass ist nicht mehr feierlich.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
AMD hat schon Interposer vor Jahren genutzt für MCM Packages.
Gibt verschiedene Arten von Interposer. Von einfacher billiger Platine bis hin zum teuren Silizium Interposer mit mehreren Metalllagen für die erstmal Belichtungsmasken erstellt werden müssen.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Wenn die Kosten wirklich in diesen Dimensionen liegen - kombiniert mit dem 4/8GB Limt - kann es gut als Begruendung herhalten, dass NV erst einmal bis HBM V2 'abwartet'.
Gut - aber es ist nur ein Geruecht.. bisher..
TNT
Nicht vergessen, dass die Herstellungskosten abhängig von der (gerade) produzierten Stückzahl sind. Beispiel: Lass bei AMD ein custom SoC entwickeln und bei einer Foundry produzieren und die ersten paar Stück kosten dich sagen wir 10 Mio $ pro Stück. Wenn du 1 Mio davon abnimmst, kommst du vielleicht herunter auf 100 USD pro Stück. Jetzt könnte jemand, der davon gehört hat, auch auf die Idee kommen lauthals zu rufen "10 Mio $ teurer Chip, kein bisschen konkurrenzfähig!". Mit dieser Aussage beweist er lediglich, dass er von industriellen Fertigungsprozessen und Marktwirtschaft wenig Ahnung hat.
Wichtig in diesem Fall sind die Stückkosten in Massenproduktion, nicht während der Risikoproduktion.
Daneben wage ich zu bezweifeln, dass NV schon Zugriff auf die IP hat. Wäre ich AMD und hätte derart in die Entwicklung dieser Speichertechnologie investiert, würde dafür sorgen, dass die Konkurrenz erstmal in der Warteschlange stehen darf.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Wir wissen doch ehh schon, dass die R9 390X nicht günstig werden wird, aber so ein bisschen Dual-Link-Interposer wird da kaum ins Gewicht spielen.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
HBM wird bestimmt ein neues Standbein, die Speicherdichte wird nochmals höher Mehr Speicher pro n³:
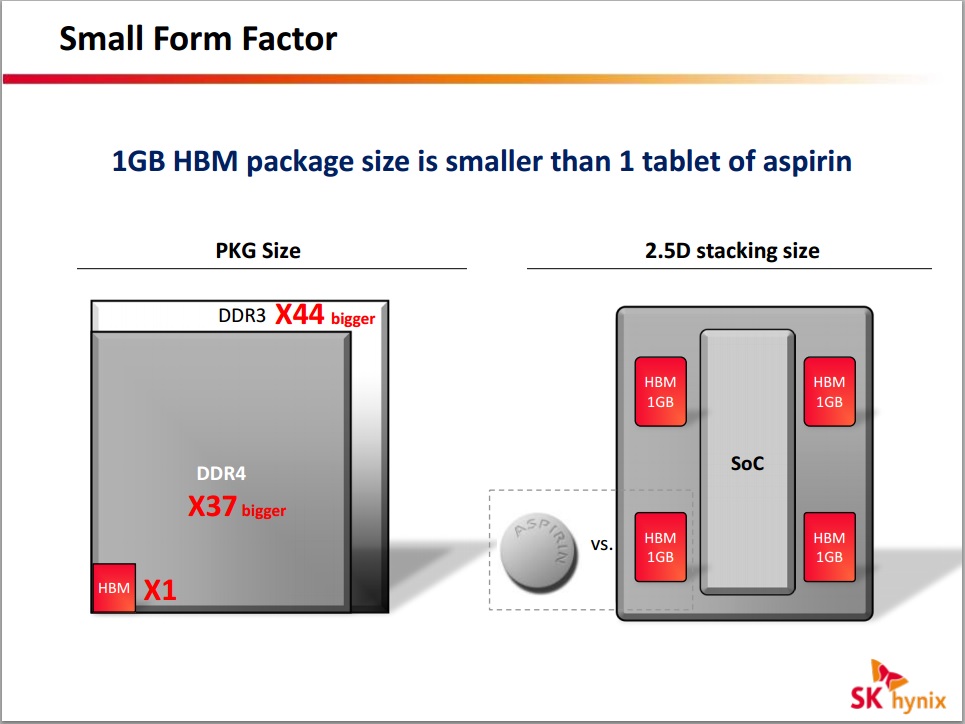
Die Folie von SKhynix hat interessante Bilder dabei.
Mir mach nur die Stromdichte etwas sorgen, allerdings sollte das mit Kohlenstoffnanoröhren für die "bumps" kein Problem sein:
Die Folie von SKhynix hat interessante Bilder dabei.
Mir mach nur die Stromdichte etwas sorgen, allerdings sollte das mit Kohlenstoffnanoröhren für die "bumps" kein Problem sein:
http://de.wikipedia.org/wiki/KohlenstoffnanoröhreFür die Elektronikindustrie sind vor allem die Strombelastbarkeit und die Wärmeleitfähigkeit interessant: Erstere beträgt schätzungsweise das 1000-fache der Belastbarkeit von Kupferdrähten, letztere ist bei Raumtemperatur mit 6000 W/(m·K) mehr als 2,5-mal so hoch wie die von natürlichem Diamant mit 2190 W/(m·K)[5], dem besten natürlich vorkommenden Wärmeleiter. Da CNTs auch Halbleiter sein können, lassen sich aus ihnen Transistoren fertigen, die höhere Spannungen und Temperaturen als Siliziumtransistoren aushalten. Erste experimentelle, funktionsfähige Transistoren aus CNTs wurden bereits hergestellt.
w0mbat
Commodore Special
- Mitglied seit
- 19.05.2006
- Beiträge
- 416
- Renomée
- 18
- Mein Laptop
- Lenovo ThinkPad L450@Ubuntu MATE
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5800X3D
- Mainboard
- MSI MAG B550M Mortar Max WIFI
- Kühlung
- NZXT Kraken X63
- Speicher
- G.SKILL F4-3600C17D-32GTZR
- Grafikprozessor
- XFX Speedster QICK 319 Radeon RX 6800 BLACK Gaming
- Display
- LG 34UC79G-B
- SSD
- 2TB WD_BLACK SN850X | 2TB Samsung 970 EVO Plus
- Soundkarte
- Realtek ALC1220
- Gehäuse
- Lian Li O11 Dynamic Mini
- Netzteil
- Cougar SF750 Platinum
- Tastatur
- CM QuickFire Rapid-i
- Maus
- Logitech G Pro X Superlight 2
- Betriebssystem
- Windows 11 Pro x64
- Webbrowser
- Firefox
Wir wissen doch ehh schon, dass die R9 390X nicht günstig werden wird, aber so ein bisschen Dual-Link-Interposer wird da kaum ins Gewicht spielen.
Es gibt keinen dual-link interposer. Das war ein fake.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Mir mach nur die Stromdichte etwas sorgen, allerdings sollte das mit Kohlenstoffnanoröhren für die "bumps" kein Problem sein:
Wieso Sorgen? Welche Ströme [mA] müssen denn in so einem Speicherstapel geleitet werden?
CNT Transistoren sind ein separates Thema, da dürfte aber noch ein Thread irgendwo offen sein.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Oge, bei einfachen Berechnungen klar, aber wenn da 9K oder 45Mbits Pixel in Echtzeit den 0/1 Zustand ändern, wird es lustig bzw bunt auf dem Schirm.Wieso Sorgen? Welche Ströme [mA] müssen denn in so einem Speicherstapel geleitet werden?
CNT Transistoren sind ein separates Thema, da dürfte aber noch ein Thread irgendwo offen sein.

Bisher sind es knapp 191 Ampere pro Tahiti GPU mit 2048 Shader bei 348Bit SIV.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Oge, bei einfachen Berechnungen klar, aber wenn da 9K oder 45Mbits Pixel in Echtzeit den 0/1 Zustand ändern, wird es lustig bzw bunt auf dem Schirm.
Bisher sind es knapp 191 Ampere pro Tahiti GPU mit 2048 Shader bei 348Bit SIV.
HBM benötigt keine derart hohen Ströme. Solange bspw. eine leistungshungrige GPU nicht in einem Stapel sitzt, werden auch keine TSVs damit belastet. Interessant wäre dein Argument, wenn sagen wir, 4 (Teil-)GPUs in einem Stapel aufeinandergesetzt werden.
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 985
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS PRIME X370-PRO
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Umso länger ich darüber nachdenke, umso mehr Sinn macht diese breite Aufstellung von AMD. AMD wird mittelfristig nämlich kaum um HMC herumkommen. HBM und HMC sind nicht bloß Konkurrenten, sondern ergänzen sich in vielen Teilbereichen. HBM ist vom Aufbau simpler gestrickt. Die Einfachheit von HBM ist jedoch keine Schwäche, sondern eine der Stärken. Die Herausforderung bei HBM liegt nicht im Funktionsprinzip, sondern in der Fertigung mit Stack samt TSV. Das hat man mit HMC gemein. Die Anbindung zum Host ist jedoch eine gänzlich andere. Bei HBM erfolgt diese über einen parallelen (obgleich mit 1024-Bit sehr breiten) Bus, wie schon seit DRAM Urzeiten üblich. Bei HMC wird dieser durch einen seriellen, Hochfrequenz-Link ersetzt. Das erinnert entfernt an die gescheiterten FB-DIMMs. Durch die seriellen Anbindung ist sogar eine Daisy Chain von mehreren HMCs möglich. Dadurch kommt man mit wesentlich weniger Datenleitungen aus und es sind größere Wegstrecken möglich. Es bedarf somit bei HMC keines teuren Interposers, weil die Chipstapel nicht in unmittelbarer Nähe zum Host untergebracht werden müssen. Das eröffnet neue Anwendungsfelder und gibt AMD mehr Spielraum. Bei GPUs wird man wohl auf absehbare Zeit allein auf HBM setzen, weil der bei HMC betriebene zusätzliche Aufwand keine ersichtlichen Vorteile bieten würde. Bei CPUs sieht es ein wenig anders aus. Dort könnte HMC den OEMs gerade recht kommen, weil er mehr Freiheiten bietet. Insbesondere wäre durch die Verwendung von HMC weiterhin ein getrennter Einkauf von CPU und DRAM möglich. Andernfalls müsste AMD sehen, wie sie den Tagespreis für den fest verlöteten Stacked DRAM an ihre Abnehmer weiterreichen. Letztendlich sind jedoch HBM und HMC beide nur Übergangstechnologien. Bei mobilen SoCs deutet sich an, dass die Zukunft bei der Integration von eDRAM mit Wide-I/O direkt in einen gemeinsamen Chipstapel mit CPU, GPU und FCH liegt, obwohl dies hohe Anforderungen an die Optimierung der Signalwege und die Kühlung stellt. Obgleich HBM und HMC nur Übergangstechnologien sind, werden sie trotzdem für viele Jahre die Platzhirsche sein.AMD ist übrigens im HMC Konsortium vertreten und auch im HBM Konsortium.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 57
- Aufrufe
- 13K