Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Projektnews MLC@Home : [TWIM Notes] Jan 5 2021 -- A 6 Month Retrospective
This Week in MLC@Home
Notes for Jan 5 2021
A weekly summary of news and notes for MLC@Home
Summary
Happy 2021!
This past week marked the 6 month anniversary of this project, so we wanted to look back at how far we've come, assess what's gone well, find areas we need to improve, and talk about the future.
Overall, the community response has been amazing and we feel like we've built a really solid foundation for understanding and evaluating neural networks. We'll list some of our thoughts below, and we encourage you, the community to comment below with your thoughts as well.
The Good
The actual work completed: You, the community, has trained over 260,000 neural networks for this project, modelling 110 different automata/machine types, with more in the works. When DS3 is done, we'll have over 1,000,000 trained networks. This is truly a unique contribution to science, and makes an amazing basis for study for years to come. I can already see 3 or 4 new lines of research coming from this dataset alone.
Community engagement: We've made a special effort to reach out to the community, with weekly updates and attempting to be active on the forums and on twitter. We're a small project from a small lab in a small school. While it can always be better, we'd like to think this is has been a plus. Additionally, we've received support from the BOINC developers and general community as a whole via the BOINCNetwork Discord server and BOINC mailing lists, which were fantastically helpful in getting the project up and running in the first place.
The technology: We're leveraging the BOINC infrastructure, and its working despite our WUs being a little out-of-the ordinary for it. We support 2 of the three major operating systems, on x86 and ARM, and GPUs from NVidia and AMD. Are they perfect? hardly. There's plenty of room for improvement and we're trying to make them better. But for 6 months in, we'll claim that's a very good start overall. The server side has gone well to, as the new server we moved to a few months ago has been a real help. Fun fact, for the first few months this project was run off an old thinkpad.. you make do with what you have.
Areas to Improve:
Publish papers and release a dataset: You deserve a timely release of the dataset you helped create. We really wanted to have that out by now, and we feel we have enough data now to do it. But it takes time to write and time to curate/prepare/to document the dataset for release, and frankly that's taking longer than it should. That's on us, and we're working on it. We should be looking at days to weeks, not months.
More supported platforms: We seek developers with C++ experience who can help us support new platforms, especially OSX and Android.
More collaborators on the science side: COVID has really made this extra hard. I'll be honest, many ML researchers I pitched this idea too weren't all that interested early on because a) they were skeptical that the system would work and/or that people would volunteer, b) we didn't support GPUs, and or c) were interested but had no time. Now that we do, and our volunteer pool has swelled in general, we need to re-engage. Published results will help our case.
This is still a 1-person operation: If I may get personal a minute, most of the above is due to the fact this is still a 1 person operation for the most part, and a person who is only a part time doctoral candidate with a full time job and family in addition to running this project. It's not like I'm a regular grad student who can sit for hours a day in a lab and write, either code or papers. I basically steal whatever time I can on the night and weekends. Doing a part-time doctorate is hard enough, choosing to create, develop, monitor, and moderate an entire volunteer computing project on top of that is frankly a bit nuts. But I'm passionate about the work we're doing here, and want to see it succeed. And I'm confident it will. Note: I try to say "we" when acting as project admin because I do feel eventually there will be more than just me, however that's not the case (yet).
What the future holds
MLDS: Publish, both the first rounds of datasets and a paper or two. This is our top priority.
MLDS: DS4 will switch to training CNNs for image classification, leading to a whole new set of insights and questions.
It's important if MLC is to grown and continue that it grown beyond the MLDS application. Therefore, engage with new researchers and research thrusts that are amenable to our unique project architecture. Hyperparameter and architecture search seem extremely well suited for our system.
There are plenty more things we could mention, like tweaks to validations (some good, some .. err..less so), having a podcast made about the project, the generosity we've received from other project admins helping us getting our feet under us. And, of course, badges. We, as admins, have learned a lot about how to run a project, and despite some stumbles we hope you find the science compelling, the project interesting, and the community welcoming.
At 6 months in, we're on the cusp of real results, which should feed lots more interesting science. Thanks to all our volunteers for helping push the science of machine learning forward, and we hope to give you reason to continue to support us for many years to come.
If you have feedback, please leave it in the comments below.
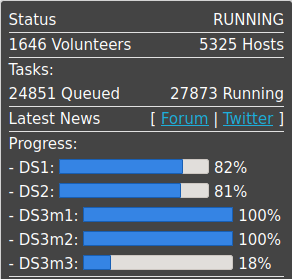
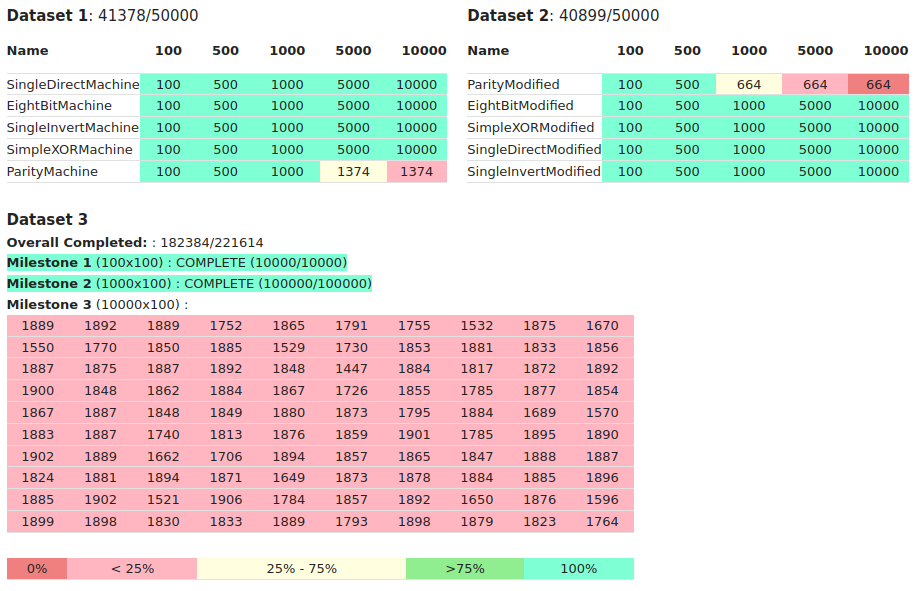
Project status snapshot: (note these numbers are approximations)