App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Opteron HT-Link
- Ersteller bschicht86
- Erstellt am
Nochmal eine kurze Rückmeldung bezüglich der NUMA-Problematik, bzw. was man davon in "der Praxis" bemerkt. Praxis ist bei mir ein optisches Simulationsprogramm.
Ich habe 12 Kerne (auf 2 Chips), die mit 12 Rechenthreads (alle single-threaded) gefüttert werden. Getestet wurden drei Zuweisungsmodell: a) Windows weist die Threads automatisch auf die Kerne zu. b) Ich lege die Threads nacheinander auf einzelne Kerne fest (Kern 0, der nächste Kern 1, dann Kern 2, ...), auf die Gefahr hin, dass die Daten nicht am ausführenden Chip liegen. c) Ich starte jede Instanz mit dem Konsolenbefehl start /affinity - die Daten liegen dann immer im lokalen Speicher. Getestet wurde an einer kleinen Testaufgabe die ca. 10 Minuten läuft.
a) 707 s - 107,4 %
b) 665 s - 101 % (+-8 s)
c) 658 s - 100 % (sehr stabile Zeit)
Meine Applikation scheint den Hypertransportbus zwischen den Kernen nicht sehr zu belasten, die Latenzen werden wohl vom Cache ganz gut abgefangen. Allein durch das unterbleibende Umsortieren der Aufgaben zwischen den Kernen, gewinne ich pro Simulationslauf real dann durchaus über einen Tag. Die richtige NUMA-Anordnung scheint dagegen weniger gravierend zu sein. Bei einem Viersockelsystem, speziell mit langsamen HT mag das dann anders aussehen.
Ich habe 12 Kerne (auf 2 Chips), die mit 12 Rechenthreads (alle single-threaded) gefüttert werden. Getestet wurden drei Zuweisungsmodell: a) Windows weist die Threads automatisch auf die Kerne zu. b) Ich lege die Threads nacheinander auf einzelne Kerne fest (Kern 0, der nächste Kern 1, dann Kern 2, ...), auf die Gefahr hin, dass die Daten nicht am ausführenden Chip liegen. c) Ich starte jede Instanz mit dem Konsolenbefehl start /affinity - die Daten liegen dann immer im lokalen Speicher. Getestet wurde an einer kleinen Testaufgabe die ca. 10 Minuten läuft.
a) 707 s - 107,4 %
b) 665 s - 101 % (+-8 s)
c) 658 s - 100 % (sehr stabile Zeit)
Meine Applikation scheint den Hypertransportbus zwischen den Kernen nicht sehr zu belasten, die Latenzen werden wohl vom Cache ganz gut abgefangen. Allein durch das unterbleibende Umsortieren der Aufgaben zwischen den Kernen, gewinne ich pro Simulationslauf real dann durchaus über einen Tag. Die richtige NUMA-Anordnung scheint dagegen weniger gravierend zu sein. Bei einem Viersockelsystem, speziell mit langsamen HT mag das dann anders aussehen.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich bin mir nicht sicher inwiefern du den NUMA-Einfluß messen kannst wenn alle Threads ausschließlich den lokalen Speicher nutzen. Dass dann keine HT-Last anliegt ist eigentlich klar. Sind die Zahlen identisch wenn du /affinity nicht setzt?
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Natürlich kann ein Opteron 2x 144Bit (bzw. 2x128Bit + 2x16Bit für ECC) er hat doch allgemein doppelt so viele Einheiten wie ein FX-8000.Egal welches System, du kannst bei 144 Bit nicht gleichzeitig schreiben und lesen.
Die 144 Bit stammen von dir.
--- Update ---
Da brauchen wir gar nichts abgleichen. Diese Begriffe sind ganz genau in den JEDEC-Dokumenten definiert. Die entsprechende Dokumentennummer darfst du dir selber suchen.
Leider hast du die richtigen Begriffe NICHT richtig genutzt
Nochmal: Die drei "Datenleitungen" dienen zur Auswahl der acht Banks. Deswegen heißen sie auch BA[0..2] und nicht RA[0..2].
Ein DIMM kann nur maximalzweivier Ranks haben, da es dafür nur zwei "Datenleitungen" gibt.
Zeig mir ein DIMM, dasmehr als zweiacht Ranks hat!

Hab gerade gelesen, dass bei DDR4 bis 512GByte pro Riegel möglich sind: http://www.hardwareschotte.de/magazin/was-ist-neu-bei-ddr4-ram-a41651
Im Gegensatz zu DDR3, wo noch maximal vier Ranks und acht Bänke pro Modul möglich waren, sind es bei DDR4 mit acht Ranks und 16 Bänken genau doppelt so viele. Diese 16 Bänke werden bei DDR4 in Gruppen à vier Bänke aufgeteilt, wobei jede Speicherzelle einer Bank wiederum in Zeilen und Spalten unterteilt ist. Dabei liegt die Speicherkapazität einer Zeile bei DDR3-RAM bei 1 kByte oder 2 kByte - bei DDR4 sind es lediglich noch 512 Byte.
a) Ist ohne Affinity. b) Ist datenseitig quasi ohne Affinity, für den Kern mit Affinity.Ich bin mir nicht sicher inwiefern du den NUMA-Einfluß messen kannst wenn alle Threads ausschließlich den lokalen Speicher nutzen. Dass dann keine HT-Last anliegt ist eigentlich klar. Sind die Zahlen identisch wenn du /affinity nicht setzt?
Die Problem ist, dass ich von der Hochsprache C# nicht ohne weiteres eine externe Applikation auf einem Kern starten kann. Ich kann sie nur starten und sie danach an einen Kern binden. In den zuvor absolvierten paar Taktzyklen hat Windows aber schon automatisch entschieden, auf welchem Knoten die Daten abgelegt werden. Bei der Hälfte der Fälle müsste ich daneben liegt, trotzdem scheint das hinreichend gut zu funktionieren.
Bei Bschichts 4-Knoten System hat aber ja nicht mal das Messen der HT-Bandbreite funktioniert. Insofern, ist meine Aussage nur auf Sockel F Systeme mit zwei Sockeln beschränkt.
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Im BIOS gibt es schonmal keine Option auf Ganged oder Unganged. Also muss ich wohl mit meinen 2,5GB/s leben 
Hab nun auch ein neues Netzteil besorgt, das alte war ja hoffnungslos an der "Kotzgrenze". Jetzt ist die ganze Apparatur fast so leise wie der AM1-PC.
Problem bleibt aber immernoch der niedrige HT-Takt
Hab nun auch ein neues Netzteil besorgt, das alte war ja hoffnungslos an der "Kotzgrenze". Jetzt ist die ganze Apparatur fast so leise wie der AM1-PC.
Problem bleibt aber immernoch der niedrige HT-Takt
Ob der niedrige HT-Takt denn ein Problem darstellt, wissen wir streng genommen noch nicht - es ist eine Hypothese, die quantifiziert werden sollte. Vielleicht kannst du ja mittels BOINC mal versuchen, rauszubekommen, ob der langsame Hyperlink überhaupt stört?
Ich hatte vor ewigen Zeiten mal versucht die Geschwindigkeit einer BOINC-Anwendung zu messen [1]. Die ganze Vorgehensweise, wie man das Benchmark baut, ... , steht dort drin. Das lieferte im Prinzip brauchbare quantitative Ergebnisse. Im Prinzip kannst du das gleiche mit deiner bevorzugten Anwendung machen. Du lädst 24 WUs runter, setzt alle sofort auf Pause und machst ein Backup des Clienten. Das Backup kannst du später immer wieder einspielen.
Dann lässt du das Benchmark mit 24 physikalischen Kernen durchlaufen, misst den Fortschritt. Dann spielst du das Backup ein und rechnest die gleichen WUs mit nur einer physikalischen CPU (6 Kerne, die anderen drei CPUs nimmst du aus dem System raus) und wirst sehen, wie schnell sie dann laufen.
Mit den Messwerten kannst du dann abschätzen, inwiefern der HT-Link nun ein Problem darstellt.
[1] - http://foveon.de/sonstiges/cpdn/
Ich hatte vor ewigen Zeiten mal versucht die Geschwindigkeit einer BOINC-Anwendung zu messen [1]. Die ganze Vorgehensweise, wie man das Benchmark baut, ... , steht dort drin. Das lieferte im Prinzip brauchbare quantitative Ergebnisse. Im Prinzip kannst du das gleiche mit deiner bevorzugten Anwendung machen. Du lädst 24 WUs runter, setzt alle sofort auf Pause und machst ein Backup des Clienten. Das Backup kannst du später immer wieder einspielen.
Dann lässt du das Benchmark mit 24 physikalischen Kernen durchlaufen, misst den Fortschritt. Dann spielst du das Backup ein und rechnest die gleichen WUs mit nur einer physikalischen CPU (6 Kerne, die anderen drei CPUs nimmst du aus dem System raus) und wirst sehen, wie schnell sie dann laufen.
Mit den Messwerten kannst du dann abschätzen, inwiefern der HT-Link nun ein Problem darstellt.
[1] - http://foveon.de/sonstiges/cpdn/
Falls doch mal mit dem BKDG was gemacht werden soll geht lesen/schreiben hiermit: http://www.mdcc-fun.de/k.helbing/Bus-Scan/. Die benötigten WinRing0-Dateien gibts dort auch (eigenes Verzeichnis). Bus-Nr.=0x00, Device-Nr.=0x18, Function und Address lt. BKDG.
Schreiben ist aber Muster ohne Wert, wenn ein Neustart gefordert wird.
Schreiben ist aber Muster ohne Wert, wenn ein Neustart gefordert wird.
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Also, mit dem Tool kann ich problemlos die HT-Frequenzen schalten, jedoch gibt es da noch einen riesigen Stolperstein.
Hier sieht man schön die Liste der Links.

Hier zu meinem Problem:

Wie man sehen kann, schaltet ein Befehl von allen "Node" den einen Link gleichzeitig. Das wär zwar nicht das Problem, aber an den ersten beiden "Node" hängt ja der Chipsatz, der nur 1GHz kann. Wär der an Link 0, statt Link 1 geklemmt, wär es ebenfalls kein Problem.
Das blöde daran ist, es will die WinRing0 nicht initialisieren, obwohl sie ja von TurionPowerControl erfolgreich benutzt wird.
--- Update ---
Aha, wozu hat man Augen, wenn diese das wichtigste übersehen.![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]") (-node)
(-node)

Hat also mit einer Batch-Datei geklappt und habe alle nennenswerten cohärenten Links auf 2,2GHz bekommen. Ich hoffe nur, dass Prime95 mit 60GB RAM ein guter HT-Link-Tester (Stabilität) ist.
--- Update ---
Hier noch der Auszug meiner Batch, falls das noch irgendwen interessiert:
Hier sieht man schön die Liste der Links.
Hier zu meinem Problem:
-htset <link> <value>
Sets the multiplier of the specified hypertransport link for active node. May cause instability
and machine freezing.
Wie man sehen kann, schaltet ein Befehl von allen "Node" den einen Link gleichzeitig. Das wär zwar nicht das Problem, aber an den ersten beiden "Node" hängt ja der Chipsatz, der nur 1GHz kann. Wär der an Link 0, statt Link 1 geklemmt, wär es ebenfalls kein Problem.
Falls doch mal mit dem BKDG was gemacht werden soll geht lesen/schreiben hiermit: http://www.mdcc-fun.de/k.helbing/Bus-Scan/.
Das blöde daran ist, es will die WinRing0 nicht initialisieren, obwohl sie ja von TurionPowerControl erfolgreich benutzt wird.
--- Update ---
Aha, wozu hat man Augen, wenn diese das wichtigste übersehen.
(-node)Hat also mit einer Batch-Datei geklappt und habe alle nennenswerten cohärenten Links auf 2,2GHz bekommen. Ich hoffe nur, dass Prime95 mit 60GB RAM ein guter HT-Link-Tester (Stabilität) ist.
--- Update ---
Hier noch der Auszug meiner Batch, falls das noch irgendwen interessiert:
Code:
TurionPowerControl -node 0 -htset 0 12
TurionPowerControl -node 1 -htset 0 12
TurionPowerControl -node 2 -htset 1 12
TurionPowerControl -node 3 -htset 1 12
TurionPowerControl -htset 2 12
Zuletzt bearbeitet:
Wenn es das Netzteil hergibt, nimmt Linpack. Da rechnen alle Kerne gemeinsam an einem Problem (sollten also den HT-Link benutzen), und du hast auch gleich einen Benchmark-Wert zum Quantifizieren des Vorteils eines hohen HT-Taktes.
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Also Linpack bringt auch keinen Vorteil zu Tage.
Mit dem neuen Netzteil kann ich nun auch alle 24 kerne ohne Abschaltung benutzen (Altes NT hat bei Last losgeheult, jetziges bleibt fast Silent)
Konkret in Zahlen:
1,0GHz HT: Dauer 1026s, 170,3GFlops
2,2GHz HT: Dauer 1032s, 169,3GFlops
Auslastung 32GB RAM
Mit dem neuen Netzteil kann ich nun auch alle 24 kerne ohne Abschaltung benutzen
(Altes NT hat bei Last losgeheult, jetziges bleibt fast Silent)Konkret in Zahlen:
1,0GHz HT: Dauer 1026s, 170,3GFlops
2,2GHz HT: Dauer 1032s, 169,3GFlops
Auslastung 32GB RAM
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@bschicht86
Die GFlops sind schon sehr gut, mit 8x 4GHz (6GByte RAM Auslastung) kommt mein FX-8350 gerade mal auf 75 GFlops mit AVX.
Hier gibt es eine Übersicht bezüglich Opteron HT-Link: http://www.qdpma.com/systemarchitecture/SystemArchitecture_Opteron.html
HT-Assist soll eine höhere Speicherbandbreite beim Streamen ermöglichen.
Die GFlops sind schon sehr gut, mit 8x 4GHz (6GByte RAM Auslastung) kommt mein FX-8350 gerade mal auf 75 GFlops mit AVX.
Hier gibt es eine Übersicht bezüglich Opteron HT-Link: http://www.qdpma.com/systemarchitecture/SystemArchitecture_Opteron.html
HT-Assist soll eine höhere Speicherbandbreite beim Streamen ermöglichen.
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Was hast du denn deinem FX angetan? 
Meiner kommt bei 4GHz auf 80,8GFlops. (Ebenfalls 6GB RAM)
(Ebenfalls 6GB RAM)
Meiner kommt bei 4GHz auf 80,8GFlops.
(Ebenfalls 6GB RAM)WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@bschicht86
Das kommt immer auf das System an, mit vielen Hintergrund Programmen geht es schon mal in den Keller mit den GFlops.
Immerhin 97GFlops mit 4.7GHz, zwar wird ein Fehler ausgeworfen, aber die Berechnungen sind fertig und das Konzept steht:
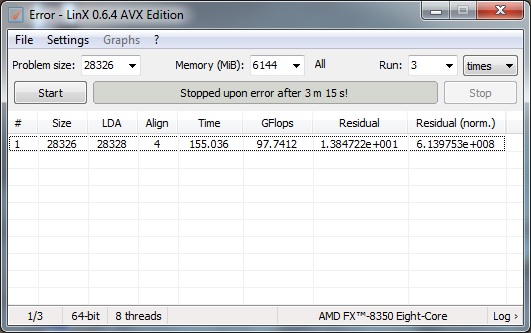
Das kommt immer auf das System an, mit vielen Hintergrund Programmen geht es schon mal in den Keller mit den GFlops.
Immerhin 97GFlops mit 4.7GHz, zwar wird ein Fehler ausgeworfen, aber die Berechnungen sind fertig und das Konzept steht:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Keine Ahnung warum ein Fehler kommt, der PC läuft schon mehrer Tage mit Dauerlast durch.Was bringen dir 97 GFlops, wenn das Ergebnis falsch ist (siehe den normierten Restfehler ganz rechts)?
Von daher interessiert mich ein nicht produktives einzel Programm eher weniger.
")
Ich habe mal meinen Dual Opteron 2435 mit dem StreamBenchmark getestet. 12 Kerne kann man dort nicht auswählen, insofern lief das nicht so wirklich gut. Ich kam mit 4 von 12 Kernen auf ca. 14 GB/s an Speicherbandbreite, halte das Ergebnis durch eine Verwendung von allen Kernen noch für steigerbar.
Hyperthreading kann man in dem Progrämmchen ausschalten, von 2er Potenzenabweichende Kernzahlen sind hingegen ein Problem.
Hyperthreading kann man in dem Progrämmchen ausschalten, von 2er Potenzenabweichende Kernzahlen sind hingegen ein Problem.
Starsky
Captain Special
- Mitglied seit
- 24.03.2004
- Beiträge
- 239
- Renomée
- 3
- Standort
- Celestes
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 3900X
- Mainboard
- MSI X570 Unify
- Kühlung
- Noctua NH-15D
- Speicher
- 2x 16 Gb Kingston HyperX Fury DDR4-3200MHz
- Grafikprozessor
- Zotac 1080 AMP! Extreme Plus
- Display
- 3x AOC Displays
- SSD
- Samsung NVME EVO 960 / Kingston HyperX Predator
- Gehäuse
- CM Cosmos II
- Netzteil
- Antec HPC 1300
- Betriebssystem
- Windows 10
Der Thread ist zwar nicht mehr der neuste aber extrem informativ für mich gewesen.
Vielleicht noch ein guter Tipp: mit SiSoft Sandra kann man die Speicherbandbreite messen, es zeigt auch an ob NUMA aktiv ist - drastische Unterschiede entstehen hier wenn man Node Interleaving an bzw. ausschaltet.
Mit dem Tool TurionPowerControl lässt sich auch der nforce nfp2050/3600 vonn 1000Mhz auf 2200Mhz bewegen, aber SiSoft zeigt danach keinen nennenswerten Unterschied an
Vielleicht noch ein guter Tipp: mit SiSoft Sandra kann man die Speicherbandbreite messen, es zeigt auch an ob NUMA aktiv ist - drastische Unterschiede entstehen hier wenn man Node Interleaving an bzw. ausschaltet.
Mit dem Tool TurionPowerControl lässt sich auch der nforce nfp2050/3600 vonn 1000Mhz auf 2200Mhz bewegen, aber SiSoft zeigt danach keinen nennenswerten Unterschied an
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 36K
- Antworten
- 25
- Aufrufe
- 6K
- Antworten
- 0
- Aufrufe
- 25K