App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Bobcat, das Bulldözerchen
- Ersteller Opteron
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ok, sagen wir mal der Pfeil ist falsch rum. Dann bemäkel ich mal Deine Idee des RegRead. Da steht sicher nichts Relavantes für die AGU drin. Aber den REgread braucht man trotzdem, da wenigstens 1 Parameter einer Instruktion ja ein Register sein sollteDa ist auch ein Fehler im Bobcat-Pipelinediagramm. Das ist ja gewissermaßen ein Ablaufplan, der immer strikt von links nach rechts abläuft und eben Verzweigungen entsprechend der Pfeile enthalten kann. Das Problem ist jetzt, daß der Pfeil nach RegRead zu AGU offensichtlich in die falsche Richtung zeigt (weg von AGU, aber dann würde man da ja nie hinkommen). Denn das läuft doch so ab:
Ein AGU-Befehl wir gescheduled, die Adresse/Offset/Scale wird aus den Registern gelesen (RegRead), der AGU-µOp macht eine Adresse draus (AGU), woraufhin auf den DatenCache zugegriffen wird (DC1+2). Tritt dabei ein L1-Miss auf, geht es nach DC2 mit dem L2-Zugriff weiter, der dann irgendwann auch das Ergebnis liefert. In jedem Fall kehrt man irgendwann auf die "Hauptlinie" des Diagramms zurück und schreibt die Daten in ein Register (Writeback).
Naja ein Pfeil von DC1 zur ALU wäre schon recht nett, fände ich, aber gut. Wenns nur ein Ablaufdiagramm für entweder ALU oder AGU Ops ist ... ok.Wie gesagt ist das ein Ablaufdiagramm, kein Datenflußdiagramm. Result-Forwarding (für ALUs wichtiger) gibt es natürlich trotzdem, so daß eine abhängige ALU-Instruktion, die auf eine AGU-Instruktion gewartet hat, direkt loslegen kann, wenn die AGU-Instruktion bei Writeback ankommt. Sowas hat der Scheduler im Griff. Deswegen steht ja auch "Load-Use-Latency L1 Hit: 3-cyles" dran, sonst wären es 5 (3 für die AGU-Instruktion und Zugriff + Writeback der AGU + ReadReg der ALU).
Ja. Keine Einsprüche ^^Was uns zeigt, das µcoded Instruktionen 2 Zyklen Penalty haben. Die Fast-Decoder erzeugen einen Offset in den µCode-ROM, der Zugriff dauert 2 Takte, dann geht es weiter wie normal.
a) Ja, eine ALU braucht keine Adresse ^^Siehe oben. Eine ALU kann mit einer Adresse gar nichts anfangen, die rechnet immer nur mit Werten in Registern. Die AGU liefert die Daten im Registerfile ab, danach kann die ALU mit den Daten rechnen.Zitat von Opteron
Für die AGU hieße das, dass die AGU ne Adresse vor die ALU liefert und dann die Berechnung losgeht.
b) Einspruch: Eine CISC ALU kann auch direkt mit Werten aus dem Speicher rechnen. Nur RISC Maschinen ALUs haben die Einschränkung nur mit Registerdaten arbeiten zu können.
c) Die AGU liefert nichts ins Registerfile ab
") Die AGU generiert nur ne Adresse, die dann direkt der L/S Unit übergeben wird.
Die AGU generiert nur ne Adresse, die dann direkt der L/S Unit übergeben wird.Ja - und nein .. zumindest bei K8/10 gabs ja die MacroOps. Da läuft je eine ALU und AGU in Form einer MacroOp zusammen durch die Pipeline. Erst der Scheduler splittet das dann auf. Deswegen verwirrt mich das etwas, ich geh da von einer vollen MacroOp aus, und will da deren Weg nachvollziehen können. So hat man ja "nur" ein Pipeline Diagramm entweder für ALU oder AGU Opteration - langweilig ^^Nö, eine AGU-Instruktion ist eine AGU-Instruktion. Eine abhängige (oder auch unabhängige) ALU-Instruktion läuft getrennt durch die Pipeline.Zitat von Opteron
Problem bei Deiner Idee, dass das eingeschoben wird und die ALU Stufe damit ersetzt wird: Wo ist die ALU ? Wird dann nichts berechnet ?
Ok würde dann auch Sinn machen und ich frag mich dann langsam, ob man das ganze nicht einfacher machen könnte ^^Nö, das sind praktisch zwei parallele Pipes. Die waren bloß zu faul eine Verzweigung (oder eben 2 Pipelinediagramme) wie bei Bobcat zu zeichnen (wo sie ja auch glatt den Pfeil falsch rum erwischt haben). Wie oben schon gesagt, beträgt die Branch Mispredict Penalty eines K10 nur 10 Takte, die beiden DC-Stufen treffen also wie bei Bobcat nur für AGU-Instruktionen zu.
Wieso muss das alles in 1 Diagramm gepfercht werden ... wie wärs mit übersichtlichen Einzeldiagrammen ^^
Hm, ok ne ganze Cacheline in 2 Takten .. klingt logisch, ist mal mein FavoritDer wird vielleicht immer gleich eine ganze Cacheline (64Byte) über 2 Takte fetchen (oder die 256 Bit kommen dadurch zustande, daß über 2 Takte je 128Bit geholt werden) und erst damit weitermachen, wenn der entsprechende Puffer hinreichend leer ist. Wenn ich mich richtig erinnere hatte K8 einen 128Bit fetch in einen 24 Byte Puffer. Die nächsten 16 Byte konnten erst gefetcht werden, wenn im Puffer 8 Byte oder weniger übrig waren. Und dann kann es schon zu einem temporären Engpaß kommen. Aber wie gesagt, nagle mich nicht darauf fest.
Danke & ciao werd mal noch ne Nacht drüber schlafen und morgen versuchen das Pipelinefiasko zu beheben. Wahrscheinlich werd ich meine eigenen Diagramme Zeichnen müssen (falls jemand Softwaretipps für sowas hat (Visio ?), bitte gerne).
Alex
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ich bin wieder da und habe mich so langsam wieder eingefunden Es gab ja auch soviel Neues letzte Woche.
Powerpoint ist für Pipelinezeichnen wahrscheinlich ausreichend solange sie nicht so überfrachtet wird. Der Pfeil bei der AGU-Stufe ist ja tatsächlich falsch und soll wohl andersherum stehen. Das ginge per Photoshop. Ist ja derzeit in Mode
Waren die zusätzlichen Fetch-Stufen nicht im Zusammenhang mit Prefetch genannt? Bei einer falschen Vorhersage kämen weitere Fetch-Zyklen hinzu. Außerdem wurden irgendwo auch das maximale Decoding von 22 Bytes pro Takt genannt.
Sonst hier auch noch meine kleinen Anmerkungen:
- Pentium 1 ist In-Order superskalar, PPro hatte erst OoOE.
- Virtualisierung u. 64bit eröffnen dem Bobcat auch weitere Einsatzgebiete als einem Atom.
- die kleine FPU ist natürlich praktisch und hier wurde im Paper zwar nur der Multiplier beschrieben, welcher aber oft auch die meiste Fläche beansprucht:

Edit: Ich habe die Pipeline mal fix in MSPaint editiert (mehr habe ich hier nicht):
http://info.nuje.de/bobcat_pipeline_new.jpg
oder
http://info.nuje.de/bobcat_pipeline_new.png
Achso, der Zoo-Bobcat ist hier :
http://info.nuje.de/Bobcat_pic.jpg
Es gab ja auch soviel Neues letzte Woche.Powerpoint ist für Pipelinezeichnen wahrscheinlich ausreichend solange sie nicht so überfrachtet wird. Der Pfeil bei der AGU-Stufe ist ja tatsächlich falsch und soll wohl andersherum stehen. Das ginge per Photoshop. Ist ja derzeit in Mode
Waren die zusätzlichen Fetch-Stufen nicht im Zusammenhang mit Prefetch genannt? Bei einer falschen Vorhersage kämen weitere Fetch-Zyklen hinzu. Außerdem wurden irgendwo auch das maximale Decoding von 22 Bytes pro Takt genannt.
Sonst hier auch noch meine kleinen Anmerkungen:
- Pentium 1 ist In-Order superskalar, PPro hatte erst OoOE.
- Virtualisierung u. 64bit eröffnen dem Bobcat auch weitere Einsatzgebiete als einem Atom.
- die kleine FPU ist natürlich praktisch und hier wurde im Paper zwar nur der Multiplier beschrieben, welcher aber oft auch die meiste Fläche beansprucht:
Edit: Ich habe die Pipeline mal fix in MSPaint editiert (mehr habe ich hier nicht):
http://info.nuje.de/bobcat_pipeline_new.jpg
oder
http://info.nuje.de/bobcat_pipeline_new.png
Achso, der Zoo-Bobcat ist hier
:http://info.nuje.de/Bobcat_pic.jpg
Zuletzt bearbeitet:
??Ok, sagen wir mal der Pfeil ist falsch rum. Dann bemäkel ich mal Deine Idee des RegRead. Da steht sicher nichts Relavantes für die AGU drin. Aber den REgread braucht man trotzdem, da wenigstens 1 Parameter einer Instruktion ja ein Register sein sollte
Na sicher benötigt eine AGU Register! Stelle Dir mal vor, Du willst auf die Speicherstelle [rax+rbx*8+8] zugreifen, dann muß die AGU wohl die Werte der Register rax und rbx lesen. Wenn Du was schreiben willst, muß auch der Wert, der geschrieben werden soll, aus dem Regfile gelesen werden.
Nur werden eben seit K5 bzw. Pentium Pro keine CISC-ALUs mehr verbaut. Deswegen benötigt man ja den ganzen x86->µOps-Decoding-Kladderadatsch, damit man dahinter einen schönen RISC-Kern packen kannb) Einspruch: Eine CISC ALU kann auch direkt mit Werten aus dem Speicher rechnen. Nur RISC Maschinen ALUs haben die Einschränkung nur mit Registerdaten arbeiten zu können.
Die dann den Zugriff macht (das sind die DC-Stufen, DC steht für Data Cache) und den gelesenen Wert wird dann in der Writeback-Stufe ins Registerfile geschrieben (wenn was in den Speicher geschrieben wird, natürlich nicht). Wie sonst sollen 3 Zyklen load-to-use Latency hinkommen? Im Falle eines Cache-Misses, verzweigt die Pipeline ja nicht umsonst zum L2-Zugriff.c) Die AGU liefert nichts ins Registerfile ab
Aber so ist es nunmal. Auch im K8/K10 haben die ALU-µOp- und AGU-µOp-Bestandteile nach ihrer Trennung unterschiedliche Wege genommen.Ja - und nein .. zumindest bei K8/10 gabs ja die MacroOps. Da läuft je eine ALU und AGU in Form einer MacroOp zusammen durch die Pipeline. Erst der Scheduler splittet das dann auf. Deswegen verwirrt mich das etwas, ich geh da von einer vollen MacroOp aus, und will da deren Weg nachvollziehen können. So hat man ja "nur" ein Pipeline Diagramm entweder für ALU oder AGU Opteration - langweilig ^^
Dann hast Du insgesamt 3 oder noch mehr Diagramme mit lauter unterschiedlichen Latenzen. Wir auch irgendwie unübersichtlich.Ok würde dann auch Sinn machen und ich frag mich dann langsam, ob man das ganze nicht einfacher machen könnte ^^
Wieso muss das alles in 1 Diagramm gepfercht werden ... wie wärs mit übersichtlichen Einzeldiagrammen ^^
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@Dresdenboy:
Ok, Danke, dass Du es Dir angeschaut hast. Also dann ganz sicher der Pfeil falsch herum.
Da nehm ich dann mal als Ersatz gleich Dein photoshop äh - paint Bild, haha")
Dann mal zum Text, bzw. die Eckdaten:
a) In was gibt man jetzt die Branch misprediction an ? Das ist doch immer der best case, oder ?
Also im Vergleich zw. K8 & Bobcat dann der Fall ohne AGU, das wären dann die
10 <> 13 Takte, richtig ?
Also haben wir 3 Stufen mehr, das sind
a) RegRead
b) Decode 3 (bzw. Decode 2, je nach Zählweise)
c) WriteBack
Die BobC Zusatzstufe Decode 2 (oder 1) überlappt sich mit der Pick Unit des K8, und "zählt" somit nicht.
Stimmen die Fakten jetzt ? Dann bitte kurzes "Go" von Dir und/oder Gipsel, dann mach ich mich mals ans Umschreiben.
@Gipsel:
Hab in Agners OptimierungsPDF noch das hier gefunden:
Edit:
@Gipsel:
Hat sich überlappt, Antwort folgt, aber das passt schon so denke ich mal, gibts nicht viel dagegen zu sagen
ciao
Alex
Ok, Danke, dass Du es Dir angeschaut hast. Also dann ganz sicher der Pfeil falsch herum.
Da nehm ich dann mal als Ersatz gleich Dein photoshop äh - paint Bild, haha
Dann mal zum Text, bzw. die Eckdaten:
a) In was gibt man jetzt die Branch misprediction an ? Das ist doch immer der best case, oder ?
Also im Vergleich zw. K8 & Bobcat dann der Fall ohne AGU, das wären dann die
10 <> 13 Takte, richtig ?
Also haben wir 3 Stufen mehr, das sind
a) RegRead
b) Decode 3 (bzw. Decode 2, je nach Zählweise)
c) WriteBack
Die BobC Zusatzstufe Decode 2 (oder 1) überlappt sich mit der Pick Unit des K8, und "zählt" somit nicht.
Stimmen die Fakten jetzt ? Dann bitte kurzes "Go" von Dir und/oder Gipsel, dann mach ich mich mals ans Umschreiben.
@Gipsel:
Hab in Agners OptimierungsPDF noch das hier gefunden:
Misprediction penalty
AMD manuals say that the branch misprediction penalty is 10 clock cycles if the code
segment base is zero and 12 clocks if the code segment base is nonzero. In my
measurements, I have found a minimum branch misprediction penalty of 12 and 13 clock
cycles, respectively. The code segment base is zero in most 32-bit operating systems and
all 64-bit systems. It is almost always nonzero in 16-bit systems (see page 129).
Also nehmen wir mal die idealen 10 Takte, oder ? Das sollte dann ja passen, Die 13 Takte bei Bobcat sind sicherlich auch best case.The exact length of the pipelines is not known but it can be inferred that it has approximately
twelve stages, based on the fact that the branch misprediction penalty is measured to 12
clock cycles.
Das mit dem P1 ist klar, ich wollte da eigentlich "nach dem P1" schreiben (und dachte, dass ich das auch gemacht hätte), aber irgendwie ist wohl einer unüberlegten Umformulierung zum Opfern gefallen ^^ Danke fürs Aufpassen.- Pentium 1 ist In-Order superskalar, PPro hatte erst OoOE.
Edit:
@Gipsel:
Hat sich überlappt, Antwort folgt, aber das passt schon so denke ich mal, gibts nicht viel dagegen zu sagen
ciao
Alex
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Bzgl. Agners Kommentar: Da habe ich auch keine Erklärung parat, warum die 10 Zyklen da nicht erreicht werden. Die von dir aufgezählten Stufen wären zumindest der sichtbare Unterschied.
Anandtech hat den Pfeil gleich weggelassen:
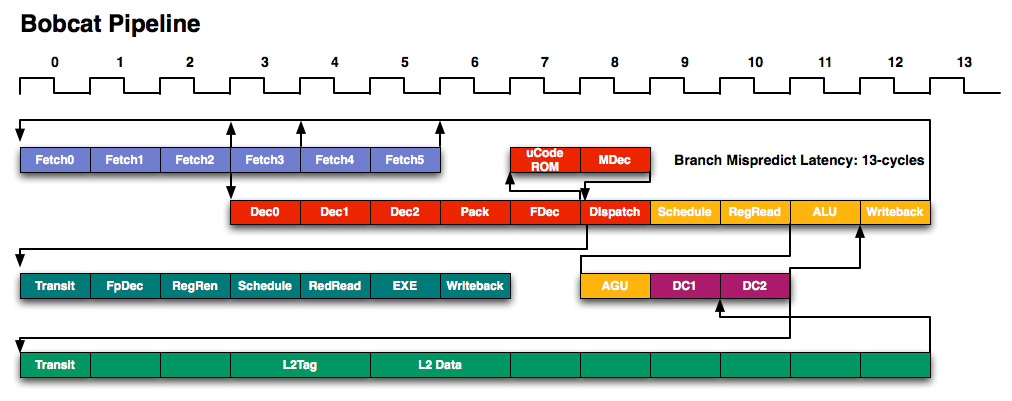
Spannender ist natürlich, wie oft die Penalty zuschlägt. Beim Bobcat eher seltener als bei den Hounds (Canines, der Ersatz für K9?).
Die Fetch-Stufen, welche später an den Anfang springen, sind nach meinem Verständnis die Fälle, wo genauere Sprungvorhersagen den Pfad doch noch anders vorhersagen. Das Prinzip finde ich elegant und habe es unter "Late Cancelling" im Kopf gespeichert. So etwas setze ich bei Bedarf auch in zeitkritischen Software-Geschichten ein, wenn jede ms zählt, aber zu früherer Zeit noch keine so hohe Sicherheit über das Ergebnis besteht. Da die der Vorhersage folgenden Aktionen (beim Bobcat das Decoding) abbrechbar sind, hat man auf jeden Fall den Zeitgewinn und bei falscher Vorhersage einen kleinen Verlust (Zeit, Energie) anstatt mit der falschen Vorhersage bis zu den EX-Stufen durchzulaufen.
Anandtech hat den Pfeil gleich weggelassen:
Spannender ist natürlich, wie oft die Penalty zuschlägt. Beim Bobcat eher seltener als bei den Hounds (Canines, der Ersatz für K9?).
Die Fetch-Stufen, welche später an den Anfang springen, sind nach meinem Verständnis die Fälle, wo genauere Sprungvorhersagen den Pfad doch noch anders vorhersagen. Das Prinzip finde ich elegant und habe es unter "Late Cancelling" im Kopf gespeichert. So etwas setze ich bei Bedarf auch in zeitkritischen Software-Geschichten ein, wenn jede ms zählt, aber zu früherer Zeit noch keine so hohe Sicherheit über das Ergebnis besteht. Da die der Vorhersage folgenden Aktionen (beim Bobcat das Decoding) abbrechbar sind, hat man auf jeden Fall den Zeitgewinn und bei falscher Vorhersage einen kleinen Verlust (Zeit, Energie) anstatt mit der falschen Vorhersage bis zu den EX-Stufen durchzulaufen.
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Hallo,
Der Artikel ist zwar in der jetzigen Form rund, allerdings gibt es ja einige Neuigkeiten.
Hat da jemand Lust die Hier noch mit einzuarbeiten?
Ich hätte das gesamte neue Bildmaterial und könnte es hier entsprechend hochladen.
Ich wollte jetzt allerdings nicht einfach am Text groß umbauen, bevor wir das weitere Vorgehen mal besprochen haben. Zudem ist meine Zeit begrenzt. Es wäre aber schön, wenn man hier zentral auch die aktuellsten Infos zum Ontario finden könnte.
Der Artikel ist zwar in der jetzigen Form rund, allerdings gibt es ja einige Neuigkeiten.
Hat da jemand Lust die Hier noch mit einzuarbeiten?
Ich hätte das gesamte neue Bildmaterial und könnte es hier entsprechend hochladen.
Ich wollte jetzt allerdings nicht einfach am Text groß umbauen, bevor wir das weitere Vorgehen mal besprochen haben. Zudem ist meine Zeit begrenzt. Es wäre aber schön, wenn man hier zentral auch die aktuellsten Infos zum Ontario finden könnte.
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Naja, rund ist was anderes, da sind noch einige Fehler drin ^^Hallo,
Der Artikel ist zwar in der jetzigen Form rund, allerdings gibt es ja einige Neuigkeiten.
Naja, das Neue ist doch praktisch alles harte Daten, keine Spekulation mehr.Ich wollte jetzt allerdings nicht einfach am Text groß umbauen, bevor wir das weitere Vorgehen mal besprochen haben. Zudem ist meine Zeit begrenzt. Es wäre aber schön, wenn man hier zentral auch die aktuellsten Infos zum Ontario finden könnte.
Da würde sich anbieten nen Unterpunkt "gesichterte Daten" sowie "Modellpolitik" einzupflegen.
Der Artikel, so wie er jetzt ist, befasst sich ja mit den technischen Innereien, das was jetzt noch dazukommt ist (abgesehen von den Korrekturen) nur noch Marketing und Praxistests / Benchmarks.
Würde vorschlagen die Punkte das einfach zu ergänzen, was meinst Du ?
Eventuell würde sich auch schon ein neuer Sammelthread rentieren. Der aktuelle ist ja explizit nur für Bobcat, das sind nur die x86 Kerne. Wenn Du jetzt Ontario/Zacate Material ergänzen willst, wär das eigentlich hier fehl am Platz.
ciao
Alex
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Ich denke der Artikel ist abgeschlossen.
Was kommt, das sind dann konkrete Daten und Produkte - was einen vollständigen neuen eigenen Artikel wert ist. Man muss auch mal einen Punkt setzen können.
Gruß Bobo(2010)
Was kommt, das sind dann konkrete Daten und Produkte - was einen vollständigen neuen eigenen Artikel wert ist. Man muss auch mal einen Punkt setzen können.
Gruß Bobo(2010)
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Noch ne kleine Zusatzinfo, aus nem IEEE Bobcat Paper:
Hübsch, also "memory disambiguation" bei Bobcat. Sicherlich mit ein Grund, wieso der kleine Kern relativ gut mithalten kann.Bobcat includes a small yet efficient OoO
load/store unit (LSU). Capable of tracking
up to 26 in-flight loads and 22 stores, this
processor is AMD’s first fully OoO LSU. It
supports both loads bypassing older loads
and loads bypassing older nonconflicting
stores. The Bobcat LSU can perform an
8-byte load and an 8-byte store on every
cycle, and it supports a three-cycle load-to-
use pipeline. The data cache supports up to
eight outstanding cache misses, as well as
hits beneath misses. Critical-word forward-
ing is used on cache misses to reduce effective
cache miss latency.
Markus Everson
Grand Admiral Special
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken
- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
FSA ==> HSA
AMD Fusion System Architecture is now Heterogeneous Systems Architecture
Außer dem Namen hat sich nichts verändert.
AMD Fusion System Architecture is now Heterogeneous Systems Architecture
Außer dem Namen hat sich nichts verändert.
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Tja - obs an Arctic Cooling liegt ...FSA ==> HSA
AMD Fusion System Architecture is now Heterogeneous Systems Architecture
Außer dem Namen hat sich nichts verändert.
MFG Bobo(2012)
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@Bobo
Wenn dem so ist, warum schreiben sie dann: AMD Fusion12 Developer Summit in June 2012
Ich glaube eher, das liegt an der Standardisierung von HSA.
Wenn dem so ist, warum schreiben sie dann: AMD Fusion12 Developer Summit in June 2012
Ich glaube eher, das liegt an der Standardisierung von HSA.
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Du kennst doch die überlasteten Praktikanten von AMDs PR-Abteilung ... und da dort personell gestrichen wurde - glaube ich erst an den Namen, wenns zu diesem Datum auch so läuft@Bobo
Wenn dem so ist, warum schreiben sie dann: AMD Fusion12 Developer Summit in June 2012
Ich glaube eher, das liegt an der Standardisierung von HSA.
Ähnliche Themen
- Antworten
- 815
- Aufrufe
- 113K
- Antworten
- 8
- Aufrufe
- 4K
- Antworten
- 10
- Aufrufe
- 4K
- Antworten
- 34
- Aufrufe
- 10K