App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Bobcat, das Bulldözerchen
- Ersteller Opteron
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
<erster entwurf,="" wird="" noch="" besser="" ") ="" wer="" will="" kann="" die="" links="" suchen="" &="" einfügen=""></erster><links>
="" wer="" will="" kann="" die="" links="" suchen="" &="" einfügen=""></erster><links>
Neuer Artikel: AMD präsentiert "Bulldozer" und "Bobcat" auf der Hot Chips
Die kompletten, originalen Präsentationensfolien der Hot Chips 22 vom Chip-Olymp der Stanford University sind hier zu finden:
<links>
Am meisten Interesse wurde natürlich dem kommenden Hochleistungsprozessor Bulldozer zu Teil. Den P3D Vorbericht von Dresdenboy dazu gibt es hier. Im Schatten dessen ging das kleinere Bobcat-Design leider etwas unter, obwohl mehr Details bekannt gegeben wurden. In diesem Artikel wollen wir jetzt näher auf Bobcat eingehen:
Laut AMDs Vorgaben aus dem Jahr 2007 sollte ein Bobcat-Kern nur 1-10 Watt verbrauchen:

Damit waren die Zielvorgaben fixiert. Die Frage war nur, wie Intels schärfster x86-Rivale sie umsetzen würde. Dazu später mehr, zuerst noch ein Blick auf den Zielmarkt.
<link uraltfolie=""><uralt folie="">
Grund dürfte sein, dass die aktuelle Notebook-Plattform Danube, bestehend aus 45nm AMD CPU und IGP-Chipsatz mit ATI Grafik, eine gute Basisleistung zum vernünftigen Preis bietet. Die Texaner konnten deshalb auch relativ viele OEM Designs gewinnen. Mit 109 geplanten Geräten, verdreifachten sich die „Designwins“ gegenüber der Vorgängerplattform mit 65nm Prozessoren <doofen marketingname="" einfügen="">[Quelle].
Diese erfolgreiche Kombination aus ATI-Grafik und AMD-Prozessor wollen die Athlon-Erfinder im nächsten Jahr noch weiter verbessern, indem die beiden Komponenten noch näher zusammenrücken. Das Verschmelzen von Grafikkern und Hauptprozessor auf einem Chip nennt AMD dabei „Fusion“.
</doofen></uralt>
</links>
</die></doofen></uralt></links>
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Deshalb soll hier nur eine Schnellübersicht erfolgen. Aktuell ist dieses Schema eines Fusion-Prozessors:
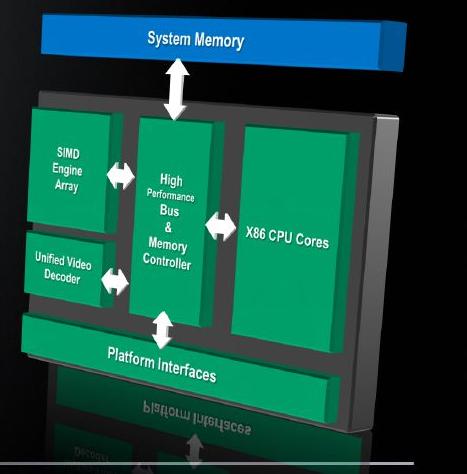
Wie man sieht ist alles (CPU/GPU/Platform Interfaces) auf einem Stück Silizium („Die“) integriert. Das spart Platz und durch die räumliche Nähe dürften sich auch Performance-Vorteile ergeben. Insgesamt ergeben sich Leistungs-, Verbrauchs-, und Platzvorteile - optimal für kleine, leichte Rechner. Intel nutzt bei seiner Clarkdale CPU z.B. ebenfalls schon CPU und GPU in einem Gehäuse. Allerdings dort mittels zwei getrennten Dies, die auf einem Chipträger mit QuickPath verbunden sind. Für Pineview, die zweite Generation der „Atoms“ nutzt der x86-Gigant sogar noch den klassischen mittlerweile auch recht behäbigen FSB. Dafür ist der neue Atom mit integrierter Grafik auf einem einzigen Stück Silizium eingeätzt. QPI ist zwar das Neueste vom Neuen, aber nicht so sparsam und zudem für Dual Channel-DDR3 schon wieder ein Flaschenhals.
</die></doofen></uralt></links><links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
</die></doofen></uralt></links>
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">Für 2011 sind drei Fusion Modelle geplant:
</die></doofen></uralt></links>

Quelle

Zusätzlich zu den beiden Bobcat Derivaten wird es noch den Llano geben, der auf der altbekannten K10 Architektur basieren wird. Sie ist ausreichend bekannt und muss deshalb nicht eingehend betrachtet werden. Bobcat dagegen ist interessant, wie man schon an obigen TDP Zahlen sehen kann. Dieser genügsame Stromkonsum ist für einen integrierten Chip aus CPU, GPU und kleinem PCIe Kontroller sehr gut. Deswegen wollen wir uns das Design einmal etwas näher anschauen. Zuerst die Architekturübersicht:
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
<schema>
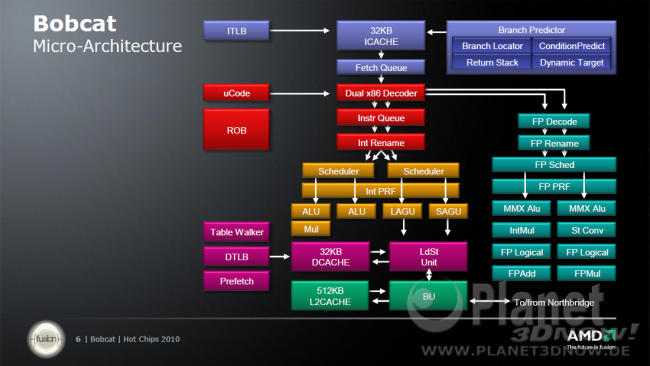
Auf den ersten Blick ist alles vorhanden, was man bei einer state-of-the-art CPU benötigt. Im Vergleich zum K8/K10 fallen die L1 Caches nur halb so groß aus, dafür wurde aber an der Assoziativität geschraubt. Der Datencache ist nun anstatt 2fach, 8fach assoziativ, und entspricht nach einer Daumenregel, somit einem 2fach assoziativen Cache von 128 kbyte. Also ist das eher eine Verbesserung, denn eine Verschlechterung.
Die restlichen Eckpunkte in Stichpunkten:
</schema></links>

Quelle: "Multicore Processors and Systems", Danke an Dresdenboy für den Link.
<links><schema>
Wie man sieht ist alles an seinem Platz. Für INT Berechnungen sehen wir 12 Stufen, AMDs K10 benützt übrigens die gleichen Stufen. Schauen wir uns jetzt dazu Bobcats Pipeline an:
<uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
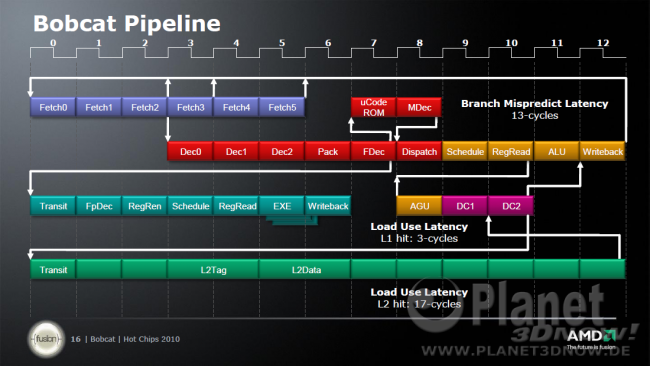
Bobcats Pipeline erinnert frappant an die obige K8/K10 Pipeline. Es gibt (ohne Datencachezugriffe mitzuzählen) jetzt 13 Stufen. Die neue Stufe bezieht sich auf das Lesen der Register, möglicherweise eine Folge der neuen physikalischen Register Files (PRF). AMD dürfte somit ziemlich sicher das K8/K10 Design als Ausgangsbasis für Bobcat genommen haben. Typisch für die K8 und K10 Architektur ist unter anderem die "Pack" Stufe. Darin werden x86 Befehle, die in 2 interne MacroOps zerlegt werden müssen, gesammelt und "verpackt". Laut AMD Informationen sind das circa 10 Prozent. Die überwältigende Mehrheit (89 Prozent) der „Feld, Wald und Wiesen“- x86 Befehle können dagegen in einem Rutsch 1:1 in MacroOps umgewandelt werden. Das verbleibende Restprozent bearbeitet die langsame Microcodeengine </die></doofen></uralt></schema></links>[Quelle].
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Auffallend beim Bobcat ist die lange L2 Pipeline/Wartezeit im Vergleich zum K8/K10 Design. Das liegt vermutlich daran, dass der L2-Cache, ähnlich wie schon der L3-Zwischenspeicher des K10s, nicht mir vollem Kerntakt betrieben wird. Laut AMD wird er nur mit der Hälfte des Kerntaktes laufen.</die></doofen></uralt></schema></links>

Quelle: http://www.azillionmonkeys.com/qed/cpuwar.html
Wie man erkennt, hatte der K6 nur 7 Pipeline-Stufen, nicht einmal halb soviel wie das Bobcat-Design (mit Datencachezugriffen). Der interne Aufbau ist aus diesem Grund komplett anders. Die Gemeinsamkeiten beschränken sich nur auf grobe Äußerlichkeiten.
Bobcats Vorfahren sind somit eindeutig in der K8 und K10 Familie zu suchen, nicht beim K6!
<links><schema>
<uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
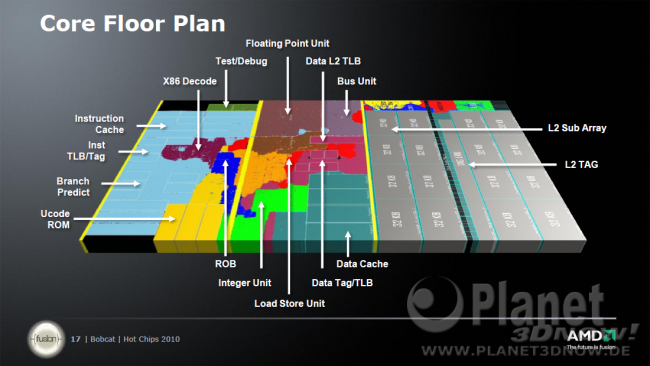
</die></doofen></uralt></schema></links>Am Floorplan sieht man, wie die verschiedenen Einheiten aus der obigen Architekturgrafik genau auf dem endgültigen Siliziumchip verteilt wird. Im Vergleich zu alten K8/K10 Diagrammen fallen erstens die unregelmäßigen, ja fast schon chaotischen Segmentierungen auf. Grund hierfür ist das Verwenden von automatischer Layoutsoftware (Electronic design automation (EDA)), die bisher nur im Embedded/SoC-Bereich gebräuchlich war. Handoptimierte Designs bestehen hingegen aus mehr oder minder aus rechteckigen, regelmäßigen Blöcken. EDA-Software beim Chipentwurf verschwendet zwar etwas Platz, spart aber eine Menge Handarbeit und somit Zeit und Kosten ein. Zweitens fällt bei genauerer Betrachtung die FPU Größe auf. Denn deren Fläche ist verschwindend gering, fast hat man Schwierigkeiten die FPU zu finden. In etwa entspricht sie der Größe des 32kB L1 Caches. Im Vergleich zu alten K8 oder gar K10 Zeiten ein deutlicher Unterschied. In Dresdenboy Blog war einmal eines IEEE Papers zu finden, in dem eine neue FPU beschrieben wird, die in nur 40 Prozent der Fläche der K8 FPU fast die gleiche Leistung bringt und dabei auch noch weit weniger Energie verbraucht. 40 Prozent Fläche käme gut hin. Die Wahrscheinlichkeit ist groß, dass die beschriebene FPU im Bobcat Verwendung findet.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""> </die></doofen></uralt><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Schauen wir uns jetzt im Vergleich dazu Intels Konkurrenzprodukt, den Atom Prozessor an.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
[H4]Die Atom Architektur[/H4]
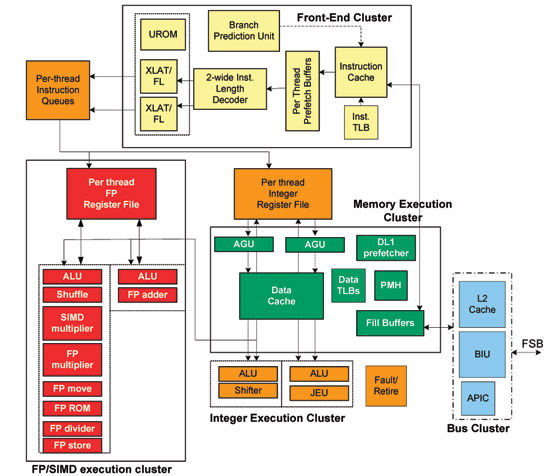
</die></doofen></uralt></schema></links>
Vergleicht man erst einmal nur die bloße Architektur, stellt man auf den ersten Blick nicht viele Unterschiede fest. Genauso wie AMD beim Bobcat setzte auch Intel bereits vor zwei Jahren auf ein 2-issue Design. Der Grund dafür ist, dass bei einem schlanken Leichtkerner ein optimales Verhältnis aus Aufwand und Nutzen besteht. Circa 95 Prozent des x86 Codes lässt sich mit einem 2-issue ohne Datenstau abarbeiten. Der Mehraufwand für komplexe parallele 3-issue (K8/K10 / Core2/Nehalem) lohnt nicht im Low-Power Bereich. AMD ist sogar beim großen Bruder Bulldozer auf eine zweifache Parallelität der Pipelines zurückgekommen. Das ergibt auch bei Hochleistungsdesigns Sinn. Ein ehemaliger AMD Entwickler erklärte dazu, dass der Verzicht auf die dritte Pipeline nur ~5 Prozent Leistung kostet. Belohnt wird die neue Sparsamkeit dafür mit etwas, wonach sich Prozessor-Enthusiasten seit Jahren sehnen – mehr Takt. Konkret spricht die gleiche Quelle von 20 bis 30 Prozent höheren Taktraten <links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">[Quelle]. Aber das sei hier nur am Rande bemerkt.
Schauen wir uns nun die Atom Pipeline genauer an:
[H4]Die Atom Pipeline[/H4]
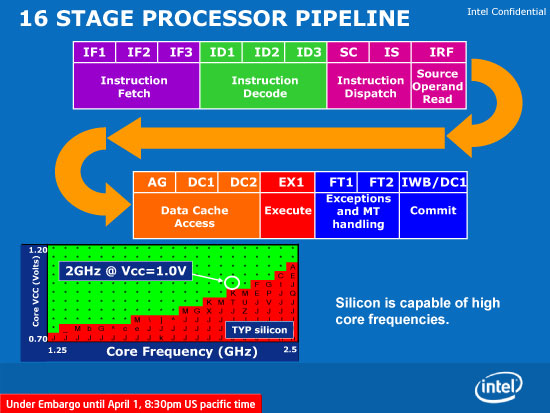
Wie man sieht hat der Atom die gleiche Pipeline-Länge wie Bobcat, denn Intel zählt die Stufen für den Daten - Cachezugriff in der obigen Illustration fest dazu. Falls aber nur Daten in den Registern manipuliert werden, fallen die drei Stufen natürlich weg. Demnach kann man also wie auch schon im vorherigen Fall eine Übereinstimmung vermelden, beide Designs sind 2issue mit einer 13 (16) Stufen langen Integer Pipeline (je nach Zählweise). Aber wie so oft, liegt der Teufel im Detail. Ein paar Punkte wurden bereits angedeutet, schauen wir sie uns im nächsten Kapitel nun einmal ganz genau an:
</die></doofen></uralt></schema></links>
Was ist denn nun besser? Tja, das kommt darauf an, welche Ziele man sich setzt. Hier sieht man nun die Auswirkungen des kleinen aber feinen Unterschiedes in den Anwendungsprofilen beziehungsweise den Designzielen. Während Atom laut Intel irgendwann auch einmal in einem Mobiltelefon auftauchen soll, lässt AMD diesen Markt links liegen. Das hat zur Folge, dass der Atom wirklich knallhart und kompromisslos auf Energiesparen getrimmt wurde, wogegen das Bobcat-Designteam einige leistungssteigernde Kompromisse eingehen durfte.
Der auffälligste und tiefgreifendste dieser Punkte ist eindeutig die Entscheidung für InOrder gegenüber Out of Order (OoO).
Bei InOrder-Designs werden die Befehle so abgearbeitet wie sie kommen. Muss auf einen Cache- oder gar RAM-Zugriff gewartet werden, dann stehen die Rechenräder still. Eine OoO CPU dagegen kann nachfolgende Befehle vorziehen, beziehungsweise Befehle auf gut Glück spekulativ berechnen lassen. Manchmal klappt das nicht und die Spekulation war umsonst, aber die Trefferrate liegt bei modernen OoO Designs oberhalb der 90 Prozent Marke. Insgesamt gibt das Ganze einen gutes Leistungsplus von ca. 20-30 Prozent. Nicht umsonst waren bis zum Atom alle Intel CPUs seit PentiumPro/Pentium-II Zeiten OoO basierend.
[H4]Hyperthreading macht müde In-Order CPUs munter !?[/H4]
Wie wir seit dem letzten Punkt wissen kann eine OoO CPU Cache- und RAM-Wartezeiten besser überbrücken, während eine InOrder CPU stillsteht. Dass das Verschwendung wäre hat auch Intel bemerkt und den Atom deshalb mit Hyperthreading ausgestattet. Damit laufen 2 Threads auf einem Kern. Falls jetzt das Rechenwerk wegen der Wartezeit eines Threads still steht, hat Thread 2 deshalb freie Fahrt. Logischerweise bringt Hyperthreading auf einer InOrder CPU deutlich mehr als auf einer OoO CPU. Gewinnt ein Nehalem mit OoO maximal 20-30 Prozent durch Hyperthreading, so können es bei Atom schon mal bis zu 70 Prozent sein [P3DTest]. Zumindest bei Multithreaded-Anwendungen. Genau da liegt aber jetzt der Hase im Pfeffer. Die Single-Thread Leistung vom Atom ist schon schlecht und wird durch die zusätzliche Belastung eines 2ten Threads nicht besser. Vereinfacht ausgedrückt:
Anstatt eines 2issue Kerns hat man mit Hyperthreading quasi zwei 1issue Kerne. Das lastet zwar die Rechenwerke gut aus, steigert aber nicht die Single-Thread Rechenleistung - eher im Gegenteil.
Berichte in den Foren darüber, dass Atom CPUs nur zäh reagieren würden, oder aber Flash Spielereien nur ruckelnd liefen, sind nicht selten zu finden. Bei Multithread Anwendungen wie Packer, Renderer oder Konvertierungen lässt Hyperthreading zwar die Muskeln spielen, aber solche Anwendungsszenarien sind - außer den Packern - auf so leistungsschwachen Rechnern eher unwahrscheinlich.
Zusätzlich gibt es im Hyperthreadingbetrieb noch eine Menge Einschränkungen. Der parallele Betrieb ist nicht so einfach zu handhaben wie man meinen könnte. Genaueres ist im Optimierungsmanual von Agner Fog in Erfahrung zu bringen.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
</die></doofen></uralt></schema></links>[H4]Das physikalische Registerfile[/H4]
Im Register stehen Daten, die unmittelbar zum Rechnen benötigt werden. Um sie dort hin zu bekommen, werden sie aus dem Cache oder RAM geladen. InOrder CPUs haben den normalen Registersatz, den die ISA zur Verfügung stellt. Im x86 Falle sind das 8 INT und 8 SSE/FP Register, für den 64 Bit Modus stehen je 16 zur Verfügung. OoO CPUs gehen die Sache jetzt etwas kreativer an. CPUs dieser Art beherrschen das Register Renaming. Das ist ein Trick, um mehr schnelle Register zu benutzen, als die x86 ISA zur Verfügung stellt. Für Bulldozer stehen z.B. 160 SSE/FP und 96 INT Register im Raum [Quelle]. Diese vielen Register braucht man v.a. für das spekulative Ausführen von Befehlen. Logischerweise kann man spekulative Berechnungen nicht auf den Orginalregistern herumschreiben lassen, das gäbe ein Datenchaos. Stattdessen bekommen diese ihren eigenen Satz der 16 x86-Register vorgespielt.
Im K8/K10 sowie allen Intel OoO CPUs gibt es nun einen sogenannten ReOrderBuffer (ROB). Wie der Name schon nahe liegt, ist er das Endstück einer OoO Berechung. Seine Aufgabe ist es, die ursprüngliche Befehlsreihenfolge wiederherzustellen. Dazu schreiben Instruktionen, deren Berechnungen in spekulativen Registern abgeschlossen wurden, ihr Endresultat d.h. den Registerinhalt in den ROB. Der ROB wiederum sortiert alle Instruktionen richtig ein, und schreibt die Ergebnisse danach in ein "offizielles" der 8 bzw.16 x86-Register zurück. Wie man nun leicht feststellen kann, wird hier oft kopiert. Das kostet Zeit, vor allem aber auch Strom. Prozessoren mit physikalischen Registern setzen dieser Verschwendung nun einen Riegel vor. Die Daten bleiben immer nur in einem Register, es wird nichts kopiert. Was sich ändert sind nur Verweise darauf.
Vereinfacht ausgedrückt: Anstatt die Daten mit Sack und Pack von einem Haus (=Register) ins nächste zu jagen, wechselt man einfach das Hausnummernschild bzw. den Wegweiser zum Haus aus und protokolliert die Namensvergaben in einem zentralen Adressverzeichnis.
Eine simple Idee die Strom einspart und auch schon in vielen CPU Designs verwendet wurde, u.a. in einigen DEC ALPHA CPUs sowie in IBMs POWER4, 5 und 7 CPUs [Quelle]. Falls jemand nun das Power6 Design vermisst: Das war ein InOrder Design. In der x86 Familie war bisher nur der unrühmliche Pentium4 damit ausgestattet. AMD verwendet die Technik nun sowohl beim Bulldozer als auch beim Bobcat, also bei allen neuen Architekturdesigns - sicher keine schlechte Entscheidung.
Im Vergleich dazu ist Atoms Fetch-Breite nur mickrig zu nennen. Die offiziellen PDFs und Berichte schweigen sich dazu "zufällig" aus. Prof. Dr. Agner Fog nennt dann auch in seinem bereits erwähnten x86 Optimierungsleitfaden enttäuschende um die 8 Byte. Also nur ein Viertel von Bobcat. Das hat dann negative Auswirkungen, wenn zwei Befehle decodiert werden müssen, die zusammen diese 8 Byte Grenze überschreiten. Vor allem 64 Bit Befehle und praktisch alle SSE2++ Befehle fallen darunter. Das erklärt dann auch Intels Zögern den Atom CPUs die 64 Bit Erweiterung freizuschalten. Die Auswirkungen sind deutlich. Solange das Front-End keine Daten liefert, können die Rechenpipelines auch nichts berechnen; die Rechenleistung sinkt damit auf 1issue. Dies erklärt dann auch das starke Plus durch Hyperthreading. Wegen Hyperthreading ist auch die Fetch-Einheit verdoppelt, so dass dann für zwei Threads 2x8 Byte eingelesen werden können. Das resultiert dann in mindestens zwei SSE Befehlen pro Takt, was ausreichend ist, um die 2issue Recheneinheiten gut auslasten zu können. Nur leider hat man davon nichts im Single-Thread-Betrieb.
</die></doofen></uralt></schema></links>
Bobcat wird die deutlich bessere Single-Thread Leistung aufweisen. Atom könnte durch Hyperthreading zumindest in Spezialfällen aufholen. Allerdings ist Bobcat kein fertiger Chip, sondern nur ein Designbaustein. Erstmals werden zwei Bobcat Kerne im bereits erwähnten Ontario/Zacate Fusion Chip Verwendung finden. Setzt man dem nun zwei Atom Prozessoren eines Pineview Atoms mit Hyperthreading gegenüber, ist die Rechnung quasi 2x2issue gegen 4x1issue. 2x2 dürfte dabei das deutlich komfortablere User Erlebnis bieten.
AMD könnte somit durch den Verzicht aufs Handygeschäft und großzügigeren Verbrauchsbudget einen deutlichen Vorteil gegenüber Intel haben. Dieser könnte sogar größer ausfallen als vermutet. Geht man normalerweise davon aus, dass ein OoO Kern größer als ein InOrder Design sein müsste, weist die neueste Vergleichsgrafik von Hans de Vries einen Flächenvorteil von Bobcat gegenüber Atom aus:
Zwar hat AMD auch einen leichten Fertigungsvorteil von 40nm gegenüber 45nm, dennoch ist es beachtlich, dass ein einzelner Bobcat-Kern kleiner ist.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Einzige Unbekannte der obigen Spekulation wären deutlich geringere Taktfrequenzen von Ontario im Vergleich zum Atom. Zwar sollte auch in diesem Fall der Fertigungsvorteil eine positive Rolle für Bobcat spielen, dennoch bleibt eine gewisse Unsicherheit, die es zu beobachten gilt. Außerdem könnte sich AMD den Leistungsvorteil natürlich auch gut bezahlen lassen, in diesem Fall bliebe für Atom die Lücke der Lowest-Cost-Netbooks.
Wenn wir mit dieser Spekulation nun in der Gerüchteküche angelangt sind, soll auch nicht verschwiegen werden, dass vielleicht sogar Apple Ontario verwenden wird. Als OpenCL Verfechter der ersten Stunde setzt Apple auf leistungsfähige GPUs. Somit ist es nicht verwunderlich, dass Apple Interesse am Ontario nachgesagt wurde [Quelle].<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""><bla>
</bla></die></doofen></uralt></schema></links>Richtig interessant wird Intel vermutlich erst wieder werden, wenn im zweiten Halbjahr 2011 die 32nm Atom Chips auf den Markt kommen. Bis dahin aber wird das Bulldözerchen alias Bobcat im Markt für größere Bewegungen sorgen.
="" wer="" will="" kann="" die="" links="" suchen="" &="" einfügen=""></erster><links>Einleitung
</links>Viel Pressewirbel und Tamtam wurde am 24. August, dem zweiten Tag der Hot Chips-Konferenz 2010 veranstaltet, denn AMD gab erstmals nähere Details zu Ihren kommenden CPU Architekturen „Bulldozer“ und „Bobcat“ bekannt. P3D berichtete:Neuer Artikel: AMD präsentiert "Bulldozer" und "Bobcat" auf der Hot Chips
Die kompletten, originalen Präsentationensfolien der Hot Chips 22 vom Chip-Olymp der Stanford University sind hier zu finden:
<links>
Am meisten Interesse wurde natürlich dem kommenden Hochleistungsprozessor Bulldozer zu Teil. Den P3D Vorbericht von Dresdenboy dazu gibt es hier. Im Schatten dessen ging das kleinere Bobcat-Design leider etwas unter, obwohl mehr Details bekannt gegeben wurden. In diesem Artikel wollen wir jetzt näher auf Bobcat eingehen:
Bobcat - wozu ?
Laut AMDs Vorgaben aus dem Jahr 2007 sollte ein Bobcat-Kern nur 1-10 Watt verbrauchen:
Damit waren die Zielvorgaben fixiert. Die Frage war nur, wie Intels schärfster x86-Rivale sie umsetzen würde. Dazu später mehr, zuerst noch ein Blick auf den Zielmarkt.
<link uraltfolie=""><uralt folie="">
Zielmarkt
Der geplante Zielmarkt ist bei 1-10 Watt Strombedarf natürlich einfach zu erraten: Kleine, leichte Net- und Notebooks mit langer Batterielaufzeit oder auch stromsparende Desktop PCs (Nettops). In diesem Segment macht sich seit 2008 Intels Atom breit, der somit in diesen Segmenten als direkter Bobcat-Gegenspieler gesehen werden muss. AMD will mit diesem Leichtprozessorkern allerdings das Segment der Mobiltelefone nicht besetzen, was einige Vorteile bietet. Siehe die Vor-und Nachteile später.AMDs aktuelle Lage
Fast schon "traditionell" kann man sagen, dass das Notebook-Segment bei AMD ein eher stiefmütterliches Dasein fristet. Intel ist mit der „Centrino“ Marke schon lange am Markt, und konnte auch mit langen Batterielaufzeiten bei guter Leistung punkten. Seit dem Abschied von Transmeta aus diesem Markt (bis auf AMD) quasi unangefochten, denn VIA ist absolut unbedeutend. Seit der ersten mobilen K10 Kernen in 45nm Fertigungstechnik, konnte AMD aber immerhin einen kleinen Erfolg verbuchen. Laut den Marktforschern von IDC stieg der Marktanteil des kleinen x86-Riesen um 0,2 Prozent auf immerhin 19 Prozent. Das ist nicht gerade viel, aber im gleichen Zeitraum sank AMDs Anteil am Mainstream/Desktop-Segment um 0,7 [Quelle]Grund dürfte sein, dass die aktuelle Notebook-Plattform Danube, bestehend aus 45nm AMD CPU und IGP-Chipsatz mit ATI Grafik, eine gute Basisleistung zum vernünftigen Preis bietet. Die Texaner konnten deshalb auch relativ viele OEM Designs gewinnen. Mit 109 geplanten Geräten, verdreifachten sich die „Designwins“ gegenüber der Vorgängerplattform mit 65nm Prozessoren <doofen marketingname="" einfügen="">[Quelle].
Diese erfolgreiche Kombination aus ATI-Grafik und AMD-Prozessor wollen die Athlon-Erfinder im nächsten Jahr noch weiter verbessern, indem die beiden Komponenten noch näher zusammenrücken. Das Verschmelzen von Grafikkern und Hauptprozessor auf einem Chip nennt AMD dabei „Fusion“.
</doofen></uralt>
</links>
Fusion
<links> <uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""> Über Fusion wurde auf P3D schon ausreichend berichtet:</die></doofen></uralt></links>
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Deshalb soll hier nur eine Schnellübersicht erfolgen. Aktuell ist dieses Schema eines Fusion-Prozessors:
Wie man sieht ist alles (CPU/GPU/Platform Interfaces) auf einem Stück Silizium („Die“) integriert. Das spart Platz und durch die räumliche Nähe dürften sich auch Performance-Vorteile ergeben. Insgesamt ergeben sich Leistungs-, Verbrauchs-, und Platzvorteile - optimal für kleine, leichte Rechner. Intel nutzt bei seiner Clarkdale CPU z.B. ebenfalls schon CPU und GPU in einem Gehäuse. Allerdings dort mittels zwei getrennten Dies, die auf einem Chipträger mit QuickPath verbunden sind. Für Pineview, die zweite Generation der „Atoms“ nutzt der x86-Gigant sogar noch den klassischen mittlerweile auch recht behäbigen FSB. Dafür ist der neue Atom mit integrierter Grafik auf einem einzigen Stück Silizium eingeätzt. QPI ist zwar das Neueste vom Neuen, aber nicht so sparsam und zudem für Dual Channel-DDR3 schon wieder ein Flaschenhals.
</die></doofen></uralt></links><links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
</die></doofen></uralt></links>
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">Für 2011 sind drei Fusion Modelle geplant:
</die></doofen></uralt></links>
- <links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""> Ontario, basierend auf ein-zwei Bobcat CPUs plus einer GPU, 9W TDP
</die></doofen></uralt></links> - Zacate, wie Ontario nur mit 18W TDP
Quelle
Zusätzlich zu den beiden Bobcat Derivaten wird es noch den Llano geben, der auf der altbekannten K10 Architektur basieren wird. Sie ist ausreichend bekannt und muss deshalb nicht eingehend betrachtet werden. Bobcat dagegen ist interessant, wie man schon an obigen TDP Zahlen sehen kann. Dieser genügsame Stromkonsum ist für einen integrierten Chip aus CPU, GPU und kleinem PCIe Kontroller sehr gut. Deswegen wollen wir uns das Design einmal etwas näher anschauen. Zuerst die Architekturübersicht:
<links><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Die Bobcat Architektur
</die></doofen></uralt><schema>
Auf den ersten Blick ist alles vorhanden, was man bei einer state-of-the-art CPU benötigt. Im Vergleich zum K8/K10 fallen die L1 Caches nur halb so groß aus, dafür wurde aber an der Assoziativität geschraubt. Der Datencache ist nun anstatt 2fach, 8fach assoziativ, und entspricht nach einer Daumenregel, somit einem 2fach assoziativen Cache von 128 kbyte. Also ist das eher eine Verbesserung, denn eine Verschlechterung.
Die restlichen Eckpunkte in Stichpunkten:
- AMD64 Architektur
- Befehlssatzerweiterungen: SSE2 / SSE3 / SSSE3 und SSE4A (kein SSE4.1 oder SSE 4.2)
- 2issue Out-of-Order Architektur, es können gleichzeitig maximal zwei x86 Befehle in veränderter Reihenfolge abgearbeitet werden.
- 32kB L1I und L1D Caches
- 512kB L2 Cache
- 90 Prozent Rechenleistung eines K10 Kerns (bisher wusste man nicht sicher, auf was sich die 90 Prozent bezogen, wobei das bei AMD mehr oder minder klar sein musste ^^).
- Bobcat benützt physikalische Register Files (PRF), dies ist wichtig fürs Register Umbenennen, später dazu mehr im Detailkapitel.
</schema></links>
Die K8 Pipeline
Bevor wir uns Bobcats Pipeline anschauen, wollen wir uns erst einmal AMDs altehrwürdige K8 Pipeline anschauen:Quelle: "Multicore Processors and Systems", Danke an Dresdenboy für den Link.
<links><schema>
Wie man sieht ist alles an seinem Platz. Für INT Berechnungen sehen wir 12 Stufen, AMDs K10 benützt übrigens die gleichen Stufen. Schauen wir uns jetzt dazu Bobcats Pipeline an:
<uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Die Bobcat Pipeline
Bobcats Pipeline erinnert frappant an die obige K8/K10 Pipeline. Es gibt (ohne Datencachezugriffe mitzuzählen) jetzt 13 Stufen. Die neue Stufe bezieht sich auf das Lesen der Register, möglicherweise eine Folge der neuen physikalischen Register Files (PRF). AMD dürfte somit ziemlich sicher das K8/K10 Design als Ausgangsbasis für Bobcat genommen haben. Typisch für die K8 und K10 Architektur ist unter anderem die "Pack" Stufe. Darin werden x86 Befehle, die in 2 interne MacroOps zerlegt werden müssen, gesammelt und "verpackt". Laut AMD Informationen sind das circa 10 Prozent. Die überwältigende Mehrheit (89 Prozent) der „Feld, Wald und Wiesen“- x86 Befehle können dagegen in einem Rutsch 1:1 in MacroOps umgewandelt werden. Das verbleibende Restprozent bearbeitet die langsame Microcodeengine </die></doofen></uralt></schema></links>[Quelle].
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Auffallend beim Bobcat ist die lange L2 Pipeline/Wartezeit im Vergleich zum K8/K10 Design. Das liegt vermutlich daran, dass der L2-Cache, ähnlich wie schon der L3-Zwischenspeicher des K10s, nicht mir vollem Kerntakt betrieben wird. Laut AMD wird er nur mit der Hälfte des Kerntaktes laufen.</die></doofen></uralt></schema></links>
Die K6 Pipeline
Oft wird wegen der oben genannten Architekturmerkmale ein Vergleich mit AMDs alten K6 Design bemüht, welches ebenfalls 2issue war. Der Aufbau der K6 Pipeline ist jedoch völlig anders, von Ähnlichkeit kann also nicht die Rede sein:
Quelle: http://www.azillionmonkeys.com/qed/cpuwar.html
Wie man erkennt, hatte der K6 nur 7 Pipeline-Stufen, nicht einmal halb soviel wie das Bobcat-Design (mit Datencachezugriffen). Der interne Aufbau ist aus diesem Grund komplett anders. Die Gemeinsamkeiten beschränken sich nur auf grobe Äußerlichkeiten.
Bobcats Vorfahren sind somit eindeutig in der K8 und K10 Familie zu suchen, nicht beim K6!
<links><schema>
<uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Der Floorplan
</die></doofen></uralt></schema></links>Am Floorplan sieht man, wie die verschiedenen Einheiten aus der obigen Architekturgrafik genau auf dem endgültigen Siliziumchip verteilt wird. Im Vergleich zu alten K8/K10 Diagrammen fallen erstens die unregelmäßigen, ja fast schon chaotischen Segmentierungen auf. Grund hierfür ist das Verwenden von automatischer Layoutsoftware (Electronic design automation (EDA)), die bisher nur im Embedded/SoC-Bereich gebräuchlich war. Handoptimierte Designs bestehen hingegen aus mehr oder minder aus rechteckigen, regelmäßigen Blöcken. EDA-Software beim Chipentwurf verschwendet zwar etwas Platz, spart aber eine Menge Handarbeit und somit Zeit und Kosten ein. Zweitens fällt bei genauerer Betrachtung die FPU Größe auf. Denn deren Fläche ist verschwindend gering, fast hat man Schwierigkeiten die FPU zu finden. In etwa entspricht sie der Größe des 32kB L1 Caches. Im Vergleich zu alten K8 oder gar K10 Zeiten ein deutlicher Unterschied. In Dresdenboy Blog war einmal eines IEEE Papers zu finden, in dem eine neue FPU beschrieben wird, die in nur 40 Prozent der Fläche der K8 FPU fast die gleiche Leistung bringt und dabei auch noch weit weniger Energie verbraucht. 40 Prozent Fläche käme gut hin. Die Wahrscheinlichkeit ist groß, dass die beschriebene FPU im Bobcat Verwendung findet.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""> </die></doofen></uralt><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Schauen wir uns jetzt im Vergleich dazu Intels Konkurrenzprodukt, den Atom Prozessor an.
Vergleich mit Atom
</die></doofen></uralt></schema></links>Zuallererst muss man beim Atom erwähnen, dass Intel nicht nur den klassischen PC-Markt im Visier hat, sondern von Anfang an auch den der Mobiltelefone im Blick hatte. Aus diesem Grunde ist die Atom Architektur konsequent auf Stromsparen ausgelegt. Eine InOrder-Architektur sollte, dank einfachen Aufbaus, nochmals Transistoren einsparen. AMD hingegen wollte nicht ganz so radikal geizen beim Bobcat und setzt, wie bereits oben erwähnt, auf eine „Out of Order“-Architekur. Genaueres folgt nun in den nächsten Absätzen:<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
[H4]Die Atom Architektur[/H4]
</die></doofen></uralt></schema></links>
Vergleicht man erst einmal nur die bloße Architektur, stellt man auf den ersten Blick nicht viele Unterschiede fest. Genauso wie AMD beim Bobcat setzte auch Intel bereits vor zwei Jahren auf ein 2-issue Design. Der Grund dafür ist, dass bei einem schlanken Leichtkerner ein optimales Verhältnis aus Aufwand und Nutzen besteht. Circa 95 Prozent des x86 Codes lässt sich mit einem 2-issue ohne Datenstau abarbeiten. Der Mehraufwand für komplexe parallele 3-issue (K8/K10 / Core2/Nehalem) lohnt nicht im Low-Power Bereich. AMD ist sogar beim großen Bruder Bulldozer auf eine zweifache Parallelität der Pipelines zurückgekommen. Das ergibt auch bei Hochleistungsdesigns Sinn. Ein ehemaliger AMD Entwickler erklärte dazu, dass der Verzicht auf die dritte Pipeline nur ~5 Prozent Leistung kostet. Belohnt wird die neue Sparsamkeit dafür mit etwas, wonach sich Prozessor-Enthusiasten seit Jahren sehnen – mehr Takt. Konkret spricht die gleiche Quelle von 20 bis 30 Prozent höheren Taktraten <links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">[Quelle]. Aber das sei hier nur am Rande bemerkt.
Schauen wir uns nun die Atom Pipeline genauer an:
[H4]Die Atom Pipeline[/H4]
Wie man sieht hat der Atom die gleiche Pipeline-Länge wie Bobcat, denn Intel zählt die Stufen für den Daten - Cachezugriff in der obigen Illustration fest dazu. Falls aber nur Daten in den Registern manipuliert werden, fallen die drei Stufen natürlich weg. Demnach kann man also wie auch schon im vorherigen Fall eine Übereinstimmung vermelden, beide Designs sind 2issue mit einer 13 (16) Stufen langen Integer Pipeline (je nach Zählweise). Aber wie so oft, liegt der Teufel im Detail. Ein paar Punkte wurden bereits angedeutet, schauen wir sie uns im nächsten Kapitel nun einmal ganz genau an:
</die></doofen></uralt></schema></links>
Der Teufel steckt im Detail
Trotz aller Gemeinsamkeiten gibt es fundamentale Unterschiede zwischen den beiden Ansätzen.Die In-Order und Out-of-Order Entscheidung
Zuallererst muss man die schon angesprochene In-Order Basis des Atoms gegen Bobcats Out-of-Order (OoO) vergleichen.Was ist denn nun besser? Tja, das kommt darauf an, welche Ziele man sich setzt. Hier sieht man nun die Auswirkungen des kleinen aber feinen Unterschiedes in den Anwendungsprofilen beziehungsweise den Designzielen. Während Atom laut Intel irgendwann auch einmal in einem Mobiltelefon auftauchen soll, lässt AMD diesen Markt links liegen. Das hat zur Folge, dass der Atom wirklich knallhart und kompromisslos auf Energiesparen getrimmt wurde, wogegen das Bobcat-Designteam einige leistungssteigernde Kompromisse eingehen durfte.
Der auffälligste und tiefgreifendste dieser Punkte ist eindeutig die Entscheidung für InOrder gegenüber Out of Order (OoO).
Bei InOrder-Designs werden die Befehle so abgearbeitet wie sie kommen. Muss auf einen Cache- oder gar RAM-Zugriff gewartet werden, dann stehen die Rechenräder still. Eine OoO CPU dagegen kann nachfolgende Befehle vorziehen, beziehungsweise Befehle auf gut Glück spekulativ berechnen lassen. Manchmal klappt das nicht und die Spekulation war umsonst, aber die Trefferrate liegt bei modernen OoO Designs oberhalb der 90 Prozent Marke. Insgesamt gibt das Ganze einen gutes Leistungsplus von ca. 20-30 Prozent. Nicht umsonst waren bis zum Atom alle Intel CPUs seit PentiumPro/Pentium-II Zeiten OoO basierend.
[H4]Hyperthreading macht müde In-Order CPUs munter !?[/H4]
Wie wir seit dem letzten Punkt wissen kann eine OoO CPU Cache- und RAM-Wartezeiten besser überbrücken, während eine InOrder CPU stillsteht. Dass das Verschwendung wäre hat auch Intel bemerkt und den Atom deshalb mit Hyperthreading ausgestattet. Damit laufen 2 Threads auf einem Kern. Falls jetzt das Rechenwerk wegen der Wartezeit eines Threads still steht, hat Thread 2 deshalb freie Fahrt. Logischerweise bringt Hyperthreading auf einer InOrder CPU deutlich mehr als auf einer OoO CPU. Gewinnt ein Nehalem mit OoO maximal 20-30 Prozent durch Hyperthreading, so können es bei Atom schon mal bis zu 70 Prozent sein [P3DTest]. Zumindest bei Multithreaded-Anwendungen. Genau da liegt aber jetzt der Hase im Pfeffer. Die Single-Thread Leistung vom Atom ist schon schlecht und wird durch die zusätzliche Belastung eines 2ten Threads nicht besser. Vereinfacht ausgedrückt:
Anstatt eines 2issue Kerns hat man mit Hyperthreading quasi zwei 1issue Kerne. Das lastet zwar die Rechenwerke gut aus, steigert aber nicht die Single-Thread Rechenleistung - eher im Gegenteil.
Berichte in den Foren darüber, dass Atom CPUs nur zäh reagieren würden, oder aber Flash Spielereien nur ruckelnd liefen, sind nicht selten zu finden. Bei Multithread Anwendungen wie Packer, Renderer oder Konvertierungen lässt Hyperthreading zwar die Muskeln spielen, aber solche Anwendungsszenarien sind - außer den Packern - auf so leistungsschwachen Rechnern eher unwahrscheinlich.
Zusätzlich gibt es im Hyperthreadingbetrieb noch eine Menge Einschränkungen. Der parallele Betrieb ist nicht so einfach zu handhaben wie man meinen könnte. Genaueres ist im Optimierungsmanual von Agner Fog in Erfahrung zu bringen.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
</die></doofen></uralt></schema></links>[H4]Das physikalische Registerfile[/H4]
Im Register stehen Daten, die unmittelbar zum Rechnen benötigt werden. Um sie dort hin zu bekommen, werden sie aus dem Cache oder RAM geladen. InOrder CPUs haben den normalen Registersatz, den die ISA zur Verfügung stellt. Im x86 Falle sind das 8 INT und 8 SSE/FP Register, für den 64 Bit Modus stehen je 16 zur Verfügung. OoO CPUs gehen die Sache jetzt etwas kreativer an. CPUs dieser Art beherrschen das Register Renaming. Das ist ein Trick, um mehr schnelle Register zu benutzen, als die x86 ISA zur Verfügung stellt. Für Bulldozer stehen z.B. 160 SSE/FP und 96 INT Register im Raum [Quelle]. Diese vielen Register braucht man v.a. für das spekulative Ausführen von Befehlen. Logischerweise kann man spekulative Berechnungen nicht auf den Orginalregistern herumschreiben lassen, das gäbe ein Datenchaos. Stattdessen bekommen diese ihren eigenen Satz der 16 x86-Register vorgespielt.
Im K8/K10 sowie allen Intel OoO CPUs gibt es nun einen sogenannten ReOrderBuffer (ROB). Wie der Name schon nahe liegt, ist er das Endstück einer OoO Berechung. Seine Aufgabe ist es, die ursprüngliche Befehlsreihenfolge wiederherzustellen. Dazu schreiben Instruktionen, deren Berechnungen in spekulativen Registern abgeschlossen wurden, ihr Endresultat d.h. den Registerinhalt in den ROB. Der ROB wiederum sortiert alle Instruktionen richtig ein, und schreibt die Ergebnisse danach in ein "offizielles" der 8 bzw.16 x86-Register zurück. Wie man nun leicht feststellen kann, wird hier oft kopiert. Das kostet Zeit, vor allem aber auch Strom. Prozessoren mit physikalischen Registern setzen dieser Verschwendung nun einen Riegel vor. Die Daten bleiben immer nur in einem Register, es wird nichts kopiert. Was sich ändert sind nur Verweise darauf.
Vereinfacht ausgedrückt: Anstatt die Daten mit Sack und Pack von einem Haus (=Register) ins nächste zu jagen, wechselt man einfach das Hausnummernschild bzw. den Wegweiser zum Haus aus und protokolliert die Namensvergaben in einem zentralen Adressverzeichnis.
Eine simple Idee die Strom einspart und auch schon in vielen CPU Designs verwendet wurde, u.a. in einigen DEC ALPHA CPUs sowie in IBMs POWER4, 5 und 7 CPUs [Quelle]. Falls jemand nun das Power6 Design vermisst: Das war ein InOrder Design. In der x86 Familie war bisher nur der unrühmliche Pentium4 damit ausgestattet. AMD verwendet die Technik nun sowohl beim Bulldozer als auch beim Bobcat, also bei allen neuen Architekturdesigns - sicher keine schlechte Entscheidung.
Die Fetch-Breite
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""> AMDs Bobcat holt sich pro Takt beachtliche 32byte Daten aus dem Instruktionscache. Dies scheint - zusammen mit den SSE4A Befehlen - ein Erbe des K10 zu sein und überrascht etwas bei einem Mobil-Design. Intel nützt selbst bei den aktuellen High-End CPUs den üblichen 16 Byte Fetch, den es seit seligen PentiumPro Zeiten gibt. AMD setzte beim K8 ebenfalls auf "nur" 16 Byte. Aber nun ja, über zu viel Leistung wird sich niemand beschweren wollen. Vermutlich hat AMD Simulationen gefahren und berechnet, dass die Fetch-Breite nicht viel Energie kostet beziehungsweise sich insgesamt positiv bemerkbar macht.Im Vergleich dazu ist Atoms Fetch-Breite nur mickrig zu nennen. Die offiziellen PDFs und Berichte schweigen sich dazu "zufällig" aus. Prof. Dr. Agner Fog nennt dann auch in seinem bereits erwähnten x86 Optimierungsleitfaden enttäuschende um die 8 Byte. Also nur ein Viertel von Bobcat. Das hat dann negative Auswirkungen, wenn zwei Befehle decodiert werden müssen, die zusammen diese 8 Byte Grenze überschreiten. Vor allem 64 Bit Befehle und praktisch alle SSE2++ Befehle fallen darunter. Das erklärt dann auch Intels Zögern den Atom CPUs die 64 Bit Erweiterung freizuschalten. Die Auswirkungen sind deutlich. Solange das Front-End keine Daten liefert, können die Rechenpipelines auch nichts berechnen; die Rechenleistung sinkt damit auf 1issue. Dies erklärt dann auch das starke Plus durch Hyperthreading. Wegen Hyperthreading ist auch die Fetch-Einheit verdoppelt, so dass dann für zwei Threads 2x8 Byte eingelesen werden können. Das resultiert dann in mindestens zwei SSE Befehlen pro Takt, was ausreichend ist, um die 2issue Recheneinheiten gut auslasten zu können. Nur leider hat man davon nichts im Single-Thread-Betrieb.
</die></doofen></uralt></schema></links>
Zusammenfassung
Zusammenfassend muss man leider sagen, dass es für den Atom nicht gut ausschaut. Das Design ist deutlich für absolutes Stromsparen ausgelegt, um auch im Mobiltelefonmarkt bestehen zu können. Leider gibt es aber noch kein einziges x86 Handy. Eventuell wird sich das ändern, nachdem Intel vor kurzem Infineons Mobiltelefonsparte übernommen hat [Quelle]. Aber trotzdem wird sich der Atom den Mitbewerbern in anderen Segmenten stellen müssen, solange man CPUs im Net- und Notebooks bzw. Nettopbereich absetzen will. Die Vor- und Nachteile sind dabei klar verteilt:Bobcat wird die deutlich bessere Single-Thread Leistung aufweisen. Atom könnte durch Hyperthreading zumindest in Spezialfällen aufholen. Allerdings ist Bobcat kein fertiger Chip, sondern nur ein Designbaustein. Erstmals werden zwei Bobcat Kerne im bereits erwähnten Ontario/Zacate Fusion Chip Verwendung finden. Setzt man dem nun zwei Atom Prozessoren eines Pineview Atoms mit Hyperthreading gegenüber, ist die Rechnung quasi 2x2issue gegen 4x1issue. 2x2 dürfte dabei das deutlich komfortablere User Erlebnis bieten.
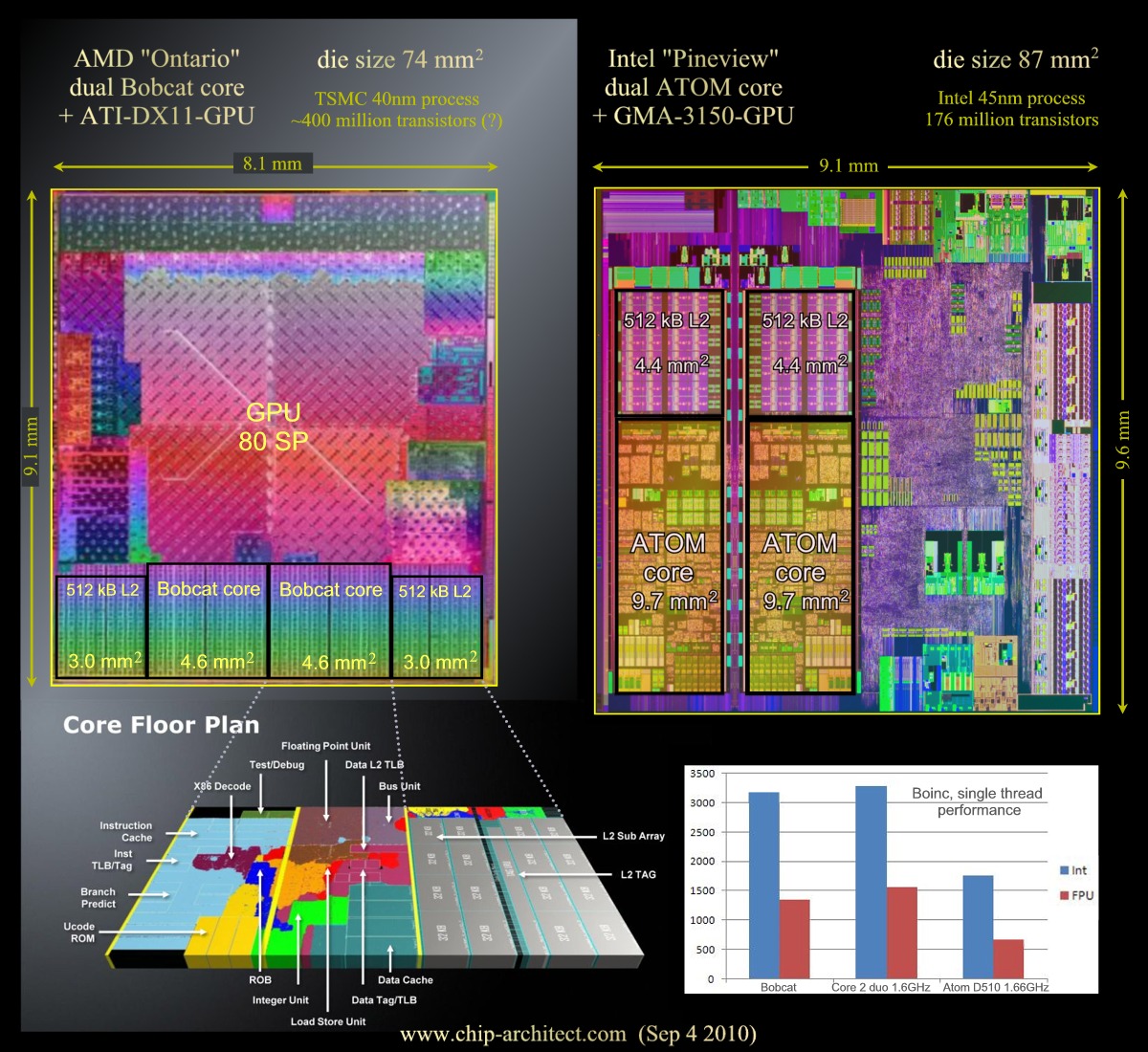
AMD könnte somit durch den Verzicht aufs Handygeschäft und großzügigeren Verbrauchsbudget einen deutlichen Vorteil gegenüber Intel haben. Dieser könnte sogar größer ausfallen als vermutet. Geht man normalerweise davon aus, dass ein OoO Kern größer als ein InOrder Design sein müsste, weist die neueste Vergleichsgrafik von Hans de Vries einen Flächenvorteil von Bobcat gegenüber Atom aus:
Zwar hat AMD auch einen leichten Fertigungsvorteil von 40nm gegenüber 45nm, dennoch ist es beachtlich, dass ein einzelner Bobcat-Kern kleiner ist.
<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^="">
Ausblick
</die></doofen></uralt></schema></links>Nachdem nun bekannt ist, dass nicht nur Bobcats Rechenleistung sondern auch Ontarios Die-Flächenverbrauch konkurrenzfähig ist, kann man vom Bobcat das erwarten, wofür eher der Name des größeren Bruders Bulldozer stehen würde – den Gegner wegschieben - so wie amerikanische Pioniere im zweiten Weltkrieg feindliche Bunkerfestungen mit Planierraupen einfach überrollten: Das untere Marktsegment wird mit den vollintegrierten Bobcat-Kernen neu definiert. Selbst der aktuelle integrierte Pineview-Atom ist in allen Belangen unterlegen. Wenn man den Vergleich auf den ganzen Chip, inklusive ATI-Grafikteil ausweitet, wird der AMD Vorteil eher noch größer ausfallen. Selbst beim Verbrauch liegt Atom nicht vorne. Intel gibt für einen Einzelkern-Pineview mindestens 7 Watt an. Für den Zweikerner fallen schon 15 Watt an [Quelle]. Ontario und Zacata werden sich dagegen zwischen 9 und 18 Watt eingruppieren. Angesichts der deutlich höheren Rechen- und Grafikleistung absolut akzeptabel.Einzige Unbekannte der obigen Spekulation wären deutlich geringere Taktfrequenzen von Ontario im Vergleich zum Atom. Zwar sollte auch in diesem Fall der Fertigungsvorteil eine positive Rolle für Bobcat spielen, dennoch bleibt eine gewisse Unsicherheit, die es zu beobachten gilt. Außerdem könnte sich AMD den Leistungsvorteil natürlich auch gut bezahlen lassen, in diesem Fall bliebe für Atom die Lücke der Lowest-Cost-Netbooks.
Wenn wir mit dieser Spekulation nun in der Gerüchteküche angelangt sind, soll auch nicht verschwiegen werden, dass vielleicht sogar Apple Ontario verwenden wird. Als OpenCL Verfechter der ersten Stunde setzt Apple auf leistungsfähige GPUs. Somit ist es nicht verwunderlich, dass Apple Interesse am Ontario nachgesagt wurde [Quelle].<links><schema><uralt folie=""><doofen marketingname="" einfügen=""><die zahlen="" gibts="" hoffentlich="" irgendwo="" auf="" der="" marketingfolie="" ^^=""><bla>
</bla></die></doofen></uralt></schema></links>Richtig interessant wird Intel vermutlich erst wieder werden, wenn im zweiten Halbjahr 2011 die 32nm Atom Chips auf den Markt kommen. Bis dahin aber wird das Bulldözerchen alias Bobcat im Markt für größere Bewegungen sorgen.
Danksagungen
- Mitglied jcworks für das Korrekturlesen
- Mitglied Martin Bobowsky für die Textüberarbeitung
- Hans de Vries für seine Ontario <> Pineview Vergleichsgrafik
- Dresdenboy für den Link auf die K8 Pipeline
- Golem für das Ontario Bild von der IFA 2010
Zuletzt bearbeitet:
- Mitglied seit
- 18.11.2008
- Beiträge
- 11.422
- Renomée
- 731
- Standort
- 8685x <><
- Aktuelle Projekte
- Spinhenge; Orbit; Milkyway
- Lieblingsprojekt
- Orbit@home; Milkyway@home
- Meine Systeme
- Tuban, 3,8~ Ghz x6 /Turbo 4,095GHz 2x Radeon HD 5850@5870 CFx. // Rechner 2: 5900x B02 //3= 9850 /4 = Rasp
- BOINC-Statistiken

- Mein Desktopsystem
- 5900xt (bis 5,3Ghz Boost); 3900x (bis 4,66 Boots); Thuban 1090x(bis 4 GHz Turbo)
- Mein Laptop
- P-
- Details zu meinem Desktop
- Prozessor
- siehe oben. alles Lukü mit max Anzahl ausgesuchter sehr starker Lüfter. (Rechner 3 = R 9 3900x
- Mainboard
- Asus MSI b 550 Tomahawk/; M4A79Deluxe für Thuban / MSI b 550 Tomahawk für R 9
- Kühlung
- ausgesklügelte Luftkühlung mit starkem Airflow
- Speicher
- vollbelegung
- Grafikprozessor
- Midrange oc 12GB /& 8 GB / & 3GB
- Display
- 2x 22" |(Benq; LG) und 1x 23,6" Samsung TFTs Eyefinity +2x21" für die anderen Rechner
- SSD
- 3x
- HDD
- (Tower voll!)
- Optisches Laufwerk
- Asus SATA-DVD RW
- Soundkarte
- o.b.
- Gehäuse
- ANTEC Twelfehundred Bequiet u.a.
- Netzteil
- vorhanden überall
- Tastatur
- ja gibt es jes
- Maus
- ja
- Betriebssystem
- Win 7 V 64 / und alternative
- Webbrowser
- Opera &/ IEE64/ &Safari und alternative
- Verschiedenes
- Thuban: |V-CoreCPU =1,23- 1,47V Turbo//norm. VID= 1,45V System läuft mit 4 Upgrades seit 2008 stabil!
Klasse und übersichtlich gemacht, Alex...Danke!
hört sich durchaus vielversprechend an! Amd wäre es zu wünschen, dass alles so klappt.
hört sich durchaus vielversprechend an! Amd wäre es zu wünschen, dass alles so klappt.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Jopp, schöne Auflistung... "Bulldözerchen" klingt ja niedlich 
Um den Fluff-Faktor noch etwas zu Steigern könntest du noch Dresdenboys Bild mit dem Bobcat aus dem Rostocker Zoo einbinden, der sich danach sehnt einen Atom zu verspeisen
Ich bin wirklic hgespannt auf Ontario und die ersten Konkreten Daten, Benches, (P)Reviews usw.
IMHO dürfte Ontario angesichts der schwindenden Bedeutung des desktopmarktes, gegenüber Llano das wesentlich wichtigere Fusion-Produkt darstellen. Im Endkundenmarkt wohl sogar bedeutender als Bulldozer...
Gruß
ich
Um den Fluff-Faktor noch etwas zu Steigern könntest du noch Dresdenboys Bild mit dem Bobcat aus dem Rostocker Zoo einbinden, der sich danach sehnt einen Atom zu verspeisen
Ich bin wirklic hgespannt auf Ontario und die ersten Konkreten Daten, Benches, (P)Reviews usw.
IMHO dürfte Ontario angesichts der schwindenden Bedeutung des desktopmarktes, gegenüber Llano das wesentlich wichtigere Fusion-Produkt darstellen. Im Endkundenmarkt wohl sogar bedeutender als Bulldozer...
Gruß
ich

 Gibts davon auch andere Quellen? Falls nicht, kann man die Bilder auch als Attachment im Forum hochladen
Gibts davon auch andere Quellen? Falls nicht, kann man die Bilder auch als Attachment im Forum hochladen Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ne, das wäre dann zuviel Spielerei, da soll mal noch ein offizieller P3D Artikel daraus werden. Die Überschrift ist auch eher so gemeint, dass Bobcat die Mitbewerber in Bulldozer Manier überrollen wird. Nur halt in nem anderen SegmentUm den Fluff-Faktor noch etwas zu Steigern könntest du noch Dresdenboys Bild mit dem Bobcat aus dem Rostocker Zoo einbinden, der sich danach sehnt einen Atom zu verspeisen
Das scheint sich mittlerweile zu bestätigen:

Wenn das wirklich stimmt, dann gute Nacht Atom
Das Bildchen kommt auch noch mit rein, passt perfekt
")
Das dagegen nicht

auch wenns fluffig ist
ciao
Alex
P.S: Danke auch an dieser Stelle an jcworks fürs Korrekturlesen.
jcworks
Admiral Special
- Mitglied seit
- 17.09.2002
- Beiträge
- 1.030
- Renomée
- 27
- Standort
- Kümmersbruck/BY
- Aktuelle Projekte
- Simap, Docking, Spinhenge, QFA, Poem
- Lieblingsprojekt
- Simap; (medizinische Projekte sind für mich sinnvoll)
- Meine Systeme
- AMD PhenomII-1090, 955, 910e, AMD AthlonII-250, Athlon X2-5000@CAD, intel C2D-Merom
- BOINC-Statistiken

- Mein Laptop
- Dell Vostro 1700 - C2D-Merom 2GHz
- Details zu meinem Desktop
- Prozessor
- AMD Phenom X6-1090
- Mainboard
- Gigabyte MA790FX-DQ6
- Kühlung
- Scythe Mugen 2
- Speicher
- Corsair DDR2RAM 2x 1GB DDR2-800
- Grafikprozessor
- ATI Radeon 4770
- Display
- 23", Iiyama, X2377HDS
- HDD
- Samsung HD252KJ
- Optisches Laufwerk
- Sony SH-S203P
- Soundkarte
- onboard
- Gehäuse
- HQ farbig LCD Display 6125
- Netzteil
- bequiet BQT E6-350Watt
- Betriebssystem
- W-XPpro
- Webbrowser
- Firefox 3.5.19
P.S: Danke auch an dieser Stelle an jcworks fürs Korrekturlesen.
hehe.. Danke fürs Danke *g*
aber der Text bzw der Artikel ist ja von dir... ich hab nur ein bißchen 'genörgelt' ^^
... nun gehts aber weiter.. will ja alle Geheimnisse des Bulldözerchens kennenlernen..
")
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Auch ARM hat sich zukünftig für OoO-Designs entschieden - denn der Cortex-Kern ist ebenso ein OutofOrder-Kern. Genau deswegen hat ARM gerade noch so eben im Jahr 2004 Artisan erworben.
Der Handy-Bereich ist also nicht zwingend auf InOrder Prozessoren angewiesen, um besonders stromsparend zu sein ... ansonsten ist das aber schon prima mit dem Thread hier.
MFG Bobo(2010)
Der Handy-Bereich ist also nicht zwingend auf InOrder Prozessoren angewiesen, um besonders stromsparend zu sein ... ansonsten ist das aber schon prima mit dem Thread hier.
MFG Bobo(2010)
p4z1f1st
Grand Admiral Special
- Mitglied seit
- 28.04.2003
- Beiträge
- 9.722
- Renomée
- 81
- Details zu meinem Desktop
- Prozessor
- AMD FX-6300
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- HEATKILLER® CPU Rev3.0 LC + HEATKILLER® GPU-X² 69x0 LT
- Speicher
- 2x 4096 MB G.Skill RipJawsX DDR3-1600 CL7
- Grafikprozessor
- AMD Radeon RX 480 8GB
- Display
- Dell U2312HM
- HDD
- Crucial m4 SSD 256GB
- Optisches Laufwerk
- Sony Optiarc AD-7260S
- Soundkarte
- Creative Labs SB Audigy 2 ZS
- Gehäuse
- Chieftec Scorpio TA-10B-D (BxHxT: 205x660x470mm)
- Netzteil
- Seasonic X-Series X-660
- Betriebssystem
- Microsoft Windows 10 Professional 64bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- Watercool HTF2 Dual + 2x Papst 4412 F/2GL
O - M - G
Wo ist der "Danke"-Button?
Wo ist der "Danke"-Button?
nazgul99
Grand Admiral Special
- Mitglied seit
- 01.05.2005
- Beiträge
- 3.592
- Renomée
- 224
- Standort
- Irgendwo in der Nähe
- Mein Laptop
- ThinkPad Edge E145 / 8GB / M500 480GB / Kubuntu /// Asus U38N / 6GB / Matt / Postville / Kubuntu/W8
- Details zu meinem Desktop
- Prozessor
- AMD A10-7800
- Mainboard
- MSI A88XI AC
- Kühlung
- Scythe Shuriken Rev.2
- Speicher
- 2x 8GB DDR3-2133
- Grafikprozessor
- IGP
- Display
- HP LP2465, MVA, 1920x1200, 24"
- SSD
- Samsung 850 EVO 500GB
- HDD
- ST9500325AS 500GB
- Optisches Laufwerk
- ja, so'n USB-Dings
- Soundkarte
- onboard, optisch -> SMSL Q5 PRO -> ELAC EL60
- Gehäuse
- Silverstone ML06B
- Netzteil
- SST-ST30SF
- Betriebssystem
- Kubuntu
- Webbrowser
- Firefox
- Verschiedenes
- Synology DS414slim 3x 1,5 TB RAID5
Wo ist der "Danke"-Button?
Such ich auch schon nach ... *gedrückt* Opteron!
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Nero oder Dr@ machen da demnächst nen Artikel drauß, da dürft Ihr dann drücken
Wobei ich zu meiner Schande selbst zugeben muss, dass ich den Mechanismus dahinter selbst nicht checke ^^
Beim normalen Danke wird ja dem News Ersteller gedankt, aber mittlerweile gibts da irgendwie ein 2tes Danke für den Autor. Falls irgendwer nen Link hat, wo beschrieben wird wies geht ... bitte gerne ^^
Wobei ich zu meiner Schande selbst zugeben muss, dass ich den Mechanismus dahinter selbst nicht checke ^^
Beim normalen Danke wird ja dem News Ersteller gedankt, aber mittlerweile gibts da irgendwie ein 2tes Danke für den Autor. Falls irgendwer nen Link hat, wo beschrieben wird wies geht ... bitte gerne ^^
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
So nun - Feuer Frei, möge sich ein Admin des Textes annehmen und eine News Meldung daraus basteln
Danke nochmals an Bobo fürs Textüberarbeiten.
Falls noch irgendjemand Tipp, Komma, oder sonstige Fehler findet, einfach editieren, ich melde mich aus dem Thread für heute ab ^^
Danke nochmals an Bobo fürs Textüberarbeiten.
Falls noch irgendjemand Tipp, Komma, oder sonstige Fehler findet, einfach editieren, ich melde mich aus dem Thread für heute ab ^^
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
In x86 vielleicht eher als bei anderen architekturen....Der Handy-Bereich ist also nicht zwingend auf InOrder Prozessoren angewiesen, um besonders stromsparend zu sein ...
Kann mal jemand gegenchecken wie groß das Frontend im Vergleich bei einem ARM ist? - denn das was man an einer stelle mehr hat, muss man ja woanders wieder einsparen....
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Da gibts doch den berühmten Vergleich, bei dem ein ARM Kern so gro0 wie der x86 Dekoder des Atoms ist ^^In x86 vielleicht eher als bei anderen architekturen....
Kann mal jemand gegenchecken wie groß das Frontend im Vergleich bei einem ARM ist? - denn das was man an einer stelle mehr hat, muss man ja woanders wieder einsparen....
.
EDIT :
.
Falls noch irgendjemand Tipp, Komma, oder sonstige Fehler findet, einfach editieren, ich melde mich aus dem Thread für heute ab ^^
Ok, hab doch noch ne FPU Info beim Floorplan ergänzt, nachdem mir aufgefallen ist, dass Bobcats FPU winzig ist
Jetzt aber ..
Gute Nacht
Noch eine Info ans P3D Team: Bin morgen erst wieder abends online.
Mal eine kleine Anmerkung zu den Pipelinelängen. Bei der Abbildung zum K8/K10 wurde wie beim Atom auch keine Unterscheidung zwischen AGU/ALU-Pipeline gemacht. Die Branch Mispredict Penalty eines K10 beträgt genau 10 Takte (die DC-Stufen fallen weg, es geht direkt nach einer ALU-Instruktion wieder nach vorne), also ganze 3 Takte weniger als bei Bobcat. Es ist somit sozusagen ein 10/12 Stufen Design (ALU/AGU), während Bobcat 13/15 Stufen aufweist (es kommen bei Bobcat für AGU-Instruktionen nur zwei Stufen dazu nicht drei, wie im Artikel steht, das Pipelinediagramm zeigt das eigentlich deutlich).
Die 3 zusätzlichen Stufen des Bobcat gegenüber dem K10 verteilen sich auf eine Stufe im Fetch und die beiden Stufen zum Zugriff auf das PRF (RegRead und Writeback).
Die 3 zusätzlichen Stufen des Bobcat gegenüber dem K10 verteilen sich auf eine Stufe im Fetch und die beiden Stufen zum Zugriff auf das PRF (RegRead und Writeback).
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Oh Mann, auch noch ne Unterteilung nach AGU/ALU *g*Mal eine kleine Anmerkung zu den Pipelinelängen. Bei der Abbildung zum K8/K10 wurde wie beim Atom auch keine Unterscheidung zwischen AGU/ALU-Pipeline gemacht. Die Branch Mispredict Penalty eines K10 beträgt genau 10 Takte (die DC-Stufen fallen weg, es geht direkt nach einer ALU-Instruktion wieder nach vorne), also ganze 3 Takte weniger als bei Bobcat. Es ist somit sozusagen ein 10/12 Stufen Design (ALU/AGU), während Bobcat 13/15 Stufen aufweist
Dass FPU, L2 etc. extra sind ist klar, aber muss man die AGUs wirklich unbedingt mitzählen
Aber ich sehe schon dass Du recht hast, ist unterschiedlich.
Öh ja, da sind deutlich 3 Stufen:(es kommen bei Bobcat für AGU-Instruktionen nur zwei Stufen dazu nicht drei, wie im Artikel steht, das Pipelinediagramm zeigt das eigentlich deutlich).
AGU/DC1/DC2, wie oder was zählst Du denn genau ?
Die eine Stufe im Fetch fällt, weg, da gegenüber dem K8 die "Pick" Stufe weggefallen ist, da meinte aber schon mal wer (ich glaub Hans de Vries, aber nagel mich nicht fest), dass man das genausogut Fetch 2 nennen könnte ... da dachte ich mir also nichts dabei.Die 3 zusätzlichen Stufen des Bobcat gegenüber dem K10 verteilen sich auf eine Stufe im Fetch und die beiden Stufen zum Zugriff auf das PRF (RegRead und Writeback).
Aber ne andre Frage, weisst Du, was die Fetch 3,4,5 sein sollen ?
ciao
Alex
P.S: Ausserdem sehe ich gerade, dass sich auch noch eine zusätzliche Decode Stufe eingeschlichen hat ...
Die obige Pipeline zählt ab 1, die untere schon ab 0 ... doof ^^
Zuletzt bearbeitet:
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Hallo,
Ich möchte mich im Namen des gesamten P3D-Teams bei allen am Artikel Beteiligten und ganz besonders bei Opteron bedanken. Vielen vielen Dank!
Der Artikel ist wirklich toll geworden und taugt auch als Modell für zukünftige Community-Artikel - wie ich es mal nennen möchte! Gerade der kollaborative Ansatz gefällt mir besonders gut. Großes Lob an alle Beteiligten von mir!
Wenn mal wieder jemand eine Idee zu einem Artikel hat und diesen hier auf P3D veröffentlichen will, dann meldet euch einfach mal bei uns. Da lässt sich bestimmt was machen. Kompetent und verständlich geschriebene Artikel sind immer gern gesehen.
MfG @
Ich möchte mich im Namen des gesamten P3D-Teams bei allen am Artikel Beteiligten und ganz besonders bei Opteron bedanken. Vielen vielen Dank!
Der Artikel ist wirklich toll geworden und taugt auch als Modell für zukünftige Community-Artikel - wie ich es mal nennen möchte! Gerade der kollaborative Ansatz gefällt mir besonders gut. Großes Lob an alle Beteiligten von mir!
Wenn mal wieder jemand eine Idee zu einem Artikel hat und diesen hier auf P3D veröffentlichen will, dann meldet euch einfach mal bei uns. Da lässt sich bestimmt was machen. Kompetent und verständlich geschriebene Artikel sind immer gern gesehen.
MfG @
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken
- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
@Dr@:
Hattest Du kein Bobcat Die Photo schießen können ? Dann wär das böse cb Wasserzeichen auch weg ^^
Bei Golem gibts eines ohne Wasserzeichen.
")
Ich hatte die Möglichkeit, hab mich aber zu dusselig angestellt. Die Bilder sind alle nix richtig geworden. Hätte ich vorher gewusst, was ich da alles fotografieren konnte, dann hätte ich mich besser vorbereitet.
Du könntest höchstens dieses hier einfügen (Ontario + Champlain + meine Hand mit Uhr + John Taylor):
Wir sollen aber von AMD noch Material bekommen. Die Folien der Präsentation und auch die Videos von den Demos. Bisher ist aber noch nichts angekommen. Mal abwarten.
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ja ne, das hab ich schon gesehen, da ist mir der Kopf in der Mitte zu dominant ^^
Auschneiden macht auch keinen Sinn, da es zu klein ist.
Edit:
Editieranforderungen an den aktuellen Artikel:
a) Seite 2:
CB Bild austauschen durch das von Golem, das hat kein Wasserzeichen:

Änder das bitte auch im Artikel, passe den Quelllink an auf:
http://scr3.golem.de/?d=1009/Bobcat-IFA&a=77709
b) Seite 3:
Das Pipelinebild durch das von Dresdenboy austauschen:

Zusätzlich den Text ändern auf:
<TODO>
c)Ausserdem noch diesen Satz auf Seite 4 (Die In-Order und Out-of-Order Entscheidung) ändern:
Alt:
d)
Zusätzliche dann auf der letzten Seite 5:
Absatz <Ausblick>
Alt:
http://newsroom.intel.com/community...oks-hit-shelves-today?cid=rss-90004-c1-258388
Danke auf golem ändern, nicht cb
Danke an Mitglieder Gipsel und Dresdenboy für den Hinweise und Korrekturen auf Fehler in der Illustration der Bobcat Pipeline und den zugehörigen Text
Thx
Alex
Auschneiden macht auch keinen Sinn, da es zu klein ist.
Edit:
Editieranforderungen an den aktuellen Artikel:
a) Seite 2:
CB Bild austauschen durch das von Golem, das hat kein Wasserzeichen:
Änder das bitte auch im Artikel, passe den Quelllink an auf:
http://scr3.golem.de/?d=1009/Bobcat-IFA&a=77709
b) Seite 3:
Das Pipelinebild durch das von Dresdenboy austauschen:
Zusätzlich den Text ändern auf:
<TODO>
c)Ausserdem noch diesen Satz auf Seite 4 (Die In-Order und Out-of-Order Entscheidung) ändern:
Alt:
Neu:Nicht umsonst waren bis Atom alle Intel CPUs seit Pentium1 Zeiten OoO basierend.
Da stand mal "nach dem Pentium1", aber so wie der Satz jetzt steht, ist er natürlich falsch ^^Nicht umsonst waren bis zum Atom alle Intel CPUs seit PentiumPro/Pentium-II Zeiten OoO basierend.
d)
Zusätzliche dann auf der letzten Seite 5:
Absatz <Ausblick>
Alt:
Neu:Selbst beim Verbrauch liegt Atom nicht vorne. Intel gibt für einen Einzelkern-Pineview mindestens 7 Watt an. Für den Zweikerner fallen schon 15 Watt an [Quelle]. Ontario und Zacata werden sich dagegen zwischen 9 und 18 Watt eingruppieren. Angesichts der deutlich höheren Rechen- und Grafikleistung absolut akzeptabel.
Selbst beim Verbrauch liegt Atom nur sehr knapp vorne. Intel gibt für einen Einzelkern-Pineview mindestens 7 Watt an. Für den Zweikerner fallen schon 15 Watt an [Quelle]. Der kürzlich Anfang September 2010 vorgestellte Zweikern Atom N550 kann diese 15W jetzt zwar immerhin mit 8,5W deutlich unterbieten - allerdings auf Kosten des Takt, der bei nur 1,5 GHz liegt. Ontario und Zacata werden sich mit jeweils 2 Kernen zwischen 9 und 18 Watt eingruppieren. Angesichts der deutlich höheren Rechen- und Grafikleistung absolut akzeptabel.
http://newsroom.intel.com/community...oks-hit-shelves-today?cid=rss-90004-c1-258388
Danke auf golem ändern, nicht cb
Danke an Mitglieder Gipsel und Dresdenboy für den Hinweise und Korrekturen auf Fehler in der Illustration der Bobcat Pipeline und den zugehörigen Text
Thx
Alex
Zuletzt bearbeitet:
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken
- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Ich habe leider keinen Zugriff auf den Artikel. Das muss Nero machen.
Die ALU-Stufe wird durch die AGU-Stufe ersetzt. Deswegen sind es nur die zwei DC-Stufen zusätzlich (schau mal, wo die Pfeile abzweigen, und wo sie sich wieder einordnenÖh ja, da sind deutlich 3 Stufen:
AGU/DC1/DC2, wie oder was zählst Du denn genau ?
). Das sieht im Prinzip genau so wie bei K8/K10 aus: entweder ALU oder AGU und im AGU-Fall noch die zwei Stufen für den DC-Zugriff oben drauf.Ich würde mal tippen, daß das optionale Stufen sind, falls die Decoder so schnell waren (oder eben die x86-Instruktionen so lang), daß im aktuellen Fenster keine zwei Instruktionen mehr drin waren (sprich die über die Grenze zum nächsten Fenster reichen) und noch auf die nächsten 256Bit gewartet werden muß. Aber nagel mich nicht darauf fest.Aber ne andre Frage, weisst Du, was die Fetch 3,4,5 sein sollen?
Opteron
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Also da sind wir uns dann nicht über die Pfeilsemantik im Klaren.Die ALU-Stufe wird durch die AGU-Stufe ersetzt. Deswegen sind es nur die zwei DC-Stufen zusätzlich (schau mal, wo die Pfeile abzweigen, und wo sie sich wieder einordnen
MMn zeigt der erste Pfeil von der AGU zur RegRead/vor ALU, dass dort die Adresse übergeben wird, damit dann die ALU losrechnen kann.
Das gleiche zuvor beim µCode Rom. Der erste Pfeil geht rein, der zweite raus.
Für die AGU hieße das, dass die AGU ne Adresse vor die ALU liefert und dann die Berechnung losgeht.
Problem an der Idee:
Wo ist der Inputpfeil für die AGU ^^
Problem bei Deiner Idee, dass das eingeschoben wird und die ALU Stufe damit ersetzt wird: Wo ist die ALU ? Wird dann nichts berechnet ?
Bisher, beim K8 wars so, dass die Rechen-Op in der ResStation wartet, bis die Adresse berechnet ist, und wenn davon der Input kommt, dann gehts weiter. Siehe auch nach dem nächsten Zitat:
Das läuft beim K8/K10 parallel ab, ALU und AGU Op gleichzeitig, deswegen steht das im K8 Diagramm auch als eine Stufe drin. Allerdings sind das ALU/AGU Ops von 2 unterschiedlichen MacroOps.Das sieht im Prinzip genau so wie bei K8/K10 aus: entweder ALU oder AGU und im AGU-Fall noch die zwei Stufen für den DC-Zugriff oben drauf.
Ich glaube da mal, dass da zu arg vereinfacht wurde.Beim Bobcat ist auch noch ein Taktsignal dabei, beim K8 nicht, da sind das nur Pipelinestufen.
Kann auch nicht sein, da Bobcat laut dem vollen Foliensatz nen 32byte Prefetch hat, die längste x86 Intruktion ist aber nur 15Byte lang, ergo reicht das immer für 2 x86 Instruktionen pro Takt...Ich würde mal tippen, daß das optionale Stufen sind, falls die Decoder so schnell waren (oder eben die x86-Instruktionen so lang), daß im aktuellen Fenster keine zwei Instruktionen mehr drin waren (sprich die über die Grenze zum nächsten Fenster reichen) und noch auf die nächsten 256Bit gewartet werden muß. Aber nagel mich nicht darauf fest.
Vielleicht zusätzliche Stufen für ein paar Sonderfälle, die nicht oft vorkommen ?
Da ist auch ein Fehler im Bobcat-Pipelinediagramm. Das ist ja gewissermaßen ein Ablaufplan, der immer strikt von links nach rechts abläuft und eben Verzweigungen entsprechend der Pfeile enthalten kann. Das Problem ist jetzt, daß der Pfeil nach RegRead zu AGU offensichtlich in die falsche Richtung zeigt (weg von AGU, aber dann würde man da ja nie hinkommenAlso da sind wir uns dann nicht über die Pfeilsemantik im Klaren.
). Denn das läuft doch so ab:Ein AGU-Befehl wir gescheduled, die Adresse
") /Offset/Scale wird aus den Registern gelesen (RegRead), der AGU-µOp macht eine Adresse draus (AGU), woraufhin auf den DatenCache zugegriffen wird (DC1+2). Tritt dabei ein L1-Miss auf, geht es nach DC2 mit dem L2-Zugriff weiter, der dann irgendwann auch das Ergebnis liefert. In jedem Fall kehrt man irgendwann auf die "Hauptlinie" des Diagramms zurück und schreibt die Daten in ein Register (Writeback).
/Offset/Scale wird aus den Registern gelesen (RegRead), der AGU-µOp macht eine Adresse draus (AGU), woraufhin auf den DatenCache zugegriffen wird (DC1+2). Tritt dabei ein L1-Miss auf, geht es nach DC2 mit dem L2-Zugriff weiter, der dann irgendwann auch das Ergebnis liefert. In jedem Fall kehrt man irgendwann auf die "Hauptlinie" des Diagramms zurück und schreibt die Daten in ein Register (Writeback).Wie gesagt ist das ein Ablaufdiagramm, kein Datenflußdiagramm. Result-Forwarding (für ALUs wichtiger) gibt es natürlich trotzdem, so daß eine abhängige ALU-Instruktion, die auf eine AGU-Instruktion gewartet hat, direkt loslegen kann, wenn die AGU-Instruktion bei Writeback ankommt. Sowas hat der Scheduler im Griff. Deswegen steht ja auch "Load-Use-Latency L1 Hit: 3-cyles" dran, sonst wären es 5 (3 für die AGU-Instruktion und Zugriff + Writeback der AGU + ReadReg der ALU).MMn zeigt der erste Pfeil von der AGU zur RegRead/vor ALU, dass dort die Adresse übergeben wird, damit dann die ALU losrechnen kann.
Was uns zeigt, das µcoded Instruktionen 2 Zyklen Penalty haben. Die Fast-Decoder erzeugen einen Offset in den µCode-ROM, der Zugriff dauert 2 Takte, dann geht es weiter wie normal.Das gleiche zuvor beim µCode Rom. Der erste Pfeil geht rein, der zweite raus.
Siehe oben. Eine ALU kann mit einer Adresse gar nichts anfangen, die rechnet immer nur mit Werten in Registern. Die AGU liefert die Daten im Registerfile ab, danach kann die ALU mit den Daten rechnen.Für die AGU hieße das, dass die AGU ne Adresse vor die ALU liefert und dann die Berechnung losgeht.
Nö, eine AGU-Instruktion ist eine AGU-Instruktion. Eine abhängige (oder auch unabhängige) ALU-Instruktion läuft getrennt durch die Pipeline.Problem bei Deiner Idee, dass das eingeschoben wird und die ALU Stufe damit ersetzt wird: Wo ist die ALU ? Wird dann nichts berechnet ?
Das ist bei ziemlich jeder CPU so.Bisher, beim K8 wars so, dass die Rechen-Op in der ResStation wartet, bis die Adresse berechnet ist, und wenn davon der Input kommt, dann gehts weiter.
Nö, das sind praktisch zwei parallele Pipes. Die waren bloß zu faul eine Verzweigung (oder eben 2 Pipelinediagramme) wie bei Bobcat zu zeichnen (wo sie ja auch glatt den Pfeil falsch rum erwischt haben). Wie oben schon gesagt, beträgt die Branch Mispredict Penalty eines K10 nur 10 Takte, die beiden DC-Stufen treffen also wie bei Bobcat nur für AGU-Instruktionen zu.Das läuft beim K8/K10 parallel ab, ALU und AGU Op gleichzeitig, deswegen steht das im K8 Diagramm auch als eine Stufe drin. Allerdings sind das ALU/AGU Ops von 2 unterschiedlichen MacroOps.
Der wird vielleicht immer gleich eine ganze Cacheline (64Byte) über 2 Takte fetchen (oder die 256 Bit kommen dadurch zustande, daß über 2 Takte je 128Bit geholt werden) und erst damit weitermachen, wenn der entsprechende Puffer hinreichend leer ist. Wenn ich mich richtig erinnere hatte K8 einen 128Bit fetch in einen 24 Byte Puffer. Die nächsten 16 Byte konnten erst gefetcht werden, wenn im Puffer 8 Byte oder weniger übrig waren. Und dann kann es schon zu einem temporären Engpaß kommen. Aber wie gesagt, nagle mich nicht darauf fest.Kann auch nicht sein, da Bobcat laut dem vollen Foliensatz nen 32byte Prefetch hat, die längste x86 Intruktion ist aber nur 15Byte lang, ergo reicht das immer für 2 x86 Instruktionen pro Takt...
Vielleicht zusätzliche Stufen für ein paar Sonderfälle, die nicht oft vorkommen ?
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 812
- Aufrufe
- 113K
- Antworten
- 8
- Aufrufe
- 4K
- Antworten
- 10
- Aufrufe
- 4K
- Antworten
- 34
- Aufrufe
- 10K