App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Zambezi - Fehler, Bugs, mangelnde Performance - Woran liegt es?
- Ersteller rasmus
- Erstellt am
rasmus
Admiral Special
- Mitglied seit
- 07.07.2008
- Beiträge
- 1.191
- Renomée
- 47
- Mein Laptop
- Notebook, was ist das?
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 3600
- Mainboard
- MSI B450M PRO-VDH MAX
- Kühlung
- Luft
- Speicher
- 32 GB Gskill Ripjaws
- Grafikprozessor
- Nvidia 3070 ti FE
- Display
- Asus PB278Q 27" 2560*1440
- SSD
- Ja
- HDD
- auch
- Optisches Laufwerk
- ja
- Soundkarte
- onboard
- Gehäuse
- irgendwas mit glas
- Netzteil
- thermaltake toughpower pf1 750W
- Maus
- Rat 9
- Betriebssystem
- Win 7 64bit, Win 10 64 bit
- Webbrowser
- Firefox
- Verschiedenes
- http://valid.canardpc.com/show_oc.php?id=628058
Nachdem die neue Bulldozer Architektur Einzug in die Desktop-Prozessoren bei AMD gehalten hat, stellt sich (nicht nur für mich hoffe ich) die Frage, gibt es dort ernsthafte Fehler, Probleme mit der Architektur, dem Prozess oder den Treibern... was kann dazu geführt haben, daß Zambezi in verschiedenen Bereichen so deutlich unterhalb des Konkurrenten und auch der alten Architektur des eigenen Hauses liegt.
FX ist da - und ich bin ganz froh, daß er da ist, denn es geht voran mit neuen Ideen - nun bin ich sehr neugierig, ob sich herausfinden lässt, ob Bulldozer nicht doch einfach grandios ist, allerdings Fehler in Umsetzung, Fertigung, etc. dazu führten, daß die erste Version einfach im gefühlten Pre-Beta Stadium ausgeliefert wird.
Jetzt kann man natürlich hergehen und alles auf die (Software-)Optimierungen schieben, aber darum soll es nicht gehen, vielmehr erscheint doch logisch, das AMD sich erhofft und ausgerechnet hat, zumindest auf dem gleichen Leistungsniveau wie die alte Archi bei den aktuellen Softwares und Anwendungsgebieten zu bleiben.
Ich habe bereits ein bisschen hier und da gesucht und bisher hört man:
Natürlich hat nichts davon bereits Anspruch auf Richtigkeit, da es bisher alles noch nicht bewiesen ist.
FX ist da - und ich bin ganz froh, daß er da ist, denn es geht voran mit neuen Ideen - nun bin ich sehr neugierig, ob sich herausfinden lässt, ob Bulldozer nicht doch einfach grandios ist, allerdings Fehler in Umsetzung, Fertigung, etc. dazu führten, daß die erste Version einfach im gefühlten Pre-Beta Stadium ausgeliefert wird.
Jetzt kann man natürlich hergehen und alles auf die (Software-)Optimierungen schieben, aber darum soll es nicht gehen, vielmehr erscheint doch logisch, das AMD sich erhofft und ausgerechnet hat, zumindest auf dem gleichen Leistungsniveau wie die alte Archi bei den aktuellen Softwares und Anwendungsgebieten zu bleiben.
Ich habe bereits ein bisschen hier und da gesucht und bisher hört man:
- Die Cachelatenzen sind viel zu hoch im L2 und L3 Link
L2 write langsamer als Phenom und das bei mehr Kernen
- der L2 sollte besser 12-14 haben (statt 27?)
- der L3 der Konkurrenzarchi SB ist dreimal schneller
Warum ist der auf 4 Blöcke aufgeteilte L3 mit so schlechten Latenzen ausgestattet
- es gibt möglicherweise Probleme mit den FPUs - daher das schlechte Abschneiden in Games
- Der vielbesprochene Windows Scheduler Patch
- Nichterreichen des Taktziels von >4GHz Basistakt
Zu hoher Stromhunger bei Standardspannung
- Prefetching Fehler
- Prefetch Anweisungen laden jetzt direkt in den L1D Cache
Prefetch Anweisungen in den Anwendungen verschlechtern oftmals die Performance, da man sich mit dem Hardwareprefetcher in die Quere kommt und zusätzlich den Cache mit evtl doch nicht benötigten Informationen trasht.
- L1D/L1I Verhältnis
- L1I thrashing
- zur Zeit heisser Kandidat: Decoder
Natürlich hat nichts davon bereits Anspruch auf Richtigkeit, da es bisher alles noch nicht bewiesen ist.
Zuletzt bearbeitet:
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Füg noch trashing im L1i-cache hinzu, evtl. fehler beim Prefetching und einige Errata auf der Liste sehen auch so aus als wären sie...suboptimal.
Wenn ein Prozessor schon Profiling betreibt um Code optimal auszuführen, dann sollte er sich nicht "ver-profilen" und am ende das Gegenteil von dem bewirken was eigentlich geplant war.
Auch die FPU, zugegeben mag einer Überarbeitung bedürfen.
Wenn ein Prozessor schon Profiling betreibt um Code optimal auszuführen, dann sollte er sich nicht "ver-profilen" und am ende das Gegenteil von dem bewirken was eigentlich geplant war.
Auch die FPU, zugegeben mag einer Überarbeitung bedürfen.
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Die größten Fragezeichen derzeit für mich:
1. Wieso ist der L1D Cache kleiner als der L1I Cache? Das ergibt für mich überhaupt keinen Sinn. Mal sehen, ob ich dazu noch etwas erfahren kann.
2. Wie kommt man zu dieser blöden Entscheidung den L1 Cache nach virtuellen Adressen zu taggen? Die Probleme mit den prozessabhängigen Adressräumen waren vorhersehbar. Oder hat da die Hardwareabteilung nicht mit den Softwarejungs geredet? Die sind doch extra dafür da...
3. Wieso hat der L3 Cache so eine schlechte Latenz? Der L3 im Bulldozer ist über die Module verteilt und nicht mehr ein großer Block, wie beim K10, wieso schafft man es trotzdem nicht die Zugriffszeiten zu verbessern?
1. Wieso ist der L1D Cache kleiner als der L1I Cache? Das ergibt für mich überhaupt keinen Sinn. Mal sehen, ob ich dazu noch etwas erfahren kann.
2. Wie kommt man zu dieser blöden Entscheidung den L1 Cache nach virtuellen Adressen zu taggen? Die Probleme mit den prozessabhängigen Adressräumen waren vorhersehbar. Oder hat da die Hardwareabteilung nicht mit den Softwarejungs geredet? Die sind doch extra dafür da...
3. Wieso hat der L3 Cache so eine schlechte Latenz? Der L3 im Bulldozer ist über die Module verteilt und nicht mehr ein großer Block, wie beim K10, wieso schafft man es trotzdem nicht die Zugriffszeiten zu verbessern?
Dresdenboy
Redaktion
☆☆☆☆☆☆
@Ge0rgy:
Das IBS-Profiling muss explizit von einer Software genutzt werden. Bei der normalen Ausführung spielt es keine Rolle.
@Lynxeye:
Hier spielen sicher einige Tradeoffs eine Rolle. Dafür hat der L3-Cache laut ICC-Paper eine sehr hohe Bandbreite für viele parallele Zugriffe. Aber die Bandbreite pro Modul ist beschränkt.
Dass BD sein Taktziel nicht erreicht, liegt offenbar nichtmal daran, dass er eine höhere Spannung braucht (siehe P3D-Artikel -> OC mit 1,27V), sondern bei Standardspannung wohl dank Prozessproblemen zuviel Strom schluckt. Das schränkt den Takt dank einer Ziel-TDP ein.
Das IBS-Profiling muss explizit von einer Software genutzt werden. Bei der normalen Ausführung spielt es keine Rolle.
@Lynxeye:
Hier spielen sicher einige Tradeoffs eine Rolle. Dafür hat der L3-Cache laut ICC-Paper eine sehr hohe Bandbreite für viele parallele Zugriffe. Aber die Bandbreite pro Modul ist beschränkt.
Dass BD sein Taktziel nicht erreicht, liegt offenbar nichtmal daran, dass er eine höhere Spannung braucht (siehe P3D-Artikel -> OC mit 1,27V), sondern bei Standardspannung wohl dank Prozessproblemen zuviel Strom schluckt. Das schränkt den Takt dank einer Ziel-TDP ein.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Bzgl Scheduler bleibt auch die Frage offen, ob bzw. wie und weshalb sich einzelne Threads sogar hardware-seitig auf die Füße treten.
Von Georgy und Opteron wurde auch auf den Belang der Stream Writes hingewiesen
(vgl. AMD Family 15h (Bulldozer) Software Optimization Guide, Section 6.5)
http://www.planet3dnow.de/vbulletin/showpost.php?p=4505242&postcount=928
In diesem Blog etwas ausführlicher beleuchtet:
http://abinstein.blogspot.com/2011/04/first-look-at-amd-family-15h-bulldozer.html
Ob die genannten Nachteile nur in Ausnahmefällen greifen, oder sogar zu einem großen Teil für die niedrigen Cache-Durchsätze verantwortlich sind, bleibt weiter Spekulation (?).
Von Georgy und Opteron wurde auch auf den Belang der Stream Writes hingewiesen
(vgl. AMD Family 15h (Bulldozer) Software Optimization Guide, Section 6.5)
http://www.planet3dnow.de/vbulletin/showpost.php?p=4505242&postcount=928
In diesem Blog etwas ausführlicher beleuchtet:
http://abinstein.blogspot.com/2011/04/first-look-at-amd-family-15h-bulldozer.html
Ob die genannten Nachteile nur in Ausnahmefällen greifen, oder sogar zu einem großen Teil für die niedrigen Cache-Durchsätze verantwortlich sind, bleibt weiter Spekulation (?).
Dresdenboy
Redaktion
☆☆☆☆☆☆
Hier kommt vieles zusammen, aber manches ist eine nicht ganz korrekte Interpretation, weil man es von bisherigen Architekturen anders kennt.
Die Cache-Write-Werte sind bei Write-Through-Caches anders. Das sah man zuletzt beim P4EE.
Dann gibt es wohl eine Bandbreitenlimitierung pro Modul von 64b in/out zur Northbridge (inkl. L3). Aber L3 ist ja auch nicht für Bandbreite, sondern für Latenz wichtig.
Erstmal ist Analyse angesagt. Alles andere sind bis jetzt auch nur Hypothesen, was aber mangels Hardware verständlich ist.
Mein "Favorit": Es kommt schon gar nicht schnell genug Code herein. Alles andere wird dann natürlich ausgebremst.
Die Cache-Write-Werte sind bei Write-Through-Caches anders. Das sah man zuletzt beim P4EE.
Dann gibt es wohl eine Bandbreitenlimitierung pro Modul von 64b in/out zur Northbridge (inkl. L3). Aber L3 ist ja auch nicht für Bandbreite, sondern für Latenz wichtig.
Erstmal ist Analyse angesagt. Alles andere sind bis jetzt auch nur Hypothesen, was aber mangels Hardware verständlich ist.
Mein "Favorit": Es kommt schon gar nicht schnell genug Code herein. Alles andere wird dann natürlich ausgebremst.
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Nächster Punkt:
Prefetch Anweisungen laden jetzt direkt in den L1D Cache. Schon Untersuchungen mit Nehalem und K10 zeigen: prefetch Anweisungen in den Anwendungen verschlechtern oftmals die Performance, da man sich mit dem Hardwareprefetcher in die Quere kommt und zusätzlich den Cache mit evtl doch nicht benötigten Informationen trasht.
Das könnte bedeuten, dass mit heutigem Anwendungscode der sehr knapp bemessene L1D Cache des Bulldozers bis zu Kotzgrenze getrasht wird und wichtige Daten oftmals aus dem L2 oder gar L3 Cache nachgeladen werden müssen, was mit den langen Zugriffszeiten dieser Caches bei Bulldozer besonders ärgerlich ist.
Prefetch Anweisungen laden jetzt direkt in den L1D Cache. Schon Untersuchungen mit Nehalem und K10 zeigen: prefetch Anweisungen in den Anwendungen verschlechtern oftmals die Performance, da man sich mit dem Hardwareprefetcher in die Quere kommt und zusätzlich den Cache mit evtl doch nicht benötigten Informationen trasht.
Das könnte bedeuten, dass mit heutigem Anwendungscode der sehr knapp bemessene L1D Cache des Bulldozers bis zu Kotzgrenze getrasht wird und wichtige Daten oftmals aus dem L2 oder gar L3 Cache nachgeladen werden müssen, was mit den langen Zugriffszeiten dieser Caches bei Bulldozer besonders ärgerlich ist.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Interessante Hypothese. Es gab dazu doch auch noch einen Hinweis zu einer Java-JIT, wenn ich richtig liege. Dort wurde empfohlen, das SW-Prefetching auszuschalten, weil es mit HW-Prefetcher allein besser lief.Nächster Punkt:
Prefetch Anweisungen laden jetzt direkt in den L1D Cache. Schon Untersuchungen mit Nehalem und K10 zeigen: prefetch Anweisungen in den Anwendungen verschlechtern oftmals die Performance, da man sich mit dem Hardwareprefetcher in die Quere kommt und zusätzlich den Cache mit evtl doch nicht benötigten Informationen trasht.
Das könnte bedeuten, dass mit heutigem Anwendungscode der sehr knapp bemessene L1D Cache des Bulldozers bis zu Kotzgrenze getrasht wird und wichtige Daten oftmals aus dem L2 oder gar L3 Cache nachgeladen werden müssen, was mit den langen Zugriffszeiten dieser Caches bei Bulldozer besonders ärgerlich ist.
Aber wo genau die Prefetches landen, will ich mir nochmal anschauen.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Wie? - Bei BD sind die Module immernoch mit 64bit an die Northbridge angebunden? OoDann gibt es wohl eine Bandbreitenlimitierung pro Modul von 64b in/out zur Northbridge (inkl. L3). Aber L3 ist ja auch nicht für Bandbreite, sondern für Latenz wichtig.
Ich dachte den Flaschenhals der K10 hätten Sie endlich beseitigt.
Und bei K10 gilt das pro Kern, bei BD aber gleich für 2 Int-Cores


Die NB ist auch nicht wirklich höher getaktet als beim K10, somit ist die Bandbreite pro kern sogar nur halb so groß? WTF?

Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Zu 1:
- Die Cachelatenzen sind viel zu hoch im L2 und L3
- der L2 sollte besser 12-14 haben
- der L3 der Konkurrenzarchi SB ist dreimal schneller
- es gibt möglicherweise Probleme mit den FPUs - daher das schlechte Abschneiden in Games
- Der vielbesprochene Windows Scheduler Patch
- Nichterreichen des Taktziels von >4GHz Basistakt
Absolut normal. Hängt sehr stark von der Cache Größe ab.
AMDs L2 ist so schnell wie Intels L3, beide sind 2MB groß und beide sind gleich schnell.
Intels L2 ist recht klein, 256k, kein Wunder, dass der so schnell ist.
AAber: AMD hats fertig gebracht den Phenom L2 gleich schnell zu machen, obwohl doppelt so groß wie Intel. Viel mir gestern erst in nem Review auf, der Athlon2 L2 war wieder langsamer (10 zu 15 Takte).
Wie dem auch sei es gibt die Aussage von AMD, dass man die 20 Takte gut mit nem großen OoO Puffer und Prefetchern verschleiern könne, das wäre quasi alles Kinderkram.
Fragen die bleiben: Geht das nun schief oder nicht?
Baustelle ist eher der L1 Cache mit dem Write Combining Buffer. Wenns da schon wieder so losgeht, Ist die Frage, ob man dann nicht gleich einen großen 32kB L1D Cache verbaut und sich den WCC dann spart. Im Moment hat der auch schon 4kB. Aber gut - wer weiß wieviel ein WB L1 Cache das Design wieder verlangsamen könnte.
Frage in die Runde: Da muss es doch irgendwo ein Paper zu WT/WB TradeOffs geben ... das muss doch schon mal jemand untersucht haben. Kann mich noch an die 486er erinnern, da kam das WB gerade auf. Da konnte man bei den AMDs zw. WT und WB umschalten. WB gab maximal ~5% SpeedUp wenn ich mich recht erinnere, aber ist laaange her

zu 2:
Eigentlich das Gleiche, bei 2MB ein Ding der Unmöglichkeit. Aber mit jedem Shrink wirds besser, und die 1MB Modelle haben ja schon 18T anstatt 20.
zu 3: Ebenfalls die gleiche Geschichte, der AMD L3 ist nach Intel Lesart eher ein L4. Den seh ich eher als Bonus. Aja, da fällt mir ein, dass es doch die Geschichte geben soll, dass man den L3 komplett nem Modul oder so zuordnet. Da gäbs vielleicht ein paar Spielereien. Da müßte man "seine" Apps untersuchen, und dann je nach App Profil den L3 steuern, so ähnlich wie bei den Grafikkartenprofilen. Das wär mal lustig ^^
Aber keine Ahnung obs wirklich was bringt. Ansonsten verweise ich noch auf die alte Grafik hier:
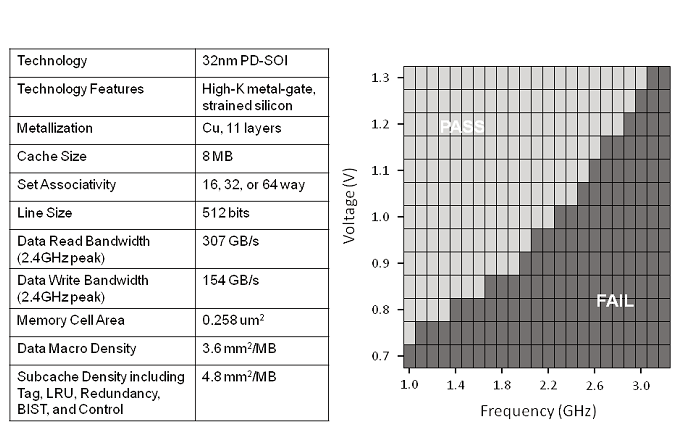
http://www.planet3dnow.de/vbulletin/showthread.php?p=4416527#post4416527
Da sieht man, dass das Plansoll 2,4 Ghz bei 1,0V-1,1V war. Nun hat man nur 2,0-2,2GHz bei 1,18V, deutlicher Hinweis, dass das Herstellungsprozess nicht so läuft wie man den gerne haben will. Die OC Berichte lesen sich mit ~2,6Ghz bei 1,3-1,4V auch eher seehr bescheiden. 3 GHz schaffte keiner.
Apropos: Da kam mir letztens die Idee, dass Llano kein optimaler, bzw. der falsche Vorläufer für den 32nm Prozess für BD war, eben wg. Llanos GPU Parts. Der läuft mit deutlich weniger Takt und braucht andere Prozess - Rahmenbedingungen. Damit gibts gute Aussichten für BD: Optimierungspotential für dessen reines Hochtaktdesign sollte noch reichtlich vorhanden sein. Sieht gut aus für BDv2 in 32nm - wenn mans in den Griff bekomme ^^
zu 4:
Hmm Probleme .. naja sind halt nur 4FPUs. Zwar 2xFMAC, aber wenn man viele FP Ops aus 8 Threads anstehen, wirds wohl doch eng. Das will man natürlich auch, läuft ja unter Effizienzsteigerung, aber tja ... frage mich gerade, ob man ne 3te FMAC Unit reinhängen könnte, auch im Hinblick auf zukünftige Verbreitung von 256b AVX Code. Aber bevor man da sich da den Kopf zerbricht sollte man erst untersuchen, ob es auch wirklich überhaupt daran liegt.
zu5:
Naja Überbewerten würde ich den jetzt auch nicht, aber man könnte das oben erwähnte - hypothetische L3 Cache Zuordnungstool auch noch gleich mit nem Festpinnautomatismus versehen - falls es was bringt - das muss man halt mal bei ein paar Programmen austesten. Im Desktopbereich bedeutet das wohl Hauptsächlich Spiele
")
zu6:Tja, ja läuft unter Prozessoptimierung, siehe oben, da ist noch viel Luft.
Zu 1: Der L1I Cache wird gemeinsam benützt und der L1D Cache ist wohl aus Taktgründen so klein.Die größten Fragezeichen derzeit für mich:
1. Wieso ist der L1D Cache kleiner als der L1I Cache? Das ergibt für mich überhaupt keinen Sinn. Mal sehen, ob ich dazu noch etwas erfahren kann.
2. Wie kommt man zu dieser blöden Entscheidung den L1 Cache nach virtuellen Adressen zu taggen? Die Probleme mit den prozessabhängigen Adressräumen waren vorhersehbar. Oder hat da die Hardwareabteilung nicht mit den Softwarejungs geredet? Die sind doch extra dafür da...
3. Wieso hat der L3 Cache so eine schlechte Latenz? Der L3 im Bulldozer ist über die Module verteilt und nicht mehr ein großer Block, wie beim K10, wieso schafft man es trotzdem nicht die Zugriffszeiten zu verbessern?
zu 2: War doch bei AMD schon immer so, denke ich, wird schon nen Grund dazu geben.
zu 3: Die Meisten Messungen die ich gesehen habe, messen mit AIDA. Man müßte mal Sandra darauf loslassen und den Graph anschauen, der sollte eigentlich wie bei Intel die ersten 2MB - also zw. 2 und 4MB im Graph - schneller anzeigen. Kurz: Wohl nur ne Sache der richtigen Messung.
Ja da war irgendwo was,war das nicht auch im Linux Kernel?Interessante Hypothese. Es gab dazu doch auch noch einen Hinweis zu einer Java-JIT, wenn ich richtig liege. Dort wurde empfohlen, das SW-Prefetching auszuschalten, weil es mit HW-Prefetcher allein besser lief.
Aber wo genau die Prefetches landen, will ich mir nochmal anschauen.
Allerdings ist Software Prefetch schein seit K10 Zeiten relativ gut und wird seitdem immer seltener benutzt, Intel kanns ja noch länger auf dem Niveau.
Das Thema hatten wir auch vor Kurzem im 3DC, hatte die Vermutung, dass der Win7 Scheduler beim Thread - Tanz um die Kerne besonders schlecht für BD wäre, da dann gleich immer 2MB herumgewuchtet werden müssen (wenn man nicht zufällig im anderen Cluster landet). Mal schauen, ob Win8 da Besserung bringt, viel scheints dann aber doch nicht zu bringen - bzw. man müßte es mal mit Festpinnen ausprobieren. Eine Seite hat ja Festgepinnt, um ne 4 Thread CPU zu simulieren und hatte gute Ergebnisse. Frage ist jetzt, obs vielleicht ein Seiteneffekt des Festpinnenes war. Kann man ja einfach überprüfen: Einfach mal 4 Threads auf 2 Module pinnen.
Aber 64bit .. hmmm glaub ich eher nicht, die 2MB L3 Cluster sind mit 2x140bit angebunden:
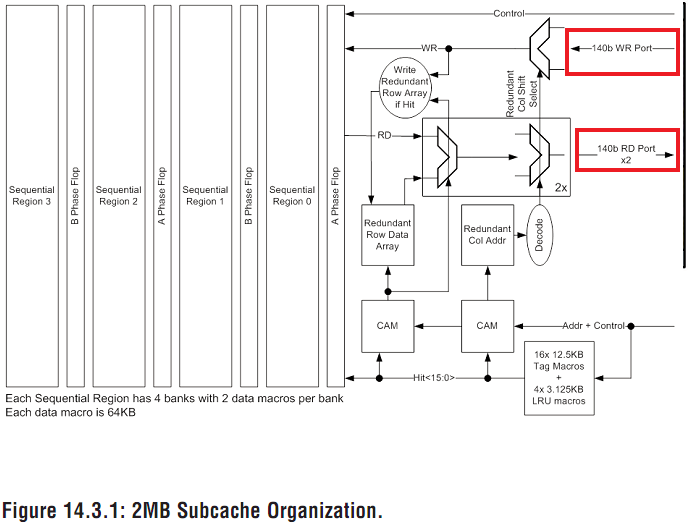
Für was soll das gut sein, wenn die Module nur 64bit hätten?
ciao
Alex
Zuletzt bearbeitet:
rasmus
Admiral Special
- Mitglied seit
- 07.07.2008
- Beiträge
- 1.191
- Renomée
- 47
- Mein Laptop
- Notebook, was ist das?
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 3600
- Mainboard
- MSI B450M PRO-VDH MAX
- Kühlung
- Luft
- Speicher
- 32 GB Gskill Ripjaws
- Grafikprozessor
- Nvidia 3070 ti FE
- Display
- Asus PB278Q 27" 2560*1440
- SSD
- Ja
- HDD
- auch
- Optisches Laufwerk
- ja
- Soundkarte
- onboard
- Gehäuse
- irgendwas mit glas
- Netzteil
- thermaltake toughpower pf1 750W
- Maus
- Rat 9
- Betriebssystem
- Win 7 64bit, Win 10 64 bit
- Webbrowser
- Firefox
- Verschiedenes
- http://valid.canardpc.com/show_oc.php?id=628058
Ich versuche das ganz oben nach und nach zu updaten je nach Informationslage, allerdings bin ich absolute kein Designspezi oder Techniker, insofern kann ich nicht beurteilen, ob zb. der L3 vollkommen in Ordnung ist, weil eher ein L4 etc. Ich verlasse mich da auf das was ich finde und Ihr beitragt. Ich finde nur eine Sammlung der Ideen und Vermutungen, was im Argen liegen könnte ganz gut.
Hier ist nochmal ein 4 Core 4 Modul / 4C2M und 8C/8M Test, sprich keine Ressourcenteilung gegenüber Ressourcenteilung.
Hier ist nochmal ein 4 Core 4 Modul / 4C2M und 8C/8M Test, sprich keine Ressourcenteilung gegenüber Ressourcenteilung.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Na das mit den Cache Levels stimmt schon, aber die sind halt unterschiedlich angeordnet.
Wenn Du an ner 10m Stange Striche bei 3,2cm, 25cm und 6m machst, ist das halt was anderes, als bei 1,6cm, 200cm und 8 bzw. max.10m.
Dickster und wichtigster Unterschied ist da eindeutig der Unterschied zw. 25 <> 200. Was da besser <> schlechter ist ... schwierig zu sagen.
.
EDIT :
.
So nach dem Studium bei rwt würde ich sagen, dass es an den Dekodern liegt.
Es gibt 4 für 8 Ausführungseinheiten. Das war bisher ok, da gabs seit dem K7 ja 3 Dekoder für 6 Einheiten (3xINT 3xFP).
Aber der Kasus Knacktus dürfte sein, dass jetzt 2 Threads laufen, nicht nur einer. Sprich bei dickem INT+SSE Code, wie z.B. bei Cinebench verhungern die Exec. Units. Wobei bei Cinebench die gemeinsame FPU eventuelll auch schon überlastet sein könnte - weiß man ja nicht, kranken kanns an vielen Sachen, aber der INtel Compiler sollte es in dem Fall wirklich nicht sein ^^
Preisfrage ist dann allerdings, wie es Sandy schafft mit SMT zuzulegen, dort gibts schließlich auch nur 3+1 Decoder ... Rätsels Lösung und Sandys Retter könnte da der dicke µOp Cache sein. Der sollte bei Cinebench ziemlich gut laufen.
AMD hat sowas ja noch nicht. Und wenn sies einbauen wollen, dann ist die Preisfrage: Wie ?
Je für einen thread, aber was ist dann mit den FPU Ops? Einen für das gesamte Modul? Dann trashen sich die 2 Threads, falls nicht das gleiche Programm darauf läuft. Bin echt gespannt, was sie sich für BDv2 & 3 ausgedacht haben. Ob da nur Kinderkram kommt oder der größere Umbau.
Mal schauen was das RRC Patent nochmal dazu sagt, aber nicht mehr in dieser Nacht .... ^^
Guten Morgen
Alex
P.S:
Mal schauen, ob noch jemand was zum accelerate mode weiß (apropos ... die FMA Werte bei ht4u sind schon seehr gut, wenn man überlegt, dass die FMA Instruktionen doubles sind, also 2 Decoder beschäftigen, eventuell hilft da doch schon das mtune bdver für den "acc. mode" ... aber naja mal abwarte).
Edit:
Hmmm ....ne Erklärung für die schlechte single Thread Leistung ist das allerdings nicht
P.P.S:
Lacher zum Schluß, David Kanter fragt nach P3D, weils Dresdenboy erwähnt hatte:
Wenn Du an ner 10m Stange Striche bei 3,2cm, 25cm und 6m machst, ist das halt was anderes, als bei 1,6cm, 200cm und 8 bzw. max.10m.
Dickster und wichtigster Unterschied ist da eindeutig der Unterschied zw. 25 <> 200. Was da besser <> schlechter ist ... schwierig zu sagen.
.
EDIT :
.
So nach dem Studium bei rwt würde ich sagen, dass es an den Dekodern liegt.
Es gibt 4 für 8 Ausführungseinheiten. Das war bisher ok, da gabs seit dem K7 ja 3 Dekoder für 6 Einheiten (3xINT 3xFP).
Aber der Kasus Knacktus dürfte sein, dass jetzt 2 Threads laufen, nicht nur einer. Sprich bei dickem INT+SSE Code, wie z.B. bei Cinebench verhungern die Exec. Units. Wobei bei Cinebench die gemeinsame FPU eventuelll auch schon überlastet sein könnte - weiß man ja nicht, kranken kanns an vielen Sachen, aber der INtel Compiler sollte es in dem Fall wirklich nicht sein ^^
Preisfrage ist dann allerdings, wie es Sandy schafft mit SMT zuzulegen, dort gibts schließlich auch nur 3+1 Decoder ... Rätsels Lösung und Sandys Retter könnte da der dicke µOp Cache sein. Der sollte bei Cinebench ziemlich gut laufen.
AMD hat sowas ja noch nicht. Und wenn sies einbauen wollen, dann ist die Preisfrage: Wie ?
Je für einen thread, aber was ist dann mit den FPU Ops? Einen für das gesamte Modul? Dann trashen sich die 2 Threads, falls nicht das gleiche Programm darauf läuft. Bin echt gespannt, was sie sich für BDv2 & 3 ausgedacht haben. Ob da nur Kinderkram kommt oder der größere Umbau.
Mal schauen was das RRC Patent nochmal dazu sagt, aber nicht mehr in dieser Nacht .... ^^
Guten Morgen
Alex
P.S:
Mal schauen, ob noch jemand was zum accelerate mode weiß (apropos ... die FMA Werte bei ht4u sind schon seehr gut, wenn man überlegt, dass die FMA Instruktionen doubles sind, also 2 Decoder beschäftigen, eventuell hilft da doch schon das mtune bdver für den "acc. mode" ... aber naja mal abwarte).
Edit:
Hmmm ....ne Erklärung für die schlechte single Thread Leistung ist das allerdings nicht
P.P.S:
Lacher zum Schluß, David Kanter fragt nach P3D, weils Dresdenboy erwähnt hatte:
What is P3Dnow?
David
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
@Opteron:
Auf RWT soll man nicht soviel direktverlinken. Darum habe ich das nur so erwähnt")
Die von dir erwähnte Diskussion vergaß aber, dass bei 4 Dekodern auch bis zu 8 µops rauskommen -> als 4 MacroOps (mops, ALU+AGU oder FPU+AGU). Das reicht dann wieder.
Die Dekoder hatte ich hier u. da (u.a. im Redaktionsthread) erwähnt. Beispiel steht jetzt auf RWT
Aber das will ich noch explizit untersuchen.
@L3:
140b heißt ja soviel wie 128b netto ohne ECC usw. Das kann schon sinnvoll sein, da es auch Transfers unabhängig von den Modulen gibt (prefetched data vom IMC vllt. - muss ich mal schauen) und auch mal 2 Module gleichzeitig anfragen könnten. Das wird sicher nicht direkt durchgerouted, aber irgendwo gibts Buffer, die dazwischenliegen. Diese kann man dann schneller füllen. Also mit 64b meine ich auch 64b in+64b out. Eventuell auch pro Core (WCC-Interface oder L2-Interface-> wäre aber kein NBB-Takt). Aber so sieht's erstmal aus -> 17,6GB/s limit in beide Richtungen. Das sollte sich auch irgendwie verifizieren lassen.
Jedenfalls gibt es da interessante Zahlen:
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=6
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=2
Der neue L3 macht sich schon bemerkbar. Dort - wenn L2 nicht so stört, steht bei 4MB etwa 140GB/s Durchsatz -> 17,5GB/s pro Core (hier nicht Modul).
Und schau mal die von Sandra gemessenen Cache-Latenzen an... *g*
Auf RWT soll man nicht soviel direktverlinken. Darum habe ich das nur so erwähnt
Die von dir erwähnte Diskussion vergaß aber, dass bei 4 Dekodern auch bis zu 8 µops rauskommen -> als 4 MacroOps (mops, ALU+AGU oder FPU+AGU). Das reicht dann wieder.
Die Dekoder hatte ich hier u. da (u.a. im Redaktionsthread) erwähnt. Beispiel steht jetzt auf RWT
Aber das will ich noch explizit untersuchen.
@L3:
140b heißt ja soviel wie 128b netto ohne ECC usw. Das kann schon sinnvoll sein, da es auch Transfers unabhängig von den Modulen gibt (prefetched data vom IMC vllt. - muss ich mal schauen) und auch mal 2 Module gleichzeitig anfragen könnten. Das wird sicher nicht direkt durchgerouted, aber irgendwo gibts Buffer, die dazwischenliegen. Diese kann man dann schneller füllen. Also mit 64b meine ich auch 64b in+64b out. Eventuell auch pro Core (WCC-Interface oder L2-Interface-> wäre aber kein NBB-Takt). Aber so sieht's erstmal aus -> 17,6GB/s limit in beide Richtungen. Das sollte sich auch irgendwie verifizieren lassen.
Jedenfalls gibt es da interessante Zahlen:
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=6
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=2
Der neue L3 macht sich schon bemerkbar. Dort - wenn L2 nicht so stört, steht bei 4MB etwa 140GB/s Durchsatz -> 17,5GB/s pro Core (hier nicht Modul).
Und schau mal die von Sandra gemessenen Cache-Latenzen an... *g*
Zuletzt bearbeitet:
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Nicht böse gemeint, aber um die Durchmischung der verschiedenen BD Threads zu verhindern:
Ich würde in diesem Thread ganz gerne beim Thema der technischen Probleme von Bulldozer bleiben. Können andere Dinge, wie theoretische andere Bulldozer Konfigurationen bitte in einem anderen Thread diskutiert werden?
Ich würde in diesem Thread ganz gerne beim Thema der technischen Probleme von Bulldozer bleiben. Können andere Dinge, wie theoretische andere Bulldozer Konfigurationen bitte in einem anderen Thread diskutiert werden?
Nur am Rande : Koennte damit Windows bzw. der Windows Scheduler gut umgehen?
- Mitglied seit
- 18.11.2008
- Beiträge
- 11.407
- Renomée
- 724
- Standort
- 8685x <><
- Aktuelle Projekte
- Spinhenge; Orbit; Milkyway
- Lieblingsprojekt
- Orbit@home; Milkyway@home
- Meine Systeme
- Tuban, 3,8~ Ghz x6 /Turbo 4,095GHz 2x Radeon HD 5850@5870 CFx. // Rechner 2: 5900x B02 //3= 9850 /4 = Rasp
- BOINC-Statistiken

- Mein Desktopsystem
- 5900xt (bis 5,3Ghz Boost); 3900x (bis 4,66 Boots); Thuban 1090x(bis 4 GHz Turbo)
- Mein Laptop
- P-
- Details zu meinem Desktop
- Prozessor
- siehe oben. alles Lukü mit max Anzahl ausgesuchter sehr starker Lüfter. (Rechner 3 = R 9 3900x
- Mainboard
- Asus MSI b 550 Tomahawk/; M4A79Deluxe für Thuban / MSI b 550 Tomahawk für R 9
- Kühlung
- ausgesklügelte Luftkühlung mit starkem Airflow
- Speicher
- vollbelegung
- Grafikprozessor
- Midrange oc 12GB /& 8 GB / & 3GB
- Display
- 2x 22" |(Benq; LG) und 1x 23,6" Samsung TFTs Eyefinity +2x21" für die anderen Rechner
- SSD
- 3x
- HDD
- (Tower voll!)
- Optisches Laufwerk
- Asus SATA-DVD RW
- Soundkarte
- o.b.
- Gehäuse
- ANTEC Twelfehundred Bequiet u.a.
- Netzteil
- vorhanden überall
- Tastatur
- ja gibt es jes
- Maus
- ja
- Betriebssystem
- Win 7 V 64 / und alternative
- Webbrowser
- Opera &/ IEE64/ &Safari und alternative
- Verschiedenes
- Thuban: |V-CoreCPU =1,23- 1,47V Turbo//norm. VID= 1,45V System läuft mit 4 Upgrades seit 2008 stabil!
Lynxeye hat völlig Recht:
Es ist zwar ein anlehnendes Thema, das auch hier diskutiert werden kann, aber wenn schon zwei Threads zum Thema BD bestehen, vllt. etwas sorgsamer wählen, wo man was reinschreibt.
Die Themen gehen jedoch ineinander über und überschneiden sich, sodass vieles hier und dort (im BD auf Weltreise BD PART II) gepostet werden kann, und wir sehen das auch nicht allzu streng...
Aber es würde der Übersicht schon dienlich sein, wenn wir hier vor dem posten noch mal überlegen, wo es am besten passt. Das dient dann uns allen!
Somit sind ein paar Beiträge in den BD Thread rübergewandert, hoffe auf Verständnis!
Vielen Dank!
Es ist zwar ein anlehnendes Thema, das auch hier diskutiert werden kann, aber wenn schon zwei Threads zum Thema BD bestehen, vllt. etwas sorgsamer wählen, wo man was reinschreibt.
Die Themen gehen jedoch ineinander über und überschneiden sich, sodass vieles hier und dort (im BD auf Weltreise BD PART II) gepostet werden kann, und wir sehen das auch nicht allzu streng...
Aber es würde der Übersicht schon dienlich sein, wenn wir hier vor dem posten noch mal überlegen, wo es am besten passt. Das dient dann uns allen!
Somit sind ein paar Beiträge in den BD Thread rübergewandert, hoffe auf Verständnis!
Vielen Dank!
LehmannSaW
Vice Admiral Special
- Mitglied seit
- 21.09.2007
- Beiträge
- 597
- Renomée
- 36
- Standort
- poloidal cell 5 im 3. grid block
- Mein Laptop
- HP ENVY x360 15 Dark Ash Silver mit Ryzen 5 2500U
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 1800X
- Mainboard
- ASRock X370 Taichi
- Kühlung
- NZXT Kraken X61
- Speicher
- 16GB G.Skill Trident Z DDR4-3200 @ 3200Mhz
- Grafikprozessor
- Sapphire Radeon R9 Nano
- Display
- Acer Predator XR341CK 34-Zoll mit FreeSync
- SSD
- 250GB Samsung SSD 960 EVO M.2 + 256GB Samsung SSD 840 Pro SSD + 525GB Crucial MX300
- HDD
- 4TB Seagate Desktop SSHD
- Optisches Laufwerk
- keines
- Soundkarte
- on-Board
- Gehäuse
- NZXT S340 ELITE weiß
- Netzteil
- be quiet Straight Power 10 CM 800W
- Betriebssystem
- Windows 10 Pro 64
- Webbrowser
- Mozilla Firefox / IE
Ich bin kein Spezialist in Sachen CPU-Design, möchte aber trotzdem nochmal einiges zusammen fassen, woran es liegen könnte
AMD FX 8-Kern: 4x Dekoder füttern ein Modul (2x Integer Kerne)
AMD Phenom 6-Kern: 3x Dekoder füttern ein Kern
...
AMD FX 8-Kern: Ein Integer Kern enthält 2x AGU/ALU
AMD Phenom 6-Kern: Ein Kern enthält 3x AGU/ALU
ein drittel weniger Leistung
AMD FX 8-Kern: L1D Cache 16KB groß, 4-Wege assoziiert, Load-to-use Latenz 4 Zyklen
AMD Phenom 6-Kern: L1D Cache 64KB groß , 2-Wege assoziiert, Load-to-use Latenz 3 Zyklen
kleiner und langsamer
AMD FX 8-Kern: L2 Cache 2MB groß, Latenz ca.20 Zyklen (höher wenn L2 <-> L1-Verkehr)
AMD Phenom 6-Kern: L2 Cache 512KB groß, Latenz ca.12 Zyklen (14, wenn hoher L2 <-> L1-Verkehr)
Shared L2 Cache pro Modul oder Kern 2MB / + 8-10 Latenz Zyklen
AMD FX 8-Kern: L3 Cache 8 MB, Latenz ca.69 Zyklen / ca.17ns mit Turbo (ca.19ns ohne Turbo)
AMD Phenom 6-Kern: L3 Cache 6 MB, Latenz ca.54 Zyklen / ca.15 ns
2 MB mehr L3 Cache / Latenz +15 Zyklen / +2ns
AMD FX 8-Kern: 4x 256Bit Shared FPUs
AMD Phenom 6-Kern: 6x 128Bit FPUs
zwar Flex, dennoch ein drittel weniger
Die Performanz stellt erneut die Grundfrage:
Schaffen zwei Arbeiter mehr als ein Meister und sein Schüler?
Meine Meinung.
Im Falle AMD FX gegen Intel SB hat das erst einmal nicht geklappt.
Der Meister hat die besseren Werkzeuge (Caches / Anbindungen), gute Zulieferer (optimierter Code) und Ahnung wie die Arbeit gemacht wird (hohe IPC), so muss der Schüler nur zu arbeiten um schneller zu sein.
Nun könnte man den beiden Arbeiter bessere Werkzeuge geben, den Zulieferer verbessern und so Ihre Arbeitsweise erhöhen.
Gruß Lehmann
AMD FX 8-Kern: 4x Dekoder füttern ein Modul (2x Integer Kerne)
AMD Phenom 6-Kern: 3x Dekoder füttern ein Kern
...
AMD FX 8-Kern: Ein Integer Kern enthält 2x AGU/ALU
AMD Phenom 6-Kern: Ein Kern enthält 3x AGU/ALU
ein drittel weniger Leistung
AMD FX 8-Kern: L1D Cache 16KB groß, 4-Wege assoziiert, Load-to-use Latenz 4 Zyklen
AMD Phenom 6-Kern: L1D Cache 64KB groß , 2-Wege assoziiert, Load-to-use Latenz 3 Zyklen
kleiner und langsamer
AMD FX 8-Kern: L2 Cache 2MB groß, Latenz ca.20 Zyklen (höher wenn L2 <-> L1-Verkehr)
AMD Phenom 6-Kern: L2 Cache 512KB groß, Latenz ca.12 Zyklen (14, wenn hoher L2 <-> L1-Verkehr)
Shared L2 Cache pro Modul oder Kern 2MB / + 8-10 Latenz Zyklen
AMD FX 8-Kern: L3 Cache 8 MB, Latenz ca.69 Zyklen / ca.17ns mit Turbo (ca.19ns ohne Turbo)
AMD Phenom 6-Kern: L3 Cache 6 MB, Latenz ca.54 Zyklen / ca.15 ns
2 MB mehr L3 Cache / Latenz +15 Zyklen / +2ns
AMD FX 8-Kern: 4x 256Bit Shared FPUs
AMD Phenom 6-Kern: 6x 128Bit FPUs
zwar Flex, dennoch ein drittel weniger
Die Performanz stellt erneut die Grundfrage:
Schaffen zwei Arbeiter mehr als ein Meister und sein Schüler?
Meine Meinung.
Im Falle AMD FX gegen Intel SB hat das erst einmal nicht geklappt.
Der Meister hat die besseren Werkzeuge (Caches / Anbindungen), gute Zulieferer (optimierter Code) und Ahnung wie die Arbeit gemacht wird (hohe IPC), so muss der Schüler nur zu arbeiten um schneller zu sein.
Nun könnte man den beiden Arbeiter bessere Werkzeuge geben, den Zulieferer verbessern und so Ihre Arbeitsweise erhöhen.
Gruß Lehmann
Zuletzt bearbeitet:
rasmus
Admiral Special
- Mitglied seit
- 07.07.2008
- Beiträge
- 1.191
- Renomée
- 47
- Mein Laptop
- Notebook, was ist das?
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 3600
- Mainboard
- MSI B450M PRO-VDH MAX
- Kühlung
- Luft
- Speicher
- 32 GB Gskill Ripjaws
- Grafikprozessor
- Nvidia 3070 ti FE
- Display
- Asus PB278Q 27" 2560*1440
- SSD
- Ja
- HDD
- auch
- Optisches Laufwerk
- ja
- Soundkarte
- onboard
- Gehäuse
- irgendwas mit glas
- Netzteil
- thermaltake toughpower pf1 750W
- Maus
- Rat 9
- Betriebssystem
- Win 7 64bit, Win 10 64 bit
- Webbrowser
- Firefox
- Verschiedenes
- http://valid.canardpc.com/show_oc.php?id=628058
Also, wenn ich das richtig sehe, dann bestätigt Sandra den erheblich langsameren Cache im Gegensatz zum Phenom.
Beim L2 kann ich verstehen, daß die Latenzen höher sind, da 1 Block und größer.
Beim L3 kann ich es nicht verstehen.
@ Lynx Ich stimme Dir da zu bezüglich des Threadinhaltes. So war es gedacht.
Ich möchte dennoch einmal kurz den Gedanken aufgreifen, der verschoben wurde. Allerdings nicht im Sinne von wäre es besser, sondern im Sinne von könnte es daran liegen.
Könnte es sein, daß das Bulldozer Design auf Ebendieses ausgelegt war, nämlich den entsprechenden Teil mit der GPU zu verstärken und das das Fehlen desselben nun zu einer Art Lücke führt?
Leider weiss man ja auch nicht, wie der Komodo auf FMx ausgestaltet werden sollte, von daher kann man darüber kaum spekulieren.
Zumindest wäre es etwas, daß man auch im Hinterkopf haben könnte.
Zurück zum Thema
Die Übersicht von Lehmann zeigt ziemlich deutlich, daß, pragmatisch verglichen, der Zambezi in den benannten Bereichen langsamer und schwächer ausgestattet ist.
Da muss man nun sehen, inwieweit die architektonischen Unterschiede dieses rechtfertigen, bzw. ausgleichen (können).
Beim L2 kann ich verstehen, daß die Latenzen höher sind, da 1 Block und größer.
Beim L3 kann ich es nicht verstehen.
@ Lynx Ich stimme Dir da zu bezüglich des Threadinhaltes. So war es gedacht.
Ich möchte dennoch einmal kurz den Gedanken aufgreifen, der verschoben wurde. Allerdings nicht im Sinne von wäre es besser, sondern im Sinne von könnte es daran liegen.
Könnte es sein, daß das Bulldozer Design auf Ebendieses ausgelegt war, nämlich den entsprechenden Teil mit der GPU zu verstärken und das das Fehlen desselben nun zu einer Art Lücke führt?
Leider weiss man ja auch nicht, wie der Komodo auf FMx ausgestaltet werden sollte, von daher kann man darüber kaum spekulieren.
Zumindest wäre es etwas, daß man auch im Hinterkopf haben könnte.
Zurück zum Thema
Die Übersicht von Lehmann zeigt ziemlich deutlich, daß, pragmatisch verglichen, der Zambezi in den benannten Bereichen langsamer und schwächer ausgestattet ist.
Da muss man nun sehen, inwieweit die architektonischen Unterschiede dieses rechtfertigen, bzw. ausgleichen (können).
Dresdenboy
Redaktion
☆☆☆☆☆☆
@Lehmann:
So eine ähnliche Aufstellung werde ich noch bauen. Derzeit ist mein Fokusthema: Kommen überhaupt genug Befehle zu den Kernen. Klappt das nicht (durch nicht richtig für das Decoding optimierten (!) Code), ist alles andere zweitrangig.
Kein Code -> keine Leistung. Ganz einfach. SuperPi-Code z. B. würde etwa einen Decode-Durchsatz von 1-2 Befehlen pro Takt erreichen. Zur Erinnerung: es sind 4 Dekoder vorhanden (fehlen in deiner Übersicht).
@rasmus:
Weil es kein Extra-Posting ist, ein kurzer Kommentar zu GPU als Ersatz: Das ist in weiter Ferne. Die GPU kann BDver1, BDver2 usw. erstmal nicht als FPU-Ersatz dienen. Das liegt alles zu weit auseinander. Dann dauert die FPU-Schleife mal nicht kurz 100 Zyklen sondern 20000 wegen Overhead.
So eine ähnliche Aufstellung werde ich noch bauen. Derzeit ist mein Fokusthema: Kommen überhaupt genug Befehle zu den Kernen. Klappt das nicht (durch nicht richtig für das Decoding optimierten (!) Code), ist alles andere zweitrangig.
Kein Code -> keine Leistung. Ganz einfach. SuperPi-Code z. B. würde etwa einen Decode-Durchsatz von 1-2 Befehlen pro Takt erreichen. Zur Erinnerung: es sind 4 Dekoder vorhanden (fehlen in deiner Übersicht).
@rasmus:
Weil es kein Extra-Posting ist, ein kurzer Kommentar zu GPU als Ersatz: Das ist in weiter Ferne. Die GPU kann BDver1, BDver2 usw. erstmal nicht als FPU-Ersatz dienen. Das liegt alles zu weit auseinander. Dann dauert die FPU-Schleife mal nicht kurz 100 Zyklen sondern 20000 wegen Overhead.
rasmus
Admiral Special
- Mitglied seit
- 07.07.2008
- Beiträge
- 1.191
- Renomée
- 47
- Mein Laptop
- Notebook, was ist das?
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 3600
- Mainboard
- MSI B450M PRO-VDH MAX
- Kühlung
- Luft
- Speicher
- 32 GB Gskill Ripjaws
- Grafikprozessor
- Nvidia 3070 ti FE
- Display
- Asus PB278Q 27" 2560*1440
- SSD
- Ja
- HDD
- auch
- Optisches Laufwerk
- ja
- Soundkarte
- onboard
- Gehäuse
- irgendwas mit glas
- Netzteil
- thermaltake toughpower pf1 750W
- Maus
- Rat 9
- Betriebssystem
- Win 7 64bit, Win 10 64 bit
- Webbrowser
- Firefox
- Verschiedenes
- http://valid.canardpc.com/show_oc.php?id=628058
Ah okay danke für die Aufklärung bzgl. GPU
Decoder: Wenn ich das richtig verstehe, müsste man dazu dafür sorgen, daß jeweils nur INT oder FP gecheckt wird (soweit das überhaupt möglich ist) und bei INT ggf sogar einen Kern im Modul abschalten um einen weiteren Vergleichspunkt zu haben?
Decoder: Wenn ich das richtig verstehe, müsste man dazu dafür sorgen, daß jeweils nur INT oder FP gecheckt wird (soweit das überhaupt möglich ist) und bei INT ggf sogar einen Kern im Modul abschalten um einen weiteren Vergleichspunkt zu haben?
LehmannSaW
Vice Admiral Special
- Mitglied seit
- 21.09.2007
- Beiträge
- 597
- Renomée
- 36
- Standort
- poloidal cell 5 im 3. grid block
- Mein Laptop
- HP ENVY x360 15 Dark Ash Silver mit Ryzen 5 2500U
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 1800X
- Mainboard
- ASRock X370 Taichi
- Kühlung
- NZXT Kraken X61
- Speicher
- 16GB G.Skill Trident Z DDR4-3200 @ 3200Mhz
- Grafikprozessor
- Sapphire Radeon R9 Nano
- Display
- Acer Predator XR341CK 34-Zoll mit FreeSync
- SSD
- 250GB Samsung SSD 960 EVO M.2 + 256GB Samsung SSD 840 Pro SSD + 525GB Crucial MX300
- HDD
- 4TB Seagate Desktop SSHD
- Optisches Laufwerk
- keines
- Soundkarte
- on-Board
- Gehäuse
- NZXT S340 ELITE weiß
- Netzteil
- be quiet Straight Power 10 CM 800W
- Betriebssystem
- Windows 10 Pro 64
- Webbrowser
- Mozilla Firefox / IE
Kein Code -> keine Leistung. Ganz einfach. SuperPi-Code z. B. würde etwa einen Decode-Durchsatz von 1-2 Befehlen pro Takt erreichen. Zur Erinnerung: es sind 4 Dekoder vorhanden (fehlen in deiner Übersicht).
Stimmt, ich füge das mal noch hinzu. Den Rest übernimmt dann aber der Profi in solchen Dingen, nämlich du
Mente
Grand Admiral Special
- Mitglied seit
- 23.05.2009
- Beiträge
- 3.674
- Renomée
- 136
- Aktuelle Projekte
- constalation astroids yoyo
- Lieblingsprojekt
- yoyo doking
- Meine Systeme
- Ryzen 3950x
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD 5800X3D
- Mainboard
- Asus ROG Crosshair VIII Dark Hero
- Kühlung
- Headkiller IV
- Speicher
- 3800CL14 G.Skill Trident Z silber/rot DIMM Kit 32GB, DDR4-3600, CL15-15-15-35 (F4-3600C15D-16GTZ)
- Grafikprozessor
- AMD Radeon RX 6900 XT Ref. @Alphacool
- Display
- MSI Optix MAG27CQ
- SSD
- SN8502TB,MX5001TB,Vector150 480gb,Vector 180 256gb,Sandisk extreme 240gb,RD400 512gb
- HDD
- n/a
- Optisches Laufwerk
- n/a
- Soundkarte
- Soundblaster X4
- Gehäuse
- Phanteks Enthoo Pro 2 Tempered Glass
- Netzteil
- Seasonic Prime GX-850 850W
- Tastatur
- Logitech G19
- Maus
- Logitech G703
- Betriebssystem
- Win 10 pro
- Webbrowser
- IE 11 Mozilla Opera
- Verschiedenes
- Logitech PRO RENNLENKRAD DD
Hallo LehmannSaW
die größen solltest du aber positiv stellen im L2 und L3, die anbindung ist negativer da langsamer.
Wobei das mal verglichen mit DDR2 zu DDR3 dort war zwar eine Latenz mit 4-4-4-12 (ddr2-800)so bei 46ns wogegen 9-9-9- (DDR31333) oftmals bei 56ns lag hier konnte der DDR3 nur durch die bandbreite gewinnen.Im Fall bulli wurde ja der L2 und L3 aufgebort nur der ist doch nun auch anders Struckturiert von den Anbindungen? Oder sehe ich da was falsch.
lg
die größen solltest du aber positiv stellen im L2 und L3, die anbindung ist negativer da langsamer.
Wobei das mal verglichen mit DDR2 zu DDR3 dort war zwar eine Latenz mit 4-4-4-12 (ddr2-800)so bei 46ns wogegen 9-9-9- (DDR31333) oftmals bei 56ns lag hier konnte der DDR3 nur durch die bandbreite gewinnen.Im Fall bulli wurde ja der L2 und L3 aufgebort nur der ist doch nun auch anders Struckturiert von den Anbindungen? Oder sehe ich da was falsch.
lg
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ah stimmt, da gehts ja jetzt schon rund ... *sorry*@Opteron:
Auf RWT soll man nicht soviel direktverlinken. Darum habe ich das nur so erwähnt
Ne, da ändert sich nix dran, denn deshalb wurden die AGUs wurden bei den Exec. Units nicht mitgezählt. Wenn Du das willst, dann stehts beim K10 6µOps <> 9Units bzw. beim Bulldozer 8 µOps gegen 12 Exec Units, in dem Fall wieder das gleiche Verhältnis nur jetzt 2:3. Ok, sollte man vielleicht so diskutieren, stimmt "besser"Die von dir erwähnte Diskussion vergaß aber, dass bei 4 Dekodern auch bis zu 8 µops rauskommen -> als 4 MacroOps (mops, ALU+AGU oder FPU+AGU). Das reicht dann wieder.
Wäre immer noch zu wenig, dann die 140/128b liegen ja auch doppelt bzw. gar dreifach an, steht ja groß im Bild 2x140b read, 1x140bit write. Und das gilt *pro* 2MB Segment. Also insgesamt das Ganze noch mal 4. Ob da ein Thread gleichzeitig darauf zugreifen kann glaub ich allerdings nicht, hab Music gebeten einmal den RMMT mutli Thread Bench durchlaufen zu lassen, damit sollte man dann schon auf die 307GB/s kommen, hoffe ich@L3:
140b heißt ja soviel wie 128b netto ohne ECC usw. Das kann schon sinnvoll sein, da es auch Transfers unabhängig von den Modulen gibt (prefetched data vom IMC vllt. - muss ich mal schauen) und auch mal 2 Module gleichzeitig anfragen könnten. Das wird sicher nicht direkt durchgerouted, aber irgendwo gibts Buffer, die dazwischenliegen. Diese kann man dann schneller füllen. Also mit 64b meine ich auch 64b in+64b out.
Hmm, hört sich dann eher nach RAM Bandbreite als nach Cache Bandbreite an. Aber gut die bisherigen (single thread) Messungen entsprechen eher dem als den 307GB/sEventuell auch pro Core (WCC-Interface oder L2-Interface-> wäre aber kein NBB-Takt). Aber so sieht's erstmal aus -> 17,6GB/s limit in beide Richtungen. Das sollte sich auch irgendwie verifizieren lassen.

Hmm, immerhin mal 140GB/s, also dass muss dann ein multi thread Bench sein, erst recht wenn Du jetzt pro Kern. Aber oben meintest Du noch 2x64b pro Modul, oder? Hat sich das jetzt auf Kern geändert? Für nen Kern kann ich mir das vorstellen.Jedenfalls gibt es da interessante Zahlen:
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=6
http://www.lostcircuits.com/mambo//...ask=view&id=102&Itemid=1&limit=1&limitstart=2
Der neue L3 macht sich schon bemerkbar. Dort - wenn L2 nicht so stört, steht bei 4MB etwa 140GB/s Durchsatz -> 17,5GB/s pro Core (hier nicht Modul).
Für ein Modul würde ich das Gleiche wie für ein L3 Segment veranschlagen, 2x140b read, 1x 140b write.
Bei dem Thema fällt mir auch gerade ein GCC Patch / diskussion wieder ein, da gings um 256b unaligned loads &stores die in 128b aufgesplitten werden sollten, damits besser auf BD läuft.
Für Stores ist das gut, für loads nicht -> loads laufen wohl mit den vollen 256b:
http://gcc.gnu.org/bugzilla/show_bug.cgi?id=49089
Sieht "gut" aus, wobei da blöderweise durch die log Skala der wichtige Part verzerrt wirdUnd schau mal die von Sandra gemessenen Cache-Latenzen an... *g*
Komisch finde ich nur den Knick bei 1MB - hat AMD da streng nur 1 MB pro Thread segmentiert? Zumindest der erste Bench ist doch nicht mth, oder?
Oohh .. die Dekoder ja, da hab ich gestern schon ne Frage in Deinen News-Thread gepostet, und zwar wie sicher das ist, dass diese "4 Decoder" gleich sind?Kein Code -> keine Leistung. Ganz einfach. SuperPi-Code z. B. würde etwa einen Decode-Durchsatz von 1-2 Befehlen pro Takt erreichen. Zur Erinnerung: es sind 4 Dekoder vorhanden (fehlen in deiner Übersicht).
Ich trau AMD nach dem ganzen Schlamassel zu, dass das genau nur wieder die gleichen Decoder wie beim K10 sind, 3fastpath + 1complex = 4
Dazu dann halt höchstens noch Fusion, aber das Kraut macht das sicher auch nicht fett.
Da würde ich mal vorsichtshalber nachhaken ob man mehr Infos aus AMD herausbringen kann.
ciao
Alex
Nightshift
Grand Admiral Special
- Mitglied seit
- 19.08.2002
- Beiträge
- 4.447
- Renomée
- 81
- Standort
- Tief im Weeeeeesss-teheheheeen ;-)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- SIMAP, Docking, POEM
- Lieblingsprojekt
- SIMAP
- Meine Systeme
- Ci7-3770K@3,8 GHz, C2Q 9550@3,4 GHz, AthlonII 620 X4 (+ 2x Ci3-2100, 2x C2D 8400, 9x A4-3420, E-450)
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- Ryzen 7 3700X @stock
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-D15 chromax.black
- Speicher
- 2x 16 GB Corsair Vengeance LPX (schwarz) PC4-25600U (DDR4-3200) CL16-18-18-36 @stock
- Grafikprozessor
- Powercolor RX 5700 Red Dragon @stock
- Display
- Eizo FlexScan EV2750
- SSD
- Corsair MP600 1TB M.2 NVMe | Kingston A2000 NVMe PCIe SSD 1TB | Samsung 850 EVO 500 GB
- Optisches Laufwerk
- LG BH16NS55| NEC AD-7203S
- Soundkarte
- onboard :-P der Hardwaregott habe meine Creative Audgiy 2ZS selig
- Gehäuse
- Nanoxia Deep Silence 5, schallgedämmt
- Netzteil
- be quiet! Straight Power E11 650W
- Tastatur
- Razer Ornata Chroma
- Maus
- Logitech Lift for Business
- Betriebssystem
- Win 10 Pro 64bit
- Webbrowser
- Firefox
- Verschiedenes
- rockstable & silent
- Schau Dir das System auf sysprofile.de an
Wenn ich mir das Verfügbare Material angucke, dann sehe ich das Hauptproblem in Cache-Latenzen und Cache-Bandbreiten sowie dem Snoop-Traffic, der evtl. in der Realität deutlich höher ausfällt als das im Labor geplant war. Besonders die niedrige Bandbreite des L1D als WT-Cache ist auffallend.
Zudem fällt der Snoop-Traffic durch die eh schon suboptimalen Cache-Lantenzen und Bandbreiten zusätzlich ins Gewicht, da ist die Frage ob der WCC dann noch viel drehen kann.
Wobei sich mir da die Frage stellt, ob AMD nicht vielleicht sehr genau die Schwäche des Cache-Designs kannte und deshalb auf die jetzige Lösung gesetzt hat. Komplett non-exclusive hätte zwar seine Vorteile, benötigt aber vll. noch mehr Bandbreite die eben nicht da ist.
Insgesamt glaub ich der AMD-Aussage nicht so ganz, dass sie das alles hinter OoO verstecken können. Die Architektur ist auf Throughput ausgelegt, scheint aber gerade an der Stelle Probleme zu haben!?
Zudem fällt der Snoop-Traffic durch die eh schon suboptimalen Cache-Lantenzen und Bandbreiten zusätzlich ins Gewicht, da ist die Frage ob der WCC dann noch viel drehen kann.
Wobei sich mir da die Frage stellt, ob AMD nicht vielleicht sehr genau die Schwäche des Cache-Designs kannte und deshalb auf die jetzige Lösung gesetzt hat. Komplett non-exclusive hätte zwar seine Vorteile, benötigt aber vll. noch mehr Bandbreite die eben nicht da ist.
Insgesamt glaub ich der AMD-Aussage nicht so ganz, dass sie das alles hinter OoO verstecken können. Die Architektur ist auf Throughput ausgelegt, scheint aber gerade an der Stelle Probleme zu haben!?
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Bei allen Briefings zur Architektur wurde eigentlich die Frage nach den Dekodern aufgeworfen und ob die überhaupt ausreichen würden um beide Threads ausreichend zu versorgen. Damals beharrten die Herren immer darauf, dass es auf jeden Fall reichen würde. Glauben wollte es nie jemand so recht. Da gab es dann auch Fragen, ob die Dekoder mit doppelter Frequenz laufen würden und ähnliches. Chekib Akrout war damals dabei.
Ähnliche Themen
- Antworten
- 9
- Aufrufe
- 5K
- Antworten
- 10
- Aufrufe
- 4K