App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD FX - Top oder Flop? (Teil 1)
- Ersteller Dresdenboy
- Erstellt am
Dresdenboy
Redaktion
☆☆☆☆☆☆
★ Themenstarter ★
Einleitung
Der Zeitpunkt, auf den viele unserer Leser bereits lange warteten, ist nun erreicht: der offizielle Launch von AMDs erstem Prozessor auf Basis der neuen Bulldozer-Architektur (zu unserem Bulldozer Benchmark-Artikel). Diesem voraus gingen viele Gerüchte und Spekulationen. Umso näher dieser inoffiziell mehrmals verschobene Tag rückte, umso mehr häuften sich vorab von Dritten veröffentlichte Benchmarkergebnisse. AMD selbst versüßte uns die Zeit mit vielen Architekturdetails und Hintergrundinformationen, welche u. a. auf den letzten beiden „Hot Chips“-Veranstaltungen und der Konferenz ISSCC 2011 bekanntgegeben wurden. Damit konnte man sich zwar schon mehr vom zu erwartenden realen Prozessor vorstellen, aber weiterhin fehlten wichtige Details, wie z. B. die zukünftigen Taktfrequenzen der Modelle sowie Art und Umfang von neuen Turbo-Core-Modi.Dank der vielen schon aufgetauchten Informationen sind die meisten dieser Fragen nun auch beantwortet, bis auf die wichtigste: Welche Leistung liefert diese neue Serie von Prozessoren? Das soll im Detail untersucht werden. Aufgrund der knappen Vorbereitungszeit bietet es sich jedoch an, diese Erkenntnisse in mehreren Teilen aufzuarbeiten.
Um es vorweg zu nehmen: die neue Mikroarchitektur stellt eine grundlegende Änderung gegenüber AMDs anderen Prozessorkernen („Stars“ wie z. B. im Phenom II X6, „Husky“ im Llano oder „Bobcat“ im Zacate oder Ontario) dar. Die Situation ist der bei der Einführung des P4 von Intel vergleichbar. Hierbei ist aber nicht der mit Pentium 4 häufig verbundene hohe Energiebedarf gemeint, sondern der Grad der Änderung in der Architektur, was erst mit Einsatz entsprechend optimierter Software richtig zur Geltung kam. Damals war der Energieverbrauch v. a. für Desktopsysteme oder Server noch nicht so sehr im Fokus wie heute. Darum wurde auch die Bulldozer-Mikroarchitektur u. a. für eine gute Energieeffizienz ausgelegt, was ein Hauptgrund für das Bulldozer-Modulkonzept – der Zusammenlegung zweier Rechenkerne inkl. FPU zu einem optimierten Dual-Core-Modul – war.
Schaut man etwas in die Vergangenheit, sind die vielen Neuerungen beim Bulldozer gar nicht erst seit der ersten Vorstellung 2009 bekannt. Bereits 2005 gab es Aussagen von AMDs damaligem CTO Fred Weber, welcher über die Richtungen für zukünftige Entwicklungen sprach. Diese Punkte wurden dabei von ihm hervorgehoben:
- Bevorzugung von Thread Level Parallelism (TLP) statt Instruction Level Parallelism (ILP), also höhere Performance durch mehr Threads anstelle von höherer Single-Thread-Leistung
- Kombination von Befehlen (wie bei Intels MicroOp-Fusion, von Weber „Instruction Combining“ genannt)
- Höhere Taktfrequenzen für höhere Single-Thread-Leistung
- Niedrigere Speicherzugriffslatenzen
- Niedrigere Sprungvorhersagelatenz und deutlich bessere Sprungvorhersage
- Geteilte Nutzung von Einheiten wie die FPU durch zwei Kerne zu deren besseren Auslastung und damit erhöhter Energieeffizienz
- Helper-Threads, welche bald benötigte Daten vorab in die Caches laden
Von all diesen Punkten wurde bis auf die Helper-Threads alles so im Bulldozer verwirklicht.
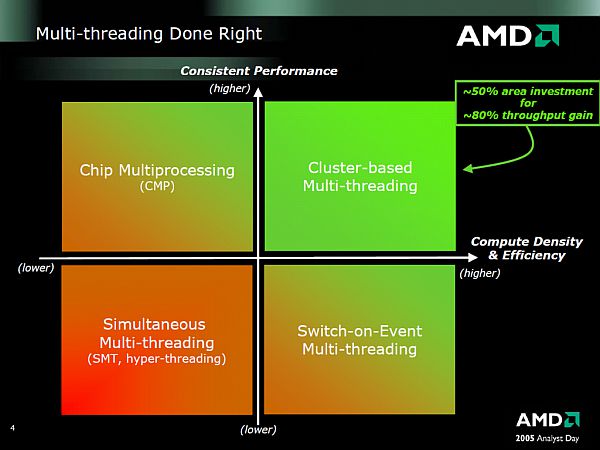
Schließlich gab es ebenfalls 2005 einen Hinweis von AMDs CTO Charles R. Moore, einem weiteren wichtigen Mann hinter der Bulldozer-Architektur. Dieser lieferte schon damals in einer Folie Argumente für ein entsprechendes Architekturkonzept - dem "Cluster-based Multithreading" oder kurz CMT. Demnach sollte für die Ausführung von zwei Threads - passend zu Fred Webers Aussagen - ein Teil der Einheiten eines Prozessorkerns verdoppelt und der Rest gemeinsam von den Threads genutzt werden:
Nach diesen ersten eher vagen Andeutungen tauchten erstmals 2008 in Patenten Architekturbilder auf, welche den grundsätzlichen Aufbau eines Bulldozer-Moduls darstellten:
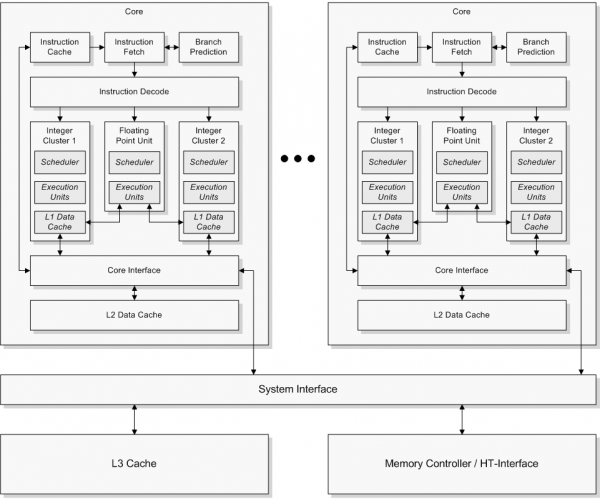
Interessant hierbei ist die Bezeichnung des Moduls als „Core“, während die jetzigen „Integer Cores“ den in den Patenten beschriebenen „Integer Clustern“ entsprechen. Wie man das aber genau nennt, ist eine Frage der Definition. Aber da hat selbst Fred Weber schon 2005 von zwei Kernen gesprochen, die sich eine FPU teilen. Somit ist diese Darstellung auch nicht erst eine Erfindung des Marketings aus den letzten Jahren.
In der folgenden Folie ist zu sehen, wie es heutzutage dargestellt wird:

Ziel des Ganzen war es, die Energieeffizienz zu erhöhen. Da der Entwurf solcher Mikroarchitekturen immer einen Kompromiss darstellt (wie praktisch jede Entwicklung eines massengefertigten Produkts), ist auch die Bulldozer-Architektur ein solcher Kompromiss. Weitere Hintergründe dazu liefert Pollacks „Gesetz“, benannt nach einem Intel-Entwickler. Demnach beeinflussen sich Schaltungskomplexität, Taktfrequenz, Rechenleistung pro Takt, Energieaufnahme und Schaltungsfläche nach bestimmten (Daumen-)Regeln gegenseitig. [1] [2]
Mit etwas Aufwand kann man diese Faktoren aber zu seinen Gunsten beeinflussen. Eine Möglichkeit ist das moderne Energiemanagement in Prozessoren, welche den Idle- und auch den Last-Verbrauch senken können und sogar leistungsfördernde Maßnahmen wie einen Turbo-Modus ermöglichen.
Eine weitere Möglichkeit ist, komplexe Schaltungen (mit höherem Verbrauch) durch eine stärkere Auslastung mit Hilfe mehrerer Threads (häufig zwei) effizienter zu nutzen. Da bei neueren Herstellungsprozessen die Leckströme prozentual schon relativ groß werden können (~20% oder mehr), ist es sogar schon „teuer“, eine Schaltung nur zur 50% zu nutzen und es wird eine höhere Nutzungsquote angestrebt. Das erfolgt dann durch Simultaneous Multithreading (SMT bzw. Hyperthreading bei Intel) oder andere Multithreading-Techniken. Der Mehraufwand dafür hält sich in Grenzen. Beim Pentium 4 sprach Intel von etwa 5% zusätzlicher Chip- bzw. Die-Fläche. Bei Nehalem oder Sandy Bridge dürfte dieser Anteil auf Grund von weiteren Komponenten auf den Dies noch kleiner sein. So eine gemeinsame Nutzung hat aber den Nachteil, dass die Leistung der einzelnen Threads im Vergleich zum Single-Threaded-Betrieb deutlich nachlässt. Wenn z. B. ein Programm auf Sandy Bridge mit Hyperthreading 20% mehr Leistung erreicht, bedeutet das auch, dass jeder Thread nur mit 60% der Single-Thread-Leistung läuft.
Genau dieses Konzept der gemeinsamen Nutzung von komplexen Einheiten hat nun auch AMD für sich entdeckt und setzt es im Bulldozer und den darauf folgenden Architekturgenerationen um. Allerdings ist das Konzept scheinbar der auserkorene Gewinner nach mehreren Entwicklungsanläufen (wenn man viele Patente nach den K7-Entwürfen betrachtet) und verschiedenen Einflüssen (z. B. Mikroarchitekturguru Andy Glew). Die Herangehensweise ist allerdings eine andere als bei Intel. Man begann nicht mit einem großen, leistungsfähigen Core, um festzustellen, dass noch ein zweiter Thread darauf passt. Sondern man wollte von vornherein zwei Kerne nehmen und die komplexen Einheiten gemeinsam nutzen, wo es sinnvoll war. Das ermöglichte dann natürlich auch, diese Einheiten noch etwas leistungsfähiger zu gestalten, da die „Kosten“ in Form höheren Verbrauchs oder Die-Fläche geteilt werden. Folgende Einheiten wurden für eine geteilte Nutzung bestimmt:
- Instruction Fetch, Instruction Prefetch, Instruction Cache
- Sprungvorhersage
- Decoding/Dispatch
- Floating Point Unit mit Scheduler und Ausführungseinheiten
- L2-Cache
- Integer Scheduler
- Integer Ausführungseinheiten
- Load/Store-Unit
- L1-Datencache
- Retirement
Da man bei der bisherigen „Family 10h“-Microarchitektur (von Barcelona bis Thuban) einige Flaschenhälse bzw. weniger effiziente Einheiten identifiziert hat, wurden die Integer-Kerne entsprechend überarbeitet. Das führte teilweise zu Einsparungen, aber auch zu Verbesserungen bzw. Optimierungen.
[BREAK=Untersuchung der Befehlsausführung]
Untersuchung der Befehlsausführung
Um zu untersuchen, wie sich die Ausführung von Befehlen zwischen Bulldozer und anderen Architekturen unterscheidet, haben wir die Latenzen und Durchsätze verschiedener Befehle mit Hilfe von AIDA64 gemessen und verglichen. Zum Vergleich wurden noch der Husky-Core im Llano (welcher selbst schon Verbesserungen gegenüber den Stars-Cores mitbringt), der Sandy-Bridge-Core sowie der Bobcat-Core herangezogen.Dabei sagt die Befehlslatenz aus, nach wieviel Taktzyklen ein folgender Befehl mit dem Ergebnis des betrachteten Befehls weiterarbeiten kann. Das spielt dann eine Rolle, wenn die Out-of-Order-Ausführung des Prozessors und der Compiler nicht in der Lage sind, diese Latenzen durch geeignete Anordnung der Befehle zu "verstecken". Die Auswirkung auf die durchschnittliche Rechenleistung ist nicht so groß wie beim Durchsatz. Dieser beziffert, wie viele dieser Befehle pro Takt maximal gleichzeitig ausgeführt werden können und stellt das obere Limit dessen dar, was Out-of-Order-Ausführung und der Compiler beim Zusammenstellen des Programmcodes ausnutzen können.
Im ersten der folgenden zwei Diagramme sind die durchschnittlichen Befehlslatenzen für verschiedene Befehlsgruppen dargestellt. Man kann dort erkennen, dass v. a. die Latenzen der Integer-Befehle (X86, AMD64) beim Bulldozer sichtbar zugenommen haben (deutlicher bei den 64-Bit-Befehlen). Von den Befehlen wurden zur Vermeidung von Verzerrungen sehr selten bzw. in der Praxis gar nicht genutzte Befehle bzw. -kombinationen herausgenommen. Bei den verschiedenen Befehlssatzerweiterungen ergibt sich ein gemischtes Bild. Bei x87-, SSE- und SSE2-Befehlen gibt es sogar eine Verbesserung zum Husky-Core, während SSE3-, MMX(+) und auch die Integer-Divisions-Befehle vermutlich unter Nutzungshäufigkeits- bzw. Energieeffizienz-Kriterien langsamer und damit sparsamer implementiert wurden. Die Division ist dementsprechend fast genau nur halb so schnell wie im Llano.

Das zweite Diagramm zeigt den durchschnittlichen Durchsatz. Diese können in dieser Form aber auch nur für einen groben Vergleich herhalten, da die Befehle im real auftretenden Befehlsmix mit ganz anderen Häufigkeiten auftreten [3]. Hier wird deutlich, dass selbst Sandy Bridge im Vergleich zu Husky nicht immer besser dasteht. Das liegt daran, dass viele der getesteten Befehle im Husky-Core von allen drei Integer-Einheiten ausgeführt werden können und im Sandy Bridge z. B. nur durch eine oder zwei der vorhandenen Einheiten ausführbar sind. Das verwundert nicht unbedingt, da Sandy Bridge auch auf Energieeffizienz hin optimiert wurde, was auch die Anpassung der vorhandenen Einheiten an die zu erwartenden Anwendungen einschließt.
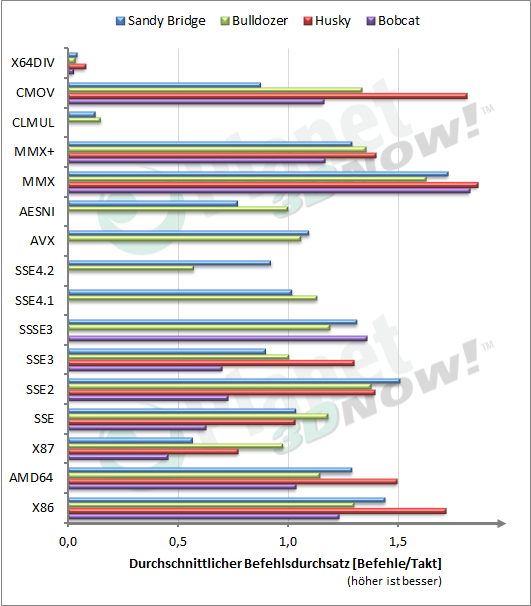
Generell ist erkennbar, dass Bulldozer bei Integer-Befehlen etwa 10% weniger Durchsatz erreicht, als Sandy Bridge. Das Bild ist hier aber durch den nicht eingebrachten Befehlsmix verzerrt, denn wenn man sich die am häufigsten verwendeten Integer-Befehle anschaut, sollte der Vorteil zu Gunsten Sandy Bridges größer ausfallen. Zu bedenken ist auch, dass mit SMT (Hyperthreading) auf Sandy Bridge dieser Durchsatz auf 2 Threads aufgeteilt wird, während Bulldozer für den zweiten Thread einen zweiten Core bereitstellt.
Cache-Latenzen und -Durchsatz wirken sich auch auf diese Werte teilweise aus, da die getesteten Befehle auch Speicherzugriffe enthalten.
Codeoptimierung
Die obige Betrachtung bietet schon eine erste Erklärungsmöglichkeit der beobachteten Leistung des Prozessors. Aber das reicht noch nicht. Wie schon erwähnt, ähnelt der Umfang der Änderungen der Bulldozer-Architektur dem der Netburst-Architektur im Pentium 4. Dementsprechend abhängig ist die erzielbare Rechenleistung von Codeoptimierung für die Architektur. Das bedeutet nicht nur optimale Nutzung vorhandener Befehlserweiterungen (wie AVX oder FMA4), sondern auch die entsprechende Anordnung von Befehlen im compilierten Code für eine optimale Dekodierung und Ausführung. Weiterhin bieten die neue Modul- und die Cache-Architektur weitere „Fettnäpfchen“ für ineffizienten Code. So ähnlich hatte der Pentium 4 zu Beginn mit für Pentium 3 optimiertem Code zu kämpfen, ganz zu schweigen von der anfangs fehlenden Nutzung der SSE2-Erweiterung.Hier heißt es also Abwarten bis entsprechend optimierte Software bereitsteht. Hier kann man AMD keinen Vorwurf machen, da man dort schon länger intensiv an der Verbesserung von Compilern, v. a. den Open-Source-Projekten GCC und Open64, arbeitet. Auch bei kommerziellen Anbietern wird die Unterstützung vermutlich nicht lange auf sich warten lassen.
Eine interessante Möglichkeit, früh mit optimiertem Code arbeiten zu können, bieten Managed-Code-Sprachen, welche auf die Just-In-Time-Übersetzung und auch -Optimierung von Byte-Code-bauen (z. B. Java oder .NET). Hier wäre ein Update der entsprechenden VM ausreichend, um existierende Anwendungen auch effizient auf dem Bulldozer laufen zu lassen.
[BREAK=Vergleichstabelle verschiedener Architekturen]
Vergleichstabelle verschiedener Architekturen
Abschließend für diesen ersten Teil sollen hier verschiedene Microarchitekturen in einer Tabelle gegenübergestellt werden:<table style="TEXT-ALIGN: center" summary="Bulldozer im Vergleich mit anderen Mikroarchitekturen" border="1" cellpadding="3" cellspacing="0"><tbody><tr><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">
</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">K7</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">K8</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">K10</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">Llano</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">Bulldozer-Kern</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">Bulldozer-Modul</th><th style="BACKGROUND: rgb(0,140,88); COLOR: rgb(255,255,255); FONT-WEIGHT: bold">Sandy Bridge</th></tr><tr><td>Decode</td><td>3 MacroOps</td><td>3 MacroOps</td><td>3 MacroOps</td><td>3 MacroOps</td><td>4 mops (+1 mit Branch Fusion)</td><td>4 mops (+1 mit Branch Fusion)</td><td>4 µOps (+1 mit Macro Op-Fusion)</td></tr><tr><td>Issue</td><td>3 MacroOps</td><td>3 MacroOps</td><td>3 MacroOps</td><td>3 MacroOps</td><td>2 ALU + 2 AGU + 4 FP</td><td>2x2 ALU + 2x2 AGU + 4 FP</td><td>4 MacroOps</td></tr><tr><td>ROB</td><td>72</td><td>72</td><td>72</td><td>84</td><td>128</td><td>2x128</td><td>168</td></tr><tr><td>FPU-Width (bit)</td><td>64 (80)</td><td>64 (80)</td><td>128</td><td>128</td><td>128 - 256</td><td>256</td><td>256</td></tr><tr><td>FPU Units</td><td>fadd, fmul, fmisc (64b)</td><td>fadd, fmul, fmisc (64b)</td><td>fadd, fmul, fmisc (128b)</td><td>fadd, fmul, fmisc (128b)</td><td>2x fmac 128b + 2x Integer SIMD 128b</td><td>2x fmac 128b + 2x Integer SIMD 128b</td><td>fadd, fmul, falu (256b)</td></tr><tr><td>L1 Instruction Cache (kB, Ways)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>32 (8)</td></tr><tr><td>L1 Data Cache (kB, Ways)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>64 (2)</td><td>16 (4)</td><td>2 x 16 (4)</td><td>32 (8)</td></tr><tr><td>L1D$ Bandbreite Reads/Writes (bit/cycle)</td><td>2 x 64b reads/writes</td><td>2 x 64b reads/writes</td><td>2 x 128/0 x 64 oder
1 x 128/1 x 64 oder
0 x 128/2 x 64
0 x 128/2 x 64
</td><td>2 x 128/0 x 64 oder
1 x 128/1 x 64 oder
0 x 128/2 x 64?
0 x 128/2 x 64?
</td><td>2 x 128/1 x 128</td><td>4 x 128/2 x 128</td><td>384 kombiniert (wahrscheinlich 384/0 oder 256/128)</td></tr><tr><td>L2 (kB)</td><td>256 - 512</td><td>512 - 1024</td><td>512 - 1024</td><td>1024</td><td>2048 (shared)</td><td>2048 (shared)</td><td>256</td></tr><tr><td>L3 (kB)</td><td>-</td><td>-</td><td>2048 - 6144</td><td>-</td><td>8192</td><td>8192</td><td>8192 (shared)</td></tr><tr><td>Anzahl Threads</td><td>1</td><td>1</td><td>1</td><td>1</td><td>1</td><td>2</td><td>2</td></tr><tr><td>Die area per core (mm²)</td><td>~69 (130 nm)</td><td>22,5 (65 nm)</td><td>15,3 (45 nm)</td><td>9,69 (32 nm)</td><td>-</td><td>18 (32 nm, ohne L2)
30,9 (32 nm, mit 2M L2)
</td><td>18,4 (32 nm, 256kB L2)
Westmere: 17,2 (32 nm, 256kB L2)
Im nächsten Teil soll genauer auf die Besonderheiten der Architektur eingegangen werden.
Quellen:
[1] http://en.wikipedia.org/wiki/Pollack's_Rule
[2] http://citavia.blog.de/2010/09/28/in-depth-sandy-bridge-article-on-rwt-9476659/
[3] http://www.strchr.com/x86_machine_code_statistics
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 21