App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Intel Nehalem
- Ersteller Desti
- Erstellt am
Einiges ist ja bereits zum Nehalem bekannt, zum IDF wird es jetzt konkreter:
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm
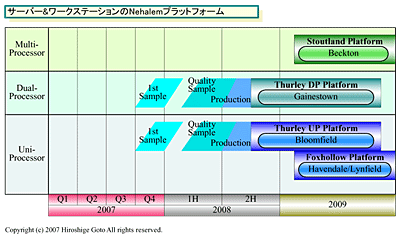
Samples bereits dieses Jahr, Auslieferung in einem Jahr.
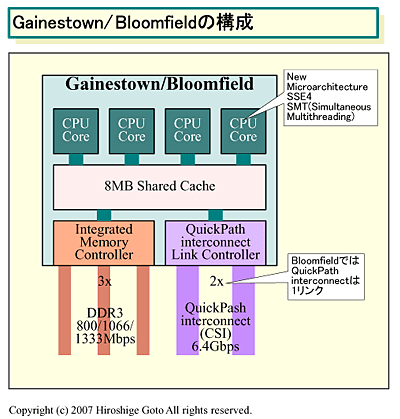
Mit drei Memorychannels wird er 50% mehr Speicherbandbreite als AMDs Shanghai bieten. Als Speicher wird DDR3 und RDDR3 vorgesehen.

Verschiedene Kombinationsmöglichkeiten für 1 und 2 Sockel Server.
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm
Samples bereits dieses Jahr, Auslieferung in einem Jahr.
Mit drei Memorychannels wird er 50% mehr Speicherbandbreite als AMDs Shanghai bieten. Als Speicher wird DDR3 und RDDR3 vorgesehen.
Verschiedene Kombinationsmöglichkeiten für 1 und 2 Sockel Server.
p4z1f1st
Grand Admiral Special
- Mitglied seit
- 28.04.2003
- Beiträge
- 9.722
- Renomée
- 81
- Details zu meinem Desktop
- Prozessor
- AMD FX-6300
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- HEATKILLER® CPU Rev3.0 LC + HEATKILLER® GPU-X² 69x0 LT
- Speicher
- 2x 4096 MB G.Skill RipJawsX DDR3-1600 CL7
- Grafikprozessor
- AMD Radeon RX 480 8GB
- Display
- Dell U2312HM
- HDD
- Crucial m4 SSD 256GB
- Optisches Laufwerk
- Sony Optiarc AD-7260S
- Soundkarte
- Creative Labs SB Audigy 2 ZS
- Gehäuse
- Chieftec Scorpio TA-10B-D (BxHxT: 205x660x470mm)
- Netzteil
- Seasonic X-Series X-660
- Betriebssystem
- Microsoft Windows 10 Professional 64bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- Watercool HTF2 Dual + 2x Papst 4412 F/2GL
Du meinst 50% mehr Speicherbandbreite, die komplett flau daliegen wird, so wie es die Bandbreite der HT-Anbindung von AMD tut?
Ragas
Grand Admiral Special
- Mitglied seit
- 24.05.2005
- Beiträge
- 4.470
- Renomée
- 85
- Details zu meinem Desktop
- Prozessor
- AMD Athlon 64 X2 3800+ @2520MHz; 1,4V; 53°C
- Mainboard
- Asus A8N-E
- Kühlung
- Thermaltake Sonic Tower (doppelt belüftet)
- Speicher
- 4x Infineon DDR400 512MB @207MHz
- Grafikprozessor
- Nvidia GeForce FX 7800GT
- Display
- 1.: 24", Samsung SyncMaster 2443BW, 1920x1200 TFT 2.: 19", Schneider, 1280x1024 CRT
- HDD
- Seagate Sata1 200GB 7200rpm, 2x250GB Seagate SATA2 im Raid0
- Optisches Laufwerk
- DVDBrenner LG GSA 4167
- Soundkarte
- Creative X-Fi Extreme Music
- Gehäuse
- Thermaltake Soprano Silber
- Netzteil
- Be-quiet! Darkpower 470W
- Betriebssystem
- Windows XP; Linux Mandriva 2007.1 (Kernel: 2.6.22.2 Ragas-Edition :D )
- Webbrowser
- Firefox
- Verschiedenes
- -Lüftersteuerung: Aerogate3
Du meinst 50% mehr Speicherbandbreite, die komplett flau daliegen wird, so wie es die Bandbreite der HT-Anbindung von AMD tut?
hm.. vergleichtst du nicht ein bisschen Äpfel mit Birnen?!
Allerdings müssen 50% in der theorie noch nichts heißen, denn eine schlechte Effizienz der controller kann das ganz schnell wieder auffressen. mal sehen, vileicht ist es auch soviel bandbreite, um ein besseres prefetching zu ermöglichen.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hmm also ich würd sagen, dass Intel 33% mehr Bandbreite hat ... ansonsten müsste AMD ja 1,5 Speicherkanäle haben ...Mit drei Memorychannels wird er 50% mehr Speicherbandbreite als AMDs Shanghai bieten. Als Speicher wird DDR3 und RDDR3 vorgesehen.
So oder so, die 4 Kerne mit Intels agressivem Prefetch und v.a. mit SMT (2fach?) werden die Speicherkanäle schon auslasten ... das sieh nicht gut aus für AMD, da muss man als AMD-Fan 2008 wohl wieder auf die nächste CPU Generation (Bulldozer) hoffen. Aber gut, Nehalem komm tja erst in H2/08, also nicht soo dramatisch, falls sich AMD nicht wieder verspätet
")
Edit:
Frage .. wie baut man 4P Systeme auf ? Laut Grafik gibts da nur 2 Links ...
Edit2:
Alles klar .. dafür gibts in der Übersichtsgrafik ganz oben ja die "Beckton" Version, aber die wird anscheinend erst 2009 nachgeschoben.
ciao
Alex
Zuletzt bearbeitet:
NOFX
Grand Admiral Special
- Mitglied seit
- 02.09.2002
- Beiträge
- 4.532
- Renomée
- 287
- Standort
- Brühl
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600 @Stock
- Mainboard
- ASUS B350M-A
- Kühlung
- Boxed-Kühler
- Speicher
- 2x 8 G.Skill RipJaws 4 rot DDR4-2800 DIMM
- Grafikprozessor
- PowerColor Radeon RX 480 Red Dragon 8GB
- Display
- LG 34UM-68 (FreeSync)
- SSD
- PowerColor Radeon RX 480 Red Dragon 8GB
- HDD
- 1x 1,5TB Seagate S-ATA
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- onBoard
- Gehäuse
- Thermaltake Versa H15
- Netzteil
- Cougar SX 460
- Betriebssystem
- Windows 10 Pro x64
- Webbrowser
- Google Chrome
Kein FB-Dimm mehr? Nurnoch DDR3 und Registered DDR3, oder hab ich was falsch verstanden?
@Opteron: Der K10 hätte 33% weniger Bandbreite, der Nehalem hat aber 50% mehr...")
@Opteron: Der K10 hätte 33% weniger Bandbreite, der Nehalem hat aber 50% mehr...
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.032
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
8 Mb Cache halte ich für arg viel. Zwar wird immer behauptet, Intel hätte soviel Fab-Kapazität, daß sie gar nicht wissen, wie sie ihre Diefläche verballern sollen, aber das ist doch Unsinn, niemand baut soviel Cache drauf, wenn es nichts bringt.
Wenn das Teil im Prinzip so ähnlich aufgebaut ist wie die AMDs, sollte der interne Memory-Controller doch für gute Latenzen sorgen, und zusammen mit der wirklich ausreichenden Bandbreite würde das bedeuten, daß ein Mehr an Cache die Performance längst nicht so stark verbessert wie das beim aktuellen Core2 mit FSB ist.
Weiterhin sollte man doch auch davon ausgehen, daß es nicht nötig ist, mit hohem Aufwand noch jedes mögliche Fitzelchen Leistung rauszuquetschen, denn wie wir auch beim Sprung von K7 zu K8 gesehen haben, bringt so ein integrierter Memorycontroller locker mal 20-30% mehr.
Also entweder sind die Latenzen dann trotzdem nicht so gut, wie man denken würde, oder Intel hat Angst vor Bulldozer - aber letzteres halte ich für unwahrscheinlich, denn wie üblich bei AMD wird sich das Teil mindestens ein Jahr verspäten und Intel könnte mit gewohnt überragender Fertigungstechnik sowieso alles abfangen, falls es eng wird.
Übrigens glaube ich wegen der o.g. 20-30% zu erwartender Mehrleistung nicht, daß der eigentliche Kern wesentlich anders ist als beim Core2. Wenn er erstmal "frei atmen" kann, dürfte da noch einiges rauszuholen sein; eine grundsätzlich neue Architektur kann man dann im nächsten Schritt immer noch bringen, statt unnötigerweise zwei Schritte auf einmal zu machen.
Wenn das Teil im Prinzip so ähnlich aufgebaut ist wie die AMDs, sollte der interne Memory-Controller doch für gute Latenzen sorgen, und zusammen mit der wirklich ausreichenden Bandbreite würde das bedeuten, daß ein Mehr an Cache die Performance längst nicht so stark verbessert wie das beim aktuellen Core2 mit FSB ist.
Weiterhin sollte man doch auch davon ausgehen, daß es nicht nötig ist, mit hohem Aufwand noch jedes mögliche Fitzelchen Leistung rauszuquetschen, denn wie wir auch beim Sprung von K7 zu K8 gesehen haben, bringt so ein integrierter Memorycontroller locker mal 20-30% mehr.
Also entweder sind die Latenzen dann trotzdem nicht so gut, wie man denken würde, oder Intel hat Angst vor Bulldozer - aber letzteres halte ich für unwahrscheinlich, denn wie üblich bei AMD wird sich das Teil mindestens ein Jahr verspäten und Intel könnte mit gewohnt überragender Fertigungstechnik sowieso alles abfangen, falls es eng wird.
Übrigens glaube ich wegen der o.g. 20-30% zu erwartender Mehrleistung nicht, daß der eigentliche Kern wesentlich anders ist als beim Core2. Wenn er erstmal "frei atmen" kann, dürfte da noch einiges rauszuholen sein; eine grundsätzlich neue Architektur kann man dann im nächsten Schritt immer noch bringen, statt unnötigerweise zwei Schritte auf einmal zu machen.
G
gast_003
Guest
Der Sprung vom K7 zum K8 war aber ein bischen mehr als nur die Integration des Speichercontrollers.
Rechne dort bei Intel lieber mit schätzungsweise 5% Mehrleistung, denn der grosse L2 Cache fängt ohnehin viele zugriffe ab und frisst somit den Latenzvorteil wieder auf.....was wohl auch der Grund dafür sein wird warum es Versionen ohne nutzbaren Speichercontroller geben wird.
Rechne dort bei Intel lieber mit schätzungsweise 5% Mehrleistung, denn der grosse L2 Cache fängt ohnehin viele zugriffe ab und frisst somit den Latenzvorteil wieder auf.....was wohl auch der Grund dafür sein wird warum es Versionen ohne nutzbaren Speichercontroller geben wird.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Naja .. also ich setze beim Prozentrechnen gerne Maximum = 100%. Also im dem Fall Max = 3 Speicherkontroller = 100%. Setzt man den Opteron als 100%, dann hätte Nehalem 150%, das stimmt, aber Prozente über 100% finde ich nicht wirklich sinnvoll ... naja egal, ich weiss was gemeint ist@Opteron: Der K10 hätte 33% weniger Bandbreite, der Nehalem hat aber 50% mehr...
Wieso viel Cache ? AMD hat da auch nicht weniger bei 45nm. Shanghai hat 4x512 L2 + 6MB L3 = 8 MB gesamt. Intel kann die allemal brauchen, das SMT verlangt neben der dickeren Speicherbandbreite auch mehr Cache. Wobei ich mich dann ernsthaft frage, ob sich die 8 logischen Kerne nicht gegenseitig die Daten aus dem, meiner Meinung nach eher kleinen, 8 MB L2 hauen.8 Mb Cache halte ich für arg viel. Zwar wird immer behauptet, Intel hätte soviel Fab-Kapazität, daß sie gar nicht wissen, wie sie ihre Diefläche verballern sollen, aber das ist doch Unsinn, niemand baut soviel Cache drauf, wenn es nichts bringt.
Vor-/Nachteil von L2 gegen L3:
L2 spart eine Stufe zum RAM ein -> bessere Latenz ohne L3
Ingesamt wird der L2 aber langsamer werden da jeder Core drauf zugreifen muss. AMDs lokaler L2 sollte auf alle Fälle schneller werden. Hätte AMD auch SMT würde ich AMDs Konzept zum Gewinner küren, so aber ... bin ich nur gespannt
ciao
Alex
Zuletzt bearbeitet:
mtb][sledgehammer
Grand Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 4.375
- Renomée
- 30
- Mein Laptop
- HP Compaq nx6125
- Details zu meinem Desktop
- Prozessor
- Athlon XP 2500+
- Mainboard
- Asrock K7S8XE
- Kühlung
- AC / selfmade Wakü
- Speicher
- 1 GB PC3200 Team Memory
- Grafikprozessor
- ATI Radeon 9500
- Display
- 20,1'' Samsung SyncMaster 205BW 1680x1050
- HDD
- Samsung SV0802N
- Optisches Laufwerk
- Toshiba DVD-ROM SD-M1612
- Soundkarte
- Creative SB Live! Player 1024
- Gehäuse
- Chenbro Net Server Tower
- Netzteil
- Coba 400 Watt (silent)
- Betriebssystem
- Windows XP, Ubuntu Linux
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- knc TV Station , Terratec Cinergy 1200 DVB-C
Ich denke mit Nahelem bekommt Intel eben das Problem, was AMD heute mit Barcelona hat: es muss ein einzelner Die sein, welcher außer den 4 Kernen samt Cache noch die Northbridge, und die Speichercontroller beinhaltet. Und da kann Intel eben nicht einfach fröhlich mit MBs prahlen, wie das heute noch im Unverstand möglich ist.Wieso viel Cache ? AMD hat da auch nicht weniger bei 45nm. Shanghai hat 4x512 L2 + 6MB L3 = 8 MB gesamt. Intel kann die allemal brauchen, das SMT verlangt neben der dickeren Speicherbandbreite auch mehr Cache. Wobei ich mich dann ernsthaft frage, ob sich die 8 logischen Kerne nicht gegenseitig die Daten aus dem, meiner Meinung nach eher kleinen, 8 MB L2 hauen.
Bin mal echt gespannt, wie das klappt mit für physikalischen und 8 logischen Kernen, die auf nur einen L2 Cache zugreifen. Insbesondere, falls Intel nicht die L1 Caches vergrößert. Das sind einfach gigantische Bandbreiten, die der L2 Cache liefern muss, um genügend Performance zu bieten.
mocad_tom
Admiral Special
- Mitglied seit
- 17.06.2004
- Beiträge
- 1.234
- Renomée
- 52
Intel muss innerhalb einer Generation lernen, was AMD in den letzten 5 Jahren kontinuierlich aufbauen konnte. Eine Direct-Connect-Architektur, die Integration der Northbridge, die Snoop-Mechanismen so mit den Caches verheiraten, das es nicht stark langsamer wird. Getrennte Stromversorgungen für Speichercontroller&Kerne.
Wie will Intel seine Kerne runtertakten, den Takt des L2-Caches aber oben behalten?
Ein 4-Port-L2-Chache ist deutlich komplexer.
B.t.w. ich dachte es war mal angedacht eine zusätzliche Cache-Hierarchie zu integrieren?
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=2955&p=3
>Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that
>only the highest level of cache would be shared, meaning that Nehalem could
>very well have a similar cache hierarchy to AMD's Barcelona (independent L1/L2
>caches per core, but a shared L3 cache). The power of each core is "dynamically
>managed" which might indicate that Nehalem goes one step further than AMD's
>Barcelona core: it could have independent power planes.
Die Mainboard-Layouter müssen erst ihre Erfahrungen machen usw.
Mit Whitefield ist bei Intel bereits ein CSI+Mem-Controller-Multisockel-Prozessor flöten gegangen.
Ich bin hier sehr misstrauisch, ich bin auch bis heute noch nicht sicher, ob Intel wirklich beide Kerne getrennt voneinander runtertakten kann. Ich verstehe nämlich die neue "Performance-Boost-Technologie" des Penryn nicht so ganz.
Wieso muss ein Core in C3 sein?
http://www.tecchannel.de/pc_mobile/news/467464/
Es müsste doch reichen, wenn einer runtergetaktet ist(800Mhz) und der andere über die spezifizierte Grenze geht. Damit kann ein Core Hintergrund-Jobs bearbeiten, der andere einen einzelnen grossen Thread bearbeiten. Original TDP-Aufteilung: 17,5+17,5W, mit 800MHz wird ein Kern noch 8W verbraten -> 27W+8W -> daraus folgt: es reicht wenn Kern 2
nur runtergetaktet wird.
C3 bedeutet aber, das ein Core taktmässig sehr weit unten ist, auch der Cache muss nach dem Aufwachen zunächst wieder restauriert werden.
Grüße,
Tom
Wie will Intel seine Kerne runtertakten, den Takt des L2-Caches aber oben behalten?
Ein 4-Port-L2-Chache ist deutlich komplexer.
B.t.w. ich dachte es war mal angedacht eine zusätzliche Cache-Hierarchie zu integrieren?
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=2955&p=3
>Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that
>only the highest level of cache would be shared, meaning that Nehalem could
>very well have a similar cache hierarchy to AMD's Barcelona (independent L1/L2
>caches per core, but a shared L3 cache). The power of each core is "dynamically
>managed" which might indicate that Nehalem goes one step further than AMD's
>Barcelona core: it could have independent power planes.
Die Mainboard-Layouter müssen erst ihre Erfahrungen machen usw.
Mit Whitefield ist bei Intel bereits ein CSI+Mem-Controller-Multisockel-Prozessor flöten gegangen.
Ich bin hier sehr misstrauisch, ich bin auch bis heute noch nicht sicher, ob Intel wirklich beide Kerne getrennt voneinander runtertakten kann. Ich verstehe nämlich die neue "Performance-Boost-Technologie" des Penryn nicht so ganz.
Wieso muss ein Core in C3 sein?
http://www.tecchannel.de/pc_mobile/news/467464/
Es müsste doch reichen, wenn einer runtergetaktet ist(800Mhz) und der andere über die spezifizierte Grenze geht. Damit kann ein Core Hintergrund-Jobs bearbeiten, der andere einen einzelnen grossen Thread bearbeiten. Original TDP-Aufteilung: 17,5+17,5W, mit 800MHz wird ein Kern noch 8W verbraten -> 27W+8W -> daraus folgt: es reicht wenn Kern 2
nur runtergetaktet wird.
C3 bedeutet aber, das ein Core taktmässig sehr weit unten ist, auch der Cache muss nach dem Aufwachen zunächst wieder restauriert werden.
Grüße,
Tom
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Auch wieder wahr ... auf den obigen Folien steht nix von L2 oder L3, da ist nur die Rede von "shared" Cache. Das könnte also auch L3 sein, und den L2 könnte der Hiroshige einfach zum jeweiligen CPU-Kern dazugeschlagen haben ... gut aufgepasstB.t.w. ich dachte es war mal angedacht eine zusätzliche Cache-Hierarchie zu integrieren?
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=2955&p=3
>Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that
>only the highest level of cache would be shared, meaning that Nehalem could
>very well have a similar cache hierarchy to AMD's Barcelona (independent L1/L2
>caches per core, but a shared L3 cache). The power of each core is "dynamically
>managed" which might indicate that Nehalem goes one step further than AMD's
>Barcelona core: it could have independent power planes.
ciao
Alex
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wobei sich mir dann irgendwie nicht der Sinn von shared L2 *und* shared L3 erschließen will ..ok klar, ginge, aber schaut irgendwie "unpraktisch" aus. Dagegen spräche das Intel das früher beim P4 auch so gemacht hatte, da gabs ja die P4 XEON mit 4 MB L3, das waren Geräte ..L3 Cache kommt wohl nur bei den großen Multiprozessorversionen.
Naja mal schauen, was noch so an Infos plätschert, während der IDF.
ciao
Alex

G
gast_003
Guest
Ich würde sagen soviel zum shared L2 Cache für alle 4 kerne.
Schaut mir auf dem Foto eher so aus als wenn sich immer 2 Kerne einen L2 Cache teilen...erinnert mich irgendwie an das damalige Pentium D konzept.
Schaut mir auf dem Foto eher so aus als wenn sich immer 2 Kerne einen L2 Cache teilen...erinnert mich irgendwie an das damalige Pentium D konzept.
Ragas
Grand Admiral Special
- Mitglied seit
- 24.05.2005
- Beiträge
- 4.470
- Renomée
- 85
- Details zu meinem Desktop
- Prozessor
- AMD Athlon 64 X2 3800+ @2520MHz; 1,4V; 53°C
- Mainboard
- Asus A8N-E
- Kühlung
- Thermaltake Sonic Tower (doppelt belüftet)
- Speicher
- 4x Infineon DDR400 512MB @207MHz
- Grafikprozessor
- Nvidia GeForce FX 7800GT
- Display
- 1.: 24", Samsung SyncMaster 2443BW, 1920x1200 TFT 2.: 19", Schneider, 1280x1024 CRT
- HDD
- Seagate Sata1 200GB 7200rpm, 2x250GB Seagate SATA2 im Raid0
- Optisches Laufwerk
- DVDBrenner LG GSA 4167
- Soundkarte
- Creative X-Fi Extreme Music
- Gehäuse
- Thermaltake Soprano Silber
- Netzteil
- Be-quiet! Darkpower 470W
- Betriebssystem
- Windows XP; Linux Mandriva 2007.1 (Kernel: 2.6.22.2 Ragas-Edition :D )
- Webbrowser
- Firefox
- Verschiedenes
- -Lüftersteuerung: Aerogate3
Ich würde sagen soviel zum shared L2 Cache für alle 4 kerne.
Schaut mir auf dem Foto eher so aus als wenn sich immer 2 Kerne einen L2 Cache teilen...erinnert mich irgendwie an das damalige Pentium D konzept.
 hmmm wozu packen die dann alle cores wieder auf einen die?! da musses doch irgend ne direkte Verbindung zwischen denen geben.
hmmm wozu packen die dann alle cores wieder auf einen die?! da musses doch irgend ne direkte Verbindung zwischen denen geben.p4z1f1st
Grand Admiral Special
- Mitglied seit
- 28.04.2003
- Beiträge
- 9.722
- Renomée
- 81
- Details zu meinem Desktop
- Prozessor
- AMD FX-6300
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- HEATKILLER® CPU Rev3.0 LC + HEATKILLER® GPU-X² 69x0 LT
- Speicher
- 2x 4096 MB G.Skill RipJawsX DDR3-1600 CL7
- Grafikprozessor
- AMD Radeon RX 480 8GB
- Display
- Dell U2312HM
- HDD
- Crucial m4 SSD 256GB
- Optisches Laufwerk
- Sony Optiarc AD-7260S
- Soundkarte
- Creative Labs SB Audigy 2 ZS
- Gehäuse
- Chieftec Scorpio TA-10B-D (BxHxT: 205x660x470mm)
- Netzteil
- Seasonic X-Series X-660
- Betriebssystem
- Microsoft Windows 10 Professional 64bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- Watercool HTF2 Dual + 2x Papst 4412 F/2GL
Ja, sieht mir auch nach 2x L2 aus...und ein shared L3 erkenne ich nicht
G
gast_003
Guest
Wenn ich den kranz drumherum richtig deute, dann dürfte da Northbridge, Speichercontroller und co sein.....wie bei AMD ebend.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Das wird schon passen, schau Dir mal Suns T2 an ... sind halt nur 2(oder mehr) Bänke.Ich würde sagen soviel zum shared L2 Cache für alle 4 kerne.
Schaut mir auf dem Foto eher so aus als wenn sich immer 2 Kerne einen L2 Cache teilen...erinnert mich irgendwie an das damalige Pentium D konzept.
ciao
Alex
G
gast_003
Guest
Angesichts der Anordnung der Kerne dürfte es ohnehin interessant werden wie diese coordiniert werden, denn mit gleichen Signalwegen dürfte mit der Reihenanordnung ja essig sein.
Hier wäre wohl eine genauer Plan zur Aufteilung der CPU interessant aber vom ersten Bild her tippe ich ebend auf die Crossbar zwischen dem zweiten und dritten Kern, sowie 2 getrennten L2 Caches, die ev. noch über die crossbar miteinander kommunizieren.
letztenendes erinnert das aber dennoch an 2 zusammengebappte und im design angepasste Dualcores...nur nicht ganz so schlimm wie beim Pentium D, wo die Kerne ja über den FSB kommunizierten.
Ich lasse mich aber gerne eines besseren belehren.
Hier wäre wohl eine genauer Plan zur Aufteilung der CPU interessant aber vom ersten Bild her tippe ich ebend auf die Crossbar zwischen dem zweiten und dritten Kern, sowie 2 getrennten L2 Caches, die ev. noch über die crossbar miteinander kommunizieren.
letztenendes erinnert das aber dennoch an 2 zusammengebappte und im design angepasste Dualcores...nur nicht ganz so schlimm wie beim Pentium D, wo die Kerne ja über den FSB kommunizierten.
Ich lasse mich aber gerne eines besseren belehren.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Kollege, wo sollen die L2s denn hin ... irgendwo musst Du die aufs DIE pflanzen ...letztenendes erinnert das aber dennoch an 2 zusammengebappte und im design angepasste Dualcores...nur nicht ganz so schlimm wie beim Pentium D, wo die Kerne ja über den FSB kommunizierten.
Zwischen den beiden Teilen wird der L2 Controller sein, das ist bei AMD und L3 genauso, und da kam bis jetzt auch keiner auf die Idee, dass der L3 in 2x1MB für je 2 Kerne aufgeteilt ist ...
ciao
Alex
G
gast_003
Guest
Gegenüberliegend wäre da eine Möglichkeit aber das würde den Chip dann in die Länge ziehen.
Dann würde der L2 Cache quasi von oben und unten von den Kernen angesprochen aber wohin dann mit der crossbar? Entweder an die Seite oder das Teil kreuzt dann wieder den L2 Cache. Ich vermute allerdings weiterhin das der L2 Cache hier durch die crossbar geteilt wird und diese dann wie beim K10 die Vermittlungsarbeit übernimmt (ich meine mich zu erinnern das beim K10 ein Kern auch auf die Daten des L2 Cache eines anderen Kerns zugreifen kann).....wäre wohl denkbar ungünstig wenn alle 4 Kerne gleichzeitig auf die Daten zugreifen wollen.
Dann würde der L2 Cache quasi von oben und unten von den Kernen angesprochen aber wohin dann mit der crossbar? Entweder an die Seite oder das Teil kreuzt dann wieder den L2 Cache. Ich vermute allerdings weiterhin das der L2 Cache hier durch die crossbar geteilt wird und diese dann wie beim K10 die Vermittlungsarbeit übernimmt (ich meine mich zu erinnern das beim K10 ein Kern auch auf die Daten des L2 Cache eines anderen Kerns zugreifen kann).....wäre wohl denkbar ungünstig wenn alle 4 Kerne gleichzeitig auf die Daten zugreifen wollen.
mocad_tom
Admiral Special
- Mitglied seit
- 17.06.2004
- Beiträge
- 1.234
- Renomée
- 52
Ich schließe mich sompe an, es sind 2x4mb l2 und nicht ein 8mb-4-port-l2
Es sieht stark nach nem dual-opteron ähnlichen aufbau aus.
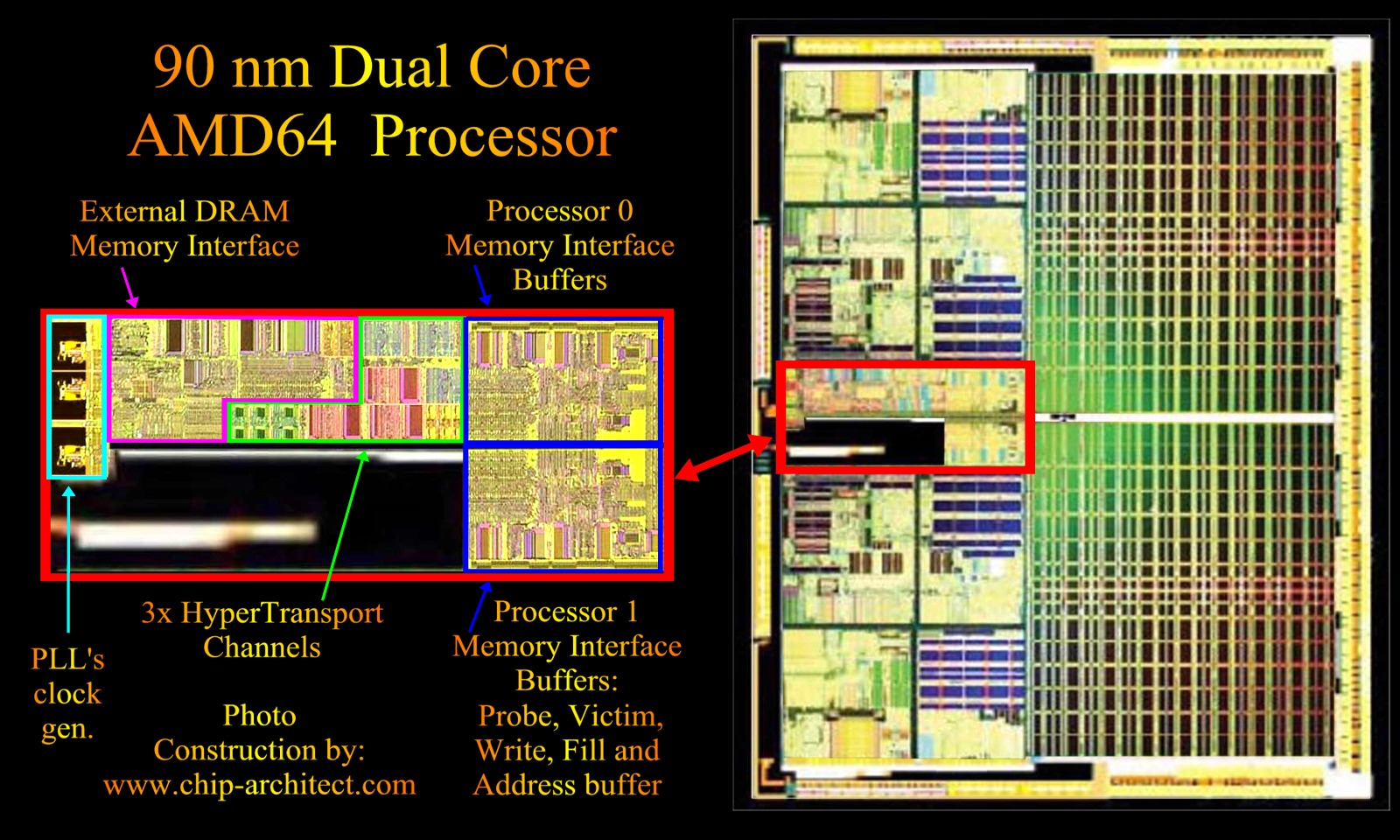
Zwei Core-2-Duo werden mit einer Infrastruktur verbunden, die der Dual-Opteron-Infrastruktur(Crossbar,SRQ) sehr nahe kommt.
Ich habe vor fast 2 Jahren mal einen Die gezeichnet, wie ein 8-Kern-Opteron aussehen könnte:
http://www.planet3dnow.de/vbulletin/showthread.php?p=2482859#post2482859
Offensichtlich hat Intel das Bildchen mal zu sehen bekommen.
Grüße,
Tom
Es sieht stark nach nem dual-opteron ähnlichen aufbau aus.
Zwei Core-2-Duo werden mit einer Infrastruktur verbunden, die der Dual-Opteron-Infrastruktur(Crossbar,SRQ) sehr nahe kommt.
Ich habe vor fast 2 Jahren mal einen Die gezeichnet, wie ein 8-Kern-Opteron aussehen könnte:
http://www.planet3dnow.de/vbulletin/showthread.php?p=2482859#post2482859
Offensichtlich hat Intel das Bildchen mal zu sehen bekommen.
Grüße,
Tom
Ich schließe mich sompe an, es sind 2x4mb l2 und nicht ein 8mb-4-port-l2
Es sieht stark nach nem dual-opteron ähnlichen aufbau aus.
Zwei Core-2-Duo werden mit einer Infrastruktur verbunden, die der Dual-Opteron-Infrastruktur(Crossbar,SRQ) sehr nahe kommt.
Ich habe vor fast 2 Jahren mal einen Die gezeichnet, wie ein 8-Kern-Opteron aussehen könnte:
http://www.planet3dnow.de/vbulletin/showthread.php?p=2482859#post2482859
Offensichtlich hat Intel das Bildchen mal zu sehen bekommen.
Grüße,
Tom
Dann hat der Penryn also auch keinen Shared Cache, sondern 2*3 MiB, sieht schließlich genauso aus.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 78
- Aufrufe
- 14K
- Antworten
- 2
- Aufrufe
- 3K
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 1K