App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Kaveri - der Trinity Nachfolger
- Ersteller FredD
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Weiß jemand zufällig, was es mit Design-Team von Kaveri auf sich hat?
Wird das ein Wurf aus dem AMD Engineering Centre Bangalore?
Noch Fragen?Die Kaveri (Kannada: xxxxxx, Tamil: xxxxx; früher auch anglisiert Cauvery, seltener Kavery) ist ein Fluss im Süden Indiens.
")
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Achso, DU willst 100% sichere Info? Na die gibts doch nie, AMD legt offiziell nicht mal offen, wieviel Entwicklerteams sie wo haben.Konkrete info bitte, soweit vorhanden. Lexikon Auszug hab ich schon in Post 1.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Antwort aus der Diskussion im TrinityThread über Kaveris eventuell abgeschwächten CMT-Ansatz:
Wohl klar, dass das 2 getrennte sein müßten, aber wie gut die dann laufen, wenn sie nur jeden 2ten Takt was von nem gemeinsamen Decoder bekämen ...
Wie der Name schon sagt ist das Ganze "spekulativ", wenn schief läuft war die Ganze Sache für den A****. viel Stromverbrauch für nix, dazu noch der Logikaufwand/Flächenverbrauch. Dann lieber 2 getrennte Threads mit 2er Durchsatz, als einer mit 1,5 und höherem Stromverbrauch. Zumindest aus Serversicht, als Desktopuser würde man sicherlich über den zweiten Fall froh sein, aber das interessiert AMD augenscheinlich ja nicht mehr, siehe BD-Design")
")

Ich verstehe Deine Argumente, aber die bei AMD sind sicherlich nicht blöd, die haben seit Anfang 2011 BDs im Lab und kennen Agners Schwachstellenliste sicherlich etwas länger. Genausogut konnten sie sicherlich auch diverse Optionen durchsimulieren. Ich bin sicher, dass sie nicht die Schlechteste für Steamroller genommen haben ^^
Oder willst Du die 2 Instruktionen LEA & INC/DEC mitzählen ... ? Das läuft bei mir unter Meßfehler.
Ich schrieb nicht umsonst AVX, und nicht AVX+FMA+XOP
Da gehts schon los, wie hättest Du es gerne, einen loop buffer für 2 Kerne oder nur einen loop buffer für beide?Das mit dem loop buffer würde aber auh ohne aufgetrennte decoder gehen und den Druck vom Frontend nehmen.
Wohl klar, dass das 2 getrennte sein müßten, aber wie gut die dann laufen, wenn sie nur jeden 2ten Takt was von nem gemeinsamen Decoder bekämen ...
Tja, solange wir nicht wissen was "ordentlich" ist ...spMT würde den singlethread-Fall ordentlich beschleunigen, was trotz aufgetrennten decodern mit der aktuellen Fassung nicht geht.
Wie der Name schon sagt ist das Ganze "spekulativ", wenn schief läuft war die Ganze Sache für den A****. viel Stromverbrauch für nix, dazu noch der Logikaufwand/Flächenverbrauch. Dann lieber 2 getrennte Threads mit 2er Durchsatz, als einer mit 1,5 und höherem Stromverbrauch. Zumindest aus Serversicht, als Desktopuser würde man sicherlich über den zweiten Fall froh sein, aber das interessiert AMD augenscheinlich ja nicht mehr, siehe BD-Design
Ja, aber SpMT wär dagegen deutlich aufwändiger. Über den Stromverbrauch beschwert sich bei Intel ja auch keiner.Intel mag nah an die 2 rankommen, muss dafür aber auch einigen Aufwand betreiben.
Also wenn Du jetzt speziell von Scouts redest, dann steigt der Durchsatz nicht auf 4. Scouts kundschaften den Code nur aus, und "wärmen" den Cache auf. Rechnen tuen sie nix. Dafür brauchts dann SpMT, das rechnet noch spekulativ, aber wie gut das halt ist, ist die Frage, im Zweifelsfall siehe oben.CMT mit scout-threads würde ermöglichen dass man im Singlethread-Fall immerhin 4 ALUs zur verfügung hat anstatt nur 2 und bei Vollauslastung mit einigen Tricks (wie der loop-buffer z.b.) immerhin 1 dedizierte ALUs pro thread.
Ist doch wurst, Hauptsache schneller ...Das Auftrennen des decoders separiert das Design wieder zu einem herkömmlichen Multicore der sich "nur" die FPU mit seinem bruder teilt.
HMm reden wir jetzt vom Front-End oder über den Decoder, als Teil des Front-Ends. c't hat nur gesagt, dass die Decoder gesplittet werden, vom Rest haben die nichts gesagt. Aus dem Flächenverbrauch, den Du auch richtig einschätzt, hoffe ich, dass die Vorhersagelogik, die den Hauptteil des Front-Ends ausmachen weiterhin gemeinsam benutzt werden kann. Notfalls per DDR, das muss sich doch irgendwie hintrixen lassenWenn ich mir die Dieshots angucke ist die FPU immernoch vergleichssweise klein wenn man das Frontend danebenlegt. Und die getrennte FPU in dem Fall ja eher hinderlich weil man sonst genauso wie Intel verfahren könnte. Also irgendwie nix halbes und nix ganzes.
Das Hauptproblem sind wohl die beiden Threads. Die muss man irgendwie da durchschleußen, AMD hat sich jetzt fürs vertikale MT entschieden, de-facto läuft der Decoder pro Kern also grob-gesehen mit halben Takt. Wenn Du jetzt aufs Doppelte verbreiterst hilft das aber auch nichts, da man pro Thread kaum 8 Decoder auslasten kannMan kann den 2. INT-Kern nicht zur beschleunigung eines einzelnen threads nutzen, genausowenig kann man die Datenleitungen recyceln wie Intel das macht. Man hat also mehr oder weniger den CMT-Vorteil ad acta gelegt... und das wofür? - weil man nicht in der Lage ist einen vernünftigen decoder vorne dranzubauen?
Das Problem sind doch auch die µCode-Befehle. Bisher gibts nur einen µCode-Dec., wenn der arbeitet, ist alles blockiert.Wenn ich mir das so ansehe und mit der Liste von Agner Fog vergleiche... sollten sie doch in Gottes namen erst die anderen Punkte angehen und den Decoder noch etwas verbreitern, abgefedert durch loop cache und fertig. Aber das alles wieder zu separieren was man mühselig zusammengefasst hat... naja...
Ich verstehe Deine Argumente, aber die bei AMD sind sicherlich nicht blöd, die haben seit Anfang 2011 BDs im Lab und kennen Agners Schwachstellenliste sicherlich etwas länger. Genausogut konnten sie sicherlich auch diverse Optionen durchsimulieren. Ich bin sicher, dass sie nicht die Schlechteste für Steamroller genommen haben ^^
Ja, wichtig schon, aber Performance/Watt und Die-Flächenverbrauch ist eben wichtiger. Der Rest sollte laut Plan ja aus dem Takt kommen. Steamroller sollte da eigentlich langsam hinkommen, wo AMD hinwill. Schon mit Piledriver steigt IPC und Takt etwas, dann noch nen schönen Schub bei beidem für Steamroller, dann wär ich zufrieden. Gut, Intel hat dann Haswell, aber wenn sie die Steamroller-FPU auch verbreitern/verbessern (immerhin wissen wir ja schon von der DIV-Einheit), wird das dann doch ne runde Sache. Intel wird weiter besser sein, aber nicht mehr so stark. (hoffentlich ^^).Ja, deswegen ist aber eine hohe pro Kern Leistung immer noch wichtig. Man muss deswegen ja nicht zu Single-Cores zurückkehren, aber doch auf eine möglichst hohe Performance pro Kern bedacht sein.
Siehe oben, was interessiert mich CMT, das ist so wichtig wie die Gehäusefarbe rosa bei nem Notebook. Schön anzuschauen, aber wenn der schwarze Rechner mehr Wumms bei gleichen Kosten & Stromverbrauch hat, ist mir das egal.Und dafür müssen 2 getrennte Decoder her? Sehe ich nicht so. Ein breiterer oder flexiblerer Decoder erhöht doch den Durchsatz genauso. Ich kann Ge0rgy nur zustimmen, getrennte Decoder führen das CMT Design nur ad.absurdum. Ich würde es viel lieber sehen, dass man aus den beiden Integer Clustern einen macht.
Und dir ist anscheinend entgangen, dass ich von INT-Cores redeteMehr als 2 geht nicht? Dir ist aber schon klar, dass das theoretische Maximum bei 4 liegt?
Oder willst Du die 2 Instruktionen LEA & INC/DEC mitzählen ... ? Das läuft bei mir unter Meßfehler.Ich schrieb:Das ist nicht ganz korrekt.
Und das ist korrekt, und zwar ganzAktuell bekommt AMD nur eine 256b AVX Instruktion pro Takt durch die FPU, da steht Intel besser da.
Ich schrieb nicht umsonst AVX, und nicht AVX+FMA+XOP
4 256bit Operationen? Also auch mit FMA und XOP geht das nicht, wir redeten doch gerade nur von der FPU, oder? Da kriegst Du keine 4 durch. Mit FMA bekommst Du zwei durch die beiden 128b FMACs, nicht vier, und die IMACs sind nur 128bittig. Wenn Du die noch dazurechnen willst (ist ja eh irgendwie komisch INT Units in der FPU), dann kommen wir max. auf 2x256 plus 2x128.Erstmal sind Instruktionen eher nebensächlich, entscheidend sind die Rechenoperationen, die in der Instruktion verpackt sind. Intel kann momentan maximal 2 256-bit Rechenoperationen pro Takt, Bulldozer hingegen 4 256-bit Rechenoperationen, also doppelt so viele.
Ich finds praktisch, 256b for free. Das kostet keine extra Leitungen und die INT-Pfade würden durch die Port-Begrenzung eh brach liegen. Einziger Nachteil ist der Strafzuschlag beim Moduswechsel SSE <> AVX. Das kostet bei Intel, bei AMD ists umsonst. Damit kommt die AMD Lösung faulen Programmierern näher. Die können einfach mal schnell ein paar brauchbare AVX/FMA-Befehle in den alten SSE-Code mischen, und sich übers Speedup freuen.Allerdings ist für Bulldozer FMA notwendig. Zudem teilen sich hier die Rechenoperationen in jeweils 2 Integer und FP. Integer wird mWn momentan auch nur durch XOP unterstützt. Bei Intel geht das halt nicht, da deren Rechenwerke nur 128-bittig sind, und für 256-bit FP Rechenoperationen die Integer Rechenwerke "missbraucht" werden. Nicht besonders elegant, aber besser als nichts als Übergangslösung.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Hat er aber nicht. CMT verbessert ja Flächen- und Energieeffizienz. Bei gleichen Kosten und gleicher Leistungsaufnahme kann der "schwarze Rechner" also nicht mehr Wumms haben.Siehe oben, was interessiert mich CMT, das ist so wichtig wie die Gehäusefarbe rosa bei nem Notebook. Schön anzuschauen, aber wenn der schwarze Rechner mehr Wumms bei gleichen Kosten & Stromverbrauch hat, ist mir das egal.
Das ist erstmal nebensächlich. Die theoretisch maximale IPC liegt trotzdem bei 4.Und dir ist anscheinend entgangen, dass ich von INT-Cores redete
Na offensichtlich nicht, siehe nachfolgend.Und das ist korrekt, und zwar ganz
Ok, sind vermutlich doch nur 3. Ich zitiere mal den SOG:4 256bit Operationen? Also auch mit FMA und XOP geht das nicht
Ich bin davon ausgegangen, dass jeweils ein IMAC an den Integer Ports hängt. Ist aber doch nur an Port 0 einer. Wie auch immer, es sind 2x 128-bit FMA + 2x 128-bit SIMD. Macht also insgesamt bis zu 3 256-bit Operationen. Rein von den Kapazitäten steht AMD also erstmal besser da, und nicht wie von dir behauptet Intel.There are four logical pipes: two FMAC and two packed integer. For example, two 128-bit
FMAC and two 128-bit integer ALU ops can be issued and executed per cycle.
Also ich finde es nicht praktisch. Für mich ist es nur eine Notlösung. Damit baust du dir nur unnötig Wartezyklen an Ports ein, die ansonsten anderweitig genutzt werden könnten. Was anderes war aber vermutlich auf die Schnelle nicht machbar, um SB AVX zu spendieren. Wenn es so toll sein soll, dann frage dich doch mal, warum man das nicht schon mit SSE gemacht hat. Also die FPU auf 64-bit belassen und die anderen 64-bit von den Integer Rechenwerken abzweigen. Ich rechne damit, dass mit Haswell diese Notlösung wieder rausfliegt und dieser eine "echte" 256-bit FPU mitbringt.Ich finds praktisch, 256b for free. Das kostet keine extra Leitungen und die INT-Pfade würden durch die Port-Begrenzung eh brach liegen. Einziger Nachteil ist der Strafzuschlag beim Moduswechsel SSE <> AVX. Das kostet bei Intel, bei AMD ists umsonst. Damit kommt die AMD Lösung faulen Programmierern näher. Die können einfach mal schnell ein paar brauchbare AVX/FMA-Befehle in den alten SSE-Code mischen, und sich übers Speedup freuen.
Duplex
Admiral Special
Im Vergleich zu Deneb gibt es keine x86 pro Takt mehr Leistung oder Effizienz Verbesserungen. / 45 > 32nm Vorteil.Hat er aber nicht. CMT verbessert ja Flächen- und Energieeffizienz. Bei gleichen Kosten und gleicher Leistungsaufnahme kann der "schwarze Rechner" also nicht mehr Wumms haben.
AMDs größte Probleme bei Bulldozer sind aktuell
- Nur 1 FPU für 2 Threads
- Nur 1 Decoder für 2 Threads
- 16KB L1D Cache
- Allgemein langsame Cache Latenzen durch das Wright Trough Cache Design
Steamroller braucht
- 1 FPU pro Thread
- 1 Decoder pro Thread
- 32KB L1D Cache
- Schnellere Cache Latenzen
@gruffi
2x Cluster aus dem CMT Konzept > 1x Breites Cluster erstellen macht das Design aber deutlich breiter, ich glaube sowas ähnliches hat man bei einem stonierten K9 mal geplant, den Core Bereich vom K8 massiv breiter gestallten.
Zuletzt bearbeitet:
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
@Opteron
Es geht mir nicht um CMT als solches, der Punkt ist aber, wenn sich die decoder so mal eben auftrennen lassen und die Schwachstellen die Agner Fog in seinem Dokument angibt schon länger bekannt sind & simuliert, warum hat man BD dann überhaupt so gebracht und das mit den aufgrtrennten decodern nicht von Hause aus eingebaut.
Das Problem mit der Bandbreite existiert auch nur wenn beide threads vollast anliegen haben, BD schafft aber IPC von 2 nichtmal im Singlethread.Fall. Daher ist das Decoderproblem nur sekundär.
Dazu kommt, dass es im Programmablauf recht häufig schleifen gibt. Aktuell müssen die instruktionen in jedem schleifendurchlauf wieder und wieder durch die "langsamen" decoder. Ein Loop cache, wie der name schon sagt, verschafft dem Frontend hier luft, weil die schleife aus dem cache laufen kann und die decoder inzwischen schonmal weiterdecodieren können.
Daher würde ich eine verbreiterung und verbesserung des µCode-Verhaltens in Verbindung mit loop cache für besser halten.
Wenn man die CMT Vorteile ohnehin ad acta legt, hätte man sich den Aufwand ersparen können und gleich weder normale multicores bauen.
Aber wer bin ich schon...
Die von AMD werden sicher wissen was sie tun...
Intel sagt nicht umsonst, die Cachepipeline ist ebenso wichtig wie die Rechenpipeline selbst.
bezüglich der scout threads... nunja... in Zeiten wo die Sprungvorhersagen über 90% trefferquoten liefern können, würde ich mal fast denken sollte es auch möglich sein die wahrscheinlichkeit dass spMT richtig liegt halbwegs hoch zu bekommen...
.
EDIT :
.
Bei Write through und Decodern sag ich nichts, aber der rest ist quatsch.
mehr als 16Kb L1D$ hat ein Sandybridge pro thread auch nicht wenn SMT zum Einsatz kommt.
Die FPU schlägt sich bestenfalls in Benchmarks nieder, im realen Leben ist der Anteil an FPU-Code, der dazu auch noch vollast verursacht vergleichsweise gering.
Und wir dürfen nicht vergessen, BD hat insgesamt 4 ALUs, Deneb nur 3.
Es stehen also absolut gesehen mehr ressourcen zur Verfügung, nur kann man die a) nicht alle für 1 Thread nutzen und b) bestehen durch das cachedesign und alle anderen von Agner Fog beschrieben Probleme (z.b. das mit den Zugriffen auf die Cachelines) noch genug Schlaglöcher.
Wenn AMD es schaffen würde die Int-Cores im Mittel so gut auszulasten dass sie ansatzweise eine IPC von 2 erreichen, dann würde ich sagen können AMD muss das Design verbreitern um sich weiter zu verbessern, aber wenn man nichtmal 2-fach OoO ausgelastet kriegt, hat man ganz andere Probleme...
.
EDIT :
.
Das wäre auch eine Rückkehr zum klassischen Kern, und eine Absage an die Clusterstruktur als Solche.
Aber K8 hatte seine Probleme nicht bei der Breite des inneren Kerns... sondern ironischerweise ebenfalls beim Frontend.![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]")
Es geht mir nicht um CMT als solches, der Punkt ist aber, wenn sich die decoder so mal eben auftrennen lassen und die Schwachstellen die Agner Fog in seinem Dokument angibt schon länger bekannt sind & simuliert, warum hat man BD dann überhaupt so gebracht und das mit den aufgrtrennten decodern nicht von Hause aus eingebaut.
Das Problem mit der Bandbreite existiert auch nur wenn beide threads vollast anliegen haben, BD schafft aber IPC von 2 nichtmal im Singlethread.Fall. Daher ist das Decoderproblem nur sekundär.
Dazu kommt, dass es im Programmablauf recht häufig schleifen gibt. Aktuell müssen die instruktionen in jedem schleifendurchlauf wieder und wieder durch die "langsamen" decoder. Ein Loop cache, wie der name schon sagt, verschafft dem Frontend hier luft, weil die schleife aus dem cache laufen kann und die decoder inzwischen schonmal weiterdecodieren können.
Daher würde ich eine verbreiterung und verbesserung des µCode-Verhaltens in Verbindung mit loop cache für besser halten.
Wenn man die CMT Vorteile ohnehin ad acta legt, hätte man sich den Aufwand ersparen können und gleich weder normale multicores bauen.
Aber wer bin ich schon...
Die von AMD werden sicher wissen was sie tun...
Intel sagt nicht umsonst, die Cachepipeline ist ebenso wichtig wie die Rechenpipeline selbst.
bezüglich der scout threads... nunja... in Zeiten wo die Sprungvorhersagen über 90% trefferquoten liefern können, würde ich mal fast denken sollte es auch möglich sein die wahrscheinlichkeit dass spMT richtig liegt halbwegs hoch zu bekommen...
.
EDIT :
.
Im Vergleich zu Deneb gibt es keine x86 pro Takt mehr Leistung oder Effizienz Verbesserungen. / 45 > 32nm Vorteil.
AMDs größte Probleme bei Bulldozer sind aktuell
- Nur 1 FPU für 2 Threads
- Nur 1 Decoder für 2 Threads
- 16KB L1D Cache
- Allgemein langsame Cache Latenzen durch das Wright Trough Cache Design
Bei Write through und Decodern sag ich nichts, aber der rest ist quatsch.
mehr als 16Kb L1D$ hat ein Sandybridge pro thread auch nicht wenn SMT zum Einsatz kommt.
Die FPU schlägt sich bestenfalls in Benchmarks nieder, im realen Leben ist der Anteil an FPU-Code, der dazu auch noch vollast verursacht vergleichsweise gering.
Und wir dürfen nicht vergessen, BD hat insgesamt 4 ALUs, Deneb nur 3.
Es stehen also absolut gesehen mehr ressourcen zur Verfügung, nur kann man die a) nicht alle für 1 Thread nutzen und b) bestehen durch das cachedesign und alle anderen von Agner Fog beschrieben Probleme (z.b. das mit den Zugriffen auf die Cachelines) noch genug Schlaglöcher.
Wenn AMD es schaffen würde die Int-Cores im Mittel so gut auszulasten dass sie ansatzweise eine IPC von 2 erreichen, dann würde ich sagen können AMD muss das Design verbreitern um sich weiter zu verbessern, aber wenn man nichtmal 2-fach OoO ausgelastet kriegt, hat man ganz andere Probleme...
.
EDIT :
.
Im Vergleich zu Deneb gibt es keine x86 pro Takt mehr Leistung oder Effizienz Verbesserungen. / 45 > 32nm Vorteil.
AMDs größte Probleme bei Bulldozer sind aktuell
- Nur 1 FPU für 2 Threads
- Nur 1 Decoder für 2 Threads
- 16KB L1D Cache
- Allgemein langsame Cache Latenzen durch das Wright Trough Cache Design
Steamroller braucht
- 1 FPU pro Thread
- 1 Decoder pro Thread
- 32KB L1D Cache
- Schnellere Cache Latenzen
@gruffi
2x Cluster aus dem CMT Konzept > 1x Breites Cluster erstellen macht das Design aber deutlich breiter, ich glaube sowas ähnliches hat man bei einem stonierten K9 mal geplant, den Core Bereich vom K8 massiv breiter gestallten.
Das wäre auch eine Rückkehr zum klassischen Kern, und eine Absage an die Clusterstruktur als Solche.
Aber K8 hatte seine Probleme nicht bei der Breite des inneren Kerns... sondern ironischerweise ebenfalls beim Frontend.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Ich habe auch nicht von Deneb gesprochen. Es ging erstmal nur um Bulldozer. Beide Kerne 1:1 zu vergleichen, ist nicht so ohne weiteres möglich. Eine Bulldozer CU ist einen Tick kleiner als zwei Husky Kerne. Und mit dem Taktvorteil der Pipeline kann Bulldozer die schlechtere Skalierung von CMT gegenüber CMP gut ausgleichen. Also selbst so gesehen hat Bulldozer keinen Nachteil. Darüber hinaus besitzt er viele Erweiterungen, die Husky nicht besitzt, wie FMA, AVX, XOP, AES, SSSE3, SSE4, etc. Und Bulldozer steht gerade mal am Anfang der Entwicklung, während Husky, ausgehend vom K7, eine über 10 Jahre lange Entwicklung hinter sich hat. Das sollte das Potenzial des CMT Designs schon recht gut verdeutlichen.Im Vergleich zu Deneb gibt es keine x86 pro Takt mehr Leistung oder Effizienz Verbesserungen. / 45 > 32nm Vorteil.
Denke ich nicht. Das würde ja bedeuten, dass 2 Threads auf einer CU zu langsam wären. Sind sie aber nicht. Die Skalierung mit 70-80% liegt völlig im Rahmen des angekündigten. Ich denke, wir sind uns einig, dass ein Thread zu langsam ist, nicht zwei.AMDs größte Probleme bei Bulldozer sind aktuell
- Nur 1 FPU für 2 Threads
- Nur 1 Decoder für 2 Threads
- 16KB L1D Cache
Wieso macht es das Design breiter? 2x 4 Pipes mit je einer ALU oder AGLU ist doch theoretisch erstmal genauso viel Transistorlogik wie 1x 8 Pipes mit je einer ALU oder AGLU. Eventuell wird Verteilerlogik (Multiplexer) etwas aufwändiger. Aber wenn Intel das mit 6 Pipes schafft, dann sollte das auch noch mit 8 Pipes machbar sein.2x Cluster aus dem CMT Konzept > 1x Breites Cluster erstellen macht das Design aber deutlich breiter
Crashtest
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2008
- Beiträge
- 9.281
- Renomée
- 1.413
- Standort
- Leipzig
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Collatz, yoyo, radac
- Lieblingsprojekt
- yoyo
- Meine Systeme
- Ryzen: 2x1600, 5x1700, 1x2700,1x3600, 1x5600X; EPYC 7V12 und Kleinzeuch
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Lenovo IdeaPad 5 14ALC05
- Details zu meinem Desktop
- Prozessor
- Ryzen 7950X / Ryzen 4750G
- Mainboard
- ASRock B650M PGRT / X570D4U
- Kühlung
- be quiet! Dark Rock Pro4 / Pure Rock Slim 2
- Speicher
- 64GB DDR5-5600 G Skill F5-5600J3036D16G / 32 GB DDR4-3200 ECC
- Grafikprozessor
- Raphael IGP / ASpeed AST-2500
- Display
- 27" Samsung LF27T450F
- SSD
- KINGSTON SNVS2000G
- HDD
- - / 8x Seagate IronWolf Pro 20TB
- Optisches Laufwerk
- 1x B.Ray - LG BD-RE BH16NS55
- Soundkarte
- onboard HD?
- Gehäuse
- zu kleines für die GPU
- Netzteil
- be quiet! Pure Power 11 400W / dito
- Tastatur
- CHERRY SECURE BOARD 1.0
- Maus
- Logitech RX250
- Betriebssystem
- Windows 10 19045.4355 / Server 20348.2402
- Webbrowser
- Edge 124.0.2478.51
- Verschiedenes
- U320 SCSI-Controller !!!!
- Internetanbindung
- ▼1000 MBit ▲82 MBit
Ähm an Bulldozer wird seit 2007 gebastelt ! Allein die SSE5 Entwicklung und der spätere Wandel zu XOP, AVX, FMA4 etc hat einige Zeit benötigt !
Manche Sachen kann Bulldozer auch wenns erst einmal "inaktiv ist", etwa
- FMA3
- CVT16 bzw. F16C
- einige Dinge von BMI
Manche Sachen kann Bulldozer auch wenns erst einmal "inaktiv ist", etwa
- FMA3
- CVT16 bzw. F16C
- einige Dinge von BMI
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Das war die Theorie, die Praxis hat man nunHat er aber nicht. CMT verbessert ja Flächen- und Energieeffizienz. Bei gleichen Kosten und gleicher Leistungsaufnahme kann der "schwarze Rechner" also nicht mehr Wumms haben.
Außerdem ist CMT ein zu schwammiger Begriff. Angenommen, sie trixen das nun hin, dass die riesige Sprungvorhersage weiterhin gemeinsam benutzt werden kann. Trotzdem gibts aber getrennte Decoder, 2 pro Thread statt 4 und statt 1x64kB gibts 2x32 L1I-Cache. Soviel mehr an Fläche braucht das nicht, und es wäre immernoch CMT; oder wie würdest DU das nennen?
Überleg Dir was Du sagst. Praktisch ist die IPC um 1. Wenn man jetzt so wie ich rechnet, hätte AMD immerhin noch ne Effizienz von 50%, in Deinem Fall nur von 25%. D.h. Du machst AMD schlechter als ich.Das ist erstmal nebensächlich. Die theoretisch maximale IPC liegt trotzdem bei 4.
Doch ganz offensichtlich schon. Nochmal ich schrieb AVX. AVX ist AVX und nicht AVX mit XOP und FMA. Meine Aussage bezog sich eindeutig auf AVX. Wenn ich X sage, kannst Du nicht sagen falsch, weil X zusammen mit Y ...Na offensichtlich nicht, siehe nachfolgend.
Du kannst gerne anmerken, dass ich den Sachverhalt mit FMA nicht erwähnt habe, der die theoretische Lage für AMD deutlich verbessern würde. Aber ich das hab ich absichtlich wegfallen lassen, da so gut wie keiner auf XOP+FMA codiert. Immerhin kümmern die sich bei x264 jetzt etwas darum, ein schöner Anfang, mehr aber auch nicht.
In der Praxis wird man ne Menge AVX-Code haben, bei dem AMD dann aber immer hinten liegen wird.
Sag ich dochOk, sind vermutlich doch nur 3. Ich zitiere mal den SOG:
Siehe oben, ich habe behauptet das Intel mit AVX-Code AMD überlegen ist. Das war vorher schon richtig, und das bleibts auchIch bin davon ausgegangen, dass jeweils ein IMAC an den Integer Ports hängt. Ist aber doch nur an Port 0 einer. Wie auch immer, es sind 2x 128-bit FMA + 2x 128-bit SIMD. Macht also insgesamt bis zu 3 256-bit Operationen. Rein von den Kapazitäten steht AMD also erstmal besser da, und nicht wie von dir behauptet Intel.
Ich akzeptiere gerne Deinen FMA-Hinweis, aber wieviel das in der Praxis bringt muss man erstmal abwarten. Mehr als 5%-Relevanz seh ich erstmal nicht, deswegen ließ ich das weg. Naja immerhin schauts im Moment schon besser aus, als damals mit 3dnow.
3 Opterationen würd ich aber auch nicht rechnen, die IMACs können nur INT und kein FP, helfen also nicht für den FP-Durchsatz. Man könnte sie jetzt bei INT-Zuschlagen, dann hätte man nen schönen 4er Durchsatz mit reinem INT-code. Aber solange keiner XOP nutzt, ist das auch nur schöne Theorie

Nö, denn die INT-Einheit hängt am gleichen Port. Wenn da jetzt ne FP-OP kommt, wäre der INT-Teil, der auch mit dran hängt eh arbeitslos.Also ich finde es nicht praktisch. Für mich ist es nur eine Notlösung. Damit baust du dir nur unnötig Wartezyklen an Ports ein, die ansonsten anderweitig genutzt werden könnten.
Na das war damals P4 und der mobile-Chip Yonah, die hatten noch ganz andere Ports. Insbesondere hatte die nur 2, Conroe wurde dann auf 3 aufgebohrt. Wenn mans grob betrachtet also von 2fach superskalar auf 3.Was anderes war aber vermutlich auf die Schnelle nicht machbar, um SB AVX zu spendieren. Wenn es so toll sein soll, dann frage dich doch mal, warum man das nicht schon mit SSE gemacht hat. Also die FPU auf 64-bit belassen und die anderen 64-bit von den Integer Rechenwerken abzweigen.
Jo Haswell wird so oder so ein großer Umbau, bin gespannt was das wird und wie sie FMA integeren werden.Ich rechne damit, dass mit Haswell diese Notlösung wieder rausfliegt und dieser eine "echte" 256-bit FPU mitbringt.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Das ist ne gute Frage. Vermutlich haben sie falsch simuliert, oder sich aufs ursprüngliche Konzept von Glew verlassen ...@Opteron
Es geht mir nicht um CMT als solches, der Punkt ist aber, wenn sich die decoder so mal eben auftrennen lassen und die Schwachstellen die Agner Fog in seinem Dokument angibt schon länger bekannt sind & simuliert, warum hat man BD dann überhaupt so gebracht und das mit den aufgrtrennten decodern nicht von Hause aus eingebaut.
Ja nen Loop Buffer brauchts auf alle Fälle auch, aber das Thema hatten wir schon. Wenn Loop-Buffer, dann zweiDas Problem mit der Bandbreite existiert auch nur wenn beide threads vollast anliegen haben, BD schafft aber IPC von 2 nichtmal im Singlethread.Fall. Daher ist das Decoderproblem nur sekundär.Dazu kommt, dass es im Programmablauf recht häufig schleifen gibt. Aktuell müssen die instruktionen in jedem schleifendurchlauf wieder und wieder durch die "langsamen" decoder. Ein Loop cache, wie der name schon sagt, verschafft dem Frontend hier luft, weil die schleife aus dem cache laufen kann und die decoder inzwischen schonmal weiterdecodieren können.
Bin ich auch dafür, aber eventuell braucht mans halt in einem Aufwasch mit dezidierten Decodern (und hoffentlich weiterhin gemeinsam benutzer Sprungvorhersage).Daher würde ich eine verbreiterung und verbesserung des µCode-Verhaltens in Verbindung mit loop cache für besser halten.
Selbe Frage an Dich, wie an gruffi, was genau ist CMT?Wenn man die CMT Vorteile ohnehin ad acta legt, hätte man sich den Aufwand ersparen können und gleich weder normale multicores bauen.
Aber wer bin ich schon...
HoffentlichDie von AMD werden sicher wissen was sie tun...

Jupp, die besten Rechenwerke bringen nichts, wenn die Daten nicht rangeschafft werden können.Intel sagt nicht umsonst, die Cachepipeline ist ebenso wichtig wie die Rechenpipeline selbst.
Naja, Sprungvorhersage ist was anderes, als spekulativ ausführen. Wie gut das liefe müßte man erstmal testen. Bin mir gerade nicht sicher, ob Glew dazu schon was schrieb.bezüglich der scout threads... nunja... in Zeiten wo die Sprungvorhersagen über 90% trefferquoten liefern können, würde ich mal fast denken sollte es auch möglich sein die wahrscheinlichkeit dass spMT richtig liegt halbwegs hoch zu bekommen...
@FredD:
Ebenfalls gleiche Frage, wann ist ein Chip CMT, und wann nicht
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Ok die Definition ist schwammig, zugegeben, aber der Witz beim CMT war doch grade, dass Aufwändige Teile shared werden um Transistoren zu sparen.
Und das Frontend gehört wohl definitiv zu den aufwändigen Parts. Wie groß die Decoder selbst dabei allerdings genau sind, entzieht sich meiner Kenntnis.
Das ursprüngliche Konzept von Glew war ja dazu da spMT zu ermöglichen/vereinfachen, wenn sie wirklich so dusslich sind, das dann für baren Münze zu nehmen, spMT einfach wegzulassen und zu erwarten dass die Rechnung aufgeht, sind sie entweder dümmer als ich dachte oder ständig bekifft.
Ich kann doch auch nicht bei einem hochgezüchteten Turbomotor "mal eben" den Turbo weglassen und dann erwarten dass da ein super Aggregat rauskommt!?
Sprungvorhersage wird doch bereits benutzt um abzuschätzen wie ein sprung ausgeht und die Daten vorab in die caches zu laden. Ist es da so abwegig das nicht nur in die caches zu holen sondern gleich schonmal zu berechnen?
Ich meine Memory Dismabiguation ermöglicht ja schon loads vor stores zu machen und dabei in Kauf zu nehmen dass das falsche geladen wird weil der store es überschrieben hätte.
Sprungvorhersage ermittelt was als nächstes für Daten gebraucht werden. Also ist "die mitte" dazwischen ja wohl das spekulative rechnen.
Ich frage mich wie stark ein auf 6 fach aufgebohrter Decoder einen BD heute schon beschleunigen würde ohne dass man viel ändert.
Aber wieso meinst du zwei loop buffer pro thread!? je einen für Int und FP-Code oder wie?
ich denke der LB als solcher würde wenn groß genug sogar im aktuellen fall mit shared decoder vieles erleichtern. Er während die recheneinheiten munter takt um takt eine schleife durchjubeln könnte ein 6-fach decoder schonmal wieder ordentlich instruktionen nachschieben damits weitergeht.
Mit einem einzigen loop Buffer / Trace cache pro Modul hätte man evtl. noch ganz andere Möglichkeiten, man könnte nämlich im singlethread-Fall unabhängige Instruktionen auf dem zweiten int-Kern rechnen lassen. Die Aufteilung der Instruktionen auf die Int-Kerne wäre also im singlthread-Fall weniger statisch. Da effektiv sowieso alle instruktionen aus dem gemeinsamen I$ kommen wäre es also auch wurscht welcher INT-Core sie nun definitiv ausführt.
Naja, ich träume zuviel.
Aber irgendwie kommt mir die Sache mit den getrennten decodern quer. IMHO könnte man dann gleich wieder konventionelle Kerne bauen und sich das ganze Drama sparen.
Nebenbei bemerkt, wäre interessant ob ein BD aktuell mit Loop Buffer überhaupt die 2er IPC knacken kann oder ob es im retirement und bei LOAD/STORE da nicht noch etwas klemmt...
Ein paar der von Agner Fog gefundenen "Probleme" betraf ja auch unnötige Verlangsamungen bei bestimmten Cachezugriffen wenn die eine cacheline überspannen o.ä.
Also müsste man hier erstmal Hand anlegen und die cachepipeline optimieren bevor man sich über die decoder gedanken macht.
Was mich bei getrennten decodern auch interessiert, ob man dann nicht gleich 3 pro INT-Core bräuchte um die FP-unit mit gefüttert zu halten... mit 2 Decodern bei 2 ALUs kann man nur Int gesättigt halten, nicht auch noch FP.
Und das Frontend gehört wohl definitiv zu den aufwändigen Parts. Wie groß die Decoder selbst dabei allerdings genau sind, entzieht sich meiner Kenntnis.
Das ursprüngliche Konzept von Glew war ja dazu da spMT zu ermöglichen/vereinfachen, wenn sie wirklich so dusslich sind, das dann für baren Münze zu nehmen, spMT einfach wegzulassen und zu erwarten dass die Rechnung aufgeht, sind sie entweder dümmer als ich dachte oder ständig bekifft.
Ich kann doch auch nicht bei einem hochgezüchteten Turbomotor "mal eben" den Turbo weglassen und dann erwarten dass da ein super Aggregat rauskommt!?
Sprungvorhersage wird doch bereits benutzt um abzuschätzen wie ein sprung ausgeht und die Daten vorab in die caches zu laden. Ist es da so abwegig das nicht nur in die caches zu holen sondern gleich schonmal zu berechnen?
Ich meine Memory Dismabiguation ermöglicht ja schon loads vor stores zu machen und dabei in Kauf zu nehmen dass das falsche geladen wird weil der store es überschrieben hätte.
Sprungvorhersage ermittelt was als nächstes für Daten gebraucht werden. Also ist "die mitte" dazwischen ja wohl das spekulative rechnen.
Ich frage mich wie stark ein auf 6 fach aufgebohrter Decoder einen BD heute schon beschleunigen würde ohne dass man viel ändert.
Aber wieso meinst du zwei loop buffer pro thread!? je einen für Int und FP-Code oder wie?
ich denke der LB als solcher würde wenn groß genug sogar im aktuellen fall mit shared decoder vieles erleichtern. Er während die recheneinheiten munter takt um takt eine schleife durchjubeln könnte ein 6-fach decoder schonmal wieder ordentlich instruktionen nachschieben damits weitergeht.
Mit einem einzigen loop Buffer / Trace cache pro Modul hätte man evtl. noch ganz andere Möglichkeiten, man könnte nämlich im singlethread-Fall unabhängige Instruktionen auf dem zweiten int-Kern rechnen lassen. Die Aufteilung der Instruktionen auf die Int-Kerne wäre also im singlthread-Fall weniger statisch. Da effektiv sowieso alle instruktionen aus dem gemeinsamen I$ kommen wäre es also auch wurscht welcher INT-Core sie nun definitiv ausführt.
Naja, ich träume zuviel.
Aber irgendwie kommt mir die Sache mit den getrennten decodern quer. IMHO könnte man dann gleich wieder konventionelle Kerne bauen und sich das ganze Drama sparen.
Nebenbei bemerkt, wäre interessant ob ein BD aktuell mit Loop Buffer überhaupt die 2er IPC knacken kann oder ob es im retirement und bei LOAD/STORE da nicht noch etwas klemmt...
Ein paar der von Agner Fog gefundenen "Probleme" betraf ja auch unnötige Verlangsamungen bei bestimmten Cachezugriffen wenn die eine cacheline überspannen o.ä.
Also müsste man hier erstmal Hand anlegen und die cachepipeline optimieren bevor man sich über die decoder gedanken macht.
Was mich bei getrennten decodern auch interessiert, ob man dann nicht gleich 3 pro INT-Core bräuchte um die FP-unit mit gefüttert zu halten... mit 2 Decodern bei 2 ALUs kann man nur Int gesättigt halten, nicht auch noch FP.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Schlägt zwar in eine andere Richtung (VLIW), dürfte aber deine Aussage zumindest relativieren: Clustered Loop BufferWenn Loop-Buffer, dann zwei pro Thread ...
Da müsste man wohl die Ingenieure von Sun fragen, die haben das Konzept zuerst aufgebracht und so benannt. Ich würde den Begriff auf "Architektur mit mehr als 1 Integer ALU pro Kern, die auf gemeinsam geteilte Funktionseinheiten zugreifen" zusammenraffen.@FredD:
Ebenfalls gleiche Frage, wann ist ein Chip CMT, und wann nicht
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Das wäre aber kontraproduktiv für singlethreaded Performance. Was genau hast du damit also gewonnen?Angenommen, sie trixen das nun hin, dass die riesige Sprungvorhersage weiterhin gemeinsam benutzt werden kann. Trotzdem gibts aber getrennte Decoder, 2 pro Thread statt 4 und statt 1x64kB gibts 2x32 L1I-Cache. Soviel mehr an Fläche braucht das nicht, und es wäre immernoch CMT; oder wie würdest DU das nennen?
Das ändert trotzdem nichts an der theoretisch maximalen IPC von 4. Das sollte für AMD ja vielmehr das Signal sein, dass man bezüglich Auslastung noch Spielraum nach oben hat.Überleg Dir was Du sagst. Praktisch ist die IPC um 1. Wenn man jetzt so wie ich rechnet, hätte AMD immerhin noch ne Effizienz von 50%, in Deinem Fall nur von 25%. D.h. Du machst AMD schlechter als ich.
Ich weiss ja nicht, ob dir das nicht bekannt ist, aber FMA ist Teil der AVX Spezifikation. Und die Integer Einheiten kommen nicht nur bei XOP zum Zuge, sondern genauso bei MMX, SSE und AVX. Wie ich bereits sagte, was du geschrieben hast, ist nicht ganz korrekt. Intel steht bezüglich Ausführungskapazitäten nicht besser da. Ganz im Gegenteil. Daran ändern übrigens auch 3 statt 4 256-bit Ops nichts.Doch ganz offensichtlich schon. Nochmal ich schrieb AVX. AVX ist AVX und nicht AVX mit XOP und FMA. Meine Aussage bezog sich eindeutig auf AVX.
Darum ging es auch gar nicht. Keiner hat ausschliesslich von FP Operationen gesprochen.3 Opterationen würd ich aber auch nicht rechnen, die IMACs können nur INT und kein FP, helfen also nicht für den FP-Durchsatz.
Ist das nicht schon Einschränkung genug? Bei AMD hängen sie schliesslich an unterschiedlichen Ports. Was ist, wenn eine Integer Operation gerade ausgeführt wird? Dann ist einer der Ports bei Intel auf jeden Fall erstmal blockiert für eine 256-bit FP Operation. Und hast du dir schon mal die Befehlslatenzen angeschaut? Was Intel da macht, gibt's nicht gratis. Das hast du ja nun schon selbst erwähnt.Nö, denn die INT-Einheit hängt am gleichen Port.
Ich spreche von Pentium-M / Core. Die hatten im Grunde die gleichen Ports. Da hat sich bis heute nicht viel geändert.Na das war damals P4 und der mobile-Chip Yonah, die hatten noch ganz andere Ports.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@Ge0rgy:
Sorry, das mit dem 2 Puffer pro Thread war großer Blödsinn
Meinte 2 pro Modul, für jeden Thread einen, das wurde dann verkürzt wiedergegeben und damit ziemlicher Unsinn ^^
Ansonsten, tja das Front-End .. tolle Baustelle. Hab mich gerade wieder an die Schwungrad-Sache erinnert, das hatte Dresdenboy in der guten alten Zeit mal ausgegraben, hatte das hier mal zusammengefasst:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4314475#post4314475
Hab auch nochmal das Paper überflogen, interessant ist eventuell die Aussage über CISC-Decoder im Allgemeinen:
Im Flyweehl Patent reden sie auch von nem doppelt so hoch getaktetem Front-End, wäre ja ideal fürs 2 Kerne
Da könnte man dann weiter spekulieren, ob ct vielleicht was falsch verstanden hat. Z.B. das jeder Thread seinen eigenen Trace-Cache / µOpPuffer, oder wie auch immer wirs nennen, bekommt.
Und selbst wenn irgendwo in nem aktuellen Intel AVX Manual was von FMA stünde, dann wäre das sicherlich nicht AMDs FMA4 *g*
Conroe war bereits 128bittig. Gegenüber Yonah wurde da nicht nur AMD64 und von 64->128b SSE aufgebohrt, sondern auch ein dritter Port (Port 5) nachgerüstet, wie schon erwähnt eben der Schritt von 2fach auf 3fach superskalar. Das entspannt die ganze Lage allgemein, wenn da ein kompletter Port mit 3-4 untergeordneten INT/FP-Units zusätzlich angeschlossen wird.
Ums abzuschließen: Datenpfade waren von 64 -> 128b nicht das Problem, da eh viel umgebaut wurde. Aktuell dagegen wurde nur die Vektoren auf 256b erweitert, nur dafür großartig Leitungen zu verlegen rentiert nicht. Außerdem gibts noch 2 weitere Ports, an die man eventuelle INT-Ops vergeben kann. Beim Yonah häts nur eine Alternative gegeben. Nebenbei bemerkt, wenn Du schon Intel kein "echtes" 256b AVX bescheinigst, was hat dann AMD? Da ists doch eher schlimmer, eine 256b Instruktion muss in 2 Ops zerlegt werden und wenn man direkt mit 2 gleichwertige 128b Befehlen programmiert ist man ~3% schneller.
Sorry, das mit dem 2 Puffer pro Thread war großer Blödsinn
Meinte 2 pro Modul, für jeden Thread einen, das wurde dann verkürzt wiedergegeben und damit ziemlicher Unsinn ^^
Ansonsten, tja das Front-End .. tolle Baustelle. Hab mich gerade wieder an die Schwungrad-Sache erinnert, das hatte Dresdenboy in der guten alten Zeit mal ausgegraben, hatte das hier mal zusammengefasst:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4314475#post4314475
Hab auch nochmal das Paper überflogen, interessant ist eventuell die Aussage über CISC-Decoder im Allgemeinen:
Eventuell ging einfach nicht mehr beim BD, größere Decoder hätten eventuell die Taktfrequenz gedrückt. Mit Flywheel könnte man das auch umgehen. Hoffentlich kommts noch, oder wenigstens halt irgendein Puffer *g*Due to the use of CISC ISA, the parallel x86 decoders have been traditionally one of the most complex parts of the processor, limiting the maximum achievable clock frequency and amounting for an important part of the total power budget.
Im Flyweehl Patent reden sie auch von nem doppelt so hoch getaktetem Front-End, wäre ja ideal fürs 2 Kerne
Da könnte man dann weiter spekulieren, ob ct vielleicht was falsch verstanden hat. Z.B. das jeder Thread seinen eigenen Trace-Cache / µOpPuffer, oder wie auch immer wirs nennen, bekommt.
Tipp: Zwei Caches = Doppelter Durchsatz.Das wäre aber kontraproduktiv für singlethreaded Performance. Was genau hast du damit also gewonnen?
Ja so siehts der OptimistDas ändert trotzdem nichts an der theoretisch maximalen IPC von 4. Das sollte für AMD ja vielmehr das Signal sein, dass man bezüglich Auslastung noch Spielraum nach oben hat.
Wer hat Dir denn den Unsinn erzählt? FMA hat eigene CPUID. Wenns so wäre, dann würde Sandy-Bridge ja auch FMA können müssen, schließlich hat er AVX und laut Deiner Auffassung würde das FMA beinhalten. Nene, das ist großer Käse, den Du da erzählst.Ich weiss ja nicht, ob dir das nicht bekannt ist, aber FMA ist Teil der AVX Spezifikation.
Und selbst wenn irgendwo in nem aktuellen Intel AVX Manual was von FMA stünde, dann wäre das sicherlich nicht AMDs FMA4 *g*
Ah, das stimmt, v.a. SSSE3 geht noch auf die beiden Ports, das Shuffel-Zeugs halt. Gut, da hast Du also recht.Und die Integer Einheiten kommen nicht nur bei XOP zum Zuge, sondern genauso bei MMX, SSE und AVX.
Auch wenn Dus weiter nicht einsehen willst ich schrieb explizit AVX Instruktion. Da ist es auch egal, ob irgendein Manual vielleicht nen Schreibfehler hat. Eine FMA-Instruktion ist ganz sicher keine AVX Instruktion. Keine Ahnung, was Du da für ein Interpretationsproblem hastWie ich bereits sagte, was du geschrieben hast, ist nicht ganz korrekt. Intel steht bezüglich Ausführungskapazitäten nicht besser da. Ganz im Gegenteil. Daran ändern übrigens auch 3 statt 4 256-bit Ops nichts.
Doch ich, ne AVX-Instruktion ist perse FP. INT Befehle kommen erst mit AVX2Darum ging es auch gar nicht. Keiner hat ausschliesslich von FP Operationen gesprochen.
Hmm nö, wieso sollte es ein Problem sein? Wenn eine INT gerade ausgeführt wird, dann kann logischerweise kein FP Befehl an dem einen Port drankommen. Aber insgesamt gibts 3 Ports, an jedem hängen gemischte INT/FP Units, das reicht schon.Ist das nicht schon Einschränkung genug? Bei AMD hängen sie schliesslich an unterschiedlichen Ports. Was ist, wenn eine Integer Operation gerade ausgeführt wird? Dann ist einer der Ports bei Intel auf jeden Fall erstmal blockiert für eine 256-bit FP Operation.
Hm meinst Du die Latenz beim Moduswechsel? Ja die hab ich erwähnt. Ansonsten - bei den normalen Latenzen - war AMD aber sehr selten vorne. Darüber will ich mich aber gar nicht beschweren, ist eher normal, BD ist halt auch mehr ein Hochtaktdesign, als Intels Ansatz.Und hast du dir schon mal die Befehlslatenzen angeschaut? Was Intel da macht, gibt's nicht gratis. Das hast du ja nun schon selbst erwähnt.
Nenn mal Codenamen, z.B. Yonah, Pentium-M gabs viele.Ich spreche von Pentium-M / Core. Die hatten im Grunde die gleichen Ports. Da hat sich bis heute nicht viel geändert.
Conroe war bereits 128bittig. Gegenüber Yonah wurde da nicht nur AMD64 und von 64->128b SSE aufgebohrt, sondern auch ein dritter Port (Port 5) nachgerüstet, wie schon erwähnt eben der Schritt von 2fach auf 3fach superskalar. Das entspannt die ganze Lage allgemein, wenn da ein kompletter Port mit 3-4 untergeordneten INT/FP-Units zusätzlich angeschlossen wird.
Ums abzuschließen: Datenpfade waren von 64 -> 128b nicht das Problem, da eh viel umgebaut wurde. Aktuell dagegen wurde nur die Vektoren auf 256b erweitert, nur dafür großartig Leitungen zu verlegen rentiert nicht. Außerdem gibts noch 2 weitere Ports, an die man eventuelle INT-Ops vergeben kann. Beim Yonah häts nur eine Alternative gegeben. Nebenbei bemerkt, wenn Du schon Intel kein "echtes" 256b AVX bescheinigst, was hat dann AMD? Da ists doch eher schlimmer, eine 256b Instruktion muss in 2 Ops zerlegt werden und wenn man direkt mit 2 gleichwertige 128b Befehlen programmiert ist man ~3% schneller.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Bei singlethreaded Workloads? Eher nicht.Tipp: Zwei Caches = Doppelter Durchsatz.
Und? Wen interessiert das denn? Du kannst dir das AVX Whitepaper bei Intel runterladen und selbst nachschauen. Danach können wir gerne nochmal darüber reden, wer hier Unsinn erzählt.FMA hat eigene CPUID.
Ich zitiere dir sogar den relevanten Teil:Der Punkt ist einfach, dass Intel noch kein FMA bei Sandy Bridge bringen konnte. Daher haben sie FMA ein extra Kapitel spendiert. Und deshalb hat auch CPUID ein extra Bit dafür. Was nichts daran ändert, dass FMA zu AVX gehört.FMA is a future extension of Intel AVX
Ich weiss nicht, was du für ein Problem hast, dir auch mal was sagen zu lassen. Aber eines sollte dir bewusst sein, ohne überheblich klingen zu wollen, über solche Sachen weiss ich ganz bestimmt besser Bescheid als du. Was du hier erzählst, ist schon wieder Halbwissen. Wie zuvor auch schon. AVX(1) ist nicht per se FP, auch wenn hier sicherlich der Fokus liegt. AVX(1) besitzt auch implizite und explizite Ganzzahloperationen. Implizite sind jene, die ebenfalls von Ganzzahlrechenwerken verarbeitet werden, selbst wenn sie als FP Instruktionen deklariert sind. Ein typisches Beispiel sind logische Operationen (and, or, xor). Und du darfst dir gerne mal im AMD SOG anschauen, wo diese Operationen verarbeitet werden. Richtig, nicht in den FMACs, sondern an Port 2 und 3. Also den Ports, wo das ganze Ganzzahl Gedöns dranhängt. Es ist also problemlos möglich, dass 4 AVX Instruktionen an allen 4 Ports ausgeführt werden, auch ohne FMA.Doch ich, ne AVX-Instruktion ist perse FP. INT Befehle kommen erst mit AVX2
AMD kann es aber eben gleichzeitig mit getrennten Ports, Intel nicht. Mal davon abgesehen, jede Instruktion hat eine gewisse Latenz, braucht also eine bestimmte Anzahl an Zyklen, bis sie von den EUs verarbeitet wurde. Inwiefern man jeden neuen Zyklus bereits eine neue Operation nachschieben kann, kann ich dir nicht sagen. Wenn die Rechenwerke aber voneinander unabhängig arbeiten, sollte das möglich sein. Bei Intels Lösung ist das auf jeden Fall nicht möglich, da die Rechenwerke eben nicht mehr voneinander unabhängig sind.Hmm nö, wieso sollte es ein Problem sein? Wenn eine INT gerade ausgeführt wird, dann kann logischerweise kein FP Befehl an dem einen Port drankommen.
Mal davon abgesehen, dass AMD kein Hochtaktdesign besitzt, ich sprach nicht von AMD. Es ging um Intel vs Intel, mit und ohne diese Notlösung.Hm meinst Du die Latenz beim Moduswechsel? Ja die hab ich erwähnt. Ansonsten - bei den normalen Latenzen - war AMD aber sehr selten vorne. Darüber will ich mich aber gar nicht beschweren, ist eher normal, BD ist halt auch mehr ein Hochtaktdesign, als Intels Ansatz.
Core war Yonah. Der Vorgänger in Form des Pentium-M war glaube ich Dothan.Nenn mal Codenamen, z.B. Yonah, Pentium-M gabs viele.
Port 5 ändert aber nichts am Sachverhalt. Das sind ja lediglich weitere Operationen. Thema ist erstmal Port 0 und 1. Und die existierten eben schon bei Yonah. Wenn's also so toll gewesen sein soll, hätte man schon dort Integer und FP Rechenwerke gemeinsam nutzen können. Die Ausgangssituation war die gleiche wie bei SB. Unterschied ist lediglich, dass es damals um die Hälfte der Datenbreite ging. Der sonstige Umbau beim Core 2 tut da nichts zur Sache.Conroe war bereits 128bittig. Gegenüber Yonah wurde da nicht nur AMD64 und von 64->128b SSE aufgebohrt, sondern auch ein dritter Port (Port 5) nachgerüstet, wie schon erwähnt eben der Schritt von 2fach auf 3fach superskalar. Das entspannt die ganze Lage allgemein, wenn da ein kompletter Port mit 3-4 untergeordneten INT/FP-Units zusätzlich angeschlossen wird.
Bitte nicht schon wieder so viel erfinden. Etwas derartiges habe ich nicht gesagt. Ich sagte "echte" 256-bit FPU. Wie diese dann strukturiert ist, 1x 256-bit, 2x 128-bit (AMD) oder 4x 64-bit, ist ein anderes Thema.Nebenbei bemerkt, wenn Du schon Intel kein "echtes" 256b AVX bescheinigst, was hat dann AMD?
Crashtest
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2008
- Beiträge
- 9.281
- Renomée
- 1.413
- Standort
- Leipzig
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Collatz, yoyo, radac
- Lieblingsprojekt
- yoyo
- Meine Systeme
- Ryzen: 2x1600, 5x1700, 1x2700,1x3600, 1x5600X; EPYC 7V12 und Kleinzeuch
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Lenovo IdeaPad 5 14ALC05
- Details zu meinem Desktop
- Prozessor
- Ryzen 7950X / Ryzen 4750G
- Mainboard
- ASRock B650M PGRT / X570D4U
- Kühlung
- be quiet! Dark Rock Pro4 / Pure Rock Slim 2
- Speicher
- 64GB DDR5-5600 G Skill F5-5600J3036D16G / 32 GB DDR4-3200 ECC
- Grafikprozessor
- Raphael IGP / ASpeed AST-2500
- Display
- 27" Samsung LF27T450F
- SSD
- KINGSTON SNVS2000G
- HDD
- - / 8x Seagate IronWolf Pro 20TB
- Optisches Laufwerk
- 1x B.Ray - LG BD-RE BH16NS55
- Soundkarte
- onboard HD?
- Gehäuse
- zu kleines für die GPU
- Netzteil
- be quiet! Pure Power 11 400W / dito
- Tastatur
- CHERRY SECURE BOARD 1.0
- Maus
- Logitech RX250
- Betriebssystem
- Windows 10 19045.4355 / Server 20348.2402
- Webbrowser
- Edge 124.0.2478.51
- Verschiedenes
- U320 SCSI-Controller !!!!
- Internetanbindung
- ▼1000 MBit ▲82 MBit
Also FMA gehört nicht zu AVX !
Oben stehts doch gut erklärt:
Sandy kann AVX. Sandy kann aber kein FMA. Wäre FMA ein Teil von AVX könnte der Sandy dies doch !!!!
Es ist durch aus möglich, dass FMA ein Teilbestandteil von AVX2 wird - vergleichbar dem Basissatz, dass SSE2 bei AMD64 dabei ist (es gibt kein AMD64-fähigen Prozzi ohne SSE2)
Nebenbei - bekämpft euch auf Computerbase oder per PM !!!!!!!!
Oben stehts doch gut erklärt:
Sandy kann AVX. Sandy kann aber kein FMA. Wäre FMA ein Teil von AVX könnte der Sandy dies doch !!!!
Es ist durch aus möglich, dass FMA ein Teilbestandteil von AVX2 wird - vergleichbar dem Basissatz, dass SSE2 bei AMD64 dabei ist (es gibt kein AMD64-fähigen Prozzi ohne SSE2)
Nebenbei - bekämpft euch auf Computerbase oder per PM !!!!!!!!
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Natürlich gehört FMA zu AVX. Das Zitat ist doch eindeutig. Ich glaube, ihr habt einfach Verständnisprobleme mit dem Oberbegriff AVX und einzelnen Iterationen davon. AVX(1), AVX2, AVX3 oder was da noch kommen mag, ist alles AVX. Genauso wie SSE(1), SSE2, SSE3, etc, alles SSE ist.
ONH
Grand Admiral Special
Ach ne, dann ist ja klar das ihr beide aneinander vorbeigeredet hat der eine meint mit AVX die Erweiterungen (Vonder ersten bist zur Versionwelche Nächstes Jahr oder Später in Prozessoren implementiert werden) allgemein und er Andere die erste Version welche Intel in SB implementiert hat, wo FMA nicht dabei ist. Dann kann man ja jetzt das Streiten darum was dazugehört lassen, da schlussendlich wohl beide nicht unrecht haben, und zurück zum Thema Kaveri kommen.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ok, zu warten, bis der Diskussionsstaub sich legt, würde wohl dazu führen, dass ich mich erst auf Seite 100 des Threads beginne einzumischen ;^) Also werfe ich jetzt mal ein paar Gedanken ins Feld:
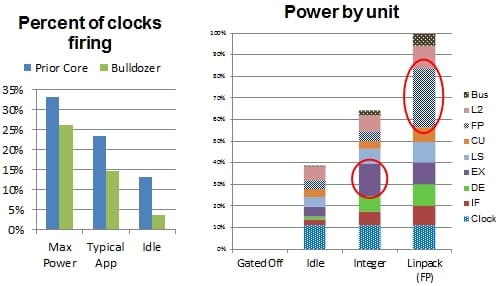
Wie die von mir im Trinity-Thread geposteten P/F-Kurven zeigten, sinkt in höheren Taktbereichen die Effizienz (Performance/Watt) schnell. Was da nicht zu sehen war: ein (zunehmender Teil) davon ist Leakage.
Was dagegen für das Design festgelegt wurde, sind die TDP-Stufen. Wenn nun fleißig hier und da zusätzliche Logik eingebaut wird, wächst erstmal die Leakage, unabhängig vom Clock-Gating (welches die Auslastungseffekte abmildert). Aber auch im idle-Betrieb sind ein paar Verbraucher aktiv. Also die separate FPU pro Kern könnte den Idle-Verbrauch vom Modul um 20% erhöhen (Clock-Anteil entspr. Flächenanteil plus den FP-Grundumsatz).
Beim Linpack-Benchmark nutzt die FPU (inkl. Anteil bei "Clock") etwa 30% des Verbrauchs allein in Anspruch. Mit doppelter FPU wäre das dank weniger Auslastung zwar geringer, aber durch die notwendigen Erweiterungen bei Decoder, L/S-Unit usw. schätze ich, dass der Verbrauch dann immer noch grob 25% höher wäre.
Dazu nochmal die Graphen bei The Register (für mehr Farbe im Thread):
http://www.theregister.co.uk/2011/02/24/amd_bulldozer_core_isscc/page2.html
Ergebnis:
Idle+20%, Load+25%. Höherer Idle-Verbrauch wirkt sich auf die Turbospielräume anderer Module aus und wäre schlecht für Mobile-CPUs, der FP-Load-Verbrauch schränkt den Takt generell ein, etwa. 15-20% (die Spannung kann dann ja gesenkt werden). Also nach Taktkorrektur erreicht das Konstrukt bei HPC evtl. 50% mehr FP-Performance, bei Spielen u.ä. FP-Codes so 0-20%. Als dedizierer HPC-Chip wäre das interessant.
Die Herstellkosten des Chips würden nur um ein paar Dollar steigen.
Man kann die Auswirkungen eines dedizierten Decoders, L2-Caches, FPU und aller weiteren geteilten Komponenten in Aten-Ra's Blog nachlesen:
http://atenra.blog.com/2012/02/01/amd’s-bulldozer-cmt-scaling/
Die 4M/4T-Fälle einiger FP-Benchmarks zeigen genau den Fall.
Idontcare im Anandtech-Forum hat da auch eine ausführliche Analyse verschiedener Verbrauchseffekte beim Sandy Bridge durchgeführt:
http://forums.anandtech.com/showthread.php?p=32451355#post32451355
Wie die von mir im Trinity-Thread geposteten P/F-Kurven zeigten, sinkt in höheren Taktbereichen die Effizienz (Performance/Watt) schnell. Was da nicht zu sehen war: ein (zunehmender Teil) davon ist Leakage.
Was dagegen für das Design festgelegt wurde, sind die TDP-Stufen. Wenn nun fleißig hier und da zusätzliche Logik eingebaut wird, wächst erstmal die Leakage, unabhängig vom Clock-Gating (welches die Auslastungseffekte abmildert). Aber auch im idle-Betrieb sind ein paar Verbraucher aktiv. Also die separate FPU pro Kern könnte den Idle-Verbrauch vom Modul um 20% erhöhen (Clock-Anteil entspr. Flächenanteil plus den FP-Grundumsatz).
Beim Linpack-Benchmark nutzt die FPU (inkl. Anteil bei "Clock") etwa 30% des Verbrauchs allein in Anspruch. Mit doppelter FPU wäre das dank weniger Auslastung zwar geringer, aber durch die notwendigen Erweiterungen bei Decoder, L/S-Unit usw. schätze ich, dass der Verbrauch dann immer noch grob 25% höher wäre.
Dazu nochmal die Graphen bei The Register (für mehr Farbe im Thread):
http://www.theregister.co.uk/2011/02/24/amd_bulldozer_core_isscc/page2.html
Ergebnis:
Idle+20%, Load+25%. Höherer Idle-Verbrauch wirkt sich auf die Turbospielräume anderer Module aus und wäre schlecht für Mobile-CPUs, der FP-Load-Verbrauch schränkt den Takt generell ein, etwa. 15-20% (die Spannung kann dann ja gesenkt werden). Also nach Taktkorrektur erreicht das Konstrukt bei HPC evtl. 50% mehr FP-Performance, bei Spielen u.ä. FP-Codes so 0-20%. Als dedizierer HPC-Chip wäre das interessant.
Die Herstellkosten des Chips würden nur um ein paar Dollar steigen.
Man kann die Auswirkungen eines dedizierten Decoders, L2-Caches, FPU und aller weiteren geteilten Komponenten in Aten-Ra's Blog nachlesen:
http://atenra.blog.com/2012/02/01/amd’s-bulldozer-cmt-scaling/
Die 4M/4T-Fälle einiger FP-Benchmarks zeigen genau den Fall.
Idontcare im Anandtech-Forum hat da auch eine ausführliche Analyse verschiedener Verbrauchseffekte beim Sandy Bridge durchgeführt:
http://forums.anandtech.com/showthread.php?p=32451355#post32451355
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Du kannst dir das AVX Whitepaper bei Intel runterladen und selbst nachschauen. Danach können wir gerne nochmal darüber reden, wer hier Unsinn erzählt. Ich zitiere dir sogar den relevanten Teil:
Natürlich gehört FMA zu AVX. Das Zitat ist doch eindeutig. Ich glaube, ihr habt einfach Verständnisprobleme mit dem Oberbegriff AVX und einzelnen Iterationen davon. AVX(1), AVX2, AVX3 oder was da noch kommen mag, ist alles AVX. Genauso wie SSE(1), SSE2, SSE3, etc, alles SSE ist.
Ne, das Problem ist, dass Du nicht up-to-date bist und olle Kamellen erzählst. Dein Zitat gabs zuletzt in der 2009er Spezifikation. Dein AVX Paper gibts auch gar nicht mehr, das heißt jetzt nicht mehr "Intel® Advanced Vector Extensions Programming Reference" sondern allgemein "Intel® Architecture Instruction Set Extensions Programming Reference". Mittlerweile haben wir eben 2012 und es gibt anstatt der 2009er Version 6 (Dateiname: AVX_319433-006) jetzt Version 12a vom Februar 2012 (319433-012a).
Alt:
FMA is a future extension of Intel AVX
Neu:
FMA instruction extensions are described in Chapter 6.
Links:
http://software.intel.com/file/41604
http://software.intel.com/file/21558
Also bring Dich mal auf den neuesten Stand. Für mich ist das Thema damit beendet.
@Dresdenboy:
Danke. Hast Du eigentlich nochmal irgendwo was vom Flywheel gehört? Hab gerade gesehen, dass im Flywheelpaper in den Quellen auch auf ein früheres Paper verweisen. Das liest sich eigentlich genau wie die Implementierung des SandyB. µCode Caches:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.68.4152&rep=rep1&type=pdf
Vielleicht kommt Flywheel ja in Haswell ...
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nee, das Problem ist, dass du jetzt nur wieder nach Ausreden suchst. Ich habe neben der ursprünglichen Version auch 319433-011 hier. Die ist von Juni 2011 und mW auch die aktuellste Final Version. Da heisst es übrigens immer noch Intel® Advanced Vector Extensions Programming Reference. Da brauchst du nicht bis 2009 zurückzugehen oder mir was von irgendeiner Alpha Version erzählen, die du jetzt nach vielleicht 2 Tagen Suche gefunden hast, von der du bisher gar nichts wusstest. Das ist einfach nur kindisch. An meiner ursprünglichen Aussage ändert das ja nichts. AVX(1) und FMA gehören zur selben Spezifikation. Selbst wenn diese nun nicht mehr AVX, sondern anders heissen mag.Ne, das Problem ist, dass Du nicht up-to-date bist und olle Kamellen erzählst. Dein Zitat gabs zuletzt in der 2009er Spezifikation. Dein AVX Paper gibts auch gar nicht mehr, das heißt jetzt nicht mehr "Intel® Advanced Vector Extensions Programming Reference" sondern allgemein "Intel® Architecture Instruction Set Extensions Programming Reference". Mittlerweile haben wir eben 2012 und es gibt anstatt der 2009er Version 6 (Dateiname: AVX_319433-006) jetzt Version 12a vom Februar 2012 (319433-012a).
Dresdenboy
Redaktion
☆☆☆☆☆☆
Interessante Diskussion. Die veröffentlichten AMD Marketing-Bildchen lassen miich jedoch nicht so recht an eine Abkehr vom CMT-Ansatz glauben.

Das glaube ich auch nicht, deshalb auch meine Ausführungen. Das Konzept ist nicht das Problem, sondern eher die beschlossenen Trade-Offs, Constraints, Kosten/Zeit/Komplexitäts-Überlegungen.
Aber wenn Zeit und Kosten bei BD1 noch nicht ausreichten, werden diese sich über den gezeigten Pfad noch gut akkumulieren.
Ähnliche Themen
- Antworten
- 638
- Aufrufe
- 141K
- Antworten
- 12
- Aufrufe
- 6K
- Antworten
- 0
- Aufrufe
- 44K