App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@gruffi:
Ist doch alles egal worüber Du jetzt diskutieren willst. Ob Du jetzt händisch kopierst, oder ne Automatik, oder sonstwer ... die Hauptsache ist, dass Llano einen nicht coherenten Bus hat.
Die Aussage ist glasklar, da müssen wir nicht um den Rest herumstreiten. Llano hat nicht coherente Speicherbereiche, ergo ists mit HSA Essig, da HSA laut der Definition im PDF koherenten, gemeinsam benützten Speicher voraussetzt (which operate coherently in shared memory).
Da seh ich wirklich keinen Spielraum, wenn Du magst können wir mal Gipsel fragen, wie er das interpretieren würde.
Ist doch alles egal worüber Du jetzt diskutieren willst. Ob Du jetzt händisch kopierst, oder ne Automatik, oder sonstwer ... die Hauptsache ist, dass Llano einen nicht coherenten Bus hat.
so is a non coherent bus
Die Aussage ist glasklar, da müssen wir nicht um den Rest herumstreiten. Llano hat nicht coherente Speicherbereiche, ergo ists mit HSA Essig, da HSA laut der Definition im PDF koherenten, gemeinsam benützten Speicher voraussetzt (which operate coherently in shared memory).
Da seh ich wirklich keinen Spielraum, wenn Du magst können wir mal Gipsel fragen, wie er das interpretieren würde.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Jup, hab es zu sehr aus der Sicht der CPU betrachtet.Jetzt haust du aber was durcheinander. Der nicht cacheable Speicher läuft über das Garlic Interface, nicht Onion. Im Grunde läuft alles nicht kohärente über Garlic, alles kohärente über Onion.
Wir haben 3 Speicherbereiche:
1)GPU Speicher
2)gemeinsamer Speicher
3)CPU Speicher.
Aus CPU Sicht:
1 ist non cachable, schreibzugriffe darauf werden über Onion geleitet, lesezugriffe müssen per Software synchronisiert werden.
2 muß per MMU gepinnt sein
3 erlaubt normale Zugriffe.
Aus GPU Sicht:
1 zugriff über Garlic
2 zugriff über Onion, kohärent, langsam
3 wegen unterschiedlicher Virtuelle Adressräume nicht nutzbar
The GPU can send coherent memory requests to CPU memory that is pinned, but the CPU relies on the driver and explicit synchronization to communicate with the GPU.
In dem von dir verlinktem Dokument ist doch das Schema für Sandy abgebildet und beschrieben. CPUs, L3, GPU und Memory Controler hängen an einem gemeinsamen RingBus und alle können munter kohärent auf den gemeinsamen Speicher zugreifen. Demnach hat Sandy schon Huma. Zudem kann der L3 beim Zugriff auf gemeinsame Datenbereiche enorm beschleunigen.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Hinter den kohärenten GPU-CPU Speicher von Sandy-Bridge möchte ich mal ein "?" Fragezeichen setzen. Vom gemeinsamen Adressraum (die wichtigste Eigenschaft von hUMA) ist noch keine Rede.In dem von dir verlinktem Dokument ist doch das Schema für Sandy abgebildet und beschrieben. CPUs, L3, GPU und Memory Controler hängen an einem gemeinsamen RingBus und alle können munter kohärent auf den gemeinsamen Speicher zugreifen. Demnach hat Sandy schon Huma. Zudem kann der L3 beim Zugriff auf gemeinsame Datenbereiche enorm beschleunigen.
Quelle: http://www.realworldtech.com/sandy-bridge-gpu/9/The graphics integration in Sandy Bridge is particularly novel as Intel is sharing the LLC with the GPU. The driver allocates regions of the cache at way granularity (128KB) – and can actually request the whole cache. Each thread can spill 32KB of data back to the LLC, for a total of nearly 2MB in the larger 12 shader core variants. Almost any GPU data can be held in the LLC, including vertices, textures and many other types of state.
The Sandy Bridge LLC and ring interconnect can rapidly pass data from the GPU back to the CPU – AMD’s Fusion is a far higher performance GPU, but that particular style of communication is discouraged. Since the GPU has a weaker ordering model, a flush command is needed to force data to be written back to the LLC prior to the CPU reading it. The driver can also allocate a portion of the LLC as a non-coherent cache for display data and other uses. For example, the results of transcoding might be written out to the the non-coherent region.
While this excellent system integration promises many benefits, at present it is restricted mainly to multimedia workloads. For graphics, it is largely an academic advantage to any but Intel’s driver team. The GPU is exposed through graphics APIs; yet neither OpenGL nor DirectX programs can interact with coherent memory and bypass I/O copies (let alone use the LLC). AMD has introduced an OpenCL extension for a zero copy mechanism on Windows systems already, and presumably Intel will follow once they have OpenCL and DirectCompute capable hardware. Intel’s graphics driver can take advantage of fast CPU/GPU communication, but that is only because it has raw access to the GPU hardware. These advances pave the way for Ivy Bridge and certainly promise good things in the future, but also serve to point out some of the deficiencies in the current generation.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Eine Schwäche von Kabini ist aktuell das schmale 64bit-Ram-Interface; hier hat Baytrail die doppelte Bandbreite. Inwiefern kann HSA hier helfen, den Traffic über das Ram-Interface zu reduzieren und so das Nadelöhr Ram-Interface zu mildern und so womöglich ein 128bit-Interface gar überflüssig machen? Das würde dann nicht nur die Performance von Kabini steigern, sondern Kabini auch einen Kostenvorteil gegenüber Baytrail ermöglichen, zumal Baytrails Die obwohl dem (teureren) 22nm-Prozess fast so groß wie Kabini sein soll.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hab auch irgendwo gelesen, dass Sandy den L3/LLC "nur" hat, um darüber die Daten auszutauschen. Ivy ist jetzt auf dem Zero-Copy stand, also Llano/Trinity-Niveau. Oder ums frustrierender zu formulieren: Sie haben mit AMD gleichgezogen, Kaveri lässt ja auch sich wartenHinter den kohärenten GPU-CPU Speicher von Sandy-Bridge möchte ich mal ein "?" Fragezeichen setzen. Vom gemeinsamen Adressraum (die wichtigste Eigenschaft von hUMA) ist noch keine Rede.

Nette Idee, aber das würde ich jetzt wieder im Kabinithread diskutieren wollen ^^Eine Schwäche von Kabini ist aktuell das schmale 64bit-Ram-Interface; hier hat Baytrail die doppelte Bandbreite. Inwiefern kann HSA hier helfen, den Traffic über das Ram-Interface zu reduzieren und so das Nadelöhr Ram-Interface zu mildern und so womöglich ein 128bit-Interface gar überflüssig machen? Das würde dann nicht nur die Performance von Kabini steigern, sondern Kabini auch einen Kostenvorteil gegenüber Baytrail ermöglichen, zumal Baytrails Die obwohl dem (teureren) 22nm-Prozess fast so groß wie Kabini sein soll.
Nur Kurz: Aus Bandbreitensicht reicht wohl Zero-Copy. HSA ist dann "nur" nett, da es einfacher zu programmieren ist.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Also laut meinen Infos ist Haswell mit Instat Access ausgestattet, das eine Version von Zero Copy ist. Von Ivy wüsste ich nichts... Hast du Quellen dazu?Hab auch irgendwo gelesen, dass Sandy den L3/LLC "nur" hat, um darüber die Daten auszutauschen. Ivy ist jetzt auf dem Zero-Copy stand, also Llano/Trinity-Niveau. Oder ums frustrierender zu formulieren: Sie haben mit AMD gleichgezogen, Kaveri lässt ja auch sich warten
Eine kurze Rcherche hat auch ergeben, dass Intel InstantAccess und PixelSync zwei Intel exklusive DX 11.1 Erweiterungen sind. Somit also auch lediglich Treiberbasierend und abhängig von der Windows Plattform. Ich denke das ist ein völlig anderer Ansatz und kaum vergleichbar mit AMDs Ansatz. Ich bin ehrlich gesagt über diese exklusiven DX 11.1 Features sehr überrascht
http://pixeljudge.com/en/news/intel’s-additional-directx-extensions-for-haswell/
Somit dürften Benchmarks mit Rome 2 und Grid 2 auch nicht mehr als neutral bewertet werden ab Haswell.At GDC 2013 Intel has announced the features supported by iGPUs inside Haswell CPUs, including DirectX 11.1 and two new Intel-exclusive DirectX extensions – Instant Access and PixelSync. Intel has revealed that GRID 2 and Rome 2 will both support these new extensions.
Zuletzt bearbeitet:
Locuza
Commodore Special
- Mitglied seit
- 03.03.2011
- Beiträge
- 351
- Renomée
- 3
Die Erweiterungen sind ja auch eig. nicht offiziell, da DX keine Erweiterungen erlaubt, dass sind zwei extra API Hacks für DX11.Eine kurze Rcherche hat auch ergeben, dass Intel InstantAccess und PixelSync zwei Intel exklusive DX 11.1 Erweiterungen sind. Somit also auch lediglich Treiberbasierend und abhängig von der Windows Plattform. Ich denke das ist ein völlig anderer Ansatz und kaum vergleichbar mit AMDs Ansatz. Ich bin ehrlich gesagt über diese exklusiven DX 11.1 Features sehr überrascht
http://pixeljudge.com/en/news/intel’s-additional-directx-extensions-for-haswell/
Somit dürften Benchmarks mit Rome 2 und Grid 2 auch nicht mehr als neutral bewertet werden ab Haswell.
Interessant wäre es noch zu wissen, wie Grid 2 auf einem Haswell performt, ersichtlich über dem Durchschnitt oder nicht?
Man könnte vielleicht sonst schon einschätzen, wie viel InstantAccess bringen könnte.
Toll wäre es, wenn AMD und Nvidia etwas ähnliches wie PixelSync in ihre ROPs einbauen würden und es dann natürlich offiziellen gemeinsamen DX Support geben würde.
PixelSync scheint dramatisch effizienter zu sein, als OIT per Pixel-Linkend-List gelöst.
Ein Intel Mitarbeiter hat bei B3D gemeint, dass dies allerdings bei AMD und Nvidia vermutlich schwerer zu implantieren sei, als bei ihren GPUs, da ihre Architektur doch deutlicher unterscheidet, als die Lösungen von AMD und Nvidia.
Btw. habe ich so in Erinnerung das Thief APU Anpassungen bekommen sollte, unter Umständen finden sich dort ZeroCopy und bei Kaveri vllt. noch mehr.
Ich meine auch das ganze kam erst ab Haswell.Öhh .. vielleicht wars auch Haswell ... so sicher bin ich mir da jetzt nicht.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Aus selbem LinkPixelSync scheint dramatisch effizienter zu sein, als OIT per Pixel-Linkend-List gelöst.
Ein Intel Mitarbeiter hat bei B3D gemeint, dass dies allerdings bei AMD und Nvidia vermutlich schwerer zu implantieren sei, als bei ihren GPUs, da ihre Architektur doch deutlicher unterscheidet, als die Lösungen von AMD und Nvidia.
PixelSync is more interesting of two when it comes to game graphics. Order Independent Transparency (OIT) is the rendering technology for correctly drawing transparent objects, even in cases when they intersect. DirectX 11 allows implementing OIT, but such implementations are quite heavy on memory and memory bandwidth. Intel's hardware solution uses some clever tricks to reduce the memory requirement, while using OIT, without sacrificing too much accuracy. With PixelSync, enabling OIT in games running on Haswell's iGPU reduces performance by 10%.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
@Opteron
Ich will nicht darüber diskutieren. Complicated sprach ja davon, dass er denke, dass bereits "Llanos Speichercontroller HSA-fähig" ist. Darauf wollte ich nur nochmal Bezug nehmen. Denn laut Spezifikation ist dem auch so. Es wird ein kohärenter gemeinsam genutzter Speicher zwischen LCU und TCU vorgeschrieben. Und das hat Llano, realisiert über das Onion Interface. Was Llano darüber hinaus noch hat bzw haben darf, ist doch völlig belanglos. An der Stelle macht die Spezifikation keine Einschränkungen. Insofern verstehe ich nicht, was es da noch gross zu diskutieren gibt. Das ist eindeutig. Llano ist laut aktueller Spezifikation kompatibel zu HSA.
Ich will nicht darüber diskutieren. Complicated sprach ja davon, dass er denke, dass bereits "Llanos Speichercontroller HSA-fähig" ist. Darauf wollte ich nur nochmal Bezug nehmen. Denn laut Spezifikation ist dem auch so. Es wird ein kohärenter gemeinsam genutzter Speicher zwischen LCU und TCU vorgeschrieben. Und das hat Llano, realisiert über das Onion Interface. Was Llano darüber hinaus noch hat bzw haben darf, ist doch völlig belanglos. An der Stelle macht die Spezifikation keine Einschränkungen. Insofern verstehe ich nicht, was es da noch gross zu diskutieren gibt. Das ist eindeutig. Llano ist laut aktueller Spezifikation kompatibel zu HSA.
Nein. Ein gemeinsam genutzter Speicher und ein gemeinsamer Adressraum sind zwei verschiedene Dinge. Ersteres kann wohl SB, zweites aber definitiv nicht. Etwas vergleichbares zu hUMA soll von Intel meines Wissens erst 2014 oder 2015 kommen.In dem von dir verlinktem Dokument ist doch das Schema für Sandy abgebildet und beschrieben. CPUs, L3, GPU und Memory Controler hängen an einem gemeinsamen RingBus und alle können munter kohärent auf den gemeinsamen Speicher zugreifen. Demnach hat Sandy schon Huma.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Wie wir ja festgestellt haben kann auch erst Haswell InstantAccess (ähnlich ZeroCopy) und das lediglich unter DX 11.1.
Somit wird auch bei Ivy Bridge noch zwischen CPU und GPU Speicher hin und her kopiert.
---------- Beitrag hinzugefügt um 13:43 ---------- Vorheriger Beitrag um 13:40 ----------
Und übrigens gibt es ja auch schon erste Stimmen von Entwicklern die sich darüber beschweren um wie vieles komplizierter das Speichermanagement mit dem ESRAM auf der Xbox sei gegenüber der hUMA Version der PS4. Das dürfte sich auch für die Intel CPUs mit dedizierten onDie RAM auswirken. Wie viele Entwickler werden sich diese Zusatzarbeit machen beim portieren?
Somit wird auch bei Ivy Bridge noch zwischen CPU und GPU Speicher hin und her kopiert.
---------- Beitrag hinzugefügt um 13:43 ---------- Vorheriger Beitrag um 13:40 ----------
Und übrigens gibt es ja auch schon erste Stimmen von Entwicklern die sich darüber beschweren um wie vieles komplizierter das Speichermanagement mit dem ESRAM auf der Xbox sei gegenüber der hUMA Version der PS4. Das dürfte sich auch für die Intel CPUs mit dedizierten onDie RAM auswirken. Wie viele Entwickler werden sich diese Zusatzarbeit machen beim portieren?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Und ich verstehe nicht, wie Du im Kontext von:Insofern verstehe ich nicht, was es da noch gross zu diskutieren gibt. Das ist eindeutig. Llano ist laut aktueller Spezifikation kompatibel zu HSA.
Von einer vermeintlichen Kohärenz sprechen willst? Ich sehe da nicht mal 1% Spielraum zur HSA-kompatibilität von LLano. Naja, immerhin haben wir unsere verschiedenen Standpunkte diesmal dann ohne großes Herumgerede gefunden.so is a non coherent bus
Halten für die Zukunft fest: Für Dich ist Llano HSA-kompatibel, für mich nicht.
@Complicated:
Bei Intel funktioniert das EDRAM als Cache ... hat also keine eigenen Adressen, das sollte dann kein Problem sein.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Alos ich würde gerne noch mal wissen an welcher Stelle du diesen Satz im Paper gefunden hast. Zwischen einem nicht kohärenten Bus und kohärentem Speicher besteht meines wissens ein Unterschied. Vor allem da Llano einen Bus für kohärente Zugriffe (Onion) und einen Bus für nicht-kohärente Zugriffe (Garlic) besitzt die unabhängig vom normalen SI-Interface agieren. Ich denke hier ist der Zusammenhang im Paper entscheidend und was dort genau beschrieben wird. Übrigens gibt es auch mit hUMA nach wie vor nicht-kohärente Speicherbereiche und Zugriffe die aber von der Software definiert werden können.
---------- Beitrag hinzugefügt um 16:04 ---------- Vorheriger Beitrag um 15:57 ----------
Ich finde die Folien verwirrend. Da ist LLC (Last Level Cache) am Ringbus angeschlossen und dann danach noch ein Level 4 Cache bei GT3, der ja dann eher der Last Level wäre.
Gibt es da ein Paper oder eine Beschreibung? Und was soll das bitte für Performance Vorteile bringen? Ein vierter gemeinsamer Cachelevel für GPU und CPU unterscheidet sich nun genau worin von dem RAM den die Xbox verwendet?@Complicated:
Bei Intel funktioniert das EDRAM als Cache ... hat also keine eigenen Adressen, das sollte dann kein Problem sein.
---------- Beitrag hinzugefügt um 16:04 ---------- Vorheriger Beitrag um 15:57 ----------
Ich finde die Folien verwirrend. Da ist LLC (Last Level Cache) am Ringbus angeschlossen und dann danach noch ein Level 4 Cache bei GT3, der ja dann eher der Last Level wäre.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Die Quelle hatte ich doch im Kabinithread angegeben.Alos ich würde gerne noch mal wissen an welcher Stelle du diesen Satz im Paper gefunden hast. Zwischen einem nicht kohärenten Bus und kohärentem Speicher besteht meines wissens ein Unterschied. Vor allem da Llano einen Bus für kohärente Zugriffe (Onion) und einen Bus für nicht-kohärente Zugriffe (Garlic) besitzt die unabhängig vom normalen SI-Interface agieren. Ich denke hier ist der Zusammenhang im Paper entscheidend und was dort genau beschrieben wird.
Hab jetzt mal nochmal über den Satz hier "meditiert":
A heterogeneous hardware platform that integrates both LCUs and TCUs, which operate coherently in shared memory.
Ich glaub ich kenn jetzt unsere verschiedene Auffassung. Ihr versteht das "shared memory" also irgendein Speicherbereich, wenns da irgendwo ein paar MB gibt, wo beide kohärent zugreifen können, dann seht Ihr die Bedingung als erfüllt an. Ich versteh das dagegen allgemeiner als einen einzigen, großen, gemeinsam benutzten & (normalerweise) kohärenten Speicher. Wenn es dann Softwarebefehle gibt, die auch non-coherent zulassen, würde ich das nicht als Problem sehen, der Default ist ja kohärent sein.
Aber ich geb jetzt zu, dass mans auch so sehen kann, dass Llano HSA ist. Ich würde dann zwar im Englischen schreiben "which operate coherently in a shared memory area." Aber so genau sieht das der schlampige PDF-Schreiber sicherlich nicht.
@LLC/L4:
Ja ist zimelich "witzig", einerseits LLC, andrerseits nochmal ne Cachestufe außerhalb ^^
Aber wie besagt, das ist Cache, da brauchts keine extra Adressen, das ist der Unterschied zur XBOX.
Locuza
Commodore Special
- Mitglied seit
- 03.03.2011
- Beiträge
- 351
- Renomée
- 3
Man kann es zwar nicht direkt mit Laras Haaren vergleichen, aber bei Tomb Raider sieht man wie sehr so etwas reinhaut.Aus selbem Link
Minus 30% Performance Verlust.
Aber das hat jetzt nichts mit APUs im direktem Sinne zu tun.
Was bedeutet denn eig. "HSA fähig"?Ich will nicht darüber diskutieren. Complicated sprach ja davon, dass er denke, dass bereits "Llanos Speichercontroller HSA-fähig" ist.
Wie halt auch bei jeder AMD APU eig. auch geschehen sollte.Wie wir ja festgestellt haben kann auch erst Haswell InstantAccess (ähnlich ZeroCopy) und das lediglich unter DX 11.1.
Somit wird auch bei Ivy Bridge noch zwischen CPU und GPU Speicher hin und her kopiert.
Ich vermute eher das es für ZeroCopy genauso spezielle Anpassungen geben muss, da oben stand ja irgendetwas das AMD schon eine OCL-Erweiterung für Windows hat, fragt sich nur welche Modis es genau gibt und was Llano automatisch per Hardware löst und wozu er prinzipiell in der Lage wäre, aber nur mit passender Software Unterstützung.
Intels eDRAM cached automatisch die Daten. Ich meine Intel erlaubt eh keine direkte Software-Anpassung davon, da laut Analyse ihre Hardwarelösung in den meisten Fällen immer von Vorteil ist.Und übrigens gibt es ja auch schon erste Stimmen von Entwicklern die sich darüber beschweren um wie vieles komplizierter das Speichermanagement mit dem ESRAM auf der Xbox sei gegenüber der hUMA Version der PS4. Das dürfte sich auch für die Intel CPUs mit dedizierten onDie RAM auswirken. Wie viele Entwickler werden sich diese Zusatzarbeit machen beim portieren?
Intel hat beim eDRAM einen automatischen Cache Mechanismus, welcher CPU und GPU Anfragen cached.Gibt es da ein Paper oder eine Beschreibung? Und was soll das bitte für Performance Vorteile bringen? Ein vierter gemeinsamer Cachelevel für GPU und CPU unterscheidet sich nun genau worin von dem RAM den die Xbox verwendet?
Bei der Xbox One ist der eSRAM ein per Software verwaltetes Scratchpad und auch wenn da so ein schwarzer kleiner Pfeil zur CPU führt, der leider nicht beschriftet ist, ist dieser primär nur für die GPU gedacht.
http://en.wikipedia.org/wiki/Scratchpad_memory
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Sry, aber damit liegst du falsch. Wenn wir von Speicher sprechen, geht es natürlich um Speicherbereiche, nicht um den kompletten physischen Speicher. Dass ein Speicherbereich den kompletten physischen Speicher umfasst, ist lediglich ein Sonderfall, nicht obligatorisch.Ich glaub ich kenn jetzt unsere verschiedene Auffassung. Ihr versteht das "shared memory" also irgendein Speicherbereich, wenns da irgendwo ein paar MB gibt, wo beide kohärent zugreifen können, dann seht Ihr die Bedingung als erfüllt an. Ich versteh das dagegen allgemeiner als einen einzigen, großen, gemeinsam benutzten & (normalerweise) kohärenten Speicher.
Davon hat keiner gesprochen und darum geht es auch gar nicht. Was dein ständiges Rumreiten auf Garlic an der Stelle soll, ist unverständlich. Wenn jemand von CPU Performance spricht, würdest du doch auch nicht dauernd mit irgendwelchen Vergleichen der iGPU kommen. Es geht um den kohärenten Bus, also Onion. Es geht NICHT um Garlic.Und ich verstehe nicht, wie Du im Kontext von:
Übrigens, wenn du das HSA Paper mal sorgfältig durchlesen würdest, würde dir auch noch folgendes auffallen:
The coherent memory heap is the default heap on HSA and is always
present. Implementations may also provide a non-coherent heap for advance programmers to request
when they know there is no sharing between processor types.
Dazu auch extra nochmal die Übersicht einer HSA Plattform, die das gut verdeutlicht:

Das erzähle ich hier nun schon seit einigen Seiten. Da kann es gar keine unterschiedlichen Standpunkte geben. Das ist mehr als eindeutig. Kein Ahnung, was du hier beweisen willst. Aber du hörst dich total bockig an. Wieder mal, obwohl du weisst, dass es andere eigentlich besser wissen sollten.
 David Kanter hat in seinem Artikel ja auch geschrieben, warum neben dem kohärenten Speicher auch weiterhin ein nicht kohärenter Speicher genutzt wird:
David Kanter hat in seinem Artikel ja auch geschrieben, warum neben dem kohärenten Speicher auch weiterhin ein nicht kohärenter Speicher genutzt wird:However, it is substantially faster than accessing cacheable shared memory, since there is no coherency overhead.
Auch das hatte ich zuvor schon mal erwähnt. Deshalb ist es wahrscheinlich, dass auch zukünftige APUs weiterhin auf nicht kohärenten Speicher an den Stellen setzen werden, wo Kohärenz nicht notwendig ist, Performance aber kritisch sein kann.
Ich fasse also extra für dich nochmal zusammen. Ein kohärenter gemeinsam genutzter Speicher ist zwingend erforderlich für HSA. Ein zusätzlicher nicht kohärenter Speicher ist optional. Llano hat beides und ist damit zu HSA kompatibel! Ende der Debatte.
Nennen wir es besser "HSA kompatibel". Das hatte ich im anderen Thread schon mal gepostet:Was bedeutet denn eig. "HSA fähig"?
1.5. Implementation Components
An HSA implementation is a system that passes the HSA Compliance Test Suite. It consists of:
• A heterogeneous hardware platform that integrates both LCUs and TCUs, which operate coherently in shared memory.
• A software compilation stack consisting of a compiler, linker and loader.
• A user-space runtime system, which also includes debugging and profiling capabilities.
• Kernel-space system components.
Für ausführlichere Infos kannst du dir das HSA PDF bei AMD kostenlos runterladen.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Tut mir leid, aber da bist Du auf dem Holzweg, es ist wichtig, dass es *ein* Speicher ist, das zielt auf die gemeinsamen Adressen ab, da es auch nur einen Speicherkontroller gibt. Das sieht man auch in Deinem schönen Bild, da ist nur *eine* HMMU, kein Onion, kein Garlic, keine extra GPU-MMU, nix außer der HMMU.Sry, aber damit liegst du falsch. Wenn wir von Speicher sprechen, geht es natürlich um Speicherbereiche, nicht um den kompletten physischen Speicher. Dass ein Speicherbereich den kompletten physischen Speicher umfasst, ist lediglich ein Sonderfall, nicht obligatorisch.
Wichtige Bilder in dem Kontext sind diese hier:
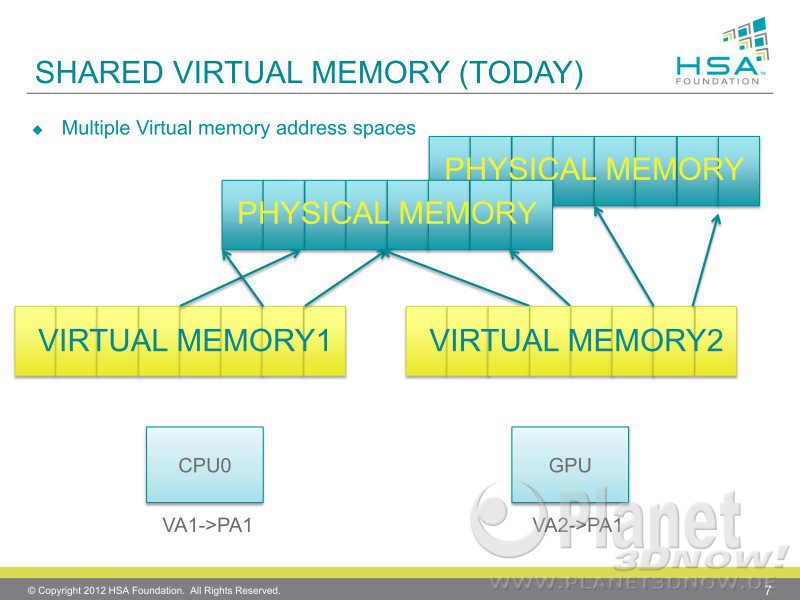
Als Datum steht "today" da, ergo sind das alle Chips bisher bis Richland.
Das HSA-Speichermodell sieht aber so aus:
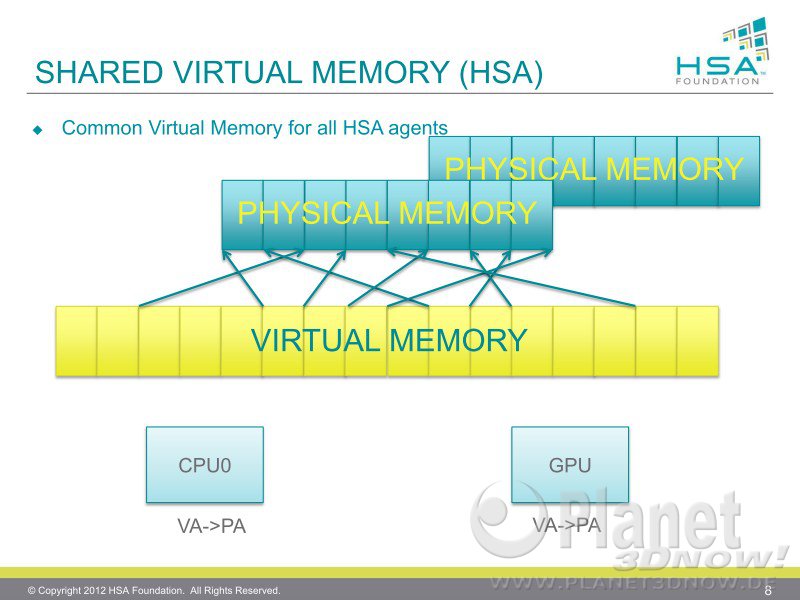
EIN virtueller Speicher und EIN physikalischer Speicher. Steht auch in dem PDF, aus dem Du Dein Schaubild hast klipp und klar:
Coherent memory regions.
In traditional GPU devices, even when the CPU and GPU are using the
same system memory region, the GPU uses a separate address space from the CPU, and the graphics
driver must flush and invalidate GPU caches at required intervals in order for the CPU and GPU to
share results. HSA embraces a fully coherent shared memory model, with unified addressing. This
provides programmers with the same coherent memory model that they enjoy on SMP CPU systems.
This enables developers to write applications that closely couple LCU and TCU codes in popular design
patterns like producer-consumer. The coherent memory heap is the default heap on HSA and is always
present. Implementations may also provide a non-coherent heap for advance programmers to request
when they know there is no sharing between processor types.
Oder auch hier:
HSA erlaubt das, Llano kann das nicht.Shared page table support.
To simplify OS and user software, HSA allows a single set of page table
entries to be shared between LCUs and TCUs. This allows units of both types to access memory
through the same virtual address. The system is further simplified in that the operating system only
needs to manage one set of page tables. This enables Shared Virtual Memory (SVM) semantics
between LCU and TCU.
Richtig, da hast Du mich jetzt überzeugt.Ich fasse also extra für dich nochmal zusammen. Ein kohärenter gemeinsam genutzter Speicher ist zwingend erforderlich für HSA. Ein zusätzlicher nicht kohärenter Speicher ist optional.
Falsch, da Llano nicht einen, sondern 2 Speicherbereiche hat, System Memory und Local Memory hieß das früher mal, in Deinem HSA-Schaubild gibts aber nur einen Block System Memory...Llano hat beides und ist damit zu HSA kompatibel!
JaEnde der Kohärenz-Debatte.
")
NeinEnde der LLno-ist-HSA-kompatibel-Debatte.
(Also aus meiner Sicht ja, wenn man sich den Kontext des Satzes anschaut, also das ganze HSA-PDF in dem der Satz gebraucht wird, muss man zu dem Schluss kommen, dass Llano ganz sicher nicht HSA-kompatibel ist. Aber Du willst sicher noch einen Kommentar dazu abgeben )Schick doch gleich den Link mit:Für ausführlichere Infos kannst du dir das HSA PDF bei AMD kostenlos runterladen.
Heterogeneous-System-Architecture: A Technical Review.pdf.
P.S:
Zum "bockig" und dem folgendem Grinsekommentar: Mir wärs ehrlich gesagt lieber wenn wir auf der Sachebene blieben. Denk mal drüber nach, wie ich Dich jetzt verhöhen und mich über Dein fehlendes Wissen zum HSA-Speichermodell lustig machen könnte ...
Pirx
Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 1.234
- Renomée
- 11
- Standort
- Mädels auf Bäumen wachsen
- Mein Laptop
- Samsung NC20
- Details zu meinem Desktop
Wie wird eigentlich das Betriebssystem damit klarkommen, wenn es plötzlich ja eigentlich keine richtige Grafikkarte mit soundsoviel "VRAM" gibt, sondern nur noch eine APU?
Markus Everson
Grand Admiral Special
http://amddevcentral.com/afds/assets/presentations/1004_final.pdf -> Seite 8
Sieht aus als ob Opteron näher dran ist. Aber was sagt mir das in Bezug auf Kaveri, wenn jede APU-Inkarnation vor dem Erscheinen als das Non-plus-Ultra, das Ein-und-Alles, das Ende aller Integrationsprobleme von CPU und GPU und überhaupt als das Beste seit geschnittenem Brot vorgestellt wird ...und sich im Nachhinein als dann doch wieder eher halbherziger Rohrkrepierer entpuppt mit der Option das sein Nachfolger aber dann nun wirklich...?
Gerade gelesen "HSA wird erst mit Open CL 2.0 so richtig durchstarten". Sollten Kunden also lieber erst mal zu leistungsfähigen CPUs greifen und dann in zwei bis x Jahren nochmal bei AMD vorbei schauen um zu sehen ob die dann allmählich 10 Jahre alten Versprechungen noch eingelöst werden?
Sieht aus als ob Opteron näher dran ist. Aber was sagt mir das in Bezug auf Kaveri, wenn jede APU-Inkarnation vor dem Erscheinen als das Non-plus-Ultra, das Ein-und-Alles, das Ende aller Integrationsprobleme von CPU und GPU und überhaupt als das Beste seit geschnittenem Brot vorgestellt wird ...und sich im Nachhinein als dann doch wieder eher halbherziger Rohrkrepierer entpuppt mit der Option das sein Nachfolger aber dann nun wirklich...?
Gerade gelesen "HSA wird erst mit Open CL 2.0 so richtig durchstarten". Sollten Kunden also lieber erst mal zu leistungsfähigen CPUs greifen und dann in zwei bis x Jahren nochmal bei AMD vorbei schauen um zu sehen ob die dann allmählich 10 Jahre alten Versprechungen noch eingelöst werden?
Zuletzt bearbeitet:
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
@Pirx
So wie das Betriebssystem auch damit klar kommt, dass mehr als ein Kern vorhanden ist die auf den physikalischen Speicher zugreift.
Beim initialisieren reservieren sich der Grafiktreiber eine gewünschte Speichermenge, der Rest wird dynamisch von den Threads auf den Kernen und der GPU genutzt.
So wie das Betriebssystem auch damit klar kommt, dass mehr als ein Kern vorhanden ist die auf den physikalischen Speicher zugreift.
Beim initialisieren reservieren sich der Grafiktreiber eine gewünschte Speichermenge, der Rest wird dynamisch von den Threads auf den Kernen und der GPU genutzt.
mariahellwig
Grand Admiral Special
http://amddevcentral.com/afds/assets/presentations/1004_final.pdf -> Seite 8
Gerade gelesen "HSA wird erst mit Open CL 2.0 so richtig durchstarten". Sollten Kunden also lieber erst mal zu leistungsfähigen CPUs greifen und dann in zwei bis x Jahren nochmal bei AMD vorbei schauen um zu sehen ob die dann allmählich 10 Jahre alten Versprechungen noch eingelöst werden?
10 Jahre wird es nicht dauern, aber vermutlich bis Mitte nächsten Jahres schon. Anfang 2014 die finale Spezifikation und weitere 6 Monate später die Umsetzung seitens AMD.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Gerade gelesen "HSA wird erst mit Open CL 2.0 so richtig durchstarten". Sollten Kunden also lieber erst mal zu leistungsfähigen CPUs greifen und dann in zwei bis x Jahren nochmal bei AMD vorbei schauen um zu sehen ob die dann allmählich 10 Jahre alten Versprechungen noch eingelöst werden?
Nein natürlich nicht. Du musst jetzt sparen, dann zum Kaveri-Start (ist bald, die Schwalben fliegen tief und der letzte Neumond hatte einen milchigen Schleier) mindestens 2 pfeilschnelle Kaveri-Systeme kaufen und noch eine Reserve-CPU ins Regal legen und dann in 2 Jahren, wenn die Superdupersoftware rauskommt, dann wirste krass in den Sitz gepresst!!! (Dank Gestenerkennung und Körperscanner über WEbcam wird dir das "AMD-Siri-Programm" anschließend wg. Deiner verkrapften Sitzhaltung den Gang zum Klo empfehlen.
 )
)Ne im Ernst .. ist immer so Hardware ist nur so gut wie die Software, die sie nützt und da haben wir immer das Henne-Ei-Problem. Damals bei 3dnow wars halt sch...lecht, jetzt mit HSA siehts besser aus, ARM ist mit im Boot und OpenCL schaut auch gut aus, da ist intel auch dabei.
Voll nutzen wird man HSA so schnell aber nicht können, da muss erst noch Software geschrieben werden. Hoffentlich gibts da nen PS4-Effekt. Wenn sich das rumspricht, dass es gut zu programmieren ist und am Ende viel Rechenleistung übrig bleibt, könnte der HSA-Stein ins Rollen kommen und Fahrt aufnehmen
Bis dahin muss man hoffen, dass Kaveri genug IPC-Kohlen nachlegt und auch bei aktueller Wald&Wiesen-Software gut ausschaut.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Der PS4 Efekt könnte vor allem darin bestehen, dass gute Tools und Libraries verfügbar werden. Hoffe ich zumindest.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Es ist ja auch ein Speicher innerhalb des selben Speicherbereiches. Es wird trotzdem nicht vorgeschrieben, dass sämtliche Speicherbereiche kohärent sein müssen. Da bist du auf dem Holzweg.es ist wichtig, dass es *ein* Speicher ist
Nein, du interpretierst einfach falsch. HMMU steht hier lediglich als Platzhalter. Sozusagen eine Art Black Box. Der konkrete Aufbau wird nicht vorgeschrieben. Sowas wird dann idR als "implementationsspezifisch" in solchen Dokumenten bezeichnet. Und natürlich kann die Implementierung etwas wie Onion und Garlic in Llano sein.Das sieht man auch in Deinem schönen Bild, da ist nur *eine* HMMU, kein Onion, kein Garlic, keine extra GPU-MMU, nix außer der HMMU.
Die Formulierungen sind eindeutig und sagen überhaupt nichts davon, dass dies vorgeschrieben wird. Was genau verstehst du denn an Begriffen wie "embraces" oder "allows" nicht? Das sind von HSA unterstützte Features, die in ihrer Funktionsweise dann auch näher spezifiziert werden können. Diese werden HSA kompatiblen Plattformen aber nicht vorgeschrieben. ZB ein gemeinsamer Adressraum ist ein von HSA forciertes Feature, aber keine Grundvoraussetzung für HSA Kompatibilität. Das kann sich in Zukunft mit neuen Spezifikationen vielleicht mal ändern. Im Moment ist es aber so wie es ist.Steht auch in dem PDF, aus dem Du Dein Schaubild hast klipp und klar:
Oder auch hier:
Ich sehe da aber zwei klar voneinander getrennte Blöcke, einen kohärenten und einen nicht kohärenten Bereich. Und genau das ist das, was die HSA Spezifikation auch beschreibt. Deine Folien sind dafür belanglos. Diese zeigen ja lediglich den kohärenten Bereich. Innerhalb dieses kohärenten Bereiches darf es natürlich nur einen gemeinsamen Speicher geben. Genau das wird bei Llano mittels Onion auch sichergestellt. Deshalb ist Llano auch HSA kompatibel.in Deinem HSA-Schaubild gibts aber nur einen Block System Memory...
Altes Fusion Dokument. Tut hier nichts zur Sache. Auf Seite 8 steht auch nur so viel wie, Llano besitzt zwei Speicherbereiche, einen kohärenten und einen nicht kohärenten. So wie es das HSA Paper auch beschreibt. Also keine Neuigkeiten.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 180
- Antworten
- 11
- Aufrufe
- 785
- Antworten
- 30
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 148
- Antworten
- 44
- Aufrufe
- 1K