App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Alles rund um Compiler und Softwareentwicklung
- Ersteller gruffi
- Erstellt am
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Damit die anderen Threads nicht noch weiter geshreddert werden, mach ich mal hier einen neuen auf, wo weiterdiskutiert werden kann.
Zum Thema ICC, und um mit dem Ammenmärchen aufzuräumen, dass der auch für AMD immer der schnellste wäre. Da LAME und ähnliche Encoder gerne in Reviews verwendet werden, habe ich LAME mal durch den aktuellen GCC 4.9.0 (MinGW 64-bit) gejagt, -march/mtune auf native, also für meinem Llano X4 optimiert. Ergebnis, ~15% schneller als der aktuelle ICC 14 Build von rarewares. Der MinGW Build läuft selbst auf meinem Core2 Notebook noch etwas schneller als der ICC Build. Allerdings sind dort die Unterschiede erwartungsgemäss deutlich geringer.
ICC

GCC (MinGW)

MinGW 4.9.2 Builds
K10 (amdfam10):
http://www.file-upload.net/download-10070595/lame_mingw_4.9.2_x86_64_amdfam10.7z.html
Llano (native):
http://www.file-upload.net/download-10070599/lame_mingw_4.9.2_x86_64_llano_native.7z.html
Vishera / Trinity / Richland (bdver2):
http://www.file-upload.net/download-10070594/lame_mingw_4.9.2_x86_64_bdver2.7z.html
Kaveri (bdver3)
http://www.file-upload.net/download-10073768/lame_mingw_4.9.2_x86_64_bdver3.7z.html
Sandy Bridge (sandybridge):
http://www.file-upload.net/download-10070598/lame_mingw_4.9.2_x86_64_sandybridge.7z.html
Haswell (haswell):
http://www.file-upload.net/download-10070592/lame_mingw_4.9.2_x86_64_haswell.7z.html
Falls gewünscht, kann ich auch noch MinGW Builds für andere Prozessoren hochladen.
Liste bekannter bzw nützlicher kostenfreier Software für Entwicklung und Benchmarken:
Cinebench
POV-Ray
Stand: 08.06.2014
Verhaltensregeln:
Ich bitte alle hier sachlich zu bleiben und konstruktive Beiträge zu verfassen. Sinnvolle Spekulationen, Fakten, Fragen, Vorschläge, Tests, Kritik, ist alles erwünscht. Leute, die das zusammengetragene Material ständig mit Erkenntnisresistenz torpedieren und nichts sinnvolles beitragen, sind hier unerwünscht.
Zum Thema ICC, und um mit dem Ammenmärchen aufzuräumen, dass der auch für AMD immer der schnellste wäre. Da LAME und ähnliche Encoder gerne in Reviews verwendet werden, habe ich LAME mal durch den aktuellen GCC 4.9.0 (MinGW 64-bit) gejagt, -march/mtune auf native, also für meinem Llano X4 optimiert. Ergebnis, ~15% schneller als der aktuelle ICC 14 Build von rarewares. Der MinGW Build läuft selbst auf meinem Core2 Notebook noch etwas schneller als der ICC Build. Allerdings sind dort die Unterschiede erwartungsgemäss deutlich geringer.
ICC

GCC (MinGW)

MinGW 4.9.2 Builds
K10 (amdfam10):
http://www.file-upload.net/download-10070595/lame_mingw_4.9.2_x86_64_amdfam10.7z.html
Llano (native):
http://www.file-upload.net/download-10070599/lame_mingw_4.9.2_x86_64_llano_native.7z.html
Vishera / Trinity / Richland (bdver2):
http://www.file-upload.net/download-10070594/lame_mingw_4.9.2_x86_64_bdver2.7z.html
Kaveri (bdver3)
http://www.file-upload.net/download-10073768/lame_mingw_4.9.2_x86_64_bdver3.7z.html
Sandy Bridge (sandybridge):
http://www.file-upload.net/download-10070598/lame_mingw_4.9.2_x86_64_sandybridge.7z.html
Haswell (haswell):
http://www.file-upload.net/download-10070592/lame_mingw_4.9.2_x86_64_haswell.7z.html
Falls gewünscht, kann ich auch noch MinGW Builds für andere Prozessoren hochladen.
Liste bekannter bzw nützlicher kostenfreier Software für Entwicklung und Benchmarken:
Cinebench
Benchmark für 3D-Rendering - Webseite
Code::BlocksMultiplattform Entwicklungsumgebung (unterstützt etliche Compiler, Open Source) - Webseite
CPU-ZInfotool für wichtige Systemkomponenten - Webseite (Cache Latency Tool)
GPU-ZInfotool für Grafikprozessoren - Webseite
Hyper PiPi-Berechnung (Super Pi integriert) - Webseite
LAMEMP3 Audio Encoder (Open Source) - Webseite
MinGWPOV-Ray
Raytracer (Benchmark integriert, Open Source) - Webseite
RightMark Memory AnalyzerAnalysetool für Cache oder RAM (Open Source) - Webseite
System Stability TesterBenchmark und Stresstester mittels Pi-Berechnung - Webseite
Visual Studio ExpressEntwicklungsumgebung von Microsoft - Webseite
x264H.264 Video Encoder (Open Source) - Webseite
x265H.265 Video Encoder (Open Source) - Webseite
y-cruncherBenchmark und Stresstester mittels Berechnung diverser mathematischer Konstanten - Webseite
Stand: 08.06.2014
Verhaltensregeln:
Ich bitte alle hier sachlich zu bleiben und konstruktive Beiträge zu verfassen. Sinnvolle Spekulationen, Fakten, Fragen, Vorschläge, Tests, Kritik, ist alles erwünscht. Leute, die das zusammengetragene Material ständig mit Erkenntnisresistenz torpedieren und nichts sinnvolles beitragen, sind hier unerwünscht.
Zuletzt bearbeitet:
Unbekannter Krieger
Grand Admiral Special
- Mitglied seit
- 04.10.2013
- Beiträge
- 4.606
- Renomée
- 119
- Mein Laptop
- HP 15-bq102ng (sackteuer u. ab Werk instabil)
- Details zu meinem Desktop
- Prozessor
- FX-8320E@4,2 GHz & 2,6 GHz Northbridge (jeweils mit UV)
- Mainboard
- Asus M5A99X Evo R2.0 (eher enttäuschend ggü. ASRock E3)
- Kühlung
- Raijintek Nemesis (Lüfter mittig im sowie hinter dem Kühler; erstklassig)
- Speicher
- 4x4 GiB Hynix DDR3-1866 ECC
- Grafikprozessor
- XFX RX 570 8G (P8DFD6)@1180 & 2150 MHz@starkem, fortdauerndem UV | ASRock RX 570 8G@das Gleiche
- Display
- BenQ XL2411T ~ nach 3 RMAs und 6 Monaten wieder brauchbar
- SSD
- Crucial MX100 256 GB (ein Glückskauf) | SanDisk Ultra Plus 256 GB (ein Glückskauf)
- HDD
- WD20EZRZ u. a. (Seagate, Hitachi, WD)
- Optisches Laufwerk
- TSST SH-222AL
- Gehäuse
- Corsair Carbide 300R (ein Fehlkauf)
- Netzteil
- CoolerMaster V450S (ein Glückskauf)
- Betriebssystem
- Win8.x x64, Win7 x64
- Webbrowser
- welche mit minimalem Marktanteil & sinnvollen Konzepten (nicht Chrome-Seuche und Sieche-Fuchs)
- Verschiedenes
- frühere GPUs: , Asus RX 480 O8G@580 O8G, VTX3D 7850 1G
Hallo!
Ich hätte Interesse an einem FX-8350-optimierten LAME. Da ich kein Fan von Kommandozeilen bin, nutze ich bislang WinLAME. Es scheint mir nicht, als könne man die LAME-Komponente einfach austauschen.
Kennst du zufällig eine GUI für LAME, die ich alternativ verwenden könnte und die den Austausch von LAME ermöglicht?
Ich hätte Interesse an einem FX-8350-optimierten LAME. Da ich kein Fan von Kommandozeilen bin, nutze ich bislang WinLAME. Es scheint mir nicht, als könne man die LAME-Komponente einfach austauschen.
Kennst du zufällig eine GUI für LAME, die ich alternativ verwenden könnte und die den Austausch von LAME ermöglicht?
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Vielleicht LameXP? Ich kenne WinLAME ehrlich gesagt nicht. Kann dir daher auch nicht sagen, was funktionell vergleichbar ist. Früher habe ich immer CDex genutzt. Das hat aber schon seit längerem kein Update mehr gesehen. RazorLame gäbe es auch noch. Einfach mal nach "LAME Frontend" oder ähnlichem suchen. Da wird man einiges finden.
Ein Piledriver Build sollte kein Problem sein. Mal schauen, ob ich den noch heute Abend hochladen kann.
Ein Piledriver Build sollte kein Problem sein. Mal schauen, ob ich den noch heute Abend hochladen kann.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.262
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@gruffi
Kannst du dazu evt. was sagen:

Patched läuft es reproduzierbar schneller, jedoch in der Messtoleranz.
Kannst du dazu evt. was sagen:
Patched läuft es reproduzierbar schneller, jedoch in der Messtoleranz.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.262
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ok, ich hab es jetzt 3x mal in einer Windows Sitzung laufen lassen, die Toleranz geht gegen +/- 3 Pkt.
Sonst hätte ich den I7-4770K nicht "überholen" können:
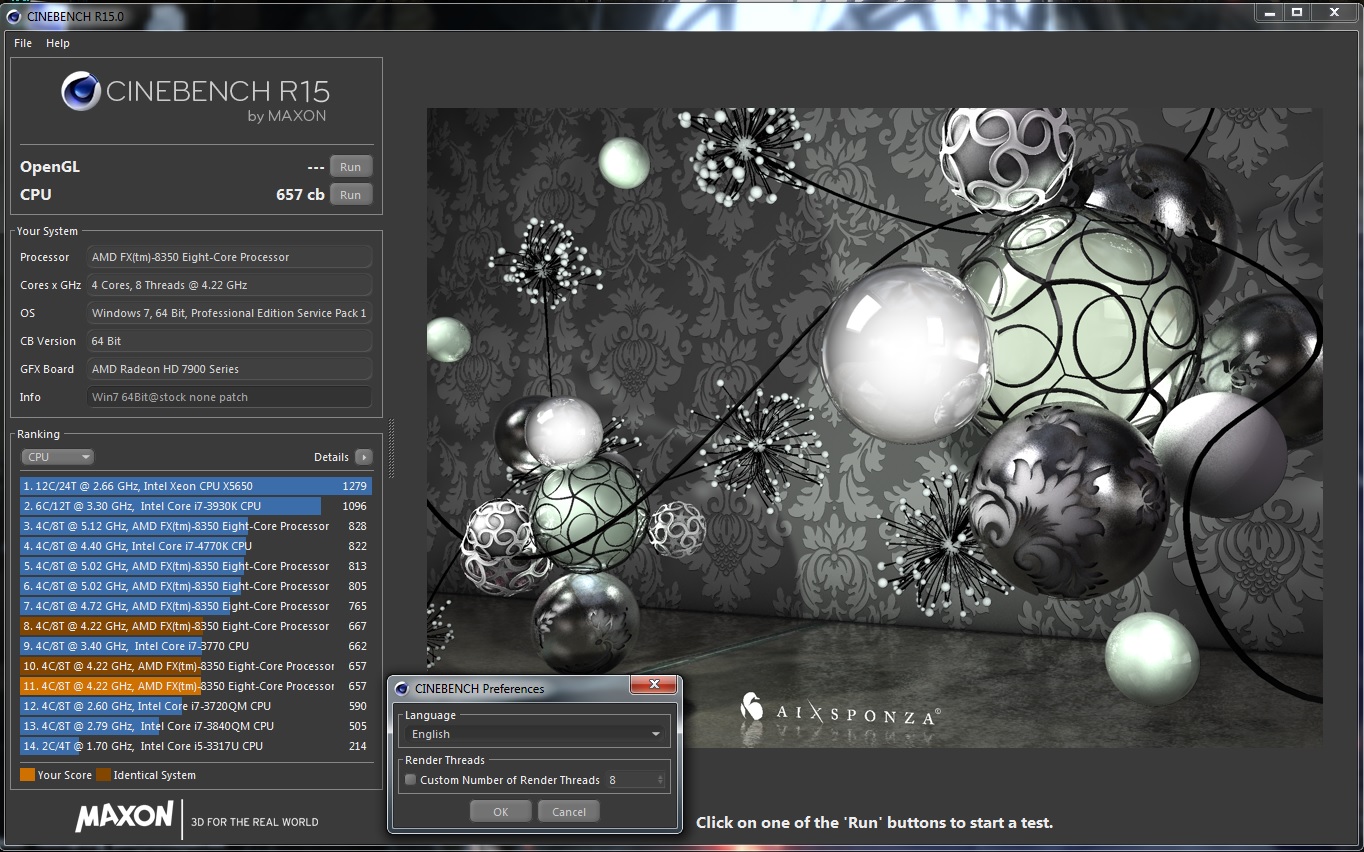
Sonst hätte ich den I7-4770K nicht "überholen" können:
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
LAME für bdver2 und bdver3 steht im Startbeitrag zur Verfügung.
 Auch wenn man es nach wie vor noch nicht völlig ausschliessen kann. Die starke Intel Optimierung in Cinebench liesse sich halt nur mit einer Neukompilierung lösen, am besten mit einem neutralen Compiler. Das wird aber so schnell nicht passieren.
Auch wenn man es nach wie vor noch nicht völlig ausschliessen kann. Die starke Intel Optimierung in Cinebench liesse sich halt nur mit einer Neukompilierung lösen, am besten mit einem neutralen Compiler. Das wird aber so schnell nicht passieren.
Den Patcher kenne ich nicht. Ich würde mir von solchen Sachen aber nicht mehr allzu viel versprechen. Cinebench R15 ist ja noch nicht so alt. Da sollte also eine relativ aktuelle Version des Intel Compilers zum Einsatz kommen. Und Intel scheint bei neueren Versionen nichts beeinträchtigendes mehr mit der CPUID Herstellerkennung anzustellen. Oder formulieren wir es anders. Aufgrund der Auflagen der FTC machen sie es zumindest nicht mehr so offensichtlich.@gruffi
Kannst du dazu evt. was sagen:
Auch wenn man es nach wie vor noch nicht völlig ausschliessen kann. Die starke Intel Optimierung in Cinebench liesse sich halt nur mit einer Neukompilierung lösen, am besten mit einem neutralen Compiler. Das wird aber so schnell nicht passieren.
Zuletzt bearbeitet:
Unbekannter Krieger
Grand Admiral Special
- Mitglied seit
- 04.10.2013
- Beiträge
- 4.606
- Renomée
- 119
- Mein Laptop
- HP 15-bq102ng (sackteuer u. ab Werk instabil)
- Details zu meinem Desktop
- Prozessor
- FX-8320E@4,2 GHz & 2,6 GHz Northbridge (jeweils mit UV)
- Mainboard
- Asus M5A99X Evo R2.0 (eher enttäuschend ggü. ASRock E3)
- Kühlung
- Raijintek Nemesis (Lüfter mittig im sowie hinter dem Kühler; erstklassig)
- Speicher
- 4x4 GiB Hynix DDR3-1866 ECC
- Grafikprozessor
- XFX RX 570 8G (P8DFD6)@1180 & 2150 MHz@starkem, fortdauerndem UV | ASRock RX 570 8G@das Gleiche
- Display
- BenQ XL2411T ~ nach 3 RMAs und 6 Monaten wieder brauchbar
- SSD
- Crucial MX100 256 GB (ein Glückskauf) | SanDisk Ultra Plus 256 GB (ein Glückskauf)
- HDD
- WD20EZRZ u. a. (Seagate, Hitachi, WD)
- Optisches Laufwerk
- TSST SH-222AL
- Gehäuse
- Corsair Carbide 300R (ein Fehlkauf)
- Netzteil
- CoolerMaster V450S (ein Glückskauf)
- Betriebssystem
- Win8.x x64, Win7 x64
- Webbrowser
- welche mit minimalem Marktanteil & sinnvollen Konzepten (nicht Chrome-Seuche und Sieche-Fuchs)
- Verschiedenes
- frühere GPUs: , Asus RX 480 O8G@580 O8G, VTX3D 7850 1G
@gruffi
http://winlame.sourceforge.net/index.php
Mein winLAME-Installationsverzeichnis sieht so aus:

@all
Tarnung eines Intels als AMD und umgekehrt für Compilertestzwecke
Ich würde es gern selbst testen, doch laut HWInfo64 ist AMD-V (Virtualisierung) bei mir "disabled", obwohl "supported".
Im BIOS ist "Secure Virtual Machine" aktiviert. Es wird ein Fehler oder eine Einstellung im OS sein. Oder ein Anzeigefehler.
Selbst falls ich VMs zum Laufen bekäme, müsste ich nur für den Test eine einrichten.
Zumindest wird Virtualisierung für den Test benötigt, zudem VMWare (andere VM wird wohl auch gehen).
Für die genaue (kurze!) Anleitung, siehe Beitrag #43 hier
http://www.techpowerup.com/forums/t...courtesy-the-stilt.186056/page-2#post-2927933
@WindHund
Du meintest einen 3770k, nicht einen 4770k, oder?
http://winlame.sourceforge.net/index.php
Mein winLAME-Installationsverzeichnis sieht so aus:
@all
Tarnung eines Intels als AMD und umgekehrt für Compilertestzwecke
Ich würde es gern selbst testen, doch laut HWInfo64 ist AMD-V (Virtualisierung) bei mir "disabled", obwohl "supported".
Im BIOS ist "Secure Virtual Machine" aktiviert. Es wird ein Fehler oder eine Einstellung im OS sein. Oder ein Anzeigefehler.
Selbst falls ich VMs zum Laufen bekäme, müsste ich nur für den Test eine einrichten.
Zumindest wird Virtualisierung für den Test benötigt, zudem VMWare (andere VM wird wohl auch gehen).
Für die genaue (kurze!) Anleitung, siehe Beitrag #43 hier
http://www.techpowerup.com/forums/t...courtesy-the-stilt.186056/page-2#post-2927933
@WindHund
Du meintest einen 3770k, nicht einen 4770k, oder?
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
So wie ich das gelesen habe, nutzt WinLAME eine eigene Schnittstelle für LAME, bereitgestellt mittels nLAME.dll. Da nützen einem die Standard Builds (lame.exe, lame_enc.dll) leider nichts.
gruffi mal ne blöde Frage, nutzt du vllt. die 32bit ICC Version von Lame?
Die hatte ich nämlich auch erst und hatte bei meinem 5800k auch ca. 13-15% Differenz. Mit 64 bit nehmen sich beide Versionen allerdings nichts, bzw. sind die Werte des ICC sogar minimalst besser.
E: eine Gemeinsame Testdatei und vllt. auch noch die selben Parameter wären vllt auch für so einen Test hilfreich.

Die hatte ich nämlich auch erst und hatte bei meinem 5800k auch ca. 13-15% Differenz. Mit 64 bit nehmen sich beide Versionen allerdings nichts, bzw. sind die Werte des ICC sogar minimalst besser.
E: eine Gemeinsame Testdatei und vllt. auch noch die selben Parameter wären vllt auch für so einen Test hilfreich.
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nein, ich habe schon die 64-bit Version genutzt. 32-bit habe ich separat auch getestet. Da hatte ich immer noch bessere Ergebnisse mit MinGW. Auch wenn es etwas weniger war. 32-bit liefert generell niedrigere Ergebnisse. Daher sollte man schon 64-bit nutzen, wenn es das System erlaubt.
Du hast halt einen anderen Prozessor mit anderer Architektur als ich. Das eine lässt sich nicht auf das andere übertragen. Deshalb hatte ich das auch im Startbeitrag nochmal angesprochen. Weil ja auch gerne mal behauptet wird, der ICC würde auch für AMD grundsätzlich die besten Ergebnisse liefern. Zuletzt auch hier im Forum wieder. Dem ist eben nicht so. Der ICC ist und bleibt ein Glücksspiel für AMD CPUs.
Testdatei war übrigens eine ~50 MB grosse WAV Datei, einmal mit -V0 und einmal mit -V2 Flag für LAME. Man sollte am besten mehrere Durchläufe machen, um Ausreisser zu eliminieren. Auch hat es bei mir geholfen, den Prozess mittels Task-Manager auf einen Kern festzupinnen. Dann waren die Ergebnisse relativ konstant. Davor gab es deutlich mehr Schwankungen.
2 Screenshots noch im Startbeitrag eingefügt.
Du hast halt einen anderen Prozessor mit anderer Architektur als ich. Das eine lässt sich nicht auf das andere übertragen. Deshalb hatte ich das auch im Startbeitrag nochmal angesprochen. Weil ja auch gerne mal behauptet wird, der ICC würde auch für AMD grundsätzlich die besten Ergebnisse liefern. Zuletzt auch hier im Forum wieder. Dem ist eben nicht so. Der ICC ist und bleibt ein Glücksspiel für AMD CPUs.
Testdatei war übrigens eine ~50 MB grosse WAV Datei, einmal mit -V0 und einmal mit -V2 Flag für LAME. Man sollte am besten mehrere Durchläufe machen, um Ausreisser zu eliminieren. Auch hat es bei mir geholfen, den Prozess mittels Task-Manager auf einen Kern festzupinnen. Dann waren die Ergebnisse relativ konstant. Davor gab es deutlich mehr Schwankungen.
2 Screenshots noch im Startbeitrag eingefügt.
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.262
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ok, danke für dein Input!Den Patcher kenne ich nicht. Ich würde mir von solchen Sachen aber nicht mehr allzu viel versprechen. Cinebench R15 ist ja noch nicht so alt. Da sollte also eine relativ aktuelle Version des Intel Compilers zum Einsatz kommen. Und Intel scheint bei neueren Versionen nichts beeinträchtigendes mehr mit der CPUID Herstellerkennung anzustellen. Oder formulieren wir es anders. Aufgrund der Auflagen der FTC machen sie es zumindest nicht mehr so offensichtlich.
Den ICC-Patcher gibt es z.B. hier: http://encode.ru/threads/1602-ICC-patcher-for-AMDs
Es ist ja ok wenn gewisse Feature abgefragt werden vom Programm, müssen sogar wenn das Programm "kompatible" sein soll.
Aber eine reine Abfragung Intel Präsent oder nicht, ist ein wenig verdächtig.
Hab mal den y-cruncher Multithread gegen SuperPi 1.6 laufen lassen:

17 Minuten 33 Sek vs 9.332 Sek

Man könnte meinen, die Software hat sich in 19 Jahre verhundertfacht (111)
bbott
Grand Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 4.363
- Renomée
- 60
- Mein Laptop
- HP Compaq 8510p
- Details zu meinem Desktop
- Prozessor
- AMD FX-8370
- Mainboard
- Asus M5A99X
- Kühlung
- Corsair H60
- Speicher
- 16GB DDR3-1866 Crucial
- Grafikprozessor
- Sapphire HD5770
- Display
- 4k 27" DELL
- SSD
- Samsung Evo 850
- HDD
- 2x Seagate 7200.12
- Optisches Laufwerk
- Pioneer, Plextor
- Soundkarte
- Creative X-Fi Xtreme Music
- Gehäuse
- Silverstone TJ-02S
- Netzteil
- Enermax 450W
- Betriebssystem
- Windows 7
Hallo!
Ich hätte Interesse an einem FX-8350-optimierten LAME. Da ich kein Fan von Kommandozeilen bin, nutze ich bislang WinLAME. Es scheint mir nicht, als könne man die LAME-Komponente einfach austauschen.
Kennst du zufällig eine GUI für LAME, die ich alternativ verwenden könnte und die den Austausch von LAME ermöglicht?
Wie wäre es mit BeSweet bzw. BeLight?!
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Wobei die Performance von Pi Berechnungen nicht nur vom Prozessor abhängt, sondern vor allem vom verwendeten Algorithmus. Super Pi Mitte der 90er nutze Gauss–Legendre. Mittlerweile werden halt effizientere Algorithmen genutzt, wie zb Chudnovsky. Der System Stability Tester erlaubt übrigens auch die Berechnung mittels Gauss–Legendre.Man könnte meinen, die Software hat sich in 19 Jahre verhundertfacht (111)
Übrigens, ich würde im Startbeitrag gerne eine Liste mit häufig genutzten Tools fürs Testen, Benchmarken, Übertakten/Untervolten, etc mit ihren Eigenheiten anlegen. Wünsche sind willkommen.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Auch wenn schon vielfach durchgekaut, würde es als direkte Referenz (die dann auch kompakt sämtliche Fragen beantwortet) nichts schaden, gleich auf die häufigsten (oder lautesten?) Vertreter zu sprechen zu kommen, d.h. gerade so Kandidaten wie Cinebench (siehe Kaveri - Thread).Übrigens, ich würde im Startbeitrag gerne eine Liste mit häufig genutzten Tools fürs Testen, Benchmarken, Übertakten/Untervolten, etc mit ihren Eigenheiten anlegen. Wünsche sind willkommen.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.262
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Den 3770K mit Standard Takt gepatcht und den 4770K übertaktet & gepatcht.@WindHund
Du meintest einen 3770k, nicht einen 4770k, oder?
Hast du im UEFI eine "IOMMU" Option, wenn ja "enabled" Einstellen. (evt. geht AMD-V deswegen nicht)
Ok, also kann ein Algo soviel ausmachen?Wobei die Performance von Pi Berechnungen nicht nur vom Prozessor abhängt, sondern vor allem vom verwendeten Algorithmus. Super Pi Mitte der 90er nutze Gauss–Legendre. Mittlerweile werden halt effizientere Algorithmen genutzt, wie zb Chudnovsky. Der System Stability Tester erlaubt übrigens auch die Berechnung mittels Gauss–Legendre.
Übrigens, ich würde im Startbeitrag gerne eine Liste mit häufig genutzten Tools fürs Testen, Benchmarken, Übertakten/Untervolten, etc mit ihren Eigenheiten anlegen. Wünsche sind willkommen.
Der System Stability Tester skaliert mit Gauss-Leg. negative auf mehr Threads:




Was halltest du von: http://www.yeppp.info/home/yeppp-performance-numbers/
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Übrigens, ich würde im Startbeitrag gerne eine Liste mit häufig genutzten Tools fürs Testen, Benchmarken, Übertakten/Untervolten, etc mit ihren Eigenheiten anlegen. Wünsche sind willkommen.
Den RMMA und das CPU-Z Cache Latency Tool, die P3Dn verwenden, finde ich für die theoretische Betrachtung des Caches immer sehr interessant:
http://cpu.rightmark.org/products/rmma.shtml
http://www.cpuid.com/medias/files/softwares/misc/latency.zip
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Die negative Skalierung bei mehreren Threads ist eigentlich normal. Je mehr Threads Last erzeugen, umso weniger Performance hast du pro Thread, weil dann diverse Ressourcen geteilt werden müssen oder weil Threadsynchronisierung ausbremst. Und gerade von 4 auf 8 Threads fällt bei deinem FX die Performance pro Thread deutlicher ab, da sich nun 2 Threads ein Modul teilen müssen. Man sollte bedenken, dass in der Zeit dann aber auch 8x 32M Stellen berechnet wurden und nicht nur 4x 32M. Das macht in der gleichen Zeit immer noch fast 50% mehr berechnete Stellen bei 8 Threads.Der System Stability Tester skaliert mit Gauss-Leg. negative auf mehr Threads:
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.423
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
Was halltest du von: http://www.yeppp.info/home/yeppp-performance-numbers/
Ich hab das letztens auch schon zweimal gepostet, wir komplett wegignoriert.

Falls es möglich ist z.B. einen x264 mit GCC 4.9.0 + Bd.Ver2 zu compilieren, der diese Bibliothek nutzt wär das mal ein lohnendes Testobjekt.
Vielleicht könnte sich das ein Compilierprofi mal ansehen. 8)
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Weiss nicht, ob sich das wirklich lohnt. LLVM Clang schaut nicht gerade gut gegen GCC 4.9 aus, wenn es um Audio Encoding geht. GCC 4.10 ist ja auch schon am Start. Habe ich bisher aber noch nicht getestet, da er noch instabil sein soll.
---------- Beitrag hinzugefügt um 22:37 ---------- Vorheriger Beitrag um 22:16 ----------
Naja, das Problem ist, die Software müsste erst mal eine solche Bibliothek nutzen. Ich glaube nicht, dass das bei x264 der Fall ist. Wenn eine solche Bibliothek nicht genutzt wird, dann müsste man es erst implementieren. Das kann uU recht aufwändig werden. Und die Frage wäre dann, ob es sich in dem Fall überhaupt lohnt. Im Endeffekt sind das in den Yeppp Diagrammen nur spezielle und für Prozessoren meist sehr aufwändig zu berechnende Operationen, die in den meisten Anwendungen gar keine oder eine nur sehr begrenzte Verwendung finden. Schaut in den Diagrammen zwar toll aus, wenn zB log dreimal so schnell berechnet werden kann. Wenn es aber zB nur 0,1% der Laufzeit ausmacht, springt unterm Strich trotzdem keine sichtbar verbesserte Performance heraus. Das fällt dann eher unter Messtoleranz. Solche Bibliotheken machen wirklich nur dort Sinn, wo solche Operationen auch häufig genutzt werden.Falls es möglich ist z.B. einen x264 mit GCC 4.9.0 + Bd.Ver2 zu compilieren, der diese Bibliothek nutzt wär das mal ein lohnendes Testobjekt.
Unbekannter Krieger
Grand Admiral Special
- Mitglied seit
- 04.10.2013
- Beiträge
- 4.606
- Renomée
- 119
- Mein Laptop
- HP 15-bq102ng (sackteuer u. ab Werk instabil)
- Details zu meinem Desktop
- Prozessor
- FX-8320E@4,2 GHz & 2,6 GHz Northbridge (jeweils mit UV)
- Mainboard
- Asus M5A99X Evo R2.0 (eher enttäuschend ggü. ASRock E3)
- Kühlung
- Raijintek Nemesis (Lüfter mittig im sowie hinter dem Kühler; erstklassig)
- Speicher
- 4x4 GiB Hynix DDR3-1866 ECC
- Grafikprozessor
- XFX RX 570 8G (P8DFD6)@1180 & 2150 MHz@starkem, fortdauerndem UV | ASRock RX 570 8G@das Gleiche
- Display
- BenQ XL2411T ~ nach 3 RMAs und 6 Monaten wieder brauchbar
- SSD
- Crucial MX100 256 GB (ein Glückskauf) | SanDisk Ultra Plus 256 GB (ein Glückskauf)
- HDD
- WD20EZRZ u. a. (Seagate, Hitachi, WD)
- Optisches Laufwerk
- TSST SH-222AL
- Gehäuse
- Corsair Carbide 300R (ein Fehlkauf)
- Netzteil
- CoolerMaster V450S (ein Glückskauf)
- Betriebssystem
- Win8.x x64, Win7 x64
- Webbrowser
- welche mit minimalem Marktanteil & sinnvollen Konzepten (nicht Chrome-Seuche und Sieche-Fuchs)
- Verschiedenes
- frühere GPUs: , Asus RX 480 O8G@580 O8G, VTX3D 7850 1G
@WindHund
Und dein FX-8350 konnte beide einholen oder gar überholen?
IOMMU ist eingeschaltet.
@LoRDxRaVeN
Werden die vom Cache-Tool angezeigten Werte von BIOS-Einstellungen beeinflusst?
Und dein FX-8350 konnte beide einholen oder gar überholen?
IOMMU ist eingeschaltet.
@LoRDxRaVeN
Werden die vom Cache-Tool angezeigten Werte von BIOS-Einstellungen beeinflusst?
Zuletzt bearbeitet:
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Kann ich eigentlich nicht sagen - ich habe selbst keinerlei Erfahrung mit der Anwendung der Tools. Aber prinzipiell, wenn es sich auf "pro Takt" bezieht, fällt mir jetzt nichts ein, das du im BIOS verändern kannst, dass eine Auswirkung hat. Absolute Latenzen etc. würden sich mit unterschiedlichen Cachetaktfrequenzen natürlich ändern.
Wenn du willst, kannst du "MusicIsMyLife" fragen. Er hat den Vishera Artikel geschrieben und die Tools eingesetzt.
LG
Wenn du willst, kannst du "MusicIsMyLife" fragen. Er hat den Vishera Artikel geschrieben und die Tools eingesetzt.
LG
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.262
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ok, dann ist das eher was für Stabilitätstest. Interessant dann sollte man nicht nur die Zeit sehen sondern auch die Datenmenge die Verarbeitet wird.Die negative Skalierung bei mehreren Threads ist eigentlich normal. Je mehr Threads Last erzeugen, umso weniger Performance hast du pro Thread, weil dann diverse Ressourcen geteilt werden müssen oder weil Threadsynchronisierung ausbremst. Und gerade von 4 auf 8 Threads fällt bei deinem FX die Performance pro Thread deutlicher ab, da sich nun 2 Threads ein Modul teilen müssen. Man sollte bedenken, dass in der Zeit dann aber auch 8x 32M Stellen berechnet wurden und nicht nur 4x 32M. Das macht in der gleichen Zeit immer noch fast 50% mehr berechnete Stellen bei 8 Threads.
Hier mal noch y-cruncher Single Thread & MT 256MB / ST 32M



Bei x264 hilft es oft die neuste Datei Version zu laden: http://www.x264.nl/x264_main.phpIch hab das letztens auch schon zweimal gepostet, wir komplett wegignoriert.
Falls es möglich ist z.B. einen x264 mit GCC 4.9.0 + Bd.Ver2 zu compilieren, der diese Bibliothek nutzt wär das mal ein lohnendes Testobjekt.
Vielleicht könnte sich das ein Compilierprofi mal ansehen. 8)
Sieht man doch im CineBench R15 Bild oben, alle FX-8350 Ergebnisse sind mit dem selben System zustande gekommen.@WindHund
Und dein FX-8350 konnte beide einholen oder gar überholen?
IOMMU ist eingeschaltet.
@LoRDxRaVeN
Werden die vom Cache-Tool angezeigten Werte von BIOS-Einstellunegn beeinflusst?
Ja die Cache Werte werden beeinflusst, mit höherem Takt sinkt die Latenz.
")
€dit: Bezüglich AMD-V, das hier schon probiert: http://www.youtube.com/watch?v=YzaCOZAYtJs ?
Zuletzt bearbeitet:
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.423
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
Naja, das Problem ist, die Software müsste erst mal eine solche Bibliothek nutzen. Ich glaube nicht, dass das bei x264 der Fall ist. Wenn eine solche Bibliothek nicht genutzt wird, dann müsste man es erst implementieren. Das kann uU recht aufwändig werden. Und die Frage wäre dann, ob es sich in dem Fall überhaupt lohnt. Im Endeffekt sind das in den Yeppp Diagrammen nur spezielle und für Prozessoren meist sehr aufwändig zu berechnende Operationen, die in den meisten Anwendungen gar keine oder eine nur sehr begrenzte Verwendung finden. Schaut in den Diagrammen zwar toll aus, wenn zB log dreimal so schnell berechnet werden kann. Wenn es aber zB nur 0,1% der Laufzeit ausmacht, springt unterm Strich trotzdem keine sichtbar verbesserte Performance heraus. Das fällt dann eher unter Messtoleranz. Solche Bibliotheken machen wirklich nur dort Sinn, wo solche Operationen auch häufig genutzt werden.
Das ist klar.
Ich ging mal davon aus, das x264 doch recht viele mathematische Berechnungen durchführt (weiss batürlich nicht genau welche exakt).
Wenn die Bibliothek kaum genutzt wird ist es natürlich obsolet.
---------- Beitrag hinzugefügt um 12:47 ---------- Vorheriger Beitrag um 12:37 ----------
Bei x264 hilft es oft die neuste Datei Version zu laden: http://www.x264.nl/x264_main.php
Hab immer die Neueste (r2431) am Start. 8)
Auf deiner Seite ist nur die (r2334) als aktuell verzeichnet.
Die nehmen auch erst den GCC 4.7.2
Wo kann man sich denn mal einlesen wie man z.B. x264 Prozessorspezifisch compiliert?
Oder kann einer (wenn es wenig genug ist) mal auflisten, was man (neben GCC nat.) braucht.
Bin da nicht so in dem Thema drin.
Gibt es ein MinGW-build mit GCC 4.9.0?
Das letzte MinGW-build ist ja fast ein Jahr alt und noch mit GCC 4.8.1.
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
MinGW ist im Startbeitrag verlinkt. Da findest du aktuelle 32- und 64-bit Versionen. Ich kann ja mal versuchen, ob ich x264 mit Version 4.9 kompiliert bekomme. Viel erwarten solltest du aber nicht. So wie ich das sehe, ist x264 schon ziemlich gut handgetuned mittels Assembler. Da kann auch der beste Compiler nicht mehr viel machen. Zumal dann eh ein separater Assembler zum Einsatz kommt wie NASM oder YASM.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 3
- Aufrufe
- 2K
- Antworten
- 1
- Aufrufe
- 965
- Antworten
- 37
- Aufrufe
- 14K