App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
News AMD präsentiert nächstes GPU Design und kehrt VLIW den Rücken; Update 16.6: Gemeinsamer Adressraum mit x86
- Ersteller Opteron
- Erstellt am
User-News
Von Opteron
Hinweis: Diese "User-News" wurde nicht von der Planet 3DNow! Redaktion veröffentlicht, sondern vom oben genannten Leser, der persönlich für den hier veröffentlichten Inhalt haftet.
Wie man schon auf der Hauptseite lesen konnte, findet derzeit der AMD Fusion Developer Summit (AFDS) statt. Neben einer kleinen Demo des nächsten Fusion Chips Trinity gab AMD dabei auch Details zur nächsten GPU Design preis.
Kurz zur Erinnerung, mit der HD2900 führte AMD 2007 erstmals eine Karte mit VLIW5 Vector Einheiten ein:

Dabei werden bis zu 5 Befehle in ein VLIW Paket verpackt und dann von 5 Recheneinheiten abgearbeitet. Dieses "Verpacken" geschieht dabei per Software mittels eines Compilers, der im Grafiktreiber integriert ist. Der Vorteil liegt auf der Hand: Es wird weniger Chipfläche für die Thread/VLIW Logik gebraucht, d.h. es bleibt mehr Platz für die eigentlichen Recheneinheiten.
Der Nachteil ebenfalls: Dass ein komplettes VLIW Paket gefüllt werden kann, ist sehr unwahrscheinlich. Im Mittel waren es um ~3 Instruktionen pro Paket. Außerdem ist ist der "Packetbündelalgorithmus" nicht trivial, sondern eher komplex zu nennen.
Letztes Jahr gab es mit der HD6900 Reihe bereits die erste Abkehr vom lang verwendeten VLIW5 System. Eine Einheit wurde entfernt und deren Aufgaben auf die restlichen 4 Einheiten, die dafür etwas verbessert wurden, verteilt. Kurz: VLIW4 wurde benützt.

Dadurch, dass die verbliebenen 4 Einheiten fast die gleiche Funktionalität haben, und natürlich durch das Wegfallen der 5ten Einheit, vereinfachte sich das Verteilen der Instruktionen. Allerdings scheint es nicht genug gewesen zu sein, denn nun kehrt AMD dem VLIW Prinzip komplett den Rücken, und greift einen nVidia ähnlichen Ansatz auf: Mehrere, unabhängige SIMD Einheiten sollen es jetzt richten:
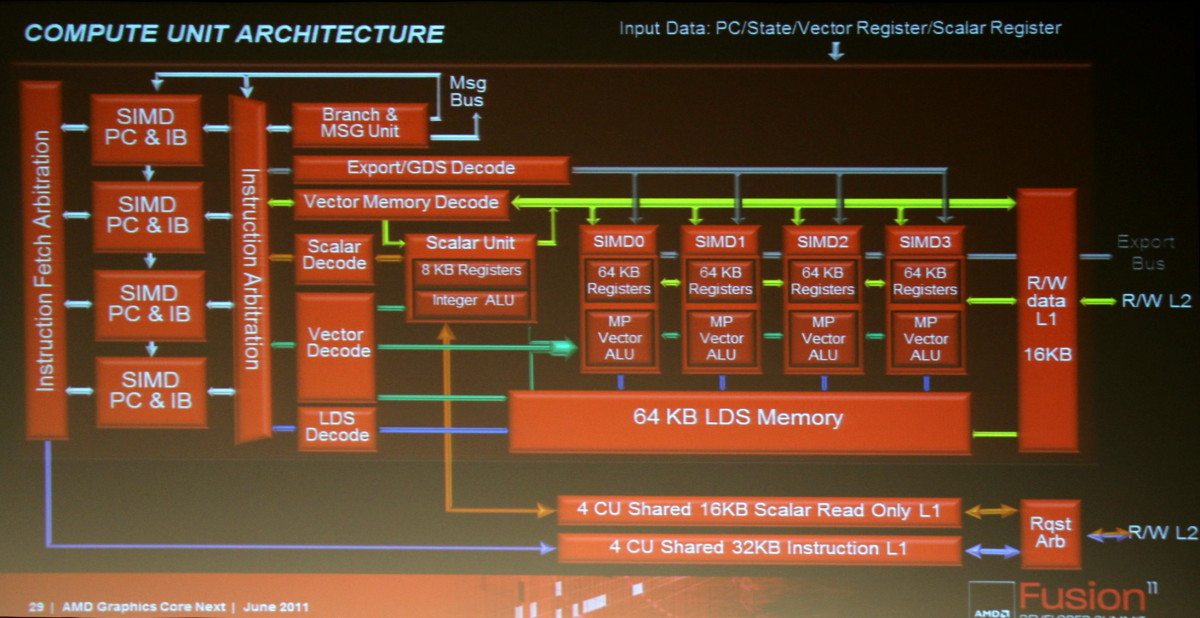
Edit 16.6.2011:
Der Betrieb dieser Einheiten ist dabei recht flexibel, SIMD, MIMD, SMT, alles ist möglich:

Die Vorteile gegenüber eines VLIW Designs werden hier angesprochen, links mit VLIW (alte Generation ab R600), rechts die neue Generation:

Vermutlich war die steigende Komplexität, die mit jeder weiteren Shader Einheit zunahm, am Ende doch zuviel. Auf obiger Folie wird neben dem bereits erwähnten, komplexen Compiler noch auf komplexe Assemblercodes, schwieriges Debugging und komplizierte Tools verwiesen. AMD weist desweiteren auf den folgenden Präsentationsfolien deutlich auf die vereinfachte ISA und auf die vereinfachte Programmierbarkeit hin:


Ein weiterer Vorteil ist laut AMD, das die Leistung besser vorhersagbar ist. Die alte VLIW Designs konnten zwar oft mit hoher, theoretischer Rechenleistung glänzen, jedoch war die Leistung in der Praxis nicht genauso hoch, sondern lag typischerweise um die ~70-80%, wohingegen nVidia Ihre theoretische Rechenleistung deutlich besser ausschöpfen konnte.
Weitere Neuerungen:
- Es gibt eine extra 32/64bit Skalar Unit, z.B. vergleichbar mit einem abgespeckten Bulldozer INT Cluster.
- Alle Caches werden durch ECC abgesichert, was im professionelle Umfeld fast schon Pflicht ist und bei nvidia schon durch Fermi eingeführt wurde.
- Ebenfalls an Bord ist eine Branch Unit
- Mehr Programmierfeatures: Funktionsaufrufe, Rekursion und Exceptions werden unterstützt.
Weiteres Merkmal ist die Unterstützen der 64bit Speicherpointer der CPU. Bisher muss man Daten noch vom CPU RAM in den Grafikspeicher laden, um die GPU rechnen zu lassen, das fällt nun weg:

Genutzt wird dabei die IOMM Unit des Chipsatzes, die erstmals im 890FX Chipsatz zu finden war. Mittlerweile sind alle Modelle der neuen, 900er Chipsatzreihe für AM3+ mit einer IOMMU ausgerüstet:

Alles in Allem ist zeigt man sich mit dieser Architektur bestens für die kommende OpenCL und C++ AMP Zukunft gerüstet:

Eventuell wird die neue Architektur bereits Ende diesen Jahres im Laden stehen, so man dieser Meldung Glauben schenken will:
http://www.xbitlabs.com/news/graphi...neration_Radeon_Graphics_Later_This_Year.html"In a couple of days you are going to hear about our exciting new graphics architecture that will be coming out later this year and will be utilized by our future APUs," so Rick Bergman.
Update 17.6:
Gestern wurde der Start Ende 2011 noch einmal bestätigt. Im Live Blog auf pcper (unter Quellen verlinkt), konnten es die Moderatoren fast selbst nicht glauben:
Diskussion im Forum:MAJOR CORRECTION TO MAKE: the compute unit technology we are getting details on here is for the NEXT GPU architecture to be released, it is NOT two gens away. You will see parts based on this design by the end of the year!!!
http://www.planet3dnow.de/vbulletin/showthread.php?t=389946
Präsentationsfolien:
Update 18.6: Mittlerweile gibts alle PDFs bei AMD zum Herunterladen:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4447839#post4447839
Alte Screenshots:






















Programmierbeispiele:




Updateslides 16.6:



Quellen:
http://www.hardware.fr/news/11648/afds-architecture-futurs-gpus-amd.html
http://www.pcper.com/news/Editorial/AMD-Fusion-Developer-Summit-2011-Live-Blog
Zuletzt bearbeitet:
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.031
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
Kommentare am besten direkt hier rein:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4446514#post4446514
http://www.planet3dnow.de/vbulletin/showthread.php?p=4446514#post4446514
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Kommentare am besten direkt hier rein:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4446514#post4446514
Diskussion im Forum:
http://www.planet3dnow.de/vbulletin/showthread.php?t=389946
")
Ich machs mal fett ^^
Makso
Grand Admiral Special
- Mitglied seit
- 15.02.2006
- Beiträge
- 3.393
- Renomée
- 142
- Standort
- Österreich
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Folding@Home, POEM, Docking
- Lieblingsprojekt
- Folding@Home
- Folding@Home-Statistiken
- Mein Laptop
- Desktopsystem
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1400@3,8GHz
- Mainboard
- Asrock B350 Pro4
- Kühlung
- Scythe Mugan 5
- Speicher
- 2x4GB ADATA
- Grafikprozessor
- RX 550
- Display
- BenQ 21,5
- SSD
- Samsung 960Pro
- HDD
- 1TB WD
- Optisches Laufwerk
- LG schwarz
- Soundkarte
- AC 97
- Gehäuse
- NZXT Beta Evo
- Netzteil
- AXP SimplePower 630W
- Betriebssystem
- Win 10
- Webbrowser
- Chrome
super news. wenn das so stimmt und die HD7xxx auftrumpfen kann, dann hoffe ich wird Folding@Home wieder Spaß machen mit einer AMD Graka!
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 986
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS ProArt B550-Creator
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Aber lustig ist es schon. Zuerst verteufelt man nVidias Fermi wo man kann und dann klont man ihn wenig später beinah 1:1. 
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Aber lustig ist es schon. Zuerst verteufelt man nVidias Fermi wo man kann und dann klont man ihn wenig später beinah 1:1.
Falsch. Sieh bitte in den verlinkten Thread, Fermi hat einzelne Skalarrechenwerke, bei dem hier gezeigten handelt es sich um Vektorrechenwerke.
Diapolo
Vice Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 839
- Renomée
- 21
- Details zu meinem Desktop
- Prozessor
- AMD A8-3850
- Mainboard
- ASUS F1A75-V EVO (BIOS 1803)
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x2GB OCZ DDR3-1600 (OCZ3P1600LVAM4GK)
- Grafikprozessor
- XFX Radeon HD 7970 Core Edition
- HDD
- OCZ Vertex 4 256GB, OCZ Vertex Turbo 60GB + WD Raptor 150GB
- Netzteil
- be quiet! Dark Power PRO P9 550W
- Betriebssystem
- Windows 7 Ultimate SP1 (64-Bit)
Falsch. Sieh bitte in den verlinkten Thread, Fermi hat einzelne Skalarrechenwerke, bei dem hier gezeigten handelt es sich um Vektorrechenwerke.
Hätte mich auch sehr gewundert, wenn AMD seine gute Vektorlösung zu Gunsten eines Fermi-Skalardesigns geschmissen hätte.
Dia
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 986
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS ProArt B550-Creator
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Es ist eine skalare Einheit ergänzt um vier SIMD Einheiten. Das hat ein wenig vom IBM Cell. Aber auch nur ganz entfernt....bei dem hier gezeigten handelt es sich um Vektorrechenwerke.
Dennoch ähnelt damit die neue AMD Generation deutlich stärker nVidias aktueller Architektur als die der R8xx/R9xx.
Aber wie sagt man so schön: Vom Feind lernen, heißt Siegen lernen...
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Wenn du dir die Folien genau ansiehst erkennst du, dass es sich hierbei viel mehr um 4 SIMD Einheiten ergänzt um eine skalare Einheit handelt. Auch wenn es ein radikale Abkehr vom bisher gefahrenen VLIW Ansatz ist, ähnelt die Architektur damit mehr der Geforce7 / Radeon X1800, als NVdias aktueller Arch.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Falsch. Sieh bitte in den verlinkten Thread, Fermi hat einzelne Skalarrechenwerke, bei dem hier gezeigten handelt es sich um Vektorrechenwerke.
Das ist irgendwie alles in einem, neue Folie von heute:
MIMD, SIMT, sogar SMT und Vector und Scalar
")
Onkel_Dithmeyer
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 22.04.2008
- Beiträge
- 12.949
- Renomée
- 4.041
- Standort
- Zlavti
- Aktuelle Projekte
- Universe@home
- Lieblingsprojekt
- Universe@home
- Meine Systeme
- cd0726792825f6f563c8fc4afd8a10b9
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- Ryzen 9 3900X @4000 MHz//1,15V
- Mainboard
- MSI X370 XPOWER GAMING TITANIUM
- Kühlung
- Custom Wasserkühlung vom So. G34
- Speicher
- 4x8 GB @ 3000 MHz
- Grafikprozessor
- Radeon R9 Nano
- Display
- HP ZR30W & HP LP3065
- SSD
- 2 TB ADATA
- Optisches Laufwerk
- LG
- Soundkarte
- Im Headset
- Gehäuse
- Xigmatek
- Netzteil
- BeQuiet Dark Pro 9
- Tastatur
- GSkill KM570
- Maus
- GSkill MX780
- Betriebssystem
- Ubuntu 20.04
- Webbrowser
- Firefox Version 94715469
- Internetanbindung
- ▼100 Mbit ▲5 Mbit
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
SMT? das SMT?
Das Ganze ist mEn, und ich bin kein Fachman auf dem Gebiet, eine relativ aufwendige Architektur im Vergleich zum Vorgänger.
Jein, SMT heißt erstmal nur, dass unterschiedliche Threads gleichzeitig auf nem Prozessor laufen, wie genau ... da gibts viele Wege.
Gipsel hats hier im Detail erklärt:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4447839#post4447839
Ansonsten, die Präsentationsfolien sind jetzt online:
http://developer.amd.com/DOCUMENTATION/PRESENTATIONS/Pages/default.aspx
Onkel_Dithmeyer
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 22.04.2008
- Beiträge
- 12.949
- Renomée
- 4.041
- Standort
- Zlavti
- Aktuelle Projekte
- Universe@home
- Lieblingsprojekt
- Universe@home
- Meine Systeme
- cd0726792825f6f563c8fc4afd8a10b9
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- Ryzen 9 3900X @4000 MHz//1,15V
- Mainboard
- MSI X370 XPOWER GAMING TITANIUM
- Kühlung
- Custom Wasserkühlung vom So. G34
- Speicher
- 4x8 GB @ 3000 MHz
- Grafikprozessor
- Radeon R9 Nano
- Display
- HP ZR30W & HP LP3065
- SSD
- 2 TB ADATA
- Optisches Laufwerk
- LG
- Soundkarte
- Im Headset
- Gehäuse
- Xigmatek
- Netzteil
- BeQuiet Dark Pro 9
- Tastatur
- GSkill KM570
- Maus
- GSkill MX780
- Betriebssystem
- Ubuntu 20.04
- Webbrowser
- Firefox Version 94715469
- Internetanbindung
- ▼100 Mbit ▲5 Mbit
Ah, ok, danke für den Link ")
Markus Everson
Grand Admiral Special
Da die Folien nun zum Download bereit stehen möchte ich eure Aufmerksamkeit auf Folie 20 von http://developer.amd.com/documentation/presentations/assets/6-Demers-FINAL.pdf lenken.
"Features added incrementally each year"
Meine Interpreation: nix is mit dem großen Sprung auf die neue Architektur die da kommen wird um all unsere Probleme zu lösen, deren simpelste Parameter zu berechnen wir aber unwürdig sind.
Nicht vergessen: Auch AMD kocht nur mit Wasser und begrenzten Ressourcen.
"Features added incrementally each year"
Meine Interpreation: nix is mit dem großen Sprung auf die neue Architektur die da kommen wird um all unsere Probleme zu lösen, deren simpelste Parameter zu berechnen wir aber unwürdig sind.
Nicht vergessen: Auch AMD kocht nur mit Wasser und begrenzten Ressourcen.
Ähnliche Themen
- Antworten
- 4
- Aufrufe
- 1K
- Antworten
- 781
- Aufrufe
- 106K
- Antworten
- 0
- Aufrufe
- 2K