Der Youtuber
AdoredTV spekuliert in seinem "EPYC Masterplan P.2" über eine künftige Trennung von Multicore Dies und den übrigen SoC bzw. Uncore Einheiten bei den künftigen Zen CPUs. Dabei geht er sogar so weit, dass der Level 3 Cache ebenso in separate Dies ausgelagert werden könnte.
Dabei könnten 4 Stück der neuen 16 Core Dies mit einem Uncore Die zu einer 64 Core CPU als MCM zusammengestellt werden.
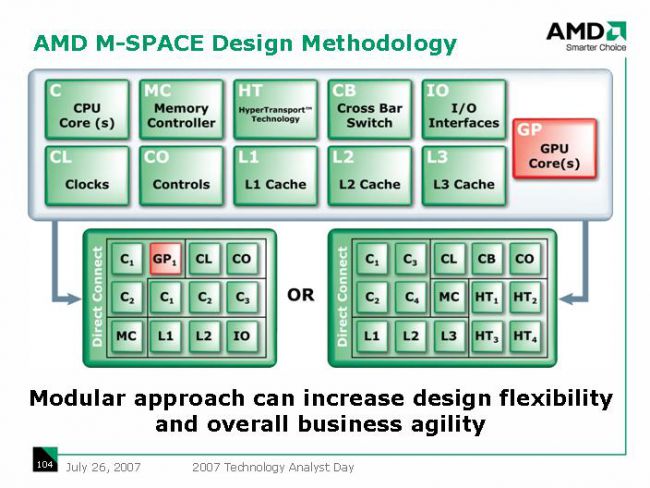
Entsprechend den zuletzt aufgetauchten Folien würden demnach künftige
Core-Dies nur noch als
CCX produziert, also das, was an den
CCM angebunden ist, ggf. sogar ohne den Level 3 Cache. Die
UMC müssten wohl zumindest auch in den CCX Core Dies untergebracht sein, damit bei MCMs die Speicheranbindung skalieren kann.
Im
Uncore Die mit dem
IO Complex könnten dafür alle Elemente zusammen gefasst werden, die im Infinity Fabric eine
CAKE Schnittstelle nutzen. Für verschiedene Produktvarianten müssten dann die jeweils gleichen Core Dies mit einem passenden Uncore Die verbunden werden um SoCs für Mobile, Desktop und Mullti-Socket Systeme zu ermöglichen.

Zumindest spricht die steigende MHz Zahl bei DDR-SDRAM (u.a. DDR5) und sicherlich auch die des Ininity Fabric in 7nm für diese These. Der Interconnect und RAM werden wesentlich schneller an Takt zulegen, als es bei einzelnen Cores noch möglich ist.
Auf jeden Fall ein schönes Beispiel für
Out of the Box Thinking, das die Flexibilität des als so wichtig erachteten Infinity Fabric in Betracht zieht.