App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Beema - der Kabini Nachfolger
- Ersteller FredD
- Erstellt am
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Opteron hat schon recht, die Taktbarkeit in Abhängigkeit von der Spannung verhält sich zwischen 28nm HP und 28nm fdSOI ähnlich wie zwischen 28nm HP und 28nm LP, was er auch vor längerer Zeit schon im Prozess-Thread gepostet hat.
Insofern lässt sich der Bonus von +35% CPU-Takt des NovaThor nicht auf einen etwaigen fdSOI Beema/Mullins übertragen, da wir annehmen müssen, dass Kabini/Temash mit einem dem HP ähnlichen 28nm HPM Prozess gebacken wurden. Bitte korrigiert mich, wenn hierzu genauere Informationen bekannt sind. Wenn dank der geringeren Leakage im Vergleich zu Kabini nur durchschnittlich 20% höhere Takte bei gleicher TDP erreicht würden, wäre das aber auch schon ein beachtlicher Schritt.
Insofern lässt sich der Bonus von +35% CPU-Takt des NovaThor nicht auf einen etwaigen fdSOI Beema/Mullins übertragen, da wir annehmen müssen, dass Kabini/Temash mit einem dem HP ähnlichen 28nm HPM Prozess gebacken wurden. Bitte korrigiert mich, wenn hierzu genauere Informationen bekannt sind. Wenn dank der geringeren Leakage im Vergleich zu Kabini nur durchschnittlich 20% höhere Takte bei gleicher TDP erreicht würden, wäre das aber auch schon ein beachtlicher Schritt.
Dass ARM wesentliche fdSOI Design "Vorlagen" eingebracht hat, würde ich gerne mit einer Quelle belegt sehen.Man sollte berücksichtigen, dass beim NovaThor ARM involviert war und entsprechende, fdSOI-gerechte Vorlagen für die Kerne geliefert hat. Den Schritt müsste AMD bei Beema alleine gehen.
MfG
von der bekannten fdSOI-PublizistinThe NovaThor L8580 is essentially a straight port from 28nm bulk to 28nm FD-SOI of the (very successful) NovaThor L8540, with just a bit of tweaking to fully leverage cool things you can do with FD-SOI, like biasing to increase performance and conserve power.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hab davon auch noch nichts gehört. Auf der einen Seite wärs glaubhaft, wenn man überlegt, dass STM sich die LP-Sourcen geholt an, auf der anderen Seite machen sie ja selbst Grundlagenforschung mit IBM zusammen. Da mal schnell nen simplen ARM A9 umzustricken, ist wohl keine Hexerei.Ich würde auch gerne eine Quelle finden, muss aber wohl mindestens bis heute abend zurückrudern, weil ich auf die Schnelle nichts gefunden habe.
Zu Beema: Glaube da im Moment auch eher, dass es bulk HP wird. Hintergrund ist der Leak-Informationsfetzen, dass die XBox1 mit Puma-Kernen kommt. Das gabs mal vorab inoffiziell. Nach der Präsentation hörte man aber komischerweise herzlich wenig davon, während bei der PS4 ganz offen Jaguar erwähnt wurde.
Bisschen merkwürdig, das sieht so aus, als ob die XBOx-Kerne noch unter NDA lägen. Wenn es Puma Kerne wären, würde es die Schweigsamkeit erklären.
Die Wahrscheinlichkeit, dass sich MS auf ein Risiko wie FS-SOI einließe sehe ich aber als gering an, ergo Bulk und deshalb auch bei Beema eher Bulk, da ich denke, dass Beema auf dem Xbox1-Design basiert. Für Sonderwünsche wie FDSOI hat AMD kein Geld. Aber warten wirs mal ab.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.385
- Renomée
- 85
Ich würde durchaus nicht ausschließen, dass noch in H1/14 ein kleines Update von Jaguar kommt, bei dem dann endlich auch der Turbomodus vollwertig funktioniert. Womöglich hat AMD auf solche Features erst mal verzichtet, weil Jaguar ja auch für PS4/Xbox rechtzeitig fertig sein musste, sodass man womöglich all die Features, die dort keine Rolle spielen, zurückgestellt hat. Für Temash/Kabini wäre ein echter Turbomodus aber sehr wichtig, sodass es meines Erachtens jetzt erst mal Zeit wäre, diese Features nachzuliefern. Bei Puma sind derartige Features dann hoffentlich Standard.
nVoodoo
Vice Admiral Special
- Mitglied seit
- 16.03.2007
- Beiträge
- 531
- Renomée
- 1
- Standort
- Nördliches Emsland
- Meine Systeme
- R7 1700;2xX5650;i7 4700MQ;2x E5430;Athlon 5350
- BOINC-Statistiken

Mein Tipp 8) zur Fertigung ist... das wir vor Anfang Q4/14 kein einziges AMD Produkt <=22nm sehen werden...
SR oder SRb FX (falls überhaupt) tippe ich auf 28nm SHP/HP
Kaveri in 28nm SHP/HP
Beema in 28nm HP/LP
und auch die 9000er GPUs in 28nm
und dann vllt wie gesagt als Tipp Anfang Q4/14 20nm für ARM Server & GPUs der rest dann danach Beema & Kaveri Nachfolger + FX (falls überhaupt)
Hätte den Vorteil für AMD gleich viel auf einmal in Auftrag zu geben und so vllt die Preise drücken zu können... Yields dürften dann auch relativ gut sein...
SR oder SRb FX (falls überhaupt) tippe ich auf 28nm SHP/HP
Kaveri in 28nm SHP/HP
Beema in 28nm HP/LP
und auch die 9000er GPUs in 28nm
und dann vllt wie gesagt als Tipp Anfang Q4/14 20nm für ARM Server & GPUs der rest dann danach Beema & Kaveri Nachfolger + FX (falls überhaupt)
Hätte den Vorteil für AMD gleich viel auf einmal in Auftrag zu geben und so vllt die Preise drücken zu können... Yields dürften dann auch relativ gut sein...
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.385
- Renomée
- 85
Mein Tipp 8) zur Fertigung ist... das wir vor Anfang Q4/14 kein einziges AMD Produkt <=22nm sehen werden...
Das halte ich ebenfalls für sehr wahrscheinlich. Die 20nm-Prozesse scheinen einfach zu wenig zu bringen. AMD kann es sich aus der aktuellen Situation gar nicht leisten, Geld für die Entwicklung auf einem neuen Prozess in die Hand zu nehmen, von dem nicht viel zu erwarten ist. Man wird schon alleine daher den sicheren Weg gehen, und auf den bestehenden Prozessen durch Optimierungen im Design Verbesserungen zu erzielen.
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Den Vorteil der gesteigerten Flächeneffizienz, d.h. der etwa 1.8 bis 1.9-fachen Transistordichte gegenüber 28nm kann man den 20nm Prozessen nicht absprechen. Lediglich den Vorteil der vorerst geringfügig gesteigerten Energieeffizienz, (d.h. den nur um etwa 1.3 gesteigerten Transistorschaltzeiten), welcher sich erst mit kostspieligen Optimierungen, v.a. finFETs, nach Aufwendung von zusätzlicher Zeit und R&D-Budget ausbauen wird. Für Mobil-SOCs wie Kabini oder Beema in der Größenordnung von ~100mm² @28nm ergäben sich keine wirklichen Vorteile darin, bei sogar höheren Transistorkosten den Chip auf ~60mm² zu schrumpfen.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
20nm scheinen sich nur vorerst nur für große GPU Chips zu lohnen. Die haben dann aber auch wieder schnell mit termischen Problemen zu kämpfen. Für extrem energiesparende Chips wärs auch noch interessant, wenn die Gewinnmarge stimmt.
Bei gleichen Transistorkosten dürfte sich 20nm für andere Produkte erst lohnen, wenn der Yield mit 28nm vergleichbar ist, da dann mehr Chips aus einem Wafer geholt werden können. Alles eine Kalkulation mit zig uns unbekannten Parametern.
Bei gleichen Transistorkosten dürfte sich 20nm für andere Produkte erst lohnen, wenn der Yield mit 28nm vergleichbar ist, da dann mehr Chips aus einem Wafer geholt werden können. Alles eine Kalkulation mit zig uns unbekannten Parametern.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Transistorenkosten? Kenn ich nicht, es wird eigentlich immer nur in Waferkosten gerechnet. Selbst wenn da ein Wafer doppelt so teuer ist, könnte es sich immer noch rechnen, dann bei nem Full-node Shrink bekommt man ja auch doppelt soviele Chips unter. Die Kosten wären in dem Fall dann zwar "nur" gleich, aber so ein 20nm Die verbraucht weniger Strom und/oder lässt sich höher takten, d.h. man wird sicherlich nen höheren Verkaufspreis erzielen können.Bei gleichen Transistorkosten dürfte sich 20nm für andere Produkte erst lohnen, wenn der Yield mit 28nm vergleichbar ist, da dann mehr Chips aus einem Wafer geholt werden können. Alles eine Kalkulation mit zig uns unbekannten Parametern.
Aber natürlich hast Du recht ... da gibts viele Parameter und das blöde ist, dass man die Yields nicht vor dem Produktionsstart kennt ^^
Im Spezialfall von Globalfoundries wird AMD sicherlich aber auch erstmal mit schlechten Yields rechnen (wenn GF Dies überhaupt gebacken bekommt ^^)
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
") meinte natürlich die Kosten / Transistor die für 20nm gleich denen bei 28nm sein sollen, wie es hier schon verschiedentlich angesprochen wurde. Da derselbe Chip bei 28nm und 20nm die gleiche Transistoranzahl hat, folgt daraus dass der Chip Preis in der Produktion gleich bliebe. Da man bei 20nm durch geringeren Verschnitt im Randbereich mehr als die doppelte Menge an Chips unterbringt, folgt daraus, dass die Waferkosten mehr als das doppelte betragen.
meinte natürlich die Kosten / Transistor die für 20nm gleich denen bei 28nm sein sollen, wie es hier schon verschiedentlich angesprochen wurde. Da derselbe Chip bei 28nm und 20nm die gleiche Transistoranzahl hat, folgt daraus dass der Chip Preis in der Produktion gleich bliebe. Da man bei 20nm durch geringeren Verschnitt im Randbereich mehr als die doppelte Menge an Chips unterbringt, folgt daraus, dass die Waferkosten mehr als das doppelte betragen. Jetzt müßte man nur noch wissen, ob sich die Kosten / Transistor, welche meines Wissens auf einer Folie von Nvidia auftauchten und ich meine auch seitens AMD schon davon gehört/gelesen zu haben, sich auf den ganzen Wafer beziehen oder auf die good Dies.
Ich finde meine Argumentationskette etwas plausiblerSelbst wenn da ein Wafer doppelt so teuer ist,

Und eben mehr Transistoren in großen Chips unterbringen die für 28nm zu groß wären und dadurch einen miserablen Yield hätten.Die Kosten wären in dem Fall dann zwar "nur" gleich, aber so ein 20nm Die verbraucht weniger Strom und/oder lässt sich höher takten, d.h. man wird sicherlich nen höheren Verkaufspreis erzielen können.
Mhh, da fällt mir ein, beim letztem Intel shrink war nicht so viel mit mehr Takt oder weniger Strom, hab das aber nicht so richtig verfolgt und bringe da womöglich was durcheinander.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wieso?
Ne das eine sind doch 28nm Transistoren, das andere 20nm. die 20nm sind enger gepackt -> mehr Transistoren pro Wafer -> mehr Chips pro Wafer -> weniger Kosten pro Die *falls* ein 20nm Wafer den gleichen Preis hätte wie ein 28nm Wafer.Da derselbe Chip bei 28nm und 20nm die gleiche Transistoranzahl hat, folgt daraus dass der Chip Preis in der Produktion gleich bliebe.
Wieso nur im Randbereich? Das macht vielleicht max. so 5-10 Dies aus, wenn wir von kleinen DIes wie Kabini reden, passen ca. 500 davon in 28nm auf nen 300 mm Wafer, bei 20nm wärens knapp über 1000, der Randverschnitt spielt da keine große Rolle.Da man bei 20nm durch geringeren Verschnitt im Randbereich mehr als die doppelte Menge an Chips unterbringt, folgt daraus, dass die Waferkosten mehr als das doppelte betragen.
Ich kann Dir da aber leider überhaupt nicht folgenIch finde meine Argumentationskette etwas plausibler

Yields sind von vielen Faktoren abhängig, Du nennst jetzt die Die-Größe. Ist ein Faktor, der *für* 20nm spräche, das stimmt, aber ich hab ihn nicht erwähnt, da ein eingefahrenen 28nm Prozess gegen nen neuen 20nm Prozess verglichen wird. Da ist der Faktor der Erfahrungskurve der wichtigere. Der eingefahrene 28nm Prozess hat pro Wafer schlicht weniger Defekte, die man meiner Einschätzung nach nicht mit kleineren Dies wettmachen kann. Defekt ist Defekt, kleinere Dies sind zwar besser, aber nicht so gut wie weniger Defekte/WaferUnd eben mehr Transistoren in großen Chips unterbringen die für 28nm zu groß wären und dadurch einen miserablen Yield hätten.
")
Intel hat auch Probleme, der 22nm Prozess ist/war noch nicht optimal, aber teilweise limitieren sie sich durch die miserable Paste zw. Gehäuse und DIE selbst. Da muss man mal auf die Ivy-E CPUs warten die bald kommen, die sind verlötet. Bin gespannt wie die laufen werden. So oder so, sie haben nen 2xnm Prozess mit Finfets in Massenproduktion, von sowas kann GF nur träumen.Mhh, da fällt mir ein, beim letztem Intel shrink war nicht so viel mit mehr Takt oder weniger Strom, hab das aber nicht so richtig verfolgt und bringe da womöglich was durcheinander.
Bei Haswell spielt außerdem auch noch mit rein, dass sie da FMA eingeführt haben, was die Rechenleistung verdoppelt. Damit steigt natürlich auch der Energiebedarf deutlich an, von nichts kommt nichts.
Duplex
Admiral Special
So schlecht kann der Prozess aber nicht sein, einige berichten das ihr Gesamtes System mit einem Ivy Bridge 4,5Ghz ca. 50w weniger verbraucht als ein Sandy Bridge 4,5Ghz.Intel hat auch Probleme, der 22nm Prozess ist/war noch nicht optimal, aber teilweise limitieren sie sich durch die miserable Paste zw. Gehäuse und DIE selbst. Da muss man mal auf die Ivy-E CPUs warten die bald kommen, die sind verlötet. Bin gespannt wie die laufen werden. So oder so, sie haben nen 2xnm Prozess mit Finfets in Massenproduktion, von sowas kann GF nur träumen.
Das sind Fortschritte, das DIE ist nur 160mm² groß und die iGPU hat mehr EUs als beim 32nm SB.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wer hat denn behauptet, dass es überhaupt keine Fortschrätte gäbeSo schlecht kann der Prozess aber nicht sein, einige berichten das ihr Gesamtes System mit einem Ivy Bridge 4,5Ghz ca. 50w weniger verbraucht als ein Sandy Bridge 4,5Ghz.
Das sind Fortschritte, das DIE ist nur 160mm² groß und die iGPU hat mehr EUs als beim 32nm SB.

Abgesehen davon gibts auch "einige", die nichtmal 4,5 Ghz schaffen, da sie es nicht gekühlt bekommen. Sinnlose Rosinenpickerei je nach Standpunkt ...
nVoodoo
Vice Admiral Special
- Mitglied seit
- 16.03.2007
- Beiträge
- 531
- Renomée
- 1
- Standort
- Nördliches Emsland
- Meine Systeme
- R7 1700;2xX5650;i7 4700MQ;2x E5430;Athlon 5350
- BOINC-Statistiken
So schlecht kann der Prozess aber nicht sein, einige berichten das ihr Gesamtes System mit einem Ivy Bridge 4,5Ghz ca. 50w weniger verbraucht als ein Sandy Bridge 4,5Ghz.
Das sind Fortschritte, das DIE ist nur 160mm² groß und die iGPU hat mehr EUs als beim 32nm SB.
Ohne iGPU Anteil wäre Ivy/HW nur noch sehr schwer zu kühlen sein... allein deshalb muss Intel den iGPU Anteil aufbohren... Und solange kein anderer vergleichbar komplexer Chip geshrinkt wird von 32nm auf 22nm kann man die Qualität von Intel's Prozess auch nicht genau beurteilen weil man keine Vergleichswerte hat... Ich meine es wundert ja nun wirklich keinen das von 32nm -> 22nm die Effizenz steigt (bei ungefähr gleicher Chipbasis)
BTW: Es wird schon wieder sehr OT...
Zuletzt bearbeitet:
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Die Betrachtung der kleinsten Kosteneinheit der Fertigung kann durchaus sinnvoll sein, derartige Folien hatten wir schon vor längerer Zeit in einem anderen Thread. Insbesondere für die Betrachtung des Shrinks eines Designs oder einer Weiterentwicklung mit gleichem oder ähnlichem Transistorbudget haben die "Transistorkosten" doch eine direkte Aussagekraft.Ne das eine sind doch 28nm Transistoren, das andere 20nm. die 20nm sind enger gepackt -> mehr Transistoren pro Wafer -> mehr Chips pro Wafer -> weniger Kosten pro Die *falls* ein 20nm Wafer den gleichen Preis hätte wie ein 28nm Wafer.
nVoodoo
Vice Admiral Special
- Mitglied seit
- 16.03.2007
- Beiträge
- 531
- Renomée
- 1
- Standort
- Nördliches Emsland
- Meine Systeme
- R7 1700;2xX5650;i7 4700MQ;2x E5430;Athlon 5350
- BOINC-Statistiken
Die Betrachtung der kleinsten Kosteneinheit der Fertigung kann durchaus sinnvoll sein, derartige Folien hatten wir schon vor längerer Zeit in einem anderen Thread. Insbesondere für die Betrachtung des Shrinks eines Designs oder einer Weiterentwicklung mit gleichem oder ähnlichem Transistorbudget haben die "Transistorkosten" doch eine direkte Aussagekraft.
Und wie errechnet man die Transistorkosten? Wie teuer 1 Transistor ist weiss man ja erst wenn der Wafer fetig ist und man weiß wie viele Chips am Ende dabei wirklich herrausgekommen sind... und welche Chips hergestellt wurden mit was für einer Packdichte etc. ?!
Das ist doch ein reiner Theoriewert sowas kann man doch nur errechnen wenn man auf dem ganzen Wafer z.B. nur SRam zellen hat oder nicht?
Oder geht es jetzt nur um die reinen Produktionskosten also ohne was "hinten rauskommt" ?!
Zuletzt bearbeitet:
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
An der Kurvenform siehst du ja bereits, dass yields in der Rechnung der Kosten pro Transistor enthalten sind. Das folgende paper geht über die Kalkulation recht ausführlich ins Detail: http://users.ece.cmu.edu/~maly/maly/DAC94.pdf
Die anfangs höheren Verkaufserlöse von effizienteren Chips, dank Transistoren mit besseren elektrostatischen Eigenschaften, stehen natürlich auf einem anderen Blatt.
EDIT:
Ich hoffe, damit wäre der Fertigungs-Exkurs langsam zu Ende gebracht, und die eigentlich interessanten technischen Eigenschaften von Beema werden wieder thematisiert.
Die anfangs höheren Verkaufserlöse von effizienteren Chips, dank Transistoren mit besseren elektrostatischen Eigenschaften, stehen natürlich auf einem anderen Blatt.
EDIT:
Ich hoffe, damit wäre der Fertigungs-Exkurs langsam zu Ende gebracht, und die eigentlich interessanten technischen Eigenschaften von Beema werden wieder thematisiert.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
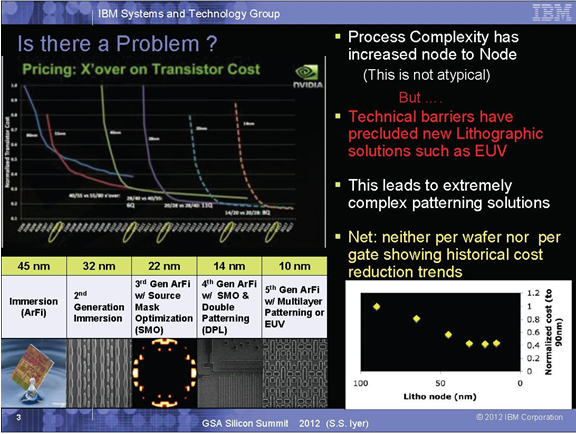
Ach das alte nVidia Schema. Naja ok .. aber so wie ich das sehe sind die aufgetragene "Transistorenkosten" ne Funktion aus Yields, Scaling-Faktor und Waferkosten (X'tor costs unten). Mit dem Scalingfaktor sind also die besseren Packungsdichten in der Kalkulation dabei:
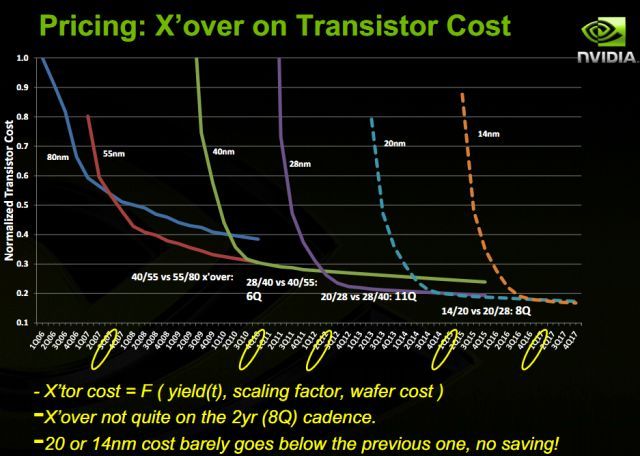
Außerdem sieht man an der Folie auch meine Argumentation. Am Anfang sind die neuen Prozesse ziemlich unrentabel, da die alten besser eingefahren sind.
Edit; Ja stimmt, wir sind hier langsam etwas vom Thema weg ^^
Außerdem sieht man an der Folie auch meine Argumentation. Am Anfang sind die neuen Prozesse ziemlich unrentabel, da die alten besser eingefahren sind.
Edit; Ja stimmt, wir sind hier langsam etwas vom Thema weg ^^
Ich glaub, in der Disziplin Watt/Fläche lag ein Prescott mit seinen 112mm² immer noch ein Stückchen höher.Ohne iGPU Anteil wäre Ivy/HW nur noch sehr schwer zu kühlen sein... allein deshalb muss Intel den iGPU Anteil aufbohren
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Wie von mir bereits Thread erwähnt, je mehr neue Features und technische Neuerungen die nächste "kleine" APU erhalten soll, desto länger wird sich deren Veröffentlichung hinziehen. Laut Digitimes soll Beema/Mullins erst H2/2014 erscheinen. Bis dahin sollen neue Kabini-Modelle (A4-5350, A4-5150, E1-2650) die Wartezeit überbrücken.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wie von mir bereits Thread erwähnt, je mehr neue Features und technische Neuerungen die nächste "kleine" APU erhalten soll, desto länger wird sich deren Veröffentlichung hinziehen. Laut Digitimes soll Beema/Mullins erst H2/2014 erscheinen. Bis dahin sollen neue Kabini-Modelle (A4-5350, A4-5150, E1-2650) die Wartezeit überbrücken.
Ja aber obs an der Technik liegt? Grund scheint mir eher die Verschiebung der Kabini-Desktopmodelle zu sein. Wenn die später kommen, verkauft man die neuen Modelle ebenfalls später, da die alten sonst zu schnell verramscht werden müssen und sich nicht auszahlen. Kann auch ne Rolle bei der Kaveri-Verschiebung sein, Richland ist noch groß im Lager.
Mit Glücl kommt Beema dann doch nach altem Zeitplan - zumindest im Mobilebereich. Da wird Kabini ja schon verkauft.
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Ja. Mehr Neuerungen, mehr und längere Entwicklung, mehr Validierung; ein neuer Prozess, um gegen die 14nm Konkurrenz antreten zu können, würde ebenfalls Zeit kosten.Ja aber obs an der Technik liegt?
Doch um die Frage weniger pauschal beantworten zu können, müsste man wissen, ob die Prioritäten des Unternehmens bei der Produktentwicklung oder der Vermarktung liegen.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Jupp das ist der springende Punkt.Doch um die Frage weniger pauschal beantworten zu können, müsste man wissen, ob die Prioritäten des Unternehmens bei der Produktentwicklung oder der Vermarktung liegen.
Eventuell passt es ihnen auch gut in den Kram, falls Beema schon 20nm sein sollte.
Falls nicht und das Teil noch in 28nm kommt, glaub ichs aber eher weniger. Die "neue Tecknik" ist ja nur der HSA-Baustein aus dem Kaveri/Playstation, glaube jetzt nicht, dass es da irgendwelche super-technischen Nova gäbe. Vermutlich ist Beema auch nur ein "Abfalldesign" aus den Verbesserungen der Konsolenchips.
FredD
Gesperrt
★ Themenstarter ★
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
So gesehen dürften das (weitgehend schon bekannte Bausteine sein, einschließlich GCN 2 und Platform Security Processor (ich vermute aus Kaveri). Connected Standby könnte u.U. auch den Konsolen APUs entstammen, wäre zumindest ganz im Geschmack der XBox. Das H2/14 Release könnte m.M. nach dem Versuch mit fdSOI geschuldet sein (FredD schon wieder mit seiner ollen fd-Kamelle ... ja ja ich weiß )
)Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Seit ich weiss, dass 20nm-FDSOI immer noch gatefirst benutzt bin ich eher skeptisch geworden ...
Eventuell wollen sie da des guten zuviel ... schon bei 28nm wars grenzwertig und jetzt wollen sies selbst noch bei 20nm machen? Auch wenn ich kein Experte bin, bekomm ich bei dem Gedanken leichte Bauchschmerzen, insbesonderer auch deshalb da GFs 28nm mit Gatefirst nicht gerade ruhmreich sonder eher das Gegenteil davon war ...
Eventuell wollen sie da des guten zuviel ... schon bei 28nm wars grenzwertig und jetzt wollen sies selbst noch bei 20nm machen? Auch wenn ich kein Experte bin, bekomm ich bei dem Gedanken leichte Bauchschmerzen, insbesonderer auch deshalb da GFs 28nm mit Gatefirst nicht gerade ruhmreich sonder eher das Gegenteil davon war ...
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 290
- Antworten
- 505
- Aufrufe
- 79K
- Antworten
- 240
- Aufrufe
- 51K