App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Bulldozer rollt an....
- Ersteller neax
- Erstellt am
- Status
- Für weitere Antworten geschlossen.
Dass was wir BD2 2012 sehen, dürften die Früchte eines Jahrelang aufgebauten CPU-Design-Teams sein.Aber sicher fuer das aktuelle Produkt muessen erst andere Dinge gelingen bevor man ueber Zukunft nachdenkt, aber AMD macht es schon fleissig; denn BD2 soll ja 2012 schon auf den Markt kommen - sprich die Gendanken sollte sich AMD gemacht haben - sprich der Tapeout sollte nicht mehr ganz so weit weg sein...oder?
Ende 2005 machte AMD aufgrund des finanziellen Athlon X2-Erfolg ein 2. CPU-Entwickler-Team, neben vielleicht einem CPU-Execution-Team
AFAIK wurde zu dieser Zeit auch ein CPU-Entwickler-Zentrum in Indien errichtet.
(Ob das jetzt das 2. CPU-Entwickler-Team ist oder nur Unterschützer der von 2. Teams in den USA oder sonst wie arbeiten, weiß ich nicht)
Ein halbes Jahr später wurde Bobcat & Bulldozer & Fusion sowie der ATI-Kauf präsentiert.
Mit den ATI-Kauf, erhielten sich noch ein "Chipsatz-Team".
Vereinfacht (=eventuell falsch) und Daumen-mal-Pi, arbeiteten primär
1. CPU-Team am Bulldozer
2. CPU-Team am Bobcat
"Chipsatz-Team" an den Fusions (Ontario, Fusion)
wobei das R&D-Center in Indien vielleicht überall dazu half.
Der Erste Große Auftrag von Indien-Center dürfte die K10-Optemierung/Exection alias Shanghai sein, um Erfahrungen zu Sammenln.
Und diesemal könnte es vielleicht ähnlich laufen. Während das 1. CPU-Team an BD1.0 bis 2009 arbeitet und dann gleich danach am BD2.0 bis 2011 weiterarbeitet, könnte das Excection-Team mit Hilfe von Shanghai den Bulldozer-Serienreif gemacht haben.
Kurz gesagt, die Kurzen Entwicklungszeiten sind möglich, weil ein zusätzliches R&D-Team bzw./sowie das Indien-R&D-Center in der Vergangenheit aufgebaut (=Einstellen und Erfahrung sammeln) wurde.
Somit ist es möglich Fusion-Modelle (je eines mit Bobcat-Kern & K10/Bulldozer-Kern) jedes Jahr am Markt neu konfiguriert (mit leichten (Core?-)Verbesserungen) zu bringen und dass AMD 2-x86-gleichzeitig entwickeln konnte bzw. weiterentwickeln kann. (statt nur Eines, wie es früher üblich war)
Somit sieht die Zukunft von AMD viel besser als früher aus, wo AMD damals nur EINE Architektur entwickeln und pflegen konnte ( K8 ) während Intel DREI Architketuren entwickeln und pflegen konnte alias zuerst Pentium-M, Itanium, Netburst und später Larabee, Core2/Sandy-Bridge, Atom.
Dazu hatte AMD damals keine Plattformen
Heute entwickelt & pflegen sie ZWEI Architketuren sowie dazu Plattformen.
Mit Einführung von Llano & Bulldozer (& Bobcat) Mitte 2011 dürften wir die ersten Früchte sehen, von einem R&D-Aufbau (=Einstellen sowie Erfahrung sammeln, sowie den laden ins Laufen bringen) was Ende 2005 begonnen wurde.
Und wenn der Laden gut läuft, läuft er auch die nächsten Jahre gut weiter.
AMD hat bald in kürze keine echten Nachteile mehr, sodass ein stablierer Finanzverlauf zu erwarten ist.
Mit Fusion (inkl. UVD 3.0 & DX11) sind sie Technologie sogar mal vorne.
Zwar sieht es in kürze vielleicht besser gegen Intel aus als früher, aber es formiert sich gerade mit ARM eine neue Front und da ist es gut, wenn der AMD-Laden bzw. AMD-Entwicklungen gut laufen.
Edit: Zumindestens habe ich es so mitbekommen.
Zuletzt bearbeitet:
Ich würde das eher so lesen, dass die Programmierer das in ihrer Software entscheiden können wie die Auslastung verteilt wird - das fände ich ja mal richtig cool.
Noch besser wäre es wenn es dann ein Tool gäbe wo jeder User das selber switchen kann auf OS Ebene. Vielleicht installiere ich mir dann doch noch das Fusion-Desktop Tool
http://sites.amd.com/us/game/downloads/fusion-for-desktops/Pages/overview.aspx
Und was soll mit den Tasks passieren die das Betriebssystem mitbringt ?
LinuS
Vice Admiral Special
Und ich dachte, dass bereits Barcelona aus Indien stammtDer Erste Große Auftrag von Indien-Center dürfte die K10-Optemierung/Exection alias Shanghai sein, um Erfahrungen zu Sammenln.
")

cumec
Admiral Special
- Mitglied seit
- 03.05.2006
- Beiträge
- 1.305
- Renomée
- 19
- Standort
- Schüttorf / Niedersachsen
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Simap, Spin
- Lieblingsprojekt
- Simap
- Meine Systeme
- Phenom X4 @ 3000MHz
- BOINC-Statistiken

- Folding@Home-Statistiken
- Details zu meinem Desktop
- Prozessor
- Phenom II X6 1075T @ 3900MHz
- Mainboard
- Gigabyte MA790GP-DS4H
- Kühlung
- Gelid Tranquillo
- Speicher
- 8GB PC 800
- Grafikprozessor
- Saphire HD4850 - 512mb
- Display
- ViewSonic VA2216w / Eizo Flexscan L695
- HDD
- 64GB OCZ Agility 2 / 1TB Samsung F3
- Optisches Laufwerk
- Samsung DVD-ROM 16x
- Soundkarte
- Onboard
- Gehäuse
- Chieftec Bravo BA-01
- Netzteil
- be quiet! Straight Power E5 500W
- Betriebssystem
- Win7 Professional 64bit / Ubuntu 64bit
- Webbrowser
- Fox 4
Und ich dachte, dass bereits Barcelona aus Indien stammt
Dem ist meines Wissens auch so.
The Bulldozer 2-core CPU module contains 213M transistors in an 11-metal layer 32nm high-k metalgate SOI CMOS process and is designed to operate from 0.8 to 1.3V. This micro-architecture improves performance and frequency while reducing area and power over a previous AMD x86-64 CPU in the same process. The design reduces the number of gates/cycle relative to prior designs, achieving 3.5GHz+ operation in an area (including 2MB L2 cache) of 30.9mm2.
Kann das mal jemand vergleichen mit Phenom II und Sandy Bridge?
Hab extra links dazu rausgesucht
http://www.anandtech.com/show/2775
http://www.tomshardware.com/reviews/sandy-bridge-core-i7-2600k-core-i5-2500k,2833-2.html


Dresdenboy
Redaktion
☆☆☆☆☆☆
Das wurde alles schon im November beackertKann das mal jemand vergleichen mit Phenom II und Sandy Bridge?
Hab extra links dazu rausgesucht
http://www.anandtech.com/show/2775
http://www.tomshardware.com/reviews/sandy-bridge-core-i7-2600k-core-i5-2500k,2833-2.html
Siehe z.B. auch hier auf XS:http://67.90.82.13/forums/showthread.php?p=4638148#post4638148 ff. (weiter unten gibt es einen Core-Größen-Vergleich.
Hier auf P3DNow! habe ich es mit er Suche nicht so schnell gefunden. Wer kann helfen?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
SUpi ... ISSCC Präsentation ist rum, aber nirgends gibts Infos.
Halt ne - hier ein kleines Stückchen:
Soviel also zum Thema gesteigerte IPC ...
Hab aber noch ein Stückchen Hoffnung, dass da was mit dem Bobcat Kern verwechselt wurde ... mal abwarten, was noch durchsickert und ob AMD mal Ihren BLOG aktualisieren.
Auch wahrscheinlich ist die Verwechslung des Autors von "past AMD cores" mit der alten Hot Chips Aussage "180% Leistung eines Bulldozer CMP Designs". Ich hoffe mal das wars. Gab damals ja bereits mehrere, die das verwechselten.
Zum ersten, allgemeinen BD Beitrag steht in der verlinkten Quelle nur das, was schon im Abstract stand, Transistoren, Takt, Spannung, Die-Size. Das hätte sich der Autor dann gleich ganz sparen können.
Halt ne - hier ein kleines Stückchen:
http://www.eetimes.com/electronics-...na-eyes-petaflops-IBM-hits-5-GHz?pageNumber=2A separate paper described Bulldozer's 40-entry instruction out-of-order scheduler and execution unit that can issue up to four instructions per cycle. The unit helps the core meet its target of delivering 90 percent of performance of past AMD cores with a significant reduction in area and power, said Michael Golden, another AMD engineer.
Soviel also zum Thema gesteigerte IPC ...
Hab aber noch ein Stückchen Hoffnung, dass da was mit dem Bobcat Kern verwechselt wurde ... mal abwarten, was noch durchsickert und ob AMD mal Ihren BLOG aktualisieren.
Auch wahrscheinlich ist die Verwechslung des Autors von "past AMD cores" mit der alten Hot Chips Aussage "180% Leistung eines Bulldozer CMP Designs". Ich hoffe mal das wars. Gab damals ja bereits mehrere, die das verwechselten.
Zum ersten, allgemeinen BD Beitrag steht in der verlinkten Quelle nur das, was schon im Abstract stand, Transistoren, Takt, Spannung, Die-Size. Das hätte sich der Autor dann gleich ganz sparen können.
Zuletzt bearbeitet:
p4z1f1st
Grand Admiral Special
- Mitglied seit
- 28.04.2003
- Beiträge
- 9.722
- Renomée
- 81
- Details zu meinem Desktop
- Prozessor
- AMD FX-6300
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- HEATKILLER® CPU Rev3.0 LC + HEATKILLER® GPU-X² 69x0 LT
- Speicher
- 2x 4096 MB G.Skill RipJawsX DDR3-1600 CL7
- Grafikprozessor
- AMD Radeon RX 480 8GB
- Display
- Dell U2312HM
- HDD
- Crucial m4 SSD 256GB
- Optisches Laufwerk
- Sony Optiarc AD-7260S
- Soundkarte
- Creative Labs SB Audigy 2 ZS
- Gehäuse
- Chieftec Scorpio TA-10B-D (BxHxT: 205x660x470mm)
- Netzteil
- Seasonic X-Series X-660
- Betriebssystem
- Microsoft Windows 10 Professional 64bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- Watercool HTF2 Dual + 2x Papst 4412 F/2GL
Könnt ihr euch alle nicht einfach bis heute in einer Woche gedulden? ")
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wozu, die Präsentation ist doch gelaufen ^^Könnt ihr euch alle nicht einfach bis heute in einer Woche gedulden?
Sag mal nen eingefleischten Fußballfan er solle auf den Spielbericht des letzten Spieltages seiner Mannschaft ne Woche warten ^^
@ONH:
Ah ok, ist mir nicht aufgefallen ... wer sich das wohl wieder ausgedacht hat ... ? Intel hat ein paar Itanium Infos ja auch schon vorab verbreitet.
p4z1f1st
Grand Admiral Special
- Mitglied seit
- 28.04.2003
- Beiträge
- 9.722
- Renomée
- 81
- Details zu meinem Desktop
- Prozessor
- AMD FX-6300
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- HEATKILLER® CPU Rev3.0 LC + HEATKILLER® GPU-X² 69x0 LT
- Speicher
- 2x 4096 MB G.Skill RipJawsX DDR3-1600 CL7
- Grafikprozessor
- AMD Radeon RX 480 8GB
- Display
- Dell U2312HM
- HDD
- Crucial m4 SSD 256GB
- Optisches Laufwerk
- Sony Optiarc AD-7260S
- Soundkarte
- Creative Labs SB Audigy 2 ZS
- Gehäuse
- Chieftec Scorpio TA-10B-D (BxHxT: 205x660x470mm)
- Netzteil
- Seasonic X-Series X-660
- Betriebssystem
- Microsoft Windows 10 Professional 64bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- Watercool HTF2 Dual + 2x Papst 4412 F/2GL
Heute in einer WocheWozu, die Präsentation ist doch gelaufen ^^
Sag mal nen eingefleischten Fußballfan er solle auf den Spielbericht des letzten Spieltages seiner Mannschaft ne Woche warten ^^
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ja der nächste Spieltag ist sicher auch ganz interessant, aber mich würde halt auch das aktuelle Resultat intreressieren
Naja abwarten, was anders bleibt einen nicht übrig.
Onkel_Dithmeyer
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 22.04.2008
- Beiträge
- 12.943
- Renomée
- 4.014
- Standort
- Zlavti
- Aktuelle Projekte
- Universe@home
- Lieblingsprojekt
- Universe@home
- Meine Systeme
- cd0726792825f6f563c8fc4afd8a10b9
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- Ryzen 9 3900X @4000 MHz//1,15V
- Mainboard
- MSI X370 XPOWER GAMING TITANIUM
- Kühlung
- Custom Wasserkühlung vom So. G34
- Speicher
- 4x8 GB @ 3000 MHz
- Grafikprozessor
- Radeon R9 Nano
- Display
- HP ZR30W & HP LP3065
- SSD
- 2 TB ADATA
- Optisches Laufwerk
- LG
- Soundkarte
- Im Headset
- Gehäuse
- Xigmatek
- Netzteil
- BeQuiet Dark Pro 9
- Tastatur
- GSkill KM570
- Maus
- GSkill MX780
- Betriebssystem
- Ubuntu 20.04
- Webbrowser
- Firefox Version 94715469
- Internetanbindung
- ▼100 Mbit ▲5 Mbit
Muss man eben ein wenig suchen
http://www.tweakpc.de/news/20453/amd-bulldozer-takt-und-performance-zahlen-auf-der-isscc/
edit:
ich seh grad, die berufen sich auf deine Quelle... mist ^^
http://www.tweakpc.de/news/20453/amd-bulldozer-takt-und-performance-zahlen-auf-der-isscc/
edit:
ich seh grad, die berufen sich auf deine Quelle... mist ^^
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Irgendwie bist du mir mit deinen Rückschlüssen immer zu schnell. Und dass du dich dabei schon mal etwas zu weit aus dem Fenster lehnst, muss ich hoffentlich nicht erwähnen. Ups, jetzt habe ich es doch gemacht.SUpi ... ISSCC Präsentation ist rum, aber nirgends gibts Infos.
Halt ne - hier ein kleines Stückchen: http://www.eetimes.com/electronics-...na-eyes-petaflops-IBM-hits-5-GHz?pageNumber=2
Soviel also zum Thema gesteigerte IPC ...
Wo steht hier etwas von IPC? Da steht nur etwas von Scheduler und Ausführungseinheiten. Zu IPC gehört aber noch einiges mehr dazu.Vergleichen wir doch K10 und Bulldozer mal total simpel. K10 hat je Kern 3x ALU + 3x AGU und je ALU/AGU einen 8-entry Scheduler. Bulldozer hat nunmehr je "Kern" einen einzigen 40-entry Scheduler und 2x ALU + 2x AGU. Nimmt man die Ausführungseinheiten als Basis, dürfte ein Bulldozer "Kern" nur 2/3 bzw 66,67% der theoretischen Leistungsfähigkeit eines K10 Kerns bereitstellen können. Nun spricht der Ingenieur aber von 90%, was eine gesteigerte Effizienz von 35% wäre. Nicht schlecht, wenn du mich fragst. Gehen wir einfach mal davon aus, dass das Frontend einen ähnlichen Effizienzschub erhalten hat und damit die gesamte Pipeline 35% effizienter arbeitet. Was bleibt unterm Strich übrig?
[K10]
theoretische Leistungsfähigkeit (EUs) = 100%
Effizienz = 100%
-> IPC = 100% (theoretische Leistungsfähigkeit * Effizienz)
[Bulldozer]
theoretische Leistungsfähigkeit (EUs) = 90%
Effizienz = 135%
-> IPC = 121,5% (theoretische Leistungsfähigkeit * Effizienz)
Das heisst, die theoretische Leistungsfähigkeit ist zwar geringer, aufgrund der verbesserten Effizienz steigt die IPC aber trotzdem um über 20%.
Also immer schön vorsichtig sein, was man in welche Aussagen hineininterpretiert.
nonworkingrich
Captain Special
- Mitglied seit
- 28.04.2006
- Beiträge
- 234
- Renomée
- 4
Bitte was?!?! 
20% mehr IPC und höherer Takt und trotzdem nur 90% Performance? Da haben wohl gleich mehrere Raum-Zeit-Dimensionsfalten zugeschlagen.
20% mehr IPC und höherer Takt und trotzdem nur 90% Performance? Da haben wohl gleich mehrere Raum-Zeit-Dimensionsfalten zugeschlagen.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Interessante Diskussion zum BD-Beitrag auf dem ISSCC gestern hier auf dem semiaccurate-forum:
Damit lassen sich womöglich einige Dinge besser spekulieren:
"The unit helps the core meet its target of delivering 90 percent of performance of past AMD cores with a significant reduction in area and power, said Michael Golden, another AMD engineer."
1) Offenbar kann im multithreaded Betrieb die IPC des bisherigen K10.5-Cores (="past AMD cores") nur zu ca. 90% erreicht werden, wofür aber gewaltig Enerige und Diesize gespart werden; d.h. der Vergleich bezieht sich wohl klar auf K10.5; entsprechend war auch meine gestrige Überlegung, dass man nun eine theroetische Obergrenze von 2 bei der IPC hat.
2) Damit kann der Kommentar von JF-AMD, dass der 16-Core-BD rund 50% mehr "Throughput" hat, als Magny-Cours mit 12 Cores, auch besser einordnen: "Throuhput" interpretiere ich als optimalen multithreaded Einsatz, also dass alle Cores optimal genutzt werden. Nachdem aber dann ein BD-Core nur 90% der IPC von Magny-Cours hat, lassen sich Andeutungen zur nötigen Taktfrequenz ableiten: 150%*(12/16)/0,9=1,25 => um das zu erfüllen, bräuchte dann BD eine rund 25% höhere Taktfrequenz.
3) Diese Spekulation mit +25% an Takt wird ja möglich auch durch die Info letztens (hab leider den Link nicht) über den ersten Super-Computer mit BD-16Core-CPUs unterstützt, wo ja die Rede von 2,5Ghz ist, womit dann womöglich die Base-Fequenz gemeint sein könnte, weil ich ja für den "Throughput" maximalen multithreaded Einsatz unterstelle, sodass in diesem Fall die Cores voll ausgelastet sein müssten, also ein Turbo-Einsatz so gut wie ausfällt. Erste Magny-Cours hatten (glaube ich) 2,1Ghz => 2,5Ghz wären nicht mal +20%
4) Zur Ableitung der SC-Performance: mach dem bekannten Aufbau des BD-Moduls dürfte man davon ausgehen, dass im singlethreaded Einsatz ein ganzes BD-Modul deultich mehr IPC ermöglichen sollte, als ein einzelnes bisheriges K10.5-Cores: ich unterstelle hier eine um 10% höhere IPC. Mit 2) unterstelle ich einen BD-Grundtakt von rund +25% gegenüber K10.5, darauf käme dann noch der Turbo-Modus (nochmal rund +15% angenommen). Mit diesen Annahmen würde ein BD-Modul eine singletreaded Leistung im Vergleich zu K10.5 von 1,25*1,15*1,1=1,58 erreichen
Ok, 158% an singlethreaded Leistung im Vergleich zu K10.5 dürfte etwas viel sein, wenn ein Modul auch "nur" 180% an multithreaded Leistung gegenüber K10.5 hat. Allerdings ist ein Teil dieser 158% dem Turbo-Modus zuzurechnen, welcher ja auch heute eine Erhöhung singlethreaded Leistung ermöglicht, ohne Turbo blieben als 1,1*1,25=137,5%. Sollte aber sowas in der Art heraus kommen, wäre diese Modul-Lösung von BD schon eine schöne µ-Architektur.
...alles nur meine persönliche Spekulation und Interpretation
Damit lassen sich womöglich einige Dinge besser spekulieren:
"The unit helps the core meet its target of delivering 90 percent of performance of past AMD cores with a significant reduction in area and power, said Michael Golden, another AMD engineer."
1) Offenbar kann im multithreaded Betrieb die IPC des bisherigen K10.5-Cores (="past AMD cores") nur zu ca. 90% erreicht werden, wofür aber gewaltig Enerige und Diesize gespart werden; d.h. der Vergleich bezieht sich wohl klar auf K10.5; entsprechend war auch meine gestrige Überlegung, dass man nun eine theroetische Obergrenze von 2 bei der IPC hat.
2) Damit kann der Kommentar von JF-AMD, dass der 16-Core-BD rund 50% mehr "Throughput" hat, als Magny-Cours mit 12 Cores, auch besser einordnen: "Throuhput" interpretiere ich als optimalen multithreaded Einsatz, also dass alle Cores optimal genutzt werden. Nachdem aber dann ein BD-Core nur 90% der IPC von Magny-Cours hat, lassen sich Andeutungen zur nötigen Taktfrequenz ableiten: 150%*(12/16)/0,9=1,25 => um das zu erfüllen, bräuchte dann BD eine rund 25% höhere Taktfrequenz.
3) Diese Spekulation mit +25% an Takt wird ja möglich auch durch die Info letztens (hab leider den Link nicht) über den ersten Super-Computer mit BD-16Core-CPUs unterstützt, wo ja die Rede von 2,5Ghz ist, womit dann womöglich die Base-Fequenz gemeint sein könnte, weil ich ja für den "Throughput" maximalen multithreaded Einsatz unterstelle, sodass in diesem Fall die Cores voll ausgelastet sein müssten, also ein Turbo-Einsatz so gut wie ausfällt. Erste Magny-Cours hatten (glaube ich) 2,1Ghz => 2,5Ghz wären nicht mal +20%
4) Zur Ableitung der SC-Performance: mach dem bekannten Aufbau des BD-Moduls dürfte man davon ausgehen, dass im singlethreaded Einsatz ein ganzes BD-Modul deultich mehr IPC ermöglichen sollte, als ein einzelnes bisheriges K10.5-Cores: ich unterstelle hier eine um 10% höhere IPC. Mit 2) unterstelle ich einen BD-Grundtakt von rund +25% gegenüber K10.5, darauf käme dann noch der Turbo-Modus (nochmal rund +15% angenommen). Mit diesen Annahmen würde ein BD-Modul eine singletreaded Leistung im Vergleich zu K10.5 von 1,25*1,15*1,1=1,58 erreichen
Ok, 158% an singlethreaded Leistung im Vergleich zu K10.5 dürfte etwas viel sein, wenn ein Modul auch "nur" 180% an multithreaded Leistung gegenüber K10.5 hat. Allerdings ist ein Teil dieser 158% dem Turbo-Modus zuzurechnen, welcher ja auch heute eine Erhöhung singlethreaded Leistung ermöglicht, ohne Turbo blieben als 1,1*1,25=137,5%. Sollte aber sowas in der Art heraus kommen, wäre diese Modul-Lösung von BD schon eine schöne µ-Architektur.
...alles nur meine persönliche Spekulation und Interpretation
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Theoretische Performance, nicht tatsächliche Performance. Die tatsächliche Performance hängt ja auch von Code und Auslastung ab. Wenn die Auslastung also entsprechend höher ist, kann auch die IPC steigen, trotz weniger theoretischer Performance.Bitte was?!?!
20% mehr IPC und höherer Takt und trotzdem nur 90% Performance?
Ausserdem war hier von Takt keine Rede.Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wo steht da was von Scheduler und Ausührungseinheiten ?Irgendwie bist du mir mit deinen Rückschlüssen immer zu schnell. Und dass du dich dabei schon mal etwas zu weit aus dem Fenster lehnst, muss ich hoffentlich nicht erwähnen. Ups, jetzt habe ich es doch gemacht.
Ich zitiers mal nochmal:
Es geht ganz eindeutig um den vollen Kern, und der hätte angeblich nur 90%, wenn sich der Author da mal nicht verschrieben hat. Das ist unmissverständlich.The unit helps the core meet its target of delivering 90 percent of performance of past AMD cores
nonworkingrich
Captain Special
- Mitglied seit
- 28.04.2006
- Beiträge
- 234
- Renomée
- 4
Aber ein Kern besteht nunmal aus Scheduler und Ausführungseinheiten. Deshalb ist es wichtig, dass man die Rechnung auch umgekehrt führt, dann kommt man schon auf realistischere 40% höhere IPC.
Was natürlich grob falsch gerechnet ist, im nvidia performance enhancement calculation manual steht, wie es richtig geht:
120% (Scheduler) + 120% (EUs) = 240%
Beim Cache gabs sicher auch Verbesserungen in derselben Größenordnung, macht summa summarum stolze 360%, die BD (wir setzen noch schnell ein + vor die 360) schneller ist, mithin also fast fünfmal so schnell. Da muss Ivy Bridge sich warm anziehen.
Was natürlich grob falsch gerechnet ist, im nvidia performance enhancement calculation manual steht, wie es richtig geht:
120% (Scheduler) + 120% (EUs) = 240%
Beim Cache gabs sicher auch Verbesserungen in derselben Größenordnung, macht summa summarum stolze 360%, die BD (wir setzen noch schnell ein + vor die 360) schneller ist, mithin also fast fünfmal so schnell. Da muss Ivy Bridge sich warm anziehen.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Hier eine andere Ausführung bzgl. der IPC von BD-Core zu aktellem Core:
"...As Michael Golden, an AMD engineer, explained during its presentation, each dual-core module, when fully loaded, is capable of delivering 90% of the speed of a similar native dual-core processor, while featuring a lower power consumption and utilizing less die space.
This enables AMD to pack more cores inside the same die space and power budget..."
Also wie von mir vorhin angenommen:
Vergleich zwischen:
BD-"module" und "native dualcore" oder anders: die Gesamt-Leistung eines BD-Modules im Vergleich zu zwei eigenständigen ("native") Cores (wohl der K10.5-Klasse)
Und "fully loaded" => wohl keine Turbo-mode und multithreaded
Dabei "lower power" und weniger "die space"
.
EDIT :
.
Mehr von Tim Fischer und Michael Golden:
"...“Bulldozer’s” integer data and processor control sequencing are handled in the Integer Execution Unit (EX). This unit consists of a 1-cycle out-of-order instruction scheduler, four integer pipelines, and a Level1 Data Cache. The design also includes significant circuit and floorplan changes to improve frequency (speed) while reducing per core power rating over previous designs. Handling up to four 64-bit instructions per thread, the EX unit improves instruction scheduling and execution while significantly improving frequency/B] and power over previous designs. The ISSCC paper will describe the logic and circuit design of the EX instruction scheduler and datapaths. It will also detail how Bulldozer’s high frequency is achieved using robust, reliable circuit designs.."
"...All of this is required so that the module gives high architectural performance, measured in the number of instructions completed per cycle (IPC).
Building circuits to meet these constraints is quite a challenge, given the module’s aggressive frequency target..."
"...As Michael Golden, an AMD engineer, explained during its presentation, each dual-core module, when fully loaded, is capable of delivering 90% of the speed of a similar native dual-core processor, while featuring a lower power consumption and utilizing less die space.
This enables AMD to pack more cores inside the same die space and power budget..."
Also wie von mir vorhin angenommen:
Vergleich zwischen:
BD-"module" und "native dualcore" oder anders: die Gesamt-Leistung eines BD-Modules im Vergleich zu zwei eigenständigen ("native") Cores (wohl der K10.5-Klasse)
Und "fully loaded" => wohl keine Turbo-mode und multithreaded
Dabei "lower power" und weniger "die space"
.
EDIT :
.
Mehr von Tim Fischer und Michael Golden:
"...“Bulldozer’s” integer data and processor control sequencing are handled in the Integer Execution Unit (EX). This unit consists of a 1-cycle out-of-order instruction scheduler, four integer pipelines, and a Level1 Data Cache. The design also includes significant circuit and floorplan changes to improve frequency (speed) while reducing per core power rating over previous designs. Handling up to four 64-bit instructions per thread, the EX unit improves instruction scheduling and execution while significantly improving frequency/B] and power over previous designs. The ISSCC paper will describe the logic and circuit design of the EX instruction scheduler and datapaths. It will also detail how Bulldozer’s high frequency is achieved using robust, reliable circuit designs.."
"...All of this is required so that the module gives high architectural performance, measured in the number of instructions completed per cycle (IPC).
Building circuits to meet these constraints is quite a challenge, given the module’s aggressive frequency target..."
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Jo, aber ich gehe mal davon aus, dass der Autor wenigstens das weiss ^^Aber ein Kern besteht nunmal aus Scheduler und Ausführungseinheiten.
Aht sich aber anscheinend eh schon aufgelöst, zumindest schreibt jetzt die letzte Quelle das so wie ich schon mutmaßte:
Also der übliche Vergleich zu nem hypothetischen CMP Bulldozer, nicht zu nem "alten AMD Kern". So passt das"...As Michael Golden, an AMD engineer, explained during its presentation, each dual-core module, when fully loaded, is capable of delivering 90% of the speed of a similar native dual-core processor, while featuring a lower power consumption and utilizing less die space.

Mehr von Tim Fischer und Michael Golden:
"...“Bulldozer’s” integer data and processor control sequencing are handled in the Integer Execution Unit (EX). This unit consists of a 1-cycle out-of-order instruction scheduler, four integer pipelines, and a Level1 Data Cache. The design also includes significant circuit and floorplan changes to improve frequency (speed) while reducing per core power rating over previous designs. Handling up to four 64-bit instructions per thread, the EX unit improves instruction scheduling and execution while significantly improving frequency/B] and power over previous designs. The ISSCC paper will describe the logic and circuit design of the EX instruction scheduler and datapaths. It will also detail how Bulldozer’s high frequency is achieved using robust, reliable circuit designs.."
"...All of this is required so that the module gives high architectural performance, measured in the number of instructions completed per cycle (IPC).
Building circuits to meet these constraints is quite a challenge, given the module’s aggressive frequency target..."
Thx, wobei ich mich da jetzt auch frage, wo der Rest ist

Ich mein Du Jungs verraten nicht viel mehr als schon im Abtract stand, für die Details verweisen sie aufs ISSCC Paper ...
Blöd ...Aja und das Front-End wird anscheinend immer noch nicht offen gelegt:
This paper describes design techniques used to wring maximum performance from the GLOBALFOUNDRIES 32nm SOI manufacturing process. Changes in clocking, latching, power management and on-chip memories are part of the comprehensive circuit updates incorporated into Bulldozer. These are detailed in the paper, along with significant power reduction improvements, including clock gating, a new low-power flop design, and L1 cache power improvements. This paper also details design of the Bulldozer Floating Point Unit (FPU) shown in Figure 2.

Zuletzt bearbeitet:
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
...Also der übliche Vergleich zu nem hypothetischen CMP Bulldozer, nicht zu nem "alten AMD Kern". So passt das ...
Die Frage ist nur, was versteht er unter "similar native dual-core"? Welchen Aufbau würde dieser haben? Ein Dualcore, von dem jedes Core nur zwei Dekoder oder drei oder doch vier davon hat? Irgendwie hilft das auch noch nicht richtig weiter, ein Vergleich mit irgendetwas Unbekanntem? Klasse!
...Thx, wobei ich mich da jetzt auch frage, wo der Rest ist
Ich mein Du Jungs verraten nicht viel mehr als schon im Abtract stand, für die Details verweisen sie aufs ISSCC Paper ...
Das finde ich allerdings recht schwach, dass AMD nichts davon, was sie auf dem ISSCC prästentieren, irgendwo dann auch offen legen, sondern darüber schweigen, als wenn das ISSCC eine geheime Veranstaltung wäre...
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Finde ich jetzt nicht so das große Problem, ich denke er bezieht sich auf die alten Folien hier:Die Frage ist nur, was versteht er unter "similar native dual-core"? Welchen Aufbau würde dieser haben? Ein Dualcore, von dem jedes Core nur zwei Dekoder oder drei oder doch vier davon hat? Irgendwie hilft das auch noch nicht richtig weiter, ein Vergleich mit irgendetwas Unbekanntem? Klasse!
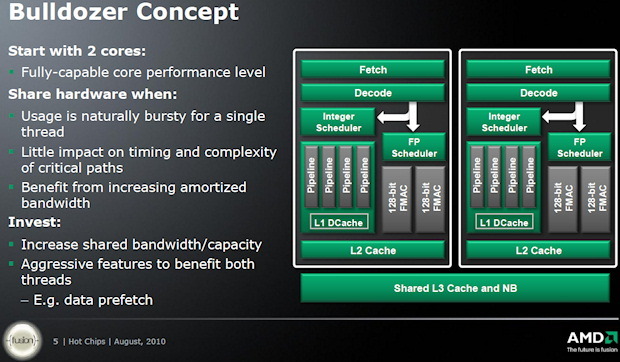

Ok, die Decoderfrage ist da nicht geklärt, aber da muss man davon ausgehen, das die gleich "dick" ausfallen würde.
Das finde ich allerdings recht schwach, dass AMD nichts davon, was sie auf dem ISSCC prästentieren, irgendwo dann auch offen legen, sondern darüber schweigen, als wenn das ISSCC eine geheime Veranstaltung wäre...
Ich glaub da gabs mal wieder ein Kommunikationsproblem. Der eine Blogeintrag liest sich ja schon uralt. Der Kollege schreibt da "Join me in SanF in February", hört sich an, als ob er das vor Wochen geschrieben hätte. Deswegen sind da keine Details drin, da er dachte, dass die Nachricht früher freigeschaltet werden würde, und das interessierte Publikum dann kommen könnte..
Naja AMD halt
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Schon mal in den Sinn gekommen, dass es sich dabei um ein kommerzielles Event handeln könnte... Das finde ich allerdings recht schwach, dass AMD nichts davon, was sie auf dem ISSCC prästentieren, irgendwo dann auch offen legen, sondern darüber schweigen, als wenn das ISSCC eine geheime Veranstaltung wäre...

Wer dort ist, hat entweder mit sehr harten Dollars bezahlt und/oder gehört zum erlauchten Kreis der Top-Halbleiterexperten ... oder ist in der glücklichen Lage als Student dort beizuwohnen (da gibt es noch gesonderte Regeln für diesen Ausbildungspersonenkreis).
Ansonsten ist Zahlemann & Söhne angesagt. In einem Jahr dürften die dortigen Infos dann frei verfügbar sein.
PPS: Ich merke mal an, dass bei der IPC-Diskussion dabei völlig AVX übersehen wird - was bei entsprechend kompilierter Software sicherlich den einen und anderen deutlichen Leistungssprung geben wird.
MFG Bobo(2011)
Markus Everson
Grand Admiral Special
Schon mal in den Sinn gekommen, dass es sich dabei um ein kommerzielles Event handeln könnte
Wer dort ist, hat entweder mit sehr harten Dollars bezahlt und/oder gehört zum erlauchten Kreis der Top-Halbleiterexperten ... oder ist in der glücklichen Lage als Student dort beizuwohnen (da gibt es noch gesonderte Regeln für diesen Ausbildungspersonenkreis).
Ansonsten ist Zahlemann & Söhne angesagt. In einem Jahr dürften die dortigen Infos dann frei verfügbar sein.
Sehr schöne Zusammenfassung der Motivation des Veranstalters und der Besucher.
Was aber sollte die Motivation AMDs als Teilnehmer sein, seine Folien ein Jahr lang zurück zu halten? Kriegen die dafür ne Jahresproduktion Wafer aus [Edit]
Zuletzt bearbeitet:
- Status
- Für weitere Antworten geschlossen.
Ähnliche Themen
- Antworten
- 96
- Aufrufe
- 9K
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 6
- Aufrufe
- 1K