App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich denke es geht weniger um männlich/weibliche Vorlieben, sondern um den "Uncanny Valley" Effekt:
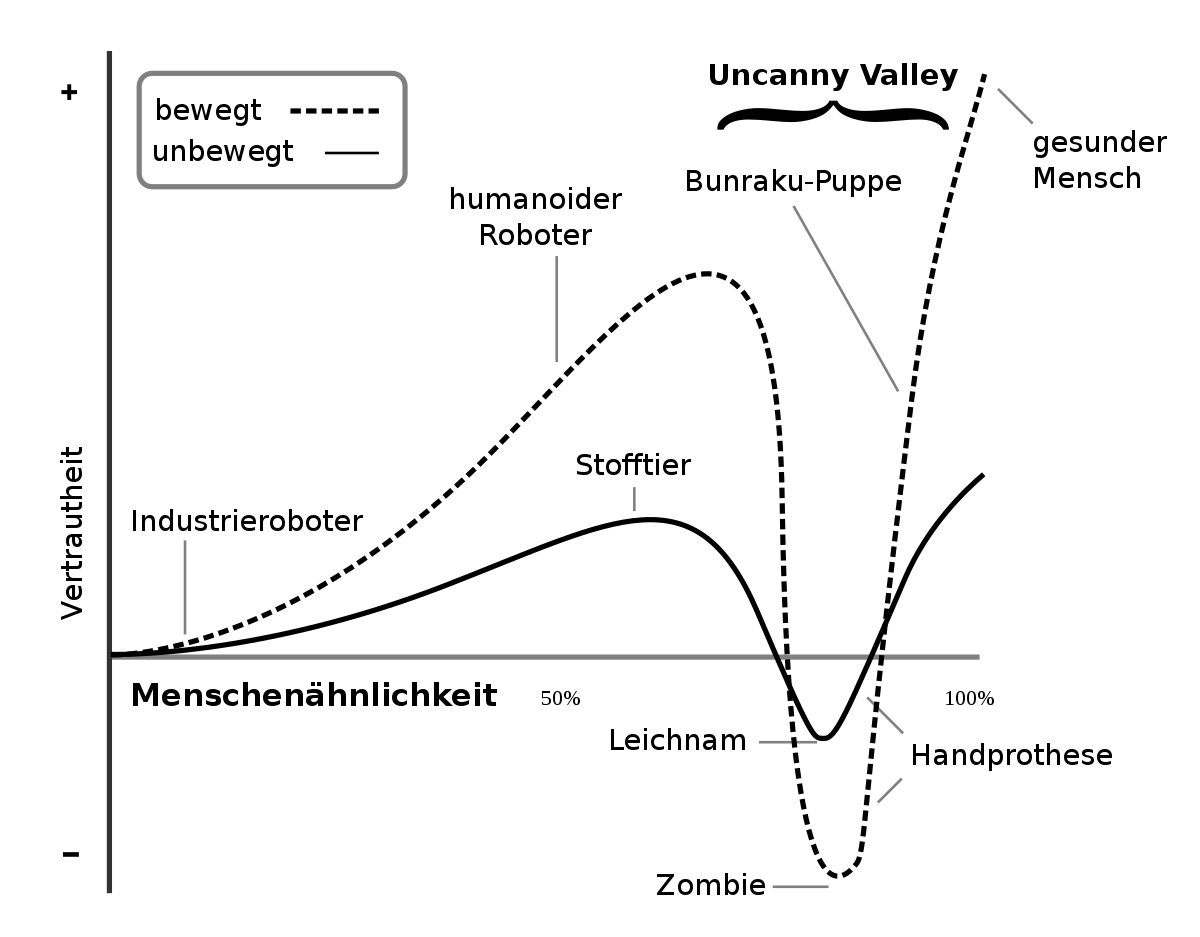
 de.wikipedia.org
de.wikipedia.org

[automerge]1688566204[/automerge]
Gute Nachrichten von AMDs Software-Baustelle:

 www.semianalysis.com
www.semianalysis.com
Uncanny Valley – Wikipedia
[automerge]1688566204[/automerge]
Gute Nachrichten von AMDs Software-Baustelle:
AMD AI Software Solved – MI300X Pricing, Performance, PyTorch 2.0, Flash Attention, OpenAI Triton
Matching Nvidia Performance With 0 Code Changes With MosaicML
www.semianalysis.com
To date, this was mostly for Nvidia hardware. MosaicML’s stack can achieve over 70% hardware FLOPS utilization (HFU) and 53.3% model FLOPS utilization (MFU) on Nvidia’s A100 GPUs in large language models without requiring writing custom CUDA kernels. Note that Google’s stack for PaLM model on TPUv4 only achieved 57.8% HFU and 46.2% MFU. Likewise, Nvidia’s own Megatron-LM stack only achieved 52.8% HFU and 51.4% MFU on a 175B parameter model. Mosaic’s stack, much of which is open source, is an obvious choice unless every last drop needs to be squeezed out with many dedicated scaling engineers for clusters of 10,000s of GPUs.
Now, MosaicML is going to be able to offer the same with AMD hardware. They have only just gotten their Instinct MI250 GPUs this quarter, but they are already close to matching Nvidia.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Die Diskussion zeigt nur dass es um XDNA momentan nichts relevantes zu berichten gibt. Es is Sommerpause.
(im Gegenteil musste ich eben feststellen, dass der Blog Artikel den einen Github-Link nicht mehr aufweist)
Der Vergleich von PCWorld im Video ist mehr Äpfel vs Birnen als dass man Schlüsse ziehen könnte. Letztlich ist das nur AMDs APU AI Cores mit Microsoft Video AI-FX vs Nvidia GPU Cores mit Nvidias Video AI-FX. Ob das bessere Freistellen oder die bessere Augenkorrektur am trainierten Modell, oder an der Inferencing-Leistung, oder an beidem lag, lässt sich nicht beurteilen. Ich vermute es liegt an den trainierten Daten.
(im Gegenteil musste ich eben feststellen, dass der Blog Artikel den einen Github-Link nicht mehr aufweist)
Der Vergleich von PCWorld im Video ist mehr Äpfel vs Birnen als dass man Schlüsse ziehen könnte. Letztlich ist das nur AMDs APU AI Cores mit Microsoft Video AI-FX vs Nvidia GPU Cores mit Nvidias Video AI-FX. Ob das bessere Freistellen oder die bessere Augenkorrektur am trainierten Modell, oder an der Inferencing-Leistung, oder an beidem lag, lässt sich nicht beurteilen. Ich vermute es liegt an den trainierten Daten.
Zuletzt bearbeitet:
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
David McAfee von AMD hat im TechPowerup Interview nochmals bestätig, dass XDNA kein FPGA ist. Als Ryzen AI geht es nur um Effizienz im Laptop, nicht um neue Möglichkeiten abseits der CPU ISA. Entsprechend sieht man das noch nicht im Desktop kommen. Alles weitere hängt von der kommenden SW Entwicklung ab.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
AMD Video zum Getting Started with Ryzen AI Software, kurz vor der Advancing AI Veranstaltung zur Einführung des MI300 im Dezember 2023, für uns 19:00 Uhr.
Zuletzt bearbeitet:
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
In der Advancing AI Veranstaltung selbst hat Lisa Su den Start von Hawk Point mit XDNA bestätigt.
Beim Nachfolger Strix Point spricht gemäss der Präsentationsfolie von XNDA2 "Next-Gen NPU for generative AI". Man erwartet dafür noch in 2024 erheblich höhere Leistung. Gerüchte gehen von 50 TOPS aus, die auch Microsoft für küntige Anwendungsfälle als relevante Grösse sieht.
Allerdings wird in den Fussnoten zur Präsentation vom 6. Dezember für Strix Point eine 3-fache NPU Performance zum 7040 angeführt.
Phönix startete anfänglich mit beworbenen 12 TOPS, die heute mit 10 TOPS angegeben werden. Hawk Point hat offiziell dazu 33% bzw. 60% mehr mit 16 TOPS, Strix Point würde entsprechend dieses mehr als verdoppeln und 36 TOPS aufweisen. Die 50 TOPS sind somit möglich wenn AMD damit die CPU/NPU kombinierte Leistung angibt, diese ist bei Phoenix und Hawk Point mit 33 bzw. 39 "total" TOPS angegeben.
Zum Start der Ryzen AI Software habe ich einen News-Artikel verfasst.
 forum.planet3dnow.de
forum.planet3dnow.de
Der aktuelle Beta-Treiber für XDNA auf Phoenix enthält xbutil.exe um XRT bzw. die Xilinx Runtime Umgebung zu nutzen.
Ich musste den Beitrag wegen der TOPS Angaben nachbearbeiten, falls jemand weiss warum und wann aus den 12 TOPS des 7040 irgendwann 10 TOPS wurden bitte posten...
Beim Nachfolger Strix Point spricht gemäss der Präsentationsfolie von XNDA2 "Next-Gen NPU for generative AI". Man erwartet dafür noch in 2024 erheblich höhere Leistung. Gerüchte gehen von 50 TOPS aus, die auch Microsoft für küntige Anwendungsfälle als relevante Grösse sieht.
Allerdings wird in den Fussnoten zur Präsentation vom 6. Dezember für Strix Point eine 3-fache NPU Performance zum 7040 angeführt.
Phönix startete anfänglich mit beworbenen 12 TOPS, die heute mit 10 TOPS angegeben werden. Hawk Point hat offiziell dazu 33% bzw. 60% mehr mit 16 TOPS, Strix Point würde entsprechend dieses mehr als verdoppeln und 36 TOPS aufweisen. Die 50 TOPS sind somit möglich wenn AMD damit die CPU/NPU kombinierte Leistung angibt, diese ist bei Phoenix und Hawk Point mit 33 bzw. 39 "total" TOPS angegeben.
Zum Start der Ryzen AI Software habe ich einen News-Artikel verfasst.
News - Ryzen AI Software 1.0
In der AMD Präsentation Advancing AI vom 06. Dezember '23 hat Lisa Su neben dem Launch der Hawk Point APUs auch eine neue Entwicklungsumgebung vorgestellt. https://www.youtube.com/live/tfSZqjxsr0M?si=IUjCMUG9nKLN4QfT&t=6982 Mit Ryzen AI Software 1.0 erhält der Programmierer eine...
Der aktuelle Beta-Treiber für XDNA auf Phoenix enthält xbutil.exe um XRT bzw. die Xilinx Runtime Umgebung zu nutzen.
Ich musste den Beitrag wegen der TOPS Angaben nachbearbeiten, falls jemand weiss warum und wann aus den 12 TOPS des 7040 irgendwann 10 TOPS wurden bitte posten...
Zuletzt bearbeitet:
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Jason Banta, AMD General Manager OEM PC Business, und David MacAffee, AMD VP General Manager Ryzen CPU Business, im Interview bei PCWorld.
- Ryzen 7000 -> 8000 ist gleiches XDNA1 mit höherer Taktrate
- XDNA2 in Strix Point still in 2024 major iteration, 3x NPU performance
- Zen4c in Ryzen3 und Ryzen5 SKUs, NPU nicht in kleinen APUs
- NPU vs. GPU, beide können AI, NPU wesentlich effizienter, GPU wesentlich genauer v.a. bei visuellen Anwendungen
- lokale LLMs für Vorteile der Sicherheit, der Effizienz, der Verfügbarkeit bzw. Kosten
- Marketing von AI PCs nur mittels Partnerschaften der Softwareanbieter
- Ryzen AI Software wird nur mit den APUs mit XDNA nutzbar sein
- NPU ist momentan noch nicht übertaktbar
- im Gaming sind Partner für AI noch in der Experimentierphase
- NPU in Desktops "maybe someday soon"
- dNPU gibt es bei Xilinx für Datacenter, für Desktops "remains to be seen"
- AMD AI Development Competition via Hackster

AMD Talks Ryzen 8000 Mobile, AI On Desktop, Data Center Accelerators | The Full Nerd Special
Join The Full Nerd gang as they talk about the latest PC hardware topics. In this episode the gang is live from AMD's Advancing AI event and joined by Jason ... www.youtube.com
www.youtube.com
Zuletzt bearbeitet:
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Einschätzungen zu Ryzen AI und ROCm von einem AI-Entwickler von Pygmalion.ai...
- Ryzen AI ist spät und nur Windows
- ROCm ist auf Linux sehr gut supportet und eine gute Alternative zu CUDA (speku: er bezieht sich auf ROCm via LLVM)
- AMD (wie Intel) fehlt ein Load-Balancing-Modell das alle - NPU, GPU, CPU - nutzen kann um maximale Performance zu erreichen um sich so gegen Nvidia zu behaupten
- Speicherbandbreite bzw. -Latenz und -Grösse sind viel wichtiger als peak TOPS
- AMD sollte ROCm auf allen GPUs supporten um neuen Entwicklern und Anwendern einen einfacheren Einstieg zu gewähren
- Für Konsolenspiele wäre Cloud-AI eine erwartbare Entwicklung (=always on)
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Aus einer Aktienanalyse - AI wird wohl im Automotiv Sektor mit Versal AI Edge XA und V2000A vom erwarteten Marktwachstum profitieren:

 seekingalpha.com
seekingalpha.com
AMD's $225 Milestone Ahead (NASDAQ:AMD)
Advanced Micro Devices, Inc. is targeting the automotive AI market, which is projected to reach $15 billion by 2030. Read more about AMD stock here.
seekingalpha.com
AMD's expansion into the automotive AI with Versal AI Edge XA adaptive SoC and Ryzen Embedded V2000A Series processor is an important fundamental development. This is a strategic move to target high-growth markets, as automotive is experiencing a vital shift towards advanced technologies like AI, infotainment systems, and autonomous driving (ADAS).
The sector is projected to hit $15 billion in market size by 2030. In this context, the Automotive AI market may deliver a CAGR of 24% (2022–2030). Fundamentally, AMD is capitalizing on the demand for advanced automotive applications through Versal AI Edge XA and Ryzen Embedded V2000A.
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
- Ryzen AI ist spät und nur Windows
Das ist auch mein Gedanke, sollte AMD das nicht so schnell wie möglich als Open Source unter Linux promoten?
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Ich denke AMD ist immer noch zu knapp bei Entwicklern. Dann gibt es erst mal für Desktop Apps nur das eine und für Server/Cloud das andere typische OS mit unterstützten Entwicklungstools. Ich denke auch, besser wäre immer Multiplattform und von unterschiedlichen Erfahrungen profitieren.Das ist auch mein Gedanke, sollte AMD das nicht so schnell wie möglich als Open Source unter Linux promoten?
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Ich denke AMD ist immer noch zu knapp bei Entwicklern. Dann gibt es erst mal für Desktop Apps nur das eine und für Server/Cloud das andere typische OS mit unterstützten Entwicklungstools. Ich denke auch, besser wäre immer Multiplattform und von unterschiedlichen Erfahrungen profitieren.
Gerade deswegen sollte man das auf Open Source auslagern. Allerdings hat man ja mit Microsoft auch irgendeine Partnerschaft laufen, wobei ich finde, dass die AMD auch sehr oft im Regen stehen gelassen haben und mir ehrlich gesagt, davon nicht viel verspreche.
Bei ROCm sieht es ja Gott sei dank etwas besser aus und die kommenden APUs werden unterstützt.
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.904
- Renomée
- 42
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
So rund läuft es mit rocm auch nicht. Bei mir lief es eine Zeitlang gut mit einer 5700xt bis mal ein update kam. Seit dem geht nichts mehr ausser Berechnungsfehler. Alles neu aufzusetzen hat nichts gebracht.
Auch wenn der Treiber von Nvidia closed source ist, wird ältere Hardware echt lange unterstützt. Es läuft in der Regel.
Auch wenn der Treiber von Nvidia closed source ist, wird ältere Hardware echt lange unterstützt. Es läuft in der Regel.
Yoshi 2k3
Admiral Special
- Mitglied seit
- 18.01.2003
- Beiträge
- 1.447
- Renomée
- 238
- BOINC-Statistiken

- Mein Laptop
- Apple Mac Book Pro 14" 2023
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7800X3D
- Mainboard
- ASUS PRIME X670E-PRO WIFI
- Kühlung
- Watercool Heatkiller IV
- Speicher
- 64 GB Team Group DDR5-6400 (2x 32 GB)
- Grafikprozessor
- Nvidia Geforce RTX 4090 FE
- Display
- Nixeus NX-EDG27
- Soundkarte
- SMSL SU-9 USB DAC
- Gehäuse
- Caselabs SM8
- Netzteil
- FSP Hydro Ti Pro 1000W
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Firefox
- Schau Dir das System auf sysprofile.de an

E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Eben, so ist es. AMD hat in allen Bereichen zu wenige Entwickler um einen vollen Support mit Plattform und APIs zu bieten. Man verschiebt die Leute dorthin, wo das meiste Geld vermutet wird. Der Blick geht nach vorne, auch weil noch zu wenige Kunden da sind, die alte HW/SW Kombis nutzen wollen.So rund läuft es mit rocm auch nicht. Bei mir lief es eine Zeitlang gut mit einer 5700xt bis mal ein update kam. ...
Auch wenn der Treiber von Nvidia closed source ist, wird ältere Hardware echt lange unterstützt. Es läuft in der Regel.
XDNA ist stand heute Desktop-AI für Consumer und Büro mit WinOS. Workstation und Cloud-AI ist bis auf weiteres GPU mit ROCm.
Mit XDNA Ryzen-AI Support auf Linux reagiert man nur und wundert sich ob da etwas kommt das HW verkauft. Trotz Alveo V70 Karte gibt es auch noch nichts aus dem Datacenter zu hören. Bin gespannt ab wann man hier etwas finden wird: www.amd.com/en/resources/case-studies.html#q=xdna
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Interessante News:
https://www.eenewseurope.com/en/amd-combines-embedded-processor-and-fpga-in-edge-ai-architecture/
AMD Pressemitteilung: https://ir.amd.com/news-events/pres...veils-embedded-architecture-combines-embedded
https://www.eenewseurope.com/en/amd-combines-embedded-processor-and-fpga-in-edge-ai-architecture/
The Embedded+ architecture combines the AMD Ryzen Embedded processors with the Versal adaptive SoCs onto a single board for original design manufacturers (ODMs) for edge AI.
The design has been validated by AMD to help the ODMs reduce qualification and build times for faster time-to-market without needing to expend additional hardware and R&D resources for edge AI boards in medical, industrial, and automotive applications. A key advantage is that the architecture uses a single development environment based on the AMD Vitis tool to programme the FPGA fabric, AI engines and CPU.
Edit: https://www.sapphiretech.com/en/commercial/edge-plus-vpr_4616Sapphire Technology has developed the first board using the Embedded+ architecture in a mini-ITZ form factor. The 30W Edge+ VPR-4616-MB uses the Ryzen Embedded R2314 processor and Versal AI Edge VE2302 Adaptive SoC. The VPR-4616-MB is also available in a full system, including memory, storage, power supply, and chassis.
The Embedded+ qualified VPR-4616-MB from Sapphire Technology is immediately available.
AMD Pressemitteilung: https://ir.amd.com/news-events/pres...veils-embedded-architecture-combines-embedded
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Nach näherem darüber nachdenken, finde ich den Zug unternehmerisch sehr interessant.
AMD hat sich hier einen Markt für AI ausgesucht, den Nvidia nicht mit steigenden Verbrauchswerten dominieren kann, da begrenzte Formfaktoren, was Kühlung betrifft. Mit dieser embedded+ Plattform könnten sie ein Geschäftsmodell wie bei dGPUs im Consumer/Gaming Markt anstreben und mit diesem Referenz Design andere OEMs, für die der GPU Markt schwieriger wird, ein zusätzliches Standbein bieten.
Die OEM-Chanel sind etabliert und die Produktpalette bietet eine hohe Varianz in einem Bereich den Nvidia nicht abdeckt. Es wir spannend sein zu sehen ob Sapphire da exklusiv Hersteller einer Nische bleiben wird oder sich eine umfangreichere Strategie zeigen wird, die einen Wachstum für AI/FPGA in kleinen Formfaktoren beim Edge-Computing erwartet.
AMD hat sich hier einen Markt für AI ausgesucht, den Nvidia nicht mit steigenden Verbrauchswerten dominieren kann, da begrenzte Formfaktoren, was Kühlung betrifft. Mit dieser embedded+ Plattform könnten sie ein Geschäftsmodell wie bei dGPUs im Consumer/Gaming Markt anstreben und mit diesem Referenz Design andere OEMs, für die der GPU Markt schwieriger wird, ein zusätzliches Standbein bieten.
Die OEM-Chanel sind etabliert und die Produktpalette bietet eine hohe Varianz in einem Bereich den Nvidia nicht abdeckt. Es wir spannend sein zu sehen ob Sapphire da exklusiv Hersteller einer Nische bleiben wird oder sich eine umfangreichere Strategie zeigen wird, die einen Wachstum für AI/FPGA in kleinen Formfaktoren beim Edge-Computing erwartet.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Joel Hruska von AMD schrieb in seinem Blog-Artikel, dass die XDNA NPU künftig im Windows Task Manager separat angezeigt werden soll.

 community.amd.com
community.amd.com
Das wird die Sichtbarkeit für alle Kunden und Entwickler deutlich erhöhen, hoffentlich auch die künftige Softwareunterstützung und Nutzung.
Upcoming Windows Task Manager Update Will Add NPU Monitoring For Ryzen 8040 Series Processors
As AI PCs become more popular, there’s a growing need for system monitoring tools that can track the performance of the new NPUs (Neural Processing Units) available on select Ryzen™ 8040 Series mobile processors. A neural processing unit – also sometimes referred to an integrated or on-die AI...
Das wird die Sichtbarkeit für alle Kunden und Entwickler deutlich erhöhen, hoffentlich auch die künftige Softwareunterstützung und Nutzung.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Da schau her - auch Zotac startet in den Server-Markt und baut das Portfolio massiv aus: https://www.heise.de/news/Epyc-Xeon-flotte-GPUs-Zotac-baut-ab-jetzt-Server-9656631.htmlDie OEM-Chanel sind etabliert und die Produktpalette bietet eine hohe Varianz in einem Bereich den Nvidia nicht abdeckt. Es wir spannend sein zu sehen ob Sapphire da exklusiv Hersteller einer Nische bleiben wird oder sich eine umfangreichere Strategie zeigen wird, die einen Wachstum für AI/FPGA in kleinen Formfaktoren beim Edge-Computing erwartet.
AMD und Nvidia pushen da scheinbar beide. Ich bin gespannt wer von den GPU-OEMs da mitzieht. Das könnte zum schrumpfen der Anzahl an Herstellern führen.Mit den Servern und Workstations baut sich Zotac jetzt ein neues Standbein auf – offensichtlich mit Nvidias Unterstützung, denn ohne gäb's keine (KI-)Beschleuniger der Firma. Letztere darf Zotac ins Ausland verkaufen – für China gibt es langsamere Varianten oder Bundles aus Gehäusen und Mainboards.
Den Verkaufsstart hat die Firma für den 25. März 2024 angesetzt. Auf einer Landing-Page führt Zotac bereits zahlreiche Server auf, die bald bestellbar sein sollen. Preise sind bislang nicht bekannt.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
XDNA wird bei Ryzen AI Marketing nur im Kontext erwähnt
See how AMD Ryzen™ AI enables transformative AI experiences locally with the battery life, speed, and quiet operation of a traditional PC thanks to AMD XDNA™ architecture. Ryzen™ AI is available now on select laptops with AMD Ryzen™ processors.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
hier etwas spät - das Video kam am 12.01.2023 nur 5 Tage nach dem 1. Post in diesem Thread raus - aber dennoch gut für Einsteiger in das Thema.
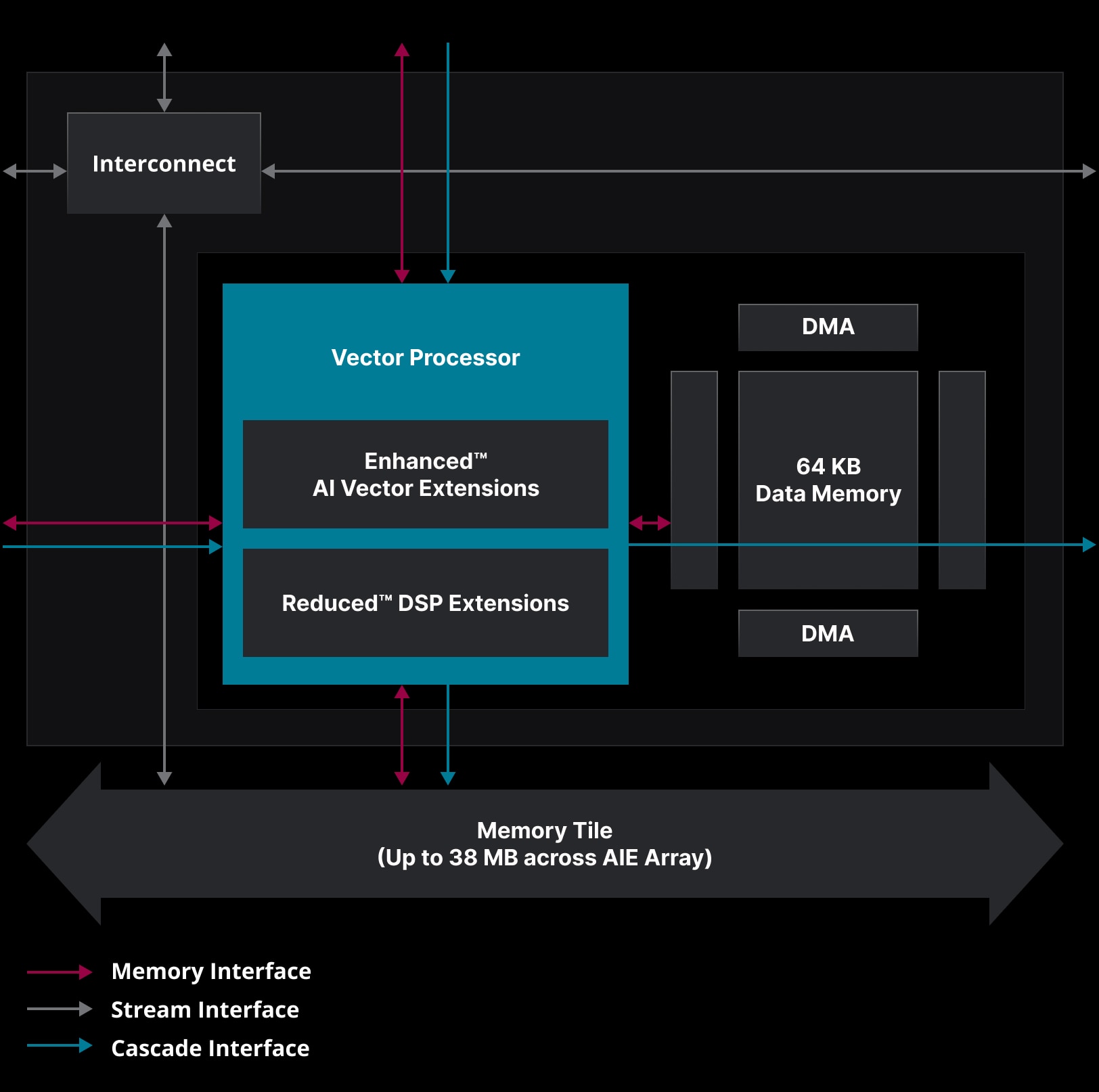 Die Vermutung der Xilinx-Basis für XDNA war aber falsch, AMD nutzt tatsächlich ein ML-optimiertes Design mit 64kb Daten je Vectorprozessor mit reduzierten DSP Fähigkeiten.
Die Vermutung der Xilinx-Basis für XDNA war aber falsch, AMD nutzt tatsächlich ein ML-optimiertes Design mit 64kb Daten je Vectorprozessor mit reduzierten DSP Fähigkeiten.
Die XDNA-Webseite von AMD.
Die XDNA-Webseite von AMD.
Jede KI-Engine-Kachel besteht aus einem VLIW- (Very Long Instruction Word), SIMD- (Single Instruction Multiple Data) Vektorprozessor, der für maschinelles Lernen und erweiterte Signalverarbeitungsanwendungen optimiert ist. Der Prozessor der KI-Engine kann mit über 1,3 GHz laufen, was effiziente Funktionen mit hohem Durchsatz und geringer Latenz ermöglicht. Jede Kachel enthält außerdem Programm- und lokalen Speicher zum Speichern von Daten, Gewichtungen, Aktivierungen und Koeffizienten, einen RISC-Skalarprozessor und verschiedene Verbindungsmodi für die Verarbeitung verschiedener Arten der Datenkommunikation.
Zuletzt bearbeitet:
Das ist genau die AI engine aus den Xilinx Versal SOCs:
https://www.xilinx.com/products/technology/ai-engine.html
https://www.xilinx.com/products/technology/ai-engine.html
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Ja genau. XDNA ist eine Ai Engine die auf ML hin optimiert ist. Weniger DSP Leistung und mehr Datendurchsatz. Unklar bleibt nach wie vor warum nur die Alveo V70 als XDNA ACAP bezeichnet wird. Sind alle anderen DSP optimiert oder ist XDNA eine zweite ML optimierte Variante einer AI-Engine?
Von Xilinx gibt es jedenfalls die Ai-Engine in einer DSP optimieren Variante (Gen1) und in einer ML optimieren Variante (Gen2). Beide sind in diversen Versal SOCs zu finden.
Das man diese dort nicht als XDNA bezeichnet dürfte wohl eher dem Marketing geschuldet sein
Die Alveo Karte scheint ja auch auf den gleichen Engines zu basieren.
Lustigerweise tauchen die Versal SOCs dann doch auf der XDNA Seite als Produkte auf.
https://www.amd.com/de/technologies/xdna.html
Interessant bleibt allerdings noch was genau sich hinter XDNA2 verbergen wird.
Das man diese dort nicht als XDNA bezeichnet dürfte wohl eher dem Marketing geschuldet sein
Die Alveo Karte scheint ja auch auf den gleichen Engines zu basieren.
Lustigerweise tauchen die Versal SOCs dann doch auf der XDNA Seite als Produkte auf.
https://www.amd.com/de/technologies/xdna.html
Interessant bleibt allerdings noch was genau sich hinter XDNA2 verbergen wird.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Bislang kann ich mir lediglich vorstellen, dass AMD/Xilinx die bisherige AI-ML Engine als XDNA-Varianten auf Eigenheiten angepasst haben, damit diese mit AMDs Zen, RDNA und CDNA in der Speicherverwaltung kompatibel sind. Nur im Kontext mit der Alveo V70 spricht das Marketing von AI-Workloads, die lokal auf Ryzen-AI oder in der Cloud auf dem Beschleuniger abgearbeitet werden können. Das spricht für Anpassungen in der Speicherverwaltung und vielleicht sogar Erweiterungen für Verschlüsselung. Ansonsten verweist auch die Riallto Schulung auf Xilinx AI-ML Architekturdokumentationen, die wiederum gänzlich den Terminus XDNA vermissen lassen. Entsprechend wird das in ISA und Funktionalität sonst indentisch sein.
Das Einführungsviedeo von Riallto ist auch gut für das generelle Verständnis der AI-ML Engine von AMD/Xilinx.
Das Einführungsviedeo von Riallto ist auch gut für das generelle Verständnis der AI-ML Engine von AMD/Xilinx.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Zur Computex 2024 gibt es bislang nur ein Artikel von Anandtech, der sich ausführlicher mit der NPU und den neuen XDNA2 fähigkeiten beschäftigt und die relevanten Folien zeigt.
Eine zentrale Neuerung ist Block FP16.
Eine zentrale Neuerung ist Block FP16.

Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 460
- Antworten
- 44
- Aufrufe
- 2K
- Antworten
- 0
- Aufrufe
- 3K