App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
CDNA 3 - MI300
- Ersteller pipin
- Erstellt am
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit

Wahrscheinlich gibts am 13. Juni von AMD selbst nähere Infos, aber es gibt weitere Gerüchte, deswegen mache ich mal nen Thread dazu auf.
Von AMD ist bislang erst offiziell bekannt, dass MI300 für den Supercomputer El Capitan kommt. Umsatztechnisch soll es sich erst im vierten Quartal 2023 auswirken.
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Laut AdoredTV soll MI300 aber nicht nur als APU, sondern auch als GPU und CPU erscheinen:
MI300A - APU
- 6 GPU chiplets
- 3 CPU chiplets
- 128 GB HBM3
MI300X - GPU
- discrete GPU
- 8 chiplets with 304 CUs
- 128/192 GB HBM3
MI300C - CPU
- 96 Genoa cores
- HBM3
MI300A - APU
- 6 GPU chiplets
- 3 CPU chiplets
- 128 GB HBM3
MI300X - GPU
- discrete GPU
- 8 chiplets with 304 CUs
- 128/192 GB HBM3
MI300C - CPU
- 96 Genoa cores
- HBM3
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Etwas zu El Capitan, der MI300A einsetzen wird:

 www.exascaleproject.org
www.exascaleproject.org
Siting the El Capitan Exascale Supercomputer at Lawrence Livermore National Laboratory - Exascale Computing Project
Lawrence Livermore National Lab is preparing for El Capitan, the National Nuclear Security Administration’s first exascale supercomputer.
COE is the Center of Excellence, and that’s a basic mechanism under which our application teams and our software experts, in general, are interacting with HPE and AMD. So RAJA is a portability suite built on C++ abstractions, primarily lambdas, that many of our applications in the process of porting from primarily CPUs—prior to our Sierra system—have adopted in order to be able to run on GPUs and basically be able to simplify the effort involved in porting to new systems. It’s similar to the Kokkos infrastructure that’s produced at Sandia. The two, RAJA and Kokkos, are actually very similar.
In general, our application teams have found preparations for AMD GPUs to be pretty straightforward. We largely credit the use of RAJA for that. Our application teams basically spent 3 to 5 years getting ready to run on Sierra. And the effort that’s been involved in terms of man months has been more like 3 to 5 months—man months—to be ready to run on AMD GPUs.
So to give you some specific examples for El Cap, we’ll be using the HPE—formerly Cray—Slingshot network in El Capitan. So that’s, you know, significant portions of that networking technology were developed through ECP funding. We are also in AMD technology, so we’ll be using the MI300A. The A is for APU, which is accelerated processing unit, which provides integrated CPU and GPU technology on the same package. So it’s using CPU chiplets and GPU chiplets all together to form a single processing unit. And that type of technology would not have been available for El Capitan without the work that AMD did under PathForward.
Sabroe SMC
Grand Admiral Special
- Mitglied seit
- 14.05.2008
- Beiträge
- 4.764
- Renomée
- 530
- Standort
- Castrop-Rauxel
- Mein Laptop
- Gigabyte P37, i7 4720HQ, 16 Gb, 128 Gb SSD, 1Tb HD, 17" FHD
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X3D
- Mainboard
- Asus TUF Gaming X670E Plus
- Kühlung
- Noctua NH-D15 chromax.black
- Speicher
- G.Skill Trident Z5 RGB silber DIMM Kit 64GB DDR5-6400 CL32-39-39-102 on-die ECC
- Grafikprozessor
- Palit GeForce RTX 4090 GameRock
- Display
- Samsung U32H850, 31.5" (3840x2160)
- SSD
- Kingston KC3000 PCIe 4.0 NVMe SSD 2TB
- Optisches Laufwerk
- irgendeins
- Soundkarte
- Onboard
- Gehäuse
- SilverStone Seta D1, schwarz
- Netzteil
- ASUS ROG Strix, ROG-STRIX-850G Gold Aura Edition, 850W ATX 3.0
- Tastatur
- Razer BlackWidow Ultimate
- Maus
- Zowie Gaming Mouse FK1
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Firefox in aktuellster Version
- Verschiedenes
- Teufel Concept C (Schwarz) bestehend aus - 2 Satelliten-Lautsprecher CS 25 FCR Mk3 (Schwarz) 1 Aktiv-Subwoofer CC 2013 SW (Schwarz)
- Internetanbindung
-
▼500 Mbit/s
▲25 Mbit/s
www.exascaleproject.org
Standort für den Exascale-Supercomputer El Capitan am Lawrence Livermore National Laboratory - Exascale Computing Project
Das Lawrence Livermore National Lab bereitet sich auf El Capitan vor, den ersten Exascale-Supercomputer der National Nuclear Security Administration.
www.exascaleproject.org www.exascaleproject.org
COE ist das Center of Excellence, und das ist ein grundlegender Mechanismus, unter dem unsere Anwendungsteams und unsere Softwareexperten im Allgemeinen mit HPE und AMD zusammenarbeiten. RAJA ist also eine Portabilitätssuite, die auf C++-Abstraktionen, vor allem Lambdas, aufbaut, die viele unserer Anwendungen im Prozess der Portierung von primär CPUs - vor unserem Sierra-System - übernommen haben, um auf GPUs laufen zu können und im Grunde den Aufwand für die Portierung auf neue Systeme zu vereinfachen. Es ist ähnlich wie die Kokkos-Infrastruktur, die in Sandia produziert wird. Die beiden, RAJA und Kokkos, sind sich tatsächlich sehr ähnlich.
Im Allgemeinen haben unsere Anwendungsteams festgestellt, dass die Vorbereitungen für AMD-GPUs ziemlich unkompliziert sind. Das verdanken wir größtenteils der Verwendung von RAJA. Unsere Anwendungsteams haben im Grunde 3 bis 5 Jahre damit verbracht, sich auf Sierra vorzubereiten. Und der Aufwand in Form von Mannmonaten war eher 3 bis 5 Monate - Mannmonate, um für AMD-GPUs gerüstet zu sein.
Um Ihnen ein paar konkrete Beispiele für El Cap zu geben: Wir werden das HPE-vormals Cray-Slingshot-Netzwerk in El Capitan verwenden. Ein großer Teil dieser Netzwerktechnologie wurde mit ECP-Mitteln entwickelt. Wir setzen auch AMD-Technologie ein, d. h. wir verwenden den MI300A. Das A steht für APU (Accelerated Processing Unit), die integrierte CPU- und GPU-Technologie auf demselben Gehäuse bietet. Es werden also CPU-Chips und GPU-Chips verwendet, die zusammen eine einzige Verarbeitungseinheit bilden. Und diese Art von Technologie wäre ohne die Arbeit, die AMD im Rahmen von PathForward geleistet hat, für El Capitan nicht verfügbar gewesen.
Übersetzt mit www.DeepL.com/Translator (kostenlose Version)
Standort für den Exascale-Supercomputer El Capitan am Lawrence Livermore National Laboratory - Exascale Computing Project
Das Lawrence Livermore National Lab bereitet sich auf El Capitan vor, den ersten Exascale-Supercomputer der National Nuclear Security Administration.
www.exascaleproject.org www.exascaleproject.org
COE ist das Center of Excellence, und das ist ein grundlegender Mechanismus, unter dem unsere Anwendungsteams und unsere Softwareexperten im Allgemeinen mit HPE und AMD zusammenarbeiten. RAJA ist also eine Portabilitätssuite, die auf C++-Abstraktionen, vor allem Lambdas, aufbaut, die viele unserer Anwendungen im Prozess der Portierung von primär CPUs - vor unserem Sierra-System - übernommen haben, um auf GPUs laufen zu können und im Grunde den Aufwand für die Portierung auf neue Systeme zu vereinfachen. Es ist ähnlich wie die Kokkos-Infrastruktur, die in Sandia produziert wird. Die beiden, RAJA und Kokkos, sind sich tatsächlich sehr ähnlich.
Im Allgemeinen haben unsere Anwendungsteams festgestellt, dass die Vorbereitungen für AMD-GPUs ziemlich unkompliziert sind. Das verdanken wir größtenteils der Verwendung von RAJA. Unsere Anwendungsteams haben im Grunde 3 bis 5 Jahre damit verbracht, sich auf Sierra vorzubereiten. Und der Aufwand in Form von Mannmonaten war eher 3 bis 5 Monate - Mannmonate, um für AMD-GPUs gerüstet zu sein.
Um Ihnen ein paar konkrete Beispiele für El Cap zu geben: Wir werden das HPE-vormals Cray-Slingshot-Netzwerk in El Capitan verwenden. Ein großer Teil dieser Netzwerktechnologie wurde mit ECP-Mitteln entwickelt. Wir setzen auch AMD-Technologie ein, d. h. wir verwenden den MI300A. Das A steht für APU (Accelerated Processing Unit), die integrierte CPU- und GPU-Technologie auf demselben Gehäuse bietet. Es werden also CPU-Chips und GPU-Chips verwendet, die zusammen eine einzige Verarbeitungseinheit bilden. Und diese Art von Technologie wäre ohne die Arbeit, die AMD im Rahmen von PathForward geleistet hat, für El Capitan nicht verfügbar gewesen.
Übersetzt mit www.DeepL.com/Translator (kostenlose Version)
vinacis_vivids
Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 1.421
- Renomée
- 254
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
MI300 GPU
440CU (8X55CU-GCD)
28.160 SP
1,7-2,2Ghz Takt
128GB HBM RAM
256 flop fp64 X 440CU X 1,7Ghz ~ 191,48 Tflops fp64 !
Bei ~900W sind das ~112,5W pro 55CU GCD
MI300A APU
330CU (6X55CU-GCD)
21.120 SP
1,7-2,2Ghz
128GB HBM RAM
256 flop fp64 X 330CU X 1,7Ghz ~ 143,61 Tflops fp64 !
24 Cores CPU
Zen5
Takt ?
440CU (8X55CU-GCD)
28.160 SP
1,7-2,2Ghz Takt
128GB HBM RAM
256 flop fp64 X 440CU X 1,7Ghz ~ 191,48 Tflops fp64 !
Bei ~900W sind das ~112,5W pro 55CU GCD
MI300A APU
330CU (6X55CU-GCD)
21.120 SP
1,7-2,2Ghz
128GB HBM RAM
256 flop fp64 X 330CU X 1,7Ghz ~ 143,61 Tflops fp64 !
24 Cores CPU
Zen5
Takt ?
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
MI300 GPU
440CU (8X55CU-GCD)
28.160 SP
1,7-2,2Ghz Takt
128GB HBM RAM
256 flop fp64 X 440CU X 1,7Ghz ~ 191,48 Tflops fp64 !
Bei ~900W sind das ~112,5W pro 55CU GCD
Quelle? Das sind ja noch mehr CUs als AdoredTV angegeben hat.
vinacis_vivids
Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 1.421
- Renomée
- 254
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
MI300 GPU
440CU (8X55CU-GCD)
28.160 SP
1,7-2,2Ghz Takt
128GB HBM RAM
256 flop fp64 X 440CU X 1,7Ghz ~ 191,48 Tflops fp64 !
Bei ~900W sind das ~112,5W pro 55CU GCD
Quelle? Das sind ja noch mehr CUs als AdoredTV angegeben hat.
AI Hype Will Drive Datacenter GPU Prices Sky High
UPDATED Like many HPC and AI system builders, we are impatient to see what the “Antares” Instinct MI300A hybrid CPU-GPU system on chip from AMD might look
 www.nextplatform.com
www.nextplatform.com
MI300A APU - 330CU / 24C
MI300 GPU - 440CU
MI300C - 24CU / 192C

★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Es soll sogar 4 MI300 Versionen geben.
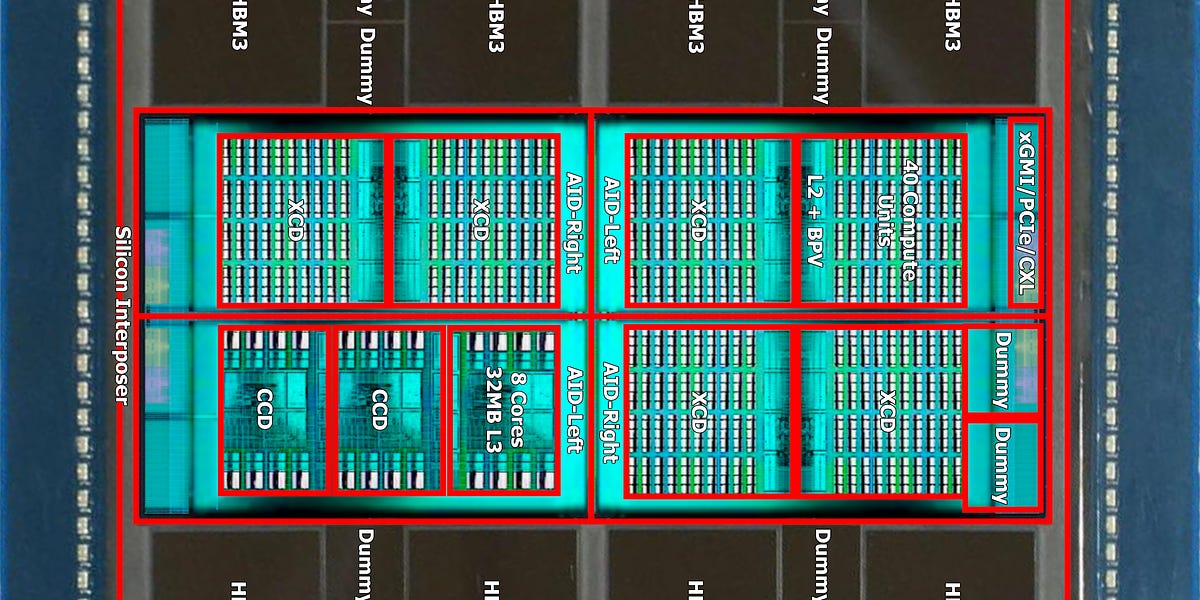
 www.semianalysis.com
www.semianalysis.com
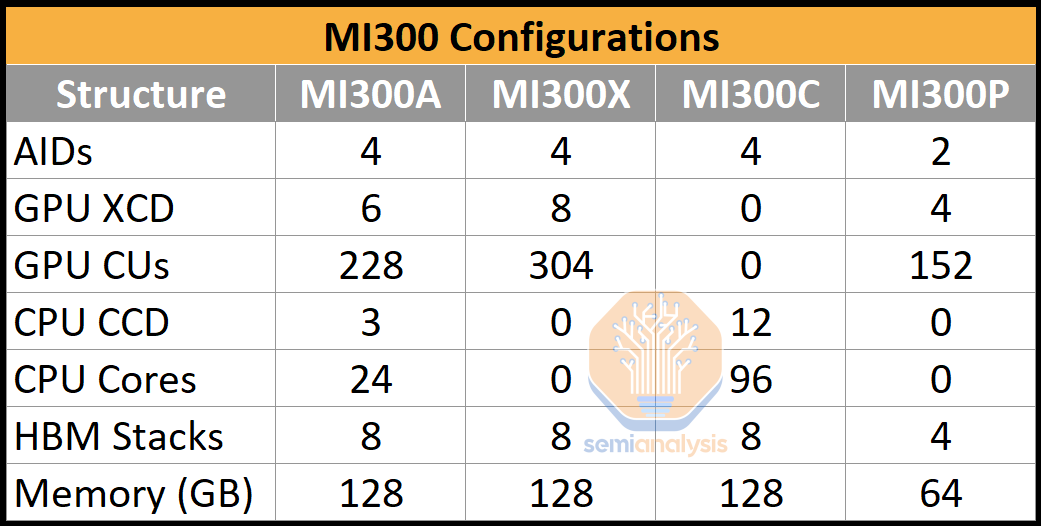
AMD MI300 – Taming The Hype – AI Performance, Volume Ramp, Customers, Cost, IO, Networking, Software
Amazing engineering, but what of the path to market?
www.semianalysis.com
E555user
Grand Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Die Präsentation anlässlich der AMD Data Center and AI Technology Premiere hat nicht ganz so viel ergeben.
MI300A mit
Die Taktraten sind nicht klar.
Von AI Cores war nicht die Rede.
Auch andere Varianten wurden zunächst nicht vorgestellt.
MI300A mit
- CPU Cores: 24
- GPU XCD: 6
- HBM Stacks: 8x2 in 8GB
- Memory in GB: 128GB (shared memory)
- Sampling Q2, RampUp Q4
- CPU Cores: 0
- GPU XCD: 8
- HBM Stacks: 8x3 in 8GB
- Memory in GB: 192GB @ 5.218TB/s (8x 652.25GB/s)
- IF Bandbreite 892GB/s (ca. 30% mehr als Bandbreite pro HBM Stack)
- Sampling Q3, RampUp Q4
Die Taktraten sind nicht klar.
Von AI Cores war nicht die Rede.
Auch andere Varianten wurden zunächst nicht vorgestellt.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Nextplattorm hat etwas mehr Informationen zur MI300-Serie:
 www.nextplatform.com
www.nextplatform.com
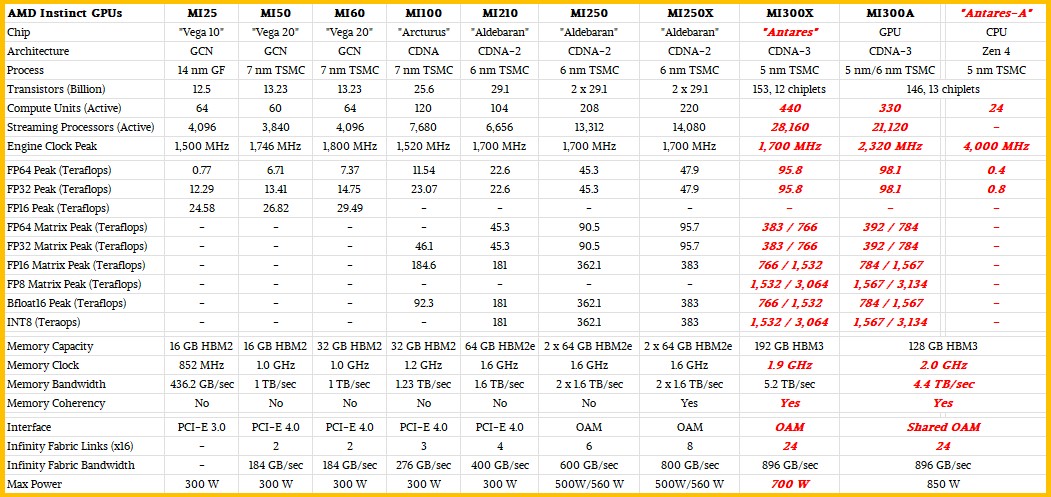
Den Codenamen "Antares" habe sich die Jungs selber zurecht gelegt")
The Third Time Charm Of AMD’s Instinct GPU
The great thing about the Cambrian explosion in compute that has been forced by the end of Dennard scaling of clock frequencies and Moore’s Law lowering
www.nextplatform.com
Den Codenamen "Antares" habe sich die Jungs selber zurecht gelegt
One last thing. AMD has cooked up a little something called the AMD Instinct Platform, which puts eight of the MI300X GPUs and 1.5 TB of HBM3 memory into an industry standard, Open Compute-compliant, Universal Base Board (UBB) form factor. Intel has done the same for its “Ponte Vecchio” GPUs, which also plug into Open Compute Accelerator Module (OAM) sockets. Both Microsoft and Facebook put forth the OAM and UBB standards, and they absolutely want GPUs that adhere to these if they can get them, and if not, they want Nvidia HGX boards with their SXM4 and SXM5 sockets to at least fit in the same enclosures without modification.
The MI300A is sampling now and will be shipping later this year, presumably in time for El Capitan to make it onto the November 2023 Top500 rankings as the most powerful supercomputer in the world. The MI300X will start sampling in the third quarter and is expected to start shipping by the end of the year. The launch of the MI300 family of GPU accelerators, complete with feeds, speeds, and hopefully pricing, is slated for later this year – our guess is around the SC23 supercomputing conference in November, perhaps the week before.
Heaven only knows what they might cost. If you have to ask you can’t afford it. . . . But probably in the neighborhood of $20,000 with supply shortages pushing up street prices to perhaps as high as $30,000.
Software Update bringt deutlichen Schub für Mi250, sicherlich dann auch für MI300.

 www.mosaicml.com
www.mosaicml.com
Training LLMs with AMD MI250 GPUs and MosaicML
With the release of PyTorch 2.0 and ROCm 5.4, we are excited to announce that LLM training works out of the box on AMD datacenter GPUs, with zero code changes, and at high performance (144 TFLOP/s/GPU)! We are thrilled to see promising alternative options for AI hardware, and look forward to...
www.mosaicml.com
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Die Tabelle mit den Verbrauchsangaben pro System finde ich interessant. Während die einzelnen GPUs von Nvidia deutlich weniger verbrauchen mit 400W vs. 560 W, kommt ein Gesamtsystem mit 8 Nvidia GPUs auf 6500W und 2 Systeme mit jeweils 4 AMD GPUs auf nur noch 6000W.
Da scheint AMD mit dem Interconnect um Längen effizienter zu sein.
Das sind immerhin 1.780 W mehr Systemverbrauch bei 8 GPUs oder für jede GPU ein 222 W Aufschlag um sie in das System zu integrieren bei Nvidia.

Da scheint AMD mit dem Interconnect um Längen effizienter zu sein.
Das sind immerhin 1.780 W mehr Systemverbrauch bei 8 GPUs oder für jede GPU ein 222 W Aufschlag um sie in das System zu integrieren bei Nvidia.
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Wieso wirkt sich denn bei Nvidia die Verdoppelung des HBM-Speichers nicht auf die PPC aus?Die Tabelle mit den Verbrauchsangaben pro System finde ich interessant.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich glaube das ist ein Copy/Paste Fehler. Die Specs in Shops sagen 250 W für die 40 GB Version

 geizhals.de
geizhals.de
PNY A100, 40GB HBM2 ab € 11281,16 (2025) | Preisvergleich Geizhals Deutschland
✔ Preisvergleich für PNY A100, 40GB HBM2 ✔ Produktinfo ⇒ Modell: NVIDIA A100 • Speicher: 40GB HBM2 mit ECC-Modus, 5120bit, 2.4Gbps, 1215MHz, 1555GB/s • Takt Basis… ✔ HPC-Prozessoren ✔ Testberichte ✔ Günstig kaufen
geizhals.de
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Ich glaube das ist ein Copy/Paste Fehler. Die Specs in Shops sagen 250 W für die 40 GB Version
PNY A100, 40GB HBM2 ab € 11281,16 (2025) | Preisvergleich Geizhals Deutschland
✔ Preisvergleich für PNY A100, 40GB HBM2 ✔ Produktinfo ⇒ Modell: NVIDIA A100 • Speicher: 40GB HBM2 mit ECC-Modus, 5120bit, 2.4Gbps, 1215MHz, 1555GB/s • Takt Basis… ✔ HPC-Prozessoren ✔ Testberichte ✔ Günstig kaufen
Dort bei der 80-GB-Version aber auch.
")
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Hmm Peak Power ist nicht die TDP - wenn beides identisch ist mit 40GB weniger Speicher habe ich keine Erklärung, da ja auch die TFLOPs identisch sind. Da kann man einen höheren Takt der 40GB Version ausschließen, der das zusätzliche Powerbudget ausnutzen könnte. Anderseits sind es vielleicht auch keine Meßwerte, sondern nur die Herstellerangaben. 
Pinnacle Ridge
Vice Admiral Special
- Mitglied seit
- 04.03.2017
- Beiträge
- 528
- Renomée
- 7
Der Speicher ist bei der mit 80GB doch niedriger getaktet?
Yoshi 2k3
Admiral Special
- Mitglied seit
- 18.01.2003
- Beiträge
- 1.444
- Renomée
- 237
- BOINC-Statistiken

- Mein Laptop
- Apple Mac Book Pro 14" 2023
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7800X3D
- Mainboard
- ASUS PRIME X670E-PRO WIFI
- Kühlung
- Watercool Heatkiller IV
- Speicher
- 64 GB Team Group DDR5-6400 (2x 32 GB)
- Grafikprozessor
- Nvidia Geforce RTX 4090 FE
- Display
- Nixeus NX-EDG27
- Soundkarte
- SMSL SU-9 USB DAC
- Gehäuse
- Caselabs SM8
- Netzteil
- FSP Hydro Ti Pro 1000W
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Firefox
- Schau Dir das System auf sysprofile.de an
Giagantic AMD APU at SC23 Meet the AMD MI300A and MI300X

 www.servethehome.com
www.servethehome.com
Giagantic AMD APU at SC23 Meet the AMD MI300A and MI300X
We saw the AMD Instinct MI300A (giant APU) and MI300X (GPU) at SC23 and learned a few new things about AMD's new AI and HPC platforms
www.servethehome.com
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
E555user
Grand Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
what about MI300... MLID hat es am Ende von seinem Take ausreichend zusammengefasst, AMD hat bestätigt dass sie liefern wie versprochen und viele Partner aufgezeigt die dem zustimmen.
Am ehesten wäre noch anzumerken, dass das nächste ROCm 6 bis nächsten Monat kommen soll (Hinweis: das bricht die Abwärtskompatibilität)
Hat nichts mit MI300 zu tun: Hawk Point wird bereits ausgeliefert war zu lesen
Was sonst noch erheblich war ist, dass Broadcom mit den eigenen Chips künftig Infinity Fabric xGMI Anbindungen erlauben wird, dann könnte das z.B. für Hyperscaler mit MI400 direkt angebunden werden um Cluster basierend auf Ethernet noch schneller zu machen.
APU bevorzugende Software mit einheitlichem RAM soll auf MI300A bis 4x schneller als auf Nvidias Hopper laufen.
Am ehesten wäre noch anzumerken, dass das nächste ROCm 6 bis nächsten Monat kommen soll (Hinweis: das bricht die Abwärtskompatibilität)
Hat nichts mit MI300 zu tun: Hawk Point wird bereits ausgeliefert war zu lesen
Was sonst noch erheblich war ist, dass Broadcom mit den eigenen Chips künftig Infinity Fabric xGMI Anbindungen erlauben wird, dann könnte das z.B. für Hyperscaler mit MI400 direkt angebunden werden um Cluster basierend auf Ethernet noch schneller zu machen.
APU bevorzugende Software mit einheitlichem RAM soll auf MI300A bis 4x schneller als auf Nvidias Hopper laufen.
Zuletzt bearbeitet:
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Ich bin dummerweise noch vor der Präsentation eingeschlafen. Habs aber nachgeholt und ich meine sie sagten, dass es noch im Dezember kommt.Am ehesten wäre noch anzumerken, dass das nächste ROCm 6 bis nächsten Monat kommen soll (Hinweis: das bricht die Abwärtskompatibilität)
Ansonsten war ich auch überrascht, dass Dell schon Bestellungen annimmt und das If lizenziert wird.
Aber alles in allem war es ne Runde Sache. Software ist halt noch zu beurteilen. Die Frage ist halt inwieweit AMD Kapazitäten beim packaging hat, weil das ja wirklich anspruchsvoll ist.
E555user
Grand Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Die ganze AI-Präsentation war gleichermassen im Stil der EPYC Präsentationen - gerichtet an OEM-Partner und Hyperscaler.
Man präsentiert zu aller erst eine stabile und verlässliche Entwicklung mit eigenen Vorteilen gegenüber der Konkurrenz. Man will langfristige Partner bzw. Kunden.
XDNA und PC basierte AI Entwicklung auf den APUs war noch ein Anghängsel aber hatte IMHO die meisten echten News. Das müsste meiner Meinung nach künftig eine eigene Präsentation bekommen, sobald durch Microsoft AI im Mainstream ausgerollt wird.
[automerge]1701960687[/automerge]
Da war wohl mehr XDNA(2) drin als in der Show gezeigt.
Man präsentiert zu aller erst eine stabile und verlässliche Entwicklung mit eigenen Vorteilen gegenüber der Konkurrenz. Man will langfristige Partner bzw. Kunden.
XDNA und PC basierte AI Entwicklung auf den APUs war noch ein Anghängsel aber hatte IMHO die meisten echten News. Das müsste meiner Meinung nach künftig eine eigene Präsentation bekommen, sobald durch Microsoft AI im Mainstream ausgerollt wird.
[automerge]1701960687[/automerge]
Hast Du evtl. den gesamten Foliensatz als Pressedeck zum posten?Ich bin dummerweise noch vor der Präsentation eingeschlafen.
Da war wohl mehr XDNA(2) drin als in der Show gezeigt.
Zuletzt bearbeitet:
★ Themenstarter ★
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.486
- Renomée
- 9.834
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Leider nicht. Ich versuche mal dranzukommen.Hast Du evtl. den gesamten Foliensatz als Pressedeck zum posten?
Da war wohl mehr XDNA(2) drin als in der Show gezeigt.
E555user
Grand Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Lustige Geschichte: bei Nvidia hat man mit eigenen Benchmarkbalken auf die AMD-Präsentation reagiert um diese zu diskreditieren. Dabei hat man nicht mit der Kompetenz der eigenen Kunden gerechnet. Eine erste Reaktion war (von Vigotti Francesco) hervorzuheben, dass Nvidia für diese eigenen Aussagen die Angaben von Latenz auf Durchsatz der Anfragen umgedichtet bzw. falsch verglichen hatte. Mindestens genauso fragwürdig ist die Balkendarstellung zu weiteren Batches, ohne dieses gleichermassen für ein MI300 nachzuführen.
Das Marketing nimmt bizarre Züge an, es geht offensichtlich um viel Geld.
Das Marketing nimmt bizarre Züge an, es geht offensichtlich um viel Geld.
Ähnliche Themen
- Antworten
- 3
- Aufrufe
- 363
- Antworten
- 0
- Aufrufe
- 58