App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Bulldozer rollt an....
- Ersteller neax
- Erstellt am
- Status
- Für weitere Antworten geschlossen.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Der normale Ablauf schon, aber die Frage für mich war: Was geht nebenbei noch? Bzw. welche Ressourcen werden wann belegt. Nun ist's mir klar: der Result Bus ist bei ALU+AGU ops 2mal belegt, so dass der Scheduler zwar nur einmal issued, aber danach einige issue-timeslots nicht nutzen kann, da der Result Bus belegt sein wird.@Dresdenboy:
Hm, das ist doch der normale Ablauf, oder nicht? Bevor der ALU Befehl mit MemOp loslegen kann, braucht er erstmal seine Speicheradresse, d.h. die ALU µOp warten erstmal im Scheduler, bis die AGU µOp fertig ist. Durchsatz kann trotzdem 2 µOps pro Takt sein, da die beiden µOps ja nicht aus der gleichen MacroOp stammen müssen.
Dazu eine gerade durchgeführte Pipeline-Sim (keine Angst um meinen Sonntag, das meiste hatte ich schon fertig ^^):

gelb - DISP, orange - SCHED, hellgrün - EXEC oder LS probe, hellblau - ADDGEN, rosa - DC hit, dunkelgrün - LS response (data) oder inst. complete, hellgrau - waiting for retire, dunkelgrau - retire
Das markierte add ecx, mem hängt von dem mov ecx darüber ab, wird aber schon im nächsten Zyklus gestartet, da dem Scheduler die Ankunftzeit der Daten bekannt ist (siehe auch Hans' Opteron-Artikel). Aber am Ende wird der Result Bus 2mal belegt. Mov macht das nur einmal. Aber wenn der Result-Bus in bestimmten Takten noch belegt ist, kann paar Takte früher kein neuer Befehl in der Pipeline gestartet werden.
Markus Everson
Grand Admiral Special
Wie gesagt ist mein technisches Verständnis auf das Thema bezogen beschränkt.
Herrje, hat das Forensystem schon wieder meine Ironie-Tags verschluckt?
")
Scherz beiseite. Worauf ich hinweisen wollte: Wer hohen Takt als Goldenen Pfad zur Performancesteigerung anpreist ignoriert oder übersieht das hoher Takt immer mehr Energie verschluckt als geringerer Takt.
Was ich nicht erwähnt sondern für selbstverständlich gehalten habe: Wer Effizienzsteigerung als Goldenen Pfad zur Performancesteigerung anpreist irgnoriert oder übersieht das alle Mittel zur Effizienzsteigerung schon soweit ausgereizt sind das eigentlich nur noch neue Befehle für nennenswerte Rückzahlung des Aufwandes sorgen.
Und was zum Glück keiner herausgefordert hat ist das ich das ganze auch nochmal für Multicores ausformuliere
Mein Fazit: Weder das eine noch das andere alleine wird ausreichen. AMD wird das bewußt sein und wenn es richtig gut läuft, dann könnte Bulldozer hohe Effizienz (dank neuer Architektur und Modulkonzept) bei massivem multithreading- mit hoher Performance (dank hohem Takt) in Singlethreadingsoftware verbinden.
Wenns Scheiße läuft ist alles Geschwätz nur heiße Luft und Bulldozer säuft ab wie Itanium. Aber die Gefahr kann (und will, bin ja schließlich bekennnender Fanboy) ich derzeit nicht sehen.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.228
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Wenn man vom K10 ausgeht, wäre das bei beim Bulldozer (spekulatius) 2x3 ALU + 2x1AGU für ein Modul.Deswegen ist die Darstellung doch aber nicht falsch. Aus dem Bild geht überhaupt nicht hervor, wie viele Ausführungseinheiten vorhanden sind. Wenn ich mal aus dem Software Optimization Guide für 10h zitieren darf:
Und genau diese 3 Pipes sind auch bei Magny Cours visualisiert. Bulldozer hat nun eine Pipe mehr, eben 4. Inwiefern Pipes und Ausführungseinheiten zwischen Bulldozer und K10 vergleichbar sind, ist wiederum ein anderes Thema und bisher noch unklar.
Wenn man jetzt das Hyperthreading mit einbezieht, könnten das 1x6ALU + 1x2AGU bedeuten.
Das ist jetzt zwar eine Milchmädchenrechnung, allerdings würde es wiederum den shared L2 Cache erklären bzw. verdeutlichen.
Wenn es AMD gelingt mit dem neuen Compiler, 1 Modul als 1 Kern anzusprechen wäre das schon eine heftige "Schaufel"
P.S. der reale Bulldozer kann sich doch auch auf der Stelle um 360° drehen weil beide Ketten sich gegenläufig antreiben lassen...

Das wirrwar nimmt kein Ende, bin echt mal auf die Cebit gespannt! 8)
MfG
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
@Fruehes Erklärung zu BD:
In seinem Leistungsvergleich bringt er Folgende Zahlen:
"...
Mythical 6-core bulldozer:
100% + 95% + 95% + 95% + 95% + 95% = 575%
Orochi die with 4 modules:
180% + 180% + 180% + 180% = 720%
What if we had just done a 4 core and added HT (keeping in the same die space):
100% + 95% +95% +95% + 18% + 18% + 18% + 18% = 457%
What about a 6 core with HT (has to assume more die space):
100% + 95% +95% +95% +95% +95% + 18% + 18% + 18% + 18% + 18% + 18% = 683%
..."
Es ist aber nicht korrekt, im ersten Fall ("Myticl 6-core BD") jedes weitere Core mit dem 5%-Abschlag zu belasten, aber im Orchi-Fall ein weiteres hinzukommendes Modul ohne den Abschlag zu belasten, als wäre es wiederum das Erste, insofern müsste es für den Orchi-Fall dann korrekt eher so aussehen:
180% + 95%*(180%) + 95%*(180%) +95%*(180%) +95%*(180%) = 693%
Zudem: wird im Falle von HT jedes weitere Core nur noch mit 95% belastet, dürfte die Mehrleistung durch HT deutlich höher ausfallen, als wenn dass Core zu 100% ausgelastet wäre, womit dann der Leistungszuwachs >+18% sein müsste, oder? Würde aus den +18% auch nur unwesentlich mehr, z.B. +20%, ergäbe sich schon:
100% + 95% +95% +95% +95% +95% + 18% + 20% + 20% + 20% + 20% + 20% = 693%
,,,und schon sieht alles etwas anders aus.
In seinem Leistungsvergleich bringt er Folgende Zahlen:
"...
Mythical 6-core bulldozer:
100% + 95% + 95% + 95% + 95% + 95% = 575%
Orochi die with 4 modules:
180% + 180% + 180% + 180% = 720%
What if we had just done a 4 core and added HT (keeping in the same die space):
100% + 95% +95% +95% + 18% + 18% + 18% + 18% = 457%
What about a 6 core with HT (has to assume more die space):
100% + 95% +95% +95% +95% +95% + 18% + 18% + 18% + 18% + 18% + 18% = 683%
..."
Es ist aber nicht korrekt, im ersten Fall ("Myticl 6-core BD") jedes weitere Core mit dem 5%-Abschlag zu belasten, aber im Orchi-Fall ein weiteres hinzukommendes Modul ohne den Abschlag zu belasten, als wäre es wiederum das Erste, insofern müsste es für den Orchi-Fall dann korrekt eher so aussehen:
180% + 95%*(180%) + 95%*(180%) +95%*(180%) +95%*(180%) = 693%
Zudem: wird im Falle von HT jedes weitere Core nur noch mit 95% belastet, dürfte die Mehrleistung durch HT deutlich höher ausfallen, als wenn dass Core zu 100% ausgelastet wäre, womit dann der Leistungszuwachs >+18% sein müsste, oder? Würde aus den +18% auch nur unwesentlich mehr, z.B. +20%, ergäbe sich schon:
100% + 95% +95% +95% +95% +95% + 18% + 20% + 20% + 20% + 20% + 20% = 693%
,,,und schon sieht alles etwas anders aus.
ONH
Grand Admiral Special
Die Minderleistung der 2.-nten-Cores ergibt sich aus dem Thread managment und kann somit auch mit SMT nicht zurückgeholt werden und wird da sicher nicht kleiner sein, da mehr Threads vorhanden sind. Und das scheint in den 180% bei BD schon eingerechnet zu sein. Also sieht da gar nichts anderst aus. Ausserdem ist der 95% ab dem 3. Core auch nur ein wunschdenken ind der Realität wird das eher kleiner als 95% sein.
BTW der Desktop BD wird doch zur Cebit vorgestellt. denn Phenom II +50% kann nicht Llano sein.
http://www.cebit.de/de/ueber-die-messe/themen-und-trends/cebit-neuheiten/kalenderwoche-8/starke-leistung
BTW der Desktop BD wird doch zur Cebit vorgestellt. denn Phenom II +50% kann nicht Llano sein.
http://www.cebit.de/de/ueber-die-messe/themen-und-trends/cebit-neuheiten/kalenderwoche-8/starke-leistung
Zuletzt bearbeitet:
MR2
Vice Admiral Special
- Mitglied seit
- 21.08.2002
- Beiträge
- 884
- Renomée
- 24
- Standort
- Sachsen - Erzgebirge -
- Details zu meinem Desktop
Gabs hier das neue Die Shot schon?
http://www.computerbase.de/news/har...ldozer-neue-die-shots-und-cebit-ankuendigung/
-----------------------------------------------------
Ist ja vom 24......
http://www.computerbase.de/news/har...ldozer-neue-die-shots-und-cebit-ankuendigung/
-----------------------------------------------------
Ist ja vom 24......
Zuletzt bearbeitet:
Gab es schon: http://www.planet3dnow.de/vbulletin/showthread.php?p=4385397#post4385397
Mir ist nur der deutsche Text zur Cebit unveils Geschichte neu.
Mir ist nur der deutsche Text zur Cebit unveils Geschichte neu.
Der US-amerikanische CPU- und Chip-Hersteller AMD wird auf der CeBIT 2011 Prozessoren vorstellen, mit denen die Leistung der derzeitigen Top-Modelle der Phenom-II-Reihe um 50 Prozent übertroffen werden soll.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Ja. Das sagt uns aber trotzdem noch nichts über die Funktionalität der Ausführungseinheiten. Ich denke nicht, dass man einfach die Ausführungseinheiten vom K10 übernommen hat. Die wurden sicherlich gründlich überarbeitet, wie auch die Ausführungseinheiten der FPU.Sollte Bulldozer nicht 2 AGU und 2 ALUs bekommen?!
Nicht wirklich. Pipelines und Ausführungseinheiten sind nicht das gleiche. Als "Pipe" würde ich hier vielmehr die Anbindung des Scheduler an die Ausführungseinheiten sehen.Da ist mal wieder ein Verständnisfehler (nicht von Dir, sondern allgemein) zw. Pipeline und Unit. Wo ist da der Unterschied ? Gibts nicht, Unit ist nur der funktionale Begriff, Pipeline der technische. ALU und AGU sind trotz der "Unit" Bezeichnung immer noch Pipelines.
Nehalem ist 3-issue oder 6-issue, je nach dem, ob man Load/Store mitzählt oder nicht. Praktisch genauso wie K10. Der Aufbau und damit die Funktionsweise ist einfach anders.Ein BD-Integer-Core wird wohl 2-Issue-Wide sein. K10.5 war noch 3 Issue-Wide.
Nehalem ist 4-Issue-Wide.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Sag mal bitte kurz, was Du unter Pipe verstehst, ich versteht das so wie in Wikipedia:Nicht wirklich. Pipelines und Ausführungseinheiten sind nicht das gleiche. Als "Pipe" würde ich hier vielmehr die Anbindung des Scheduler an die Ausführungseinheiten sehen.
http://de.wikipedia.org/wiki/Pipeline_%28Prozessor%29Die Pipeline (auch Befehls-Pipeline oder Prozessor-Pipeline) bezeichnet bei Mikroprozessoren eine Art „Fließband“, mit dem die Abarbeitung der Maschinenbefehle in Teilaufgaben zerlegt wird, die für mehrere Befehle parallel durchgeführt werden. Dieses Prinzip, oft auch kurz Pipelining genannt, stellt eine weit verbreitete Mikroarchitektur heutiger Prozessoren dar.
CPUs ohne Pipelines gabs mal vor Urzeiten, das letzte der Spezies das ich kenne war die K6 FPU.
Aber im speziellen BD Fall (um den gings ja) gibts aber keine FUs ohne Pipeline, deswegen ist das in dem Fall gleich, die FUs werden durch Pipelines realisiert.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Die Execution Units sind Teil der Pipelines und werden in den jeweiligen Stufen aktiv (übernehmen z.B. übergebene Werte). Man könnte es heute aber so sehen, dass es Teil-Pipelines gibt, die parallel vorliegen (z.B. für Integer-Befehle), aber zusammen wieder Teil der Gesamtpipeline sind (Fetch, Decode usw.), wo nicht nur 1 Befehl bearbeitet wird.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Hatte ich das nicht getan? Du zitierst doch hier allgemeine Erläuterungen. Ich sprach aber von dem, was AMD als "Pipe" innerhalb des Integer Clusters bezeichnet. Und das ist eben nicht das gleiche wie die Ausführungseinheiten. Wie Dresdenboy schon sagt, man kann die Ausführungseinheiten als Teil der Pipeline sehen.Sag mal bitte kurz, was Du unter Pipe verstehst
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
dann könnte Bulldozer hohe Effizienz (dank neuer Architektur und Modulkonzept) bei massivem multithreading- mit hoher Performance (dank hohem Takt) in Singlethreadingsoftware verbinden.
Falls das bei meinen Posts nicht herausgekommen ist: Exakt das wollte ich auch ausdrücken
") Nach deinem Fazit sind wir einer Meinung...
Nach deinem Fazit sind wir einer Meinung...LG
...dann könnte Bulldozer hohe Effizienz (dank neuer Architektur und Modulkonzept) bei massivem multithreading- mit hoher Performance (dank hohem Takt) in Singlethreadingsoftware verbinden....
Falls das bei meinen Posts nicht herausgekommen ist: Exakt das wollte ich auch ausdrücken
LG
Genau das waere auch meine Vorstellung - das eine ohne dem anderen wird AMD vermutlich auf Dauer nicht reichen. Ich will sogar sagen, dass beides her 'muss' um auf Dauer - beinah egal wo - bestehen zu koennen. Man wird gewiss nicht immer mehr Cores 'sinnvoll' anbinden koennen - genauso wenig wird man den Takt oder die 'Effektiviaet' eines Cores nicht unendlich erhoehen koennen.
Die Loesung liegt dazwischen.
AMD muss hier den Sweetspot auf smarter Art und Weise finden... BD mag da der Anfang sein.
BD wird gut - aber ich wage mal die Prognose, dass BD II (der, der schon 2012 den hiesigen BD abloesen soll) vielleicht erst richtig zeigen wird, was in dem Konzept steckt.
Schliesslich wird da wohl wieder ein neue Die etc. gekocht werden - dass 'nur' ein Module angefuegt wird, waere wohl etwas wenig...
!Aber leider weiss man da ja noch weniger... dabei kann es in 10 bis 22 Monaten schon so weit sein...aber wie war es noch mal mit Roadmaps..
!Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Sagt mal, in dem Prozessor-Geflüster der ct' hat sich doch mal wieder eine dolle Fehlinterpretation eingeschlichen. Die haben doch einfach in dem Bild "Percent of clocks firing" "Prior Core" durch "Llano" übersetzt. Das kann so von AMD nicht gemeint sein. So ein großer Unterschied zwischen den Kernen im Idle kann einfach nicht sein. Beide nutzen schließlich Power Gating. Zudem wurde gerade an der Verteilung des Tatksignals beim Llano stark optimiert.
TeraLord
Lieutnant
Was sagt der Spekulatius eigentlich zur zu erwartenden BOINC Performance?
Ganz simpel gedacht ist ja Programm Kontrollcode eher Integer lastig mit einigen FP oder SIMD Befehlen zur Berechung. Da könnte vom Gefühl her der AMD Ansatz ja durchaus funktionieren.
...Was aber z.B.: bei Software Renderern, Distributed Computing oder Matlab? Wenn die Performance eher von den erreichbaren FLOPs abhängt, könnte die gemeinsame FP Einheit schnell limitieren. Dann habe ich mit Zambezi keinen 8Core Prozessor, sondern doch wieder eher einen Quadcore mit einer relativ schnellen FP Unit.
Bei "Crunch Architekturen" wird ja eher die gegenteilige Ausprägung der Bulldozer Architektur entwickelt. Larrabee bzw. jetzt Knights Ferry nutzt Kerne mit 4Fach Hyperthreading und mächtigen, weiten SIMD und FP Einheiten.
Aufgehen könnte der Bulldozer Ansatz, wenn das Fusion Konzept, wie Arstechnica schreibt, einmal wirklich abhebt: Schnelle CPU Kerne, die von Massenhaft paralleler Rechenhardware umgeben sind, die das gesamte Numbercrunching übernehmen können.
Trotzdem: Bulldozer Architektur DC geeignet??
Ganz simpel gedacht ist ja Programm Kontrollcode eher Integer lastig mit einigen FP oder SIMD Befehlen zur Berechung. Da könnte vom Gefühl her der AMD Ansatz ja durchaus funktionieren.
...Was aber z.B.: bei Software Renderern, Distributed Computing oder Matlab? Wenn die Performance eher von den erreichbaren FLOPs abhängt, könnte die gemeinsame FP Einheit schnell limitieren. Dann habe ich mit Zambezi keinen 8Core Prozessor, sondern doch wieder eher einen Quadcore mit einer relativ schnellen FP Unit.
Bei "Crunch Architekturen" wird ja eher die gegenteilige Ausprägung der Bulldozer Architektur entwickelt. Larrabee bzw. jetzt Knights Ferry nutzt Kerne mit 4Fach Hyperthreading und mächtigen, weiten SIMD und FP Einheiten.
Aufgehen könnte der Bulldozer Ansatz, wenn das Fusion Konzept, wie Arstechnica schreibt, einmal wirklich abhebt: Schnelle CPU Kerne, die von Massenhaft paralleler Rechenhardware umgeben sind, die das gesamte Numbercrunching übernehmen können.
Trotzdem: Bulldozer Architektur DC geeignet??
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hmm nochmal zur Klarifikation:Der normale Ablauf schon, aber die Frage für mich war: Was geht nebenbei noch? Bzw. welche Ressourcen werden wann belegt. Nun ist's mir klar: der Result Bus ist bei ALU+AGU ops 2mal belegt, so dass der Scheduler zwar nur einmal issued, aber danach einige issue-timeslots nicht nutzen kann, da der Result Bus belegt sein wird.
(...)
Aber am Ende wird der Result Bus 2mal belegt. Mov macht das nur einmal. Aber wenn der Result-Bus in bestimmten Takten noch belegt ist, kann paar Takte früher kein neuer Befehl in der Pipeline gestartet werden.
MIt resourceBus meinst Du das dunkelgrüne, also Cache Hit ? Das ist dann bei Ops mit MemOp dann quasi 1x read und das zweite Mal write, oder ?
Jo, heutzutage sind das alles Pipelines. Aber in der guten alten Zeit, z.B. beim erwähnten K6, war die FPU FU, keine Pipeline. Ansonsten stimme ich zu, mittlerweile kann man das alles als eine große Pipe sehen, ist ja alles in Fließbandmanier organisiert, Decoder, Dispatcher, Scheduler, INT & FPU FUs. Wobei die INT FPUs dann nochmals je in AGU/ALU unterglieder sind.Die Execution Units sind Teil der Pipelines und werden in den jeweiligen Stufen aktiv (übernehmen z.B. übergebene Werte). Man könnte es heute aber so sehen, dass es Teil-Pipelines gibt, die parallel vorliegen (z.B. für Integer-Befehle), aber zusammen wieder Teil der Gesamtpipeline sind (Fetch, Decode usw.), wo nicht nur 1 Befehl bearbeitet wird.
Jo, aber Du bist ja nicht "allgemein"Hatte ich das nicht getan? Du zitierst doch hier allgemeine Erläuterungen.
Falls doch, dann erklär mir bitte die Schnittmenge der Wikidef. und Deiner Aussage:
Wieso soll jetzt nur diese eine Anbindung eine Pipe sein ? Was ist mit dem Rest drumherum ? Und überhaupt, was genau ist die Anbindung ? Laut Deiner Formulierung meinst Du irgendetwas zw. Scheduler und Ausführungseinheiten. Was ist da denn ? Mehr als ein paar bypass Leiterbahnen sehe ich da nicht, ist doch aber total uninteressantAls "Pipe" würde ich hier vielmehr die Anbindung des Scheduler an die Ausführungseinheiten sehen.

Wie besagt .. erklärs mal was Du nun genau meinst. Nachdems nicht in der Kürze klappte, diesesmal gerne etwas länger, ich werds lesen, versprochen.
Im Moment versteh ich unter Deiner Definition die gelb gezeichneten Bypasses hier:

http://chip-architect.com/news/2003_09_21_Detailed_Architecture_of_AMDs_64bit_Core.html#1
(Reservation Stations == Scheduler)
Das wirst Du aber ja wohl kaum gemeint haben, oder ?
Von was redest Du jetzt, von der gesamten Pipeline, oder nur von der INT FU Teilpipeline, die das gleiche ist, wie die INT Ausführungseinheit ? AMD benützt den Pipebegriff als Ersatz / Synonym für FUs. Vorher und nachher in der kompletten (echte) Pipeline gibts im AMD Schema keine Pipelines. Deshalb FU = Pipeline (im AMD Fall). Wenn Dus anders siehst bitte Erklärung, am Besten mit Beispiel.Ich sprach aber von dem, was AMD als "Pipe" innerhalb des Integer Clusters bezeichnet. Und das ist eben nicht das gleiche wie die Ausführungseinheiten. Wie Dresdenboy schon sagt, man kann die Ausführungseinheiten als Teil der Pipeline sehen.
Ich sehs so wie schon oben Beschrieben, eine Ausführungseinheit per se sagt erstmal gar nichts aus, ausser das was ausgeführt wird. Aber on das in Fließbandmanier in ner Pipeline passiert oder altmodisch in dem BLock, das weiss man ohne Details nicht.
Es wäre vielleicht besser wenn wir von "pipelined" und Fließband sprechen würden, anstatt von "Pipeline". Der Begriff ist mit zuvielen Bedeutungen belegt. Da gibts immer wieder Doppel und Dreifachverständnisse. Allein jetzt schon das Problem mit gesamter Pipe und INT Pipe ...
Öh, ja klingt komisch. Allerdings stand doch auch BLog als BD Vorteil, dass AMD dort die ClockGates von Anfang an in ein Design einbauen konnte, was viel einfacher bzw. besser wäre, als wenn man sie in nem bestehenden Design dazubasteln müsste, im Orginal:Sagt mal, in dem Prozessor-Geflüster der ct' hat sich doch mal wieder eine dolle Fehlinterpretation eingeschlichen. Die haben doch einfach in dem Bild "Percent of clocks firing" "Prior Core" durch "Llano" übersetzt. Das kann so von AMD nicht gemeint sein. So ein großer Unterschied zwischen den Kernen im Idle kann einfach nicht sein. Beide nutzen schließlich Power Gating. Zudem wurde gerade an der Verteilung des Tatksignals beim Llano stark optimiert.
Von daher könnte ich mir nen Vergleich mit Llano doch noch vorstellen. "Prior Core" könnte da schon auch ein Llano sein. Aber wenn das stimmen würde, würde ich fast Zacate Stromverbrauchslevels erwarten, bzw. - wenn man die gesparte Energie wieder reinvestiert - 4 GHz Standardtakt und 5 GHz TurboPerhaps most importantly, the grounds-up design opportunity enabled an unprecedented level of clock gating (see figure below from the paper) to reduce power waste as shown in the graph below.
Retrofitting a design to add logic to turn clocks off when circuits aren’t used is a time consuming and error-prone process. The Bulldozer team designed these in from the beginning which enabled the inclusion of over 30,000 individual clock enables to be used.

mocad_tom
Admiral Special
- Mitglied seit
- 17.06.2004
- Beiträge
- 1.234
- Renomée
- 52
@Opteron:
Von daher könnte ich mir nen Vergleich mit Llano doch noch vorstellen. "Prior Core" könnte da schon auch ein Llano sein.
http://blogs.amd.com/work/2011/02/22/amd-at-isscc-bulldozer-innovations-target-energy-efficiency/
And finally, a next generation AMD Turbo CORE technology implementation that provides maximum compute speed when required, and throttles back to maximum efficiency when appropriate. Bulldozer implements a significantly more aggressive version of this capability than “Llano” with more details to be disclosed in the future.
Hier bezieht sich Sam Naffziger auch auf den Llano, das steht fünf Zeilen nach der Clock-Gating-Aussage.
Aber bei Clock Gating bleibt die Leakage erhalten.
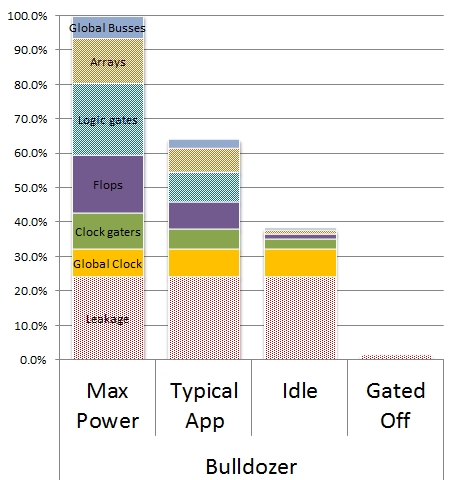
Quelle: http://www.theregister.co.uk/2011/02/24/amd_bulldozer_core_isscc/page2.html
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Wenn ich mir das hier so durchlese kommt man sich vor wie in einem Hühnerstall wo jemand das Wort "Fuchs" fallen lässt...
1. Wir haben keinerlei verlässliche Bezugspunkte um über BD kontra K10 zu spekulieren was die IPC betrifft.
2. Die Bloße tatsache dass wir 2-Issue Pro integer-Kern haben sagt über die in der Praxis erreichte IPC nicht viel aus, wie ich schon mehrfach auszudrücken versuchte. Beweist mir erstmal dass die mittlere Auslasung eines K10 über 2 liegt, bevor ihr damit kommt dass BD unterlegen wäre.
3. Ist das Modulkonzept nicht auf DIE-Size ersparnis gegenüber K10 ausgelegt sondern gegenüber einem Konzept mit "vollen" Cores der selben Architektur. Dass mit K10 kein großer Blumentopf mehr zu gewinnen ist, weiß AMD selber, auch nicht mit 5Ghz. -> also hätte es auch nichts gebracht noch mehr K10-Multicores zu bauen, ein neuer Core war sowieso fällig... also wird die Effizienz des Modulkonzeptes wohl darauf bezogen sein was ein regulärer Dualcore mit der selben Grundarchitektur geleistet hätte. Vergleiche mit K10 machen hier gar keinen Sinn.
4. Der Throughput auf dem Server mag nicht zu letzt auch Abhängig vom Speicherinterface sein, das stößt bei Server-Workloads wesentlich schneller an seine Grenzen als auf dem Desktop. Noch umsonst ist für einen der BD nachfolger Triplechannel geplant. Ohne Speicherbegrenzung mag da noch wesentlich mehr Performance rausgucken.
5. AMDs Marketing mag...ungeschikt... sein, aber die Technikabteilung ist nicht völlig verblödet...
6. BD ist die Basis für weitere Entwicklungen... die erste Inkarnation wird sicherlich noch nicht der MEssias der IT-Welt. Aber gerade durch das Modulkonzept sind dinge wie Speculative Multithreading etc. nötig die das ganze in zukünftigen BD Ablegern interessant machen.
7. Nach bisherigem Kentnisstand ist die FPU kein Flaschenhals, da sie wegen AVX sowieso doppelt so breit sein muss wie "normal" - d.h. höchstens bei 2 vollen AVX256-Threads wirds eng. Alles andere sollte ohne einbußen gehen.
also worüber streiten wir hier eigntlich? - und seit wann ist das Prozessorgeflüster die alleinige Referenz in Bezug auf den Erfolg einer CPU-Architektur? - zumal die auch nicht mehr wissen als wir...
1. Wir haben keinerlei verlässliche Bezugspunkte um über BD kontra K10 zu spekulieren was die IPC betrifft.
2. Die Bloße tatsache dass wir 2-Issue Pro integer-Kern haben sagt über die in der Praxis erreichte IPC nicht viel aus, wie ich schon mehrfach auszudrücken versuchte. Beweist mir erstmal dass die mittlere Auslasung eines K10 über 2 liegt, bevor ihr damit kommt dass BD unterlegen wäre.
3. Ist das Modulkonzept nicht auf DIE-Size ersparnis gegenüber K10 ausgelegt sondern gegenüber einem Konzept mit "vollen" Cores der selben Architektur. Dass mit K10 kein großer Blumentopf mehr zu gewinnen ist, weiß AMD selber, auch nicht mit 5Ghz. -> also hätte es auch nichts gebracht noch mehr K10-Multicores zu bauen, ein neuer Core war sowieso fällig... also wird die Effizienz des Modulkonzeptes wohl darauf bezogen sein was ein regulärer Dualcore mit der selben Grundarchitektur geleistet hätte. Vergleiche mit K10 machen hier gar keinen Sinn.
4. Der Throughput auf dem Server mag nicht zu letzt auch Abhängig vom Speicherinterface sein, das stößt bei Server-Workloads wesentlich schneller an seine Grenzen als auf dem Desktop. Noch umsonst ist für einen der BD nachfolger Triplechannel geplant. Ohne Speicherbegrenzung mag da noch wesentlich mehr Performance rausgucken.
5. AMDs Marketing mag...ungeschikt... sein, aber die Technikabteilung ist nicht völlig verblödet...
6. BD ist die Basis für weitere Entwicklungen... die erste Inkarnation wird sicherlich noch nicht der MEssias der IT-Welt. Aber gerade durch das Modulkonzept sind dinge wie Speculative Multithreading etc. nötig die das ganze in zukünftigen BD Ablegern interessant machen.
7. Nach bisherigem Kentnisstand ist die FPU kein Flaschenhals, da sie wegen AVX sowieso doppelt so breit sein muss wie "normal" - d.h. höchstens bei 2 vollen AVX256-Threads wirds eng. Alles andere sollte ohne einbußen gehen.
also worüber streiten wir hier eigntlich? - und seit wann ist das Prozessorgeflüster die alleinige Referenz in Bezug auf den Erfolg einer CPU-Architektur? - zumal die auch nicht mehr wissen als wir...
Zuletzt bearbeitet:
...Was aber z.B.: bei Software Renderern, Distributed Computing oder Matlab? Wenn die Performance eher von den erreichbaren FLOPs abhängt, könnte die gemeinsame FP Einheit schnell limitieren.
Die gemeinsame FP Einheit limitiert nur bei 256-Bit AVX-Befehlen. In allen anderen Fällen hat jeder Core seine "eigene" FPU.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Wieso? Welchen Sinn soll das machen? Vergiss einfach den Wikipedia Artikel und bleibe bei den AMD Docs.Jo, aber Du bist ja nicht "allgemein"
Falls doch, dann erklär mir bitte die Schnittmenge der Wikidef. und Deiner Aussage
Nö, genau das gehört auch zu dem, was AMD als "Pipe" bezeichnet, die Anbindung des Scheduler an die Ausführungseinheiten. Es hat ja niemand gesagt, dass das irgendwas aufwändiges oder spektakuläres wäre. Klar sind das lediglich ein paar "Leiterbahnen" und vielleicht der eine oder andere Multiplexer. Nur gehört das eben noch nicht zu den Ausführungseinheiten, aber bereits zu den Pipes.Und überhaupt, was genau ist die Anbindung ? Laut Deiner Formulierung meinst Du irgendetwas zw. Scheduler und Ausführungseinheiten. Was ist da denn ? Mehr als ein paar bypass Leiterbahnen sehe ich da nicht, ist doch aber total uninteressant
Ich sprach von der Integer Execution Pipeline, um mal den vollständigen Begriff zu nennen. Du kannst von mir aus aber auch die gesamte Pipeline nehmen. Das ist ebenso wenig falsch. Auch dazu gehören die Ausführungseinheiten.Von was redest Du jetzt, von der gesamten Pipeline, oder nur von der INT FU Teilpipeline, die das gleiche ist, wie die INT Ausführungseinheit ?
Nein, tun sie immer noch nicht. Das sagt einem schon die Logik. AMD spricht von 3 Pipes beim K10, es sind aber 6 Ausführungseinheiten. Bulldozer ist nun ein Sonderfall, da pro Pipe auch exakt eine Ausführungseinheit existiert.AMD benützt den Pipebegriff als Ersatz / Synonym für FUs.
Wie auch immer. Die Pipes beinhalten Ausführungseinheiten, jedoch sind sie kein Synonym dafür. Das ist in etwa so, als würdest du sagen, der Begriff Sonne ist ein Synonym für Wasserstoff. Die Sonne besteht zwar im Wesentlichen aus Wasserstoff, dennoch ist es nicht dasselbe.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Si claro, mach Dir da mal keine Sorgen, die FPU ist ja 2x128bittig ausgelegt. Das zählt also auch in dem Fall eher doppelt, pro Takt kannst Du max. 2xADD, 2X Mul, 1xADD/1xMul oder mit neucompiliertem Code 2xFMAC auf die Reise schicken.Was sagt der Spekulatius eigentlich zur zu erwartenden BOINC Performance?
Ganz simpel gedacht ist ja Programm Kontrollcode eher Integer lastig mit einigen FP oder SIMD Befehlen zur Berechung. Da könnte vom Gefühl her der AMD Ansatz ja durchaus funktionieren.
...Was aber z.B.: bei Software Renderern, Distributed Computing oder Matlab? Wenn die Performance eher von den erreichbaren FLOPs abhängt, könnte die gemeinsame FP Einheit schnell limitieren. Dann habe ich mit Zambezi keinen 8Core Prozessor, sondern doch wieder eher einen Quadcore mit einer relativ schnellen FP Unit.
Trotzdem: Bulldozer Architektur DC geeignet??
Wenn viele Mutliplikationen oder Additionen hintereinander in nem Code kommen, sollte das also quasi doppelt so wie bisher gehen.
Alter Code ist eh nur 128bittig, also gibts von der Sicht ebenfalls keine Probleme. Ausserdem ist 128bit Code eh schneller.
Also keine Bange, das Ding wird das perfekte Crunshing Monster, v.a. in dem Berich kannst Du mit dem oft zitierten +50% gegenüber alten K10 rechnen. Bei Zambezi eher noch mehr, da der mehr Takt erreichen wird, als die Server CPUs. Die 50% gelten offiziell nur für den Unterschied zw. Interlagos und MagnyCours.
Nö, da kommen wir nicht weiter, die Wikis fußen auf wissenschaftlicher, anerkannter Basis. Unendlich viel besser als irgendwelchem Marketinggeschurbel. V.a. wenn die Argumentation wie bei den K10<>BD Pipelines nicht stringent ist, siehe unten.Wieso? Welchen Sinn soll das machen? Vergiss einfach den Wikipedia Artikel und bleibe bei den AMD Docs.
Ok es "gehört dazu", also ist da noch mehr als die Anbindung ? Sorry, fürs spitzfindige Nachfragen, aber das muss festgenagelt werden. Oben schriebst Du nur exklusive von "Pipe = Anbindung":Nö, genau das gehört auch zu dem, was AMD als "Pipe" bezeichnet, die Anbindung des Scheduler an die Ausführungseinheiten. Es hat ja niemand gesagt, dass das irgendwas aufwändiges oder spektakuläres wäre. Klar sind das lediglich ein paar "Leiterbahnen" und vielleicht der eine oder andere Multiplexer. Nur gehört das eben noch nicht zu den Ausführungseinheiten, aber bereits zu den Pipes.
Aktueller Stand ist jetzt "Pipe = Anbindung + X", bitte das "X" genauer spezifizieren.Als "Pipe" würde ich hier vielmehr die Anbindung des Scheduler an die Ausführungseinheiten sehen.
Ok, wenn Du von der (einen)"Integer Execution Pipeline" redest, bist Du genau im Problemgebiet. Wieso solls da nur eine geben ? Ursprünglich gings doch um 3 Pipelines gegen 4 oder auch 6 ? Wieso schreibst Du nicht "von den Integer Execution Pipelines" Unwissentlich machst Du mMn genau das, was ich schon die ganze Zeit sage, du setzt die INT Ausführungseinheit mit (in diesem Fall nun einer) Pipeline gleich.Ich sprach von der Integer Execution Pipeline, um mal den vollständigen Begriff zu nennen. Du kannst von mir aus aber auch die gesamte Pipeline nehmen. Das ist ebenso wenig falsch. Auch dazu gehören die Ausführungseinheiten.
Wie schon oben geschrieben, eine CPU hat Ausführungseinheiten, INT, FP, Load/Store Units, die sind heutzutage pipelined und superskalar. Ich denke letzteren Begriff brauchen wir jetzt, sonst sieht man vor lauter Röhren den Wald nicht mehr
AMD spricht viel, wenn der Tag lange ist. Hast Du auch ne ander Begründung, außer "AMD spricht, ..." ? Ich zähl bei Hans' Bildchen, das ich oben gepostet hatte, 6 Pipelines, 3xALU, 3xAGU. Wenns keine Pipes sein sollen, dann bitte ich entweder um Nachweis, dass die AGUs oder ALUs keine Daten im Fließbandart verarbeiten, oder um eine andere Begründung, wieso diese pipelined Funktionseiheiten nicht "Pipeline " genannt werden sollten.Nein, tun sie immer noch nicht. Das sagt einem schon die Logik. AMD spricht von 3 Pipes beim K10, es sind aber 6 Ausführungseinheiten.
Hmm .. pro Pipe ? Also mehrer jetzt, oben wars doch nur eine Integer Execution Pipeline ... merkst Du das Problem ? Der Pipelinebegriff ist mit Bedeutungen überbelegt.Bulldozer ist nun ein Sonderfall, da pro Pipe auch exakt eine Ausführungseinheit existiert.
Aber Spass beiseite, da sollten wir wie schon oben gesagt dann mal den Superskalarbegriff einführen. Die INT Funktionseinheit splittet sich auf eine ALUnit und eine AGUnit auf, welche (bei BD) jeweils 2fach superskalar sind. Von mir aus können wir auch 2issue sagen, wäre mir sogar lieber. Im Endeffekt kommt man dann bei 4 Pipes raus, 2xALU, 2xAGU, beim K10 das ganze je 3fach, ergo 6.
Ne die Pipes beinhalten keine Ausführungseinheiten, die Ausführungseinheiten sind durch Pipelines/Pipelining implementiert. Funktionale Aufgabe der Sonne ist es für Licht und Wärme zu Sorgen, implementiert wird es, indem man Wasserstoffatome/moleküle fusioniert.Wie auch immer. Die Pipes beinhalten Ausführungseinheiten, jedoch sind sie kein Synonym dafür. Das ist in etwa so, als würdest du sagen, der Begriff Sonne ist ein Synonym für Wasserstoff. Die Sonne besteht zwar im Wesentlichen aus Wasserstoff, dennoch ist es nicht dasselbe.
Pipelines sind nicht notwendig, die altmodische Lösung ala K6 FPU ist nachwievor auch möglich. Macht aber halt keiner mehr. Übertragen auf den Sonnenvergleich wäre das in etwas so, wenn man als Licht & Wärmequelle anstatt der Kernfusion ne große Kerze wählen würde
Macht auch etwas warm und hell .. aber naja ...

Soviel zu meiner Sichtweise, jetzt erklär mal bitte Deine. Vor allem die Sichtweise das Du beim K10 nur auf 3 Pipelines kommst, interessiert mich.
ONH
Grand Admiral Special
@Opteron Sorry das ich da reinrede.
Wiki und wissenschaftliche Basis ist oft so, jedoch nicht zwingend, wenn jeder den Text abàndern kan wie er will, sorry bei einem Brokhaus oder so, mag das immer stimmen, bei Wiki jedoch immer seltener. klear kann das AMD Marketing noch schlechter sein Wiki ist jedoch keine wissenschaftliche Refferenz.
Wiki und wissenschaftliche Basis ist oft so, jedoch nicht zwingend, wenn jeder den Text abàndern kan wie er will, sorry bei einem Brokhaus oder so, mag das immer stimmen, bei Wiki jedoch immer seltener. klear kann das AMD Marketing noch schlechter sein Wiki ist jedoch keine wissenschaftliche Refferenz.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Grundsätzlich hast Du da recht, aber in dem Spezialfall hier weiss ich aus eigener Erfahrung, dass die Wiki 100% dem E-Tech Standard entspricht@Opteron Sorry das ich da reinrede.
Wiki und wissenschaftliche Basis ist oft so, jedoch nicht zwingend, wenn jeder den Text abàndern kan wie er will, sorry bei einem Brokhaus oder so, mag das immer stimmen, bei Wiki jedoch immer seltener. klear kann das AMD Marketing noch schlechter sein Wiki ist jedoch keine wissenschaftliche Refferenz.
AMD hingegen .. kA ... wahrscheinlich ist das Ganze dem Sachverhalt geschuldet, dass sie die Tatsache verstecken wollen, dass der neue 2issue INT Cluster schneller als der alte 3issue ist. Wenn man die Details kennt, ist das nichts Verwunderliches, aber die kennt die Marketingzielgruppe halt nicht.
Edit:
Neuer Blogeintrag von JF, aber nichts Neues, es wird nur die Aufrüstbarkeit auf Interlagos beworben:
http://blogs.amd.com/work/2011/02/25/filling-the-sockets/
Dazu gibts dann auch ein YT Video mit Bulldozer Upgrade Demo:
http://www.youtube.com/watch?v=4v07kzah91A
Aber auch nicht mehr als Taskmanager, die CPUs sind auch mit Wärmepaste beschmiert, deshalb kann man nichtmal über irgendwelche Kritzeleien darauf spekulieren
Zuletzt bearbeitet:
http://www.pcgameshardware.de/aid,8...-Mainboards-sowie-BIOS-Update/Mainboard/News/Cebit 2011: MSI bringt AMD-Bulldozer-taugliche AM3-Mainboards sowie BIOS-Update
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wenn der ominöse, schwarze AM3 Sockel kein AM3b Sockel wäre, würde ich das fast glauben ...
Aber naja, das klingt zumindest brauchbar:
So muss es sein, da würden sich viele AM3 Besitzer freuenAMD erklärte uns jedoch, dass AM3-Boards, im Gegensatz zu kommenden Platinen mit Sockel AM3+, nicht alle Funktionen von Bulldozer-CPUs unterstützen sollen. Welche Features fehlen, verriet AMD nicht.
Zuletzt bearbeitet:
- Status
- Für weitere Antworten geschlossen.
Ähnliche Themen
- Antworten
- 119
- Aufrufe
- 10K
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 6
- Aufrufe
- 1K