App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Zen - 14nm, 8 Kerne, 95W TDP & DDR4?
- Ersteller UNRUHEHERD
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Oder noch einfacher, das Diagramm stellt nur dar, dass Summit doppelt soviele Threads verarbeiten kann wie Orochikann auch gemeint sein, daß SR einfach doppelt so viel Performance hat wie Orochi.
")
MIWA
Grand Admiral Special
- Mitglied seit
- 27.10.2015
- Beiträge
- 2.215
- Renomée
- 71
- BOINC-Statistiken

- Mein Laptop
- HP Zbook X2 G4
- Details zu meinem Desktop
- Prozessor
- 2600X
- Mainboard
- AsRack X470
- Kühlung
- Eule aus Österreich ;)
- Speicher
- EUDIMM 2666mhz Dual Rank X8
- Grafikprozessor
- VII
- Display
- Phillips 55zoll
- SSD
- Intel DC3600P
- Betriebssystem
- Windoof und Linux
- Webbrowser
- Firerfox EDGE
Das steht nich nicht fest oder könnte ja ein 16kerner für "Low cost" WS kommen für am4
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Das steht nich nicht fest oder könnte ja ein 16kerner für "Low cost" WS kommen für am4
Das wär dann aber kein "Summit" wie es auf der Folie steht
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Auch Vishera basiert auf Orochi. Daher vergleicht AMD mit den neuesten Modellen. Siehe:Daß mit Orochi verglichen wird, ist auch kein gutes Zeichen, der Vergleich mit dem neuesten Modell wäre ja kleiner ausgefallen. Andererseits war nie ganz klar, was Orochi ist. Das Die von Bulldozer im Zambezi-Chip oder allgemein das 8C-Die mit dem Cache. Zum Die von Vishera haben wir ja keinen extra Codenamen.
http://www.pcgameshardware.de/FX-8320-CPU-256470/Tests/Test-FX-8320-FX-6300-FX-4300-Vishera-1032556/
Alle Vishera getauften Prozessoren basieren auf dem Orochi-Chip, AMD fertigt beispielsweise den FX-4300 auf einem teildefekten Die statt eine eigene, teure Maske zu fahren. Der kleinste Vishera kostet etwa 110 Euro und konkurriert mit Intel Core i3-3220.
TOMBOMBADIL
Lt. Commander
- Mitglied seit
- 28.04.2008
- Beiträge
- 143
- Renomée
- 10
- Standort
- Seligne, Frankreich
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 2700
- Mainboard
- MSI B450M PRO-VDH
- Kühlung
- Thermalright ARO-M14 Orange
- Speicher
- 64GB Corsair Vengeance LPX DDR4-3200
- Grafikprozessor
- Nvidia Geforce GTX 1070 ASUS STRIX 8GB
- Display
- 2x 1920×1080
- SSD
- 1x 1TB m.2, 2x 500GB Sata
- Gehäuse
- Fractal Design Define S
- Netzteil
- 550 Watt be quiet! Straight Power 11 Modular 80+ Gold
- Tastatur
- Cherry MX Board 1.0
- Maus
- Logitech G502
- Betriebssystem
- (K)Ubuntu 20.04 & Win10 for gaming
- Webbrowser
- Firefox
@Gruffti:
AMD sagt "Over 40% improvement in IPC over current AMD CPU core" und bezeichnet z.B. die FX 8xxx CPUs als 8 Kerner, nicht 4 Kerner mit CMT.
Ich würde daher eher von der durchschnittlichen IPC eines Cores im Modul verbund ausgehen, nicht von IPC steigerung im vergleich zu einem Modul.
Also so:
[Orochi - FX-8350]
8 Kerne (4 Module)
8 Threads
IPC 100%
4200 MHz Max Turbo
4100 MHz All-Core Turbo
-> All-Core Performance = 32800 (8 * 4100)
All-Core Performance = 2 * 32800 = 65600
8 Kerne
16 Threads
1,25-fache Skalierung / Kern (SMT) <=== Und das davon ausgehend dass die IPC steigerung durch SMT noch nicht in in den 40% drin sind!
IPC 160%
Bei gleichem takt also 32800 (Orochi) * 1,6 (IPC) * 1,25 (SMT) = 65600 (Also ganz genau doppelte performance eines Orochi bei identischem Takt und gleicher Kern anzahl (Ist nett dass 1,6 * 1,25 = 2))
Falls SMT schon integriert ist, dann bräuchte es also 1,25 fachen Takt (5145,5MHz) für doppelte Leistung was Dank shrink dann ja auch bei niedrigerem verbrauch durchaus sein könnte.
Oder nur 0,625 fachen Takt für gleiche leistung (2562.5MHz vs 4100MHz).
AMD sagt "Over 40% improvement in IPC over current AMD CPU core" und bezeichnet z.B. die FX 8xxx CPUs als 8 Kerner, nicht 4 Kerner mit CMT.
Ich würde daher eher von der durchschnittlichen IPC eines Cores im Modul verbund ausgehen, nicht von IPC steigerung im vergleich zu einem Modul.
Also so:
[Orochi - FX-8350]
8 Kerne (4 Module)
8 Threads
IPC 100%
4200 MHz Max Turbo
4100 MHz All-Core Turbo
-> All-Core Performance = 32800 (8 * 4100)
All-Core Performance = 2 * 32800 = 65600
8 Kerne
16 Threads
1,25-fache Skalierung / Kern (SMT) <=== Und das davon ausgehend dass die IPC steigerung durch SMT noch nicht in in den 40% drin sind!
IPC 160%
Bei gleichem takt also 32800 (Orochi) * 1,6 (IPC) * 1,25 (SMT) = 65600 (Also ganz genau doppelte performance eines Orochi bei identischem Takt und gleicher Kern anzahl (Ist nett dass 1,6 * 1,25 = 2))
Falls SMT schon integriert ist, dann bräuchte es also 1,25 fachen Takt (5145,5MHz) für doppelte Leistung was Dank shrink dann ja auch bei niedrigerem verbrauch durchaus sein könnte.
Oder nur 0,625 fachen Takt für gleiche leistung (2562.5MHz vs 4100MHz).
Dresdenboy
Redaktion
☆☆☆☆☆☆
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nee grösser, falls es sich wirklich auf die Performance der CPU bei voller Auslastung bezieht. Aktuellere Kerne gibt es ja nur in Designs mit maximal zwei Modulen. Insofern ist das schon völlig okay so. Aktuellste Bulldozer CPU, und das ist nun mal Vishera, alles andere sind APUs, gegen zukünftige Zen CPU. Ich frage mich lediglich, ob da mit normalen FX verglichen wurde, also FX-8xxx. Oder ob die TDP-Ausreisser der FX-9xxx Reihe als Basis genommen wurden.Daß mit Orochi verglichen wird, ist auch kein gutes Zeichen, der Vergleich mit dem neuesten Modell wäre ja kleiner ausgefallen.
Was Orochi ist, ist schon lange klar. Das ist der Codename für das ursprüngliche Bulldozer CPU Design mit 4 Modulen und 8 MB L3, welches sowohl für Desktop- als auch Serverderivate verwendet wurde. Zambezi nennt sich lediglich das Package der Desktop-Modelle mit der ersten Kerngeneration (bdver1).Andererseits war nie ganz klar, was Orochi ist. Das Die von Bulldozer im Zambezi-Chip oder allgemein das 8C-Die mit dem Cache. Zum Die von Vishera haben wir ja keinen extra Codenamen.
Naja, wir wissen doch, dass es in Wirklichkeit nur 4 physische Kerne (4 verarbeitende Pipelines) sind, die jeweils mittels diverser Threading-Mechanismen 2 Threads ausführen können. Insofern halten wir uns an die technischen Grundlagen und kümmern uns nicht darum, wie das Marketing Kerne zählt.AMD sagt "Over 40% improvement in IPC over current AMD CPU core" und bezeichnet z.B. die FX 8xxx CPUs als 8 Kerner, nicht 4 Kerner mit CMT.
Meine Rechnung geht auch lediglich von 40% IPC Steigerung bei einem Thread (oder eben Marketing "Kern") aus. Diese Steigerung für beide Threads eines Moduls ergäbe nochmal eine andere Rechnung. Meine Rechnung stimmt so schon. Deine hingegen ergibt keinen Sinn. Du kannst nicht einfach IPC als Konstante betrachten, die sowohl bei single- als auch multithreaded Workloads gleich ist. Genau das hast du aber getan.Ich würde daher eher von der durchschnittlichen IPC eines Cores im Modul verbund ausgehen, nicht von IPC steigerung im vergleich zu einem Modul.
Wenn du rechnest, musst du IPC für einen Fall festlegen. Also entweder pro Thread, pro Kern (Modul) oder pro gesamter CPU. Wie genau das AMD getan hat, wissen wir nicht. Da man IPC aber üblicherweise singlethreaded vergleicht, erscheint dies für mich das sinnvollste. Alles weitere berechnet man dann mittels Threadskalierung, innerhalb des Kerns (Moduls) und für alle Kerne. Der Einfachheit halber habe ich eine lineare Skalierung von Kern zu Kern angenommen. Auch wenn das die Praxis nicht ganz hergibt.
Das wäre eine Verbesserung von knapp 74%. Das lässt mich fast glauben, dass AMD einen Excavator Marketing "Kern" (ein Thread) mit einem Zen Kern (inklusive SMT) vergleicht. Würde eigentlich recht gut passen bei +40% IPC und geschätzt +25% durch SMT (oder auch +45% IPC und +20% durch SMT). Zumindest wenn man bei identischem Takt vergleicht. Dass es sich rein auf die IPC bezieht, ist wenig wahrscheinlich. Selbst wenn da steht "over 40% improvement in IPC". Und dass Zens Takt so viel höher ausfällt (20-25%), glaube ich auch nicht.Da bestimmt schon jemand eine News dafür bastelt
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Naja, wir wissen doch, dass es in Wirklichkeit nur 4 physische Kerne (4 verarbeitende Pipelines) sind, die jeweils mittels diverser Threading-Mechanismen 2 Threads ausführen können. Insofern halten wir uns an die technischen Grundlagen und kümmern uns nicht darum, wie das Marketing Kerne zählt.
Das ist mir jetzt aber neu. Deine Beschreibung mag auf FPU-Intruktionen zutreffen, jedoch nicht auf die Integer Pipeline. Hier kann man allerdings auch sehen, dass AMD vielleicht auch die IPC der schwächelnden Floating Operationen als Basis verwendet.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Auch Integer Instruktionen durchlaufen EINE (!) Pipeline. Das ändert sich auch nicht, nur weil sie zur Ausführung an zwei verschiedene Integer EUs geschickt werden können.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Du schreibst:
Ich schreibe derer sind 8 vorhanden für Integer, sprich 8 EUs.4 physische Kerne (4 verarbeitende Pipelines)
Ja wäre schön wenn man bei den Begrifflichkeiten für ein Bulldozer Modul endlich mal bleiben könnte. Ein Modul hat 2 Integer EUs und das einzige was man als Pipeline bezeichnen kann sind darin die 2 ALUs + 2 AGUs pro Integer EU. Wenn man mit dem Begriff Kern für die iEU nicht einverstanden ist sollte man das Wort Kern beim Modulkonzept einfach komplett weglassen, das führt sonst einfach zu nichts.
Aus irgendwelchen unbeschrifteten Diagrammen irgendetwas interpretieren zu wollen halte ich auch für höchst fraglich. Selbst wenn die Skalierung bei 0 beginnen sollte und linear wäre (was man nicht weiß), weiß man überhaupt nicht was in dem Diagramm eigentlich dargestellt ist. Könnte genauso gut auch die Zugriffszeit auf den L2 Cache sein oder einfach ein künstlerisches größer = besser.
Oben drüber steht ja auch wieder nur sinngemäß "40% IPC improvement expected" das ist die einzige Größe an die man sich richten sollte und die ist schon schwammig genug für diverse Spekulationen.
Aus irgendwelchen unbeschrifteten Diagrammen irgendetwas interpretieren zu wollen halte ich auch für höchst fraglich. Selbst wenn die Skalierung bei 0 beginnen sollte und linear wäre (was man nicht weiß), weiß man überhaupt nicht was in dem Diagramm eigentlich dargestellt ist. Könnte genauso gut auch die Zugriffszeit auf den L2 Cache sein oder einfach ein künstlerisches größer = besser.
Oben drüber steht ja auch wieder nur sinngemäß "40% IPC improvement expected" das ist die einzige Größe an die man sich richten sollte und die ist schon schwammig genug für diverse Spekulationen.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Wie ich bereits schrieb, auch für Integer sind nur 4 Pipelines vorhanden. Wäre ja auch komisch wenn nicht. Zu Beginn der Pipeline steht (Pre-)Fetch und Decoding. Diesen Einheiten ist es erst mal völlig wurscht ob Integer, FP, Sprung oder was auch immer für Instruktionen. Eine EU ist keine Pipeline. Man kann sie vielleicht maximal als Teilpipeline betrachten bzw Teilpipelines, wenn man ALUs und AGUs separat betrachtet. Davon spreche ich aber nicht. Ich spreche von der gesamten Architekturpipeline.Du schreibst:
Ich schreibe derer sind 8 vorhanden für Integer, sprich 8 EUs.
Was ist denn die eine Architekturpipeline? Spätestens nach dem Prefetcher teilt sich die Pipeline in 4 bzw. 8 decoding pipelines und am ende hat man 12 parallele ausführungspipelines. Aber wer sagt, dass es nur einen Prefetcher am Anfang gibt? Da sollte sowieso schon pro Thread unabhängig gearbeitet werden, also hat man quasi schon mindestens 2 "Architekturpipelines".
IT-Extremist
Gesperrt
- Mitglied seit
- 09.12.2015
- Beiträge
- 225
- Renomée
- 1
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.426
- Renomée
- 1.998
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
@ gruffi
Willst du damit ernsthaft behaupten das für dich nach dem Decoder die Verarbeitung der Informationen abgeschlossen ist?
Schon interessant was für Argumentationen an den Tag gelegt werden. Dem zufolge wäre auch das Brot nach der Ernte des Korns bereits fertig.
Willst du damit ernsthaft behaupten das für dich nach dem Decoder die Verarbeitung der Informationen abgeschlossen ist?
Schon interessant was für Argumentationen an den Tag gelegt werden. Dem zufolge wäre auch das Brot nach der Ernte des Korns bereits fertig.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hmmm ... also viel sieht man da auch nicht.
Angenommen, die Teile in den Ecken wären die Cores - das könnte gut sein - aber es bliebe viel zu wenig Fläche für die GPU übrig. Ergo ist das nicht die Zen-Apu.
Was außerdem auffällt ist, dass man keine großen Cache-Flächen erkennen kann. Selbst auf ner APU sollte man da aber wenigstens den L2-Cache erkennen können.
Mögliche Schlussfolgerung:
a) Die Zen-Apu hat nicht mal L2
b) Es ist ne GPU
c) Das Foto zeigt eine Ansicht, auf der man die Caches nicht erkennt. Damit könnte das Ganze schlimmstenfalls ein schnödes Bulldozer-Die sein. Das hat die 4 Module ebenfalls außen und mittig etwas L3-Cache. Von den Proportionen könnte das halbwegs passen, da das Schrägbild die Ansicht schmälert.
TOMBOMBADIL
Lt. Commander
- Mitglied seit
- 28.04.2008
- Beiträge
- 143
- Renomée
- 10
- Standort
- Seligne, Frankreich
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 2700
- Mainboard
- MSI B450M PRO-VDH
- Kühlung
- Thermalright ARO-M14 Orange
- Speicher
- 64GB Corsair Vengeance LPX DDR4-3200
- Grafikprozessor
- Nvidia Geforce GTX 1070 ASUS STRIX 8GB
- Display
- 2x 1920×1080
- SSD
- 1x 1TB m.2, 2x 500GB Sata
- Gehäuse
- Fractal Design Define S
- Netzteil
- 550 Watt be quiet! Straight Power 11 Modular 80+ Gold
- Tastatur
- Cherry MX Board 1.0
- Maus
- Logitech G502
- Betriebssystem
- (K)Ubuntu 20.04 & Win10 for gaming
- Webbrowser
- Firefox
Naja, wir wissen doch, dass es in Wirklichkeit nur 4 physische Kerne (4 verarbeitende Pipelines) sind, die jeweils mittels diverser Threading-Mechanismen 2 Threads ausführen können. Insofern halten wir uns an die technischen Grundlagen und kümmern uns nicht darum, wie das Marketing Kerne zählt.
Darüber kann man streiten, es ist aber eine marketing Folie daher sind vlt. durchaus marketing Kerne gemeint... Und ich gehe mal davon aus.
Meine Rechnung geht auch lediglich von 40% IPC Steigerung bei einem Thread (oder eben Marketing "Kern") aus. Diese Steigerung für beide Threads eines Moduls ergäbe nochmal eine andere Rechnung. Meine Rechnung stimmt so schon. Deine hingegen ergibt keinen Sinn. Du kannst nicht einfach IPC als Konstante betrachten, die sowohl bei single- als auch multithreaded Workloads gleich ist. Genau das hast du aber getan.
Jupp, genau das habe ich getan und auch geschrieben:
Ich gehe von der durchschnittlichen IPC eines cores aus.
Durchschnitt aller (oder zumindest aller getesteten) workloads. Ob diese mehr single oder multi threaded sind, das weiß ich nicht, das weiß nur AMD.
Das wäre eine Verbesserung von knapp 74%. Das lässt mich fast glauben, dass AMD einen Excavator Marketing "Kern" (ein Thread) mit einem Zen Kern (inklusive SMT) vergleicht. Würde eigentlich recht gut passen bei +40% IPC und geschätzt +25% durch SMT (oder auch +45% IPC und +20% durch SMT). Zumindest wenn man bei identischem Takt vergleicht. Dass es sich rein auf die IPC bezieht, ist wenig wahrscheinlich. Selbst wenn da steht "over 40% improvement in IPC". Und dass Zens Takt so viel höher ausfällt (20-25%), glaube ich auch nicht.
Damit landen wir bei genau dem was ich geschrieben habe. Zen bei dem selben Takt und selber (marketing für dich) Kern zahl führt (im durchschnitt) zu doppelter leistung eines orochi (oder eben 1.7 facher leistung eines XV).
(Im single threaded case wohl eher weniger weil cmt dann positiv für den bulldozer reinspielt smt aber nicht für zen. Im multi threaded case eher mehr weil sich cmt scaling dann negativ bei bulldozer, smt aber positiv bei zen auswirkt.)
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Schau nochmal genauer hin!Hmmm ... also viel sieht man da auch nicht.
Angenommen, die Teile in den Ecken wären die Cores - das könnte gut sein - aber es bliebe viel zu wenig Fläche für die GPU übrig. Ergo ist das nicht die Zen-Apu.
Was außerdem auffällt ist, dass man keine großen Cache-Flächen erkennen kann. Selbst auf ner APU sollte man da aber wenigstens den L2-Cache erkennen können.
Mögliche Schlussfolgerung:
a) Die Zen-Apu hat nicht mal L2
b) Es ist ne GPU
c) Das Foto zeigt eine Ansicht, auf der man die Caches nicht erkennt. Damit könnte das Ganze schlimmstenfalls ein schnödes Bulldozer-Die sein. Das hat die 4 Module ebenfalls außen und mittig etwas L3-Cache. Von den Proportionen könnte das halbwegs passen, da das Schrägbild die Ansicht schmälert.
Wie kommst du auf APU? SR ist eine CPU ohne Grafik. 512kB L2 in 14nm sind ein halber Quadratmillimeter. Ob man das bei der Qualität sieht? BD ist es jedenfalls nicht. ^^Eine kleine Hilfe:

Und besseres Material:

Hans de Vries' Interpretation:
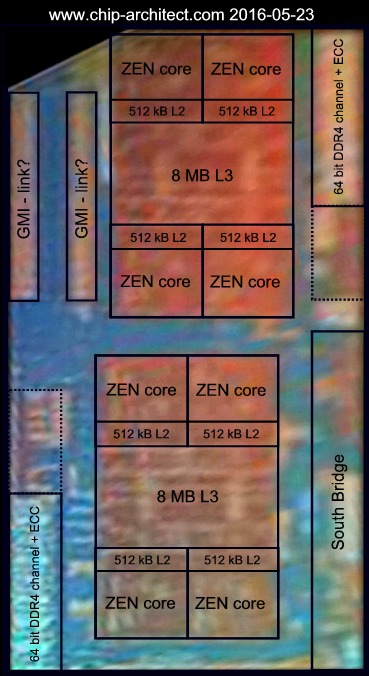
JeeBee:

Das Thema CPU-Design ist IMHO ausgelutscht, Zen wird in der Nähe dessen rauskommen was auch bei anderen CPUs üblich ist. Die erste Zen-Iteration wird wahrscheinlich einige Erweiterungen (AVX, TSX) noch nicht implementieren, das wird sich aber im Laufe der Zeit ausgleichen. Die Fabs außerhalb von Intel profitieren stark von der Verlagerung des Umsatzes zu irgendwelchen Gadgets auf Kosten von X86.
Ich erwarte für die Zukunft ausgeglichenere Marktanteile.
Ich erwarte für die Zukunft ausgeglichenere Marktanteile.
Stefan Payne
Grand Admiral Special
Können wir damit aufhören?Naja, wir wissen doch, dass es in Wirklichkeit nur 4 physische Kerne (4 verarbeitende Pipelines) sind,
Denn graben wir mal alte CPUs aus, 80286, 80386, 80486 und schauen uns die mal an.
Was sehen wir?
Richtig, nur stumpfe Dinge, die Befehle ausführen -> BD hat 2 Cores pro Modul, mit einer geteilten FPU (die eben NICHT Teil eines x86 Cores ist, da das erst beim 80486DX dabei war, SX hatte keine aktive FPU und die davor externe), auch der NX586 hatte keine FPU (nur spätere Versionen als MCM Modul).
So und anhand der Fakten haben wir nunmal 8 Cores -> 8 Integer Ausführungseinheiten. Und mehr ist ein 'Core' nun auch nicht.
Wenn dir das nicht passt, dann bezeichne das ganze als Modul.
ABER
Das ganze wurde in jedem Forum schon zich tausend mal durchgenommen...
AMD schreibt auf einer Folie auch von einem neuen "New high-Bandwidth, low-latency cache system".
Beim Übergang vom K10 auf den Bulldozer gab es bereits ein neues Cache-System, das hier und da gut arbeitete (RAR-Packer), aber teils auch ziemlicher Schrott war (L2-Zugriffszeit). Je nach dem, ob man große oder kleine Datenmengen zu beackern hatte.
Es scheint, als hätten sie aus den Problemen der ersten beiden Bulldozer-Cache-Stufen gelernt. Vielleicht kommt ein Teil der doch recht wesentlichen IPC-Steigerung gar nicht aus dem Kern-Design von Zen, sondern aus verringerten Wartezeiten auf Daten.
Beim Übergang vom K10 auf den Bulldozer gab es bereits ein neues Cache-System, das hier und da gut arbeitete (RAR-Packer), aber teils auch ziemlicher Schrott war (L2-Zugriffszeit). Je nach dem, ob man große oder kleine Datenmengen zu beackern hatte.
Es scheint, als hätten sie aus den Problemen der ersten beiden Bulldozer-Cache-Stufen gelernt. Vielleicht kommt ein Teil der doch recht wesentlichen IPC-Steigerung gar nicht aus dem Kern-Design von Zen, sondern aus verringerten Wartezeiten auf Daten.
IT-Extremist
Gesperrt
- Mitglied seit
- 09.12.2015
- Beiträge
- 225
- Renomée
- 1
Zen ohne AVX?Die erste Zen-Iteration wird wahrscheinlich einige Erweiterungen (AVX, TSX) noch nicht implementieren
Das meinst du aber nicht ernst?
Dresdenboy
Redaktion
☆☆☆☆☆☆
Schau mal die IBM-Prozessoren an. Da gibt es noch einige spannende Ideen. Auch in der Forschung - sogar ohne Quantencomputer.Das Thema CPU-Design ist IMHO ausgelutscht, Zen wird in der Nähe dessen rauskommen was auch bei anderen CPUs üblich ist. Die erste Zen-Iteration wird wahrscheinlich einige Erweiterungen (AVX, TSX) noch nicht implementieren, das wird sich aber im Laufe der Zeit ausgleichen. Die Fabs außerhalb von Intel profitieren stark von der Verlagerung des Umsatzes zu irgendwelchen Gadgets auf Kosten von X86.
Z.B. asynchrone Einheiten (besser als bei Armulet u.ä.).Zen kann erstmal bis AVX2, verschlüsselten Speicher u. VM (scheinbar besser als SGX). Etwas TSX-ähnliches (ASF o.a.) ist nicht auszuschließen, da auf den Patenten auch schon Core-Entwickler mit drauf standen (vorher nur die Forscher). Bei den Core-Zahlen würde das auch sehr helfen. Ein Stack-Cache wäre auch neu.
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Hans de Vries' Interpretation:
Core, L2 und L3 fand ich hier auch sehr eindeutig zu erkennen und interpretieren. Interessant finde ich, dass Summit Ridge nun ebenfalls als ein eher längliches Die ausgeführt ist, wie man es schon länger von Intels Dies kennt. Wenn ich zurückdenke, fällt mir das K10.5 Dualcore Dachshund-Die (z.B bei Regor verwendet) ein, welches eher länglich war. Spinnt man das weiter und verdoppelt das Die, kommt man evt. für das 16 Kern Die wieder auf was eher quadratisches
")
LG
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.426
- Renomée
- 1.998
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
@[3DC]Payne
Und wenn ich mich erinnere hatten die auch keinen Decoder wie die heutigen Prozessoren denn der wurde erst nötig als sie intern wie ein RISC Prozessor arbeiteten und die Befehle entsprechend umgewandelt werden mußten.
Damit fährt er die Decoder Logic aus seinem Posting so oder so gegen die Wand, zumal die aktuelle Ausbaustufe der Bulli Architektur ohnehin für jeden Kern einen Decoder hat.
Und wenn ich mich erinnere hatten die auch keinen Decoder wie die heutigen Prozessoren denn der wurde erst nötig als sie intern wie ein RISC Prozessor arbeiteten und die Befehle entsprechend umgewandelt werden mußten.
Damit fährt er die Decoder Logic aus seinem Posting so oder so gegen die Wand, zumal die aktuelle Ausbaustufe der Bulli Architektur ohnehin für jeden Kern einen Decoder hat.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 116
- Aufrufe
- 9K
- Antworten
- 14
- Aufrufe
- 958
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 3
- Aufrufe
- 2K