App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
News Intern: Probleme mit dem Webserver heute Nacht - und wieder da
- Ersteller Nero24
- Erstellt am
★ Themenstarter ★
- Mitglied seit
- 01.07.2000
- Beiträge
- 24.058
- Renomée
- 10.440
Wie unsere Leser bemerkt haben werden war Planet 3DNow! in den letzten 12 Stunden nicht erreichbar. Aufgrund von Problemen mit dem SCSI-Controller haben wir "Das Boot" gestern Abend heruntergefahren, um die Datenintegrität nicht zu gefährden. Anschließlich war kein Start mehr möglich; zumindest nicht mit den Mittel des Nacht-Supports vor Ort. Heute mit dem regulären Support als "Remote-Hands" war der Server - zumindest vorerst - relativ schnell wieder flott.
Wir werden zuerst einmal ausführliche Tests machen, sodass es sein kann, dass die Seite zwischenzeitlich immer mal wieder nicht erreichbar ist. Für diese Zwecke existiert ja bereits seit Jahren unser Fallback-Forum auf planet3dnow.<b>net</b>, wo wir unsere Leser immer auf dem Laufenden halten bzgl. der Arbeiten am Server.
<b>Update 29.09.2009, 13:15 Uhr</b>
Planet 3DNow! ist inzwischen wieder voll einsatzbereit, nachdem alle Komponenten einem ausführlichen Check unterzogen wurden. Was bleibt ist eine lähmende Ungewissheit bzgl. der Ursache des Ausfalls. Kurz chronologisch.
Gestern gegen 18:30 Uhr gab es erste Warn-E-Mails vom Server, dass er das Raid-1 aller SCSI-Platten verloren habe. Bis auf eine konnte im laufenden Betrieb jedoch alles wieder synchronisiert werden. Eine der DB-HDDs jedoch blieb verschollen, auch nach diversen Controller-Resets. Blieb noch einen kompletten Reset zu versuchen, in der Hoffnung, dass das Controller-BIOS die Platte bei einem Neustart wieder finden würde. Allerdings ist ein Reboot bei einem Server immer so eine Sache, der nicht zu Hause neben dem Schreibtisch steht, sondern im fernen Frankfurt am Main 350 km vom nächsten P3D-Admin entfernt.
Und so kam es wie es kommen musste: der Server bootet nicht mehr. Es war 23:30 Uhr Nachts. Im Rechenzentrum ist zu diesem Zeitpunkt nur ein Not-Support anwesend, der Monitor-Meldungen vorlesen oder vielleicht eine Live-CD einlegen, jedoch selbst nichts am Server machen darf, auch unter unserer telefonischen Anleitung nicht. Wir bekamen lediglich die Meldung, dass der Server den Bootvorgang mit "no active partitions" abbrach. Ergo hieß es erst einmal warten, bis der "echte" Support wieder im Rechenzentrum eintraf, um dessen "Remote-Hands" zu nutzen.
Dann jedoch - inzwischen haben wir den 29.09.2009 gegen halb 12 - ging es relativ schnell. Mit dem Mann vor Ort war rasch herausgefunden, dass sich im BIOS die Bootreihenfolge verstellt hatte. Der Server versuchte von einer der IDE-Platten zu booten, die als Backup-Space im Server stecken. Wir fanden heraus, dass das Tyan-Board jedes Mal die Bootreihenfolge auf IDE-0 zurücksetzte, sobald am SCSI-Controller eine Festplatte hinzugefügt oder entfernt wurde. Eine überdenkenswerte Strategie...
Aber abgesehen davon: da der Server seit November 2007 nicht angefasst wurde und seitdem ohne Probleme durchgelaufen ist, bleibt die Frage, wie das sein kann?! Ein SCSI-Kabel, das sich wie von Geisterhand über einen Zeitraum von 2 Jahren selbst lockert und damit als Verkettung unglücklicher Umstände die Bootreihenfolge ändert? Wäre mal was neues. Zumindest würde das erklären, wieso der Controller die Platten im laufenden Betrieb verloren hat und wieso der Server beim nächsten Reboot versucht hat, von IDE zu booten statt von SCSI. Aber als Erklärungsversuch äußerst dürftig.
Inzwischen ist alles wieder hergestellt, alles doppelt und dreifach gecheckt, alle Kabel kontrolliert. Offenbar ist keine der Komponenten defekt. Auch die Software inkl. der Daten scheint keinen Schaden davon getragen zu haben. So erfreulich das auf der einen Seite ist, so unbefriedigend ist dies für das Bemühen die tatsächliche Ursache zu finden und eine Wiederholung in Zukunft auszuschließen.
<b>Links zum Thema:</b><ul><li><a href="http://www.planet3dnow.de/vbulletin/showthread.php?p=2548179#post2548179">Infos zum Server</a></li><li><a href="http://www.planet3dnow.net" rel="nofollow">Das Planet 3DNow! Fallback-Forum</a></li></ul>
Wir werden zuerst einmal ausführliche Tests machen, sodass es sein kann, dass die Seite zwischenzeitlich immer mal wieder nicht erreichbar ist. Für diese Zwecke existiert ja bereits seit Jahren unser Fallback-Forum auf planet3dnow.<b>net</b>, wo wir unsere Leser immer auf dem Laufenden halten bzgl. der Arbeiten am Server.
<b>Update 29.09.2009, 13:15 Uhr</b>
Planet 3DNow! ist inzwischen wieder voll einsatzbereit, nachdem alle Komponenten einem ausführlichen Check unterzogen wurden. Was bleibt ist eine lähmende Ungewissheit bzgl. der Ursache des Ausfalls. Kurz chronologisch.
Gestern gegen 18:30 Uhr gab es erste Warn-E-Mails vom Server, dass er das Raid-1 aller SCSI-Platten verloren habe. Bis auf eine konnte im laufenden Betrieb jedoch alles wieder synchronisiert werden. Eine der DB-HDDs jedoch blieb verschollen, auch nach diversen Controller-Resets. Blieb noch einen kompletten Reset zu versuchen, in der Hoffnung, dass das Controller-BIOS die Platte bei einem Neustart wieder finden würde. Allerdings ist ein Reboot bei einem Server immer so eine Sache, der nicht zu Hause neben dem Schreibtisch steht, sondern im fernen Frankfurt am Main 350 km vom nächsten P3D-Admin entfernt.
Und so kam es wie es kommen musste: der Server bootet nicht mehr. Es war 23:30 Uhr Nachts. Im Rechenzentrum ist zu diesem Zeitpunkt nur ein Not-Support anwesend, der Monitor-Meldungen vorlesen oder vielleicht eine Live-CD einlegen, jedoch selbst nichts am Server machen darf, auch unter unserer telefonischen Anleitung nicht. Wir bekamen lediglich die Meldung, dass der Server den Bootvorgang mit "no active partitions" abbrach. Ergo hieß es erst einmal warten, bis der "echte" Support wieder im Rechenzentrum eintraf, um dessen "Remote-Hands" zu nutzen.
Dann jedoch - inzwischen haben wir den 29.09.2009 gegen halb 12 - ging es relativ schnell. Mit dem Mann vor Ort war rasch herausgefunden, dass sich im BIOS die Bootreihenfolge verstellt hatte. Der Server versuchte von einer der IDE-Platten zu booten, die als Backup-Space im Server stecken. Wir fanden heraus, dass das Tyan-Board jedes Mal die Bootreihenfolge auf IDE-0 zurücksetzte, sobald am SCSI-Controller eine Festplatte hinzugefügt oder entfernt wurde. Eine überdenkenswerte Strategie...
Aber abgesehen davon: da der Server seit November 2007 nicht angefasst wurde und seitdem ohne Probleme durchgelaufen ist, bleibt die Frage, wie das sein kann?! Ein SCSI-Kabel, das sich wie von Geisterhand über einen Zeitraum von 2 Jahren selbst lockert und damit als Verkettung unglücklicher Umstände die Bootreihenfolge ändert? Wäre mal was neues. Zumindest würde das erklären, wieso der Controller die Platten im laufenden Betrieb verloren hat und wieso der Server beim nächsten Reboot versucht hat, von IDE zu booten statt von SCSI. Aber als Erklärungsversuch äußerst dürftig.
Inzwischen ist alles wieder hergestellt, alles doppelt und dreifach gecheckt, alle Kabel kontrolliert. Offenbar ist keine der Komponenten defekt. Auch die Software inkl. der Daten scheint keinen Schaden davon getragen zu haben. So erfreulich das auf der einen Seite ist, so unbefriedigend ist dies für das Bemühen die tatsächliche Ursache zu finden und eine Wiederholung in Zukunft auszuschließen.
<b>Links zum Thema:</b><ul><li><a href="http://www.planet3dnow.de/vbulletin/showthread.php?p=2548179#post2548179">Infos zum Server</a></li><li><a href="http://www.planet3dnow.net" rel="nofollow">Das Planet 3DNow! Fallback-Forum</a></li></ul>
gruenmuckel
Grand Admiral Special
- Mitglied seit
- 17.05.2001
- Beiträge
- 29.751
- Renomée
- 1.959
- Standort
- Gerry-Weber - Stadt
- Aktuelle Projekte
- Collatz, Milkyway, POEM
- Lieblingsprojekt
- POEM & QMC etwa gleich
- Meine Systeme
- C2Q8400@3,2Ghz I7-3770K C2DE6750
- BOINC-Statistiken

- Mein Laptop
- Dell Studio 1749 @ work / Medion Erazer X7826 @ play
- Details zu meinem Desktop
- Prozessor
- Intel Core i7 6700K
- Mainboard
- Asrock Z270 Extreme4
- Kühlung
- EKL Alpenföhn Matterhorn PURE
- Speicher
- 1x 16GB G.Skill Aegis DDR4-2400 DIMM CL15-15-15-35
- Grafikprozessor
- Sapphire AMD Radeon RX 480 NITRO 8GB
- Display
- LG Ultrawide 21:9 "29UM67-P & FullHD Packard-Bell-TV
- SSD
- 1TB 840 EVO, Mushkin Reactor1TB, Sandisk Extreme 480GB
- HDD
- 1xMD04ACA400, 2x Seagate Archive 8TB
- Optisches Laufwerk
- LG GH22NS40, Sony Optiarc BD-5300S Blu-Ray Brenner
- Soundkarte
- Creative Recon3D PCIe
- Gehäuse
- Corsair Obsidian 650D (2x 140mm Vegas Duo + 1x 120mm Vegas Trio)
- Netzteil
- Corsair RM650i
- Betriebssystem
- Windows 7 64 SP1
- Webbrowser
- Firefox aktuelle Version
- Verschiedenes
- Hauppauge WinTV USB , Scythe Kaze Master Ace Lüfte
- Schau Dir das System auf sysprofile.de an
fanden heraus, dass das Tyan-Board jedes Mal die Bootreihenfolge auf IDE-0 zurücksetzte, sobald am SCSI-Controller eine Festplatte hinzugefügt oder entfernt wurde. Eine überdenkenswerte Strategie...


Die Mail an Tyan ist schon raus, oder?
PuckPoltergeist
Grand Admiral Special
Scheint Standard bei Tyan zu sein. Mit dem Problem darf ich mich hier auch immer wieder herumschlagen.Wir fanden heraus, dass das Tyan-Board jedes Mal die Bootreihenfolge auf IDE-0 zurücksetzte, sobald am SCSI-Controller eine Festplatte hinzugefügt oder entfernt wurde. Eine überdenkenswerte Strategie...

Aber abgesehen davon: da der Server seit November 2007 nicht angefasst wurde und seitdem ohne Probleme durchgelaufen ist, bleibt die Frage, wie das sein kann?! Ein SCSI-Kabel, das sich wie von Geisterhand über einen Zeitraum von 2 Jahren selbst lockert und damit als Verkettung unglücklicher Umstände die Bootreihenfolge ändert? Wäre mal was neues. Zumindest würde das erklären, wieso der Controller die Platten im laufenden Betrieb verloren hat und wieso der Server beim nächsten Reboot versucht hat, von IDE zu booten statt von SCSI. Aber als Erklärungsversuch äußerst dürftig.
Inzwischen ist alles wieder hergestellt, alles doppelt und dreifach gecheckt. Offenbar ist keine der Komponenten defekt. Auch die Software inkl. der Daten scheint keinen Schaden davon getragen zu haben. So erfreulich das auf der einen Seite ist, so unbefriedigend ist dies für das Bemühen die tatsächliche Ursache zu finden und eine Wiederholung in Zukunft auszuschließen.
Mit etwas Glück findet ihr noch in den Logs von Linux und/oder dem Controller Hinweise auf die Ausfallursache. Wenn gar nichts darin dazu geloggt wurde, habt ihr da verloren. Wenn es aber zumindest ein paar Infos in die logs geschafft haben, besteht eine Chance, den Fehler zu rekonstruieren.
Woodstock
Grand Admiral Special
- Mitglied seit
- 04.05.2002
- Beiträge
- 9.889
- Renomée
- 293
- Standort
- Somewhere in Oberfranken
- Mein Laptop
- Lenovo T460
- Details zu meinem Desktop
- Prozessor
- I7-5960x
- Mainboard
- Gigabyte GA X99 UD4
- Kühlung
- Arctic Liquid Freezer II 280
- Speicher
- 8x 8GB Corsair Venegance DDR4 2666
- Grafikprozessor
- Sapphire Nitro+ RX 480 8G D5 OC, 8GB GDDR5 (11260-01-20G)
- Display
- 2x LG 24EB23 24" 16:10 TFT/ Sony SDM-HS94 19" 5:4 TFT
- SSD
- Samsung 970 EVO Plus 250GB NVME für OS, Samsung 860 QVO 1TB für Bilder und MP3
- HDD
- 2x 3TB Seagate, 1x 2TB WD
- Optisches Laufwerk
- Asus BR Brenner, Pioneer BR Brenner
- Soundkarte
- Onoard
- Gehäuse
- Nanoxia Deep Silence 6 Anthrazit
- Netzteil
- be quiet! System Power 9 CM 600W
- Tastatur
- Zu alt
- Maus
- Auch zu alt
- Betriebssystem
- Windows 10 64
- Webbrowser
- Firefox / Chrome / IE
...
Aber abgesehen davon: da der Server seit November 2007 nicht angefasst wurde und seitdem ohne Probleme durchgelaufen ist, bleibt die Frage, wie das sein kann?! Ein SCSI-Kabel, das sich wie von Geisterhand über einen Zeitraum von 2 Jahren selbst lockert und damit als Verkettung unglücklicher Umstände die Bootreihenfolge ändert?...
War die Putzfrau im Serverraum?
") Wobei... Wenn ich den Server aus dem Link unten anschau... Die Platten sind da intern verbaut?
Wobei... Wenn ich den Server aus dem Link unten anschau... Die Platten sind da intern verbaut?Oder war es ein Techniker der aus Versehen den falschen Server erwischt und die Platten gezogen hat?
PuckPoltergeist
Grand Admiral Special
War die Putzfrau im Serverraum?
Oder war es ein Techniker der aus Versehen den falschen Server erwischt und die Platten gezogen hat?
Der Controller meckert eigentlich recht lautstark, wenn ihm Platten fehlen. Das sollte einem schon mit der ersten Platte zu denken geben, die man entfernt.

gruenmuckel
Grand Admiral Special
- Mitglied seit
- 17.05.2001
- Beiträge
- 29.751
- Renomée
- 1.959
- Standort
- Gerry-Weber - Stadt
- Aktuelle Projekte
- Collatz, Milkyway, POEM
- Lieblingsprojekt
- POEM & QMC etwa gleich
- Meine Systeme
- C2Q8400@3,2Ghz I7-3770K C2DE6750
- BOINC-Statistiken
- Mein Laptop
- Dell Studio 1749 @ work / Medion Erazer X7826 @ play
- Details zu meinem Desktop
- Prozessor
- Intel Core i7 6700K
- Mainboard
- Asrock Z270 Extreme4
- Kühlung
- EKL Alpenföhn Matterhorn PURE
- Speicher
- 1x 16GB G.Skill Aegis DDR4-2400 DIMM CL15-15-15-35
- Grafikprozessor
- Sapphire AMD Radeon RX 480 NITRO 8GB
- Display
- LG Ultrawide 21:9 "29UM67-P & FullHD Packard-Bell-TV
- SSD
- 1TB 840 EVO, Mushkin Reactor1TB, Sandisk Extreme 480GB
- HDD
- 1xMD04ACA400, 2x Seagate Archive 8TB
- Optisches Laufwerk
- LG GH22NS40, Sony Optiarc BD-5300S Blu-Ray Brenner
- Soundkarte
- Creative Recon3D PCIe
- Gehäuse
- Corsair Obsidian 650D (2x 140mm Vegas Duo + 1x 120mm Vegas Trio)
- Netzteil
- Corsair RM650i
- Betriebssystem
- Windows 7 64 SP1
- Webbrowser
- Firefox aktuelle Version
- Verschiedenes
- Hauppauge WinTV USB , Scythe Kaze Master Ace Lüfte
- Schau Dir das System auf sysprofile.de an
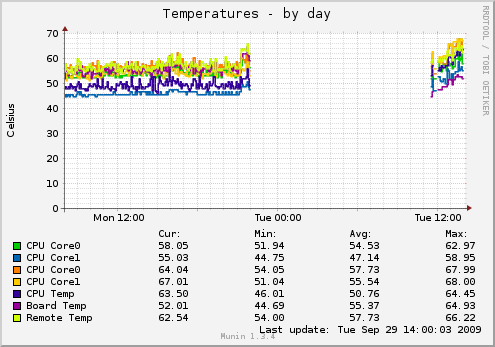
Warum wird der Server momentan deutlich wärmer als vor der Downtime?

mj
Technische Administration, Dinosaurier, ,
- Mitglied seit
- 17.10.2000
- Beiträge
- 19.529
- Renomée
- 272
- Standort
- Austin, TX
- Mein Laptop
- 2,4kg schwer
- Details zu meinem Laptop
- Prozessor
- eckig... glaub ich
- Mainboard
- quadratisch, praktisch, gut
- Kühlung
- kühler?
- Speicher
- ja
- Grafikprozessor
- auch
- Display
- viel bunt
- HDD
- ist drin
- Optisches Laufwerk
- ist auch drin (irgendwo)
- Soundkarte
- tut manchmal tuuut
- Gehäuse
- mit aufkleber!
- Netzteil
- so mit kabel und so... voll toll
- Betriebssystem
- das eine da das wo dingenskirchen halt, nech?
- Webbrowser
- so ein teil da... so grün und so
- Verschiedenes
- nunu!
Wahrscheinlich haben die Jungs mal wieder die Schranktür offen gelassen ")
KGBerlin
Grand Admiral Special
- Mitglied seit
- 03.12.2007
- Beiträge
- 11.566
- Renomée
- 356
...
Aber abgesehen davon: da der Server seit November 2007 nicht angefasst wurde und seitdem ohne Probleme durchgelaufen ist, bleibt die Frage, wie das sein kann?! ....
..... So erfreulich das auf der einen Seite ist, so unbefriedigend ist dies für das Bemühen die tatsächliche Ursache zu finden und eine Wiederholung in Zukunft auszuschließen.
.....
Never touch a running System.
And then it not run you can touch this bis it wieder run ^^
OBrian
Moderation MBDB, ,
- Mitglied seit
- 16.10.2000
- Beiträge
- 17.031
- Renomée
- 267
- Standort
- NRW
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 940 BE, C2-Stepping (undervolted)
- Mainboard
- Gigabyte GA-MA69G-S3H (BIOS F7)
- Kühlung
- Noctua NH-U12F
- Speicher
- 4 GB DDR2-800 ADATA/OCZ
- Grafikprozessor
- Radeon HD 5850
- Display
- NEC MultiSync 24WMGX³
- SSD
- Samsung 840 Evo 256 GB
- HDD
- WD Caviar Green 2 TB (WD20EARX)
- Optisches Laufwerk
- Samsung SH-S183L
- Soundkarte
- Creative X-Fi EM mit YouP-PAX-Treibern, Headset: Sennheiser PC350
- Gehäuse
- Coolermaster Stacker, 120mm-Lüfter ersetzt durch Scythe S-Flex, zusätzliche Staubfilter
- Netzteil
- BeQuiet 500W PCGH-Edition
- Betriebssystem
- Windows 7 x64
- Webbrowser
- Firefox
- Verschiedenes
- Tastatur: Zowie Celeritas Caseking-Mod (weiße Tasten)
Aber höchst interessant ist da doch, daß die Temperaturen vor dem Ausfall signifikant angestiegen sind. Entweder ein Hardwareschaden oder jemand hat daran gefingert. Jeder Fernsehkommissar würde nun fragen: "Wo waren Sie gestern zwischen 21h und 22h?"Warum wird der Server momentan deutlich wärmer als vor der Downtime?

mj
Technische Administration, Dinosaurier, ,
- Mitglied seit
- 17.10.2000
- Beiträge
- 19.529
- Renomée
- 272
- Standort
- Austin, TX
- Mein Laptop
- 2,4kg schwer
- Details zu meinem Laptop
- Prozessor
- eckig... glaub ich
- Mainboard
- quadratisch, praktisch, gut
- Kühlung
- kühler?
- Speicher
- ja
- Grafikprozessor
- auch
- Display
- viel bunt
- HDD
- ist drin
- Optisches Laufwerk
- ist auch drin (irgendwo)
- Soundkarte
- tut manchmal tuuut
- Gehäuse
- mit aufkleber!
- Netzteil
- so mit kabel und so... voll toll
- Betriebssystem
- das eine da das wo dingenskirchen halt, nech?
- Webbrowser
- so ein teil da... so grün und so
- Verschiedenes
- nunu!
Die letzte Stunde vor dem Ausfall ist das nicht wirklich verwunderlich. Wir haben alle wichtigen Dinge gesichert, ein MySQL-Dump gemacht, etc. Das belastet die Maschine spürbar, daher sind die Temperaturen in diesem Zeitraum leicht angestiegen. Der Anstieg beginnt um exakt 21:00 Uhr, als wir mit dem Backup angefangen haben, und endet um 22:00 Uhr, als wir die Maschine als letzten Notanker neustarten mussten, weil weder Busreset noch SCSI-Hostadapter-Reset geholfen haben.
Die Jungs haben die Türen mittlerweile wieder verschlossen, die Temperaturen sind auf normales Level gesunken:

Die Jungs haben die Türen mittlerweile wieder verschlossen, die Temperaturen sind auf normales Level gesunken:
Pr1nCe$$ FiFi
Grand Admiral Special
großes lob an das team! ihr seid klasse.
Starsky
Captain Special
- Mitglied seit
- 24.03.2004
- Beiträge
- 239
- Renomée
- 3
- Standort
- Celestes
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 3900X
- Mainboard
- MSI X570 Unify
- Kühlung
- Noctua NH-15D
- Speicher
- 2x 16 Gb Kingston HyperX Fury DDR4-3200MHz
- Grafikprozessor
- Zotac 1080 AMP! Extreme Plus
- Display
- 3x AOC Displays
- SSD
- Samsung NVME EVO 960 / Kingston HyperX Predator
- Gehäuse
- CM Cosmos II
- Netzteil
- Antec HPC 1300
- Betriebssystem
- Windows 10
zum glück rennt das kriegsschiff wieder =)
Bin mal gespannt ob ihr da noch etwas heraus bekommt - Ungewissheit ist ätzend
Bin mal gespannt ob ihr da noch etwas heraus bekommt - Ungewissheit ist ätzend
hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.824
- Renomée
- 331
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Tjaja die Geister in der Maschine 
Input
Vice Admiral Special
- Mitglied seit
- 23.08.2006
- Beiträge
- 965
- Renomée
- 30
Erinnerungen werden wach  , damals 2007 als das Boot in einer stürmischen Nacht heftigst Schlagseite bekamm.
, damals 2007 als das Boot in einer stürmischen Nacht heftigst Schlagseite bekamm.
Ich drück die Daumen, sicher wars nur die berühmte Putzfrau, die verflixter Weise immer für sowas Verantwortlich zu machen ist.
Gruß Input
, damals 2007 als das Boot in einer stürmischen Nacht heftigst Schlagseite bekamm.Ich drück die Daumen, sicher wars nur die berühmte Putzfrau, die verflixter Weise immer für sowas Verantwortlich zu machen ist.
Gruß Input
Nosyboy
Grand Admiral Special
- Mitglied seit
- 28.11.2001
- Beiträge
- 2.631
- Renomée
- 124
- Standort
- Switzerland
- Mein Laptop
- Lenovo IdeaPad Slim 3 (16", AMD Ryzen 5 7530U, 16GB) WIN11 / Zorin OS
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 5700X / 7nm / 65W
- Mainboard
- Gigabyte B550 Aorus Elite V2
- Kühlung
- Noctua NH-U12S Chromax Black
- Speicher
- Corsair Vengeance LPX (4x, 8GB, DDR4-3200)
- Grafikprozessor
- Sapphire Radeon Pulse 9060 XT 16GB
- Display
- Samsung C27FG70
- SSD
- Samsung SSD 860 PRO 256GB / CT1000MX500SSD1 1TB / NVMe Samsung SSD 970 EVO 1TB
- HDD
- 2TB Seagate Barracuda Green (ST2000DL003-9VT166)
- Optisches Laufwerk
- Pioneer BDR-209M
- Soundkarte
- on Board
- Gehäuse
- Chieftec Midi Tower
- Netzteil
- Seasonic Core GX ATX 3 650 W
- Tastatur
- Logitech G213
- Maus
- Logitech G403 / Logitech MX Vertical
- Betriebssystem
- WIN 10 Pro
- Webbrowser
- Opera / Edge
- Internetanbindung
- ▼100 MBit ▲20 MBit
Wie wärs ev. mal mit einem Remote Insight Board?Allerdings ist ein Reboot bei einem Server immer so eine Sache, der nicht zu Hause neben dem Schreibtisch steht, sondern im fernen Frankfurt am Main 350 km vom nächsten P3D-Admin entfernt.
Ich administriere praktisch alle Server über diese Boards - sehr praktisch.
schieby77
Commodore Special
- Mitglied seit
- 20.03.2002
- Beiträge
- 459
- Renomée
- 3
- Standort
- Erzgebirge--> Leipzig
- Mein Laptop
- Mein Rechenspecht
- Details zu meinem Desktop
- Prozessor
- Athlon xp 2500+
- Mainboard
- Epox -8RDA+ nVidia nForce Ultra 400 Rev. 2.0
- Kühlung
- Arctic Cooling Copper Silent 2 TC Rev. 2
- Speicher
- Geil 1GB (also 2 mal 512MB) DDR-RAM, 400MHz, PC 3200, Cl 2,5 (Value Serie)
- Grafikprozessor
- ATI Radeon X1600 Pro 256 MB RAM AGP 8fach
- Display
- HIGHSCREEN 19" 1397
- HDD
- 1.WD40GB/ 2.WD80GB
- Optisches Laufwerk
- LiteOn LTR -48125s CD-RW / Pioneer DVD- Rom DVD -106
- Soundkarte
- Creative SB 240 Platinum+Logitech Z 640
- Gehäuse
- Chieftec CS-901( mit Dämmatten bestückt)
- Netzteil
- Enermax 431W EG 465P-VE
- Betriebssystem
- Win XP Sp2
- Webbrowser
- Mozilla FireFox
- Verschiedenes
- Der is mittlerweile ganz schön alt^^
Naja vll. entwickelt unser "Boot", ja langsam ein eigenes Bewusstsein
Eine K.I. mit dem Namen das Boot...
lg schieby77
Eine K.I. mit dem Namen das Boot...
lg schieby77
ghostadmin
Grand Admiral Special
Verwendet ihr SCSI Terminatoren? Die machen häufiger mal die Grätsche und solche lustige Effekte passieren dann.
PuckPoltergeist
Grand Admiral Special
Verwendet ihr SCSI Terminatoren?
Das will ich doch stark hoffen.
Nur dürften die auf der einen Seite auf dem Controller und auf der anderen Seite auf der Backplane sitzen.tomturbo
Technische Administration, Dinosaurier
- Mitglied seit
- 30.11.2005
- Beiträge
- 9.450
- Renomée
- 664
- Standort
- Österreich
- Aktuelle Projekte
- Universe@HOME, Asteroids@HOME
- Lieblingsprojekt
- SETI@HOME
- Meine Systeme
- Xeon E3-1245V6; Raspberry Pi 4; Ryzen 1700X; EPIC 7351
- BOINC-Statistiken

- Mein Laptop
- Microsoft Surface Pro 4
- Details zu meinem Desktop
- Prozessor
- R7 5800X
- Mainboard
- Asus ROG STRIX B550-A GAMING
- Kühlung
- Alpenfön Ben Nevis Rev B
- Speicher
- 2x32GB Mushkin, D464GB 3200-22 Essentials
- Grafikprozessor
- Sapphire Radeon RX 460 2GB
- Display
- BenQ PD3220U, 31.5" 4K
- SSD
- 1x HP SSD EX950 1TB, 1x SAMSUNG SSD 830 Series 256 GB, 1x Crucial_CT256MX100SSD1
- HDD
- Toshiba X300 5TB
- Optisches Laufwerk
- Samsung Brenner
- Soundkarte
- onboard
- Gehäuse
- Fractal Design Define R4
- Netzteil
- XFX 550W
- Tastatur
- Trust ASTA mechanical
- Maus
- irgend eine silent Maus
- Betriebssystem
- Arch Linux, Windows VM
- Webbrowser
- Firefox + Chromium + Konqueror
- Internetanbindung
-
▼300
▲50

Der Controller hat als erstes einen Dump geschrieben.Der Controller meckert eigentlich recht lautstark, wenn ihm Platten fehlen. Das sollte einem schon mit der ersten Platte zu denken geben, die man entfernt.
Danach war eine Disk einfach weg.
Während des darauf folgenden Bus Resets kam es zu timeouts bei einem weiteren Raid1.
lg
__tom
Allfred
Grand Admiral Special
- Mitglied seit
- 11.11.2001
- Beiträge
- 7.874
- Renomée
- 98
- Standort
- Tyskland
- Details zu meinem Desktop
- Prozessor
- PIII-S 1266MHz
- Mainboard
- IBM NetVista 6568 MNG
- Kühlung
- passiv, nur Gehäuselüfter
- Speicher
- 2 x 256MB PC133 CL2
- Grafikprozessor
- GF5200 DVI lowprofile
- HDD
- Seagate 7200.9 160GB
- Optisches Laufwerk
- Slimline CD
- Soundkarte
- Chipsatz i815E
- Gehäuse
- 90mm ultra thin Desktop
- Netzteil
- HIPRO 155W
- Betriebssystem
- Planet3Dnow
- Webbrowser
- FireFox
- Verschiedenes
- Leistung mit PIII 866 = 28W
Dazu muß sich nicht ein kompletter Steckerkorb lösen, es reicht auch, daß irgendwo ein Defekt (evtl. in einem LW) die Signalpegel der Daten-/Steuer-Leitungen komplett in die Knie zwingen. Dann ist der Controller machtlos mit bekanntem Verlauf. Habt ein Augenmerk auf das nicht reanimierbare Laufwerk...Ein SCSI-Kabel, das sich wie von Geisterhand über einen Zeitraum von 2 Jahren selbst lockert und damit als Verkettung unglücklicher Umstände die Bootreihenfolge ändert?
G
Gast29012019_2
Guest
Gut solange es so läuft würde ich es belassen, aber bei einer Umrüstung des Server dann mal über SAS nachdenken, dürfte weniger anfällig als SCSI sein.
Und wenn Tyan, keine Lösung für das IDE-Problem hat, würde ich mal ganz stumpf ebenfalls ein bootfähiges System auf IDE-Platten erstellen, ebenfalls im Raid-1 so das das Boot dann halt nicht absäuft sondern nur einen Gang runterschaltet, falls SCSI ausfällt.
Und wenn Tyan, keine Lösung für das IDE-Problem hat, würde ich mal ganz stumpf ebenfalls ein bootfähiges System auf IDE-Platten erstellen, ebenfalls im Raid-1 so das das Boot dann halt nicht absäuft sondern nur einen Gang runterschaltet, falls SCSI ausfällt.
gruenmuckel
Grand Admiral Special
- Mitglied seit
- 17.05.2001
- Beiträge
- 29.751
- Renomée
- 1.959
- Standort
- Gerry-Weber - Stadt
- Aktuelle Projekte
- Collatz, Milkyway, POEM
- Lieblingsprojekt
- POEM & QMC etwa gleich
- Meine Systeme
- C2Q8400@3,2Ghz I7-3770K C2DE6750
- BOINC-Statistiken
- Mein Laptop
- Dell Studio 1749 @ work / Medion Erazer X7826 @ play
- Details zu meinem Desktop
- Prozessor
- Intel Core i7 6700K
- Mainboard
- Asrock Z270 Extreme4
- Kühlung
- EKL Alpenföhn Matterhorn PURE
- Speicher
- 1x 16GB G.Skill Aegis DDR4-2400 DIMM CL15-15-15-35
- Grafikprozessor
- Sapphire AMD Radeon RX 480 NITRO 8GB
- Display
- LG Ultrawide 21:9 "29UM67-P & FullHD Packard-Bell-TV
- SSD
- 1TB 840 EVO, Mushkin Reactor1TB, Sandisk Extreme 480GB
- HDD
- 1xMD04ACA400, 2x Seagate Archive 8TB
- Optisches Laufwerk
- LG GH22NS40, Sony Optiarc BD-5300S Blu-Ray Brenner
- Soundkarte
- Creative Recon3D PCIe
- Gehäuse
- Corsair Obsidian 650D (2x 140mm Vegas Duo + 1x 120mm Vegas Trio)
- Netzteil
- Corsair RM650i
- Betriebssystem
- Windows 7 64 SP1
- Webbrowser
- Firefox aktuelle Version
- Verschiedenes
- Hauppauge WinTV USB , Scythe Kaze Master Ace Lüfte
- Schau Dir das System auf sysprofile.de an
Ich sehe auf bei munin Boardtemperaturwerte von ~50°C.
Könnte es da bei knapp 30000 Betriebsstunden mal ne Idee sein die Kondensatoren auf Board und SCSI-Controller unter die Lupe zu nehmen? Oder ist sowas völlig ausgeschlossen?
Könnte es da bei knapp 30000 Betriebsstunden mal ne Idee sein die Kondensatoren auf Board und SCSI-Controller unter die Lupe zu nehmen? Oder ist sowas völlig ausgeschlossen?
G
Gast29012019_2
Guest
Ich sehe auf bei munin Boardtemperaturwerte von ~50°C.
Könnte es da bei knapp 30000 Betriebsstunden mal ne Idee sein die Kondensatoren auf Board und SCSI-Controller unter die Lupe zu nehmen? Oder ist sowas völlig ausgeschlossen?
Wenn die Komponenten drum rum schlecht gekühlt werden und dauerhafte Hotspots enstehen, durchaus möglich. Selbst die Controller Elektronik der Festplatten, kann sehr heiß werden, aber 50 Grad für ein Mobo ist schon recht viel, da ja die Fehlfunktion bei einer der Festplatten ja auch noch nicht geklärt worden ist.
Sollte der SCSI-Controller besserer Natur sein, könnte man versuchen den Verbund anhand eines Files was man damals gespeichert hat, wieder herzustellen. Evt. findet er dann wieder diese Platten oder kann sich am Verbund selbst wieder anmelden. Zumindest geht das bei meinem Raid-Controller, hatte zuvor die Config des Raid-5 abgespeichert, und konnte es so wieder herstellen und die Festplatte erneut anmelden, falls sie nicht defekt ist, aber durch nen defektes Kabel etc. aus dem Verbund geworfen worden ist.
tomturbo
Technische Administration, Dinosaurier
- Mitglied seit
- 30.11.2005
- Beiträge
- 9.450
- Renomée
- 664
- Standort
- Österreich
- Aktuelle Projekte
- Universe@HOME, Asteroids@HOME
- Lieblingsprojekt
- SETI@HOME
- Meine Systeme
- Xeon E3-1245V6; Raspberry Pi 4; Ryzen 1700X; EPIC 7351
- BOINC-Statistiken
- Mein Laptop
- Microsoft Surface Pro 4
- Details zu meinem Desktop
- Prozessor
- R7 5800X
- Mainboard
- Asus ROG STRIX B550-A GAMING
- Kühlung
- Alpenfön Ben Nevis Rev B
- Speicher
- 2x32GB Mushkin, D464GB 3200-22 Essentials
- Grafikprozessor
- Sapphire Radeon RX 460 2GB
- Display
- BenQ PD3220U, 31.5" 4K
- SSD
- 1x HP SSD EX950 1TB, 1x SAMSUNG SSD 830 Series 256 GB, 1x Crucial_CT256MX100SSD1
- HDD
- Toshiba X300 5TB
- Optisches Laufwerk
- Samsung Brenner
- Soundkarte
- onboard
- Gehäuse
- Fractal Design Define R4
- Netzteil
- XFX 550W
- Tastatur
- Trust ASTA mechanical
- Maus
- irgend eine silent Maus
- Betriebssystem
- Arch Linux, Windows VM
- Webbrowser
- Firefox + Chromium + Konqueror
- Internetanbindung
-
▼300
▲50
Ist zwar richtig Dein Hinweis.Ich sehe auf bei munin Boardtemperaturwerte von ~50°C.
Könnte es da bei knapp 30000 Betriebsstunden mal ne Idee sein die Kondensatoren auf Board und SCSI-Controller unter die Lupe zu nehmen? Oder ist sowas völlig ausgeschlossen?
Jedoch gibt es bisher keine intermittierende Fehler wie spontane reboots usw.
Letztlich scheint es ein abgegangener SCSI Stecker gewesen zu sein.
Zudem ist sämtliche Abluft vom Server immer ziemlich "kalt" was nicht auf zu große innere Hitze hindeutet.
lg
__tom
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 130
- Antworten
- 0
- Aufrufe
- 127
- Antworten
- 0
- Aufrufe
- 234
- Antworten
- 0
- Aufrufe
- 102
- Antworten
- 0
- Aufrufe
- 227