App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Radeon RX 6400/6500/6600/6650/6700/6750/6800/6900/6950 (XT) (Navi2x/RDNA2/PCIe 4.0): Tests/Meinungen im Netz. Links in Post 1
- Ersteller eratte
- Erstellt am
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken

- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Gozu
Vice Admiral Special
- Mitglied seit
- 19.02.2017
- Beiträge
- 521
- Renomée
- 70
- Mein Laptop
- Asus ROG Zephyrus G14 2022 (GA402RJ-L8116W) / HP 15s-eq1158ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 5900
- Mainboard
- AsRock B550 Phantom Gaming Velocita
- Kühlung
- Coolermaster MASTERLIQUID 120
- Speicher
- 2x 16GB HyperX KHX3733C19D4/16GX 3733-19
- Grafikprozessor
- AsRock RX 6800 Phantom Gaming D 16G
- Display
- 27 " iiyama G-Master GB2760QSU WQHD
- HDD
- 2x WDC WD10EADS-11P8B1
- Optisches Laufwerk
- TSSTcorp CDDVDW SH-2
- Gehäuse
- CoolerMaster HAF XB
- Netzteil
- Enermax EDT1250EWT
- Maus
- Rocat Kova
- Betriebssystem
- Windows 10 Professional x64, Manjaro
- Webbrowser
- Iron
- Internetanbindung
- ▼1000 MBit ▲50 MBit
Acer stellt nun auch AMD Karten her:

 videocardz.com
videocardz.com
Acer launches Radeon RX 7600 Predator BiFrost series, its first Radeon GPUs - VideoCardz.com
Acer launches its first Radeon GPU The BiFrost family is expanding, the company has released three new cards today. According to the report, Acer is set to introduce three new graphics cards, one powered by Intel and two by AMD. Up until now, the Predator BiFrost series had only included the Arc...
videocardz.com
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
AMD Radeon GPU Detective
Radeon™ GPU Detective (RGD) 1.0 is now available
Radeon™ GPU Detective (RGD) is our brand-new tool for investigating GPU crashes. RGD is included in the Radeon Developer Tool Suite and is available now!
Driver
Latest Adrenalin Software driver (minimum version 23.7.2)
Supported GPUs
Radeon™ RX 6000 series
Radeon™ RX 7000 series
Supported graphics APIs
Direct3D 12
Supported OSs
Windows® 10
Windows® 11
Latest Adrenalin Software driver (minimum version 23.7.2)
Supported GPUs
Radeon™ RX 6000 series
Radeon™ RX 7000 series
Supported graphics APIs
Direct3D 12
Supported OSs
Windows® 10
Windows® 11
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
AMD Software: Adrenalin Edition Preview Driver for AMD Fluid Motion Frames Release Notes (AMD)
AMD Fluid Motion Frames (AFMF) Technical Preview – Boost FPS with frame generation technology for a smoother gaming experience.
- AFMF adds frame generation technology to DirectX® 11 and 12 games on AMD Radeon™ RX 7000 (and now 6000!)Series Desktop Graphics Cards.
- We are responding to the excitement from our community and are adding support for Radeon™ RX 6000 Series Desktop Graphics Cards.
- AFMF preserves image quality by dynamically disabling frame generation during fast motion.
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 848
- Renomée
- 87
Forspoken: FSR 3
While I don’t disagree about not testing on AMD hardware, it’s far more likely the person doing the review didnt have an amd card on hand; which is still a huge oversight. It doesn’t necessarily make someone a fanboy. Correct. Maxus is based out of war-torn Ukraine. Did people assume I’m...

Watch Talos2DemoFSRvsDLSSRX6800 | Streamable
Watch "Talos2DemoFSRvsDLSSRX6800" on Streamable.
streamable.com
Das ganze "DLSS"-BS mit Ai und Tensor-Cores usw. ist eine einzige Marketing-BS von Nvidia. "DLSS" läuft unter Linux auch auf ner AMD RX6800.
Vielleicht kann das mal jemand nachtesten mit DLSS auf AMD unter Linux.
Gozu
Vice Admiral Special
- Mitglied seit
- 19.02.2017
- Beiträge
- 521
- Renomée
- 70
- Mein Laptop
- Asus ROG Zephyrus G14 2022 (GA402RJ-L8116W) / HP 15s-eq1158ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 5900
- Mainboard
- AsRock B550 Phantom Gaming Velocita
- Kühlung
- Coolermaster MASTERLIQUID 120
- Speicher
- 2x 16GB HyperX KHX3733C19D4/16GX 3733-19
- Grafikprozessor
- AsRock RX 6800 Phantom Gaming D 16G
- Display
- 27 " iiyama G-Master GB2760QSU WQHD
- HDD
- 2x WDC WD10EADS-11P8B1
- Optisches Laufwerk
- TSSTcorp CDDVDW SH-2
- Gehäuse
- CoolerMaster HAF XB
- Netzteil
- Enermax EDT1250EWT
- Maus
- Rocat Kova
- Betriebssystem
- Windows 10 Professional x64, Manjaro
- Webbrowser
- Iron
- Internetanbindung
- ▼1000 MBit ▲50 MBit
Leider gibt es eine neue Version der Demo wo sich DLSS nicht mehr auswählen lässt mit AMD Grafikkarte.
Forspoken: FSR 3
While I don’t disagree about not testing on AMD hardware, it’s far more likely the person doing the review didnt have an amd card on hand; which is still a huge oversight. It doesn’t necessarily make someone a fanboy. Correct. Maxus is based out of war-torn Ukraine. Did people assume I’m...www.techpowerup.com
Watch Talos2DemoFSRvsDLSSRX6800 | Streamable
Watch "Talos2DemoFSRvsDLSSRX6800" on Streamable.streamable.com
Das ganze "DLSS"-BS mit Ai und Tensor-Cores usw. ist eine einzige Marketing-BS von Nvidia. "DLSS" läuft unter Linux auch auf ner AMD RX6800.
Vielleicht kann das mal jemand nachtesten mit DLSS auf AMD unter Linux.

getestet auf dem ROG Ally unter ChimeraOS.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.551
- Renomée
- 593
Das ganze "DLSS"-BS mit Ai und Tensor-Cores usw. ist eine einzige Marketing-BS von Nvidia. "DLSS" läuft unter Linux auch auf ner AMD RX6800.
Vielleicht kann das mal jemand nachtesten mit DLSS auf AMD unter Linux.
Ja natürlich ist das DLSS-Programm eine Verdummbeutelung der Kunden. Die Besonderheit von den sogenannten Tensor-Cores sind die (Tensor) Matrix-Multiplikationen in hoher Bitanzahl, damit die trainierten Werte möglichst korrekt sind. Diese werden aber nur beim Training von neuronalen Netzen wichtig. Das Inferencing, also das Anwenden eines trainierten Netzes kann in optimierten NNs mit weniger Bit erfolgen. Hierbei geht es vor allem um Latenz in der Verarbeitung wenn einzelne Werte durch das Netz "seriell gejagt" werden. Ich würde vermuten ein RDNA optimiertes NN müsste immer in den IF-Cache passen und alle CUs könnten dann mit packed Math in mehreren Pixeln je CU abarbeiten.
Am Ende sind es aber bei AMD, Intel und Nvidia die gleichen Instruktionen, die hier in HW angeboten werden. Für Inferencing sehe ich die CUs mit IF-Cache von AMD als sehr gut geeignet an. Linux kann da helfen einzelne proprietäre Konstrukte in Software aufzubrechen, auch das Drumherum in Algo zum NN. Gerade durch Proton/Vulkan als einheitliche API zum Hardware-Treiber ist das Drumherum gegeben, es bleibt das NN. Das optimierte NN muss auf die Instruktionen in niedrigen Bitzahlen und die Cache-Hierarchie der Zielarchitektur angepasst werden, wir brauchen also die trainierten NNs zu DLSS als ONNX. Oder das "proprietär optimierte" NN wird halt nur durch irgend eine offene API für andere Hardware zugänglich...
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.374
- Renomée
- 1.978
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Das die meisten solcher Funktionen nur eine künstliche Abgrenzung sind und auch anderweitig umsetzbar wären sollte spätestens seit der PhysX Nummer klar sein.
Umgehungen für solche künstlichen Einschränkungen dürften eher an juristischen als an technischen Problemen scheitern.
Umgehungen für solche künstlichen Einschränkungen dürften eher an juristischen als an technischen Problemen scheitern.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
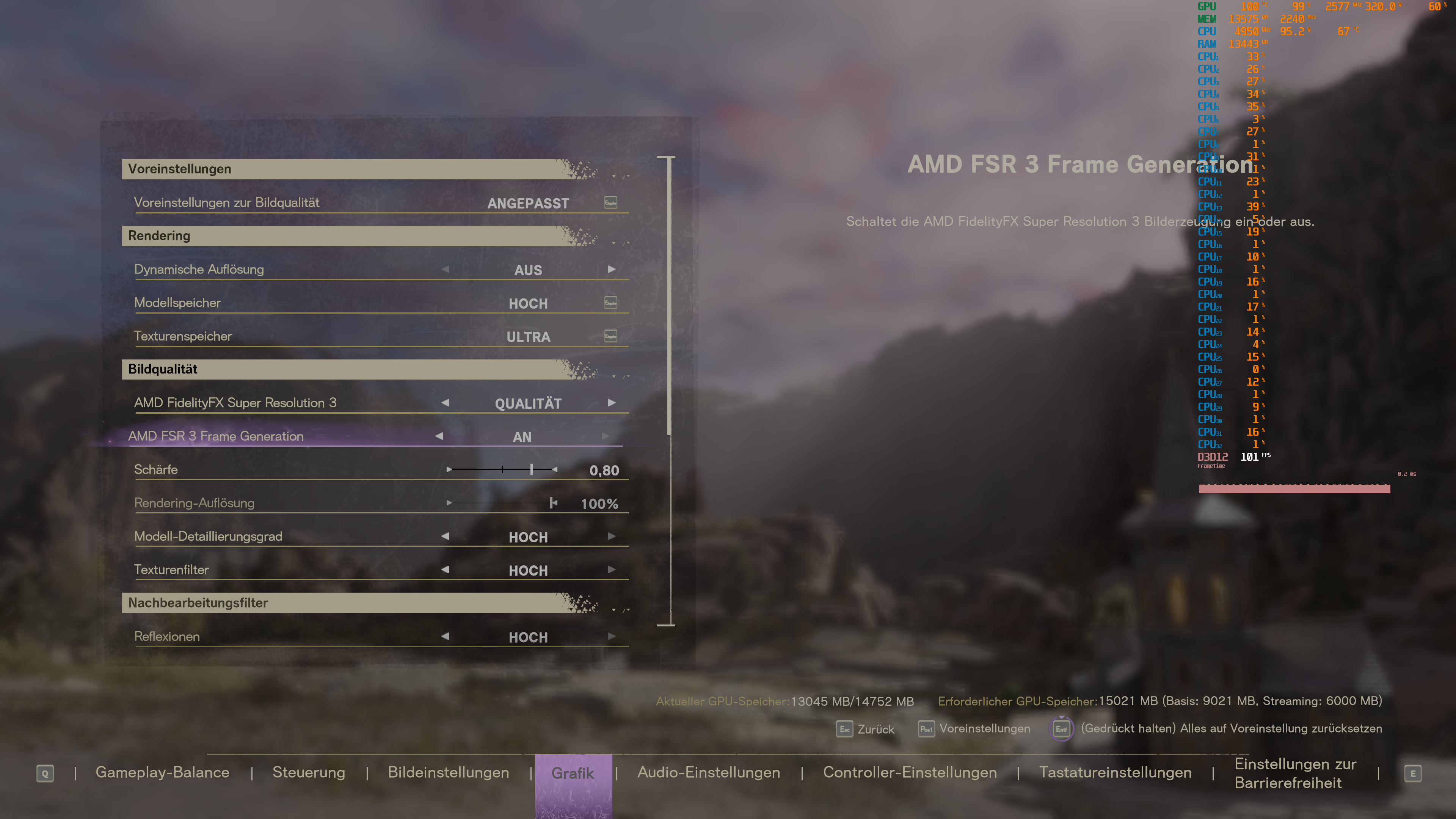
Flutsch und weg
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Totgesagte leben länger:
AMD announces two Radeon RX 6750 GRE models at $269 (10GB) and $289 (12GB) (VideoCardz)
AMD announces two Radeon RX 6750 GRE models at $269 (10GB) and $289 (12GB) (VideoCardz)
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
AMD-Grafiktreiber: Codeschmuggel durch Sicherheitslücke möglich (heise)
Betroffen sind die Grafikkarten der Baureihen AMD Radeon RX 5000, 6000 und 7000. Dafür stellt AMD die korrigierte Version 23.9.2 (23.20.11.01) der Software Arenalin seit dem späten September bereit.
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Shinsaja
Grand Admiral Special
- Mitglied seit
- 24.03.2009
- Beiträge
- 4.198
- Renomée
- 87
- Standort
- Zwickau
- Mein Laptop
- HP 445 G8 | Ryzen 7 5800U | 32GB Samsung 3200MHz | 1TB Samsung 980 M.2 NVMe | Vega 8
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5800X
- Mainboard
- Gigabyte B550M Aorus Pro
- Kühlung
- Scythe Kotetsu Mark II
- Speicher
- 32GB G.Skill Ripjaws V 3600MHz
- Grafikprozessor
- AMD Radeon RX 6800 16GB
- Display
- Samsung G3 S32AG324NU 32"
- SSD
- Samsung 970 Evo 2TB M.2 NVMe
- Soundkarte
- Realtek ALC1200
- Gehäuse
- Fractal Arc Mini R2
- Netzteil
- be quiet! Pure Power 11 CM 500W 80+ Gold
- Tastatur
- Roccat Horde Aimo
- Maus
- Roccat Kone Aimo
- Betriebssystem
- Windows 11 Pro
- Verschiedenes
- Roccat Elo 7.1 USB
- Internetanbindung
- ▼100 MBit ▲40 MBit
Wie schaut es eigentlich mit dem Thema aus, dass man das Bild einer z.B RX6600 über die IGP eines R7 5700G ausgeben lassen kann?
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Welches Bild ?Wie schaut es eigentlich mit dem Thema aus, dass man das Bild einer z.B RX6600 über die IGP eines R7 5700G ausgeben lassen kann?
Auflösung, Farbtiefe, Komprimierung, Hz, Zertifiziert ?
DualGraphics läuft, aber halt mit allen Vor- und Nachteilen.
Shinsaja
Grand Admiral Special
- Mitglied seit
- 24.03.2009
- Beiträge
- 4.198
- Renomée
- 87
- Standort
- Zwickau
- Mein Laptop
- HP 445 G8 | Ryzen 7 5800U | 32GB Samsung 3200MHz | 1TB Samsung 980 M.2 NVMe | Vega 8
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5800X
- Mainboard
- Gigabyte B550M Aorus Pro
- Kühlung
- Scythe Kotetsu Mark II
- Speicher
- 32GB G.Skill Ripjaws V 3600MHz
- Grafikprozessor
- AMD Radeon RX 6800 16GB
- Display
- Samsung G3 S32AG324NU 32"
- SSD
- Samsung 970 Evo 2TB M.2 NVMe
- Soundkarte
- Realtek ALC1200
- Gehäuse
- Fractal Arc Mini R2
- Netzteil
- be quiet! Pure Power 11 CM 500W 80+ Gold
- Tastatur
- Roccat Horde Aimo
- Maus
- Roccat Kone Aimo
- Betriebssystem
- Windows 11 Pro
- Verschiedenes
- Roccat Elo 7.1 USB
- Internetanbindung
- ▼100 MBit ▲40 MBit
Dass was die Grafikkarte generiert. Nur Ausgabe über die IGP
DannyA4
Lieutnant
- Mitglied seit
- 09.04.2007
- Beiträge
- 96
- Renomée
- 39
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 5800X
- Mainboard
- GB X570 Elite
- Kühlung
- Custom Wasserkühlung Aquacomputer
- Speicher
- 2x 16GB 3200 Crucial @3800CL16
- Grafikprozessor
- AMD Radeon 6900XT
- Display
- 3x Dell S2721DGF Triple Monitor Setup
- SSD
- Corsair MP600, PCIe 4, 1 TB
- Gehäuse
- BeQuiet! Pure Base 500
- Netzteil
- BeQuiet! Straight Power 11 850Watt
- Tastatur
- Sharkoon Purewriter RGB
- Maus
- Zowie FK1
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Internetanbindung
- ▼50MBit
Und was soll das bringen?Dass was die Grafikkarte generiert. Nur Ausgabe über die IGP
MusicIsMyLife
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 22.02.2002
- Beiträge
- 15.580
- Renomée
- 2.569
- Standort
- in der Nähe von Cottbus
- Lieblingsprojekt
- Asteroids@Home
- Meine Systeme
- Alltags-PC, Test-PC (wechselnde Hardware)
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Desktopsystem
- Alltags-PC
- Mein Laptop
- HP DV7-2225sg
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X
- Mainboard
- ASRock B650M PG Riptide
- Kühlung
- Watercool Heatkiller IV Pro Copper
- Speicher
- 2x 32 GB G.Skill TridentZ 5 TGB (F5-6000J3040G32X2-TZ5RS)
- Grafikprozessor
- AMD Radeon RX 6900XT
- Display
- ASUS ROG PG42UQ (3840x2160), Philips BDM4065UC (3840x2160), Samsung C27HG70 (2560x1440)
- SSD
- Micron 9300 Pro 7,68 TB (U.2), Samsung 850 Evo 4 TB (SATA)
- HDD
- keine, SSD only...
- Optisches Laufwerk
- LG CH08LS10 Blu-ray Disc-Player
- Soundkarte
- Creative SoundBlasterX AE-5 Plus
- Gehäuse
- Dimastech BenchTable EasyXL (vorübergehend)
- Netzteil
- Corsair RM850i
- Tastatur
- ASUS ROG Strix Flare
- Maus
- Steelseries Sensei 310
- Betriebssystem
- Windows 10 Professional
- Webbrowser
- Firefox
- Schau Dir das System auf sysprofile.de an
- Internetanbindung
- ▼250 MBit ▲45 MBit
Und was soll das bringen?Dass was die Grafikkarte generiert. Nur Ausgabe über die IGP
Einen geringeren Verbrauch im Idle bzw. unter Teillast, weil in einer solchen Konstellation die diskrete GPU komplett deaktiviert werden kann.
Siehe: Sockel AM5: Hybrid Graphics ausprobiert
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Neuer Previewtreiber vom 9.11:
AMD Software: Adrenalin Edition Preview Driver
AMD Software: Adrenalin Edition Preview Driver
November 9th - What’s New?
- Improvements to driver stability during task switching.
- Improvements to resolve cases of AMD Software: Adrenalin Edition™ intermittently crashing, or failing to display metrics.
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Extra Version nur für das Spiel
AMD Software: Adrenalin Edition 23.30.13.01 for Avatar: Frontiers of Pandora (AMD)
AMD Software: Adrenalin Edition 23.30.13.01 for Avatar: Frontiers of Pandora (AMD)
DannyA4
Lieutnant
- Mitglied seit
- 09.04.2007
- Beiträge
- 96
- Renomée
- 39
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 5800X
- Mainboard
- GB X570 Elite
- Kühlung
- Custom Wasserkühlung Aquacomputer
- Speicher
- 2x 16GB 3200 Crucial @3800CL16
- Grafikprozessor
- AMD Radeon 6900XT
- Display
- 3x Dell S2721DGF Triple Monitor Setup
- SSD
- Corsair MP600, PCIe 4, 1 TB
- Gehäuse
- BeQuiet! Pure Base 500
- Netzteil
- BeQuiet! Straight Power 11 850Watt
- Tastatur
- Sharkoon Purewriter RGB
- Maus
- Zowie FK1
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Internetanbindung
- ▼50MBit
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Ja siehe auch unter Downloads
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Ähnliche Themen
- Antworten
- 1K
- Aufrufe
- 71K
- Antworten
- 227
- Aufrufe
- 24K
- Antworten
- 611
- Aufrufe
- 46K
- Antworten
- 21
- Aufrufe
- 2K