App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Was kommt (nach den ersten Deneb (K10.5+)) fuer den Desktop bis zum Launch der BD(APUs)?
- Ersteller TNT
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@Dr@:
Allereinfachste Sichtweise: Denks Dir einfach als reziproken Wert zur Pipeline Länge")
Je kürzeres FO4, desto höherer Takt (und längere Pipline) möglich/nötig.
Problem ist es jetzt das FO4 Minimum bzw. Pipeline-Maximum zw. Energieverbrauch und Rechenoutput zu finden. Der Pentium4 hatte zwar einen guten Durchsatz, aber blöderweise ein gewisses Verbrauchsproblem. Hätten sie das im Griff gehabt, wäre das Design nichtmal sooo schlecht gewesen.
Noch was Uraltes, das ich gerade noch in einem alten Post gefunden habe, K9 Spekulationen von 2003
(War vielleicht der erste Bulldozer Thread, also alle Infos bitte ab sofort da rein (Spass))
(Spass))
Die SSE2/FP Infos sind natürlich mittlerweile olle Kamellen, aber da wir gerade beim double pumped waren ... ist die Story mit dem Decoder ganz interessant.
Mit einem doppelt getakteten 4issue Decoder könnte man natürlich 2x4issue INT Pipes auch gut versorgen.
@WindHund:
L1 $I Cache = L1 Instruktion Cache. Davon gibts - wie Du richtig gesehen hast - nur einen. Laut AMD sollen es aber 2 sein, Info gabs vor ein paar Seiten.
ciao
Alex
Allereinfachste Sichtweise: Denks Dir einfach als reziproken Wert zur Pipeline Länge
Je kürzeres FO4, desto höherer Takt (und längere Pipline) möglich/nötig.
Problem ist es jetzt das FO4 Minimum bzw. Pipeline-Maximum zw. Energieverbrauch und Rechenoutput zu finden. Der Pentium4 hatte zwar einen guten Durchsatz, aber blöderweise ein gewisses Verbrauchsproblem. Hätten sie das im Griff gehabt, wäre das Design nichtmal sooo schlecht gewesen.
Noch was Uraltes, das ich gerade noch in einem alten Post gefunden habe, K9 Spekulationen von 2003
(War vielleicht der erste Bulldozer Thread, also alle Infos bitte ab sofort da rein
(Spass))http://www.planet3dnow.de/vbulletin/showthread.php?p=925104#post925104You can consider it a fake, as these distant rumours can’t be proved for now. However, if you are still interested, you might want to know of probable technological features of next-generation AMD processors - K9.
It seems, K9 will have an integrated DDRII controller
Processor will feature speculative branching (up to 8 branches), and probably some rollback cache in case a branch is predicted wrong...
Processor will probably have 3 (!) fully-fledged x87 blocks, 3 SSE2 and 2 ALU blocks. Decoders will be capable of organizing them by three (FPU + SSE2 + ALU) for maximum performance.
K9 will possibly utilize AMD’s old patent, describing integrated Peltier element packaging
Processor might have several buffers, a kind of L0 cache. For example, a 4Kb buffer will precede and follow FPU for making its operation (SSE2, 3DNow) continuous.
K9 might also support L3 cache for commented code. I.e. decoder will be capable of acting right in L3 inserting comments into special fields.
Pipeline will probably feature 15 ALU stages, 20 FPU stages.
I-cache and decoder will perform at double speed.
AMD might situate L3 cache on crystal using 1T-SRAM.
Hyper Transport II – expected to be something like Octal Data Rate (Yellowstone) with about 1GHz carrier clock. As a result throughput will reach 25Gb/s in 16x16 configuration.
Interprocessor protocol (MOESI) will be updated and improved.
The very fast bus will provide a very interesting feature of sharing free executive units between two processors. I.e. if the first has FPU loaded and the second has it free, then the latter can handle requests from the decoder of the former.
Die SSE2/FP Infos sind natürlich mittlerweile olle Kamellen, aber da wir gerade beim double pumped waren ... ist die Story mit dem Decoder ganz interessant.
Mit einem doppelt getakteten 4issue Decoder könnte man natürlich 2x4issue INT Pipes auch gut versorgen.
@WindHund:
L1 $I Cache = L1 Instruktion Cache. Davon gibts - wie Du richtig gesehen hast - nur einen. Laut AMD sollen es aber 2 sein, Info gabs vor ein paar Seiten.
ciao
Alex
Zuletzt bearbeitet:
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Der gleiche Sun Sheng hat vorher schon 64 b Adder mit 4.7 FO4-Delays in 180 nm CMOS entworfen.
Das neue Design klingt nach einer 10 FO4 Pipeline. Wenn das wirklich weniger als halb soviel wie beim K10 ist, dann können wir uns den Rest denken.Vielleicht auch ein Indiz: aktuelles BD-Sample soll etwas unter 2 GHz gehabt haben. Die Hammer-Samples liefen meist mit 800 MHz...
In dem von HenryWince verlinkten Dokument steht was von einem Minimal erreichbaren Wert von 12 bis 10. Wie passt das zusammen?

Current projections based on circuit and architectural advances show that
the minimum achievable logic depth is 10-12 FO4 inverters.
Seit dieses FO4 aufgetaucht ist blick ich hier nix mehr. Aber trotzdem DANKE für die Versuche mich zu erhellen.
MfG @
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@WindHund:
L1 $I Cache = L1 Instruktion Cache. Davon gibts - wie Du richtig gesehen hast - nur einen. Laut AMD sollen es aber 2 sein, Info gabs vor ein paar Seiten.
ciao
Alex
Öhm, gut dann war das $ Zeichen kein Tipo von dir!

OK aber dann wäre das evt. eine Erklärung:
Im Gegensatz etwa zum elektrischen Schaltbild werden jedoch nicht konkrete Verbindungen (etwa elektrische Leitungen) zwischen konkreten Bauteilen, sondern die Wirkungen zwischen den als Blöcken dargestellten Funktionseinheiten dargestellt.
Quelle
Gruß
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Noch als Legende für die Abkürzungen, für die, die es nicht kennen:
- Pipeline-Darstellungen mit SC -> RF -> EX/AG -> DC1 -> DC2 -> DC3 -> DC4 in neueren Patenten im Vergleich zum K10 mit: SC -> EX -> DC1 -> DC2
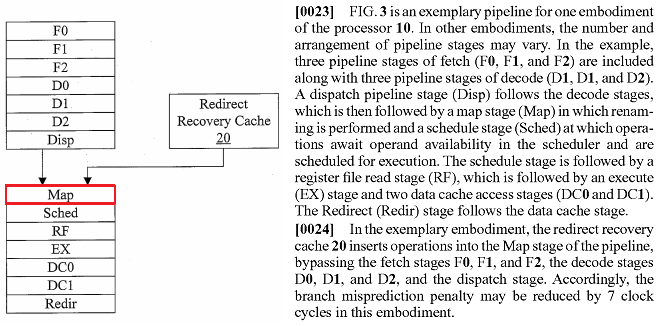
Sched = SC, nehm ich mal stark an
Frage ist jetzt, was man mit gleich 4 Cachezugriffen will ... für was wären denn die gut ?
Vielleicht worst-case Zugriffe der FPU (je 2 pro L1 Cache?),
Wenn es ein FP Patent war, wäre es vielleicht eine Erklärung.
Zu den Pipeline Stages vor cem Scheduler gibts nichts Neues, oder ?
Hmmm .. technischer Fortschritt, oder die einen reden von einer INT Pipe die anderen von einer FP Pipe, habs jetzt nicht genach nachgeprüft. Wenn beides nicht zutifft, bitte Rückmeldung, dann bin ich auch verwirrtIn dem von HenryWince verlinkten Dokument steht was von einem Minimal erreichbaren Wert von 12 bis 10. Wie passt das zusammen?
Hmm möglich, wenn man nur die Funktion schematisch darstellen will braucht man es vielleicht nicht unbedingt, aber dann würde ich wenigstens 2xL1 Cache oder so in die relevante Box schreiben.OK aber dann wäre das evt. eine Erklärung:
Ein Restzweifel bleibt bestehen, die getrennten Decoder sind ebenfalls sehr gewöhnungsbedürftig ...
ciao
Alex
Zuletzt bearbeitet:
Da geht es um die globale Taktfrequenz, nicht um die einzelner Funktionsblöcke. Wenn Du ein wenig weiter liest, haben schon die 130nm P4 mit 16,3 FO4 delays bei 3,4GHz gearbeitet. Das bedeutet, daß die Integer Fast-ALUs (die liefen ja mit 6,8GHz) mit einem FO4 delay von nur 8,15 auskamen. Für Prescott hatte Intel wohl sogar 6,25 geplant (wozu es aufgrund der Verbrauchsprobleme aber nie kam).In dem von HenryWince verlinkten Dokument steht was von einem Minimal erreichbaren Wert von 12 bis 10. Wie passt das zusammen?
mocad_tom
Admiral Special
- Mitglied seit
- 17.06.2004
- Beiträge
- 1.234
- Renomée
- 52
Zu dem Japanerbild:
Da haben wir ja nur wieder einen einzigen L1 I$ Cache... also veraltet, oder AMD hat Johan mit Falschinfos versorgt
Wieso Johan - De Gelas?
Ich habe die Infos, dass nur der L1D-Cache verdoppelt wird, der L1I (I wie Ida) aber nicht.
Hat de Gelas etwas anderes gesagt?
Grüße,
Tom
Da die µOps für Speicherzugriffe kaum auf 256bit arbeiten werden, benötigt man wohl so viele. Ein K10 wird ja bei gleichzeitigen Schreib-Lesezugriffen doch schon ausgebremst (Gesamtbandbreite beim Kopieren ist taktgemittelt auf etwa ~170 bit/Takt beschränkt, es können 256 Bit in 3 Takten kopiert werden, ein Core2/Corei7 benötigt übrigens nur 2).Frage ist jetzt, was man mit gleich 4 Cachezugriffen will ... für was wären denn die gut ?
Vielleicht worst-case Zugriffe der FPU (je 2 pro L1 Cache?)
Also im Prinzip ist bei BD eine Verdreifachung des maximalen Durchsatzes im Vergleich zum K10 bei diesem Szenario wünschenswert (2x128 Bit Lesen + 2x128Bit Schreiben pro Takt, als Sahnehäubchen vielleicht sogar noch flexibler).
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Jo, schon vor ner ganzen Zeit, musst Du verpasst haben:Wieso Johan - De Gelas?
Ich habe die Infos, dass nur der L1D-Cache verdoppelt wird, der L1I (I wie Ida) aber nicht.
Hat de Gelas etwas anderes gesagt?
http://it.anandtech.com/IT/showdoc.aspx?i=3681&p=3• Two integer clusters share fetch and decode logic but have their own dedicated Instruction and Data cache
Auf aceshardware hatte er das schon zuvor geschrieben, dass ihm das seine AMD Quellen so gesagt hätten.
Link sollte hier im Thread zu finden sein. Einfach mal die Beiträge zw. Mitte/Ende Nov. nachlesen.
@Gipsel:
Thx, das wäre auch ein Argument. Aber theoretisch könnte man sich noch denken, dass man sich die 256bit aus den beiden L1D Caches holt, die 256bit AVX Befehle laufen ja eh durch die FP Pipes.
Aber naja, da wird so oder so sicherlich viel am Design geändert worden sein.
Bei der Barcelona Präsentation hat man damals übrigens gesagt, dass man im Mittel nur immer halb soviele Stores wie loads hat. Aus dem Grund wurden nur die Loads auf 2x128bit verbreitert.
Wie sicher bist Du Dir eigentlich mit den 2 Takten für eine 256bit Kopie bei Intel ? Das würde doch bedeuten, dass Intel 256bit µOps hat, oder ?
Im realworldtech Artikel seh ich ausserdem nur je 128bit load/store:
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719&p=7
Um da also 256bit zu kopieren wären dann doch 4 Takte nötig, oder ist das Schema falsch ?
ciao
Alex
Ich würde vermuten, daß das eher Dual-128bit µOps werden. Ist im Zweifelsfall nämlich flexibler und schneller, wenn kein AVX eingesetzt wird.@Gipsel:
Thx, das wäre auch ein Argument. Aber theoretisch könnte man sich noch denken, dass man sich die 256bit aus den beiden L1D Caches holt, die 256bit AVX Befehle laufen ja eh durch die FP Pipes.
Aber naja, da wird so oder so sicherlich viel am Design geändert worden sein.
K10 kann 2 Load/Store-Operationen pro Takt durchführen, 2 x 128bit loads, 1 x 128bit load + 64bit store oder 2 x 64bit stores.Wie sicher bist Du Dir eigentlich mit den 2 Takten für eine 256bit Kopie bei Intel ? Das würde doch bedeuten, dass Intel 256bit µOps hat, oder ?
Im realworldtech Artikel seh ich ausserdem nur je 128bit load/store:
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719&p=7
Um da also 256bit zu kopieren wären dann doch 4 Takte nötig, oder ist das Schema falsch ?
Ein Core2 kann dagegen pro Takt genau einen 128bit load und einen 128bit store ausführen. Ist für einige Workloads ist das schlechter (Peak-Bandbreite fürs Lesen ist geringer), für andere allerdings besser (z.B. das Kopieren), da Lese und Schreibe-Bandbreite symmetrisch sind. Und um 256Bit zu kopieren muß man ja 256Bit Lesen und dann wieder schreiben, was (mir geht es um den Durchsatz) nunmal nur 2 Takte dauert (Takt eins 128Bit lesen + 128Bit schreiben, Takt zwei das Gleiche).
Beim K10 kannst Du Dich auf den Kopf stellen, unter 3 Takten geht es nicht, egal ob man in Takt eins 128 Bit liest und 64 Bit schreibt, das Gleiche nochmal in Takt zwei und in Takt drei 2 x 64Bit schreibt, oder in Takt ein gleich 2 x128Bit liest und dann 2 Takte zum Schreiben benötigt, ergeben sich immer 3 Takte pro 256Bit.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Bisher noch nicht. Ein 10 mm² 32 nm Kern soll aber auf der ISSCC im Februar gezeigt werden. Eigentlich kann es sich da nur um Llano handeln. Ich sehe das ähnlich wie hot. Es ist wahrscheinlicher, dass man Llano vor Bulldozer auf den Markt bringt, um damit Erfahrungen für die 32 nm Fertigung zu sammeln.Von dem hab ich bisher nichts gehört.
Wurden die öffentich gezeigt,?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Na klar, aber wenns 256bit µOps gäbe, würde das 128bit µOps ja nicht ausschließen. Eventuell spart man sich ne µOp, das wäre gut fürs Front-End.Ich würde vermuten, daß das eher Dual-128bit µOps werden. Ist im Zweifelsfall nämlich flexibler und schneller, wenn kein AVX eingesetzt wird.
Du kannst in einem Takt doch nicht die gleichen Daten lesen *und* schreiben ?K10 kann 2 Load/Store-Operationen pro Takt durchführen, 2 x 128bit loads, 1 x 128bit load + 64bit store oder 2 x 64bit stores.
Ein Core2 kann dagegen pro Takt genau einen 128bit load und einen 128bit store ausführen. Ist für einige Workloads ist das schlechter (Peak-Bandbreite fürs Lesen ist geringer), für andere allerdings besser (z.B. das Kopieren), da Lese und Schreibe-Bandbreite symmetrisch sind. Und um 256Bit zu kopieren muß man ja 256Bit Lesen und dann wieder schreiben, was (mir geht es um den Durchsatz) nunmal nur 2 Takte dauert (Takt eins 128Bit lesen + 128Bit schreiben, Takt zwei das Gleiche).
Beim K10 kannst Du Dich auf den Kopf stellen, unter 3 Takten geht es nicht, egal ob man in Takt eins 128 Bit liest und 64 Bit schreibt, das Gleiche nochmal in Takt zwei und in Takt drei 2 x 64Bit schreibt, oder in Takt ein gleich 2 x128Bit liest und dann 2 Takte zum Schreiben benötigt, ergeben sich immer 3 Takte pro 256Bit.
Wie soll das gehen, solange die Daten nicht in einem Register stehen, hast Du doch keine Register Adresse von der Du in den Speicher schreiben kannst.
Eventuell reden wir gerade aneinander vorbei, ich verstehe unter kopieren, dass Du am Ende eine exakte "Kopie" der 256bit Daten hast. Wenn es Dir nur um den L/S Durchsatz, ja- der beträgt 256bit in 2 Takten, da stimme ich gerne zu, aber für eine (echte) Kopie muss die Hälfte der Daten schon in einem Register stehen, d.h. bereits geladen sein.
Echte Kopie bei Intel:
Takt1: MOV xmm1, m128 //Load von 128bit ins xmm1 Register
Takt2: MOV xmm2, m128 //Load von 128bit ins xmm2 Register
Takt3: MOV m128, xmm1 //Store von xmm1 Register in den Speicher
Takt4: MOV m128, xmm2 //Store von xmm2 Register in den Speicher
Über die 3 Takte bei AMD gibts keine Diskussion.
Takt1: MOV xmm1, m128 //Load von 128bit ins xmm1 Register
Takt1: MOV xmm2, m128 //Load von 128bit ins xmm2 Register
Takt2: MOV m64, xmm1 //Store der ersten xmm1 Register Hälfte in den Speicher
Takt2: MOV m64, xmm2 //Store der ersten xmm2 Register Hälfte in den Speicher
Takt3: MOV m64, xmm1 //Store der zweiten xmm2 Register Hälfte in den Speicher
Takt3: MOV m64, xmm2 //Store der zweiten xmm2 Register Hälfte in den Speicher
ciao
Alex
Wenn das so ist, dann scheint eure Prognose realistischer zu sein.
Von einem 32nm-Silizium im Februar 2009 wusste ich nichts.
Ich dachte, IBM (&AMD) hatten Ende 2008 erst ein 32nm-SRAM-Test-Chip gezeigt.
Quasi, so die wichtigsten 30 Funktionen eines CPUs bzw. jene wichtigsten 30 Funktionen die bei den Veränderungen des Bulldozers dann den meisten Performance bzw. Leistungsgewinn verursachen werden.
Es ist/wäre interessant mitzulesen, aber oft kommt man bei all den Begriffen einfach nicht mit und dann hat der Text für mich einfach keine Aussagekraft mehr.
Oder man braucht sehr viel Zeit & Mühe, um in Internet Erklärungen zu diesen Begriffen zu finden, falls man überhaupt was findet.
Ich hoffe, es haben mehrere so einen Wunsch.
Dazu wird oft erklärt, wie groß eine Funktionen beim Bulldozer werden soll, aber da dann die Größe bei K10 nicht zum Vergleich herangezogen wird, kann man mit solchen Zahlen dann nichts mehr anfangen.
@Dresdenboy & Co
Wenn ich das jetzt richtig interpretiere, soll (=vermutet man jetzt) Bulldozer 2 Integerpipes (=ALU+AGU) haben, die mit doppelter Geschwindigkeit arbeiten (und somit praktisch so viel wie 4 Integer-Pipes Wert sind) und zusätzlich gibts noch 2 Load/Store Pipes mit Normaler Geschwindigkeit ??
??
Von einem 32nm-Silizium im Februar 2009 wusste ich nichts.
Ich dachte, IBM (&AMD) hatten Ende 2008 erst ein 32nm-SRAM-Test-Chip gezeigt.
Vielleicht wäre es hier Thread (oder bei manchen Usern in der Fußzeile) ein Link angebracht, wo die einzelnen Funktionen in Form eines kleines Lexikons erklärt wird.Dresdenboy schrieb:* ~10 FO4-Adder (würde mit einigem Overhead fürs Pipelining für 10 GHz bei 32nm reichen, FO4-Delay war bei 65nm ca. 15 ps)
* Pipeline-Darstellungen mit SC -> RF -> EX/AG -> DC1 -> DC2 -> DC3 -> DC4 in neueren Patenten im Vergleich zum K10 mit: SC -> EX -> DC1 -> DC2
* Sam Naffziger-Patente, wo Flip-Flops optimiert werden, damit noch ein paar Prozent mehr Zeit für die Ausführungseinheit in einer Taktphase gewonnen werden
* Datenspekulation, Cache Way Prediction...
* Patent mit Recycling AGU, welche immer nur 2 Operanden summiert statt eine 32bit-Addition und eine 3-Input-64-bit-Addition in einem Takt, wie beim Opteron
Quasi, so die wichtigsten 30 Funktionen eines CPUs bzw. jene wichtigsten 30 Funktionen die bei den Veränderungen des Bulldozers dann den meisten Performance bzw. Leistungsgewinn verursachen werden.
Es ist/wäre interessant mitzulesen, aber oft kommt man bei all den Begriffen einfach nicht mit und dann hat der Text für mich einfach keine Aussagekraft mehr.
Oder man braucht sehr viel Zeit & Mühe, um in Internet Erklärungen zu diesen Begriffen zu finden, falls man überhaupt was findet.
Ich hoffe, es haben mehrere so einen Wunsch.
Dazu wird oft erklärt, wie groß eine Funktionen beim Bulldozer werden soll, aber da dann die Größe bei K10 nicht zum Vergleich herangezogen wird, kann man mit solchen Zahlen dann nichts mehr anfangen.
@Dresdenboy & Co
Wenn ich das jetzt richtig interpretiere, soll (=vermutet man jetzt) Bulldozer 2 Integerpipes (=ALU+AGU) haben, die mit doppelter Geschwindigkeit arbeiten (und somit praktisch so viel wie 4 Integer-Pipes Wert sind) und zusätzlich gibts noch 2 Load/Store Pipes mit Normaler Geschwindigkeit
??Ich habe ja ausdrücklich vom Durchsatz gesprochenDu kannst in einem Takt doch nicht die gleichen Daten lesen *und* schreiben ?
Wie soll das gehen, solange die Daten nicht in einem Register stehen, hast Du doch keine Register Adresse von der Du in den Speicher schreiben kannst.
Eventuell reden wir gerade aneinander vorbei, ich verstehe unter kopieren, dass Du am Ende eine exakte "Kopie" der 256bit Daten hast. Wenn es Dir nur um den L/S Durchsatz, ja- der beträgt 256bit in 2 Takten, da stimme ich gerne zu, aber für eine (echte) Kopie muss die Hälfte der Daten schon in einem Register stehen, d.h. bereits geladen sein.
Echte Kopie bei Intel:
Takt1: MOV xmm1, m128 //Load von 128bit ins xmm1 Register
Takt2: MOV xmm2, m128 //Load von 128bit ins xmm2 Register
Takt3: MOV m128, xmm1 //Store von xmm1 Register in den Speicher
Takt4: MOV m128, xmm2 //Store von xmm2 Register in den Speicher
Stell Dir vor, Du schreibst einen kleinen Benchmark, der gleich einen 16kB-Block kopiert (immer schön hin und her, damit eine meßbare Zeit rauskommt). Da wird man natürlich ein paar Werte in den SSE-Registern zwischenpuffern, meinst Du nicht? So in der Art
movapd xmm1, m128[base]
movapd xmm2, m128[base+16]
movapd xmm3, m128[base+32]
movapd xmm4, m128[base+48]
movapd xmm5, m128 ...
movapd xmm6, m128
movapd xmm7, m128
movapd xmm8, m128
start:
movapd m128, xmm1
movapd xmm1, m128
movapd m128, xmm2
movapd xmm2, m128
...
movapd m128, xmm8
movapd xmm8, m128
dec counter
jnz start
movapd m128, xmm1
movapd m128, xmm2
...
movapd m128, xmm8
Und für so ein Konstrukt hat man den von mir beschriebenen Durchsatz, der eben bei Intels höher ist als bei K10. Da gibt es genügend Benchmarks, die genau das machen und das bestätigen.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Zum Japan-Artikel:
Klar, geteilte I-Caches haben wir schon gehört von Johan gehört u. die fehlenden CVT16. Aber was ich beim Lesen schonmal interessant finde, ist offenbar eine Bestätigung von 2 ALUs/2 AGUs von AMD Japan.
Aber da ist auch mind. ein Schnitzer (geht wohl nicht ohne) bzgl. der älteren Architekturen, von wegen 1 load per cycle trotz 3 AGUs. Sonst aber gute Gedanken. U.a. auch 2 ALUs/2 AGUs wegen Fläche und auch Energie.
@Gipsel:
Abinstein hat das schonmal genauer untersucht: http://abinstein.blogspot.com/search/label/K10
Er kommt auf deutlich höhere Werte, als bei verbreiteten Tests mit den Standard-Cache-Bandwidth-Benchmarks herauskommen.
Klar, geteilte I-Caches haben wir schon gehört von Johan gehört u. die fehlenden CVT16. Aber was ich beim Lesen schonmal interessant finde, ist offenbar eine Bestätigung von 2 ALUs/2 AGUs von AMD Japan.
Aber da ist auch mind. ein Schnitzer (geht wohl nicht ohne) bzgl. der älteren Architekturen, von wegen 1 load per cycle trotz 3 AGUs. Sonst aber gute Gedanken. U.a. auch 2 ALUs/2 AGUs wegen Fläche und auch Energie.
@Gipsel:
Abinstein hat das schonmal genauer untersucht: http://abinstein.blogspot.com/search/label/K10
Er kommt auf deutlich höhere Werte, als bei verbreiteten Tests mit den Standard-Cache-Bandwidth-Benchmarks herauskommen.
Der stellt ja bloß fest, daß Everest beim K10 aus irgendeinem Grund Müll mißt. Den theoretisch maximal möglichen Wert von 256 Bit/3 Takte für einen K10 gibt er aber im Prinzip auch an (bzw. weil Everest das doppelt zählt wäre das eine Kopier-Bandbreite von insgesamt 512Bit/3 Takte).@Gipsel:
Abinstein hat das schonmal genauer untersucht: http://abinstein.blogspot.com/search/label/K10
Er kommt auf deutlich höhere Werte, als bei verbreiteten Tests mit den Standard-Cache-Bandwidth-Benchmarks herauskommen.
Aber an den Zahlen da kann man sehr schön erkennen, daß ein Core2 16 Bytes pro Takt Lesen und Schreiben kann, was in einer höheren Kopierbandbreite resultiert:
Xeon 5160 3.0GHz, Read: 47860, Write: 47746, Copy: 95475 (MB/s)
3GHz * 16 Byte sind theoretisch also 48GB/s für's Lesen/Schreiben und eben (wie von Opteron angezweifelt) 96GB/s für's Kopieren. Scheint zu passen
Ein 3GHz K10 kommt (mit ordentlichem Code) maximal auf 96GB/s beim Lesen, 48GB/s beim Schreiben und eben 64GB/s beim Kopieren, also genau das Doppelte von dem, was Everest ausgibt.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
*lach*Ich habe ja ausdrücklich vom Durchsatz gesprochen
Hab ich doch glatt überlesen, sorry
Also dann ist ja eh alles klar.
Wobei sich jetzt nur noch die Frage stellt, wie praxisnah dieser "Copy" Benchmark ist. Aber naja - egal, lassen wirs.
Noch zum Everestbench:
Wenn ich mich recht erinnere, gibt das Teil nach 3-4 Läufen plötzlich einen höheren Copy Wert auf AMD CPUs aus, war mal vor ein paar Monaten aktuell. Wer mag kanns ja mal nachprüfen
Seitdem halt ich von dem Progrämmchen eh nicht mehr viel ^^
ciao
Alex
Zuletzt bearbeitet:
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Kommt ja auch drauf an wie der Bench gestrickt ist, also ob er von den 2 loads überhaupt gebrauch macht. Wennd er immer schon liest, schreibt, liest, schreibt... abwechselnd, dann bringt die zusätzlich load-bandbreite dem K10 garnichts.
Wie mans auch dreht und wendet, die Quintessenz daraus ist dass Synthetische Benches keinerlei Aussagekraft haben.
Sie gehen sowieso meistens an der Realität vorbei.
Gruß,
ich
Wie mans auch dreht und wendet, die Quintessenz daraus ist dass Synthetische Benches keinerlei Aussagekraft haben.
Sie gehen sowieso meistens an der Realität vorbei.
Gruß,
ich
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ich war mal so frei, mein Blog zu updaten
Deutet ihr eigentlich die Übersetzungen des Japan-Artikels auch so, dass AMD Japan via AMD U.S. den 2 ALU/2 AGU-Aufbau bestätigt hat? JF habe ich damit schon aufgeschreckt
Deutet ihr eigentlich die Übersetzungen des Japan-Artikels auch so, dass AMD Japan via AMD U.S. den 2 ALU/2 AGU-Aufbau bestätigt hat? JF habe ich damit schon aufgeschreckt
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ähh ne, ich deute den Absatz so, dass die Geschichte von AMD Japan nach Rückfrage bei AMD Amerika bestätigt wurde (ich glaube Du hast Dich da im Eifer des Gefechts verschrieben und meinst das GleicheDeutet ihr eigentlich die Übersetzungen des Japan-Artikels auch so, dass AMD Japan via Japan U.S. den 2 ALU/2 AGU-Aufbau bestätigt hat? JF habe ich damit schon aufgeschreckt
) Passt auch zu JFs Aussage, dass sie nur ein Sales Department in JP haben. Die kannten sich eben nicht aus und haben deshalb einfach bei jemanden in US nachgefragt, der Bescheid wusste.
Damit wären wir also wieder beim sowieso logischeren 2+2 Aufbau, gefällt mir eh besser

Wobei ich ehrlich sagen muss, dass ich dem Typen zuerst nicht glaubte, da sind viele Fehler drin, CVT16, der L1 Cache, das Datum der Konferenz, dass er mit 11.Oktober (statt November) angibt... dann das eigentümliche Design mit dem 2ten Dekoder (das kann nicht stimmen, da es unlogisch wäre 2x die gleiche Logik bei den beiden INT Kernen zu verbauen, dass *muss* der Dispatcher vor den 2 INT/ FPU Einheiten sein, und so stehts ja auch in den Dispatcher Patenten. Sieht nach mangelnden Sachverstand aus).
Allerdings sieht seine Homepage ganz gut aus:
http://www.yusuke-ohara.com/profile.htm
Anfänger ist das keiner, somit hat er wohl wirklich Connections, d.h. selbst wenn alle obigen Fehler zuträfen, kann die 2+2 Story stimmen ...
ciao
Alex
Zuletzt bearbeitet:
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Ähnliches hatten wir ja schon ganz zu Anfang spekuliert anhand dessen dass beim Bobcat-Schaubild auch "4 pipes" abgebildet waren, und dabei genau dranstand dass es 2 ALUs, eine Load und eine Store-Pipe sind.
Da wars irgendwie logisch anzunehmen dass das auch bei BD zutrifft, nur halt x2.
Sah ansosntne einfach zu ähnlich aus...nur dass sie bei BD drauf verzichteten die Funktionen der pipes direkt dranzuschreiben.
Wenn die wirklich Double Pumped sind macht das 2x2 Sinn, wenn nicht, würde es einen Rückschritt bezüglich der INT-IPC ggn. Deneb bedeuten...
Schau mer mal was denn nun definitiv rauskommt.
Vor allem bin ich auf die konkrete Auslagung gespannt. Gerade in Anbetracht solcher "Kompromisse" ist interessant wie viel Power am Ende herauskommt, bei wie viel Stromverbrauch.
Immerhin sollte BD doch angeblich bis 10W runterskalieren und von 10W-1W dann Bobcat übernehmen... und ein 10W Bulldozer liest sich irgendwie lustig
grüßchen
ich
Da wars irgendwie logisch anzunehmen dass das auch bei BD zutrifft, nur halt x2.
Sah ansosntne einfach zu ähnlich aus...nur dass sie bei BD drauf verzichteten die Funktionen der pipes direkt dranzuschreiben.
Wenn die wirklich Double Pumped sind macht das 2x2 Sinn, wenn nicht, würde es einen Rückschritt bezüglich der INT-IPC ggn. Deneb bedeuten...
Schau mer mal was denn nun definitiv rauskommt.
Vor allem bin ich auf die konkrete Auslagung gespannt. Gerade in Anbetracht solcher "Kompromisse" ist interessant wie viel Power am Ende herauskommt, bei wie viel Stromverbrauch.
Immerhin sollte BD doch angeblich bis 10W runterskalieren und von 10W-1W dann Bobcat übernehmen... und ein 10W Bulldozer liest sich irgendwie lustig
grüßchen
ich
Immerhin sollte BD doch angeblich bis 10W runterskalieren und von 10W-1W dann Bobcat übernehmen... und ein 10W Bulldozer liest sich irgendwie lustig
Falls die 45Watt-TDP bei < 2 Ghz @ 4 Modulen stimmen, dann hast du schon mit
4x10 Watt + 5 Watt-IMC jetzt schon den 10 Watt-Core.
Mit 5 Watt-IMC und 1 Modul könnte ma schon einen Neo draus machen, der jetzt auch ncoh deutlich < 2 Ghz ist.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ich habe das mal korrigiert. Möge dieser hübsche Fehler in deinem Zitat weiterlebenÄhh ne, ich deute den Absatz so, dass die Geschichte von AMD Japan nach Rückfrage bei AMD Amerika bestätigt wurde (ich glaube Du hast Dich da im Eifer des Gefechts verschrieben und meinst das Gleiche
Passt auch zu JFs Aussage, dass sie nur ein Sales Department in JP haben. Die kannten sich eben nicht aus und haben deshalb einfach bei jemanden in US nachgefragt, der Bescheid wusste.
Damit wären wir also wieder beim sowieso logischeren 2+2 Aufbau, gefällt mir eh besser
Wobei ich ehrlich sagen muss, dass ich dem Typen zuerst nicht glaubte, da sind viele Fehler drin, CVT16, der L1 Cache, das Datum der Konferenz, dass er mit 11.Oktober (statt November) angibt... dann das eigentümliche Design mit dem 2ten Dekoder (das kann nicht stimmen, da es unlogisch wäre 2x die gleiche Logik bei den beiden INT Kernen zu verbauen, dass *muss* der Dispatcher vor den 2 INT/ FPU Einheiten sein, und so stehts ja auch in den Dispatcher Patenten. Sieht nach mangelnden Sachverstand aus).
Allerdings sieht seine Homepage ganz gut aus:
http://www.yusuke-ohara.com/profile.htm
Anfänger ist das keiner, somit hat er wohl wirklich Connections, d.h. selbst wenn alle obigen Fehler zuträfen, kann die 2+2 Story stimmen ...
Es gibt übrigens in Japan noch ein Engineering Lab von AMD (oder schon nicht mehr?) - mehr auf Mobile orientiert. Das ist wohl wegen möglicher räumlicher Distanz JF bei seinen Besuchen in der Sales-Abteilung nur noch nicht vor die Füße gefallen.
Ja, die 2. Decoder finde ich auch ungewöhnlich. Auch die Pfade zu diesen 2. Decodern finde ich nicht ganz korrekt. Die 2. Scheduler (kleine, schnelle Reservation Stations?) sind mal interessant. Ich habe noch nicht die Argumente dazu nachvollziehen können. Oder sind da noch mehr Infos aus der Anfrage bei AMD eingeflossen?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wahrscheinlich hat er nur Dein Schema gesehen, aber nicht richtig verstandenJa, die 2. Decoder finde ich auch ungewöhnlich. Auch die Pfade zu diesen 2. Decodern finde ich nicht ganz korrekt. Die 2. Scheduler (kleine, schnelle Reservation Stations?) sind mal interessant. Ich habe noch nicht die Argumente dazu nachvollziehen können. Oder sind da noch mehr Infos aus der Anfrage bei AMD eingeflossen?
Im Ernst, ich seh da keinen Sinn, der einzige Reim den ich mir machen kann wäre der, dass er das Decodieren der MacroOps in µOps meint. Aber auch das passiert eigentlich nach dem Scheduler ..
So oder so ist da irgendwas falsch, ich glaube nicht an den doppelstufigen Dekoder, deine gefundenen Patente sehen da ganz anders aus, und haben bisher ja topp gepasst
ciao
Alex
P.S: Die ReOder Buffer & Reservation Stations gäbs schon im K10, möglich, dass er das mit Scheduler und 2nd Scheduler meint.
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Einen gewissen Einfluss durch Hiroshige Goto's Artikel habe ich schon pauschal vermutet. Schau ich mir das Bild hier an:Wahrscheinlich hat er nur Dein Schema gesehen, aber nicht richtig verstanden
Im Ernst, ich seh da keinen Sinn, der einzige Reim den ich mir machen kann wäre der, dass er das Decodieren der MacroOps in µOps meint. Aber auch das passiert eigentlich nach dem Scheduler ..
So oder so ist da irgendwas falsch, ich glaube nicht an den doppelstufigen Dekoder, deine gefundenen Patente sehen da ganz anders aus, und haben bisher ja topp gepasst
ciao
Alex
P.S: Die ReOder Buffer & Reservation Stations gäbs schon im K10, möglich, dass er das mit Scheduler und 2nd Scheduler meint.

(Quelle)
kann ich eine Ähnlichkeit z.B. der Datenpfade vom Dispatcher u. auch eine angedeutete 2. Decoder-Stufe (Auftrennung der MacroOps) erkennen. Dazu noch paar Infos/Ideen von hier und da und schon haben wir einen weiteren Vorschlag. Das scheint ein neues Hobby von Vielen inkl. uns zu sein: Wie stellst du dir den Bulldozer vor?
Aber aufgrund von JFs farbigem Bild mit den Pfeilen von den Int-Schedulern zum nach unten versetzten FP-Scheduler denke ich, dass es da etwas anders aussieht, als auf den japanischen Seiten suggeriert.
Nebenbei prüfe ich oft den Gedanken, ob 2x2 dennoch reichen würde, um die angedeutete Leistung auch zu erreichen. Wir sollten uns aber davon trennen, von IPC-Steigerungen zu reden, da mit z.B. 5 GHz keine nötig wäre, um ähnliche Effekte zu erreichen. Den Takt kennen wir nicht. Einiges spricht für ein mindestens teilweise höherfrequentes Design. IBM hat's doch vorgemacht. Und wenn man seine Ansprüche (Verarbeitungsbreite) etwas reduziert, sollte OoOE gut gehen. Dafür gibts ja auch genug Data Speculation. Naja, bevor ich mich in Details verfitze, schreib ich mal ein TODO: HF-BD beschreiben
Besonders einige Patente aus den Jahren 2005-2007 gehen in die Richtung. Das ist sozusagen die Vorarbeit, die Grundbausteine. Und da war Energieeffizienz auch schon lange ein Thema u. P4 lang genug bekannt.
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Wieso soll das logisch sein? Bobcat ist ein anderes Design für einen anderen Markt. Logisch ist erstmal nur, dass der weniger Rechenleistung pro Kern besitzt und daher die EUs anders dimensioniert sein können.Ähnliches hatten wir ja schon ganz zu Anfang spekuliert anhand dessen dass beim Bobcat-Schaubild auch "4 pipes" abgebildet waren, und dabei genau dranstand dass es 2 ALUs, eine Load und eine Store-Pipe sind.
Da wars irgendwie logisch anzunehmen dass das auch bei BD zutrifft, nur halt x2.
Man sollte aber bedenken, IBM geht wieder weg vom hoch taktenden In-Order Power6. Power7 ist wieder OoO, hat kürzere Pipelines und komplexere Logik. Was im Endeffekt von knapp 5 GHz in 65 nm hin zu 4 GHz in 45 nm bedeutet. Irgendwie zweifel ich daran, dass AMD hauptsächlich über den Takt gehen will. Vieles spricht bisher für signifikante IPC Verbesserungen, sowohl ILP als auch TLP. Vor allem eben die 4 Instruction Pipelines und das "mächtige" Frontend.Nebenbei prüfe ich oft den Gedanken, ob 2x2 dennoch reichen würde, um die angedeutete Leistung auch zu erreichen. Wir sollten uns aber davon trennen, von IPC-Steigerungen zu reden, da mit z.B. 5 GHz keine nötig wäre, um ähnliche Effekte zu erreichen. Den Takt kennen wir nicht. Einiges spricht für ein mindestens teilweise höherfrequentes Design. IBM hat's doch vorgemacht.
Es ist zwar ganz interessant, über die EUs zu philosophieren. Aber im Endeffekt stochern wir nur im Dunkeln, was uns nicht sonderlich weiterbringt. AMD wird genügend Simulationen gemacht haben, um die richtige Dimensionierung für einen typischen x86 Code-Mix zu finden. Diese Daten fehlen uns leider.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 929
- Antworten
- 78
- Aufrufe
- 14K
- Antworten
- 2
- Aufrufe
- 3K
- Antworten
- 763
- Aufrufe
- 100K
- Antworten
- 8
- Aufrufe
- 2K