App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Interposer Strategie - Zen, Fiji, HBM und Logic ICs
- Ersteller Complicated
- Erstellt am
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
AMD hat eine Abkehr von dem "Fusion"-Konzept angekündigt, welches zuvor mit der Einführung der ersten APUs, CPU und GPU auf einem einzigen Chip, der 2011 der Öffentlichkeit vorgestellt wurde. Dieses Konzept scheint an ein Limit gelangt zu sein, welches AMD nun seine Strategie beim grundsätzlichen Aufbau einer CPU/APU/GPU ändern lässt.
Auf der diesjährigen Investoren-Tagung wurden erste Details dazu veröffentlicht, wie Planet3D berichtet hatte - hier nochmals die relevanten Folien als Übersicht:



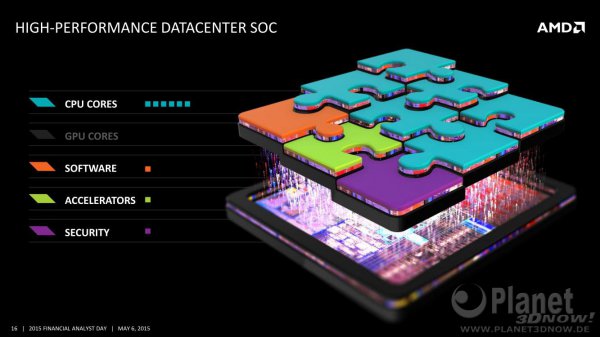
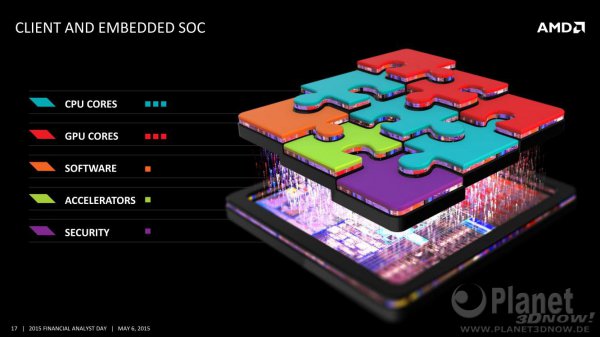

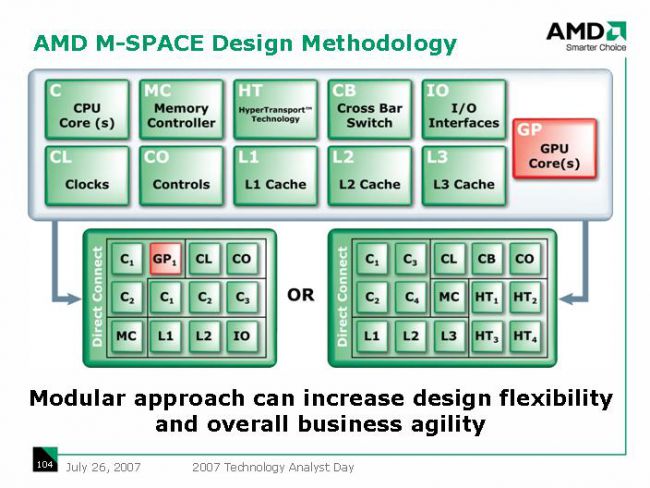
Die Fragen die ich in diesem Thread gerne diskutieren würde betreffen die einzelnen Chip-Baugruppen. Welche davon wird AMD auslagern wie z.B. die Chipsätze, welche von ASMedia entwickelt und hergestellt werden. oder wie HBM-Speicher, der bei der in Kürze erscheinenden Fiji-GPU zum Einsatz kommen wird und der erste auf einem Interposer basierenden Chip ein wird im Zuge dieser Strategie.
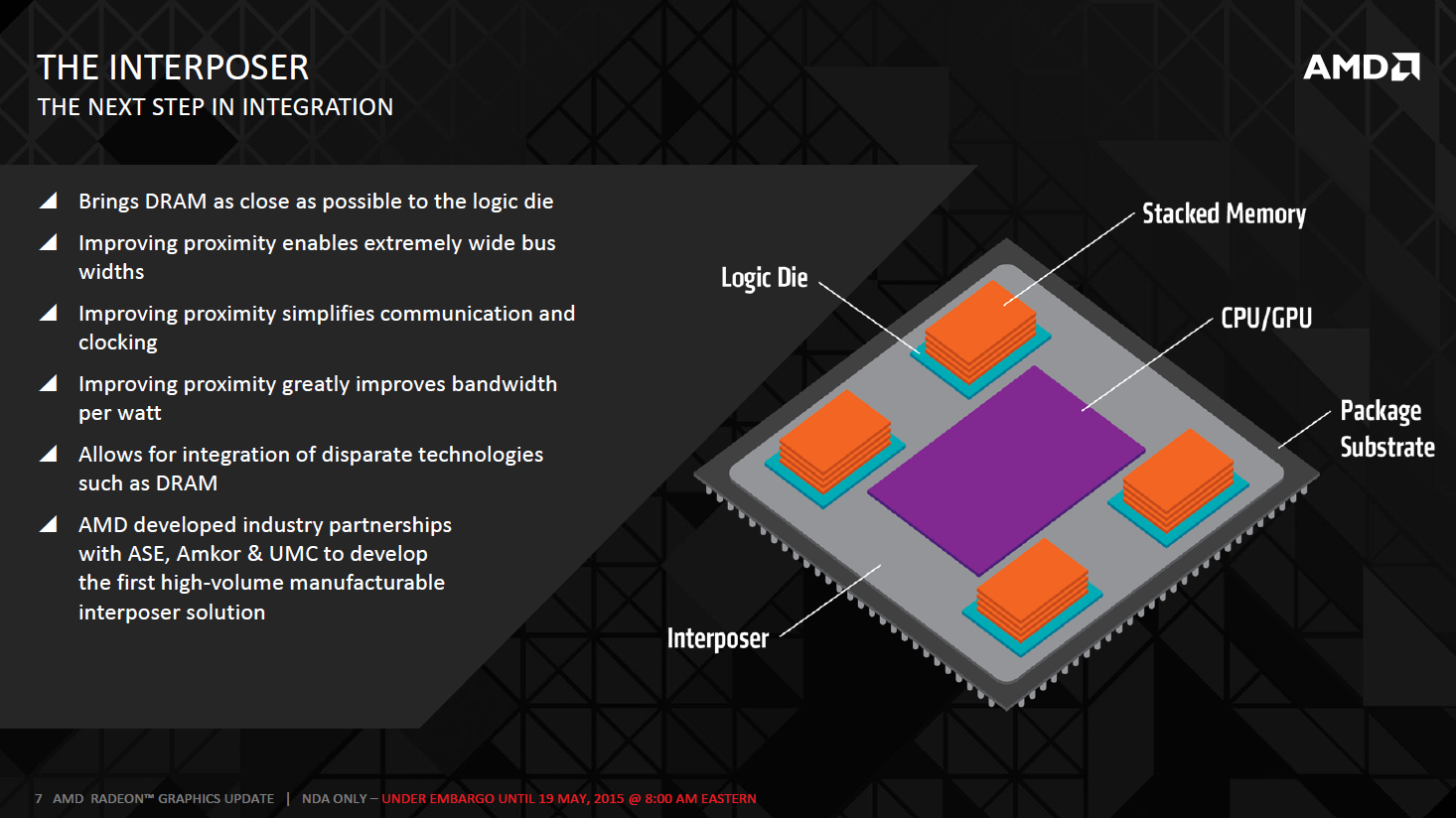
Auf dieser Folie werden die Partner der Interposer-Technologie genannt mit UMC, Amkor und ASE.
UMC ist als Foundry bekannt, doch die beiden andere sind nicht so geläufig.
Amkor ist Partner von Globalfoundries bei der Zulieferkette für 2.5 Stacking Technologie:
ASE ist der weltweit größte "assembly and test service Provider" was soviel wie ein Dienstleister rund um Zusammenbau und Tests von Halbleitern ist.
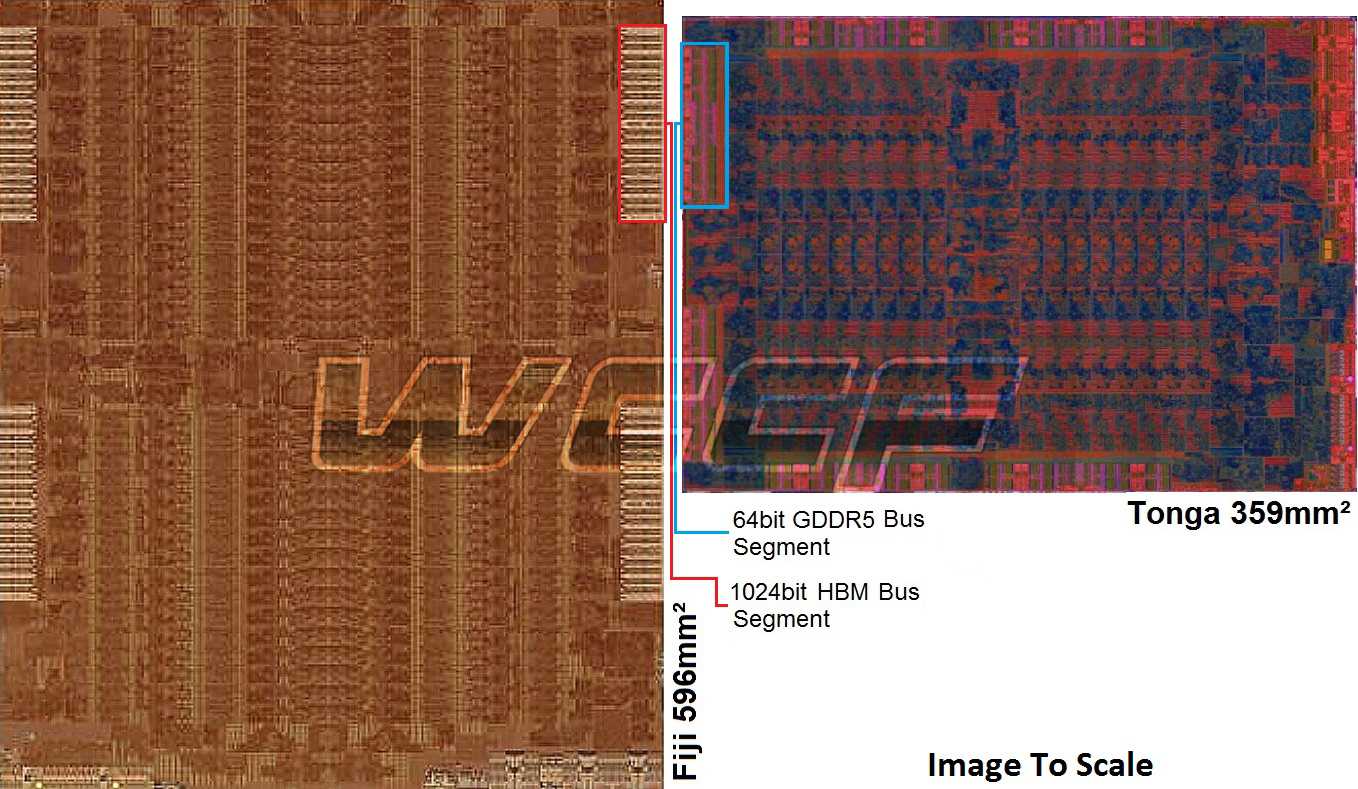
Weiterhin ist von großem Interesse wie nun AMD mit dieser Technik die Komponenten aufteilt und in welchem Fertigungsprozess diese produziert werden, bevor sie auf den Interposer kommen.
Sehr interessante und ausführliche technische Keynote zu Die-Stacking - Danke an amdfanuwe für die Quelle:
http://www.microarch.org/micro46/files/keynote1.pdf
Kosten des Interposers bei der Herstellung:
Da es passive Interposer sind, sind die Kosten überschaubar. Das ist simples Silizium von einem Wafer ohne wirklich komplizierte Strukturen:
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet pro 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Weitere Quellen:
AMD TECHNICAL REPORT: Inter-device Communication and Sharing in Emerging Memory Systems
Challenges for Power, Signal, and Reliability Verification on 3D-IC/Silicon Interposer Designs
Patent von Altera für zusammengesetzte Interposer "Stiched Interposer"
Vergleich zwischen Silikon- und Polymer-Interposer
EETimes: Vergleich 2D vs 2.5D vs 3D ICs - Grundlagen zu Stacking Technologien
Bildquellen:



A 2.5D IC/SiP using a silicon interposer
and through-silicon vias (TSVs)

A simple “True 3D IC/SiP”

A more complex “True 3D IC/SiP”
Enabling Interposer-based Disintegration of Multi-Core Processors





Auf der diesjährigen Investoren-Tagung wurden erste Details dazu veröffentlicht, wie Planet3D berichtet hatte - hier nochmals die relevanten Folien als Übersicht:
Die Fragen die ich in diesem Thread gerne diskutieren würde betreffen die einzelnen Chip-Baugruppen. Welche davon wird AMD auslagern wie z.B. die Chipsätze, welche von ASMedia entwickelt und hergestellt werden. oder wie HBM-Speicher, der bei der in Kürze erscheinenden Fiji-GPU zum Einsatz kommen wird und der erste auf einem Interposer basierenden Chip ein wird im Zuge dieser Strategie.
Auf dieser Folie werden die Partner der Interposer-Technologie genannt mit UMC, Amkor und ASE.
UMC ist als Foundry bekannt, doch die beiden andere sind nicht so geläufig.
Amkor ist Partner von Globalfoundries bei der Zulieferkette für 2.5 Stacking Technologie:
ASE ist der weltweit größte "assembly and test service Provider" was soviel wie ein Dienstleister rund um Zusammenbau und Tests von Halbleitern ist.
Weiterhin ist von großem Interesse wie nun AMD mit dieser Technik die Komponenten aufteilt und in welchem Fertigungsprozess diese produziert werden, bevor sie auf den Interposer kommen.
Sehr interessante und ausführliche technische Keynote zu Die-Stacking - Danke an amdfanuwe für die Quelle:
http://www.microarch.org/micro46/files/keynote1.pdf
Kosten des Interposers bei der Herstellung:
Da es passive Interposer sind, sind die Kosten überschaubar. Das ist simples Silizium von einem Wafer ohne wirklich komplizierte Strukturen:
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet pro 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Weitere Quellen:
AMD TECHNICAL REPORT: Inter-device Communication and Sharing in Emerging Memory Systems
Challenges for Power, Signal, and Reliability Verification on 3D-IC/Silicon Interposer Designs
Patent von Altera für zusammengesetzte Interposer "Stiched Interposer"
Vergleich zwischen Silikon- und Polymer-Interposer
EETimes: Vergleich 2D vs 2.5D vs 3D ICs - Grundlagen zu Stacking Technologien
Bildquellen:
A 2.5D IC/SiP using a silicon interposer
and through-silicon vias (TSVs)
A simple “True 3D IC/SiP”
A more complex “True 3D IC/SiP”
Enabling Interposer-based Disintegration of Multi-Core Processors
Anhänge

Zuletzt bearbeitet:
Alter Sack
Lt. Commander
- Mitglied seit
- 10.03.2013
- Beiträge
- 143
- Renomée
- 0
- Standort
- Dennheritz
- Details zu meinem Desktop
- Prozessor
- A10-6700
- Mainboard
- Asrock FM A88X Extreme6+
- Kühlung
- Scythe Ninja II
- Speicher
- 8 GB DDR 3 1600 MHz
- Grafikprozessor
- APU
- Display
- 20" Samsung 1680x1050
- SSD
- Samssung Evo 840 256 GB
- HDD
- 1x 2 TB
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- Onboard
- Netzteil
- Be Quiet 400W, 80+ Gold
- Betriebssystem
- Win7 x 64, SP1
- Webbrowser
- Opera, Firefox
- Verschiedenes
- Mein Allround-PC, den ich bei Bedarf , durch eine HD7870 aufwerte.
Bei jeweils einem Die für CPU, GPU und NB/SB-Funktionen, könnte man ein komplettes GPU-Die aus einer jeweils aktuellen Serie unterbringen.
@Fertigung z.B.: CPU/14nm, GPU/28nm und NB/SB in irgendwas zwischen 55 und 28nm? Wäre praktisch und flexibel.
@Fertigung z.B.: CPU/14nm, GPU/28nm und NB/SB in irgendwas zwischen 55 und 28nm? Wäre praktisch und flexibel.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Du solltest noch diese AMD Präsentation von 12-2013 hinzufügen:
http://www.microarch.org/micro46/files/keynote1.pdf
Seite 48 finde ich interessant.
http://www.microarch.org/micro46/files/keynote1.pdf
Seite 48 finde ich interessant.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Bedenkt man, wie lange schon am Stapeln von Silizium getüftelt wird, denke ich nicht, dass die Abkehr vom Fusion-Konzept Resultat einer erst neulichen Erkenntnis war.
Weitere Gründe absets des Fertigungsvorsprungs der Konkurrenz werden ja in der von amdfanuwe zitierten Präsentation ab S. 36 recht schön benannt:
Konsequenterweise müssten auch die APUs mit dem gemeinsamen Speicherkontroller wieder aufbrechen, so dass CPU und GPU im jeweils besten geeigneten Prozess hergestellt werden. Der Speicherkontroller müsste dann Hauptbestandteil des (aktiven) Interposers werden.
Weitere Gründe absets des Fertigungsvorsprungs der Konkurrenz werden ja in der von amdfanuwe zitierten Präsentation ab S. 36 recht schön benannt:
• All similar technology components have been integrated such as Cache, FPU, MultiMedia, NB, GPU, SB, etc...
• Only disparate technologies such as DRAM, MEMS, True IVR, Storage, Optics are left
• Process scaling will to stop supporting diverse functionalities on a single die such as fast logic, low power logic, analog, and cache
• The single die will want to break into specialized components to maximize the value of new and existing process nodes
• Process complexity is increasing and yield is dropping as mask count increases
• Large die sizes will continue to have yield challenges
• Die partitioning is challenging and there is significant microarchitecture research
Konsequenterweise müssten auch die APUs mit dem gemeinsamen Speicherkontroller wieder aufbrechen, so dass CPU und GPU im jeweils besten geeigneten Prozess hergestellt werden. Der Speicherkontroller müsste dann Hauptbestandteil des (aktiven) Interposers werden.
AMD hat eine Abkehr von dem "Fusion"-Konzept angekündigt, welches zuvor mit der Einführung der ersten APUs, CPU und GPU auf einem einzigen Chip, der 2011 der Öffentlichkeit vorgestellt wurde. Dieses Konzept scheint an ein Limit gelangt zu sein, welches AMD nun seine Strategie beim grundsätzlichen Aufbau einer CPU/APU/GPU ändern lässt.....
Irgendwie eine komische Einleitung... Was hat Fusion mit dem Aufbau einer CPU/APU oder gar Interposern zu tun!?
Ich denke mal nicht, dass sich irgendetwas ausschliesst... oder !?
TNT
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Diesen Artikel von Charlie Demerjian find ich auch noch interessant.:
https://semiaccurate.com/2015/05/19/amd-finally-talks-hbm-memory/
Bisher waren die Verbindungen der Komponenten untereinander durch die "geringe" Pinanzahl, ca. 1000 Pins / CPU, beschränkt.
Es sind nur eine begrenzte Anzahl an PCI-e, RAM Leitungen, etc. möglich, die über das Board geleitet werden müssen. Zudem sind für jeden Pin stromfressende Leitungstreiber nötig.
Durch die Microbumps und den Interposer sind wesentlich mehr Leitungen möglich, mit denen die Chips auf dem Interposer kommunizieren können (Faktor 100). Daurch ließen sich die Interconnects zwischen den Chips nicht nur durch 8 oder 16 sondern durch 128, 256 oder noch mehr Leitungen ausführen. Z.B. könnte ein GPU Chip mit der CPU nicht nur über "16 PCI-e 3.0" Leitungen angebunden sein sondern über den Interposer eben mit 256 Leitungen.
https://semiaccurate.com/2015/05/19/amd-finally-talks-hbm-memory/
Bisher waren die Verbindungen der Komponenten untereinander durch die "geringe" Pinanzahl, ca. 1000 Pins / CPU, beschränkt.
Es sind nur eine begrenzte Anzahl an PCI-e, RAM Leitungen, etc. möglich, die über das Board geleitet werden müssen. Zudem sind für jeden Pin stromfressende Leitungstreiber nötig.
Durch die Microbumps und den Interposer sind wesentlich mehr Leitungen möglich, mit denen die Chips auf dem Interposer kommunizieren können (Faktor 100). Daurch ließen sich die Interconnects zwischen den Chips nicht nur durch 8 oder 16 sondern durch 128, 256 oder noch mehr Leitungen ausführen. Z.B. könnte ein GPU Chip mit der CPU nicht nur über "16 PCI-e 3.0" Leitungen angebunden sein sondern über den Interposer eben mit 256 Leitungen.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Du solltest noch diese AMD Präsentation von 12-2013 hinzufügen:
http://www.microarch.org/micro46/files/keynote1.pdf
Seite 48 finde ich interessant.
Diesen Artikel von Charlie Demerjian find ich auch noch interessant.:
https://semiaccurate.com/2015/05/19/amd-finally-talks-hbm-memory/
Danke für die Links. Die Keynote ist sehr detailiert. Charlies Artikel finde ich oft interessant, doch leider auch zu reisserisch und nicht immer nur auf Fakten basierend. Daher verwende ich SemiAc nicht als primäre Quelle, solange es nicht anderweitig bestätigt wurde.
")
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Stacked DDR4 RAM ist auch schon angekündigt von Samsung:
http://community.cadence.com/cadenc...igh-bandwidth-memory-hmb-will-transform-drams
http://community.cadence.com/cadenc...igh-bandwidth-memory-hmb-will-transform-drams
In August 2014, as Tabrizi noted, Samsung announced that it has started mass production of the industry’s first 64GB, DDR4 RDIMMs that use 3D TSV packaging technology. The new RDIMMs include 36 DDR4 DRAM chips, each of which consists of four 4Gb DDR4 DRAM dies. According to Samsung, the new 64GB TSV module performs twice as fast as a 64GB module that uses wire bonding, while consuming half the power.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Joe Marci, CTO von AMD und früherer JEDEC-Vorstand lässt ein paar Details zu den verwendeten Interconnects zwischen HBM und GPU/CPU/APU in einem Interview zu HBM raus:
http://techreport.com/review/28294/amd-high-bandwidth-memory-explained
http://techreport.com/review/28294/amd-high-bandwidth-memory-explained
Diese Anbindungen sind nach wie vor traditionell auf dem Package.The interposer is what makes HBM's closer integration between DRAM and the GPU possible. A traditional organic chip package sits below the interposer, as it does with most any GPU, but that package only has to transfer data for PCI Express, display outputs, and some low-frequency interfaces. All high-speed communication between the GPU and memory happens across the interposer instead. Because the interposer is a silicon chip, it's much denser, with many more connections and traces in a given area than an off-chip package.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Naja, wie ich im anderen Thread schon geschrieben habe: Es wäre wirklich super wenn AMD das schaffen würde, dass sie nur noch kleine Module herstellen, und alles, nach belieben kombiniert, auf einem Interposer zusammen backen könnten. Bei den APUs sollte das deutlich weniger Ausschuss (in Prozent pro Wafer) bedeuten. Und man könnte die Module besser selektieren und kombinieren, für stromsparende oder hochleistungsfähige CPUs. Und man könnte z.B. einfach ein gutes CPU-Modul mit einem guten GPU-Modul kombinieren, für eine High-End-APU (wo man vorher vielleicht eine schlechte Ausbeute hatte). Selbst unterschiedliche, angepasste/angemessene, Fertigungsprozesse für GPU, CPU und Zusatzmodule wie Chipsatz etc. wären denkbar. Alles in Allem ein großer Gewinn - bis auf die zusätzlichen Kosten für Interposer und das zusammen backen.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Da es passive Interposer sind, sind die Kosten überschaubar. Das ist simples Silizium von einem Wafer ohne wirklich komplizierte Strukturen:
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet por 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Selbst wenn AMD 10$ pro CPU/APU/GPU für den Interposer benötigt, so spart alleine die Reduzierung des Dies bei z.B. Fiji um 40mm² deutlich mehr ein. Zudem noch ein halb so grosses PCB, keine RAMs mehr die verbunden werden sollen, weniger Stromlanes, wenige Layers. Da kommt deutlich mehr zusammen als die 10$.
Und nicht zu vergessen, dass der Umsatz für den verwendeten RAM ab sofort durch AMDs Bücher geht - alleine dadurch sollte eine Umsatzsteigerung möglich werden.
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet por 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Selbst wenn AMD 10$ pro CPU/APU/GPU für den Interposer benötigt, so spart alleine die Reduzierung des Dies bei z.B. Fiji um 40mm² deutlich mehr ein. Zudem noch ein halb so grosses PCB, keine RAMs mehr die verbunden werden sollen, weniger Stromlanes, wenige Layers. Da kommt deutlich mehr zusammen als die 10$.
Und nicht zu vergessen, dass der Umsatz für den verwendeten RAM ab sofort durch AMDs Bücher geht - alleine dadurch sollte eine Umsatzsteigerung möglich werden.
Zuletzt bearbeitet:
Die Mehrkosten durch den interposer dürften sich aber durch die höhere yield relativieren. (Vermutung)
Möglich wahre auch dass man die selbe DIE\Maske für die kleinen dGPUs und APUs nutzt.
Oder wie im diesjährigen Aprilscherz auf die Spitze treibt. Ganz unrealistisch find ich den nicht.
Möglich wahre auch dass man die selbe DIE\Maske für die kleinen dGPUs und APUs nutzt.
Oder wie im diesjährigen Aprilscherz auf die Spitze treibt. Ganz unrealistisch find ich den nicht.
LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Das ist simplesSilikonSilizium von einem Wafer ohne wirklich komplizierte Strukturen:
Allerdings wäre es mit Silikon auch ganz witzig
")
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 3.057
- Renomée
- 288
Ein hier häufig angebrachter Kritikpunkt war es doch auch, dass die Designs von CPU und GPU sich nicht gut miteinander kombinieren lassen. Das Design der CPU wird z.B. auf höheren Takt ausgelegt als das der GPU. Die APU wies dann fertigungstechnische Probleme auf, die man Globalfoundries in die Schuhe schob.
Das Problem sollte mit dem Interposer der Vergangenheit angehören.
MfG
PS: Was ist eigentlich Silikon?
Ok, LoRDxRaVeN, warst schneller.
Das Problem sollte mit dem Interposer der Vergangenheit angehören.
MfG
PS: Was ist eigentlich Silikon?
Ok, LoRDxRaVeN, warst schneller.
G
Gast11062015
Guest
Amd hätte die Zeit bis zur neuen Gen. bei den Apu´s auch besser überbrücken können.
z.b. mit GDDR5, das Interface ist auf den Kaveri ja da![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]")
Oder wenigstens die Komprimierung die die 285 beherrscht dann wäre DDR3 noch nicht soooo .........
z.b. mit GDDR5, das Interface ist auf den Kaveri ja da
Oder wenigstens die Komprimierung die die 285 beherrscht dann wäre DDR3 noch nicht soooo .........
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Allerdings wäre es mit Silikon auch ganz witzig
Ja danke habs geändert

Die Amis mit ihren Elementen
Markus Everson
Grand Admiral Special
Ihr überseht m.E. das die Defect-Rate bei Interposer/TSV überproportional steigt. Das macht man weil man muss (zum Beispiel wegen der Anzahl der Kontakte), aber nicht weil es so toll flexibel ist. ct hat das seinerzeit mal analysiert, als Intel beim Pentium II den Cache aufs MCM brachte weil er nicht mit brauchbarer Yield in ein Die integrierbar war.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ihr überseht m.E. das die Defect-Rate bei Interposer/TSV überproportional steigt. Das macht man weil man muss (zum Beispiel wegen der Anzahl der Kontakte), aber nicht weil es so toll flexibel ist. ct hat das seinerzeit mal analysiert, als Intel beim Pentium II den Cache aufs MCM brachte weil er nicht mit brauchbarer Yield in ein Die integrierbar war.
Meinst Du nicht, dass sich in den letzten 18 Jahren vielleicht etwas verbessert haben könnte, bei der Technik?
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 3.057
- Renomée
- 288
Die Herstellung des Interposers in einem ausgereiften, gröberen Prozess sollte jedenfalls kein Problem darstellen. Sind die TSVs schwierig miteinander zu verbinden, oder gibt es Alterserscheinungen? Was genau meinst Du mit der Defect-Rate bei Interposer/TSV?
MfG
MfG
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Hier eine Abhandlung von AMD zu den kommenden Speicherarchitekturen und deren Anbindung:
http://www.amd.com/Documents/AMD-Research-Report-2014-1776.pdf
http://www.amd.com/Documents/AMD-Research-Report-2014-1776.pdf
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.134
- Renomée
- 993
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 5700X3D (100-100001503)
- Mainboard
- ASUS ProArt B550-Creator
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB (11324-01-20G)
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- Western Digital SN850X (WDS400T2XHE)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64) Xfce
- Verschiedenes
- ASUS TPM-SPI (Nuvoton NPCT750A)
Intel ist nicht geizig mit Masken, aber manchmal greifen sie dennoch auf Multi-Chip-Packages zurück. Nehmen wir Westmere mit der iGPU auf einem separaten Chip oder Broadwell mit dem PCH auf einem separaten Chip. Natürlich ist dies eine "Notlösung", aber eine gangbare, falls sonst die Kosten für eine Maske durch zu geringe Stückzahlen nicht wieder eingespielt würden. Mit jedem Shrink steigen die Kosten für eine Maske schließlich exponentiell an. Außerdem bekommt Intel so noch ältere Fabs ausgelastet. Insofern begibt sich AMD hier in gute Gesellschaft. Ein Interposer ist zwar ein belichteter Halbleiter und demnach nicht mit einem herkömmlichen Package vergleichbar, aber da er lediglich Leiterbahnen enthält, übernimmt er (teilweise) dieselbe Aufgabe. Allerdings sehe ich persönlich bei HBM und gegebenfalls noch FCH das Ende der Fahnenstange erreicht. Weiter ausdehnen sollte man die Interposertechnik nicht. Verglichen mit herkömmlichen Packages ist sie nämlich doch ziemlich teuer. Verwundern sollte dies jedoch niemand, denn man muss die Interposer in Rein(st)räumen belichten und braucht dafür sehr aufwendige Anlagen sowie bei jedem Durchlauf hektoliterweise kostspielige Chemikalien.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Du hast dazu eine belastbare Quelle? Denn wir haben hier schon eine die für den Interposer Kosten in Höhe von 500-650$ pro 200mm Wafer benennt.Verglichen mit herkömmlichen Packages ist sie nämlich doch ziemlich teuer. Verwundern sollte dies jedoch niemand, denn man muss die Interposer in Rein(st)räumen belichten und braucht dafür sehr aufwendige Anlagen sowie bei jedem Durchlauf hektoliterweise kostspielige Chemikalien.
100mm² kommen auf ca. 1$
Da es passive Interposer sind, sind die Kosten überschaubar. Das ist simples Silizium von einem Wafer ohne wirklich komplizierte Strukturen:
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet por 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Da es passive Interposer sind, sind die Kosten überschaubar. Das ist simples Silizium von einem Wafer ohne wirklich komplizierte Strukturen:
http://electroiq.com/blog/2012/12/lifting-the-veil-on-silicon-interposer-pricing/
Der Interposer kostet por 100mm² 1$
Der gesamte Wafer kostet gerade mal 500-650$
Selbst wenn AMD 10$ pro CPU/APU/GPU für den Interposer benötigt, so spart alleine die Reduzierung des Dies bei z.B. Fiji um 40mm² deutlich mehr ein. Zudem noch ein halb so grosses PCB, keine RAMs mehr die verbunden werden sollen, weniger Stromlanes, wenige Layers. Da kommt deutlich mehr zusammen als die 10$.
Und nicht zu vergessen, dass der Umsatz für den verwendeten RAM ab sofort durch AMDs Bücher geht - alleine dadurch sollte eine Umsatzsteigerung möglich werden.
Wenn der Interposer quasi nix kostet dann könnte die neue HBM Grafikkarte ja auch mit mehr als 4 RAM-Stacks bestückt werden?
Houston2603
Gesperrt
- Mitglied seit
- 21.11.2010
- Beiträge
- 123
- Renomée
- 1
Könnte man. Ist unsinnig. Das zusammenbasteln ist das teure.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich bin mir nicht sicher inwiefern das in Abhängigkeit stehen sollte? Was meinst du?
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 748
- Antworten
- 0
- Aufrufe
- 724
- Antworten
- 879
- Aufrufe
- 70K
- Antworten
- 1
- Aufrufe
- 2K