App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Spekulationsthread: Was kommt 2011+
- Ersteller Ge0rgy
- Erstellt am
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Würde mich nicht stören, würde meiner Meinung nach sogar eher gut passen.Was aber, wenn der Takt, mit dem wir "sehen" doppelt so schnell ist? Dann beträgt die Latenz 4 Takte...
Bisher hab ich mich gewundert, wieso AMD nem halb so großen und nur halb so assoziativen L1 Cache die gleiche Latenz wie Intel verpasst.
Das sind ja 32kB 8fach <> 16kB 4fach. Klar, allgemein höherer Takt, aber trotzdem sind 4 Takte für so nen "primitiven" Cache ne Menge Holz.
Wenn der jetzt mit doppelten Takt laufen würde, würde es das erklären, und ich würde mich nicht beschweren ^^
ciao
Alex
P.S: Hab den Fragen Teil nochmal überarbeitet, falls Dus nicht gesehen haben solltest (Edit3).
Eventuell ist Frage c) Antwort auf Frage a);
 , könnte ja Auswirkung der Modulbauweise sein .. aber mal schauen was die Experten auf comp.arch sagen
, könnte ja Auswirkung der Modulbauweise sein .. aber mal schauen was die Experten auf comp.arch sagen ")
Abaxus
Cadet
zu c)
Ich hab zwar im Prinzip keine Ahnung wovon ihr da eigentlich genau redet aber vllt kann ich ja helfen
http://blogs.amd.com/work/2010/10/25/the-new-flex-fp/
I
Auszug:
Each Flex FP has its own scheduler; it does not rely on the integer scheduler to schedule FP commands, nor does it take integer resources to schedule 256-bit executions. This helps to ensure that the FP unit stays full as floating point commands occur. Our competitors’ architectures have had single scheduler for both integer and floating point, which means that both integer and floating point commands are issued by a single shared scheduler vs. having dedicated schedulers for both integer and floating point executions.
Ich hab zwar im Prinzip keine Ahnung wovon ihr da eigentlich genau redet aber vllt kann ich ja helfen
http://blogs.amd.com/work/2010/10/25/the-new-flex-fp/
I
Auszug:
Each Flex FP has its own scheduler; it does not rely on the integer scheduler to schedule FP commands, nor does it take integer resources to schedule 256-bit executions. This helps to ensure that the FP unit stays full as floating point commands occur. Our competitors’ architectures have had single scheduler for both integer and floating point, which means that both integer and floating point commands are issued by a single shared scheduler vs. having dedicated schedulers for both integer and floating point executions.
Dresdenboy
Redaktion
☆☆☆☆☆☆
@Opteron:
Schedule könnte in einer µArchitektur abgeschaltet werden, wo das Scheduling bereits erfolgt ist (im EC). Scheduling legt ja nur die Reihenfolge der Ausführung fest. Bei einer Schleife kann die durchaus gleich sein, sofern alle Daten bereitliegen. Aber das muss nicht zwangsweise immer so sein.
Ohne EC hätten wir immer noch versch. Takte für Back End u. Front End und evtl. den "accelerated mode" der GCC-Mailinglist (eine andere Erklärung als deine). Der Taktfaktor für das Back End kann statt 2 auch 1,5 betragen. Dann hätten wir 3 ALU u. 3 AGU ops pro externem Takt. Entsprechend 4+4 bei Faktor 2.
So wäre dann auch das 4-way Retirement sinnvoll, wo die 2 ALUs+2 AGUs nur selten mehr als 2 Macro Ops pro Takt schaffen können. Laut Doc sind die ALU-Befehle, die auch in den AGUs ausgeführt werden können, etwa die wie beim K8.
Verschiedene Takte erscheinen sinnvoll, da das Aufteilen von Pipelinestufen mit Energieeffizienzverlusten einhergeht (zusätzliche Latches, evtl. recht große Zwischenergebnisse).
Und wie schnell Decode getaktet ist, bleibt auch spannend. Wenn die Predecode-Bits mit Befehlsanfang-/-ende-Markern vorliegen, ist Decoding ein paralleler Prozess.
@Abaxus:
Danke für das Posten des Links. Habs gestern abend noch gesehen. Es gibt da nichts, was jetzt zu unserer Diskussion passt. Aber John (oder seine Helfer) erwähnt z.B. einen höheren AES-Durchsatz als bei der Konkurrenz.
Schedule könnte in einer µArchitektur abgeschaltet werden, wo das Scheduling bereits erfolgt ist (im EC). Scheduling legt ja nur die Reihenfolge der Ausführung fest. Bei einer Schleife kann die durchaus gleich sein, sofern alle Daten bereitliegen. Aber das muss nicht zwangsweise immer so sein.
Ohne EC hätten wir immer noch versch. Takte für Back End u. Front End und evtl. den "accelerated mode" der GCC-Mailinglist (eine andere Erklärung als deine). Der Taktfaktor für das Back End kann statt 2 auch 1,5 betragen. Dann hätten wir 3 ALU u. 3 AGU ops pro externem Takt. Entsprechend 4+4 bei Faktor 2.
So wäre dann auch das 4-way Retirement sinnvoll, wo die 2 ALUs+2 AGUs nur selten mehr als 2 Macro Ops pro Takt schaffen können. Laut Doc sind die ALU-Befehle, die auch in den AGUs ausgeführt werden können, etwa die wie beim K8.
Verschiedene Takte erscheinen sinnvoll, da das Aufteilen von Pipelinestufen mit Energieeffizienzverlusten einhergeht (zusätzliche Latches, evtl. recht große Zwischenergebnisse).
Und wie schnell Decode getaktet ist, bleibt auch spannend. Wenn die Predecode-Bits mit Befehlsanfang-/-ende-Markern vorliegen, ist Decoding ein paralleler Prozess.
@Abaxus:
Danke für das Posten des Links. Habs gestern abend noch gesehen. Es gibt da nichts, was jetzt zu unserer Diskussion passt. Aber John (oder seine Helfer) erwähnt z.B. einen höheren AES-Durchsatz als bei der Konkurrenz.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
JF schreibt ja, dass eine FMAC Einheit ein FADD oder ein FMUL pro Takt verarbeiten kann. Ist es nicht möglich, mittels FMAC Rechenwerk ein FADD und ein FMUL pro Takt zu verarbeiten? Ansonsten sehe ich da keinen Vorteil für Bulldozer bei SSE Code, obwohl das JF immer wieder betont hatte.
Bulldozer, 8 Module mit je 2 128-bit FMACs
8x 128-bit FADD oder FMUL
8x 128-bit FADD oder FMUL
Sandy Bridge, 8 SMT Kerne
8x 128-bit FADD
8x 128-bit FMUL
Dh, beide CPUs kommen auf einen theoretischen Durchsatz von 64 (8*4+8*4) FLOPs pro Takt.
Mit AVX sieht es ebenso aus.
Bulldozer, 8 Module mit je 2 128-bit FMACs
8x 128-bit FMAC (ADD+MUL)
8x 128-bit FMAC (ADD+MUL)
Sandy Bridge, 8 SMT Kerne
8x 256-bit FADD
8x 256-bit FMUL
Ergibt ebenfalls einen theoretischen Durchsatz von 64 (8*2*2+8*2*2 bzw 8*4+8*4) FLOPs pro Takt.
Das einzige, wo Bulldozer einen Vorteil bei SSE hätte, ist die Flexibilität pro Takt. Eben Flex FP.
Bulldozer
1. FADD+FMUL
2. FADD+FADD
3. FMUL+FMUL
Sandy Bridge
1. FADD+FMUL
2. FADD
3. FMUL
Im besten Fall hätte AMD doppelt so viel Durchsatz, im schlimmsten Fall genauso viel. Bulldozer sollte also höhere Peaks erreichen. Kann man hier grob abschätzen, wie viel das ausmacht?
Auf der anderen Seite sehe ich einen Nachteil für Bulldozer bei AVX. Nur wenn explizit FMA Instruktionen verwendet werden, liegt man auf Sandy Bridge Niveau. Werden hingegen FADD und FMUL Instruktionen verwendet, hat Sandy Bridge theoretisch doppelt so viel Durchsatz. Wird Intel nun Benchmarks dahingehend optimieren? Oder kann Bulldozer separate FADD und FMUL AVX Instruktionen als FMA AVX Instruktion ausführen?
Bulldozer, 8 Module mit je 2 128-bit FMACs
8x 128-bit FADD oder FMUL
8x 128-bit FADD oder FMUL
Sandy Bridge, 8 SMT Kerne
8x 128-bit FADD
8x 128-bit FMUL
Dh, beide CPUs kommen auf einen theoretischen Durchsatz von 64 (8*4+8*4) FLOPs pro Takt.
Mit AVX sieht es ebenso aus.
Bulldozer, 8 Module mit je 2 128-bit FMACs
8x 128-bit FMAC (ADD+MUL)
8x 128-bit FMAC (ADD+MUL)
Sandy Bridge, 8 SMT Kerne
8x 256-bit FADD
8x 256-bit FMUL
Ergibt ebenfalls einen theoretischen Durchsatz von 64 (8*2*2+8*2*2 bzw 8*4+8*4) FLOPs pro Takt.
Das einzige, wo Bulldozer einen Vorteil bei SSE hätte, ist die Flexibilität pro Takt. Eben Flex FP.
Bulldozer
1. FADD+FMUL
2. FADD+FADD
3. FMUL+FMUL
Sandy Bridge
1. FADD+FMUL
2. FADD
3. FMUL
Im besten Fall hätte AMD doppelt so viel Durchsatz, im schlimmsten Fall genauso viel. Bulldozer sollte also höhere Peaks erreichen. Kann man hier grob abschätzen, wie viel das ausmacht?
Auf der anderen Seite sehe ich einen Nachteil für Bulldozer bei AVX. Nur wenn explizit FMA Instruktionen verwendet werden, liegt man auf Sandy Bridge Niveau. Werden hingegen FADD und FMUL Instruktionen verwendet, hat Sandy Bridge theoretisch doppelt so viel Durchsatz. Wird Intel nun Benchmarks dahingehend optimieren? Oder kann Bulldozer separate FADD und FMUL AVX Instruktionen als FMA AVX Instruktion ausführen?
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
...Im besten Fall hätte AMD doppelt so viel Durchsatz, im schlimmsten Fall genauso viel. Bulldozer sollte also höhere Peaks erreichen. Kann man hier grob abschätzen, wie viel das ausmacht?
Auf der anderen Seite sehe ich einen Nachteil für Bulldozer bei AVX. Nur wenn explizit FMA Instruktionen verwendet werden, liegt man auf Sandy Bridge Niveau...
All Eure Betrachtungen dürften gleichen Takt unterstellen, also IPC. Die große Unbekannte ist hier aber dann die mögliche Taktfrequenz für BD. Es wurde ja schon von einigen Seiten von einem "Speeddemon" gesprochen. Wenn BD mit Takten um die 5Ghz, ähnlich IBMs Power, kommen sollten, würde der Vergleich zu SB plötzlich gaaanz anders aussehen. Aber über den Takt wird AMD sicherlich noch lange schweigen. Womöglich wird man ansonsten langsam alle Infos successive raus lassen, aber den möglichen Takt möglichst bis zum letzten Tag verborgen halten.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Natürlich war der FP Vergleich erstmal nur pro Takt. Mehr macht hier ja noch keinen Sinn. Und JF hat schon mal gesagt, dass die Taktraten nicht extrem steigen und man keine 5 GHz erwarten darf. Das Thema "Speeddemon" sollte man daher ad acta legen. Scheinbar wurde auch für höhere Taktraten optimiert, eine komplett andere Philosophie wie zB bei Netburst sollte man aber nicht erwarten.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Die Taktfrequenzen heben sie sich natürlich auf, weil diese sehr entscheidend sind.
"5GHz? Only if the chips were powered by magic unicorns. Expect higher clock speeds on those processors than you see today, but not 5GHz."
http://www.amdzone.com/phpbb3/viewtopic.php?f=52&t=137432&start=125#p178665
Wenn du etwas weiter oben liest, findest du unsere Diskussion bzgl. unterschiedlicher Taktdomänen in einem Modul. Ein hoher Takt für ein ganzes Modul ist gar nicht zwingend. Das Konzept könnte auch funktionieren, wenn die Module im Interlagos mit 2GHz laufen und die Execution Units mit 4GHz.
Und "Speeddemon" sollte man erstmal definieren (so wie auf AMDZone). Ad acta können wir dann die nicht eingetroffenen Spekulationen legen, wenn schließlich Alles bekanntgegeben wurde.
Schauen wir den ehemaligen Speeddemon (von diversen Power CPUs ganz zu schweigen) mal an: lange Pipeline, 2 double clocked ALUs mit entspr. schnellen Issue Ports (Basistakt für den Rest).
Taktfrequenzbereich für Willamette in 180nm: 1,3 - 2,0 GHz (http://de.wikipedia.org/wiki/Intel_Pentium_4)
Vergleich: AMD Palomino in 180nm: 1,33 - 1,73 GHz (http://de.wikipedia.org/wiki/AMD_Athlon_XP)
Demnach ca. 16% Vorsprung für den ersten Speeddemon in 180nm und 1,75V bei beiden. Northwood schafft es dann aber doch noch, in 130nm die Schere auf 46% aufzuweiten (3,4 vs. 2,33 GHz Barton). Später schrumpft sie wieder aufgrund der Power Wall, 90nm Probleme auf 19% (3,8 GHz Prescott vs. 3,2 GHz 90nm A64 - http://de.wikipedia.org/wiki/AMD_Athlon_64).
Die Anmerkungen von Mitch Alsup u. den Bulldozer Hot Chips Folien deuten in die Richtung von ca. 20-25% Taktanstieg (wenn sonst alles gleich wäre).
.
EDIT :
.
NEWS ALERT
Sorry für den Alarm, aber die BD1 Pipeline Description ist in den GCC MLs aufgetaucht:
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01883.html
John sagte nicht, dass sie nicht extrem steigen, sondern dass sie höher sein werden, aber eben keine 5 GHz:Natürlich war der FP Vergleich erstmal nur pro Takt. Mehr macht hier ja noch keinen Sinn. Und JF hat schon mal gesagt, dass die Taktraten nicht extrem steigen und man keine 5 GHz erwarten darf. Das Thema "Speeddemon" sollte man daher ad acta legen. Scheinbar wurde auch für höhere Taktraten optimiert, eine komplett andere Philosophie wie zB bei Netburst sollte man aber nicht erwarten.
"5GHz? Only if the chips were powered by magic unicorns. Expect higher clock speeds on those processors than you see today, but not 5GHz."
http://www.amdzone.com/phpbb3/viewtopic.php?f=52&t=137432&start=125#p178665
Wenn du etwas weiter oben liest, findest du unsere Diskussion bzgl. unterschiedlicher Taktdomänen in einem Modul. Ein hoher Takt für ein ganzes Modul ist gar nicht zwingend. Das Konzept könnte auch funktionieren, wenn die Module im Interlagos mit 2GHz laufen und die Execution Units mit 4GHz.
Und "Speeddemon" sollte man erstmal definieren (so wie auf AMDZone). Ad acta können wir dann die nicht eingetroffenen Spekulationen legen, wenn schließlich Alles bekanntgegeben wurde.
Schauen wir den ehemaligen Speeddemon (von diversen Power CPUs ganz zu schweigen) mal an: lange Pipeline, 2 double clocked ALUs mit entspr. schnellen Issue Ports (Basistakt für den Rest).
Taktfrequenzbereich für Willamette in 180nm: 1,3 - 2,0 GHz (http://de.wikipedia.org/wiki/Intel_Pentium_4)
Vergleich: AMD Palomino in 180nm: 1,33 - 1,73 GHz (http://de.wikipedia.org/wiki/AMD_Athlon_XP)
Demnach ca. 16% Vorsprung für den ersten Speeddemon in 180nm und 1,75V bei beiden. Northwood schafft es dann aber doch noch, in 130nm die Schere auf 46% aufzuweiten (3,4 vs. 2,33 GHz Barton). Später schrumpft sie wieder aufgrund der Power Wall, 90nm Probleme auf 19% (3,8 GHz Prescott vs. 3,2 GHz 90nm A64 - http://de.wikipedia.org/wiki/AMD_Athlon_64).
Die Anmerkungen von Mitch Alsup u. den Bulldozer Hot Chips Folien deuten in die Richtung von ca. 20-25% Taktanstieg (wenn sonst alles gleich wäre).
.
EDIT :
.
NEWS ALERT
Sorry für den Alarm, aber die BD1 Pipeline Description ist in den GCC MLs aufgetaucht:
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01883.html
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Habs mir mal nochmal angeschaut.@Opteron:
Schedule könnte in einer µArchitektur abgeschaltet werden, wo das Scheduling bereits erfolgt ist (im EC). Scheduling legt ja nur die Reihenfolge der Ausführung fest. Bei einer Schleife kann die durchaus gleich sein, sofern alle Daten bereitliegen. Aber das muss nicht zwangsweise immer so sein.
Der springende Punkt ist, ob das Schedulung eben schon erfolgt ist, oder nicht.
Der Unterschied ist der, dass das Rename bei der MIPS Architektur schon sehr früh in der Pipeline passiert, gleich nach dem Decode, vor dem Dispatch (siehe Fig.6 im letzten Post). Das passiert bei BD aber erst im Scheduler. Von daher würde dass dann Sinn machen, dass man den nicht abschaltet, wäre halt "einfach" ein Unterschied.
Die Frage ändert sich dann aber dann, ob die Map Stufe *vor* dem eigentlichen OoO dann überhaupt Sinn macht. Das wäre dann funktional was ganz anderes als im Flywheel Patent. Eventuell wirklich einfach Register Renaming in der Map Stage und OoO dann komplett später.
Nachteil wäre dann, dass in ner Schleife, die in Program Order aus dem EC kommt, jedesmal die gleichen OoO Steps ausgeführt werden müßten. Wäre ja schon praktisch wenn die bereits in. OoO Form im EC liegen würden.
Könnte aber sein, dass aufgrund des Physk. Register Files, da kein nennenswerter Nachteil entsteht, nachdem da eh keine großen Datenmengen mehr verschoben werden.
MIPS hatte ja noch die kassischen Reigster Files mit ROBs etc. pp.
Was auch noch sein könnte, wäre eine erste OoO Stufe im Front-End wie bei MIPS. Wer weiss ... ist ja eh die Frage, wie das ganze mit der Modulbauweise funktioniert ...
Trace Cache jetzt per Core, oder per Modul, und falls per Core, was passiert mit den FPU Instruktionen

Würde eigentlich Sinn machen, das Ganze 1x im Front-End zu haben. Quasi dort erstes OoO, und dann die Hauptsache mit den Updates später in den Cores. Das würde dann auch zum RWT Artikel passen, der von Renaming innerhalb der Cluster spricht. Das kann ja stimmen, nur weiss er eventuell noch nichts von nem Pre-Renaming
")
Problem bei der 1x Trace Cache pro Module Sache ist dann nur, dass man verhindern muss, dass sich die 2 Threads da gegenseitig die Traces trashen. Sollte aber auch zu lösen sein.
Was man da noch machen könnte, ist den Orochi DIE Shot von vor ~10 Seiten genauer anzuschauen. Hab mich da beim Front-End nicht weiter damit aufgehalten, was die "großen" Blöcke da sein könnten/müßten. Wenn man da ne Liste mit BTB, TLB etc. macht und die dann mit den sichtbaren (großen) Blöcken verrechnet, und einer über bleibt, müßte das dann der Trace Cache sein.
Aber naja - Photosop ...
 Eventuell nur Zeitverschwendung.
Eventuell nur Zeitverschwendung.Den EC erachte ich in Form des RRCs eigentlich als gesetzt. Immerhin ist der im Patent mit dabei, und bisher war alles aus den Patenten korrekt.Ohne EC hätten wir immer noch versch. Takte für Back End u. Front End und evtl. den "accelerated mode" der GCC-Mailinglist (eine andere Erklärung als deine). Der Taktfaktor für das Back End kann statt 2 auch 1,5 betragen. Dann hätten wir 3 ALU u. 3 AGU ops pro externem Takt. Entsprechend 4+4 bei Faktor 2.
Fraglich ist jetzt nur die Funktionalität, hat er schon die Trace Möglichkeiten, oder nicht. Eventuell kommt das Flywheel Zeugs erst in BD2, und der Accelerated Mode bezieht sich nur auf das Issue Fenster.
HMm, das Retirement ist doch auch inkl. FPU, oder nicht ? Von dort kommen dann ja auch 2 MOps. Das passt schon so, ist optimal 4 xRetire pro Takt für 2xINT und 2xFP MOps.So wäre dann auch das 4-way Retirement sinnvoll, wo die 2 ALUs+2 AGUs nur selten mehr als 2 Macro Ops pro Takt schaffen können. Laut Doc sind die ALU-Befehle, die auch in den AGUs ausgeführt werden können, etwa die wie beim K8.
Jo würde Sinn machen, eventuell hat AMD die hoch- und runtertakt Logik eingespart und vergibt einfach feste Taktraten. Wäre für BD1, eigentlich erstmal die quick and dirty Lösung. Alle Neuerungen gleich ins erste Design zu packen ging sicherlich schief, erst mal lieber kleine Brötchen packenVerschiedene Takte erscheinen sinnvoll, da das Aufteilen von Pipelinestufen mit Energieeffizienzverlusten einhergeht (zusätzliche Latches, evtl. recht große Zwischenergebnisse).
Wenn die Decoder aus den Pateten stimmen - was bisher ja immer der Fall war - brauchts da keine großen Takt, da die Decoder sehr, sehr breit sind. Nur das Issue Window könnte eben doppelt laufenUnd wie schnell Decode getaktet ist, bleibt auch spannend. Wenn die Predecode-Bits mit Befehlsanfang-/-ende-Markern vorliegen, ist Decoding ein paralleler Prozess.
Da hat mich damals ja schon gestört, dass der Decoder aus vier 2er Simple/Compl. Blöcken bestand. Jeder Block kann parallel arbeiten, solange die comp. und die simple Instr. unabhängig waren. Aaaber, es ging nur je 1 Leitung aus dem 2er Block raus, also 4x Durchsatz nicht 8fach. Mit doppelten Takt, bzw. DDR Verfahren wäre das jetzt kein Problem
")
Ich hatte es gesehen, wollte es aber nicht posten, da a) nix Neues drin steht, und b) eine Formulierung unglück ist, die führt jetzt hier auch prompt zu Fragen, ich habs mir gedacht ^^@Abaxus:
Danke für das Posten des Links. Habs gestern abend noch gesehen. Es gibt da nichts, was jetzt zu unserer Diskussion passt. Aber John (oder seine Helfer) erwähnt z.B. einen höheren AES-Durchsatz als bei der Konkurrenz.
Genau die Frage meinte ichJF schreibt ja, dass eine FMAC Einheit ein FADD oder ein FMUL pro Takt verarbeiten kann. Ist es nicht möglich, mittels FMAC Rechenwerk ein FADD und ein FMUL pro Takt zu verarbeiten? Ansonsten sehe ich da keinen Vorteil für Bulldozer bei SSE Code, obwohl das JF immer wieder betont hatte.
Natürlich kann die FMAC Einheit auch noch einen FMAC Befehl abarbeiten
Das hat er früher auch geschrieben, aber in dem Absatz dann unterschlagen, wieso auch immer ..Was aber wohl nicht geht ist ein FMAC Fusion, da hatten wir ja mal die Diskussion mit der Genauigkeit. Nen dicken Vorteil von FMAC hat man da dann nur, wenn man neu compiliert, aber das ist mit AVX nicht anders. Ansonsten beschränkt es sich bei altem Code halt auf den maximalen Durchsatz von 2xADD oder 2xMUL, wo bisher nur starr 1xADD/1xMUL möglich war.
Das wäre das oben erwähnte FMAC Fusion, glaub ich erstmal nicht, aber sicher ist nichts.Oder kann Bulldozer separate FADD und FMUL AVX Instruktionen als FMA AVX Instruktion ausführen?
JF redet nur von seinen Stromspar Server CPUs, das sind teilweise ja auch noch MCMsUnd JF hat schon mal gesagt, dass die Taktraten nicht extrem steigen und man keine 5 GHz erwarten darf. Das Thema "Speeddemon" sollte man daher ad acta legen. Scheinbar wurde auch für höhere Taktraten optimiert, eine komplett andere Philosophie wie zB bei Netburst sollte man aber nicht erwarten.
Warts mal ab, was die Übertakter aus nem AM3+ Zambezi herausholen werden
Naja anfangs mit Sockel 423 in 180nm war das eher ne Prototypenstudie die man "ausversehen" dann auch noch verkaufteNetburst hatte anfangs keine hohe Taktraten, die Taktraten wurden immer mit Abstand erhöht, genauso wie Bareclona 65nm & Shanghai 45nm

ciao
Alex
.
EDIT :
.
Mach das mal größer
NEWS ALERT
EDIT :
.
NEWS ALERT
Sorry für den Alarm, aber die BD1 Pipeline Description ist in den GCC MLs aufgetaucht:
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01883.html
Muss aber jetzt wg, schaus mir später an
Zuletzt bearbeitet:
Dr@
Grand Admiral Special
- Mitglied seit
- 19.05.2009
- Beiträge
- 12.791
- Renomée
- 4.066
- Standort
- Baden-Württemberg
- Aktuelle Projekte
- Collatz Conjecture
- Meine Systeme
- Zacate E-350 APU
- BOINC-Statistiken

- Mein Laptop
- FSC Lifebook S2110, HP Pavilion dm3-1010eg
- Details zu meinem Laptop
- Prozessor
- Turion 64 MT37, Neo X2 L335, E-350
- Mainboard
- E35M1-I DELUXE
- Speicher
- 2x1 GiB DDR-333, 2x2 GiB DDR2-800, 2x2 GiB DDR3-1333
- Grafikprozessor
- RADEON XPRESS 200m, HD 3200, HD 4330, HD 6310
- Display
- 13,3", 13,3" , Dell UltraSharp U2311H
- HDD
- 100 GB, 320 GB, 120 GB +500 GB
- Optisches Laufwerk
- DVD-Brenner
- Betriebssystem
- WinXP SP3, Vista SP2, Win7 SP1 64-bit
- Webbrowser
- Firefox 13
Damit wir uns richtig verstehen:
Jede FMAC Pipe kann nur:
1 FMAC oder
1 FMUL oder
1 FADD
Sie können FMUL und FADD nicht gleichzeitig (außer halt mit nem FMAC-Befehl)!
Wurde im Briefing zur Hot Chips so gesagt.
Jede FMAC Pipe kann nur:
1 FMAC oder
1 FMUL oder
1 FADD
Sie können FMUL und FADD nicht gleichzeitig (außer halt mit nem FMAC-Befehl)!
Wurde im Briefing zur Hot Chips so gesagt.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
So wieder da ... und naja ...Muss aber jetzt wg, schaus mir später an
Also von ner Pipeline seh ich da nicht viel, das ist eher nur der Aufbau analog zum RWT Artikel.
Das was mich enttäuscht:
Was ist das denn ? Das ist 1:1 K10 Niveau. Es stand ja schon mal irgendwo, dass die Decoder nicht groß ausgelastet wären, aber trotzdem wunder ich mich, dass das jetzt für 2 Threads reichen soll ... als einzige Verbesserung bliebe da dann nur CMP Fusion übrig. Wobei die aber in dem File nicht genannt wird ... strange, eventuell ein Zeichen, dass sie sich an den RWT Info Artikel halten.Three DirectPath instructions decoders and only one VectorPath decoder is available. They can decode three DirectPath instructions or one VectorPath instruction per cycle.
Da hoffe ich mal dass sich zukünftig noch was tut:
Prinzipiell haben sie genau das veröffentlich, was im RWT Artikel steht, kein Deut mehr. Schlimmstenfalls hat der Programmierer sogar nur den Artikel als Quelle gehabt und nicht mehr ?> The implementation is based on the current available information and may subject to change in the future.
Lol, si claro, aber wenn ne FMAC Instr. kommt, dann kann die FMAC Unit eben doch FMUL und FADD gleichzeitig ... tricky ^^Damit wir uns richtig verstehen:
Jede FMAC Pipe kann nur:
1 FMAC oder
1 FMUL oder
1 FADD
Sie können FMUL und FADD nicht gleichzeitig!
Da ist es am Besten, wenn man den µOp begriff dazu nimmt.
Was halt nicht geht ist 2 eigenständige FMUL/FADD µOps in einer FMAC Unit parallel zu verarbeiten.
ciao
Alex
.
EDIT :
.
Hmm, der/die TypeIN hätte aber wohl NDA Zugriff, ist ja ne @amd.com mail adresse ...
Und Anfang Oktober wurde schon das BDVer1 Cost File gepacht, entspricht den AMD Compiler Infos, aber ist recht einfach, in der PatchInfo die Unterschiede zw. K10 und BD zu sehen, z.B: sind die Register <> Register Kopien jetzt nur 2 Takte anstatt 4. Ausserdem stark gestiegene Latenzen für DIV und SQRT, und natürlich die üblichen Cachegrößen ^^ :
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01866.html@@ -821,14 +821,14 @@ struct processor_costs amdfam10_cost = { struct processor_costs bdver1_cost = {
COSTS_N_INSNS (1), /* cost of an add instruction */
- COSTS_N_INSNS (2), /* cost of a lea instruction */
+ COSTS_N_INSNS (1), /* cost of a lea instruction */
COSTS_N_INSNS (1), /* variable shift costs */
COSTS_N_INSNS (1), /* constant shift costs */
- {COSTS_N_INSNS (3), /* cost of starting multiply for QI */
+ {COSTS_N_INSNS (4), /* cost of starting multiply for QI */
COSTS_N_INSNS (4), /* HI */
- COSTS_N_INSNS (3), /* SI */
- COSTS_N_INSNS (4), /* DI */
- COSTS_N_INSNS (5)}, /* other */
+ COSTS_N_INSNS (4), /* SI */
+ COSTS_N_INSNS (6), /* DI */
+ COSTS_N_INSNS (6)}, /* other */
0, /* cost of multiply per each bit set */
{COSTS_N_INSNS (19), /* cost of a divide/mod for QI */
COSTS_N_INSNS (35), /* HI */
@@ -840,26 +840,26 @@ struct processor_costs bdver1_cost = {
8, /* "large" insn */
9, /* MOVE_RATIO */
4, /* cost for loading QImode using movzbl */
- {3, 4, 3}, /* cost of loading integer registers
+ {5, 5, 4}, /* cost of loading integer registers
in QImode, HImode and SImode.
Relative to reg-reg move (2). */
- {3, 4, 3}, /* cost of storing integer registers */
- 4, /* cost of reg,reg fld/fst */
- {4, 4, 12}, /* cost of loading fp registers
+ {4, 4, 4}, /* cost of storing integer registers */
+ 2, /* cost of reg,reg fld/fst */
+ {5, 5, 12}, /* cost of loading fp registers
in SFmode, DFmode and XFmode */
- {6, 6, 8}, /* cost of storing fp registers
+ {4, 4, 8}, /* cost of storing fp registers
in SFmode, DFmode and XFmode */
2, /* cost of moving MMX register */
- {3, 3}, /* cost of loading MMX registers
+ {4, 4}, /* cost of loading MMX registers
in SImode and DImode */
{4, 4}, /* cost of storing MMX registers
in SImode and DImode */
2, /* cost of moving SSE register */
- {4, 4, 3}, /* cost of loading SSE registers
+ {4, 4, 4}, /* cost of loading SSE registers
in SImode, DImode and TImode */
- {4, 4, 5}, /* cost of storing SSE registers
+ {4, 4, 4}, /* cost of storing SSE registers
in SImode, DImode and TImode */
- 3, /* MMX or SSE register to integer */
+ 2, /* MMX or SSE register to integer */
/* On K8:
MOVD reg64, xmmreg Double FSTORE 4
MOVD reg32, xmmreg Double FSTORE 4
@@ -868,8 +868,8 @@ struct processor_costs bdver1_cost = {
1/1 1/1
MOVD reg32, xmmreg Double FADD 3
1/1 1/1 */
- 64, /* size of l1 cache. */
- 1024, /* size of l2 cache. */
+ 16, /* size of l1 cache. */
+ 2048, /* size of l2 cache. */
64, /* size of prefetch block */
/* New AMD processors never drop prefetches; if they cannot be performed
immediately, they are queued. We set number of simultaneous prefetches
@@ -878,12 +878,12 @@ struct processor_costs bdver1_cost = {
time). */
100, /* number of parallel prefetches */
2, /* Branch cost */
- COSTS_N_INSNS (4), /* cost of FADD and FSUB insns. */
- COSTS_N_INSNS (4), /* cost of FMUL instruction. */
- COSTS_N_INSNS (19), /* cost of FDIV instruction. */
+ COSTS_N_INSNS (6), /* cost of FADD and FSUB insns. */
+ COSTS_N_INSNS (6), /* cost of FMUL instruction. */
+ COSTS_N_INSNS (42), /* cost of FDIV instruction. */
COSTS_N_INSNS (2), /* cost of FABS instruction. */
COSTS_N_INSNS (2), /* cost of FCHS instruction. */
- COSTS_N_INSNS (35), /* cost of FSQRT instruction. */
+ COSTS_N_INSNS (52), /* cost of FSQRT instruction. */
/* BDVER1 has optimized REP instruction for medium sized blocks, but for
very small blocks it is better to use loop. For large blocks, libcall
@@ -893,15 +893,15 @@ struct processor_costs bdver1_cost = {
{{libcall, {{8, loop}, {24, unrolled_loop},
{2048, rep_prefix_4_byte}, {-1, libcall}}},
{libcall, {{48, unrolled_loop}, {8192, rep_prefix_8_byte}, {-1, libcall}}}},
- 4, /* scalar_stmt_cost. */
- 2, /* scalar load_cost. */
- 2, /* scalar_store_cost. */
+ 6, /* scalar_stmt_cost. */
+ 4, /* scalar load_cost. */
+ 4, /* scalar_store_cost. */
6, /* vec_stmt_cost. */
0, /* vec_to_scalar_cost. */
2, /* scalar_to_vec_cost. */
- 2, /* vec_align_load_cost. */
- 2, /* vec_unalign_load_cost. */
- 2, /* vec_store_cost. */
+ 4, /* vec_align_load_cost. */
+ 4, /* vec_unalign_load_cost. */
+ 4, /* vec_store_cost. */
2, /* cond_taken_branch_cost. */
1, /* cond_not_taken_branch_cost. */
};
Falls sich jemand über:
wundern sollte:QImode, HImode and SImode.
http://www.delorie.com/gnu/docs/gcc/gccint_53.html
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Danke für den Hinweis auf das Cost-File. Die Zahlen passen. Da auch schön zu sehen: FDIV-Latenz etwas mehr als verdoppelt. Und das, obwohl mit den FMACs ein DIV-Algo mit weniger Operationen umsetzbar ist (Goldschmidt, siehe Bobcat-FPU-Paper). Natürlich ziehen die 6-Takt-Latenzen das etwas in die Länge. Aber insgesamt hätte man dank FMAC vllt. (müsste ich nachsehen) sogar mit kaum mehr Zyklen herauskommen können. Das kann man gern auch als Hinweis auf die Taktfrequenzen nehmen.
Die Decoderzahl ist nur noch nicht aktualisiert (da sind selbst gewisse PDFs noch nicht überall sauber). Die Latenzen im aktuellen GCC-Posting stimmen aber und sind bestimmt nicht aus dem RWT-Artikel Die Branch Misprediction Penalty ist übrigens *hust* Ach, ich wollte mir doch noch einen Cappu machen...
Die Decoderzahl ist nur noch nicht aktualisiert (da sind selbst gewisse PDFs noch nicht überall sauber). Die Latenzen im aktuellen GCC-Posting stimmen aber und sind bestimmt nicht aus dem RWT-Artikel
Die Branch Misprediction Penalty ist übrigens *hust* Ach, ich wollte mir doch noch einen Cappu machen... gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Läuft das nicht auf das gleiche hinaus? Man sollte vor allem auch beachten, WIE er sagt, dass es keine 5 GHz seien.John sagte nicht, dass sie nicht extrem steigen, sondern dass sie höher sein werden, aber eben keine 5 GHz
"Speeddemon" ist für mich ein Design, was ausschliesslich auf hohen Takt ausgelegt ist. Dass das Bulldozer nicht wird, sollte mittlerweile aber klar sein. Höherer Takt ja, aber eben nicht ausschliesslich.Und "Speeddemon" sollte man erstmal definieren (so wie auf AMDZone). Ad acta können wir dann die nicht eingetroffenen Spekulationen legen, wenn schließlich Alles bekanntgegeben wurde.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Gut, dann bin ich mal beruhigtDie Decoderzahl ist nur noch nicht aktualisiert (da sind selbst gewisse PDFs noch nicht überall sauber).
Jo, aber sind sie neu ? Gabs doch schon damals im Januar in der AMD Compiler Source, oder kamen jetzt Neue dazu bzw. waren die damals falsch (wie z.B. die 5 Takte ) ?Die Latenzen im aktuellen GCC-Posting stimmen aber und sind bestimmt nicht aus dem RWT-Artikel
Du bist gemeinDie Branch Misprediction Penalty ist übrigens *hust* Ach, ich wollte mir doch noch einen Cappu machen...
Naja ... der P4 war max. zwar auch "nur" ein 4 GHz Prozessor, aber die ALU lief doppelt ... da ist wieder mal schön viel Interpretationsspielraum.Läuft das nicht auf das gleiche hinaus? Man sollte vor allem auch beachten, WIE er sagt, dass es keine 5 GHz seien.
Hmm, naja nennen wirs halt dann größtenteils Speeddemon, oder 80% SpeedD, oder wie auch immer ^^"Speeddemon" ist für mich ein Design, was ausschliesslich auf hohen Takt ausgelegt ist. Dass das Bulldozer nicht wird, sollte mittlerweile aber klar sein. Höherer Takt ja, aber eben nicht ausschliesslich.
Hier ist übrigens ne Definition von nem Alpha Designer:
http://www.mdronline.com/editorial/edit13_17.htmlThe Speed Demon philosophy is best summed up by an Alpha designer who said that a processor's cycle time should be the minimum required to cycle an ALU and pass the result to the next instruction. The processor can implement any amount of complexity so long as it doesn't compromise this primary goal of ultimate speed.
Aber der Übergang ist halt fließend, zum Williamette schreiben sie in dem Artikel:
Wenn Speed Demon immer 100% Speed wäre, bräuchten sie kein "pure" ... bleibt so oder so schwammig.and the forthcoming Willamette appears to be a pure Speed Demon design
Dass das ganze nicht so schwarz/weiss ist, sieht man ja am anderen Ende. Was gibts denn sonst noch außer Speed Demons ? Da wären Brainiacs.
Wenn man jetzt sagt, BD wäre kein Speed Demon, macht das BD dann zum Brainiac ? Natürlich nicht ... wie besagt, die Übergänge sind fließend.
Auf ner Skala von 0 (Brainiac) bis 10 (Speed Demon), würde ich BD mal Pi*Daumen auf 8 setzen.
Spannende Frage wäre jetzt das Verhältnis zu Sandy. Ich denke jeder wird zustimmen, dass das weniger sein sollte, aber wieviel genau ... 7,6,5 ? Schwer zu quantifizieren.
Solange die ExUnits doppelt laufen, reichts mir \(^^)/Höherer Takt ja, aber eben nicht ausschliesslich.
ciao
Alex
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Du meinst die Einhörner? Ja, das kann man so deuten wie "deutlich unter 5 GHz". Alles Interpretationssache. Er darf ja eh nix sagen.Läuft das nicht auf das gleiche hinaus? Man sollte vor allem auch beachten, WIE er sagt, dass es keine 5 GHz seien.
Und ich hatte selbst ja schon für Interlagos einen groben Schätzwert von 2,8 GHz errechnet. Für nen DT 8-Core wäre das natürlich mehr.
Falls da doch verschieden schnell getaktete Bereiche im BD sein sollten, triffst du das mit "nicht ausschliesslich" ganz gut"Speeddemon" ist für mich ein Design, was ausschliesslich auf hohen Takt ausgelegt ist. Dass das Bulldozer nicht wird, sollte mittlerweile aber klar sein. Höherer Takt ja, aber eben nicht ausschliesslich.
.
EDIT :
.
Ein paar Zahlen im Januar-Source passen nicht ganz, andere waren noch kopiert (auch da z.B. IDIV/FPDIV/SQRT).Gut, dann bin ich mal beruhigt
Jo, aber sind sie neu ? Gabs doch schon damals im Januar in der AMD Compiler Source, oder kamen jetzt Neue dazu bzw. waren die damals falsch (wie z.B. die 5 Takte ) ?
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Ich biete 30%. Bietet jemand weniger?Hmm, naja nennen wirs halt dann größtenteils Speeddemon, oder 80% SpeedD, oder wie auch immer
edit:
Schade, am Analyst Day scheint laut JF wohl nicht viel neues zu kommen.
Don't expect a hot chips-level disclosure. This is financial analysts, so it will be much more of a business discussion.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
@Dresdenboy:
Hmm, noch zum accelerated mode ... da fiel mir gerade noch ein, dass es doch da ne passende Stelle im RWT Artikel gab. Hatte ich damals schon mal erwähnt:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4282702#post4282702
Nochmals die Zusammenfassung, Quelle im GCC:
Das muss es doch fast sein ... entweder 1 Fenster pro Takt, oder accelerated halt 2 Fenster pro Takt, falls die Instruktionen in beiden Fenstern den gewünschten Mix haben.
Hmm, noch zum accelerated mode ... da fiel mir gerade noch ein, dass es doch da ne passende Stelle im RWT Artikel gab. Hatte ich damals schon mal erwähnt:
http://www.planet3dnow.de/vbulletin/showthread.php?p=4282702#post4282702
Nochmals die Zusammenfassung, Quelle im GCC:
So und bei RWT steht:> The new hardware issues two windows of the size N bytes of
> instructions in every cycle. It goes into accelerate mode if the
> windows have the right combination of instructions or alignments. Our
> goal is to maximize the IPC by proper instruction scheduling and
> alignments.
>
> Here is a summary of the most important requirements:
>
> a) Maximum of N instructions per window.
> b) An instruction may cross the first window.
> c) Each window can have maximum of x memory loads and y memory
> stores .
> d) The total number of immediate constants in the instructions
> of a window should not exceed k.
> e) The first window must be aligned on 16 byte boundary.
> f) A Window set terminates when a branch exists in a window.
> g) The number of allowed prefixes varies for instructions.
> h) A window set needs to be padded by prefixes in instructions
> or terminated by nops to ensure adherence to the rules.
http://www.realworldtech.com/page.cfm?ArticleID=RWT082610181333&p=5The decoding begins by inspecting the first two of the 16B windows in the IBB for a single core. In many circumstances, instructions can be taken from both windows, but there are restrictions based upon alignment, number of loads and stores, branches, and other factors which can restrict decoding to a single 16B window.
Das muss es doch fast sein ... entweder 1 Fenster pro Takt, oder accelerated halt 2 Fenster pro Takt, falls die Instruktionen in beiden Fenstern den gewünschten Mix haben.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Der Trick mit den Fenstern liegt dann wohl darin, dass bei Erfüllung der Bedingungen ein Fenster schneller bearbeitet ist und dann sofort das zweite dran ist. Das könnte eine interessante Schaltung sein. Wieso war da noch nix in den Patenten?
Ich habe nun mal einige der Dinge gebloggt: http://citavia.blog.de/2010/10/26/more-bulldozer-info-and-a-deep-gpu-analysis-9794436/
Da ist auch anderes Zeug dabei. Hiroshige Goto war mal wieder fleißig. Apropos ich habe mal seine ISSCC-Zahlen zum Llano (29% Leakage u. ggüber 45nm Reduktion von dyn Power sowie Leakage um x% (nicht im Kopf)) verknüpft und kam auf 127% ursprüngliche Power (45nm, im Vergleich zu Llano's Verbesserungen). Muss mal schauen, was da noch weiter zu finden ist.
Ich habe nun mal einige der Dinge gebloggt: http://citavia.blog.de/2010/10/26/more-bulldozer-info-and-a-deep-gpu-analysis-9794436/
Da ist auch anderes Zeug dabei. Hiroshige Goto war mal wieder fleißig. Apropos ich habe mal seine ISSCC-Zahlen zum Llano (29% Leakage u. ggüber 45nm Reduktion von dyn Power sowie Leakage um x% (nicht im Kopf)) verknüpft und kam auf 127% ursprüngliche Power (45nm, im Vergleich zu Llano's Verbesserungen). Muss mal schauen, was da noch weiter zu finden ist.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Vielleicht bist Du auf nem alten Stand ?Wieso war da noch nix in den Patenten?

Hast Du schon das Patent vom 19.10.2010 gesehen ? Ist von den gleichen Leuten, die schon das Decoderpatent von 2008 schrieben, das du vor Ewigkeiten verlinkt hattest. Wurde ein halbes Jahr später eingereicht.
Aaber ... viel steht da nicht drin, die beleuchten das eher von der anderen Seite, und zwar sollen am Ende immer 4 Instruktionen rauskommen. Falls die Instruktionen jetzt aber recht lange sind, muss man halt dann noch im Notfall das zweites Fenster "anzapfen".
Widerspräche damit eher dem "accelerated" Gedanken ... ok es werden 2 statt einem Fenster eingelesen, aber am Ende kommt nicht mehr bei raus ^^
Hier der betreffende Ausschnitt:
Ausserdem noch neu, ebenfalls vom 19.10, Power-Tokens:In one specific implementation, as illustrated in FIG. 4A, pick unit 135 A may determine the actual start of four variable length instructions per cycle. In this implementation, the start pointer is used to generate InstPtr 0 , and is also used by mux 470 A, along with the corresponding first and second pointers, to generate InstPtr 1 and InstPtr 2 . Then, InstPtr 2 is used by mux 470 B, along with the corresponding first and second pointers, to generate InstPtr 3 and InstPtr 4 . Pick unit 135 A may repeat this process, or loop, various times until pick unit 135 A determines the actual start of the remaining variable length instructions within the scan window. Since InstPtr 4 is the last generated instruction pointer for each loop, next start pointer logic 475 A may store InstPtr 4 in buffer 250 each time and designate InstPtr 4 as the next start pointer for the next loop. This process enables superscalar instruction decode of variable length instructions.
In some cases, these steps do not result in four valid instruction pointers, i.e., InstPtr 0 -InstPtr 4 . In these cases, pick unit 135 A may use the last valid instruction pointer as the next start pointer for the next loop. For instance, in one example, these steps may only result in two instruction pointers (InstPtr 0 and InstPtr 2 ), e.g., if the process has reached the end of this particular scan window. In this example, pick unit 135 A may designate InstPtr 2 as the next start pointer for the next loop. Specifically, in this example, InstPtr 2 may serve as the next start pointer for the instruction bytes obtained based on a next scan window of predetermined size ‘X’. In other words, similar to the start pointer of the previous scan window, this start pointer may point to the actual start of the first variable length instruction within the next scan window.
Eventuell der Grund für AM3+Token based power control mechanism
A token-based power control mechanism for an apparatus including a power controller and a plurality of processing devices. The power controller may detect a power budget allotted for the apparatus. The power controller may convert the allotted power budget into a plurality of power tokens, each power token being a portion of the allotted power budget. The power controller may then assign one or more of the plurality of power tokens to each of the processing devices. The assigned power tokens may determine the power allotted for each of the processing devices. The power controller may receive one or more requests from the plurality of processing devices for one or more additional power tokens. In response to receiving the requests, the power controller may determine whether to change the distribution of power tokens among the processing devices.

Edit: Doch nicht neu, das Patent gabs schon mal 2008, kA wieso das jetzt nochmal publiziert wird...
Ausserdem noch ein Patent von September - schaut aber auch altbekannt aus, mit den ganzen eager execution Zeugs, eventuell nur ein altes AMD Patent in ein GF Patent umgewandelt? Naja wie auch immer, habs aber nochmal angeschaut und interessante Stellen bezgl. unser vorherigen Diskussion zu Flywheel und eventuell auch des accelerated modes gefunden:
a) Flywheel: Geht um den Decoder:
In den claims stehts auch:At block 508, the format decoder 316 and the format decoder 318 perform final decoding on the instruction operations output by the microcode decoder 312 and the fastpath decoder 314, respectively, in preparation for dispatch. This final decoding can include configuring the instruction operations in accordance with an internal dispatch format, applying register renaming, and the like. The formatted instruction operations then are fed to the dispatch buffer 320.
US7725690  17. The method as recited in claim 16 further comprising performing register renaming on the concurrently selected instructions.
istributed dispatch with concurrent, out-of-order dispatch Klingt ja fast wie die erste Renaming Stufe von Flywheel. Renaming noch vor dem ersten Dispatch, also vor den Schedulern. Passt perfekt ins Schema:
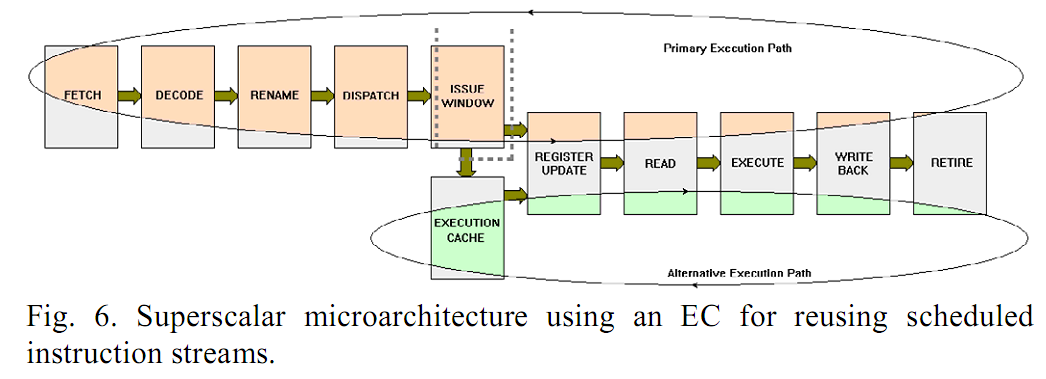
Zwar steht da nur "can include", aber ist ja mal egal. Alleine, dass das als möglich beschrieben wird, ist interessant.
Schreib das mal in den comp.arch Thread, wäre interessant, was die Profis dazu sagen
Langsam wird das Front-End zur hochinteressantesten Sache
Edit:
Nochmals als Zusammenfassung in einem Bildchen:
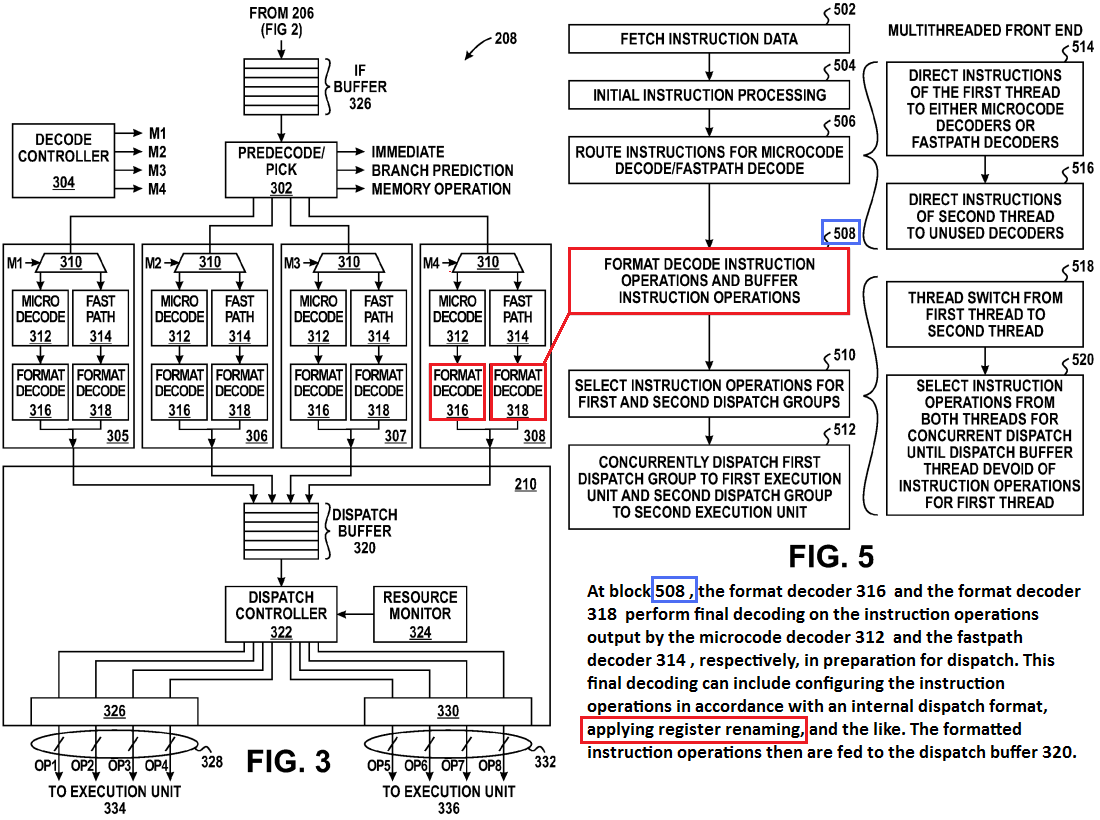
b) Accelerated mode:
Eventuell bezieht sichs auch auf den double Dispatch zw. Decoder und Schedulern.
Da gibts ja 2x4 Leitungen (in den Patenten, real wären 3x4 sinnvoll), die will man natürlich möglichst komplett auslasten, deshalb macht es dann natürlich Sinn, die Pakete so zu schnüren, dass z.B. ein 4er Paket für nen Int Cluster 2 ALU und 2 AGU Ops haben, um die Bandbreite auch 100% auslasten zu können. Die restlichen Randbedingungen könnten dafür nötig sein, damit das Instr. Päckchen passend durch den Decoder kommt.
Passenden Textstellen:
Quelle:The instruction dispatch module 208 includes a dispatch buffer 320, a dispatch controller 322, a resource monitor 324, a bus controller 326 coupled to a dispatch bus 328 and a bus controller 330 coupled to a dispatch bus 332. The dispatch bus 328 is coupled to an execution unit 334 (FIG. 4) and the dispatch bus 332 is coupled to an execution unit 336 (FIG. 4), where the execution units 334 and 336 each can include an integer execution unit or a floating point unit. The dispatch buses 326 and 332, in one embodiment, are separate (i.e., no shared conductive bus traces) and each is capable of concurrently transmitting up to N instruction operations to the corresponding execution unit. In the illustrated example, up to four (i.e., N=4) instruction operations can be dispatched on each dispatch bus for any given dispatch cycle.
(...)
Referring to FIG. 5, an example method 500 of operation of the implementation of the front-end unit 200 as represented in FIG. 3 is illustrated in accordance with at least one embodiment of the present disclosure. At block 502, the instruction fetch module 206 (FIG. 1) fetches instruction data into an instruction fetch buffer 326. In at least one embodiment, the instruction data represents one or more instructions with variable lengths, such as instructions in accordance with the x86 instruction architecture. Accordingly, in one embodiment, the instruction data includes one or more start bits and one or more end bits to delineate instructions. At block 504, the predecode/pick module 320 performs initial instruction processing by scanning the instruction data to identify the instruction boundaries and to verify that the represented instruction lengths are correct. Further, the predecode/pick module 320 predecodes the identified instructions to identify certain pertinent characteristics that may affect the processing of the instructions downstream, such as whether the instructions include an immediate field, whether there are any branches, whether an instruction may require a load operation, a store operation, or another memory operation, and the like.
Processing pipeline having parallel dispatch and method thereof
Von dem letztgenannten, gefetteten Vorgang steht allerdings NULL im neuen Patent, das ich ganz oben verlinkt hatte, und das obwohl es darin genau um die Pick Unit geht .. mysteriös ... da sollte dann eigentlich noch ein weiteres Patent kommen ...
ciao
Alex
P.S: Weitere Patente, kA ob die neu oder nur kopiert sind, zumindest sind die im Oktober veröffentlicht:
GF:
Method and apparatus for filtering memory write snoop activity in a distributed shared memory computer
Method and apparatus for filtering memory write snoop activity in a distributed shared memory computer
Direct memory access (DMA) address translation in an input/output memory management unit (IOMMU)
AMD:
System and method of load-store forwarding
Distributed directory cache
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Erstmal: Mensch, du hast ja richtig viel analysiert!Vielleicht bist Du auf nem alten Stand ?
Hast Du schon das Patent vom 19.10.2010 gesehen ? Ist von den gleichen Leuten, die schon das Decoderpatent von 2008 schrieben, das du vor Ewigkeiten verlinkt hattest. Wurde ein halbes Jahr später eingereicht.
Nun eine erste Reaktion: Die Patente stammen quasi von den Pat. Applications ab. Deshalb schau ich meist nicht rein, wenn ich die daher schon kenne. Aber ein Diff scheint sich doch zu lohnen.
Ich sehe ja jeden Dienstag und Donnerstag bei Freepatentsonline rein, da dann die neuen Patente u. Applications erscheinen. Andere Daten, geänderte Passagen können durch Anpassungen wegen anderen Patenten u. Rechteinhabern entstehen.
Die Sache mit dem Decoding:
Dass weniger als 4 Instructions (ich verstehe 4 decoded instr. pro Cycle hier als 4 ALU/FP ops + AGU ops) pro Fenster herauskommen, ist schon ok. Wenn da nur 2 ALU + 2 AGUs wären, wäre das im Durchschnitt eher zuwenig. Was mit accelerated gemeint sein kann (hatte ich glaub schon geschrieben): Wenn alles passt, kann man sich komplexere Überprüfungen (critical paths) sparen -> höherer Takt möglich, evtl. sogar doppelter.
Wenn man nämlich weiss, dass in einem bestimmten Modus eine Pipelinestufe ein Ergebnis garantiert nach 50% der Zeit an den Ausgängen anliegen hat, kann ich das auch dann schon abfassen. Wäre auch mal was.. jetzt ist es jedenfalls schon "prior art"
Bringt natürlich nur etwas, wenn die mit höherer Rate entstehenden Ergebnisse auch so schnell weitergereicht werden können, z.B. in einen Buffer.Dann bräuchte man auch "double dispatch".
Deine Anmerkung zum verschwundenen Patenttext: "downstream" wäre ja schon bei den Decodern. Aber was da beschrieben steht, kann schon durch IBM&Co patentiert sein.
Neue Probe Filter Patente (natürlich von Pat Conway) sind vermutlich auch für BD passend. Interessant auch, dass teilweise (IOMMU) noch Mitch mit auftaucht. Naja, die Arbeit fand sicher vorher schon statt. Und da GF schon recht früh solche AMD-Patente erhielt/übernahm, habe ich sie zusammen mit ATI in meiner Suchmaske.
Die Offenlegungsschrift (so heißt die Pat. App bei uns) zum Power Token Patent war eine der ersten mit dem BD-Schema. Und das spielt auch bei APM Boost eine Rolle. Rechne schonmal mit SB-ähnlichem Umgang mit der TDP. Es gibt da noch mehr. Habe auch schon was zum Sockel erfahren, was ihn unterscheidet. Spannend.. ^^ Tja.. diese P-States.. steht irgendwo, dass sie lange aktiv sein müssen? Nein. Also... geht da noch was. Auch dazwischen. Und so eine gewisse Latenz.. da sag ich mal: siehe L2.

Gibt es eigentlich ärztliche Studien zum Aufkommen von Belastungsstress bei Intel-Mitarbeitern seit wachsender Informationsmenge zum BD?
Gut, am meisten könnten da Sales Manager mit Umsatzzielen schwitzen.Dresdenboy
Redaktion
☆☆☆☆☆☆
Eine weitere Anmerkungen zum 4-fach Retirement = genug für 2 FP+2 ALU: Beim K8 werden max. 3 MacroOps pro Takt retired, obwohl von Exec-Seite her das sowohl von der FPU als auch den Integer-Units allein verursacht werden könnte. Das ist sicher auch Designvereinfachungen (Symmetrie) geschuldet, aber auch der Möglichkeit von reinem Int- oder stark FP-anteiligem Code. Was also, wenn Decode/Retirement auf 4-fach pro Thread ausgelegt ist, während EX auf 2-fach optimiert wurde?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Naja, ist halt jetzt viel effizienter. Früher hatte man nen 6 Zylinder Motor von dem abwechselnd nur je 3 Zylinder max. liefen. Konnte man in den Single Core Zeiten machen, aber wenn man wie jetzt aktuell immer mehr Kerne auf ein DIE zwängt, wirds langsam "unpraktisch".Eine weitere Anmerkungen zum 4-fach Retirement = genug für 2 FP+2 ALU: Beim K8 werden max. 3 MacroOps pro Takt retired, obwohl von Exec-Seite her das sowohl von der FPU als auch den Integer-Units allein verursacht werden könnte. Das ist sicher auch Designvereinfachungen (Symmetrie) geschuldet, aber auch der Möglichkeit von reinem Int- oder stark FP-anteiligem Code. Was also, wenn Decode/Retirement auf 4-fach pro Thread ausgelegt ist, während EX auf 2-fach optimiert wurde?
Ein deutliches Zeichen, dass da mehr auf Gesamtdurchsatz optimiert wird, ist ja der neue Dispatch Controller, anstatt 3 Leitungen aus der Pack Unit wie beim K10 gehen da jetzt 8 raus, ne "kleine" Steigerung
Ist oben im verlinkten Bild zu sehen, hatten wir galub ich auch schon diskutiert, als Du das Patent ausgegraben hattest.Was mir da noch nicht ganz klar ist, wie sie das im Modul hinbekommen. 8 Leitungen sind zuwenig für 2x 4x INT (inkl. AGUs) und 4x FP. Entweder double Dispatch, oder halt nochmal 4 Leitungen für den 2ten INT Kern. Wobei double Dispatch auch nicht viel hülfe, denn was bringt mir das, wenn die Leitungen in den falschen Cluster führen
Ansonsten hab ich mir mal noch das Front-End angeschaut, der Titel des einen Patent machte mich stutzig:
Von OoO steht aber nichts im Text ... also hab ich mal die zitierten Patente angesehen, da kommt man dann zu sowas:Title:
[SIZE=+1]Distributed dispatch with concurrent, out-of-order dispatch[/SIZE]
Document Type and Number:
United States Patent 7725690
Ok, kein OoO Dispatch, sondern ein OoO Decode, aber hej - das klingt auch viel spannender[SIZE=+1]Using multiple decoders and a reorder queue to decode instructions out of order [/SIZE]
Document Type and Number:
United States Patent 6192465

Prinzipiell war das sogar schon bekannt, aber nur indirekt. In dem bereits oben erwähnten Patent mit dem 8fach Dispatch steht ja drin, dass die 4 FaP/Complx. Decode Blöcke unabhängig sind. Tja das bedeutet nichts anderes als OoO, denn ansonsten müßten alle Decoder darauf warten, dass die vorherige Instr. fertig decodiert wurde.
In dem 6192465 Patent stehts jetzt explizit drin, wenn ein Decoder lange an ner langen Byte Folge zu knabbern hat, ist das den restlichen Decs egal, die dekodieren einfach am nächsten Block weiter und warten nicht.
Orginaltext:
Das Patent ist von 2001, da frag ich mich, wieso sie das nicht schon im K10 eingebaut haben, klingt ja recht praktisch. Naja, wäre wohl ohne Anpassungen im DownStream relativ nutzlos gewesen.13. A method for operating a microprocessor comprising:
fetching a plurality of instruction bytes;
decoding the instructions contained within the plurality of instruction bytes out of program order, wherein the decoding is performed by:
using a first decoder to decode a first instruction contained within the plurality of instructions bytes,
using a second decoder to decode a second instruction contained within the plurality of instructions bytes, wherein the second instruction occurs after the first instruction in program order, and
using the second decoder to decode a third instruction contained within the plurality of instructions bytes, wherein the third instruction occurs after the first and second instructions in program order, wherein the second decoder is configured to complete decoding the second instruction and begin decoding the third instruction after the first decoder begins decoding the first instruction and before the first decoder completes decoding the first instruction;
reordering the decoded instructions to program order;
performing dependency checking on the decoded and reordered instructions;
issuing the instructions to reservation stations for eventual execution out of program order; and
executing the instructions out of program order.
Aber zurück zu dem OoO Dispatch ... falls das wirklich OoO Dispatch wäre, gäbs eventuell Probleme mit dem Dependecy Checks, die man für die OoO Execution braucht. In dem 2001er Patent wird das in nem Puffer vor dem Dispatch wieder InO sortiert. Könnte man sicherlich im "Dispatch Puffer" im BD Patent machen, aber dann wärs eigentlich kein OoO Dispatch mehr ... im Flywheel Artikel war dazu glaube ich auch nichts.
Im 2001er Patent ist ne schöne Erklärung zu den Dependecy Checks, kopier ich mal mir rein:
Ansonsten noch ein paar Textstückchen:One proposed method for quickly decoding large numbers of instructions involves using a number of parallel decoders. However, current implementations using parallel decoders have been limited in their throughput because of the "in-order" (i.e., in program order) nature of decoding. Most programs rely upon their instructions being executed in a particular order. This order is referred to as "program order". As previously noted, most modern microprocessors support out-of-order execution. However, these microprocessors must ensure that the instructions that are executed out-of-order do not aversely affect the intended operation of the program. This is accomplished through "dependency checking". Dependency checking refers to determining which instructions rely upon other instructions' prior execution to finction properly. Thus, dependency checking ensures that the only instructions that are executed out of order are those that will not adversely affect the desired operation of the program. For typical dependency checking hardware to operate correctly, it relies upon receiving decoded instructions that are in-order. Thus, typical instruction decoders receive and decode instructions in program order so that the program order will be preserved for the dependency checking hardware (typically the next stage in the instruction processing pipeline).
This in-order configuration affects decoder throughput by causing some decoders to stall in certain instances. For example, when a new set of instruction bytes is received by the decoders, each decoder must wait to output its results (i.e., its decoded instructions) until all decoders before it have output their results. If not, the following pipeline stages may receive the decoded instructions out-of-order.
For these reasons, a method and apparatus for quickly decoding a large number of instructions is desirable. In particular, a method capable of quickly decoding large numbers of instructions out of order is desirable.
Die 8byte pro Decoder könnten zu dem N=4 aus dem GCC accelerated Text passen, mehr als 4 Instruktionen bekommt man in 8byte AMD64 Code nicht unter. Nur im 32bit Betrieb würde es nicht passen, aber naja, interessiert langsam keinen mehrThe decode units output the decoded instructions according to their relative position within the cache line portions. The decoded instructions are received by the reorder queue, which comprises a plurality of storage lines. Each storage line in turn comprises a fixed number of instruction storage locations.
The number of storage locations may equal the maximum possible number of instructions within each cache line portion.
(...)
Note that 16-byte cache lines and 8-byte sequences are used for exemplary purposes only and that other configurations are possible and contemplated (e.g., 32-byte cache lines, with four independent decoders each receiving 8-byte sequences).
Advantageously, by configuring decode units 20A-B to decode independently and out-of-order, the chance of either decode unit 20A-B stalling while waiting for the other to complete its decoding may be reduced. Furthermore, an out-of-order decoding structure may allow multiple decoders (e.g., two or more) to be more effectively utilized.
Dazu passend wär dann auch der Satz bei RWT:
2x16 verteilt auf 4x8 .. würde passen, bleibt wieder die Frage nach dem accelerated Dingens. Da meintest Du ja, dass man sich "Checks" und Überprüfungen sparen könne ...The decoding begins by inspecting the first two of the 16B windows in the IBB for a single core. In many circumstances, instructions can be taken from both windows, but there are restrictions based upon alignment, number of loads and stores, branches, and other factors which can restrict decoding to a single 16B window.
Da stellt sich jetzt die Frage, wie so ein FastPath Dekoder genau aufgebaut ist. Dazu war auch noch ne Stelle im Patent:
Also jeder FaP Decoder besteht aus nem Array von LD/Str/SSE/AVX/etc. Decoder ? Dann wären die GCC Bedingungen ja schnell erklärt ... solange es nicht mehr LD/Str. etc. pp Instruktionen sind, als einzelne Decoder in nem Dec. Block vorhanden sind, gehts in einem Rutsch durch (accellerated), ansonsten halt nicht.Note that decode units 20A-B are drawn as single boxes for exemplary purposes only. Each decode unit 20A-B may in fact comprises a number of individual decoders each configured to decode a single instruction.
Hast Du zufällig Patente zu den K7 Decodern oder PPro bei der Hand ?
Falls nicht such ich mal und schaus mir an, das ist ja jetzt der letzte weisse Fleck, wie das genau abläuft.
Hab mich bisher nur bis:
vorgearbeitet.US6393549 Instruction alignment unit for routing variable byte-length instructions
Das ist vielleicht ein Schinken ... 68 Abbildungen, 132 Seiten *urks*
Kleines Zuckerl daraus:
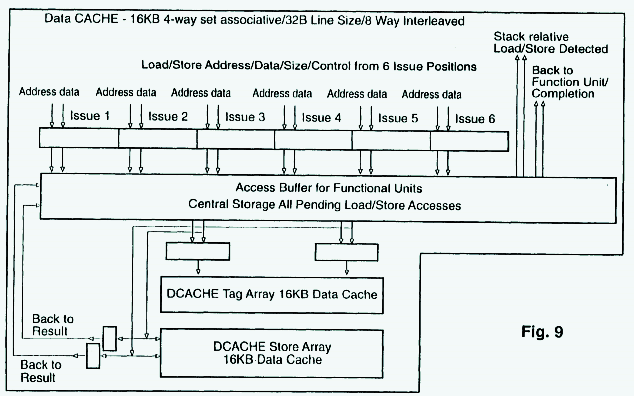
16kB 4way .. da war doch irgendwas
Naja, könnte auch gut Zufall sein, das Patent ist bald 10 Jahre alt ^^. War eventuell ein K9 bzw. K8-II Patent,irgendwo im Text steht auch was von 2 Takt Latenz, wenn ich mich recht erinnere, das würde dann ja nicht passen.
Ansonsten gibts da noch ne Menge, u.a. zu way prediction, aber hab ich mir jetzt nicht angetan
ciao
Alex
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Da stimme ich dir zu. Einfach bereitstellen. Das ist möglicherweise auch ein weiterer Grund für die Diskrepanz zw. ACP und TDP. TDP rechnet ja mit "alles aktiv", was aber mit normalem Code gar nicht dauerhaft machbar ist.Naja, ist halt jetzt viel effizienter. Früher hatte man nen 6 Zylinder Motor von dem abwechselnd nur je 3 Zylinder max. liefen. Konnte man in den Single Core Zeiten machen, aber wenn man wie jetzt aktuell immer mehr Kerne auf ein DIE zwängt, wirds langsam "unpraktisch".
Vom teilweise noch angezweifelten Code her werden scheinbar (für mich) bis zu 4 Macro Ops in eine Dispatch Group gepackt. Woanders stehts so ähnlich. Demnach wären pro Thread pro Takt (noch offen: auf welcher Basis?) 2 ALU + 2 AGU + 2 FP umsetzbar. Bzw. müsstest du bei dir 4x Int u. 4x FP für das Modul zählen (AGU sind "beiliegend"), was 8 Leitungen entspräche. Es sind wie gesagt "Macro Op-Leitungen".Ein deutliches Zeichen, dass da mehr auf Gesamtdurchsatz optimiert wird, ist ja der neue Dispatch Controller, anstatt 3 Leitungen aus der Pack Unit wie beim K10 gehen da jetzt 8 raus, ne "kleine" Steigerung
Was mir da noch nicht ganz klar ist, wie sie das im Modul hinbekommen. 8 Leitungen sind zuwenig für 2x 4x INT (inkl. AGUs) und 4x FP. Entweder double Dispatch, oder halt nochmal 4 Leitungen für den 2ten INT Kern. Wobei double Dispatch auch nicht viel hülfe, denn was bringt mir das, wenn die Leitungen in den falschen Cluster führen
Mit den Buffern, aus denen dann die Dispatch Groups Pakete geschnürt werden, würde das auch passen. Evtl. verzögern dann langsame Befehle, da noch nicht alle für eine Dispatch Group bereit sind. Da könnte dann eine spätere Dispatch Group alternativ zusammengebaut werden.. Steht da sowas irgendwo?Ok, kein OoO Dispatch, sondern ein OoO Decode, aber hej - das klingt auch viel spannender
Prinzipiell war das sogar schon bekannt, aber nur indirekt. In dem bereits oben erwähnten Patent mit dem 8fach Dispatch steht ja drin, dass die 4 FaP/Complx. Decode Blöcke unabhängig sind. Tja das bedeutet nichts anderes als OoO, denn ansonsten müßten alle Decoder darauf warten, dass die vorherige Instr. fertig decodiert wurde.
In dem 6192465 Patent stehts jetzt explizit drin, wenn ein Decoder lange an ner langen Byte Folge zu knabbern hat, ist das den restlichen Decs egal, die dekodieren einfach am nächsten Block weiter und warten nicht.
Hat den Aufwand vllt. nicht gelohnt oder andere Gründe.Das Patent ist von 2001, da frag ich mich, wieso sie das nicht schon im K10 eingebaut haben, klingt ja recht praktisch. Naja, wäre wohl ohne Anpassungen im DownStream relativ nutzlos gewesen.
Siehe oben. Buffer sind schon gut, da es ohne diese häufiger Stalls gäbe. Und für OoO sind sie wichtig, da das, was schon vorweg dekodiert wurde, erstmal irgendwo landen muss.Aber zurück zu dem OoO Dispatch ... falls das wirklich OoO Dispatch wäre, gäbs eventuell Probleme mit dem Dependecy Checks, die man für die OoO Execution braucht. In dem 2001er Patent wird das in nem Puffer vor dem Dispatch wieder InO sortiert. Könnte man sicherlich im "Dispatch Puffer" im BD Patent machen, aber dann wärs eigentlich kein OoO Dispatch mehr ... im Flywheel Artikel war dazu glaube ich auch nichts.
Wie man sieht, wurde bei AMD schon immer viel bzgl. Decoding entwickelt bzw. erforscht. Das Riesenpatent erinnert mich an ein ähnlich großes, was auch zum K9 passte. Es gibt da dieses 6-wide (mit Witt als K5-Entwickler) u. das mit den geteilten Instruction Queues (von Hans schonmal aufgegriffen).
Dieses Array von Decodern ist schon ok. Das bezieht sich vermutlich auf eine Aufteilung, je nach Instruction Code. Da kann man am Code schon erkennen, ob das AVX ist oder x87 u. leitet das weiter an eine entspr. Schaltung, die dafür optimiert ist. Die anderen brauchen dann nix tun (kein dynamic power). Früher hat man vermutlich einfach einen großen random logic Block gehabt: Instruction Bytes rein (aligned) und µOp rausDa stellt sich jetzt die Frage, wie so ein FastPath Dekoder genau aufgebaut ist. Dazu war auch noch ne Stelle im Patent:
Also jeder FaP Decoder besteht aus nem Array von LD/Str/SSE/AVX/etc. Decoder ? Dann wären die GCC Bedingungen ja schnell erklärt ... solange es nicht mehr LD/Str. etc. pp Instruktionen sind, als einzelne Decoder in nem Dec. Block vorhanden sind, gehts in einem Rutsch durch (accellerated), ansonsten halt nicht.
Quasi ein Table Lookup.Hab ich auf dem anderen Rechner. Schau ich gleich nochmal.Hast Du zufällig Patente zu den K7 Decodern oder PPro bei der Hand ?
Früher war alles viel ausführlicherDas ist vielleicht ein Schinken ... 68 Abbildungen, 132 Seiten *urks*
Auch beim K5.Der 16k Cache bei einem der älteren Designs kommt mir bekannt vor. Hatten wir den schonmal erwähnt? Egal. Hier wäre die 2 Takte Latenz auch passend zu unseren Erwartungen weiter oben.Kleines Zuckerl daraus:
16kB 4way .. da war doch irgendwas
Naja, könnte auch gut Zufall sein, das Patent ist bald 10 Jahre alt ^^. War eventuell ein K9 bzw. K8-II Patent,irgendwo im Text steht auch was von 2 Takt Latenz, wenn ich mich recht erinnere, das würde dann ja nicht passen.
Ansonsten gibts da noch ne Menge, u.a. zu way prediction, aber hab ich mir jetzt nicht angetan
Man stelle sich vor: "Hey, wir haben doch noch das 6-wide Design!" - "Nee, zu breit, zuviel Einheiten oft idle, zuviel Energieverbrauch" - "Hmm.. da habe ich kürzlich was gelesen. Wir nehmen einfach weniger Ausführungseinheiten - damit alles kleiner, einfacher, schneller - und takten die bei Bedarf hoch..."
.
EDIT :
.
Hier geht's auch um Cluster und deren Energieeffizienz (allerdings für gemeinsame Bearbeitung eines Threads):
http://www.iti.uni-stuttgart.de/~bergmats/seminar06EE/01_energy_optimization_report.pdf
EDIT #2:
Hier was zum P6 (z.B. ne Nutzenkurve zum 4-1-1 Decoder): http://www.hotchips.org/archives/hc7/2_Mon/HC7.S2/HC7.2.1.pdf
Da ging es auch um Taktfrequenz. Und das grundsätzliche P6-Design lebt heute noch ein wenig im SB weiter. Das genaue Decoderdesign ist da aber nicht drin.
Das riesige Patent hatte ich mir schonmal Mitte 2009 mit einigen anderen abgespeichert. Da könnten noch 6393549, 6604190 u. 6553482 interessant sein. Und da sind Thang Tran u. David B. Witt dabei. Es sind mehrere Designs, aber von Komplexität u. Pipelinedarstellungen her alles eher große OOO Maschinen mit "normalem" Takt.
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ich habe das nochmal angesehen. Die FDIV-Latenzen (x87) sehen deutlich anders aus als die für 128b SSE2-DIV, wo sie nicht so krass steigen (von 20 auf 27 Zyklen für Double, also 35%). Das ist im Blog auch nochmal entsprechend hervorgehoben.Danke für den Hinweis auf das Cost-File. Die Zahlen passen. Da auch schön zu sehen: FDIV-Latenz etwas mehr als verdoppelt. Und das, obwohl mit den FMACs ein DIV-Algo mit weniger Operationen umsetzbar ist (Goldschmidt, siehe Bobcat-FPU-Paper). Natürlich ziehen die 6-Takt-Latenzen das etwas in die Länge. Aber insgesamt hätte man dank FMAC vllt. (müsste ich nachsehen) sogar mit kaum mehr Zyklen herauskommen können. Das kann man gern auch als Hinweis auf die Taktfrequenzen nehmen.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
BD doch vor Llano?
http://www.xbitlabs.com/news/cpu/display/20101105133510_AMD_to_Start_Production_of_Desktop_Bulldozer_Microprocessors_in_April.html#
oder bringen sie BD-Server und BD-Desktop durcheinander.
http://www.xbitlabs.com/news/cpu/display/20101105133510_AMD_to_Start_Production_of_Desktop_Bulldozer_Microprocessors_in_April.html#
oder bringen sie BD-Server und BD-Desktop durcheinander.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 17
- Aufrufe
- 2K
- Antworten
- 19
- Aufrufe
- 3K
- Antworten
- 0
- Aufrufe
- 797