App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Spekulationsthread: Was kommt 2011+
- Ersteller Ge0rgy
- Erstellt am
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Jetzt schon auszuplaudern was in einem Jahr an konkreter Performance kommt wäre angesichts der Konkurrenz auch töricht.
Viel wird nicht zu erwarten sein von der Demo und erst recht nichts was eine konkrete Performance abschätzen lässt.
Es heißt ja auch nicht dass die Orochis die sie da vorführen wollen schon verkaufsfertiges silizium sind...evtl. ist der Takt noch recht bescheiden o.ä.
Gut, wenn sie garnichts zeigen haben sie ein Problem der Glaubwürdigkeit ob da wirklih ein BD drinsteckt und nicht einfach ein K10 o.ä.
Also wenn schon müssten sie was mit AVX zeigen oder so, was garantiert noch keine akt. CPU aus ihrem Hause beherrscht...
whatever...wir werden sehen
Viel wird nicht zu erwarten sein von der Demo und erst recht nichts was eine konkrete Performance abschätzen lässt.
Es heißt ja auch nicht dass die Orochis die sie da vorführen wollen schon verkaufsfertiges silizium sind...evtl. ist der Takt noch recht bescheiden o.ä.
Gut, wenn sie garnichts zeigen haben sie ein Problem der Glaubwürdigkeit ob da wirklih ein BD drinsteckt und nicht einfach ein K10 o.ä.
Also wenn schon müssten sie was mit AVX zeigen oder so, was garantiert noch keine akt. CPU aus ihrem Hause beherrscht...
whatever...wir werden sehen
Wie meist geht es um ein Zeichen...ein Lebenszeichen vom BD Die fuer die Investoren ..von mir aus mit Taskmanager und gebooteten System plus die eine oder andere Spielerei.
Vielleicht gibt es auch ein paar Details - aber mehr waere eher nettes Zubrot...
Vielleicht gibt es auch ein paar Details - aber mehr waere eher nettes Zubrot...
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Schon, aber ist "irgendein" lauffähiges system, das im CPU-Z irgend eine komische familie etc. ausweist (sind ja alles theoretisch manipulierbare daten) wirklich ein aussagekräftiges zeichen?
Ich meine, ich kann auch hingehen, sagen ich hätte nen monsterchip in entwicklung und dann kaufe ich nen 0815-PC, patche CPU-Z und öffne den Taksmanager und schon hab ich investoren an der Angel!? Oo
Ich meine, ich kann auch hingehen, sagen ich hätte nen monsterchip in entwicklung und dann kaufe ich nen 0815-PC, patche CPU-Z und öffne den Taksmanager und schon hab ich investoren an der Angel!? Oo
Ragas
Grand Admiral Special
- Mitglied seit
- 24.05.2005
- Beiträge
- 4.470
- Renomée
- 85
- Details zu meinem Desktop
- Prozessor
- AMD Athlon 64 X2 3800+ @2520MHz; 1,4V; 53°C
- Mainboard
- Asus A8N-E
- Kühlung
- Thermaltake Sonic Tower (doppelt belüftet)
- Speicher
- 4x Infineon DDR400 512MB @207MHz
- Grafikprozessor
- Nvidia GeForce FX 7800GT
- Display
- 1.: 24", Samsung SyncMaster 2443BW, 1920x1200 TFT 2.: 19", Schneider, 1280x1024 CRT
- HDD
- Seagate Sata1 200GB 7200rpm, 2x250GB Seagate SATA2 im Raid0
- Optisches Laufwerk
- DVDBrenner LG GSA 4167
- Soundkarte
- Creative X-Fi Extreme Music
- Gehäuse
- Thermaltake Soprano Silber
- Netzteil
- Be-quiet! Darkpower 470W
- Betriebssystem
- Windows XP; Linux Mandriva 2007.1 (Kernel: 2.6.22.2 Ragas-Edition :D )
- Webbrowser
- Firefox
- Verschiedenes
- -Lüftersteuerung: Aerogate3
Schon, aber ist "irgendein" lauffähiges system, das im CPU-Z irgend eine komische familie etc. ausweist (sind ja alles theoretisch manipulierbare daten) wirklich ein aussagekräftiges zeichen?
Ich meine, ich kann auch hingehen, sagen ich hätte nen monsterchip in entwicklung und dann kaufe ich nen 0815-PC, patche CPU-Z und öffne den Taksmanager und schon hab ich investoren an der Angel!? Oo
könntest du machen. würde aner im nachhinein deine glaubwürdigkeit stark einschränken (insofern etwas schief läuft) und damit auch das Geld, was das nächste mal von investoren kommt.
Schon, aber ist "irgendein" lauffähiges system, das im CPU-Z irgend eine komische familie etc. ausweist (sind ja alles theoretisch manipulierbare daten) wirklich ein aussagekräftiges zeichen?
Ich meine, ich kann auch hingehen, sagen ich hätte nen monsterchip in entwicklung und dann kaufe ich nen 0815-PC, patche CPU-Z und öffne den Taksmanager und schon hab ich investoren an der Angel!? Oo
Nun ja, richtig - aber sollte man eine Fakesystem zeigen und das kommt raus (und das kommt raus - siehe NV...) und es auch nur den Anschein haben, dass unter dem Kuehler ein Phenom II werkelt - schiesst man sich heftig ins Bein.
Etwas was sich AMD jetzt sicher nicht erlauben will oder kann - dann ist es besser zusagem: '..Hey Jungs, es dauert noch ein wenig...aber hier schon mal ein paar Flyer...mit der Roadmap der Ph2 fuer 2011...'
Ragas
Grand Admiral Special
- Mitglied seit
- 24.05.2005
- Beiträge
- 4.470
- Renomée
- 85
- Details zu meinem Desktop
- Prozessor
- AMD Athlon 64 X2 3800+ @2520MHz; 1,4V; 53°C
- Mainboard
- Asus A8N-E
- Kühlung
- Thermaltake Sonic Tower (doppelt belüftet)
- Speicher
- 4x Infineon DDR400 512MB @207MHz
- Grafikprozessor
- Nvidia GeForce FX 7800GT
- Display
- 1.: 24", Samsung SyncMaster 2443BW, 1920x1200 TFT 2.: 19", Schneider, 1280x1024 CRT
- HDD
- Seagate Sata1 200GB 7200rpm, 2x250GB Seagate SATA2 im Raid0
- Optisches Laufwerk
- DVDBrenner LG GSA 4167
- Soundkarte
- Creative X-Fi Extreme Music
- Gehäuse
- Thermaltake Soprano Silber
- Netzteil
- Be-quiet! Darkpower 470W
- Betriebssystem
- Windows XP; Linux Mandriva 2007.1 (Kernel: 2.6.22.2 Ragas-Edition :D )
- Webbrowser
- Firefox
- Verschiedenes
- -Lüftersteuerung: Aerogate3
Etwas was sich AMD jetzt sicher nicht erlauben will oder kann - dann ist es besser zusagem: '..Hey Jungs, es dauert noch ein wenig...aber hier schon mal ein paar Flyer...mit der Roadmap der Ph2 fuer 2011...'
Ja vorallem, da man mit anderen Produkten derzeit noch recht gut aufgestellt ist.
Z.Z. sicher - da gab es schon schlimmere Zeiten - aber Intel baut da gerade eine kleine Armada auf gegen die AMD es immer schwerer haben wird...ohne BD und Llano und Co...Ja vorallem, da man mit anderen Produkten derzeit noch recht gut aufgestellt ist.
Aber man ja zeigen, dass man auch noch etwas im Koecher hat..
Markus Everson
Grand Admiral Special
Schon, aber ist "irgendein" lauffähiges system, das im CPU-Z irgend eine komische familie etc. ausweist (sind ja alles theoretisch manipulierbare daten) wirklich ein aussagekräftiges zeichen?
Ich meine, ich kann auch hingehen, sagen ich hätte nen monsterchip in entwicklung und dann kaufe ich nen 0815-PC, patche CPU-Z und öffne den Taksmanager und schon hab ich investoren an der Angel!? Oo
Hey Duuuu. Ja, genau. Dich meine ich. Du hast Talent, Du. Ja genau, Talent.
Möchtest Du nicht steinreich werden, Du? Ich suche einen wie Dich, Du. Du könntest mir helfen, Du. Ich habe da so ein ganz tolles Ding erfunden, Du. Ja genau. Das soll das Ipad platt machen, Du. Aber dafür brauche ich noch eine gute Präsentation, Du. Da kannst Du mir doch sicher helfen, Du....? Aber psss, Du. Das muß alles ganz geheim bleiben, Du.
G
Gast30082015
Guest
Warum nur muss ich, wenn ich das lese, unweigerlich an Stewie Griffin denken.Hey Duuuu. Ja, genau. Dich meine ich. Du hast Talent, Du. Ja genau, Talent.
Möchtest Du nicht steinreich werden, Du? Ich suche einen wie Dich, Du. Du könntest mir helfen, Du. Ich habe da so ein ganz tolles Ding erfunden, Du. Ja genau. Das soll das Ipad platt machen, Du. Aber dafür brauche ich noch eine gute Präsentation, Du. Da kannst Du mir doch sicher helfen, Du....? Aber psss, Du. Das muß alles ganz geheim bleiben, Du.
 Thnx 4 that.
Thnx 4 that. 
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Ich entschuldige mich schon mal im voraus für die Frage, sollte diese im Thread schon behandelt worden sein; ich lese zwar die meiste Zeit hier mit, kann aber nicht alle Infos im Kopf behalten.
Kann der Decoder des BD beide Int-Einheiten mit Befehlen eines Threads füllen, sobald er erkennt, dass einer der beiden Threads auf eine Speicheranfrage wartet?
Ging mir gerade durch den Kopf, da ich gerade einen Treiber Lowlevel optimiere und dabei einige Spinwaits SMT freundlich ausgelegt habe. Dort kann ich dem Prozessor sagen, dass er die Schleife nicht schneller ausführen braucht, als der Speicher Daten liefern kann, da die Bedingung abhängig von einer Speicherwertveränderung ist, die nicht der Prozessor selbst auslöst, sonder eine PCIe Karte.
Bei SMT Prozessoren bringt das einen guten Leistungsschub, da der Prozessor weiß, dass er während dem warten auf den Speicher dem anderen Thread die Ressourcen zuteilen kann. Bei den aktuellen AMD Prozzies bringt es mir nur den Vorteil, dass ich Prozessor für die Dauer der Speicheranforderung idle und damit den Reordercache nicht zu sehr trashe. Sinnvolle Arbeit kann der Kern in dieser Zeit allerdings nicht leisten.
Wird sich dieses Verhalten mit Bulldozer ändern?
Kann der Decoder des BD beide Int-Einheiten mit Befehlen eines Threads füllen, sobald er erkennt, dass einer der beiden Threads auf eine Speicheranfrage wartet?
Ging mir gerade durch den Kopf, da ich gerade einen Treiber Lowlevel optimiere und dabei einige Spinwaits SMT freundlich ausgelegt habe. Dort kann ich dem Prozessor sagen, dass er die Schleife nicht schneller ausführen braucht, als der Speicher Daten liefern kann, da die Bedingung abhängig von einer Speicherwertveränderung ist, die nicht der Prozessor selbst auslöst, sonder eine PCIe Karte.
Bei SMT Prozessoren bringt das einen guten Leistungsschub, da der Prozessor weiß, dass er während dem warten auf den Speicher dem anderen Thread die Ressourcen zuteilen kann. Bei den aktuellen AMD Prozzies bringt es mir nur den Vorteil, dass ich Prozessor für die Dauer der Speicheranforderung idle und damit den Reordercache nicht zu sehr trashe. Sinnvolle Arbeit kann der Kern in dieser Zeit allerdings nicht leisten.
Wird sich dieses Verhalten mit Bulldozer ändern?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Nö das geht nicht, es gibt kein SMT, also 1Thread pro INT Cluster. Die FPU wird SMT ähnlich gemeinsam genutzt, aber dazu musst Du nichts machen, das geht automatisch. Berechnet wird, was in der Queue steht, wenn da nichts von Thread 1 kommt,dann kommt halt nichts. Wartet Thread 1 auf Daten, hat Thread2 die vollen Resourcen, ob er das nutzen kann hängt vom Code ab.Kann der Decoder des BD beide Int-Einheiten mit Befehlen eines Threads füllen, sobald er erkennt, dass einer der beiden Threads auf eine Speicheranfrage wartet?
Nein, das Einzige was man sich vorstellen könnte, wäre ein Ideln des einen Clusters und ein Hochtakten des anderen per Turbo Mode. Wenn die Wartezeit ausreichend lange ist, könnte sich das rentieren. Aber das hängt wohl auch davon ab, wie Du das der CPU mitteilen kannst.Wird sich dieses Verhalten mit Bulldozer ändern?
ciao
Ale
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
[ ... ]
Nein, das Einzige was man sich vorstellen könnte, wäre ein Ideln des einen Clusters und ein Hochtakten des anderen per Turbo Mode. Wenn die Wartezeit ausreichend lange ist, könnte sich das rentieren. Aber das hängt wohl auch davon ab, wie Du das der CPU mitteilen kannst.
Danke für die Antwort. Mitteilen kann man das dem Prozessor ganz einfach über einen Assemblerbefehl, der seit SSE2 unterstützt wird. Schade, das dadurch die Auslastung bei AMD CPUs nicht zu steigern ist.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Die Frage lautet nun: Muss die Auslastung gesteigert werden? So war es mal, als Vieles fix war (max. Takt, TDP). Aber jetzt ist es keine Verschwendung mehr, wenn ein nicht ausgelasteter Core oder die FPU Strom spart (im FPU-Fall bis zu 98%). Durch die gesparte Energie könnten andere Cores schneller arbeiten oder der gleiche Core später auch schneller, da eine Zeit lang der Energieverbrauch niedriger war (wie beim Sandy Bridge). Energie kann auch in den shared units wie Decoder gespart werden durch niedr. Durchsatz (dann clock gating) u. gefüllte Buffer.Danke für die Antwort. Mitteilen kann man das dem Prozessor ganz einfach über einen Assemblerbefehl, der seit SSE2 unterstützt wird. Schade, das dadurch die Auslastung bei AMD CPUs nicht zu steigern ist.
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Gerade in diesem Bereich wäre ich über SMT sehr froh. Ein Speicherzugriff beim Phenom dauert rund 200 Prozessortaktzyklen. Ich glaube nicht, dass in dieser geringen Zeit Clock- oder gar Powergating eingesetzt werden kann. Wenn ich also den Wartebefehl gebe, rennt die Pipeline munter mit NOOP weiter, was zwar ein Cache-Trashing verhindert, sinnvoll ist das aber meiner Meinung nach trotzdem nicht. Und um das nochmal deutlich zu machen: es geht mir nur um die INT-Einheiten, dass ein Thread mehr FPU Leistung bekommt, wenn der andere schläft ist mir klar.
Aber stimmt, ein Cross-Scheduling der Anweisungen zwischen den Int-Einheiten beim BD würde ein gemeinsamer Registerfile voraussetzen, was den schaltungstechnischen Aufwand ziemlich in die Höhe treiben würde.
Aber stimmt, ein Cross-Scheduling der Anweisungen zwischen den Int-Einheiten beim BD würde ein gemeinsamer Registerfile voraussetzen, was den schaltungstechnischen Aufwand ziemlich in die Höhe treiben würde.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Clock-Gating könnte man problemlos nutzen. Ob es für diese kurze Zeit wirklich Sinn macht, ist allerdings fraglich. Es gibt ja auch noch die CoolCore Technologie. Power-Gating ist eine andere Geschichte und problematischer, da der Aufwand um einiges höher ist.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Aja, das war Mwait, oder ? Wenn ich mich recht erinnere, nicht echter Bestandteil von SSE2, sondern nur "zufällig" mit dabei, da es halt zusammen mit dem ersten SSE2 P4 eingeführt hatte, der gleichzeitig eben auch noch SMT hatte. Oder wars schon der SSE3 P4 ... hmmm ach egal ^^Danke für die Antwort. Mitteilen kann man das dem Prozessor ganz einfach über einen Assemblerbefehl, der seit SSE2 unterstützt wird. Schade, das dadurch die Auslastung bei AMD CPUs nicht zu steigern ist.
Hmmm wie siehts denn mit Prefetch aus ? Kannst Du da nicht irgendwas sinnvolles treiben ?Gerade in diesem Bereich wäre ich über SMT sehr froh. Ein Speicherzugriff beim Phenom dauert rund 200 Prozessortaktzyklen. Ich glaube nicht, dass in dieser geringen Zeit Clock- oder gar Powergating eingesetzt werden kann. Wenn ich also den Wartebefehl gebe, rennt die Pipeline munter mit NOOP weiter, was zwar ein Cache-Trashing verhindert, sinnvoll ist das aber meiner Meinung nach trotzdem nicht. Und um das nochmal deutlich zu machen: es geht mir nur um die INT-Einheiten, dass ein Thread mehr FPU Leistung bekommt, wenn der andere schläft ist mir klar.
Ansonsten ist noch die Frage ob man die Wartezeit noch zu nem gewissen Grad mit OoO bzw. speculativen Berechnungen überbrücken kann.
Zusammengenommen sollte man damit die Not für SMT schon ziemlich eindämmen können, wenns darüberhinaus noch Zusatzboni wie hoher Takt etc. gibt, noch besser.
Speziell im Bulldozerfall kann man ja das auch andersherum sehen: Der Entwickler muss sich nicht mit SMT herumschlagen, da es 2 "echte" INT Cluster für 2 Threads gibt. Wieso kompliziert, wenns auch einfach geht
")
Ansonsten, wers noch nicht gesehen hat, AMD auf der SC10:
http://sites.amd.com/us/Documents/AMD_at_SC10_Schedule.pdf
Da gibts ein HPC Update ... mal schauen ob das noch ein bisschen mehr BD Infos gibt, als beim Analyst day.
ciao
Alex
Lynxeye
Admiral Special
- Mitglied seit
- 26.10.2007
- Beiträge
- 1.107
- Renomée
- 60
- Standort
- Sachsen
- Mein Laptop
- Lifebook T1010
- Details zu meinem Desktop
- Prozessor
- AMD FX 8150
- Mainboard
- Gigabyte GA-970A-UD3
- Kühlung
- Zalman Reserator 1 Plus
- Speicher
- 4x8GB DDR3-1600 G.Skill Ripjaws
- Grafikprozessor
- ASUS ENGTX 260
- Display
- 19" AOC LM928 (1280x1024), V7 21" (1680x1050)
- HDD
- Crucial M4 128GB, 500GB WD Caviar 24/7 Edition
- Optisches Laufwerk
- DVD Multibrenner LG GSA-4167B
- Soundkarte
- Creative Audigy 2 ZS
- Gehäuse
- Amacrox Spidertower
- Netzteil
- Enermax Liberty 500W
- Betriebssystem
- Fedora 17
- Webbrowser
- Firefox
- Verschiedenes
- komplett Silent durch passive Wasserkühlug
Ich gebe zu mein Beispiel ist ein ziemlicher Spezialfall, da der Treiber anders als viele Programme kein vorhersehbaren Datensätze verarbeitet, womit Sachen wie Prefetch ausgeschlossen sind. In Grunde sind diese Spinwaits nur kurze Verzögerungen, in denen ich auf einen Zustandwechsel der Karte warte, bis ich dem Anwendungsprogramm sagen kann: "du darfst weitermachen und mir Befehle schicken". Diese Zustandswechsel erfolgen so schnell, dass sich ein echter Taskswitch nicht lohnt.
Die Befehle gehören zwar nicht logisch zu SSE, sind aber auf allen Prozessoren an die Versionen gekoppelt. Mit SSE3 kann ich die Kerne noch effektiver schlafen legen, aber das ist eine andere Geschichte.
Und ja ich verwende die MWAIT. Ansonsten spekuliert der Prozessor immer weiter, dass er die Schleife ohne Abhängigkeiten ausführen kann und schüttet damit den Reorderbuffer zu. Somit bringt es auch auf nicht HT Systemen einen Vorteil. Bei HT Systemen schnappt sich halt der andere Thread die Ressourcen und tut was sinnvolles.
Die Befehle gehören zwar nicht logisch zu SSE, sind aber auf allen Prozessoren an die Versionen gekoppelt. Mit SSE3 kann ich die Kerne noch effektiver schlafen legen, aber das ist eine andere Geschichte.
Und ja ich verwende die MWAIT. Ansonsten spekuliert der Prozessor immer weiter, dass er die Schleife ohne Abhängigkeiten ausführen kann und schüttet damit den Reorderbuffer zu. Somit bringt es auch auf nicht HT Systemen einen Vorteil. Bei HT Systemen schnappt sich halt der andere Thread die Ressourcen und tut was sinnvolles.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Clock Gating geht taktweise u. kann - wenn von vornherein entspr. vorgesehen - pipelinestufenweise stattfinden. Das spart schonmal dynamic power. Power Gating hat etwas mehr Overhead. Siehe auch
http://www.planet3dnow.de/vbulletin/showpost.php?p=4299363&postcount=1456
@Opteron: Danke für Link
http://www.planet3dnow.de/vbulletin/showpost.php?p=4299363&postcount=1456
@Opteron: Danke für Link
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Bitte Bitte@Opteron: Danke für Link
")
Der Link zum heutigen Analyst Webcast ist gerade auch online gegangen:
http://www-waa-akam.thomson-webcast...e7&portal_id=583179303f3bd5200a6ee9411c6eb0f5
Los gehts um 17.30.
Also mal schon Popcorn bereitstellen
Wobei vielleicht auch vollwertiger Nahrung plus Kaffe vonnöten wäre:
Vielleicht warte ich doch nur ab, bis die Präsentationsfolien hier hochgeladen werden:Duration: Approximately 8 hours
http://ir.amd.com/phoenix.zhtml?c=74093&p=irol-2010analystday
Edit:
Anscheinend Motto des Tages:

Klingt eher nach Fusion, denn Bulldozer, aber in 8 Stunden kann ja viel passieren ^^
ciao
Alex
Zuletzt bearbeitet:
Crashtest
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2008
- Beiträge
- 9.275
- Renomée
- 1.413
- Standort
- Leipzig
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Collatz, yoyo, radac
- Lieblingsprojekt
- yoyo
- Meine Systeme
- Ryzen: 2x1600, 5x1700, 1x2700,1x3600, 1x5600X; EPYC 7V12 und Kleinzeuch
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Lenovo IdeaPad 5 14ALC05
- Details zu meinem Desktop
- Prozessor
- Ryzen 7950X / Ryzen 4750G
- Mainboard
- ASRock B650M PGRT / X570D4U
- Kühlung
- be quiet! Dark Rock Pro4 / Pure Rock Slim 2
- Speicher
- 64GB DDR5-5600 G Skill F5-5600J3036D16G / 32 GB DDR4-3200 ECC
- Grafikprozessor
- Raphael IGP / ASpeed AST-2500
- Display
- 27" Samsung LF27T450F
- SSD
- KINGSTON SNVS2000G
- HDD
- - / 8x Seagate IronWolf Pro 20TB
- Optisches Laufwerk
- 1x B.Ray - LG BD-RE BH16NS55
- Soundkarte
- onboard HD?
- Gehäuse
- zu kleines für die GPU
- Netzteil
- be quiet! Pure Power 11 400W / dito
- Tastatur
- CHERRY SECURE BOARD 1.0
- Maus
- Logitech RX250
- Betriebssystem
- Windows 10 19045.4355 / Server 20348.2227
- Webbrowser
- Edge 124.0.2478.51
- Verschiedenes
- U320 SCSI-Controller !!!!
- Internetanbindung
- ▼1000 MBit ▲82 MBit
naja "er" quatscht auch über Cloud --> Server !
Onkel_Dithmeyer
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 22.04.2008
- Beiträge
- 12.943
- Renomée
- 4.014
- Standort
- Zlavti
- Aktuelle Projekte
- Universe@home
- Lieblingsprojekt
- Universe@home
- Meine Systeme
- cd0726792825f6f563c8fc4afd8a10b9
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- Ryzen 9 3900X @4000 MHz//1,15V
- Mainboard
- MSI X370 XPOWER GAMING TITANIUM
- Kühlung
- Custom Wasserkühlung vom So. G34
- Speicher
- 4x8 GB @ 3000 MHz
- Grafikprozessor
- Radeon R9 Nano
- Display
- HP ZR30W & HP LP3065
- SSD
- 2 TB ADATA
- Optisches Laufwerk
- LG
- Soundkarte
- Im Headset
- Gehäuse
- Xigmatek
- Netzteil
- BeQuiet Dark Pro 9
- Tastatur
- GSkill KM570
- Maus
- GSkill MX780
- Betriebssystem
- Ubuntu 20.04
- Webbrowser
- Firefox Version 94715469
- Internetanbindung
- ▼100 Mbit ▲5 Mbit
Um 18:35 steht APU auf dem Programm. Dirk Meyer hat in seiner ersten Rede gesagt, dass Ontario diese Woche von AMD an die Partner geschickt wird.
Zuletzt bearbeitet:
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Na ja, Bulldozer ist/wird ja auch Teil von Fusion.Klingt eher nach Fusion, denn Bulldozer, aber in 8 Stunden kann ja viel passieren
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Wie erwartet: Genau so war es nun ...Ich tippe auf den Taskmanager, der die Auslastung durch 8 Endlosschleifen zeigt
1 HD Filmchen und 8 Threads im Taskmanager, war noch nichtmal 100% Last, sondern nur so ca. 25 ...
Roadmaps nicht viel Neues, ausser den 2012 Nennungen, da kommt dann wohl BDVer2 (next generation BD) im Fusion-BD Chip, aber keine näheren Spezifizierungen des 2011er Zeitplans

Aja und noch ein 8Core BD in 2012 ... sollte kein MCM sein, denn es steht auch ein 20 Core Opteron an ... ob das DIE wohl ins G34 Gehäuse passt ^^
Ich rechne da dann mal mit nur 1 MB L2 ...
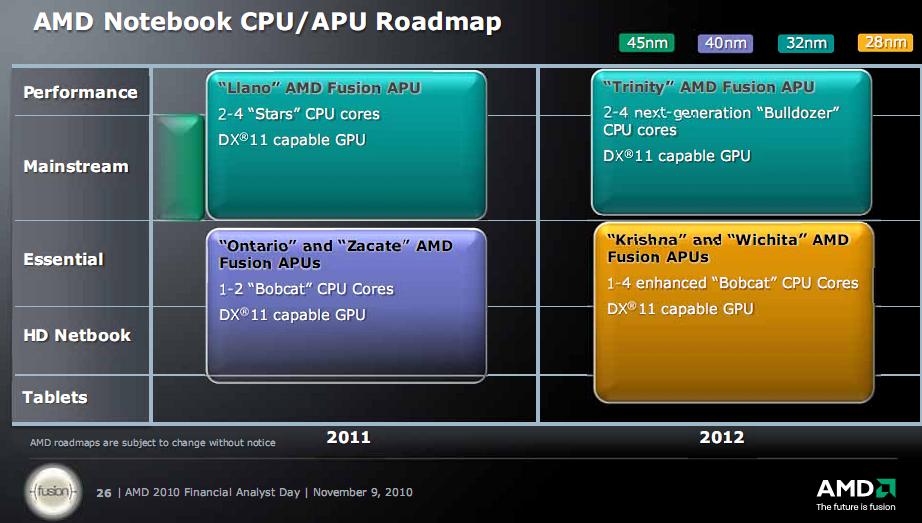
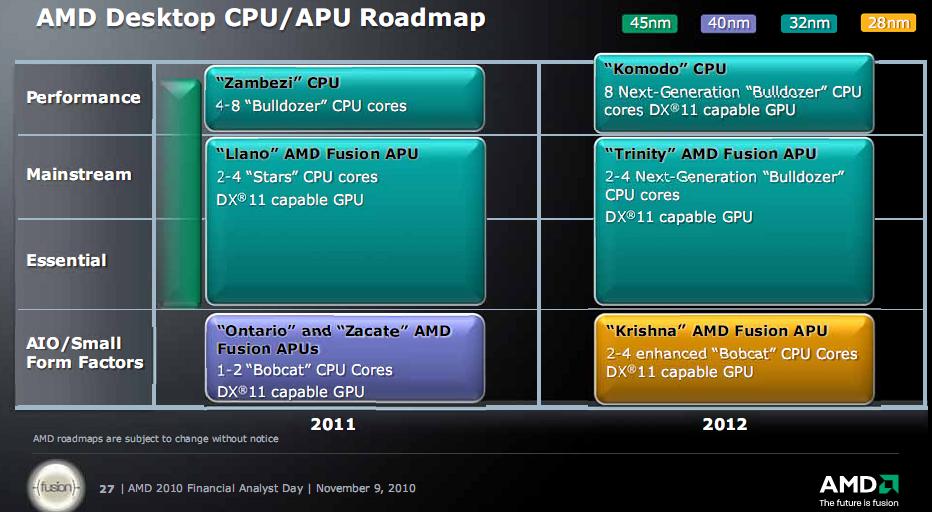
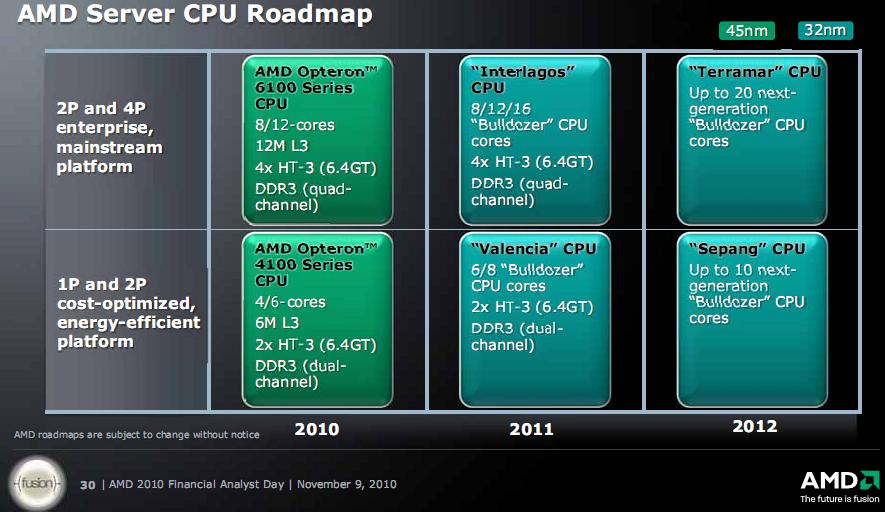
ciao
Alex
Zuletzt bearbeitet:

BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Hmm, 2012
Krishna und Wichita - 1-4 enhanced Bobcat Cores in 28 nm
Trinity - 2-4 Bulldozer Cores + DX11 GPU in 32 nm
Da gefällt mich nicht, dass diese erst für 2012 geplant sein sollen. H2/11 würde mir da deutlich besser gefallen...
Ähnliche Themen
- Antworten
- 17
- Aufrufe
- 2K
- Antworten
- 19
- Aufrufe
- 3K
- Antworten
- 0
- Aufrufe
- 791