App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Was kommt (nach den ersten Deneb (K10.5+)) fuer den Desktop bis zum Launch der BD(APUs)?
- Ersteller TNT
- Erstellt am
NOFX
Grand Admiral Special
- Mitglied seit
- 02.09.2002
- Beiträge
- 4.532
- Renomée
- 287
- Standort
- Brühl
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600 @Stock
- Mainboard
- ASUS B350M-A
- Kühlung
- Boxed-Kühler
- Speicher
- 2x 8 G.Skill RipJaws 4 rot DDR4-2800 DIMM
- Grafikprozessor
- PowerColor Radeon RX 480 Red Dragon 8GB
- Display
- LG 34UM-68 (FreeSync)
- SSD
- PowerColor Radeon RX 480 Red Dragon 8GB
- HDD
- 1x 1,5TB Seagate S-ATA
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- onBoard
- Gehäuse
- Thermaltake Versa H15
- Netzteil
- Cougar SX 460
- Betriebssystem
- Windows 10 Pro x64
- Webbrowser
- Google Chrome
Wenn man den Gesamtverbrauch eines Systems rechnet, so wird auch die Effizienz gesteigert, da eine Aufgabe schneller erledigt ist, der Gesamtverbrauch jedoch nicht über dem ohne Turbo-Modus (mit 4 aktiven) Kernen liegt.Verstehe jetzt nicht ganz wo das Problem ist Bobberon, er hat schon recht. Der Turbo Modus beim Nethalem ist keine Effizienz sondern eine Effektivität steigernde Maßnahme.
Eigentlich schon schade, dass AMD den Turbo-Modus nicht selber eingeführt hat. Selbst ein Phenom I hätte damit deutlich besser da gestanden, dem es ja vor allem (TDP-bedingt) an Takt gemangelt hat, obwohl er (bzw. einzelne Kerne) auch höher taktbar gewesen wäre.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Wir sprachen aber nur vom Prozessor. Das Gesamtsystem kennst du ja erstmal nicht und kann auf ganz unterschiedliche Art und Weise differieren. Und selbst dann kann die Effizienz trotzdem abnehmen.Wenn man den Gesamtverbrauch eines Systems rechnet, so wird auch die Effizienz gesteigert
Bobo_Oberon
Grand Admiral Special
- Mitglied seit
- 18.01.2007
- Beiträge
- 5.045
- Renomée
- 190
Quelle... 1.1 Overview
Intel® Turbo Boost technology is available only on
supported processor versions. With Intel® Turbo
Boost technology, the processor is capable of
maximizing core frequency while ensuring that it
does not exceed its electrical and thermal
specifications. This means workloads that are
naturally lower in power or lightly threaded may
take advantage of headroom in the form of
increased core frequency. ...
-> Übertaktung, wenn möglich bei 4 Kernen
-> Noch höhere Übertaktung, wenn möglich bei weniger als mit 4 Kernen (und wenn multiple Threads nicht gefragt sind).
Siehe auch: "Intel® Turbo Boost Technology Performance on demand".
Oder anders gesagt. Wenn die vielen Kerne ungenügend ausgenutzt werden, dann legt sich ein Teil davon schlafen (und konsumiert kaum noch überflüssigen Strom), während die verbliebenen Kerne um so höher takten.
Das klingt in meinen Ohren effizienzsteigernd, wenn nicht genutzte Kerne schlafen gelegt werden, dafür andere Kerne übertaktet werden, da die Einzelanwendung nur einen (hochgetakteten) Kern "gut" (-> "effizient") nutzen kann.
Im negativen Gegenbeispiel laufen 4 Kerne auf vollem Takt, wobei lediglich nur ein Kern tatsächlich genutzt wird.
MFG Bobo(2009)
Zuletzt bearbeitet:
..noch mal zurueck zur eigentlichen Frage in diesem Thread...
wenn man so das Netz durchstoeber liest man allerorts, dass der Launch der BE 965 kurz
bevor stuende.... aber leider liest man auch, dass es wohl auf eine TDP von 140 Watt
hinaus laufen koennte...aber dazu sind die Angaben widerspruechlich...
Das waere aber nun wieder ein Dingen, wenn AMD die 140 Watt TDP wahr macht...
und welchen Headroom gibt es dann noch fuer 2010?
Kann ein neues Stepping den Verbrauch wieder um ein oder zwei Stufen druecken?
wenn man so das Netz durchstoeber liest man allerorts, dass der Launch der BE 965 kurz
bevor stuende.... aber leider liest man auch, dass es wohl auf eine TDP von 140 Watt
hinaus laufen koennte...aber dazu sind die Angaben widerspruechlich...
Das waere aber nun wieder ein Dingen, wenn AMD die 140 Watt TDP wahr macht...
und welchen Headroom gibt es dann noch fuer 2010?
Kann ein neues Stepping den Verbrauch wieder um ein oder zwei Stufen druecken?
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Klar, mit 32nm locker drinKann ein neues Stepping den Verbrauch wieder um ein oder zwei Stufen druecken?

Im Ernst: Die schon 1000x angesprochenen HiK-MGs wären noch ein Kandidat.
Ansonsten seh ich da nicht viel Spielraum, der aktuelle Prozess ist schon recht gut gelungen, da ist eigentlich schon alles ausgereizt.
ciao
Alex
HelixUltra
Fleet Captain Special
- Mitglied seit
- 21.11.2008
- Beiträge
- 254
- Renomée
- 9
Angenommen, man würde die dicke zwischen den einzelnen transistorebenen erhöhen, dann würden die leckströme schon mal weniger zusätztliche tdp aufgrund von 'losschlagen' einzelner atome verursachen, ist aber aufwendiger und teurer zu bauen.
rkinet
Grand Admiral Special
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/AMD__45nm_Press_Q-A.pdfKlar, mit 32nm locker drin
Im Ernst: Die schon 1000x angesprochenen HiK-MGs wären noch ein Kandidat.
Ansonsten seh ich da nicht viel Spielraum, der aktuelle Prozess ist schon recht gut gelungen, da ist eigentlich schon alles ausgereizt.
und Roadmap: http://www.computerbase.de/bildstrecke/23406/4/
Mein TIP:
High-k/metal Gates: wohl (mobil) (Quad-) Champlain und Geneva (2010)
Ultra-low-k Dielectrics: möglich für Deneb (II - 2010 ? ) ) und ggf. Test per Propos (2009 - http://www.computerbase.de/news/hardware/prozessoren/amd/2009/april/amd_propus_rana_august/ )
Markus Everson
Grand Admiral Special
NOFX schrieb:Eigentlich schon schade, dass AMD den Turbo-Modus nicht selber eingeführt hat. Selbst ein Phenom I hätte damit deutlich besser da gestanden, dem es ja vor allem (TDP-bedingt) an Takt gemangelt hat, obwohl er (bzw. einzelne Kerne) auch höher taktbar gewesen wäre.
Zum xten Mal: Das bringt nur dann etwas wenn man die anderen Kerne runter fahren kann. Der i7 hat eine Powerplane pro Core, der P2 eine für alle Cores. Nicht genutzte Cores heizen fröhlich vor sich hin wenn sie unter Voller Spannung laufen.
Zu sehen sehr schön beim X3 und beim teilkastrierten X2.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
In dem Fall wäre wohl ein etwas effektiveres Powergating erstrebenswert.
Erst wenn man die "inaktiven" kerne richtig vom Strom trennen kann, kann man eigentlich vonn effizienz sprechen. Sonst könnte man sie theoretisch gleich einfach so weiterlaufen lassen.
Speziell im Mobilbereich ist es so wie ich es sehe, absolut essenziell das in den Griff zu kriegen.
Gerade wenn man an die Roadmap denkt, die für 2010 mobil - quadcores in 45nm ausweist.
Das kann eigentlich nur auf Propos - Basis geschehen. Und da wirds Zeit dass AMD endlich mal das Image des Stromverschwenders ablegt. Sonst wird das nie was mit dem Fuß fassen im Mobilbereich.
Selbst bei einem Dualcore ist es doof, wenn der eine Kern zwar pennt aber weiter heizt und Strom aus dem akku zieht. Aber wenn das dann später 2-3 Kerne tun, wirds brenzlig!
Die zusätzlichen Powerplanes sind IMHO nur für den Teillast-Bereich eine Entschuldigung, da wenn die Kerne unterschiedlich ausgelastet sind (aber dennoch was zu tun haben) eben nicht jeder mit der optimalen spannung angefahren werden kann, sondern der "fleißigste" - Kern die spannung für alle vorgibt... okay. Suboptimal aber aus Kostengründen akzeptbel. (Griffin hate ja schon eine Plane pro Kern, wenn ich mir das beim mobil-quad vorstelle, wird ein Champlain-Board so teuer wie eines für den i7)
Im absoluten IDLe-Zustand jedoch, ist das mit den Planes keine Entschuldigung! - entweder der Kern wird per Powergating sauber vom Strom getrennt, dann ists auch wurscht wie viel Spannung die anderen Kerne vorgeben, oder er wird eben nicht sauber getrennt und eben "nur" in einen tiefen sleepstate verbannt.
Das ist dann aber eine Frage der schaltungstechnischen Auslegung. Der i7 betreibt ja eine Menge Aufwand in Sachen Powermanagement. mit extra IC und dergleichen. So übertreiben muss AMD ja nicht, aber es kann auch nicht sein, dass Intel die einzigen sind, die es auf die Reihe kriegen, inaktive Kerne vernünftig stromlos zu bekommen.
Daher könnte das grade bei einem mobilQuad genau DAS Feature sein, welches ihm den nötigen Biss gegenüber einem SMT-dualcore o.ä. seitens Intel verleiht.
However, lassen wir uns überraschen. immerhin kriegen sie ja nun schon Denebs mit 3GHz und 95W gebacken, also ist wohl doch noch was drin im 45nm Prozess.
Erst wenn man die "inaktiven" kerne richtig vom Strom trennen kann, kann man eigentlich vonn effizienz sprechen. Sonst könnte man sie theoretisch gleich einfach so weiterlaufen lassen.
Speziell im Mobilbereich ist es so wie ich es sehe, absolut essenziell das in den Griff zu kriegen.
Gerade wenn man an die Roadmap denkt, die für 2010 mobil - quadcores in 45nm ausweist.
Das kann eigentlich nur auf Propos - Basis geschehen. Und da wirds Zeit dass AMD endlich mal das Image des Stromverschwenders ablegt. Sonst wird das nie was mit dem Fuß fassen im Mobilbereich.
Selbst bei einem Dualcore ist es doof, wenn der eine Kern zwar pennt aber weiter heizt und Strom aus dem akku zieht. Aber wenn das dann später 2-3 Kerne tun, wirds brenzlig!
Die zusätzlichen Powerplanes sind IMHO nur für den Teillast-Bereich eine Entschuldigung, da wenn die Kerne unterschiedlich ausgelastet sind (aber dennoch was zu tun haben) eben nicht jeder mit der optimalen spannung angefahren werden kann, sondern der "fleißigste" - Kern die spannung für alle vorgibt... okay. Suboptimal aber aus Kostengründen akzeptbel. (Griffin hate ja schon eine Plane pro Kern, wenn ich mir das beim mobil-quad vorstelle, wird ein Champlain-Board so teuer wie eines für den i7)
Im absoluten IDLe-Zustand jedoch, ist das mit den Planes keine Entschuldigung! - entweder der Kern wird per Powergating sauber vom Strom getrennt, dann ists auch wurscht wie viel Spannung die anderen Kerne vorgeben, oder er wird eben nicht sauber getrennt und eben "nur" in einen tiefen sleepstate verbannt.
Das ist dann aber eine Frage der schaltungstechnischen Auslegung. Der i7 betreibt ja eine Menge Aufwand in Sachen Powermanagement. mit extra IC und dergleichen. So übertreiben muss AMD ja nicht, aber es kann auch nicht sein, dass Intel die einzigen sind, die es auf die Reihe kriegen, inaktive Kerne vernünftig stromlos zu bekommen.
Daher könnte das grade bei einem mobilQuad genau DAS Feature sein, welches ihm den nötigen Biss gegenüber einem SMT-dualcore o.ä. seitens Intel verleiht.
However, lassen wir uns überraschen. immerhin kriegen sie ja nun schon Denebs mit 3GHz und 95W gebacken, also ist wohl doch noch was drin im 45nm Prozess.
NOFX
Grand Admiral Special
- Mitglied seit
- 02.09.2002
- Beiträge
- 4.532
- Renomée
- 287
- Standort
- Brühl
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Spinhenge
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600 @Stock
- Mainboard
- ASUS B350M-A
- Kühlung
- Boxed-Kühler
- Speicher
- 2x 8 G.Skill RipJaws 4 rot DDR4-2800 DIMM
- Grafikprozessor
- PowerColor Radeon RX 480 Red Dragon 8GB
- Display
- LG 34UM-68 (FreeSync)
- SSD
- PowerColor Radeon RX 480 Red Dragon 8GB
- HDD
- 1x 1,5TB Seagate S-ATA
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- onBoard
- Gehäuse
- Thermaltake Versa H15
- Netzteil
- Cougar SX 460
- Betriebssystem
- Windows 10 Pro x64
- Webbrowser
- Google Chrome
Also ich sehe hier ca. 20W mehr pro aktivem Kern (Takt liegt bei allen bei 2,8 bis 3,1GHz) bei gleicher Plattform (DDR2) bzw. 20W extra Verbrauch des 550 gegenüber dem 250, der keine deaktivierten Kerne mit sich rumschleppt:Zum xten Mal: Das bringt nur dann etwas wenn man die anderen Kerne runter fahren kann. Der i7 hat eine Powerplane pro Core, der P2 eine für alle Cores. Nicht genutzte Cores heizen fröhlich vor sich hin wenn sie unter Voller Spannung laufen.
Zu sehen sehr schön beim X3 und beim teilkastrierten X2.
20W extra TDP-Spielraum reichen (ohne Spannungserhöhung) durchaus aus, um einen Kern mit 400+ MHz höher zu takten als den Rest.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Ganz fair ist der Vergleich aber auch nicht, denn der Callisto muss ja noch den L3 durchfüttern, der Regor nicht.
Trotzdem sieht man schön, dass Callistos deaktivierte kerne immernoch schön mitsaufen an der Stromleitung.
Und das obwohl die "deaktiviert" sind, also nicht "mal eben" aufwachen können.
Interessant wäre es, wenn man einzelne Kerne per Software in einem Sleepstate festnageln könnte, um mal zu checken, wieviel TDP wirklich "gespart" wird, wenn man beim Deneb z.B. nur 2 der 4 Kerne beschäftigt und die anderen 2 ideln und zwar in tiefen schlafmodi. Denn das wäre ja der "turbomodus" - Fall.
Trotzdem sieht man schön, dass Callistos deaktivierte kerne immernoch schön mitsaufen an der Stromleitung.
Und das obwohl die "deaktiviert" sind, also nicht "mal eben" aufwachen können.
Interessant wäre es, wenn man einzelne Kerne per Software in einem Sleepstate festnageln könnte, um mal zu checken, wieviel TDP wirklich "gespart" wird, wenn man beim Deneb z.B. nur 2 der 4 Kerne beschäftigt und die anderen 2 ideln und zwar in tiefen schlafmodi. Denn das wäre ja der "turbomodus" - Fall.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nein. Hier bringst du verschiedene Sachen durcheinander. Kerne legen sich auch ohne Turbo Mode "schlafen". Effizienzsteigernd ist da erstmal gar nichts. Ganz im Gegenteil. Je weniger Leistung nicht genutzte Kerne benötigen, umso schlimmer wird es eigentlich für den Turbo Mode.Oder anders gesagt. Wenn die vielen Kerne ungenügend ausgenutzt werden, dann legt sich ein Teil davon schlafen (und konsumiert kaum noch überflüssigen Strom), während die verbliebenen Kerne um so höher takten.
Das klingt in meinen Ohren effizienzsteigernd, wenn nicht genutzte Kerne schlafen gelegt werden, dafür andere Kerne übertaktet werden, da die Einzelanwendung nur einen (hochgetakteten) Kern "gut" (-> "effizient") nutzen kann.
Kleines Rechenbeispiel:
Uncore -> 10 W
Kerne 2-4 idlen bei vollem Takt (2 GHz) -> 10 W
Kern 1 wird ausgelastet bei vollem Takt (2 GHz) -> 10 W
Kern 1 geht in Turbo Mode -> 2 GHz -> 3 GHz -> Vcore 1V -> Vcore 1,2V -> 22 W
Performance Zuwachs -> 40%
Leistungsaufnahme 30 W -> 42 W -> +40%
Effizienz gerade noch so im Rahmen
Kerne 2-4 fahren nun herunter -> 2 GHz -> 1 GHz -> Vcore 1V -> Vcore 0,8V -> 3 W
Leistungsaufnahme 23 W -> 35 W -> +52%
Effizienz verringert sich um 8%
Turbo Mode Worst-Case
Kerne 2-4 schalten sich komplett ab -> 0W
Leistungsaufnahme 20 W -> 32 W -> +60%
Effizienz verringert sich um 12,5%
Ist natürlich kein repräsentatives Beispiel und die Werte aus der Luft gegriffen. Du verstehst aber hoffentlich, worauf ich hinaus will.
Wie ich schon sagte, Intels Turbo Mode ist ein "no brainer" und keine wirklich smarte Lösung. Anstatt einen Teil der Transistoren hochzutakten und darauf zu hoffen, dass die jeweilige Anwendung gut auf Takt reagiert, in der Gewissheit, dass die Leistungsaufnahme des Kerns überproportional hochgeht, wäre es ein cleverer Designansatz, die Dämchen drehenden Transistoren dazu zu nutzen, die Single-Threaded Performance zu steigern. Ich hoffe ja, AMD wird mit Bulldozer diesbezüglich einiges umsetzen. Die Aufbereitungen von Dresdenboy sehen schon mal sehr interessant aus. Mal schauen, ob er das Angebot von John Fruehe wahrnimmt und ihm eventuell einige konkretere Informationen zur nächsten Architektur entlocken kann.
")
Wo sieht man was genau?Trotzdem sieht man schön, dass Callistos deaktivierte kerne immernoch schön mitsaufen an der Stromleitung.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
auf NoFX' Grafik mit den Balkendiagrammen.
die 20W die der 550 mehr braucht als der 250, werden wohl kaum dem L3 cache alleine geschuldet sein...
144 zu 165W ist immerhin eine Diff von 21W. Wenn das der L3 alleine wegfrisst ,sollten sie den lieber Einstampfen und dafür 2 weitere kerne aufs DIE bringen, da wären die 20W besser aufgehoben.
die 20W die der 550 mehr braucht als der 250, werden wohl kaum dem L3 cache alleine geschuldet sein...
144 zu 165W ist immerhin eine Diff von 21W. Wenn das der L3 alleine wegfrisst ,sollten sie den lieber Einstampfen und dafür 2 weitere kerne aufs DIE bringen, da wären die 20W besser aufgehoben.
hot
Admiral Special
- Mitglied seit
- 21.09.2002
- Beiträge
- 1.187
- Renomée
- 15
- Details zu meinem Desktop
- Prozessor
- AMD Phenom 9500
- Mainboard
- Asrock AOD790GX/128
- Kühlung
- Scythe Mugen
- Speicher
- 2x Kingston DDR2 1066 CL7 1,9V
- Grafikprozessor
- Leadtek Geforce 260 Extreme+
- Display
- Samsung 2432BW
- HDD
- Samsung HD403LJ, Samung SP1614C
- Optisches Laufwerk
- LG HL55B
- Soundkarte
- Realtek ALC890
- Gehäuse
- Zirco AX
- Netzteil
- Coba Nitrox 600W Rev.2
- Betriebssystem
- Vista x64 HP
- Webbrowser
- Firefox
Turbo kann garnicht effizienzsteigernd sein. Ganz desaströs wirds, wenn auchnoch die Spannung angehoben wird, im mehr Takt zu erreichen. Zudem hat man das Problem des Windows-Schedulars, der ja nicht damit klarkommt, dass die Kerne unterschiedlich getaktet sind. Das macht die Performancevorteile des Turbo sofort wieder zunichte, weil man dann x% Overhead erzeugt. Ich finde den Turbomode alles andere als toll und halte ihn für reine Benchmarkhäscherei, weil die meisten Apps, die die Performance wirklich bräuchten, mittlerweile eh mutlithreaded sind. Es ist eher die Frage, wie viele Threads sinnvoll sind und das pendelt sich über 2010 hinweg absehbar auf 3-4 Threads im Durchschnitt ein. Einige Codierer nutzen halt mehr, aber das liegt in der Natur der Sache - da halte ich es aber auch nur für eine Zeitfrage, bis diese Dinger auf OpenCL-Basis laufen und dann eine CPU überhaupt kein Land mehr sieht. Intel greift mit SMT+Turbo eigentlich nur in die Trickkiste, um die Kerngrenzen nicht aufweichen zu müssen.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Die Scheduler der Betriebssysteme sind ohnehin ein anderes Problem.
Es fragt sich eben, wenn man z.B. zur zeit 4 Threads zur Ausführung hat, legt man da je einen auf einen kern, oder packt man alle 4 auf den selben kern und lässt die anderen idlen.
was ist besser?
Zumal der Scheduler ja garnicht genug über den auszuführenden Thread wissen kann um einschätzen zu können ob er sehr aufwändig zu berechnen ist, oder eher weniger. Ob der schnell fertig sein wird oder nicht etc.
Turbomodus ist da so ne Sache... interessante wäre es vielleicht die kerne allgemein untershciedlich zu takten... also z.b. 2 kerne mit volldampf und zwei weitere nur als "hilfskerne", die langsamer laufen und nur dazu da sind, den Hauptkernen Arbeit abzunehmen wenn diese 70 oder 80% auslastung erreicht haben o.ä.
Ob das allerdings dann Software-Scheduler mäßig in dne Griff zu kriegen wäre... naja
Eigentlich müsste man das alles der HW überlassen können. Also das BS, sieht nur 1 CPU, und nagelt die mit aufgaben zu, und der Prozessor teilt sozusagen "intern" das ganze auf einzelne kerne auf. Der Prozzi kann nämlich seine eigene Auslastung ganz anders im Blickfeld behalten. Und welcher Kern grade mit welcher drehzahl schuftet und ggf. luft für weitere aufgaben hat...
Frühes aufteilen auf mehrere kerne hat den vorteil der "responsiveness", allerdings ist das bei der energieeffizienz nicht zwangsläufig so... dass es immer klug ist mehrere kerne zu beschäftigen, statt eher einen schaffen zu lassen und die anderne zu idlen.
Es stellt sich also die Frage (am Beispiel Phenom 2), sind 2 kerne auf dem zweit niedrigsten Pstate (beim 940er sind das glaubich 1,6Ghz) besser als ein Kern auf volldampf bzw. auf 2,4Ghz?
Es fragt sich eben, wenn man z.B. zur zeit 4 Threads zur Ausführung hat, legt man da je einen auf einen kern, oder packt man alle 4 auf den selben kern und lässt die anderen idlen.
was ist besser?
Zumal der Scheduler ja garnicht genug über den auszuführenden Thread wissen kann um einschätzen zu können ob er sehr aufwändig zu berechnen ist, oder eher weniger. Ob der schnell fertig sein wird oder nicht etc.
Turbomodus ist da so ne Sache... interessante wäre es vielleicht die kerne allgemein untershciedlich zu takten... also z.b. 2 kerne mit volldampf und zwei weitere nur als "hilfskerne", die langsamer laufen und nur dazu da sind, den Hauptkernen Arbeit abzunehmen wenn diese 70 oder 80% auslastung erreicht haben o.ä.
Ob das allerdings dann Software-Scheduler mäßig in dne Griff zu kriegen wäre... naja
Eigentlich müsste man das alles der HW überlassen können. Also das BS, sieht nur 1 CPU, und nagelt die mit aufgaben zu, und der Prozessor teilt sozusagen "intern" das ganze auf einzelne kerne auf. Der Prozzi kann nämlich seine eigene Auslastung ganz anders im Blickfeld behalten. Und welcher Kern grade mit welcher drehzahl schuftet und ggf. luft für weitere aufgaben hat...
Frühes aufteilen auf mehrere kerne hat den vorteil der "responsiveness", allerdings ist das bei der energieeffizienz nicht zwangsläufig so... dass es immer klug ist mehrere kerne zu beschäftigen, statt eher einen schaffen zu lassen und die anderne zu idlen.
Es stellt sich also die Frage (am Beispiel Phenom 2), sind 2 kerne auf dem zweit niedrigsten Pstate (beim 940er sind das glaubich 1,6Ghz) besser als ein Kern auf volldampf bzw. auf 2,4Ghz?
Dresdenboy
Redaktion
☆☆☆☆☆☆
Ich habe dazu nun auch was in den Blog geschrieben, dazu noch auf den Thread hier verlinkt u. dich gleich mit erwähnt.Hahaha .. geniales Zeug ... erinnert etwas an Transmetas CodeMorphing, auch wenn da "nur" von "x86-neu" auf µOp umgesetzt wird.
Hier noch der Link, für die Leute mit Registrierung:
http://www.freepatentsonline.com/20090158015.pdf
Am besten ist der Abschnitt im Text:
Wer wohl da gemeint sein könnte
Ich sehs schon kommen, Intel präsentiert auf einer IDC AVX3 fürs folgende Jahr und AMD hat ne Woche später ein KGC Update fertig
Der "non-native" Modus ist auch interessant ... da wird nicht CPU benutzt, sondern "etwas" anderes. Verdächtiger No.1 ist da natürlich eine GPU, aber die wird später eh noch extra behandelt. Somit meinen die in dem Fall eher eine sehr enge Torrenza Integration ... anscheinend lebt das noch

")
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Ich habe dazu nun auch was in den Blog geschrieben, dazu noch auf den Thread hier verlinkt u. dich gleich mit erwähnt.
Danke für die Ehre
Damit bekommt P3D jetzt auch ein haufen Klicks von Leuten, die kein Deutsch können

Noch ne Frage, weil ich eh schon hier schreibe, was meinst Du bei aceshardware mit "CMT" ?
Chip oder Cluster Multithreading ?
ciao
Alex
Dresdenboy
Redaktion
☆☆☆☆☆☆
Kein Problem mit den KlicksDanke für die Ehre
Damit bekommt P3D jetzt auch ein haufen Klicks von Leuten, die kein Deutsch können
Noch ne Frage, weil ich eh schon hier schreibe, was meinst Du bei aceshardware mit "CMT" ?
Chip oder Cluster Multithreading ?
Es gibt ja die masch. Übersetzer für jene, die hier ganz besondere Geheimnisse vermuten CMT steht in einigen Papers für Clustered Multithreading. Ich habe das auch schon in dem Eintrag mit der alten AMD-Folie angepasst.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Jo deswegen fragte ich nach, landläufig ist CMT nach wievor mit Chip MT belegt. Vom neuen Cluster MT weiß ausser Dir, mir und Lesern hier im Thread wohl kaum jemand.CMT steht in einigen Papers für Clustered Multithreading. Ich habe das auch schon in dem Eintrag mit der alten AMD-Folie angepasst.
In Zukunft geh ich mal davon aus, dass Du immer Cluster meinst, falls nicht bitte Chip ausschreiben
Wobei dann sowieso die Frage ist, wann die Chips auf nem Die Geschichte sind, und es nur noch Cluster gibt. Mein erster Gedanke, als ich die 4+4 Dekoder sah, war, dass das 4 Dekodergruppen für 4 Kerne / 8 Cluster sind. Es steht ja nicht dabei, wieviel Decoder das wirklich sind. Da steht nur "Micro Code" und "Fath Path". Ein so ein "Fast Path" könnte ja aus 4 FastPath Dekodern bestehen.
Aber naja, das passt dann nicht zum Rest des Schemas, z.B: müsste der Dispatcher viel mehr Ports haben. Naja später dann ... in 22nm ^^.
Apropos Dispatcher ... hab mich bei dem auch schon gefragt, wie das mit 2 Ports und 2 INT Clustern plus FPU aufgehen soll. Einzige Erklärung ist, dass das 4 (2x2) INT Ports und 4 FPU Ports werden. Das oft benützte Schema mit der FPU zw. den beiden INT Clustern wäre damit dann aber irreführend ... aber naja sowas wird bei Patenten wohl extra versuchen werden
Natürlich könnten auch die Portzeichnung falsch sein, glaube ich aber eher nicht, eine Hälfte INT und eine Hälfte FPU macht mehr Sinn, schon allein für die 1x4 Ausführung. Ich sähe auch keine Vorteil einer 2x Int - FPU - 2x Int Aufteilung. Siehst Du vielleicht was ? Vielleicht fürs Forwarding network ?
Wie auch immer, falls Du ein eigenes Schema zeichnest, dann mach das vielleicht gleich "richtig"
ciao
Alex
Dresdenboy
Redaktion
☆☆☆☆☆☆
Chip oder Cluster MT nimmt sich praktisch nicht viel, es gibt in manchen Papers Chip-MT-Architekturen, welche der möglichen BD-Architektur sehr ähneln.Jo deswegen fragte ich nach, landläufig ist CMT nach wievor mit Chip MT belegt. Vom neuen Cluster MT weiß ausser Dir, mir und Lesern hier im Thread wohl kaum jemand.
In Zukunft geh ich mal davon aus, dass Du immer Cluster meinst, falls nicht bitte Chip ausschreiben
Wobei dann sowieso die Frage ist, wann die Chips auf nem Die Geschichte sind, und es nur noch Cluster gibt. Mein erster Gedanke, als ich die 4+4 Dekoder sah, war, dass das 4 Dekodergruppen für 4 Kerne / 8 Cluster sind. Es steht ja nicht dabei, wieviel Decoder das wirklich sind. Da steht nur "Micro Code" und "Fath Path". Ein so ein "Fast Path" könnte ja aus 4 FastPath Dekodern bestehen.
Aber naja, das passt dann nicht zum Rest des Schemas, z.B: müsste der Dispatcher viel mehr Ports haben. Naja später dann ... in 22nm ^^.
Apropos Dispatcher ... hab mich bei dem auch schon gefragt, wie das mit 2 Ports und 2 INT Clustern plus FPU aufgehen soll. Einzige Erklärung ist, dass das 4 (2x2) INT Ports und 4 FPU Ports werden. Das oft benützte Schema mit der FPU zw. den beiden INT Clustern wäre damit dann aber irreführend ... aber naja sowas wird bei Patenten wohl extra versuchen werden
Natürlich könnten auch die Portzeichnung falsch sein, glaube ich aber eher nicht, eine Hälfte INT und eine Hälfte FPU macht mehr Sinn, schon allein für die 1x4 Ausführung. Ich sähe auch keine Vorteil einer 2x Int - FPU - 2x Int Aufteilung. Siehst Du vielleicht was ? Vielleicht fürs Forwarding network ?
Wie auch immer, falls Du ein eigenes Schema zeichnest, dann mach das vielleicht gleich "richtig"
ciao
Alex
Die Fastpath-Decoder scheinen x86-Befehle in bis zu zwei "instruction operations" übersetzen zu können. Das wäre ein indirekter Hinweis auf die MacroOps. Das wäre dann wohl ähnlich wie bei K7-K10. Es ist dann auch noch die Sprache von Dispatch Groups, wo die Befehle zusammengefasst werden.
Aber irgendwo musst du die Ports anders gesehen haben (da war der Wunsch wohl Vater des Gedankens
), denn in den Decoder-Patenten gibt es 4 solche Blöcke mit Fast Path/µC und diese können je 2 Instructions ausgeben (also max. 4 Fast + 4 µC). Das alles landet dann im Dispatch Buffer (max. 2x4 inst-op-Paare bzw. 2x4 MacroOps für 2 Threads). Von dem Buffer können max 2x4 MacroOps in die Einheiten wandern: entweder eine Int-Gruppe an einen Int-Cluster oder an die FPU. Es gibt also 3 Ziele aber nur max. 2 Pakete. Eine Einheit geht dann leer aus. Das dürfte aber kein Problem sein, da die Int Cluster max. nur 2 MacroOps pro Takt bearbeiten können sollten. Zur FPU wissen wir ja weder, wieviel sie verarbeiten kann, noch wie die Befehle kodiert sind. Und da die Cluster das Retirement selbst erledigen, wäre das pro Thread auf 2 x86-Befehle pro Takt limitiert. Und das können nur 2xInt oder 2xFPU sein (je mit 2 AGU max.).Kennst du schon den Intel AVX-CPU-Simulator hier:
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
Das wurde im ixbt-Forum diskutiert.
Among other things the modeled processor has:
• One divide unit attached to port 0.
• Two 128-bit load ports (2 and 3), each with an Address Generation Unit (AGU) attached to it.
• One 128-bit store port (port 4).
• First level cache latencies in a range between 5 and 8 cycles.
Tja... Wahrheit oder Lüge... *g*
Dresdenboy
Redaktion
☆☆☆☆☆☆
John Fruehe schrieb auf amdzone, dass Bulldozer kein SMT haben wird, sondern 1 Thread pro Core und 16 reale Cores besser sind als 8 reale u. 8 fake Cores. Gut, nennen wir die Integer Cluster also "Core" mit shared Front End, L2 u. FPU. Naja, bleibt ja doch noch Einiges an dedizierten Einheiten übrig *g*
Die shared FPU ist ja eh schon uralt u. war auch als Einheit zwischen Cores gedacht..
Hab ich schon darüber spekuliert, dass die IntegerCluster Cores dank ihrer Simplifizierung (evtl. mit vereinfachten ALUs usw.) Kandidaten für höhere Takte wären?
Außerdem ist die Architektur, die Hans de Vries auf http://www.chip-architect.com/ schonmal als Sledgehammer vorstellte (und die wir hier auch schon bespekuliert haben), recht ähnlich zu der aktuell vorliegenden... Da stand auch noch etwas Interessantes: Die 2 Cores arbeiten mit 1/2 versetztem Takt, so dass noch innerhalb eines halben Taktes ein Register-Update von Core 0 zu Core 1 stattfinden kann u. damit mit einer Latenz von 0 im 2. Core verfügbar ist.
Dann hatte ich mal zu dem Performancegraphen für die kommenden CPUs bis Interlagos noch das festgestellt:
Gegenüber Magny Cours skaliert die Performance zum Interlagos bei Integer gar nicht (!) pro Core (+/- die dargestellte Varianz), bei FP dagegen wächst sie um 25% pro Core (wieder +/- Varianz).
Gut, nennen wir die Integer Cluster also "Core" mit shared Front End, L2 u. FPU. Naja, bleibt ja doch noch Einiges an dedizierten Einheiten übrig *g*Die shared FPU ist ja eh schon uralt u. war auch als Einheit zwischen Cores gedacht..
Hab ich schon darüber spekuliert, dass die Integer
Außerdem ist die Architektur, die Hans de Vries auf http://www.chip-architect.com/ schonmal als Sledgehammer vorstellte (und die wir hier auch schon bespekuliert haben), recht ähnlich zu der aktuell vorliegenden... Da stand auch noch etwas Interessantes: Die 2 Cores arbeiten mit 1/2 versetztem Takt, so dass noch innerhalb eines halben Taktes ein Register-Update von Core 0 zu Core 1 stattfinden kann u. damit mit einer Latenz von 0 im 2. Core verfügbar ist.
Dann hatte ich mal zu dem Performancegraphen für die kommenden CPUs bis Interlagos noch das festgestellt:
Gegenüber Magny Cours skaliert die Performance zum Interlagos bei Integer gar nicht (!) pro Core (+/- die dargestellte Varianz), bei FP dagegen wächst sie um 25% pro Core (wieder +/- Varianz).
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Hmm ok, dachte ein Kern wär ein Kern mit allem drum und dran, während bei nem Cluster was fehlt. Bei AMD im Falle eines INT Clusters, würde z.B. Front und Back End fehlen.Chip oder Cluster MT nimmt sich praktisch nicht viel, es gibt in manchen Papers Chip-MT-Architekturen, welche der möglichen BD-Architektur sehr ähneln.
Oder andersherum gesagt, Front und Back End werden gemeinsam genützt.
Aber ok ... man könnte wohl auch sagen, dass die komplette NB gemeinsam von den aktuellen "Kernen" benützt wird, und das somit auch schon Cluster sind ... merken wir uns also mal, dass es egal ist
Jo seh ich auch so.Die Fastpath-Decoder scheinen x86-Befehle in bis zu zwei "instruction operations" übersetzen zu können. Das wäre ein indirekter Hinweis auf die MacroOps. Das wäre dann wohl ähnlich wie bei K7-K10.
Oder 8 Macroops von den FastP und 0 vom µCode. Das sollte auch funktionieren, oder ?Aber irgendwo musst du die Ports anders gesehen haben (da war der Wunsch wohl Vater des Gedankens
Soweit so gutDas alles landet dann im Dispatch Buffer (max. 2x4 inst-op-Paare bzw. 2x4 MacroOps für 2 Threads). Von dem Buffer können max 2x4 MacroOps in die Einheiten wandern: entweder eine Int-Gruppe an einen Int-Cluster oder an die FPU.
Jein .. der 1x4issue Betrieb sollte ja auch noch möglich seinEs gibt also 3 Ziele aber nur max. 2 Pakete.
Was ich meinte ist das Bildchen hier:
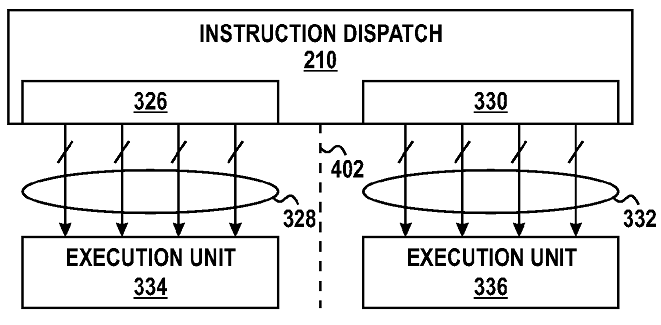
Ein Execution Unit wird im Text als FPU beschrieben, d.h. die beiden andren INT Cluster hängen an einem Port. Wenn die 4 Linien stimmen wäre das auch kein Problem, sind ja sicherlich 4 INT ALUs, aber das andere Core Bild aus dem Patent PDFs wäre dann halt falsch.
Ne kannte ich noch nicht, aber das Ding wird sicherlich keine Sandy Bridge Emulator sein, allein schon wegen den 128bit Einheiten, Sandy soll laut Intel Entwickler Aussage voll 256bit sein.Kennst du schon den Intel AVX-CPU-Simulator hier:
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
Das wurde im ixbt-Forum diskutiert.
Tja... Wahrheit oder Lüge... *g*
Jo darüber sind wir uns schon länger einigJohn Fruehe schrieb auf amdzone, dass Bulldozer kein SMT haben wird, sondern 1 Thread pro Core und 16 reale Cores besser sind als 8 reale u. 8 fake Cores.
Wie meinst Du das "zwischen" jetzt ? Lokal, positionsmäßig, oder dass sich halt 2 INT Cluster eine FPU teilen ?Die shared FPU ist ja eh schon uralt u. war auch als Einheit zwischen Cores gedacht..
Hmm nö, aber wo siehst Du eine Vereinfachung ?Hab ich schon darüber spekuliert, dass die IntegerClusterCores dank ihrer Simplifizierung (evtl. mit vereinfachten ALUs usw.) Kandidaten für höhere Takte wären?
Dass es eine Pipline pro Cluster weniger gibt ?
Jo das ist ganz nett ... hatten wir darüber nicht schon mal geredet ?Außerdem ist die Architektur, die Hans de Vries auf http://www.chip-architect.com/ schonmal als Sledgehammer vorstellte (und die wir hier auch schon bespekuliert haben), recht ähnlich zu der aktuell vorliegenden... Da stand auch noch etwas Interessantes: Die 2 Cores arbeiten mit 1/2 versetztem Takt, so dass noch innerhalb eines halben Taktes ein Register-Update von Core 0 zu Core 1 stattfinden kann u. damit mit einer Latenz von 0 im 2. Core verfügbar ist.
Das hatten wir auf alle Fälle schon mal, da gabs auch in nem andren Forum das Bildchen mit eingezeichneten % Bildchen.Dann hatte ich mal zu dem Performancegraphen für die kommenden CPUs bis Interlagos noch das festgestellt:
Gegenüber Magny Cours skaliert die Performance zum Interlagos bei Integer gar nicht (!) pro Core (+/- die dargestellte Varianz), bei FP dagegen wächst sie um 25% pro Core (wieder +/- Varianz).
Wundere mich seit damals, was das 0% Wachstum soll... Gründe gibts nicht viel, nur ein geringerer Takt, oder aber AMD rechnet den 2. INT Cluster nicht mit, da sie den beim Interlagos in den Security Modus schalten.
Naja wie auch immer ... das Bild stammt noch aus SSE5 Zeiten, glaube kaum, dass da z.B. die 256bit AVX INT Befehle mit einbezogen wird. Abgesehen davon wird die Folie nur eine Darstellung davon sein, was man mind. erreichen will..
ciao
Alex
Zuletzt bearbeitet:
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
@Spielraum für höheren Takt
Kürzlich hat Andy von Bechtolsheim vorgerechnet, wie die Rechenleistung von Großrechnern in einer Dekade um drei Größenordnungen wachsen kann.
In seinem theoretischen Design wurde an allen Ecken und Enden vergrößert, nur am Takt nicht. Er ging davon aus, dass in einer Dekade der Takt der einzelnen Cores nicht oberhalb von 4GHz liegen wird.
Da ich davon ausgehe, dass er weiß, wovon er redet, nehme ich zur Kenntnis, dass es in typischen Core-Designs offenbar eine Taktgrenze gibt, ab der es ineffizient ist, weiter zu erhöhen.
Auffällig ist auch, dass schon seit dem Pentium IV Gau der Takt der meisten CPUs nicht über 3-4GHz hinausgeht. (Ausnahmen von IBM bestätigen die Regel.)
MfG
Kürzlich hat Andy von Bechtolsheim vorgerechnet, wie die Rechenleistung von Großrechnern in einer Dekade um drei Größenordnungen wachsen kann.
In seinem theoretischen Design wurde an allen Ecken und Enden vergrößert, nur am Takt nicht. Er ging davon aus, dass in einer Dekade der Takt der einzelnen Cores nicht oberhalb von 4GHz liegen wird.
Da ich davon ausgehe, dass er weiß, wovon er redet, nehme ich zur Kenntnis, dass es in typischen Core-Designs offenbar eine Taktgrenze gibt, ab der es ineffizient ist, weiter zu erhöhen.
Auffällig ist auch, dass schon seit dem Pentium IV Gau der Takt der meisten CPUs nicht über 3-4GHz hinausgeht. (Ausnahmen von IBM bestätigen die Regel.)
MfG
Markus Everson
Grand Admiral Special
Da ich davon ausgehe, dass er weiß, wovon er redet, nehme ich zur Kenntnis, dass es in typischen Core-Designs offenbar eine Taktgrenze gibt, ab der es ineffizient ist, weiter zu erhöhen.
Warum spekulieren wenn doch (allem vernehmen nach) eine ganze Menge P2-Systeme auf 5 GHz stabil laufen?
Wäre mal Zeit eine Meßreihe mit einem derartigen System von 2,0 bis 5,0 GHz in....sagen wir mal 500 Mhz Schritten...zu ermitteln. Und zwar mit mehr als ein paar synthetischen Tests.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Andy von Bechtolsheim war doch mitbegründer von SUN wenn mich nicht alles täuscht.
Der hat durchaus KnowHow, allerdings weniger im x86-Bereich.
Nicht alle "Tricks" lassen sich 1zu1 übertragen.
Als Beispiel empfehle ich die schon des öfteren hier verlinkte und zitierte Lektüre von A.Binstein bwzüglich der Komplexität der Dekodierung von x86-Instruktionen.
http://abinstein.blogspot.com/2007/06/decoding-x86-from-p6-to-core-2-part-3.html
Wenn man also "mal eben" alles verdoppeln könnte und dafür dann ebensoviel bekommen würde wie bei taktverdoppelung, hätten das die Ingineure bei Intel und AMD bestimmt auch schon gemerkt.
(ohne nun zu wissen was von Bechtolsheim nun konkret geschrieben hat)
Also ganz "trivial" ist die Problematik sicherlich auch nicht.
Ich behaupte das was der höheren Taktung im Wesentlichen im Weg steht ist der Stromverbrauch und das Problem der immer höheren Leckströme bei kleineren Strukturen.
Nich umsosnt betreiben alle großen Prozessorhersteller momentan die Multiplizierung in Form mehrerer Kerne, statt einfach einzelne Kerne "doppelt so breit" zu machen.
@Markus Everson
Ich hoffe du meinst Ph2 - Systeme. Ein Pentium 2 auf 5GHZ wäre wirklich mal was neues
grüßle
ich
Der hat durchaus KnowHow, allerdings weniger im x86-Bereich.
Nicht alle "Tricks" lassen sich 1zu1 übertragen.
Als Beispiel empfehle ich die schon des öfteren hier verlinkte und zitierte Lektüre von A.Binstein bwzüglich der Komplexität der Dekodierung von x86-Instruktionen.
http://abinstein.blogspot.com/2007/06/decoding-x86-from-p6-to-core-2-part-3.html
Wenn man also "mal eben" alles verdoppeln könnte und dafür dann ebensoviel bekommen würde wie bei taktverdoppelung, hätten das die Ingineure bei Intel und AMD bestimmt auch schon gemerkt.
(ohne nun zu wissen was von Bechtolsheim nun konkret geschrieben hat)
Also ganz "trivial" ist die Problematik sicherlich auch nicht.
Ich behaupte das was der höheren Taktung im Wesentlichen im Weg steht ist der Stromverbrauch und das Problem der immer höheren Leckströme bei kleineren Strukturen.
Nich umsosnt betreiben alle großen Prozessorhersteller momentan die Multiplizierung in Form mehrerer Kerne, statt einfach einzelne Kerne "doppelt so breit" zu machen.
@Markus Everson
Ich hoffe du meinst Ph2 - Systeme. Ein Pentium 2 auf 5GHZ wäre wirklich mal was neues
grüßle
ich
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 933
- Antworten
- 80
- Aufrufe
- 15K
- Antworten
- 2
- Aufrufe
- 3K
- Antworten
- 764
- Aufrufe
- 101K
- Antworten
- 8
- Aufrufe
- 2K