App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD RDNA 4 - 144CU, 48GB VRAM, 3nm + 4nm
- Ersteller vinacis_vivids
- Erstellt am
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
Gerüchteküche zu RDNA4 uArch.

 www.notebookcheck.com
www.notebookcheck.com
Navi41 XTX
RX 8900XTX
144CU - 9216SP (18432 fp32 ALU)
bis zu 48GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
50-60% Plus bei Perf/Watt ggü. N31
Navi42 XT
RX 8800XT
96CU - 6144SP
24GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
Navi43 XT
RX 8700XT
48CU - 3072SP
12GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
3nm ist extrem teuer wenn AMD die Kapazität u.a. mit Apple und Nvidia teilen muss.
Weiter soll das Konzept 1xGCD + n X MCD beibehalten werden. Mir wäre es lieber AMD schenkt dem Consumer-Chips auch die GCD + GCD + MCD Technik bie bei CDNA3. Damit wäre ein doppelter 300mm^2 GCD von insgesamt 600mm^2 "günstig" machbar. Mit den MCDs dran werden das ~ 825mm^2 Chip Größe machbar.
Leider ist die Wahrscheinlichkeit sehr gering so ein Monster zu bekommen mit 48GB VRAM.
VG v_v
Gerücht: AMD Radeon RX 8000 erhält RDNA 4 GPUs mit bis zu 60% besserer Leistung pro Watt und 144 CUs
Die AMD Radeon RX 7900 XT und die Radeon RX 7900 XTX sind gerade erst auf den Markt gekommen, und schon gibt es erste Gerüchte zu Radeon RX 8000. Demnach entwickelt AMD eine komplett neue GPU-Architektur, die eine bis zu 60 Prozent bessere Leistung pro Watt als RDNA 3 erreicht.
Navi41 XTX
RX 8900XTX
144CU - 9216SP (18432 fp32 ALU)
bis zu 48GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
50-60% Plus bei Perf/Watt ggü. N31
Navi42 XT
RX 8800XT
96CU - 6144SP
24GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
Navi43 XT
RX 8700XT
48CU - 3072SP
12GB VRAM
bis zu 3,5Ghz GPU-Takt
TSMC 3nm / 4nm
3nm ist extrem teuer wenn AMD die Kapazität u.a. mit Apple und Nvidia teilen muss.
Weiter soll das Konzept 1xGCD + n X MCD beibehalten werden. Mir wäre es lieber AMD schenkt dem Consumer-Chips auch die GCD + GCD + MCD Technik bie bei CDNA3. Damit wäre ein doppelter 300mm^2 GCD von insgesamt 600mm^2 "günstig" machbar. Mit den MCDs dran werden das ~ 825mm^2 Chip Größe machbar.
Leider ist die Wahrscheinlichkeit sehr gering so ein Monster zu bekommen mit 48GB VRAM.
VG v_v
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Compute Berechnungen wie bei CDNA sind ja nochmal etwas anderes als die bisherige Form der Grafikberechnung und ein Chiplet Design dort einfacher umsetzbar.
Die Chiplet GPUs an und für sich haben wir ja bereits mit RDNA3 gesehen, auch wenn da "nur" die Speichercontroller ausgelagert und der Infinity Cache aufgeteilt wurde. Das aufteilen der Renderpipeline der Grafikberechnung dürfte deutlich schwieriger sein aber dafür ging ja auch schon eine News zu einem Patent für ein mehrteiliges Sheduler Design durch die Presse.

 www.pcgameshardware.de
www.pcgameshardware.de

 www.computerbase.de
www.computerbase.de
Die Chiplet GPUs an und für sich haben wir ja bereits mit RDNA3 gesehen, auch wenn da "nur" die Speichercontroller ausgelagert und der Infinity Cache aufgeteilt wurde. Das aufteilen der Renderpipeline der Grafikberechnung dürfte deutlich schwieriger sein aber dafür ging ja auch schon eine News zu einem Patent für ein mehrteiliges Sheduler Design durch die Presse.
Grafikkarten im Chiplet-Design: Patent von AMD aufgetaucht
Einem Patent nach plant AMD, einen schon durch Ryzen-3000- und 5000-Prozessoren bekannten Chiplet-Aufbau für Grafikkarten zu verwenden.
AMDs Patentantrag zur besseren GPU-Chiplet-Auslastung
AMD hat einen Patentantrag über die Aufteilung der Rendering-Last auf mehrere GPU-Chiplets veröffentlicht, der Two-Level-Binning beschreibt.
www.computerbase.de
Liest sich für mich wie rein ausgedachte Spezifikationen. Die Quelle (ein YouTube Kanal) ist ja auch noch extrem unglaubwürdig.
Manches davon kann natürlich zufällig zutreffen es lohnt sich aber kaum darüber zu spekulieren.
Die Patente von AMD sind da schon interessanter. Das Problem von GPU chiplets ist dabei aber nicht unbedingt, das man Aufgaben nicht auf mehrere Chips verteilen könnte, sondern dass häufig interconnects mit extrem hohen Datendurchsatz nötig wären. Dank Si-interposer bekommt man da gerade so ein paar TB/s für die MCDs bei RDNA3 zusammen. Mal als doofes Beispiel: Man teilt Frontend und Backend in 2 chiplets auf. Wenn man jetzt 20k shader mit 3Ghz mit jeweils einer fp32 variablen versorgen möchte sprechen wir schon von 240 TB/s.
Mehr Durchsatz wäre eventuell mit TSVs machbar also dann mit Chip stacking. Bei den hohen TDPs aktueller Chips wird dann aber die Kühlung problematisch.
Manches davon kann natürlich zufällig zutreffen es lohnt sich aber kaum darüber zu spekulieren.
Die Patente von AMD sind da schon interessanter. Das Problem von GPU chiplets ist dabei aber nicht unbedingt, das man Aufgaben nicht auf mehrere Chips verteilen könnte, sondern dass häufig interconnects mit extrem hohen Datendurchsatz nötig wären. Dank Si-interposer bekommt man da gerade so ein paar TB/s für die MCDs bei RDNA3 zusammen. Mal als doofes Beispiel: Man teilt Frontend und Backend in 2 chiplets auf. Wenn man jetzt 20k shader mit 3Ghz mit jeweils einer fp32 variablen versorgen möchte sprechen wir schon von 240 TB/s.
Mehr Durchsatz wäre eventuell mit TSVs machbar also dann mit Chip stacking. Bei den hohen TDPs aktueller Chips wird dann aber die Kühlung problematisch.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Da sollte man aber auch nicht vergessen das vieles von dem Bandbreitenbedarf im internen Cache des Chips stattfindet.
Deshalb sehe ich die von AMD angedachte Variante der groben Voraufteilung interessant da der ganze bandbreitenlastige Kleinkram dann auf dem jeweiligen Chiplet selbst stattfinden kann. Interessant fände ich dann aber noch die Rolle des Infinity Cache bzw. wie er letztendlich eingesetzt werden könnte. Bekommt dann jedes GPU Chiplet seinen eigenen oder wird er wie bei der aktuellen Fassung auf die Speichercontroller aufgeteilt? Eine Herausforderung könnte dabei sein das alle GPU Chiplets den gleichen VRAM nutzen können. Da könnte ein infinity Cache pro GPU Chiplet natürlich auch einiges an Bandbreitenbedarf abfangen und so die Schnittstelle entlasten. Vielleicht ist das aktuelle Design mit den kleinen VRAM Controller Chiplets ja gleichzeitig ein Feldversuch für ein solches Design?
Deshalb sehe ich die von AMD angedachte Variante der groben Voraufteilung interessant da der ganze bandbreitenlastige Kleinkram dann auf dem jeweiligen Chiplet selbst stattfinden kann. Interessant fände ich dann aber noch die Rolle des Infinity Cache bzw. wie er letztendlich eingesetzt werden könnte. Bekommt dann jedes GPU Chiplet seinen eigenen oder wird er wie bei der aktuellen Fassung auf die Speichercontroller aufgeteilt? Eine Herausforderung könnte dabei sein das alle GPU Chiplets den gleichen VRAM nutzen können. Da könnte ein infinity Cache pro GPU Chiplet natürlich auch einiges an Bandbreitenbedarf abfangen und so die Schnittstelle entlasten. Vielleicht ist das aktuelle Design mit den kleinen VRAM Controller Chiplets ja gleichzeitig ein Feldversuch für ein solches Design?
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.625
- Renomée
- 641
48GB für eine Gaming-Karte sind unrealistisch. Bereits die aktuellen 24GB werden heute nicht benötigt.
V-Cache sollte schon eher grösser werden, DirectStorage und SamplerFeedback macht grössere VRAM Kapazitäten obsolet, eine Weiterentwicklung in dem Bereich ist eher zu erwarten. Vermutlich genügen 16GB im Gaming für eine sehr lange Zeit, bei der nächsten Konsolengeneration erwarte ich wegen dem schnellen SSD-Speicher kaum mehr als die heute gebotenen 16GB, evtl. für das OS noch etwas mehr, aber nicht für Grafik.
Im Gerüchte-Beitrag steht auch nichts von 48GB sondern nur 24GB. Die 32/48GB VRAM im RGT Video waren für Pro-Karten spekuliert gewesen. Das wäre keinesfalls eine RX 8900XTX.
Im Wesentlichen ging es doch um die GCX Aufteilung in mehreren Chiplets mit jeweils drei ShaderEngines von bis zu 48CUs sowie unbekannt hohe Steigerungen bei Raytracing.
V-Cache sollte schon eher grösser werden, DirectStorage und SamplerFeedback macht grössere VRAM Kapazitäten obsolet, eine Weiterentwicklung in dem Bereich ist eher zu erwarten. Vermutlich genügen 16GB im Gaming für eine sehr lange Zeit, bei der nächsten Konsolengeneration erwarte ich wegen dem schnellen SSD-Speicher kaum mehr als die heute gebotenen 16GB, evtl. für das OS noch etwas mehr, aber nicht für Grafik.
Im Gerüchte-Beitrag steht auch nichts von 48GB sondern nur 24GB. Die 32/48GB VRAM im RGT Video waren für Pro-Karten spekuliert gewesen. Das wäre keinesfalls eine RX 8900XTX.
Im Wesentlichen ging es doch um die GCX Aufteilung in mehreren Chiplets mit jeweils drei ShaderEngines von bis zu 48CUs sowie unbekannt hohe Steigerungen bei Raytracing.
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
16GB gab's schon seit Vega FE, also im Jahr 2017. Das sind mittlerweile 6 Jahre her. Fürs Gaming Top-End, also für Navi41 halte ich 32GB VRAM-Bestückung für realistisch.
Beim 384bit SI sind es mit 36 Gbits Gddr7 rund 1.728 GB/s VRAM - Bandbreite.
Evtl. steht auch 512bit SI bei N41 zur Verfügung. Das wäre dann ~ 2.304 GB/s VRAM - Bandbreite.
8XMCD entweder 128MB oder 256MB IF$. 128MB scheinen für 4K so einen Grenznutzen zu haben. Ich tendiere zu 256MB IF$, sollte dieser billig sein.
Mit entsprechenden Shader ~ 18432 bzw. 36864SP fp32 kann dann auch langsam 8K-Leistung relevant werden.
Müsste man nur mal schauen ob AMD 2xGCD oder 3xGCD angeht.
Beim 384bit SI sind es mit 36 Gbits Gddr7 rund 1.728 GB/s VRAM - Bandbreite.
Evtl. steht auch 512bit SI bei N41 zur Verfügung. Das wäre dann ~ 2.304 GB/s VRAM - Bandbreite.
8XMCD entweder 128MB oder 256MB IF$. 128MB scheinen für 4K so einen Grenznutzen zu haben. Ich tendiere zu 256MB IF$, sollte dieser billig sein.
Mit entsprechenden Shader ~ 18432 bzw. 36864SP fp32 kann dann auch langsam 8K-Leistung relevant werden.
Müsste man nur mal schauen ob AMD 2xGCD oder 3xGCD angeht.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Wenn es eine multi Chiplet GPU wird dann würde ich eher von einer gewissen Symetrie ausgehen um möglichst viele Produkte mit möglichst wenigen Chiplet Varianten abzudecken. Hier würde sich natürlich ein Chiplet mit einem 128 Bit Speicherinterface anbieten von denen bei Bedarf 2-3 zusammengeschaltet werden können. So könnte man mit einem relativ kleinen Chip den Großteil der Produktpalette abdecken. Für Lowend könnte noch ein separater Chip entwickelt werden, sofern dieser Bereich nicht ohnehin von den APUs abgedeckt wird.
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
AMD Talks RDNA 4, GPU-Based AI Accelerators, Next-Gen Graphics Pipeline: Promises To Evolve To RDNA 4 With Even Higher Performance In Near Future
AMD's Radeon head, David Wang, has talked about RDNA 4 GPUs, AI Accelerators within GPUs and next-gen graphics pipeline in an interview.
GPU-basierte AI-Beschleunigung wird bei RDNA4 ausgebaut werden.
Randnotiz : In RDNA3 wurde MDIA (Multi-Draw Indirect Accelerator) eingebaut. Damit wird der CPU-Overhead massiv abgebaut. Die Draw-Calls gehen an den Command-Prozessor der GPU um die CPU-Auslastung zu senken.
2024 kommt RDNA4 wahrscheinlich auf dem Markt.
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.368
- Renomée
- 9.702
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
2024 kommt RDNA4 wahrscheinlich auf dem Markt.
AMD selbst sagt ja 2024, deswegen verstehe ich die aktuelle Aufregung nicht. Gibt allerdings auch Leute die behaupten Late 2024 oder Anfang 2025.
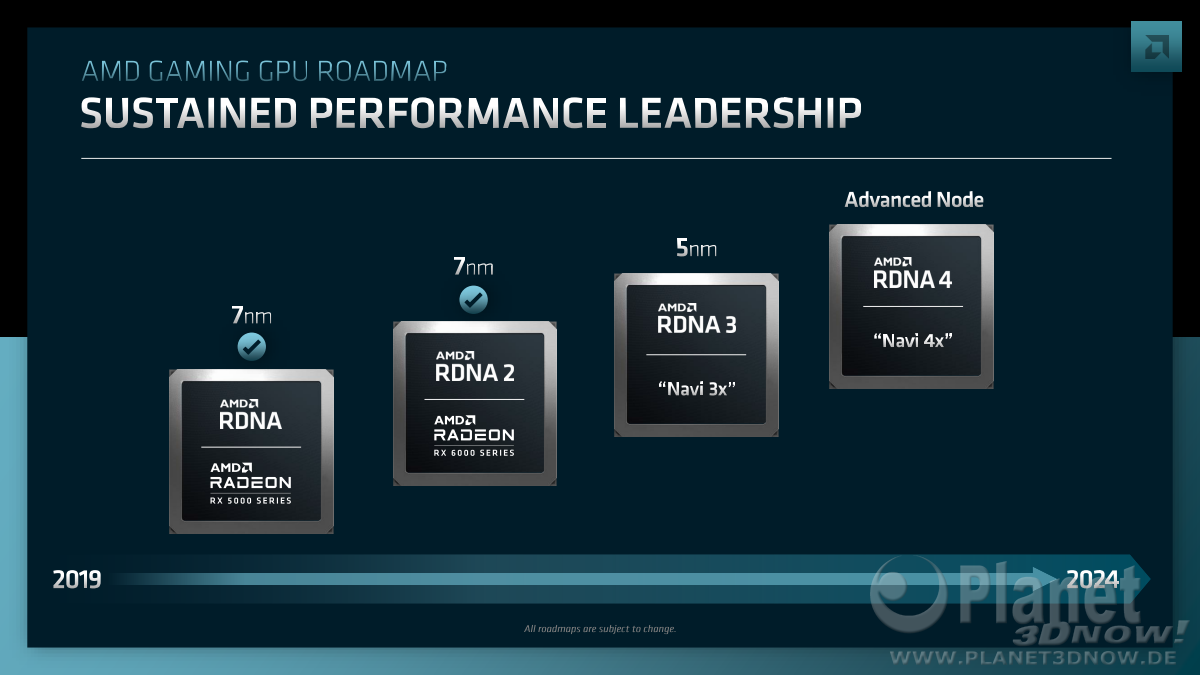
Hier übrigens noch die Quelle für die Wccftech Sachen in einer Google-Übersetzung:

西川善司の3DGE:Primitive Shader対Mesh Shaderの真実。ジオメトリパイプライン戦争の内幕とAMDのゲーマー向けGPU戦略
去る2022年12月,AMDのRadeon GPU戦略を統括するDavid Wang氏とRick Bergman氏に,インタビューする機会を得た。本稿では,彼らに聞いた「Primitive Shader対Mesh Shader」のジオメトリパイプライン標準化争いの実情と,今後のゲーマー向けGPU戦略についてをレポートしたい。
www-4gamer-net.translate.goog
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
AMD Says It Is Possible To Develop An NVIDIA RTX 4090 Competitor With RDNA 3 GPUs But They Decided Not To Due To Increased Cost & Power
AMD said that they can develop a RDNA 3 "Radeon RX 7000" GPU that competes with the NVIDIA RTX 4090 but won't due to increase power & cost.
Am Ende des Artikels sagt Bergmann auch was zu dem mGPU-Konzept: derzeit ist es günstiger eine große GPU(Cores) zu bauen (RDNA3), weshalb mGPU verschoben wurde. (auf RDNA4?).
David Wang sagte zudem, dass man sich bei RDNA4 mehr auf Ray-Tracing fokussieren werde (also mehr Transistoren für RT) und mehr Leistung bringe (+60%?).
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.236
- Renomée
- 538
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Wie wäre es die MehrLeistung auch mal in mehr Bild Qualität umzumünzen.
Bisher kommen immer mehr FPS herraus, aber immer noch mit 8 Bit und in SDR.
Es gibt inzwischen HDR 2000 und HDMI 2.1
Es hat schon Gründe, warum AMD als Konsolen Kaiser angesehen werden kann!
Bisher kommen immer mehr FPS herraus, aber immer noch mit 8 Bit und in SDR.
Es gibt inzwischen HDR 2000 und HDMI 2.1
Es hat schon Gründe, warum AMD als Konsolen Kaiser angesehen werden kann!
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Die HDR 2000 und HDMI 2.1 Geschichte ist in erster Linie Sache des Displays und wenn man bedenkt wieviel Rechenleistung inzwischen seitens der Software verbrannt wird um Entwicklungskosten für die PC Version zu sparen....
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.236
- Renomée
- 538
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ja natürlich, deswegen muss HDR auch im Spiel aktiviert werden, damit die Spiele Engine mit HDR10+ rendert.Die HDR 2000 und HDMI 2.1 Geschichte ist in erster Linie Sache des Displays und wenn man bedenkt wieviel Rechenleistung inzwischen seitens der Software verbrannt wird um Entwicklungskosten für die PC Version zu sparen....
Ohne HDMI 2.1 kein HDR 1000.
Wenn die Bilder bis zu 10 mal Größer sind liegt das nicht am Weg lassen, sondern am 100% Darstellen auf dem Display.
Und zwar nur das, was fertig gerendert wurde!
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
So wie ich das verstanden habe geht es bei der HDR Einstufung primär um die Helligkeit des Displays, der größere Farbraum durch HDR selbst geht wiederum auf die Bandbreite der Schnittstelle. HDR10+ scheint auch nicht so star wie die ursprüngliche Form zu sein sondern arbeitet dynamisch, was wohl eher was für die Verkleinerung der Bilddaten wäre und vermutlich deshalb vor allem bei den Streaming Diensten zum Einsatz kommt.
Ich sehe also erstmal nichts was im Vergleich zum normalen HDR großartig zusätzliche Rechenleistung von der GPU fordern würde.
Wenn der Artikel noch aktuell ist scheint HDR 2000 noch nicht einmal ein offizieller VESA Standard zu sein.
 www.pcgameshardware.de
www.pcgameshardware.de
Ich sehe also erstmal nichts was im Vergleich zum normalen HDR großartig zusätzliche Rechenleistung von der GPU fordern würde.
Wenn der Artikel noch aktuell ist scheint HDR 2000 noch nicht einmal ein offizieller VESA Standard zu sein.
VESA weist auf falsche Display-HDR-2000-Zertifikate hin
Die Ausweisung von Monitoren als Display-HDR 2000 zieht immer weitere Kreise. Die VESA stellt nun erneut klar, dass es kein HDR 2000 gibt.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.236
- Renomée
- 538
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
In ca. 7 Sekunden sind 13Gbyte VRAM geladen.
Da muss ich nicht auf Ray Tracing oder FSR 2.0 verzichten.
Wenn der VRAM 14 GByte hat und ein Bild nur 30MByte, ist das schon nochmal Komprimiert, in Echtzeit während des Rendern.
VSync mit 60Hz und immer noch 27MByte pro Bild.
Selbst mit HDR 400 sieht das Bild nicht so "übersichtlich" aus wie auf meinem Display.
Grüße an G-Sync !
Da muss ich nicht auf Ray Tracing oder FSR 2.0 verzichten.
Wenn der VRAM 14 GByte hat und ein Bild nur 30MByte, ist das schon nochmal Komprimiert, in Echtzeit während des Rendern.
VSync mit 60Hz und immer noch 27MByte pro Bild.
Selbst mit HDR 400 sieht das Bild nicht so "übersichtlich" aus wie auf meinem Display.
Grüße an G-Sync !
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
Raja verlässt Intel Ende 2023. Eventuell Rückkehr zu AMD um an RDNA4 mitzuarbeiten?
Sein 4096SP GCN Fiji10-Design scheint bei Intel nicht so ganz zu fruchten.
Raja will bei den GPUs auch ordentlich große Chips bauen. Mal schauen wohin er geht und ob bei AMD generell Kohle locker gemacht wird für riesen Consumer-Chips am Desktop.

 www.hardwareluxx.de
www.hardwareluxx.de
Doch eher nicht, nach 5 Jahren Intel will Raja etwas mit Software machen.
Sein 4096SP GCN Fiji10-Design scheint bei Intel nicht so ganz zu fruchten.
Raja will bei den GPUs auch ordentlich große Chips bauen. Mal schauen wohin er geht und ob bei AMD generell Kohle locker gemacht wird für riesen Consumer-Chips am Desktop.
Hochrangiger Abgang: Raja Koduri verlässt Intel - Hardwareluxx
Hochrangiger Abgang: Raja Koduri verlässt Intel.
Doch eher nicht, nach 5 Jahren Intel will Raja etwas mit Software machen.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.956
- Renomée
- 443
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich glaube das auch nicht.
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
Raja hat u.a. ansprechende XE-Cores bei/für Intel Arc gebaut, die durchaus sehr gut mithalten können und besser sind als RDNA2 / 3 uArch. Stichwörter sind u.a. "Asynchronous Ray-Tracing" und "Thread Sorting" bei der Arc uArch.
Rein von der Rohleistung (Compute shader power) braucht AMD Raja nicht mehr, das ist klar.
Was noch extrem ausgebaut werden kann ist eben Multi-GCD und optimierte RT-Leistung bzw. RT-Cores in der Hardware. RDNA3 ist nach wie vor RT auf Compute-Shader, wenn auch stark verbessert ggü. RDNA2.
Speziell für Konsolen konzipiert, könnte eine APU mit RDNA4 / Zen5 mit deutlich schnelleren RT-Cores ausgestattet werden (neben einer Erhöhung der Rohleistung).
Auch am Desktop kann RT dann in der Mittelklasse massentauglich werden.
Die Entwicklung der Vega uArch von Raja war marketingmäßig etwas übertrieben. Das hat AMD nun seit einer Weile geändert, aber jetzt sehe ich zu wenig Begeisterung bei RDNA3, obwohl die uArch auch sehr krass ist.
Im Prinzip macht Raja jetzt KI, AMD will auch stärker auf KI fokussieren. Also verringerte Präzision int8, int4. Matrix-Cores, Matrizen-Multiplikation.
Ist schon ne geile Sache, mal schauen was bei RDNA4 rauskommt.
Rein von der Rohleistung (Compute shader power) braucht AMD Raja nicht mehr, das ist klar.
Was noch extrem ausgebaut werden kann ist eben Multi-GCD und optimierte RT-Leistung bzw. RT-Cores in der Hardware. RDNA3 ist nach wie vor RT auf Compute-Shader, wenn auch stark verbessert ggü. RDNA2.
Speziell für Konsolen konzipiert, könnte eine APU mit RDNA4 / Zen5 mit deutlich schnelleren RT-Cores ausgestattet werden (neben einer Erhöhung der Rohleistung).
Auch am Desktop kann RT dann in der Mittelklasse massentauglich werden.
Die Entwicklung der Vega uArch von Raja war marketingmäßig etwas übertrieben. Das hat AMD nun seit einer Weile geändert, aber jetzt sehe ich zu wenig Begeisterung bei RDNA3, obwohl die uArch auch sehr krass ist.
Im Prinzip macht Raja jetzt KI, AMD will auch stärker auf KI fokussieren. Also verringerte Präzision int8, int4. Matrix-Cores, Matrizen-Multiplikation.
Ist schon ne geile Sache, mal schauen was bei RDNA4 rauskommt.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Nicht ganz, wenn ich mich recht erinnere steckt die RT Beschleunigung bei AMD in den ROPs und auf die Zuarbeit der Shader sind die Varianten aller Hersteller angewiesen. AMD geht einfach nur einen komplett anderen Weg als die Konkurrenz.RDNA3 ist nach wie vor RT auf Compute-Shader, wenn auch stark verbessert ggü. RDNA2.
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
Bei RDNA2 ist es so, dass bei aktiviertem RT, die TMU geopfert werden:

 www.tomshardware.com
"AMD's RDNA2 chips contain one Ray Accelerator per CU, which is similar to what Nvidia has done with it's RT cores. Even though AMD sort of takes the same approach as Nvidia, the comparison between AMD and Nvidia isn't clear cut. The BVH algorithm depends on both ray/box intersection calculations and ray/triangle intersection calculations. AMD's RDNA2 architecture can do four ray/box intersections per CU per clock, or one ray/triangle intersection per CU per clock.
www.tomshardware.com
"AMD's RDNA2 chips contain one Ray Accelerator per CU, which is similar to what Nvidia has done with it's RT cores. Even though AMD sort of takes the same approach as Nvidia, the comparison between AMD and Nvidia isn't clear cut. The BVH algorithm depends on both ray/box intersection calculations and ray/triangle intersection calculations. AMD's RDNA2 architecture can do four ray/box intersections per CU per clock, or one ray/triangle intersection per CU per clock.
There's an important distinction here that we do need to point out. AMD apparently does the ray/box intersections using modified texture units. While a rate of four ray/box intersections per clock might sound good, we don't have exact details of how that compares with Nvidia's RTX hardware. What we do know is that, in general, Nvidia's ray tracing performance is better. Also note that Intel's Arc Architecture does up to 12 ray/box intersections per clock."
Bei RDNA3 wurden die CUs erhöht von 80 auf 96 (+20%)
Bei RDNA3 wurde der Takt erhöht von 2,2-2,3Ghz auf 2,55-2,6Ghz (+16%)
Bei RDNA3 wurden die Caches extrem erhöht: L1 von 1MB auf 3MB +300%, L2 von 4MB auf 6MB +50%, L0 von 32kb auf 64kb pro WGP, also +240%.
All das hat Auswirkungen auf RT, von der raw-power Seite her, bessere RT-hitrates usw.
Intern wurde BHV-Beschleunigung verbessert (Geometry Flags für BHV) + DXR Ray Flags durch triangle culling.
Ein neuer scheduling-Algorithmus wurde eingeführt um die RT-Quads zu füllen.
Dann noch die große Erneuerung +50% vector general purpose registers (VGPRs).
Sehr lobenswert, ist dass AMD dadurch bei RT massiv aufgebohrt hat und der Rückstand sogar etwas geringer geworden ist.
Bei RDNA4 erwarte ich "Asynchronous Ray-Tracing" und eine Erhöhung von vier ray/box intersections per CU per Clock auf 12 oder 16 ray/box intersections per CU per Clock. (neben der raw-power Erhöhung). Die RT-Ausführung muss weg von den TMUs auf lange Sicht gesehen.
AMD Big Navi and RDNA 2 GPUs: Everything We Know
The AMD Big Navi / RDNA 2 architecture powers the latest consoles and high-end graphics cards.
There's an important distinction here that we do need to point out. AMD apparently does the ray/box intersections using modified texture units. While a rate of four ray/box intersections per clock might sound good, we don't have exact details of how that compares with Nvidia's RTX hardware. What we do know is that, in general, Nvidia's ray tracing performance is better. Also note that Intel's Arc Architecture does up to 12 ray/box intersections per clock."
Bei RDNA3 wurden die CUs erhöht von 80 auf 96 (+20%)
Bei RDNA3 wurde der Takt erhöht von 2,2-2,3Ghz auf 2,55-2,6Ghz (+16%)
Bei RDNA3 wurden die Caches extrem erhöht: L1 von 1MB auf 3MB +300%, L2 von 4MB auf 6MB +50%, L0 von 32kb auf 64kb pro WGP, also +240%.
All das hat Auswirkungen auf RT, von der raw-power Seite her, bessere RT-hitrates usw.
Intern wurde BHV-Beschleunigung verbessert (Geometry Flags für BHV) + DXR Ray Flags durch triangle culling.
Ein neuer scheduling-Algorithmus wurde eingeführt um die RT-Quads zu füllen.
Dann noch die große Erneuerung +50% vector general purpose registers (VGPRs).
Sehr lobenswert, ist dass AMD dadurch bei RT massiv aufgebohrt hat und der Rückstand sogar etwas geringer geworden ist.
Bei RDNA4 erwarte ich "Asynchronous Ray-Tracing" und eine Erhöhung von vier ray/box intersections per CU per Clock auf 12 oder 16 ray/box intersections per CU per Clock. (neben der raw-power Erhöhung). Die RT-Ausführung muss weg von den TMUs auf lange Sicht gesehen.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Ach dann waren es die TMUs, habe mich schon länger nicht mehr wirklich damit beschäftigt.
Geopfert wird da aber nichts sondern die Beschleunigungseinheiten stecken darin. Die TMUs erledigen die Aufgabe deshalb mit anstatt den Berechnungsschritt auf eine separate Einheit auszulagern.
Wie gesagt, AMD ist hier einen deutlich anderen Weg als die Konkurrenz gegangen bei dem die Aufgabe von vorhandenen Einheiten mit erledigt wird, hat diese aber für die Aufgabe im Funktionsumfang erweitert. Vorteil war wohl die höhere Flexibilität bei der RT Berechnung, Nachteil die geringere Leistung auf dem Gebiet.
Wird die RT Integration allerdings nur auf den geringeren Funktionsumfang der FFUs der Konkurrenz ausgelegt bringt die höhere Flexibilität natürlich herzlich wenig und erneut sind wir beim Faktor "Software" bei der effektiven Performance.
Mit zunehmenden Einsatz von Chiplet Designs kann ich mir allerdings vorstellen das auch AMD diese Berechnung auslagern könnte um einfach deutlich mehr RT Performance rauszuholen. Dann aber vermutlich auf einen spezialisierten Chiplet der dann entsprechend skaliert werden könnte um die Raster- und die RT Berechnung ein Stück weit zu trennen denn wie man sieht frißt der RT Einsatz erheblich mehr Performance als der Raster Part und langfristig gesehen auch dementsprechend auch Platz auf dem Chip um dessen Einsatz deutlich Performanter zu machen.
Eine separate Beschleunigerkarte wäre mit zwar lieber aber ich vermute das die aufgrund der Bandbreitenbeschränkungen und dem heute üblichen RT - Raster Mix aus Performancegründen nicht sinnvoll ist, welcher wiederum aus Performancegründen zum reinen RT Einsatz genutzt wird.
Geopfert wird da aber nichts sondern die Beschleunigungseinheiten stecken darin. Die TMUs erledigen die Aufgabe deshalb mit anstatt den Berechnungsschritt auf eine separate Einheit auszulagern.
Wie gesagt, AMD ist hier einen deutlich anderen Weg als die Konkurrenz gegangen bei dem die Aufgabe von vorhandenen Einheiten mit erledigt wird, hat diese aber für die Aufgabe im Funktionsumfang erweitert. Vorteil war wohl die höhere Flexibilität bei der RT Berechnung, Nachteil die geringere Leistung auf dem Gebiet.
Wird die RT Integration allerdings nur auf den geringeren Funktionsumfang der FFUs der Konkurrenz ausgelegt bringt die höhere Flexibilität natürlich herzlich wenig und erneut sind wir beim Faktor "Software" bei der effektiven Performance.
Mit zunehmenden Einsatz von Chiplet Designs kann ich mir allerdings vorstellen das auch AMD diese Berechnung auslagern könnte um einfach deutlich mehr RT Performance rauszuholen. Dann aber vermutlich auf einen spezialisierten Chiplet der dann entsprechend skaliert werden könnte um die Raster- und die RT Berechnung ein Stück weit zu trennen denn wie man sieht frißt der RT Einsatz erheblich mehr Performance als der Raster Part und langfristig gesehen auch dementsprechend auch Platz auf dem Chip um dessen Einsatz deutlich Performanter zu machen.
Eine separate Beschleunigerkarte wäre mit zwar lieber aber ich vermute das die aufgrund der Bandbreitenbeschränkungen und dem heute üblichen RT - Raster Mix aus Performancegründen nicht sinnvoll ist, welcher wiederum aus Performancegründen zum reinen RT Einsatz genutzt wird.
E555user
Admiral Special
- Mitglied seit
- 05.10.2015
- Beiträge
- 1.625
- Renomée
- 641
RDNA4 ist als Architektur in der Zielsetzung in den CUs und Funktionseinheiten - wo Koduri beisteuern könnte - sicherlich schon festgelegt. Lediglich einzelne Chipvarianten sind vielleicht noch nicht ganz so weit. Er hätte vielleicht noch so viel Einfluss wie bei Polaris damals.Raja verlässt Intel Ende 2023. Eventuell Rückkehr zu AMD um an RDNA4 mitzuarbeiten?
Sein 4096SP GCN Fiji10-Design scheint bei Intel nicht so ganz zu fruchten.
:
Doch eher nicht, nach 5 Jahren Intel will Raja etwas mit Software machen.
Er hat kein GCN Design bei Intel eingeführt - er hat GCN zu Version 5 aka Vega-Arch als Führungsperson weiterentwickelt, das ist etwas ganz anderes. Auch RDNA muss bereits während seiner Verantwortung angelegt worden sein. Intel ist mit Sicherheit für grosse Teile der Arch selbst verantwortlich, die scheint aber nicht das Problem zu sein, sondern die Treiber und die Fertigung.
(Nachtrag: glaube auch bei AMD war Koduri nicht für die dichte Integration im Fertigungslayout zuständig, das brachte erst später Vega zum Perf/Watt Erfolg)
Mit seiner neuen SW-Firma für AI könnte ein Übernahmekandidat entstehen, mit dem er sich bei einem Chipdesigner dann postitionieren könnte. AMD ist in Software auf einem guten Weg, aber noch lange nicht am Ziel. Architektur und Software als API gehen da im Design Hand in Hand. Im Treiber muss dann aufgefangen werden was in HW und realen Applikationen nicht ganz so wie in der Theorie möglich war.
Die RT-Einheiten sind separat in der Dokumentation, nur mit weniger Komplexität bzw. fokussierung auf wenige Funktionen lassen sich effizientere/schnellere Ausführungseinheiten bauen. Ich vermute, dass es zwar separate Einheiten sind, die jedoch den Shader Core den Thread dort verwaltet und mindestens dadurch teilweise blockiert ist. Die farbgebende Berechnungen für einen RT-beleuchtetes Pixel werden immer - in jeder aktuellen Arch - von den Shader-Einheiten in Compute-Shader berechnet..... RDNA3 ist nach wie vor RT auf Compute-Shader, wenn auch stark verbessert ggü. RDNA2.
:
Die Entwicklung der Vega uArch von Raja war marketingmäßig etwas übertrieben. Das hat AMD nun seit einer Weile geändert, aber jetzt sehe ich zu wenig Begeisterung bei RDNA3, obwohl die uArch auch sehr krass ist.
Raja war als Leiter der RTG für das Marketing letztlich als Abnicker verantwortlich, aber für das Marketing waren ganz andere Leute zuständig (Chris Hook, Pete Hines, Roy Taylor). Das Marketing wäre genial gewesen hätte Vega tatsächlich einen funktionierenden Prim-Shader mit Game-Support gehabt.
Die TMUs werden nicht "geopfert". Der Gedanke bei AMD ist, dass in einem Clock-Cycle, der für RT die BVH Berechnungen für Strahlenkollisionen ausführt, zu gleicher Zeit keine Textursamples berechnet werden. Das macht Sinn, da die erst danach kommen. Entsprechend nutzt RDNA die gleichen Load/Store Einheiten für Textur und RT-Beschleunigung. Ausserdem werden mit RT Fake-Effekte, die sonst über Texturen ermöglicht werden, ersetzt.Bei RDNA2 ist es so, dass bei aktiviertem RT, die TMU geopfert werden:
Für mich ist das ein gutes holistisches Design der Architektur, es braucht aber korrekten Code der das berücksichtigt (fencing/barriers/cache management).
AMD muss die RT-Leistung zu BVH-Computing je Shader-Core mindestens verdoppeln, wenn man deutliche Zugewinne machen will. Bei RDNA3 wollte man aber auf die doppelte Auslegung der RT-Beschleunigung mit entsprechendem Load/Store verzichten. Man sucht nach "eleganteren" Lösungen wo auf die Schnelle nur Brute-Force helfen würde.
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.577
- Renomée
- 2.063
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Wenn ich mich richtig an die News von damals erinnere mußten bei der Vega Entwicklung sogar Ressourcen an die RDNA Entwickler abgegeben werden weil diese aufgrund des Konsolen Einsatzes Prio hatte. Wer weiß was aus Vega ohne diese Einschränkungen geworden wäre. Die Architektur konnte ja auch nicht die offensichtlichen Einschränkungen bezüglich des Ausbaus der Recheneinheiten überwinden und blieb diesbezüglich an den Grenzen hängen die bereits Fiji offenbarte und konnte zusätzliche Leistung nur über die Taktfrequenz generieren. Vielleicht deshalb auch der Abzug der Entwicklungsressourcen?er hat GCN zu Version 5 aka Vega-Arch als Führungsperson weiterentwickelt, das ist etwas ganz anderes. Auch RDNA muss bereits während seiner Verantwortung angelegt worden sein
Mehr Recheneinheiten gab es meiner Erinnerung nach erst unter dem CDNA Label und mit weggefallener Grafik Funktionalität.
Zuletzt bearbeitet:
vinacis_vivids
Vice Admiral Special
- Mitglied seit
- 12.01.2004
- Beiträge
- 868
- Renomée
- 98
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 7950X 16C/32T
- Mainboard
- ASUS ProArt X670E-CREATOR WIFI
- Kühlung
- Arctic Liquid Freezer II 360 RGB
- Speicher
- HyperX Fury 64GB DDR5 6000Mhz CL30
- Grafikprozessor
- Sapphire Nitro+ RX 7900 XTX 24GB
- Display
- LG 5K HDR 10bit 5120x2160@60hz
- SSD
- Samsung SSD 980Pro 2TB
- Soundkarte
- Creative Soundblaster ZXR
- Gehäuse
- Cougar DarkBlader X5
- Netzteil
- InterTech Sama Forza 1200W
- Tastatur
- Cherry MX-10.0 RGB Mechanisch
- Maus
- Razer Mamba
- Betriebssystem
- Windows 11 Education Pro
- Webbrowser
- Google Chrome
- Internetanbindung
- ▼1000 Mbit
@E555user
Raja war als Kopf der RTG-Abteilung im Prinzip komplett in Polaris, Vega und RDNA1 involviert und auch für die Ergebnisse verantwortlich. Die Vega uArch war im Ergebnis äußerst enttäuschtend was die Leistung anging und konnte nur selten glänzen (Compute-Shader lastig, ETH-Mining, HDR-10bit Rendering, HBCC). Der Chip war mit 484mm^2 sehr groß und mit HMB2 Speicher sehr teuer. Konnte allerdings Aufgrund fehlenden Software-Supports nicht an die Spitze.
Das war für AMD bis dato der letzte Versuch die GPU-Krone zu ergreifen. Kosten wurden nicht gescheut. Selbst die erste 7nm GPU war Vega20. Das Vertrauen in Raja (Vega) war unendlich groß, inkl. Apple.
Aufgrund dieser Niederlage am PC hat Su sich von Raja getrennt und die GPU-Abteilung neu strukturiert. Spaltung in Grafik(RDNA) und Compute (CDNA).
Die kleineren Brötchen Polaris10 ++ Aufguss 232mm^2 und Navi10 251mm^2 hielten AMD GPUs weitgehend am Leben. Das Desktop-Highend hat man (fast) komplett Jensen überlassen, was ich sehr sehr bedauere, und das nun seit mind. 10 Jahren, insbesondere mit RDNA3, wo nur Kosten optimiert werden. Im Prinzip ist das 304mm^3 GCD vs 608mm^2 GPU, also nur die Hälfte der Die-Größe der Konkurrenz.
RDNA3 ist bei gleicher Die-Größe durchaus stärker als die Konkurrenz.
Hoffe RDNA4 greift wieder voll an die Spitze inkl. RT-Cores an und bringt die Wende am Desktop-Markt . Dafür muss massivst am RT geschraubt werden, bei Raster herrscht fast Gleichstand trotz des deutlich kleineren Chips.
Das würde auch deutlich mehr Schwung und Marktanteile bringen, wo AMD schon mal bei >50% war.
Raja war als Kopf der RTG-Abteilung im Prinzip komplett in Polaris, Vega und RDNA1 involviert und auch für die Ergebnisse verantwortlich. Die Vega uArch war im Ergebnis äußerst enttäuschtend was die Leistung anging und konnte nur selten glänzen (Compute-Shader lastig, ETH-Mining, HDR-10bit Rendering, HBCC). Der Chip war mit 484mm^2 sehr groß und mit HMB2 Speicher sehr teuer. Konnte allerdings Aufgrund fehlenden Software-Supports nicht an die Spitze.
Das war für AMD bis dato der letzte Versuch die GPU-Krone zu ergreifen. Kosten wurden nicht gescheut. Selbst die erste 7nm GPU war Vega20. Das Vertrauen in Raja (Vega) war unendlich groß, inkl. Apple.
Aufgrund dieser Niederlage am PC hat Su sich von Raja getrennt und die GPU-Abteilung neu strukturiert. Spaltung in Grafik(RDNA) und Compute (CDNA).
Die kleineren Brötchen Polaris10 ++ Aufguss 232mm^2 und Navi10 251mm^2 hielten AMD GPUs weitgehend am Leben. Das Desktop-Highend hat man (fast) komplett Jensen überlassen, was ich sehr sehr bedauere, und das nun seit mind. 10 Jahren, insbesondere mit RDNA3, wo nur Kosten optimiert werden. Im Prinzip ist das 304mm^3 GCD vs 608mm^2 GPU, also nur die Hälfte der Die-Größe der Konkurrenz.
RDNA3 ist bei gleicher Die-Größe durchaus stärker als die Konkurrenz.
Hoffe RDNA4 greift wieder voll an die Spitze inkl. RT-Cores an und bringt die Wende am Desktop-Markt . Dafür muss massivst am RT geschraubt werden, bei Raster herrscht fast Gleichstand trotz des deutlich kleineren Chips.
Das würde auch deutlich mehr Schwung und Marktanteile bringen, wo AMD schon mal bei >50% war.
Ähnliche Themen
- Antworten
- 2K
- Aufrufe
- 141K
- Antworten
- 504
- Aufrufe
- 76K
- Antworten
- 614
- Aufrufe
- 51K
- Antworten
- 1
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 1K