App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Interposer Strategie - Zen, Fiji, HBM und Logic ICs
- Ersteller Complicated
- Erstellt am
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Es ist kein Bussystem. Das ergibt sich aus der Analyse von Dresdenboy und Opteron über Zen, wo die Speicher und Cache-Systeme beschrieben werden:
http://www.planet3dnow.de/cms/26077...onferenz/subpage-speichersubsystem-im-detail/
https://de.wikipedia.org/wiki/MOESI
--- Update ---
Auch das ist im PDF beschrieben. Es kostet ca. 3-5 Zyklen die zusätzliche Logik zu überwinden, was allerdings dem reduzieren der Latenz beim Wechsel von 64 zu 16x4 Dies ungefähr entspricht. Das bedeutet dies würde sich gegenseitig aufheben laut der Studie. Was durch die zusätzliche Logik allerdings hinzu gewonnen wird ist die Möglichkeit hinter jedem dieser Schaltpunkte eine eigene Taktdomain zu betreiben oder auch abzuschalten.
Dies ist auch keine Interconnect Fabric. Bitte diese Dinge nicht vermischen. Der Interposer ersetzt eine Interconnect Fabric die nötig wäre um die Chips zu verbinden. Die Meshes und Anbindungen von denen hier gesprochen wird, sind die Anbindungen die auf einem Die die einzelnen CPU-Cores miteinander verbinden. Das Paper schlägt vor durch eben diesen Teilaktiven Interposer diese Anbindungen über den Interposer hinaus auszudehnen um eben nicht die einzelnen Chips mit klassischen TSVs/Microbumps zu verbinden, was höhere Latenzen bedeutet.
Hier auch die Grafik aus dem PDF dazu


Jetzt habe ich aber fast alle Bildchen aus dem PDF hier rein kopiert und mein Speicherplatz im Forum geht dem Ende zu. Daher empfehle ich den Rest im PDF erst einmal durch zu lesen.
http://www.planet3dnow.de/cms/26077...onferenz/subpage-speichersubsystem-im-detail/
Die MOESI-Anbindung verwendet AMD schon lange und ein Blick zu Wikipedia zeigt, dass MOESI auf Bussystemen nicht sinnvoll ist und nur bei Point-to-Point Systemen seine Stärken ausspielen kann. Es ist daher IMHO schlüßig von P2P-Kommunikation auszugehen, da somit MCM-Lösungen ermöglicht werden und auch die Wahl des L3 als Victim-Cache darauf hindeutet.Man erkennt deutlich die acht 1-Megabyte-Blöcke des L3, die jeweils von 512 KiB L2 pro Kern flankiert werden. AMD wird diesen Quad-Modul-Kernbauplan für alle im Moment angekündigten Chips beibehalten. Das bedeutet also, dass erstens die 8-Kern-Version „Summit Ridge” über 2x 8 MiB = 16 L3-Cache verfügen wird und zweitens auch die Zen-APUs mit GPU-Teil und nur einem Zen-Quad-Modul erstmals ebenfalls über einen L3-Cache verfügen werden.
Entgegen anderslautender Gerüchte setzt AMD beim Cache-Aufbau weiterhin auf exklusive L3-Caches nach der „Victim Strategy”. Das heißt, dass Daten in der Regel entweder direkt in den L1- oder in den L2-Cache geladen werden: Fallen Daten aus dem L2 heraus, landen diese „Opfer” (victims) im L3. Bei Intel-Designs liegen L2-Daten dagegen automatisch immer als Kopie auch im L3, was einerseits die effektive L3-Cachegröße und damit indirekt auch die L2-Größe begrenzt, andererseits die Kern-zu-Kern-Kommunikation vereinfacht.
Cache-Organisation und -Aufbau gehen somit Hand in Hand. Weil AMD kein inklusives Cachedesign wählte, ein Datenaustausch über den L3 also ohehin fast unmöglich ist, benötigt man auch keinen einzelnen gemeinsamen L3-Cache, sondern kann sich mit simplen 8-MiB-Modulen begnügen. Insbesondere bei Serverchips mit vielen Kernen und noch mehr Cache, wird die Cacheorganisation zum Problem. AMD setzt bei den Serverchips aber auch auf einen bewährten MCM-Ansatz, mit dem von vorne herein keine gemeinsamen L3-Caches möglich wären. Somit ist die Designentscheidung insgesamt nachvollziehbar und schlüssig. Als Speichermodell findet die bewährte und schon von K8/K10 bekannte MOESI-Strategie Anwendung.
https://de.wikipedia.org/wiki/MOESI
Das MOESI-Protokoll ist eine komplizierte Variante des MESI-Protokolls. Es vermeidet das Zurückschreiben von modifizierten Cache-Lines, wenn andere CPUs diese lesen wollen. Stattdessen wird der aktuelle Wert bei jeder Veränderung zwischen den Caches direkt propagiert (siehe Zustand Owned).
MOESI bietet keinen wesentlichen Vorteil gegenüber MESI, wenn das Verbindungsnetzwerk zwischen Prozessoren und Speichercontroller ein Bus ist. Es ist hingegen bei direkten Netzwerken von Vorteil, wie zum Beispiel bei AMD-Opteron-Systemen. Das Vermeiden des Zurückschreibens von modifizierten Cache-Lines sorgt hier für die Entlastung von Verbindungsnetzwerk und Speichercontroller. Außerdem kann die Kommunikation zwischen zwei oder mehreren CPUs bzgl. Latenz und Übertragungsrate signifikant besser sein als zwischen CPU und Hauptspeicher. Bei Multicore-CPUs mit jeweils eigenen Caches pro Core ist dies meist der Fall.
--- Update ---
Abgesehen davon sollte jegliche zusätzliche Logik zwischen zwei Kernen die Latzenz erhöhen, und nicht verringern, da mit Logik Schaltvorgänge verbunden sind.
Auch das ist im PDF beschrieben. Es kostet ca. 3-5 Zyklen die zusätzliche Logik zu überwinden, was allerdings dem reduzieren der Latenz beim Wechsel von 64 zu 16x4 Dies ungefähr entspricht. Das bedeutet dies würde sich gegenseitig aufheben laut der Studie. Was durch die zusätzliche Logik allerdings hinzu gewonnen wird ist die Möglichkeit hinter jedem dieser Schaltpunkte eine eigene Taktdomain zu betreiben oder auch abzuschalten.
Dies ist auch keine Interconnect Fabric. Bitte diese Dinge nicht vermischen. Der Interposer ersetzt eine Interconnect Fabric die nötig wäre um die Chips zu verbinden. Die Meshes und Anbindungen von denen hier gesprochen wird, sind die Anbindungen die auf einem Die die einzelnen CPU-Cores miteinander verbinden. Das Paper schlägt vor durch eben diesen Teilaktiven Interposer diese Anbindungen über den Interposer hinaus auszudehnen um eben nicht die einzelnen Chips mit klassischen TSVs/Microbumps zu verbinden, was höhere Latenzen bedeutet.
Hier auch die Grafik aus dem PDF dazu
Jetzt habe ich aber fast alle Bildchen aus dem PDF hier rein kopiert und mein Speicherplatz im Forum geht dem Ende zu. Daher empfehle ich den Rest im PDF erst einmal durch zu lesen.
Anhänge


Zuletzt bearbeitet:
MacroWelle
Captain Special
- Mitglied seit
- 15.02.2008
- Beiträge
- 236
- Renomée
- 1
Das denke ich mir, ich habe bewusst auf den Post verwiesen und nicht auf das PDF, weil ich die Tabelle für sich so nicht stehen lassen wollte.In dem PDF, welches verlinkt ist, wird das ausführlich analysiert und auch die unterschiedlichen Meshes die auf einem monolithischen Chip, auf einem Interposer oder auch im gemischten Modus das NoC bilden können.
Es wurden sogar unterschiedliche Lastszenarien (Speicher, GPU, Inter-Kern Kommunikation) zu den verschiedenen Meshes getestet mit unterschiedlichen Ergebnissen. Es geht hier allerdings niemals um fehlende Bandbreite (denn die ist durch den Interposer immer zu genüge da), sondern zumeist um Latenzen die entstehen bei Kollisionen in der Kommunikation und die Anzahl der Hops zwischen den Knoten im NoC. In jedem Fall wird ein "ButterDonut" Mesh, welches mit einem aktiven Interposer ebenfalls verbunden ist als optimal empfohlen.
Als Simpsons-Fan bin ich natürlich für eine ButterDonut-CPU
")
Naja, wobei die Verwendung der Interposer auch Geld kostet. Daher: Chips mit moderater Größe produzieren und für große CPUs (=Server=Marge) mehrere auf einen Interposer packen. So spart man sich auch gleich die Entwicklung größerer DICE.Die Kostenanalyse im Vergleich zur geopferten Latenz zeigt welche Kompromisse man eingehen muss:

Die Kosten mit 4-Core Dies sinken um ca. 20%, während man ca. 22% Latenz als Penalty erhält. Das könnte die Kostenersparnis durchaus rechtfertigen.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Abgesehen davon kann man ja erstmal davon ausgehen, dass AMD keine wilden Modelle mit super vielen kleinen Chips auf den Markt bringen wird. Der Größte dürfte aller Wahrscheinlichkeit erstmal Naples mit vier Achtkern Summit Ridge Modulen sein, welche dann vermutlich als 2x2 angeordnet sind - der optimalen Wege halber.
Wobei es dann eigentlich interessant wäre zwei spiegelverkehrte Chip-Varianten zu haben, damit man immer einen sehr kurzen Weg hat.
Etwa so:
Hmm, etwas verfeinert dann so:
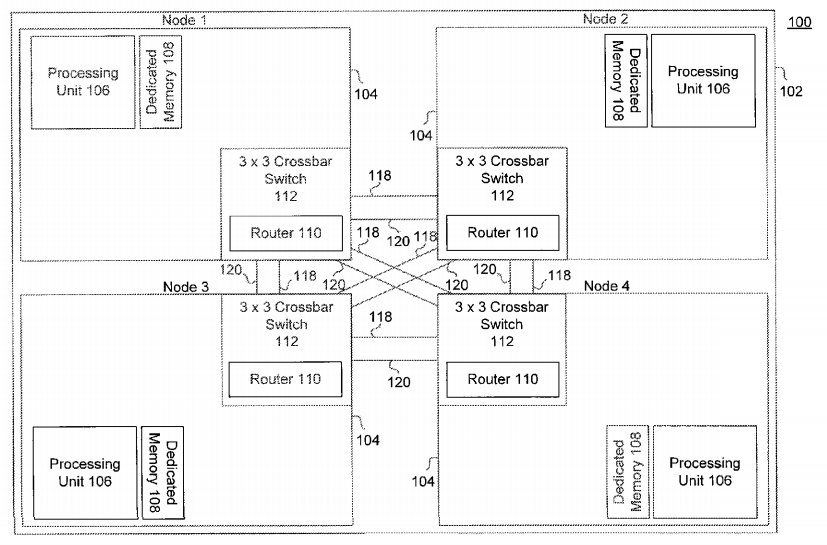

http://www.freepatentsonline.com/9436637.html
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.

Nur zur Klarstellung bzgl. der gespiegelten Dies die spekuliert wurden. Dies ist alles auf einem Die, sozusagen ein Quad-Core Modul, wie es auch für Zen beschrieben wurde.

Zuletzt bearbeitet:
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 3.057
- Renomée
- 288
Ich habe noch in Erinnerung, dass der Interposer auch dazu dienen kann, einen erhelbichen Anteil an Test-Transistoren zu übernehmen, die dann nicht mehr auf den einzelnen 14nm-Dies liegen müssen, wodurch deren teurere Chipfläche verkleinert wird.
Ist halt die Frage, ob es auch Dies gibt (vielleicht sogar eher die Mehrzahl), die gänzlich ohne Interposer verbaut werden sollen. Dann braucht man diese Transistoren natürlich trotzdem auf dem 14nm-Die.
MfG
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich denke dass derzeit lediglich passive Interposer kommen. So wie Bomby ja schon schrieb. Das mit den aktiven werden wir wohl frühestens zu Navi sehen wo es ja um "skalierbares" Design geht. Es sei denn AMD beschließt die HPC APU als erstes Testvehikel zu benutzen, da entsprechende Kosten auch umgelegt werden können im Preis.
--- Update ---
Neues zu HBM3: http://arstechnica.com/gadgets/2016/08/hbm3-details-price-bandwidth/
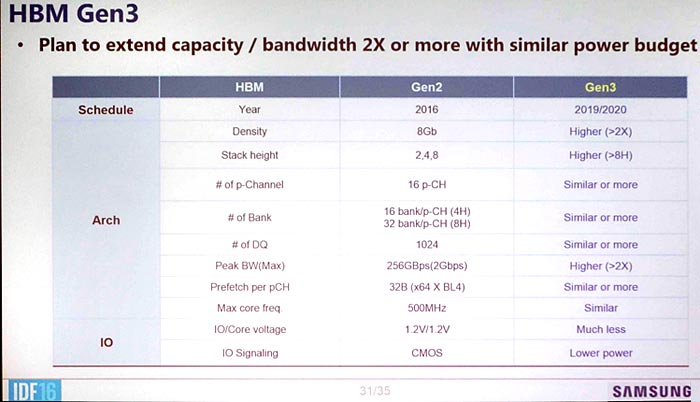
Interessant auch der geplante Low-Cost HBM von Samsung:

--- Update ---
Neues zu HBM3: http://arstechnica.com/gadgets/2016/08/hbm3-details-price-bandwidth/
Interessant auch der geplante Low-Cost HBM von Samsung:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Die Mitgliederliste bei CCIX hat sich gerade ebenfalls verdreifacht:
http://www.prnewswire.com/news-rele...-availability-of-specification-300342252.html
Neu dazu gekommen:
Amphenol Corp.
Arteris Inc.
Avery Design Systems
Atos
Cadence Design Systems, Inc.
Cavium, Inc.
Integrated Device Technology, Inc.
Keysight Technologies, Inc.
Micron Technology, Inc.
NetSpeed Systems
Red Hat Inc.
Synopsys, Inc.
Teledyne LeCroy
Texas Instruments
TSMC
Gründungsmitglieder waren ja AMD, ARM, Huawei, IBM, Mellanox Technologies, Qualcomm Technologies Inc., and Xilinx, Inc.
GenZ scheint auch auf CCIX aufzusetzen. Während CCIX innerhalb eines Server-Nodes die CPUs und Hardwarebeschleuniger verbindet mit dem RAM, soll GenZ den ganzen Node mit dem I/O und dem Datenspeicher verbinden ohne Block basierende Protokolle.
https://community.arm.com/groups/pr...cix-and-genz-address-the-needs-of-data-center


http://www.prnewswire.com/news-rele...-availability-of-specification-300342252.html
Neu dazu gekommen:
Amphenol Corp.
Arteris Inc.
Avery Design Systems
Atos
Cadence Design Systems, Inc.
Cavium, Inc.
Integrated Device Technology, Inc.
Keysight Technologies, Inc.
Micron Technology, Inc.
NetSpeed Systems
Red Hat Inc.
Synopsys, Inc.
Teledyne LeCroy
Texas Instruments
TSMC
Gründungsmitglieder waren ja AMD, ARM, Huawei, IBM, Mellanox Technologies, Qualcomm Technologies Inc., and Xilinx, Inc.
GenZ scheint auch auf CCIX aufzusetzen. Während CCIX innerhalb eines Server-Nodes die CPUs und Hardwarebeschleuniger verbindet mit dem RAM, soll GenZ den ganzen Node mit dem I/O und dem Datenspeicher verbinden ohne Block basierende Protokolle.
https://community.arm.com/groups/pr...cix-and-genz-address-the-needs-of-data-center
While CCIX allows processors to extend their cache coherency to off-chip accelerators, GenZ is addressing the need for higher performance data accesses, with an interconnect based on memory operations that addresses both server node and rack scale. Today, storage requires block based accesses with complex, code intensive software stacks. Memory operations such as loads and stores allow processors to access both volatile (ie DRAM) and non-volatile storage in the same efficient manner. Emerging Storage Class Memory (SCM) and rack level disaggregated memory pools, are example use-cases that benefit from a memory operation interconnect.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Interessant finde ich die paar technischen Details zu Gen-Z in der FAQ. Zum Beispiel:
Edit: Das ist eigentlich noch weitergehender. Im Prinzip ist Gen-Z ein Ersatz für PCIe, und könnte für das OS transparent auch PCIe emulieren:
Und weiter:
Im Moment hört sich das so an, als könnte man über Gen-Z auch sogar einfach PCIe-Sockel anbinden im Zweifelsfall, wobei auch eigene modulare Stecker geplant sind. Ist damit hier eigentlich im falschen Thread hier.
Q: Does Gen-Z specify a new physical layer technology?
A: Gen-Z leverages the IEEE 802.3 physical layer specifications. The Gen-Z members chose the IEEE 802.3 physical layer as its foundation for multiple reasons:
- IEEE 802.3 physical layer is one of the highest-volume technologies, with broad adoption across multiple market segments and deployed throughout the world.
- IEEE 802.3 technology development is driven by hundreds of companies and thousands of developers.
- IEEE 802.3 physical layer IP blocks are readily available from multiple suppliers. Further, these IP blocks are constantly evolving to deliver new capabilities and performance levels.
- IEEE 802.3 physical layer is supported by many test equipment vendors.
- IEEE 802.3 physical layer can scale from chip-to-chip, enclosure-to-enclosure, and rack-to-rack.
- IEEE 802.3 physical layer presently scales up to 56 GT/s, and will scale to 112 GT/s and beyond.
Edit: Das ist eigentlich noch weitergehender. Im Prinzip ist Gen-Z ein Ersatz für PCIe, und könnte für das OS transparent auch PCIe emulieren:
Gen-Z was developed to enhance existing solution architectures and enable new solutions architectures while delivering new levels of performance (high-bandwidth, low-latency), software efficiency, power optimizations, and industry agility. Gen-Z technologies can be transparently inserted into any solution with no operating system or middleware software changes required.
Und weiter:
Q: Does Gen-Z require operating system or software middleware changes to work?
A: Gen-Z components and existing solution stacks can be transparently supported by unmodified operating systems and application middleware. For example:
- A Gen-Z memory component that supports DRAM or byte-addressable NVM media is mapped into an unmodified operating system the same way that a DRAM DIMM component is mapped. Once mapped, the Gen-Z memory component is accessed by applications just as any other DRAM memory component is accessed.
- A Gen-Z I/O component is mapped into an unmodified operating system as a conventional PCI device. Once mapped, the Gen-Z I/O component can be associated with any existing, unmodified I/O stack and accessed just as a PCI device is accessed. This enables a wide range of I/O device types to be supported through the Gen-Z interconnect.
- A Gen-Z block storage component is mapped into an unmodified operating system and unmodified storage stack either as a PCI NVM device (e.g., NVM Express) or through an I/O host bus adapter (e.g., SAS). Once mapped, the unmodified storage stack is used to access the Gen-Z block storage component as it would any other block storage component.
- A software NIC (an extension to the existing vNIC software implementations) is mapped into an unmodified operating system and unmodified IP network stack to enable traditional network applications to transparently operate across a Gen-Z topology. To support high-speed, low-latency communications, a Gen-Z provider library is mapped underneath the OpenFabrics’ OFI Libfabric infrastructure. This enables a broad set of advanced messaging applications to operate across Gen-Z, e.g., MPI, HMEM, Sockets, and many more.
All of the above enable Gen-Z components and existing solutions to be constructed using unmodified operating systems and application middleware. As components and solution stacks evolve to take advantage of advanced Gen-Z capabilities and topologies, software changes will be required. For example, rack-scale composable solutions will require new software to manage and coordinate shared memory pools.
Im Moment hört sich das so an, als könnte man über Gen-Z auch sogar einfach PCIe-Sockel anbinden im Zweifelsfall, wobei auch eigene modulare Stecker geplant sind. Ist damit hier eigentlich im falschen Thread hier.
Zuletzt bearbeitet:
tomturbo
Technische Administration, Dinosaurier
- Mitglied seit
- 30.11.2005
- Beiträge
- 9.450
- Renomée
- 664
- Standort
- Österreich
- Aktuelle Projekte
- Universe@HOME, Asteroids@HOME
- Lieblingsprojekt
- SETI@HOME
- Meine Systeme
- Xeon E3-1245V6; Raspberry Pi 4; Ryzen 1700X; EPIC 7351
- BOINC-Statistiken

- Mein Laptop
- Microsoft Surface Pro 4
- Details zu meinem Desktop
- Prozessor
- R7 5800X
- Mainboard
- Asus ROG STRIX B550-A GAMING
- Kühlung
- Alpenfön Ben Nevis Rev B
- Speicher
- 2x32GB Mushkin, D464GB 3200-22 Essentials
- Grafikprozessor
- Sapphire Radeon RX 460 2GB
- Display
- BenQ PD3220U, 31.5" 4K
- SSD
- 1x HP SSD EX950 1TB, 1x SAMSUNG SSD 830 Series 256 GB, 1x Crucial_CT256MX100SSD1
- HDD
- Toshiba X300 5TB
- Optisches Laufwerk
- Samsung Brenner
- Soundkarte
- onboard
- Gehäuse
- Fractal Design Define R4
- Netzteil
- XFX 550W
- Tastatur
- Trust ASTA mechanical
- Maus
- irgend eine silent Maus
- Betriebssystem
- Arch Linux, Windows VM
- Webbrowser
- Firefox + Chromium + Konqueror
- Internetanbindung
-
▼300
▲50

IEEE 802.3 ist Ethernet!
Die wollen also die Knoten schlicht per Ethernet verbinden.
Quasi eine Abwandlung von Infiniband.
Die wollen also die Knoten schlicht per Ethernet verbinden.
Quasi eine Abwandlung von Infiniband.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Naja, auf jeden Fall Paketorientiert, aber ich sehe da erstmal nicht mehr direkte Kompatibilität als den Layer 1, außer evtl. dieser Kompatibilitätsmodus für NICs. Aber ich gehe grundsätzlich erstmal nicht davon aus, dass die grundsätzlich z.B. MAC-Adressen für die Hardware verwenden werden - wobei das vielleicht keine schlechte Idee wäre.
tomturbo
Technische Administration, Dinosaurier
- Mitglied seit
- 30.11.2005
- Beiträge
- 9.450
- Renomée
- 664
- Standort
- Österreich
- Aktuelle Projekte
- Universe@HOME, Asteroids@HOME
- Lieblingsprojekt
- SETI@HOME
- Meine Systeme
- Xeon E3-1245V6; Raspberry Pi 4; Ryzen 1700X; EPIC 7351
- BOINC-Statistiken
- Mein Laptop
- Microsoft Surface Pro 4
- Details zu meinem Desktop
- Prozessor
- R7 5800X
- Mainboard
- Asus ROG STRIX B550-A GAMING
- Kühlung
- Alpenfön Ben Nevis Rev B
- Speicher
- 2x32GB Mushkin, D464GB 3200-22 Essentials
- Grafikprozessor
- Sapphire Radeon RX 460 2GB
- Display
- BenQ PD3220U, 31.5" 4K
- SSD
- 1x HP SSD EX950 1TB, 1x SAMSUNG SSD 830 Series 256 GB, 1x Crucial_CT256MX100SSD1
- HDD
- Toshiba X300 5TB
- Optisches Laufwerk
- Samsung Brenner
- Soundkarte
- onboard
- Gehäuse
- Fractal Design Define R4
- Netzteil
- XFX 550W
- Tastatur
- Trust ASTA mechanical
- Maus
- irgend eine silent Maus
- Betriebssystem
- Arch Linux, Windows VM
- Webbrowser
- Firefox + Chromium + Konqueror
- Internetanbindung
-
▼300
▲50
Nachdem der "physical layer" verwendet werden soll, stecken sie die Dinger offenbar mit Ethernetkabel und Switches zusammen.
Was natürlich den Vorteil der ermöglichten räumlichen Trennung hat.
Was natürlich den Vorteil der ermöglichten räumlichen Trennung hat.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Es wird nur niemand RJ45-Stecker da dran packen, weil normale Netzwerkhardware mind. Layer 2 oder Layer 3 Kompatibilität voraussetzt. Wie in der FAQ steht werden die eigene Stecker definieren, ich nehme an unterschiedliche für interne und externe Verwendung. Natürlich könnte man die neuen Stecker dann an normale CAT-Kabel krimpen. Intern wird das auch über normale Leiterbahnen angebunden, und evtl über Slots. Wenn die schlau sind, haben die auch etwas definiert um PCIe-Sockel mit Gen-Z anzubinden, welche mit PCIe-Hardware in einen Kompatibilitätsmodus schalten.
tomturbo
Technische Administration, Dinosaurier
- Mitglied seit
- 30.11.2005
- Beiträge
- 9.450
- Renomée
- 664
- Standort
- Österreich
- Aktuelle Projekte
- Universe@HOME, Asteroids@HOME
- Lieblingsprojekt
- SETI@HOME
- Meine Systeme
- Xeon E3-1245V6; Raspberry Pi 4; Ryzen 1700X; EPIC 7351
- BOINC-Statistiken
- Mein Laptop
- Microsoft Surface Pro 4
- Details zu meinem Desktop
- Prozessor
- R7 5800X
- Mainboard
- Asus ROG STRIX B550-A GAMING
- Kühlung
- Alpenfön Ben Nevis Rev B
- Speicher
- 2x32GB Mushkin, D464GB 3200-22 Essentials
- Grafikprozessor
- Sapphire Radeon RX 460 2GB
- Display
- BenQ PD3220U, 31.5" 4K
- SSD
- 1x HP SSD EX950 1TB, 1x SAMSUNG SSD 830 Series 256 GB, 1x Crucial_CT256MX100SSD1
- HDD
- Toshiba X300 5TB
- Optisches Laufwerk
- Samsung Brenner
- Soundkarte
- onboard
- Gehäuse
- Fractal Design Define R4
- Netzteil
- XFX 550W
- Tastatur
- Trust ASTA mechanical
- Maus
- irgend eine silent Maus
- Betriebssystem
- Arch Linux, Windows VM
- Webbrowser
- Firefox + Chromium + Konqueror
- Internetanbindung
-
▼300
▲50
Ethernet braucht 4 Paare, also 8 Adern, da wäre PCIe absoluter Overkill.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Also wenn ich das richtig sehe hat PCIe pro Lane auch nur 4 Pins mit zwei Seiten (also 8 Verbindungen) für die Daten ... Der Rest ist Stromversorgung, und ein bisschen generelle Verwaltung/Steuerung (Pin 1-13 + 18 + 82).
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Gute Güte hätte man nicht einfach FreedomFabric nehmen können? Da lief doch sowieso schon alles drüber .. jetzt nimmt man Ethernet und lässt da alles drüberlaufen irgendwie wird alle paar Halbjahre das Rad neu erfunden.
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.250
- Renomée
- 234
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Ethernet muss doch nicht zwingend Kupfer sein. Kann ja Glasfaser genauso sein.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
IEEE 802.3 ist Ethernet!
Die wollen also die Knoten schlicht per Ethernet verbinden.
Quasi eine Abwandlung von Infiniband.
Gute Güte hätte man nicht einfach FreedomFabric nehmen können? Da lief doch sowieso schon alles drüber .. jetzt nimmt man Ethernet und lässt da alles drüberlaufen irgendwie wird alle paar Halbjahre das Rad neu erfunden.
Ich denke dies war bisher nicht möglich:
Das adressiert die neuen Speichertechniken wie Xpoint und anderen NVRAM die dann eben nicht mehr Block basierend angesprochen werden.Memory operations such as loads and stores allow processors to access both volatile (ie DRAM) and non-volatile storage in the same efficient manner. Emerging Storage Class Memory (SCM) and rack level disaggregated memory pools, are example use-cases that benefit from a memory operation interconnect.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Durch die hitzige Diskussion im 3DCenter habe ich mir diese Auszüge von dir aus den FAQs zu GenZ erneut genauer angeschaut:
Dazu die HBCC Infos von der Vega Präsentation:
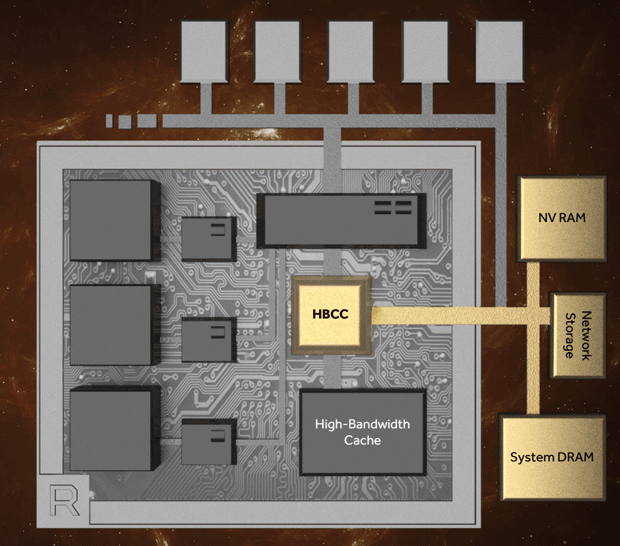
Und hier die Radeon Pro SSG:
http://www.pcgameshardware.de/Polaris-Codename-265453/News/Radeon-Pro-SSG-SSDs-1202716/
Ich schätze mal eine Vega basierende SSG wird demnach schon GenZ (HBCC+SSD) verbaut haben, wenn man die Eigenschaften zusammen zählt. Das ist deutlich früher als ich erwartet hätte.
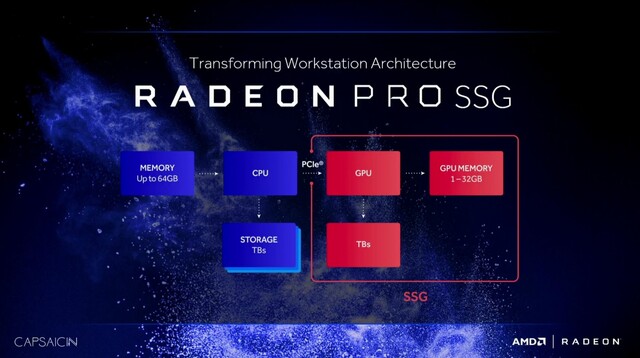
Bei den fett markierte Teilen ist mir aufgefallen, dass sie teilweise den HBCC von Vega beschreiben und einen Teil des SSD Controllers der auf der Radeon Pro SSG verbaut ist um die SSDs direkt in der GPU anzubinden.Interessant finde ich die paar technischen Details zu Gen-Z in der FAQ. Zum Beispiel:
Und weiter:
Q: Does Gen-Z require operating system or software middleware changes to work?
A: Gen-Z components and existing solution stacks can be transparently supported by unmodified operating systems and application middleware. For example:
- A Gen-Z memory component that supports DRAM or byte-addressable NVM media is mapped into an unmodified operating system the same way that a DRAM DIMM component is mapped. Once mapped, the Gen-Z memory component is accessed by applications just as any other DRAM memory component is accessed.
- A Gen-Z I/O component is mapped into an unmodified operating system as a conventional PCI device. Once mapped, the Gen-Z I/O component can be associated with any existing, unmodified I/O stack and accessed just as a PCI device is accessed. This enables a wide range of I/O device types to be supported through the Gen-Z interconnect.
- A Gen-Z block storage component is mapped into an unmodified operating system and unmodified storage stack either as a PCI NVM device (e.g., NVM Express) or through an I/O host bus adapter (e.g., SAS). Once mapped, the unmodified storage stack is used to access the Gen-Z block storage component as it would any other block storage component.
- A software NIC (an extension to the existing vNIC software implementations) is mapped into an unmodified operating system and unmodified IP network stack to enable traditional network applications to transparently operate across a Gen-Z topology. To support high-speed, low-latency communications, a Gen-Z provider library is mapped underneath the OpenFabrics’ OFI Libfabric infrastructure. This enables a broad set of advanced messaging applications to operate across Gen-Z, e.g., MPI, HMEM, Sockets, and many more.
All of the above enable Gen-Z components and existing solutions to be constructed using unmodified operating systems and application middleware. As components and solution stacks evolve to take advantage of advanced Gen-Z capabilities and topologies, software changes will be required. For example, rack-scale composable solutions will require new software to manage and coordinate shared memory pools.
Dazu die HBCC Infos von der Vega Präsentation:
Und hier die Radeon Pro SSG:
http://www.pcgameshardware.de/Polaris-Codename-265453/News/Radeon-Pro-SSG-SSDs-1202716/
Die Webseite anandtech.com hatte auf der SIGGRAPH die Gelegenheit, weitere Informationen zur Radeon Pro SSG einzuholen. Demnach wird aktuell noch ein PEX8747-Brückenchip eingesetzt, um zwei Samsung SSD 950 Pro (je 512 GB) mit jeweils vier PCI-Express-3.0-Bahnen an die GPU anzubinden. Der Flashspeicher wird als RAID-0 organisiert. Im Prototypenstatus erkennt das Betriebssystem den SSG-Speicher sehr wohl noch. Bis 2017 soll sich an dem Konzept noch einiges ändern.
Ich schätze mal eine Vega basierende SSG wird demnach schon GenZ (HBCC+SSD) verbaut haben, wenn man die Eigenschaften zusammen zählt. Das ist deutlich früher als ich erwartet hätte.
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Interessantes Patent von AMD: Computer architecture using rapidly reconfigurable circuits and high-bandwidth memory interfaces
Auch bei Google: http://www.google.com/patents/US20160380635
FPGA mit HBM auf Interposer. Schnell rekonfigurierbar mit mehreren unabhängigen FPGA-Blöcken.
Auch bei Google: http://www.google.com/patents/US20160380635
FPGA mit HBM auf Interposer. Schnell rekonfigurierbar mit mehreren unabhängigen FPGA-Blöcken.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Interessantes Patent von AMD: Computer architecture using rapidly reconfigurable circuits and high-bandwidth memory interfaces
Auch bei Google: http://www.google.com/patents/US20160380635
FPGA mit HBM auf Interposer. Schnell rekonfigurierbar mit mehreren unabhängigen FPGA-Blöcken.
Ich fand das auch interessant. Es scheint aber eine logische Fortführung vorheriger Patente zu sein, wie diesem hier:
https://www.google.com/patents/US20140176187
Das eine Bild davon ging auch durch die Medien.
G
Gast29012019_2
Guest
Inwieweit kann man das Funktionsprinzip der Threads und Intel HT vergleichen, ist es identisch von der Funktionsweise ?
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Was ist Intels HT in diesem Zusammenhang? Und von welchen Threads sprichst du hier?
G
Gast29012019_2
Guest
Einfach ausgedrückt wie funktioniert AMDs (SMT) Technik von Zen zu der von Intel SMT (HT) Technologie von Intel.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Das hat mit diesem Thema hier nichts zu tun. Falscher Thread. Hier geht es um Interposer von AMD.
HT=Hypertransport von AMD.
HT=Hypertransport von AMD.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 747
- Antworten
- 0
- Aufrufe
- 723
- Antworten
- 879
- Aufrufe
- 70K
- Antworten
- 1
- Aufrufe
- 2K