App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD Interposer Strategie - Zen, Fiji, HBM und Logic ICs
- Ersteller Complicated
- Erstellt am
HMC auf Knights Landing soll von Intel zukünftig durch HBM ersetzt werden auch zukünftige auf EMIB basierende Designs sollen HBM nutzen können:
Bei Knights Landing wird gar nichts ersetzt er sagt nur das in zukünftigen Produkten HBM benutzt werden wird da es mehr Bandbreite liefert und besser verfügbar ist.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
"HMC AUF Knights Landig soll ZUKÜNFTIG"...also bei den Folgeprodukten...Lesen bitte. Da steht auf Knights Landing wird HMC genutzt der zukünftig durch HBM wohl ersetzt wird.
"soll" drückt zur Genüge aus, dass dies nicht gesichert ist. Das alles in einem deutschen komprimierten Satz scheint nicht jedem verständlich zu sein.
"soll" drückt zur Genüge aus, dass dies nicht gesichert ist. Das alles in einem deutschen komprimierten Satz scheint nicht jedem verständlich zu sein.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.738
- Renomée
- 2.497
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Es ist aber auch ziemlich blauäugig anzunehmen das ein zu anderen Speicher Standards komplett inkompatibler Speicher Standard nur für eine einzige Produktgeneration genommen und von vorn herein geplant war ab der nächsten Generation auf einen komplett anderen Speicher zu setzen.
Locuza
Commodore Special
- Mitglied seit
- 03.03.2011
- Beiträge
- 351
- Renomée
- 3
Knights Landing ist der Codename für einen spezifischen Chip und keine Bezeichnung für eine allgemeine Produktlinie."HMC AUF Knights Landig soll ZUKÜNFTIG"...also bei den Folgeprodukten...Lesen bitte. Da steht auf Knights Landing wird HMC genutzt der zukünftig durch HBM wohl ersetzt wird.
"soll" drückt zur Genüge aus, dass dies nicht gesichert ist. Das alles in einem deutschen komprimierten Satz scheint nicht jedem verständlich zu sein.
Korrekt formuliert würde man schreiben, dass zukünftige Xeon Phi Beschleuniger wahrscheinlich HMC durch HBM ersetzen werden.
Knights Landing ist der Codename für einen spezifischen Chip und keine Bezeichnung für eine allgemeine Produktlinie.
Korrekt formuliert würde man schreiben, dass zukünftige Xeon Phi Beschleuniger wahrscheinlich HMC durch HBM ersetzen werden.
So siehts aus du musst dich richtig ausdrücken und nicht mir vorwerfen nicht richtig zu lesen...
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Danke dann werde ich das zukünftig verbessern. Ich hoffe dennoch es wurde deutlich was ich ausdrücken wollte.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Hier sind Fotos zu finden von einem Fiji-Chip der zerlegt wurde samt Interposer Die Dieshots sind sehenswert:
http://www.forum-3dcenter.org/vbulletin/showpost.php?p=11154123&postcount=13917
http://www.forum-3dcenter.org/vbulletin/showpost.php?p=11154123&postcount=13917
Beim auflegen von GPUs/CPUs mit Chip nach unten auf eine ca 400°C heiße Herdplatte, sprengen sich die Chips nach ca. 20 sec. vom Trägermaterial normalerweise ab. Hier beim Fiji mitsamt Interposer war dies ein wenig anders. Der Interposer zerbrach einfach und haftete weiterhin am Trägermaterial. Der Fiji Chip haftete ebenfalls noch am Interposer. Nach fast der doppelten Zeit als üblich lößten sich auf einmal die HBM-Stacks und die Fiji-GPU. Der Interposer haftete noch halb am Trägermaterial.

cyrusNGC_224
Grand Admiral Special
- Mitglied seit
- 01.05.2014
- Beiträge
- 5.924
- Renomée
- 117
- Aktuelle Projekte
- POGS, Asteroids, Milkyway, SETI, Einstein, Enigma, Constellation, Cosmology
- Lieblingsprojekt
- POGS, Asteroids, Milkyway
- Meine Systeme
- X6 PII 1090T, A10-7850K, 6x Athlon 5350, i7-3632QM, C2D 6400, AMD X4 PII 810, 6x Odroid U3
- BOINC-Statistiken

Ebenfalls im 3dCenter behauptet jemand, es gäbe Gemunkel über Probleme mit dem GF Prozess und schließlich auch mit ZEN und Vega.
http://www.forum-3dcenter.org/vbulletin/showthread.php?p=11153522#post11153522
Wenn dem so wäre, warum versicherte selbst Su erneut, dass ZEN voll im Plan liege und die eigenen Erwartungen sogar noch übertroffen wurden?
http://www.forum-3dcenter.org/vbulletin/showthread.php?p=11153522#post11153522
Wenn dem so wäre, warum versicherte selbst Su erneut, dass ZEN voll im Plan liege und die eigenen Erwartungen sogar noch übertroffen wurden?
Stefan Payne
Grand Admiral Special
Schaffe...
Wer dem glaubt, glaubt auch Charlie und Fuad...
Wobei die deutlich bessere Quellen haben und vertrauenswürdiger sind...
Sorry, aber das ist echt nur wert ignoriert zu werden.
Wer dem glaubt, glaubt auch Charlie und Fuad...
Wobei die deutlich bessere Quellen haben und vertrauenswürdiger sind...
Sorry, aber das ist echt nur wert ignoriert zu werden.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Habe bisher in mehreren Firmen als Softwareentwickler gearbeitet. Über die Ideen der "Oberen" hat man überall den Kopf geschüttelt und geflucht, dass die Software halbgar raus muss. Funktionierte halt halbwegs, aus Entwicklersicht aber unbefriedigend.
Nach außen priesen die Verkäufer und die "Oberen" immer, welch tolles neues Produkt sie nun haben etc.
Also überall das gleiche. Würde daher nichts auf das Geschwätz der Angestellten geben, so lange nicht ein konkreter Soll-Ist Vergleich auf dem Tisch liegt.
Nach außen priesen die Verkäufer und die "Oberen" immer, welch tolles neues Produkt sie nun haben etc.
Also überall das gleiche. Würde daher nichts auf das Geschwätz der Angestellten geben, so lange nicht ein konkreter Soll-Ist Vergleich auf dem Tisch liegt.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Wahrscheinlich weil sie es besser weis als ein Student der erzählt an seiner Uni werde dies oder jenes spekuliert. Das ist ja das lächerlichste an Quelle das es je gab.Wenn dem so wäre, warum versicherte selbst Su erneut, dass ZEN voll im Plan liege und die eigenen Erwartungen sogar noch übertroffen wurden?
Also beim rx480 hatte ich schon das Gefühl das Designziel und Prozess nicht 100% passten sonst wäre die PCie Geschichte wohl nicht passiert und Werbung war das sicherlich nicht.
Nur ob das auf Zen bzw CPU´s übertragbar ist halte ich für fraglich und vermutlich wird auch GF den Prozess eher besser in den Griff bekommen. Aber das vieles nicht Perfekt läuft glaub ich sofort sonst würde Intel nicht auch einige Zwischenschritte im selben Node machen.
Nur ob das auf Zen bzw CPU´s übertragbar ist halte ich für fraglich und vermutlich wird auch GF den Prozess eher besser in den Griff bekommen. Aber das vieles nicht Perfekt läuft glaub ich sofort sonst würde Intel nicht auch einige Zwischenschritte im selben Node machen.
Oi!Olli
Grand Admiral Special
- Mitglied seit
- 24.12.2006
- Beiträge
- 16.597
- Renomée
- 966
- Mein Laptop
- HP ProBook x360 435 G7/HP Victus 16
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R7 9800X3D
- Mainboard
- GIGABYTE X870 Eagle WIFI7
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x 32 GB CORSAIR Vengeance DDR5 RAM 6000MHz CL30
- Grafikprozessor
- INNO3D GeForce RTX 5070 Ti X3 OC 16GB Grafikkarte
- Display
- Samsung Odyssey OLED G6 LS27DG612SUXEN
- SSD
- Samsung 990 Pro 4 TB, Samsung 980 Pro 2 TB
- HDD
- Samsung TB, 2x2 TB 1x3 TB 2x8 TB
- Soundkarte
- Soundblaster Z
- Gehäuse
- Fractal Design Meshify 2 XL Black
- Netzteil
- BeQuiet Straight Pure Power 12 M 850 Watt
- Tastatur
- HyperX Alloy Elite 2
- Maus
- Logitech G403
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Opera 116 (der Browser aktualisiert sich natürlich immer)
- Verschiedenes
- X-Box One Gamepad, MS Sidewinder Joystick
Die Geschichte war ja alles in allem auch nicht sooo bewegend. Man hat den möglichen Shitstorm wohl unterschätzt.
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Enabling Interposer-based Disintegration of Multi-Core Processors
Zum PDF: https://tspace.library.utoronto.ca/bitstream/1807/70378/3/Kannan_Ajaykumar_201511_MAS_thesis.pdf
Highlights:
Kostenanalyse für monolithischen 64-core vs. 16x4-core

Es zeigt, dass durch die kleineren Dies mehr fertige SoCs pro Wafer entstehen bei selber Defektrate.
Ausserdem können die kleinen Dies durch Speedbinning für verschiedene Produkte genutzt werden. Diese Grafik zeigt die Möglichkeiten für 400 MHz mehr Takt durch das binning:

Anstatt bei 2,0-2,1 GHz die meisten funktionierenden SoCs zu haben, erhält man durch die Sortierung der jeweils 16 schnellsten 4-core Dies eine Spannbreite wo es sogar bei 2,8 GHz noch 10 SoCs/Wafer ergibt. Die meisten SoCs im Bereich 2,3-2,6 GHz.
Zum PDF: https://tspace.library.utoronto.ca/bitstream/1807/70378/3/Kannan_Ajaykumar_201511_MAS_thesis.pdf
Highlights:
Kostenanalyse für monolithischen 64-core vs. 16x4-core
Es zeigt, dass durch die kleineren Dies mehr fertige SoCs pro Wafer entstehen bei selber Defektrate.
Ausserdem können die kleinen Dies durch Speedbinning für verschiedene Produkte genutzt werden. Diese Grafik zeigt die Möglichkeiten für 400 MHz mehr Takt durch das binning:
Anstatt bei 2,0-2,1 GHz die meisten funktionierenden SoCs zu haben, erhält man durch die Sortierung der jeweils 16 schnellsten 4-core Dies eine Spannbreite wo es sogar bei 2,8 GHz noch 10 SoCs/Wafer ergibt. Die meisten SoCs im Bereich 2,3-2,6 GHz.
Anhänge

Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Na, da hat sich aber jemand Mühe gegeben das zu bestätigen, was ich schon seit zwei oder drei Jahren sage ... ")
cyrusNGC_224
Grand Admiral Special
- Mitglied seit
- 01.05.2014
- Beiträge
- 5.924
- Renomée
- 117
- Aktuelle Projekte
- POGS, Asteroids, Milkyway, SETI, Einstein, Enigma, Constellation, Cosmology
- Lieblingsprojekt
- POGS, Asteroids, Milkyway
- Meine Systeme
- X6 PII 1090T, A10-7850K, 6x Athlon 5350, i7-3632QM, C2D 6400, AMD X4 PII 810, 6x Odroid U3
- BOINC-Statistiken
Was mich wundert, wird denn diese Sortierung, das Binning nicht schon immer gemacht?
Wie hätte man denn sonst die besten und die schlechtesten anbieten können?
Wie hätte man denn sonst die besten und die schlechtesten anbieten können?
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.423
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
Was mich wundert, wird denn diese Sortierung, das Binning nicht schon immer gemacht?
Wie hätte man denn sonst die besten und die schlechtesten anbieten können?
Monolithische Chips kannst Du nur als ganzes binnen, mit entsprechend schlechtem Ergebnis. Setzt man aber per Interposer jetzt z.B. 8 Quadcore Dies zu einem 32 Core Chip zusammen, dann kann jeder der 8 Quadcore Dies besser durch Binning selektiert werden und dadurch der Gesamt-Chip entsprechend höher takten, da man sich nicht nach dem schlechtesten von allen 32 Cores richten muss, sondern nur nach dem schlechtesten Quadcore Die.
Zudem man dann gezielt selektierte Quadcore Dies miteinander kombinieren kann (welche z.B. alle 2.6Ghz geschafft haben).
cyrusNGC_224
Grand Admiral Special
- Mitglied seit
- 01.05.2014
- Beiträge
- 5.924
- Renomée
- 117
- Aktuelle Projekte
- POGS, Asteroids, Milkyway, SETI, Einstein, Enigma, Constellation, Cosmology
- Lieblingsprojekt
- POGS, Asteroids, Milkyway
- Meine Systeme
- X6 PII 1090T, A10-7850K, 6x Athlon 5350, i7-3632QM, C2D 6400, AMD X4 PII 810, 6x Odroid U3
- BOINC-Statistiken
Achso, auf das Die bezogen. So macht das Sinn, danke.
MacroWelle
Captain Special
- Mitglied seit
- 15.02.2008
- Beiträge
- 236
- Renomée
- 1
Naja je mehr Chips auf dem Interposer, desto mehr Kommunikation über diesen. Kommunikation auf dem Chips wird nahezu immer schneller sein. Das ist in dem Auszug aus dem PDF oben gar nicht bedacht. Es läuft also eher auf einen Einzelchip moderater Größe hinaus, bei dem die Anzahl SoCs (siehe Post 215) aus einem Wafer relativ hoch ist, in dem genannten Beispiel z. B. 8 Kerne. Die kann man dann ja auch besser einzeln verkaufen ")
Einzige Variante wo noch interessant wäre ist, wenn die Einzelchips intern zwischen den Kernen/Clustern gar nicht kommunizieren sondern nur über den Interposer. Also wenn man z. B. bei Zen 4-Kern-Chips baut und dadurch keine Kommunikation zwischen Clustern innerhalb des Chips braucht. Das sehe ich aber nicht, weil einen 8-Kerner hat man ja schon. Ich tippe also für Server/Workstation erst mal auf 8-Kerner und maximal 4 Chips in einer CPU.
Einzige Variante wo noch interessant wäre ist, wenn die Einzelchips intern zwischen den Kernen/Clustern gar nicht kommunizieren sondern nur über den Interposer. Also wenn man z. B. bei Zen 4-Kern-Chips baut und dadurch keine Kommunikation zwischen Clustern innerhalb des Chips braucht. Das sehe ich aber nicht, weil einen 8-Kerner hat man ja schon. Ich tippe also für Server/Workstation erst mal auf 8-Kerner und maximal 4 Chips in einer CPU.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Die Bandbreite und Latenzen auf Interposern sind mehr als ausreichend für CPUs. Das Thema hatten wir schon mehrfach. Selbst im schlechtesten Fall immer noch deutlich besser als mit mehr Sockeln zu arbeiten ...
Dresdenboy
Redaktion
☆☆☆☆☆☆
Das kommt mir bekannt vor. Damals hatte ich neben der Arbeit auch das Paper hier gefunden: http://www.eecg.toronto.edu/~enright/Kannan_MICRO48.pdfEnabling Interposer-based Disintegration of Multi-Core Processors
Zum PDF: https://tspace.library.utoronto.ca/bitstream/1807/70378/3/Kannan_Ajaykumar_201511_MAS_thesis.pdf
Auf jeden Fall solltet ihr euch auch mal die Topologien anschauen ("Double Butterdonut" usw.).
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
In dem PDF, welches verlinkt ist, wird das ausführlich analysiert und auch die unterschiedlichen Meshes die auf einem monolithischen Chip, auf einem Interposer oder auch im gemischten Modus das NoC bilden können. Es wurden sogar unterschiedliche Lastszenarien (Speicher, GPU, Inter-Kern Kommunikation) zu den verschiedenen Meshes getestet mit unterschiedlichen Ergebnissen. Es geht hier allerdings niemals um fehlende Bandbreite (denn die ist durch den Interposer immer zu genüge da), sondern zumeist um Latenzen die entstehen bei Kollisionen in der Kommunikation und die Anzahl der Hops zwischen den Knoten im NoC. In jedem Fall wird ein "ButterDonut" Mesh, welches mit einem aktiven Interposer ebenfalls verbunden ist als optimal empfohlen.Naja je mehr Chips auf dem Interposer, desto mehr Kommunikation über diesen. Kommunikation auf dem Chips wird nahezu immer schneller sein. Das ist in dem Auszug aus dem PDF oben gar nicht bedacht.
Da aktive Interposer ebenfalls Routing-Logik erhalten ist zum einen die Yieldrate deutlich schlechter und zum anderen auch die Herstellung teurer, was die Kosten nach oben treibt. Allerdings gibt es hier auch einen Zwischenweg, der in dem Paper ebenfalls aufgezeigt wird.
Wie man der Tabelle entnehmen kann würde ein 100% aktiver Interposer in dieser Größe, je nach Defektrate, Extrem schlechte Yields bieten.
Die Lösung ist den Interposer nur Teilaktiv zu machen. Für ein Interposerübergreifendes NoC wie in dem ersten Bild würden maximal 10% benötigt, eher weniger wenn man optimiert. Die Yields würden dennoch über 90% liegen.
Die Kostenanalyse im Vergleich zur geopferten Latenz zeigt welche Kompromisse man eingehen muss:
Die Kosten mit 4-Core Dies sinken um ca. 20%, während man ca. 22% Latenz als Penalty erhält. Das könnte die Kostenersparnis durchaus rechtfertigen.
--- Update ---
Ja ist der selbe Inhalt wie ich eben gesehen habeDas kommt mir bekannt vor. Damals hatte ich neben der Arbeit auch das Paper hier gefunden: http://www.eecg.toronto.edu/~enright/Kannan_MICRO48.pdf
") Danke.
Danke.Anhänge


BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Abgesehen davon kann man ja erstmal davon ausgehen, dass AMD keine wilden Modelle mit super vielen kleinen Chips auf den Markt bringen wird. Der Größte dürfte aller Wahrscheinlichkeit erstmal Naples mit vier Achtkern Summit Ridge Modulen sein, welche dann vermutlich als 2x2 angeordnet sind - der optimalen Wege halber.
Wobei es dann eigentlich interessant wäre zwei spiegelverkehrte Chip-Varianten zu haben, damit man immer einen sehr kurzen Weg hat.
Etwa so:
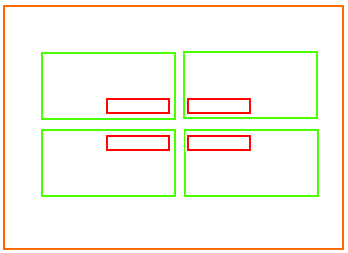
Wobei es dann eigentlich interessant wäre zwei spiegelverkehrte Chip-Varianten zu haben, damit man immer einen sehr kurzen Weg hat.
Etwa so:
Complicated
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Da alle CPU-Kerne an das NoC-Mesh angebunden sein müssen, ist das als eine Ebene tiefer vorzustellen.
Dein Vorschlag ist auf Micro-Bump-Ebene sinnvoll wenn ein passiver Interposer zum Einsatz kommt. Allerdings benötigst du zusätzlich noch Verbindungen zum Speicher die ja wiederum außerhalb am Interposer angeordnet sind.
Daher bekräftige ich nochmals den Rat von Dresdenboy einen Blick in dem PDF auf die verschiedenen NoC-Meshes zu werfen.
Das geht nämlich über die TSV-Anbindung bei Fiji<->HBM hinaus.
Dein Vorschlag ist auf Micro-Bump-Ebene sinnvoll wenn ein passiver Interposer zum Einsatz kommt. Allerdings benötigst du zusätzlich noch Verbindungen zum Speicher die ja wiederum außerhalb am Interposer angeordnet sind.
Daher bekräftige ich nochmals den Rat von Dresdenboy einen Blick in dem PDF auf die verschiedenen NoC-Meshes zu werfen.
Das geht nämlich über die TSV-Anbindung bei Fiji<->HBM hinaus.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ich bin zu 99% sicher, dass Snowy Owl und Naples einen passiven Interposer nutzen werden. Und kürzere Verbindungen sind immer sinnvoll - die Frage ist nur was ein "spiegeln" extra kosten würde. Wobei eigentlich die Frage nach dem genauen Interconnect Fabric an erster Stelle stehen müsste. Ist das zum Beispiel eine Art Bussystem, oder ein Point-to-Point-System? Und dann müsste man wissen ob das IC-Fabric tatsächlich an einer Stelle des Chips konzentriert ist, mit seinen Verbindungen, oder ob das auf jeden Kern aufgeteilt ist. Oder ist jeder Kern mit einem Switch auf dem Chip verbunden, während dann mehrere Switches über den Interposer verbunden sind? Abgesehen davon sollte jegliche zusätzliche Logik zwischen zwei Kernen die Latzenz erhöhen, und nicht verringern, da mit Logik Schaltvorgänge verbunden sind.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 747
- Antworten
- 0
- Aufrufe
- 723
- Antworten
- 879
- Aufrufe
- 70K
- Antworten
- 1
- Aufrufe
- 2K