App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD - Zen 4 /4c - 5 nm/4 nm - Genoa, Bergamo, Siena, Raphael, Phoenix Point
- Ersteller pipin
- Erstellt am
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.425
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
Wohl eher nicht, würde auch keinen Sinn machen, dann könnte man ja gleich komplett zu APUs schwenken.
Aus dem 3Dcenter Artikel:
Aus dem 3Dcenter Artikel:
Eher interessant an diesen Meldungen sind aber somit die Nebenpunkte: So wurde eine iGPU sowie die 5nm-Fertigung für Raphael bestätigt, die iGPU dürfte allerdings vermutlich eine Sparversion sein und keineswegs in die Performanceklasse der bisherigen AMD-APUs gehen.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Eine reduzierte iGPU schließt das IMHO nicht aus, sondern könnte durchaus gewollt sein, wegen den verbauten GPU-Controllern auf jeder GPU um eine gemeinsame Nutzung des GPU-Chiplets (oder später auch mehrere im Server) zu skalieren, möglicherweise auch auf eine verbaute dGPU. Da könnte es gute Gründe geben, je nach dem was AMD da konstruiert hat bei der Architektur oder in der nächsten Ausbaustufe plant.

Prozessorgerüchte zu AMD Ryzen 6000: Maximal 16 CPU-Kerne und 170 Watt
AMDs Desktop-CPU-Baureihe "Raphael" soll ohne Kernerhöhung, aber mit Zen-4-Architektur und 5-Nanometer-Technik erscheinen.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Wäre aber ein schlechter Tradeoff für AMDs Portfolio

 www.zdnet.de
www.zdnet.de
Scharfe Kritik an Intel AVX 512 | ZDNet.de
Der Befehlssatz Intel Advanced Vector Extensions 512 (Intel AVX-512) hat offenbar Probleme. Linux-Urgestein Linus Torvalds wünscht ihm sogar „einen schmerzhaften Tod.“
www.zdnet.de
Torvalds feuerte seine Kritik am Intel Advanced Vector Extensions 512 (Intel AVX-512) in einem Mailinglisten-Chat ab. Er reagierte damit auf einen Artikel von Michael Larabel. Dieser bemängelte die Unterstützung für AVX-512 in den Compiler-Anweisungen, die Intel für Alder Lake, seine 2021-Prozessoren für den Desktop, aktiviert hat, in der GNU Compiler Collection 11. Intels zukünftige Xeon Sapphire Roads-Prozessoren unterstützen immer noch AVX-512.
„Ich hoffe, dass AVX-512 einen schmerzhaften Tod stirbt und dass Intel beginnt, echte Probleme zu beheben, anstatt mit Tricks zu versuchen, Benchmarks zu erstellen, auf denen sie gut aussehen können“, schrieb Torvalds. Torvalds beanstandet Intels Fokus auf FP-Benchmarks und die Leistung seiner Prozessoren auf Supercomputern oder Hochleistungscomputern (HPCs).
„Ich hoffe, dass Intel zu den Grundlagen zurückkehrt: ihren Prozess wieder zum Laufen bringt und sich mehr auf normalen Code konzentriert, der nicht HPC oder ein anderer sinnloser Sonderfall ist.“ Er merkt an, dass in der Blütezeit von x86 Intels Rivalen bei FP-Lasten immer besser abgeschnitten haben.
„Intels FP-Leistung war relativ gesehen schlecht, und es war nicht ein Jota wichtig. Denn außerhalb der Benchmarks interessierte sich absolut niemand dafür“, erklärte Torvalds. „Dasselbe gilt jetzt – und in Zukunft – weitgehend auch für AVX-512. Ja, man kann Dinge finden, die es betrifft. Nein, diese Dinge verkaufen keine Maschinen im großen Rahmen.“ Die AVX512 habe echte Nachteile. „Ich würde es viel lieber sehen, dass das Transistor-Budget für andere Dinge verwendet wird, die viel relevanter sind. Auch wenn es immer noch FP-Mathematik ist (in der GPU, statt AVX-512). Oder geben Sie mir einfach mehr Kerne (mit guter Single-Thread-Leistung, aber ohne den Müll wie beim AVX-512), wie es AMD getan hat.“
[...]
Cloudflare: „AVX-512 abschalten“
Neben Torvalds und Phoronix hat auch die Web-Infrastruktur-Firma Cloudflare sich mit AVX-512 beschäftigt. Nach Leistungsanalysen emfiehlt sie Kunden, die die Befehlssatzerweiterung nicht für Hochleistungsaufgaben benötigen, auf dem Server und Desktop zu AVX-512 zu deaktivieren, um eine „versehentliche“ Drosselung zu vermeiden.
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.884
- Renomée
- 39
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Ich denke es geht viel um die Leistungsaufnahme AVX auf CPU gegen OpenCL auf der CU/CUDA/Tensor.
Runtergebrochen von der GPU braucht eine CU ca. 2-4 Watt und die ist bei Parallelisierung viel schneller. AMD könnte in diesem Bereich was in der Pipeline haben. Die CU als Beschleuniger und Spielwiese für Optimierungen oder wie weit das man sie aufbohrt. Optimal wäre wenn CPU und CU über den L3 zusammenarbeiten könnten. Wäre der kürzeste Weg..
Runtergebrochen von der GPU braucht eine CU ca. 2-4 Watt und die ist bei Parallelisierung viel schneller. AMD könnte in diesem Bereich was in der Pipeline haben. Die CU als Beschleuniger und Spielwiese für Optimierungen oder wie weit das man sie aufbohrt. Optimal wäre wenn CPU und CU über den L3 zusammenarbeiten könnten. Wäre der kürzeste Weg..
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.884
- Renomée
- 39
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Wenn AMD das mit dem abgeschliffenen Die bei Zen 4 umsetzt werden die Ausgleichblätchen eine bessere wärmeleitfähigkeit haben als das Silizium. Das hochsetzen der TDP auf 170 Watt spricht auf jeden Fall dafür. Wenn da ein 16 Kerner im allCore mit über 4,5 GHz austakten kann. Da geht die Post ab.
Wenn ich von meinen Zen2 ausgeht der darf auf auto sich 60 Watt für die Kerne gännen. 90 Watt für die Kerne würde eine um 33% bessere Wärmeableitung entsprechen.
Wenn ich von meinen Zen2 ausgeht der darf auf auto sich 60 Watt für die Kerne gännen. 90 Watt für die Kerne würde eine um 33% bessere Wärmeableitung entsprechen.
hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.761
- Renomée
- 286
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Von 60 auf 90 sind 50% Steigerung ")
Entspräche ziemlich genau dessen, wenn man Silizium durch Alu ersetzt..
Entspräche ziemlich genau dessen, wenn man Silizium durch Alu ersetzt..
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ja gut, 2-4W aber die Single Core Leistung willst du nicht wissen, die ist richtig mies bei einer CU (GPU Seite).Ich denke es geht viel um die Leistungsaufnahme AVX auf CPU gegen OpenCL auf der CU/CUDA/Tensor.
Runtergebrochen von der GPU braucht eine CU ca. 2-4 Watt und die ist bei Parallelisierung viel schneller. AMD könnte in diesem Bereich was in der Pipeline haben. Die CU als Beschleuniger und Spielwiese für Optimierungen oder wie weit das man sie aufbohrt. Optimal wäre wenn CPU und CU über den L3 zusammenarbeiten könnten. Wäre der kürzeste Weg..
Das macht AMD schon via Infinity Fabric - GPU und CPU Speicher koppeln, was meinst wozu SAM gut ist ?
Peet007
Admiral Special
- Mitglied seit
- 30.09.2006
- Beiträge
- 1.884
- Renomée
- 39
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 8700G
- Mainboard
- MSI Mortar B650
- Kühlung
- Wasser
- Speicher
- 32 GB
- Grafikprozessor
- IGP
- Display
- Philips
- Soundkarte
- onBoard
- Netzteil
- 850 Watt
- Betriebssystem
- Manjaro / Ubuntu
- Webbrowser
- Epiphany
Irgendeinen Grund muss es haben warum Intel/AMD am APU Konzept festhalten.
Kommt auch darauf an welche Berechnung das ansteht. Ein kleiner Intel NUC 4Kerne/24CU wenn ich mir richtig erinnere. Der schafft bei Einstein@home immer noch mehr Output als ein 64 Kerner TR. Wenn man es hinbekommt alles über den L3 zu verbinden spart man sich PCIe.
Kommt auch darauf an welche Berechnung das ansteht. Ein kleiner Intel NUC 4Kerne/24CU wenn ich mir richtig erinnere. Der schafft bei Einstein@home immer noch mehr Output als ein 64 Kerner TR. Wenn man es hinbekommt alles über den L3 zu verbinden spart man sich PCIe.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.225
- Renomée
- 536
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Irgendeinen Grund muss es haben warum Intel/AMD am APU Konzept festhalten.
Kommt auch darauf an welche Berechnung das ansteht. Ein kleiner Intel NUC 4Kerne/24CU wenn ich mir richtig erinnere. Der schafft bei Einstein@home immer noch mehr Output als ein 64 Kerner TR. Wenn man es hinbekommt alles über den L3 zu verbinden spart man sich PCIe.
Hast du vollkommen Recht, es liegt unter anderem am zweiten PCB also der Steckkarte an sich.
Da ist alles doppelt vorhanden was die Spannungsversorgung angeht.
Eine APU hat die selben VRM wie die CPU, ohne extra Platine & VRMs & Buchsen & Gehäuse & Lüfter & Kühler...
An sich sind die 170W TDP für ein APU SoC nicht mehr so weit weg.
Es gibt immer noch user die das Display am Mainboard anschließen, anstatt an der diskreten GPU. (Toter-Winkel... usw, usf.)
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
AMD Zen 4: Epyc-Prozessoren mit 96 CPU-Kernen und AVX-512
96 Kerne (6x8) für SP5, mit 12-Kanal DDR5, PCIe Gen5/Gen-Z und AVX-512

96 Kerne (6x8) für SP5, mit 12-Kanal DDR5, PCIe Gen5/Gen-Z und AVX-512
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken

- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Andere Seiten vermerken das diese Leaks man dem Gigabytehack zu "verdanken" hat.
Zuletzt bearbeitet:
Mente
Grand Admiral Special
- Mitglied seit
- 23.05.2009
- Beiträge
- 3.671
- Renomée
- 135
- Aktuelle Projekte
- constalation astroids yoyo
- Lieblingsprojekt
- yoyo doking
- Meine Systeme
- Ryzen 3950x
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD 5800X3D
- Mainboard
- Asus ROG Crosshair VIII Dark Hero
- Kühlung
- Headkiller IV
- Speicher
- 3800CL14 G.Skill Trident Z silber/rot DIMM Kit 32GB, DDR4-3600, CL15-15-15-35 (F4-3600C15D-16GTZ)
- Grafikprozessor
- AMD Radeon RX 6900 XT Ref. @Alphacool
- Display
- MSI Optix MAG27CQ
- SSD
- SN8502TB,MX5001TB,Vector150 480gb,Vector 180 256gb,Sandisk extreme 240gb,RD400 512gb
- HDD
- n/a
- Optisches Laufwerk
- n/a
- Soundkarte
- Soundblaster X4
- Gehäuse
- Phanteks Enthoo Pro 2 Tempered Glass
- Netzteil
- Seasonic Prime GX-850 850W
- Tastatur
- Logitech G19
- Maus
- Logitech G703
- Betriebssystem
- Win 10 pro
- Webbrowser
- IE 11 Mozilla Opera
- Verschiedenes
- Logitech PRO RENNLENKRAD DD
oh ha na dann weiß man doch woher die TDP kommt weitere CCX auf 96Kerne das mal ne ansage ....
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Und das genauer als je zuvor:

 www.computerbase.de
www.computerbase.de
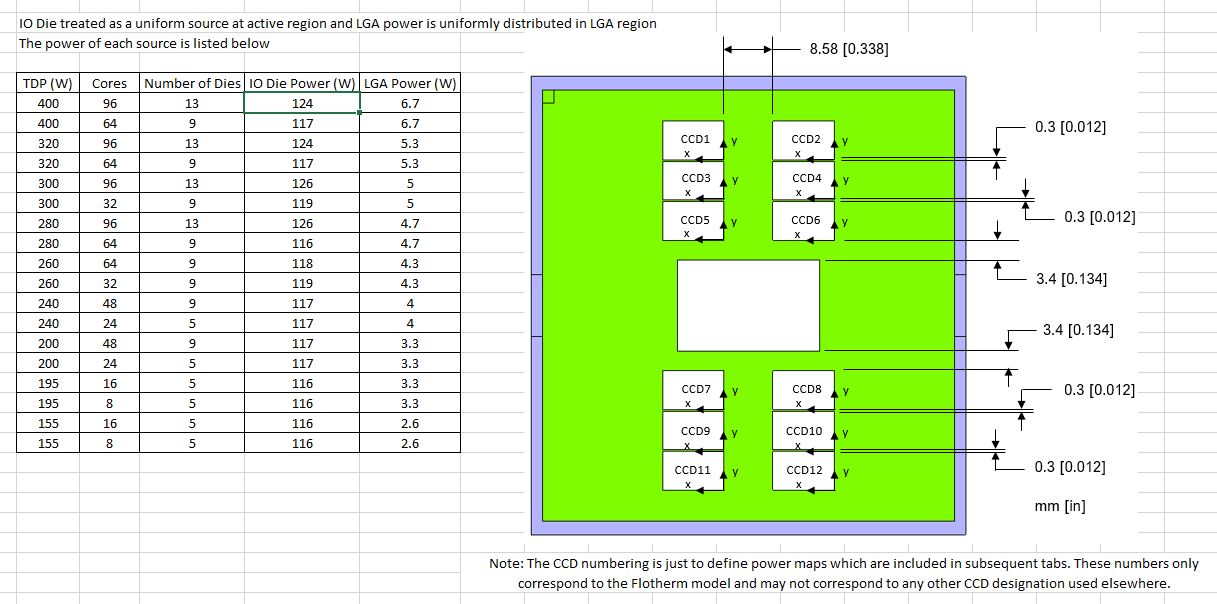
Da immer mindestens 4 CPU-Chiplets verbaut sind, geht das bis auf 2 Core/Die Salvage/Deaktivierung runter für die 8-Kern SKUs bei 155/195W TDP.
116 W davon nur für den IO-Die.
Genoa mit Zen 4: Umfangreiche Details zu AMDs nächster Server-CPU
Ein Support-Dokument für AMDs nächsten Server-Sockel SP5 gibt auch Details zu Zen 4 preis: 12 CPU-Dies inklusive AVX-512 gibt es für Genoa.
www.computerbase.de
Für die exakten TDP-Werte gibt es bereits separate Tabellen, die auch die Kern-Konfigurationen mit 96, 64, 48 bis hinab zu 32, 24, 16 und 8 Kernen beinhalten. Interessant ist dort der Verbrauch des I/O-Dies mit bis zu 126 Watt, der einen großen Anteil an den 400 Watt Maximum einnimmt. Da dürfte die TDP-Erhöhung gerade für die größeren CPUs fast ein Muss gewesen sein, denn so bleiben für 96 Kerne abzüglich des I/O-Dies letztlich maximal nicht einmal mehr 280 Watt übrig.
Da immer mindestens 4 CPU-Chiplets verbaut sind, geht das bis auf 2 Core/Die Salvage/Deaktivierung runter für die 8-Kern SKUs bei 155/195W TDP.
116 W davon nur für den IO-Die.
Zuletzt bearbeitet:
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Es soll ja Versionen von Raphael mit iGPU geben: hier liegt es nahe, dass dann das I/O-Die in 6nm ist, also all die für Rembrandt bereits entwickelten Komponenten von RDNA2 in 6nm und die DDR5-Controller in 6nm nutzt. Allerdings macht eine iGPU für Highend-Gaming keinen Sinn und für billigere Varianten der Zen4-CPU dürfte die AM5-Plattform einfach noch lange (bis 2023?) recht teuer bleiben.
Das 6nm I/O-Die dürfte aber sehr teuer sein (es dürfte wohl locker um die 150mm² groß sein, aufgrund iGPU und pad-limited) und zudem auch die neue AM5-Plattform mit DDR5. Über ganz 2022 dürften daher Zen4-CPUs für AM5 eher für extrem teuere Systeme vorbehalten bleiben. Daher erwarte ich, dass AMD auch Zen4-Varianten für AM4 bringen dürfte, mit Hilfe des "alten" viel billigeren (womöglich überarbeitete) 12nm-I/O-Die bringen dürfte.
Letztlich erwarte ich 3 Varianten von Zen4:
1) Die bekannte Version mit 6nm-I/O-Die für AM5 (Raphael)
2) Auch für Zen4 dürfte die Weiterführung der 3D-Stacked-Technlolgie mit großem L3-Cache für Highend-Gaming weit mehr bringen, als der DDR5-Speicher. Durch den großen L3 wird die teure AM5-Plattform erstmal weitgehend überflüssig, weil die Bandbreiten-Abhängigkeit durch den großen L3 entschäft wird. Highend-Gaming braucht viel eher den großen L3 mit 3D-Stacked-L3, aber sicher keine iGPU. AMD wird hier vomöglich zwei Preisklassen anbieten: Super-Highend-Gaming mit 3D-L3 für AM5 und günstigere Gaming-CPUs mit 3D-Stacked für die günstigere AM4-Plattform. Man dürfte sich hier daran orientieren, wie man dann gegenüber Alderlake jeweils steht.
3) Und schließlich die Verwertung aller schlechteren Zen4-Chiplets als günstige Zen4-CPUs für AM4 mit einem billigen 12nm+-I/O-Die.
Das 6nm I/O-Die dürfte aber sehr teuer sein (es dürfte wohl locker um die 150mm² groß sein, aufgrund iGPU und pad-limited) und zudem auch die neue AM5-Plattform mit DDR5. Über ganz 2022 dürften daher Zen4-CPUs für AM5 eher für extrem teuere Systeme vorbehalten bleiben. Daher erwarte ich, dass AMD auch Zen4-Varianten für AM4 bringen dürfte, mit Hilfe des "alten" viel billigeren (womöglich überarbeitete) 12nm-I/O-Die bringen dürfte.
Letztlich erwarte ich 3 Varianten von Zen4:
1) Die bekannte Version mit 6nm-I/O-Die für AM5 (Raphael)
2) Auch für Zen4 dürfte die Weiterführung der 3D-Stacked-Technlolgie mit großem L3-Cache für Highend-Gaming weit mehr bringen, als der DDR5-Speicher. Durch den großen L3 wird die teure AM5-Plattform erstmal weitgehend überflüssig, weil die Bandbreiten-Abhängigkeit durch den großen L3 entschäft wird. Highend-Gaming braucht viel eher den großen L3 mit 3D-Stacked-L3, aber sicher keine iGPU. AMD wird hier vomöglich zwei Preisklassen anbieten: Super-Highend-Gaming mit 3D-L3 für AM5 und günstigere Gaming-CPUs mit 3D-Stacked für die günstigere AM4-Plattform. Man dürfte sich hier daran orientieren, wie man dann gegenüber Alderlake jeweils steht.
3) Und schließlich die Verwertung aller schlechteren Zen4-Chiplets als günstige Zen4-CPUs für AM4 mit einem billigen 12nm+-I/O-Die.
Zuletzt bearbeitet:
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
AMD Zen4 Ryzen CPUs confirmed to offer integrated graphics (VideoCardz)
Upcoming Ryzen CPU series based on Zen4 architecture will all offer integrated GPU by design. While this does not mean that literally all CPUs will have iGPUs enabled, it does confirm that the mainstream Zen4 silicon will be paired with graphics for the first time. Thus, the GPU will no longer be exclusive to the Ryzen G-Series APUs.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Ich glaube AMD wird die nicht mit einem 12nm IO-Die Paaren, da es in den Servern 4xChiplets mit nur 2 aktiven Zen4 Cores geben wird bei den 8-Kern SKUs und mit 4 aktiven Kernen bei den 16-Kern SKUs. AM4 wird IMHO leer ausgehen.3) Und schließlich die Verwertung aller schlechteren Zen4-Chiplets als günstige Zen4-CPUs für AM4 mit einem billigen 12nm+-I/O-Die.
Zuletzt bearbeitet:
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.983
- Renomée
- 232
Ich glaube nicht, dass wir unter dem 6nm I/O-Die dasselbe verstehen sollten, was das I/O-Die bisher war. Vielleicht wird ein kleines 6nm I/O-Die benötigt, das aber nicht Träger der anderen Chiplets sein wird. Dieser Träger wird m.E. nach wie vor in einem älteren Prozess gefertigt.
MfG
MfG
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.425
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
Bei CB grad bestätigt: iGPU im IO Die
AMD nutzt weiterhin fast exakt gleich große 8-Kern-Chiplets und einen I/O-Die. Im neuen I/O-Die soll nun jedoch eine kleine GPU integriert sein, das bekannte 2+1-Chipdesign würde beibehalten, letztlich werden die CPUs dadurch aber auch zu APUs.
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.865
- Renomée
- 2.816
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken
- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox

erde-m
Grand Admiral Special
- Mitglied seit
- 23.03.2002
- Beiträge
- 3.272
- Renomée
- 451
- Standort
- TF
- Mitglied der Planet 3DNow! Kavallerie!
- Lieblingsprojekt
- LHC
- Meine Systeme
- AMD Ryzen9 5950X+64 GB DDR3600+RX6900XT, AMD Epyc 7V12+256 GB ECC DDR3200+R VII, AMD Ryzen 5 2500U
- BOINC-Statistiken

- Mein Laptop
- HP Envy x360 15-bq102ng Ryzen 5 2500U
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen9 5950X
- Mainboard
- Asus Prime X470-Pro
- Kühlung
- be quiet Silent Loop 280mm
- Speicher
- 64GB (4x16GB) G.Skill TridentZ Neo F4-3600C16-64GTZNC Quad Kit
- Grafikprozessor
- AMD Radeon RX 6900XT
- Display
- Acer Pro Designer PE320QK
- SSD
- M2: 2x Samsung 970Evo Plus 1TB
- HDD
- WDC WD100EFAX
- Soundkarte
- Onboard
- Gehäuse
- Fractal Define 7 Clear Tempered Glass White
- Netzteil
- bequiet Dark Power 12 1000W
- Tastatur
- Logitech G815
- Maus
- Logitech G402
- Betriebssystem
- Linux Mint 21.2; Win10Pro-64Bit
- Webbrowser
- Firefox
- Verschiedenes
- Qnap Single-port Aquantia AQC107 10GbE
- Internetanbindung
- ▼225 MBit ▲45 MBit
Wenn man schon verpixelt, dann auch den Datamatrix-Code. Mindestens 25% davon (die Daten sind alle 3x vorhanden + Fehlerkorrektur) und oder die Ränder rundum (dann erkennt die Kamera/2D-Codeleser den Code nicht als solchen)
Der Code ist: 114986FV10075

Ganz schöner Klopper, aber 12 Chiplets brauchen Platz ... da wird das I/O-Chiplet wohl weiter in 12 nm (oder doch 6nm?) gefertigt werden. Die fast quadratische Größe vereinfacht vermutlich die Verteilung der 6096 Pins und das Design der Boards. Rein von der Anordnung der Chiplets hätte es noch mehr rechteckiger sein können ... hatte ich anhand Post #37 von BoMbY auch vermutet

Zuletzt bearbeitet:
Pinnacle Ridge
Vice Admiral Special
- Mitglied seit
- 04.03.2017
- Beiträge
- 528
- Renomée
- 7
Würde es überhaupt viel bringen, die IOD in 6nm zu fertigen, bzw. würde man die Chipgröße reduzieren können?
Würde das den Verbrauch überhaupt stark beeinflussen?
Würde das den Verbrauch überhaupt stark beeinflussen?
Ähnliche Themen
- Antworten
- 3
- Aufrufe
- 970
- Antworten
- 37
- Aufrufe
- 4K
- Antworten
- 0
- Aufrufe
- 577