App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD RDNA 3 - Chiplet NAVI - NAVI 3X
- Ersteller E555user
- Erstellt am
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Ich denke hier wird dann SMT (HT) doch nicht wirklich verstanden. Entsprechend verweise ich gerne auf die theoretischen Grundlagen aus den 90ern.
Ein recht aktueller guter leicht verständlicher Artikel zur Praxis findet sich auf Anandtech. Man beachte das Kommentar zu 3DPM/3DPMavx und Corona.
Prinzip-bedingt kann eine CPU nicht in allen Ausführungseinheiten vollständig ausgelastet sein, deshalb gibt es SMT. Für Zen hier ein Beispiel wo durch doppelte Nutzung von parallelen Threads eine Auslastung optimeirt werden soll.
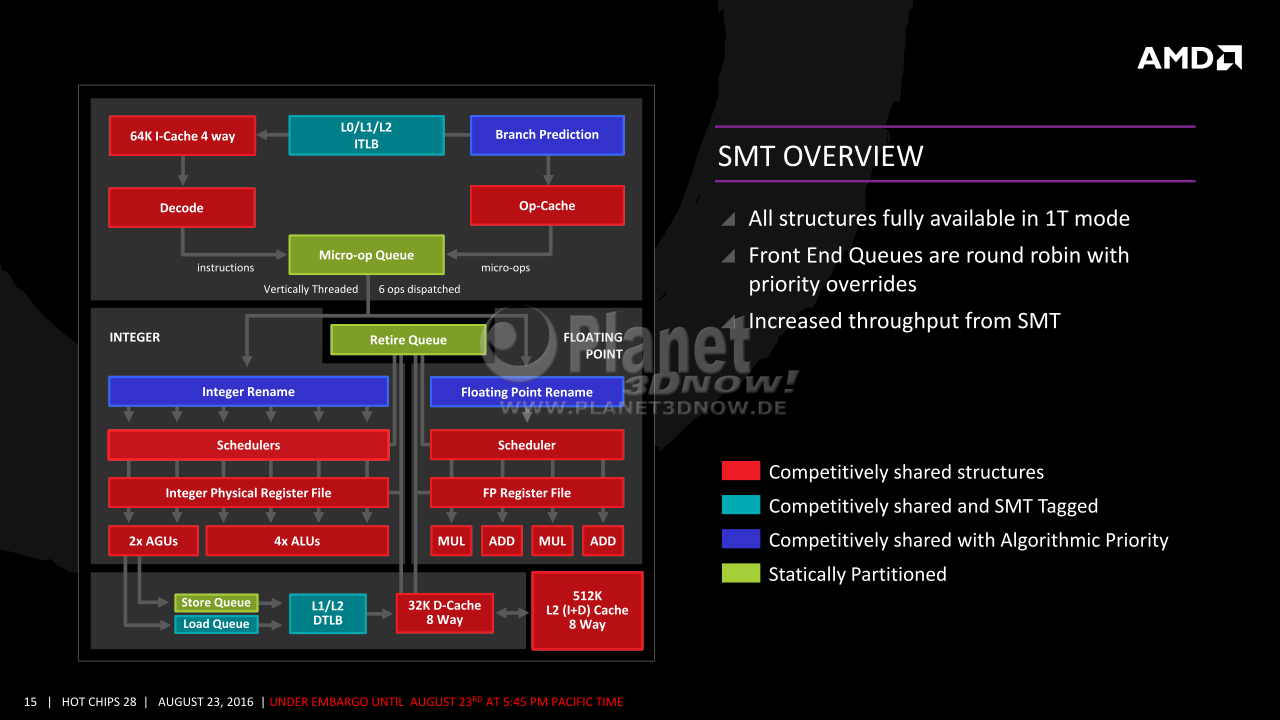
Ob SMT4 Sinn macht liegt allein am Gesamtdesign und entsprechender Software. Wenn Code und Daten im Zugriff liegen (grössere Caches bei moderner Fertigung) können auch mehr Threads parallel in einem Core verarbeitet werden. [back on topic] Bei GPUs hat man vom Prinzip her heute bis zu 64 solcher Threads, die sich aufgabenbedingt sehr gut gemeinsam Ressourcen teilen, schon mit rel. kleinen Caches. Hier mal eine historische Darstellung einer CU, die mehr and CPU-typische Schaubilder angelegt ist.

Es ist dabei in der Theorie unerheblich ob das Multithreading durch unterschiedliche Tasks verwaltet durch das OS begründet ist oder durch die Applikation als MT explizit programmiert ist. Letzteres erlaubt jedoch erst die Optimierung der Speicherzugriffe, damit das Ganze überhaupt im Sinne des Erfinders mit Blick auf höhere Auslastung aller Komponenten eines (CPU oder) GPU Kerns funktioniert.
Da GPU-Programmierung beim Gaming extrem unterschiedlichen Code für jedes einzelne Bild erfordert werden nicht nur Daten, sondern auch der Programmcode bei den Berechnungen sehr häufig gewechselt. Hier liegt der grosse Unterschied zum generischen GPU Compute. Darauf hat RDNA reagiert und CDNA erst mal nicht. Eine gute Analyse zum Thema hier bei Hardwaretimes.
Bessere Auslastung (Effizienz) von RDNA gegenüber GCN lässt sich bei wenigen vorhandenen CUs übrigens kaum beobachten. Es braucht schon viele CUs, damit diese Effekte deutlich sichtbar werden. Wenn die einzelnen Shader bzw. Algorithmen seltener auf einer CU gewechselt werden, weil es zu wenige CUs z.B. in einer APU hat, dann tritt auch nicht der Penalty bei den 64 Threads breiten Wavefronts so stark auf, weil diese genügende "Pixel-Threads" sehen um auf 64 aufgeteilt werden zu können. Auch die Instruktionen bei GCN während 4 vs. RDNA während 1 Takt zu laden fällt nicht so ins Gewicht, da diese - wie beim generischen Compute generell - dann nicht ganz so häufig gewechselt werden.
Ein recht aktueller guter leicht verständlicher Artikel zur Praxis findet sich auf Anandtech. Man beachte das Kommentar zu 3DPM/3DPMavx und Corona.
Prinzip-bedingt kann eine CPU nicht in allen Ausführungseinheiten vollständig ausgelastet sein, deshalb gibt es SMT. Für Zen hier ein Beispiel wo durch doppelte Nutzung von parallelen Threads eine Auslastung optimeirt werden soll.
Ob SMT4 Sinn macht liegt allein am Gesamtdesign und entsprechender Software. Wenn Code und Daten im Zugriff liegen (grössere Caches bei moderner Fertigung) können auch mehr Threads parallel in einem Core verarbeitet werden. [back on topic] Bei GPUs hat man vom Prinzip her heute bis zu 64 solcher Threads, die sich aufgabenbedingt sehr gut gemeinsam Ressourcen teilen, schon mit rel. kleinen Caches. Hier mal eine historische Darstellung einer CU, die mehr and CPU-typische Schaubilder angelegt ist.
Es ist dabei in der Theorie unerheblich ob das Multithreading durch unterschiedliche Tasks verwaltet durch das OS begründet ist oder durch die Applikation als MT explizit programmiert ist. Letzteres erlaubt jedoch erst die Optimierung der Speicherzugriffe, damit das Ganze überhaupt im Sinne des Erfinders mit Blick auf höhere Auslastung aller Komponenten eines (CPU oder) GPU Kerns funktioniert.
Da GPU-Programmierung beim Gaming extrem unterschiedlichen Code für jedes einzelne Bild erfordert werden nicht nur Daten, sondern auch der Programmcode bei den Berechnungen sehr häufig gewechselt. Hier liegt der grosse Unterschied zum generischen GPU Compute. Darauf hat RDNA reagiert und CDNA erst mal nicht. Eine gute Analyse zum Thema hier bei Hardwaretimes.
Bessere Auslastung (Effizienz) von RDNA gegenüber GCN lässt sich bei wenigen vorhandenen CUs übrigens kaum beobachten. Es braucht schon viele CUs, damit diese Effekte deutlich sichtbar werden. Wenn die einzelnen Shader bzw. Algorithmen seltener auf einer CU gewechselt werden, weil es zu wenige CUs z.B. in einer APU hat, dann tritt auch nicht der Penalty bei den 64 Threads breiten Wavefronts so stark auf, weil diese genügende "Pixel-Threads" sehen um auf 64 aufgeteilt werden zu können. Auch die Instruktionen bei GCN während 4 vs. RDNA während 1 Takt zu laden fällt nicht so ins Gewicht, da diese - wie beim generischen Compute generell - dann nicht ganz so häufig gewechselt werden.
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
@E555user
Ich fürchte das du SMT nicht ganz verstanden hast denn prinzipiell ist auch eine Leistungsminderung drin, sei es durch den Overhead des zusätzlichen Verwaltungsaufwandes oder durch durch einen Cache Überlauf bei weiteren Threads. Bei ersteren Fall bringt SMT faktisch nichts weil sich mit doppelt sovielen Threads sich z.B. die Laufzeit verdoppelt und mit letzteren Effekt durfte ich ebenfalls schon Bekanntschaft machen und der Leistungsverlußt war kernig. Im übrigen sind auch nicht alle Funktionen gleichzeitig ausführbar und daran kann auch SMT nichts ändern.
Ich schreibe es gern nochmal, SMT bringt keine zusätzliche Rechenleistung sondern macht nur brach liegende Kapazitäten mit den zusätzlichen virtuellen Kernen nutzbar und gut optimierte Software läßt auf dem Kern möglichst wenig davon liegen. SMT hat keine feste Skalierung, man kann nur abschätzen was durchschnittlich an brach liegender Rechenleistung nutzbar gemacht werden kann, real ist das was am Ende rauskommt bei jedem Programm eine Wundertüte bei der du bei gleichzeitig laufenden unterschiedlichen Prio Programmen auch mit Leistungsverlußten bei den einzelnen Programmen rechnen darfst die mit jedem zusätzlichen virtuellen Kern auf dem physischen Kern entsprechend ansteigen.
Was man allerdings im Desktop Bereich durchaus erkennen kann ist die offensichtlich immer schlechtere Einheitenauslastung durch neue Software, wodurch zwangsläufig für SMT mehr übrig bleibt aber das hat herzlich wenig mit Optimierung sondern vielmehr mit "Kostenoptimierung" zu tuen.
Soll der Kunde eben neue/schnellere Hardware kaufen um das zu kompensieren.
Das kann das Marketing wiederum als "SMT Optimierung" verkaufen, der Kunde kann das eh nicht vergleichen.
SMT4 ist nur ein Nieschenprodukt das nur dort sinnvoll ist wo selbst ein zweiter virtueller Kern den Physischen Kern nicht weit genug auslasten kann und um diese zu nutzen müssen die virtuellen Kerne von der Software auch genutzt werden. Hier hast du die gleichen Multithreading Hürden wie bei entsprechend vielen physischen Kernen die echte Mehrleistung bringen. Beim Stand des Multithreading Supports der aktuellen Software können wir über den Sinn bei seitens der Software in 10 Jahren nochmal reden. Heute kannst du ja schon froh sein wenn mehr als 8 (virtuellen) Kerne sinnvoll genutzt werden.
Deinen [back on topic] Einwand hättest du dir durch das erneute aufkochen des Themas übrigens schenken können denn du hattest es gerade selbst ignoriert nachdem ich bereits schrieb das ich mich raushalten wollte.
Du hättest es per PM schreiben können, hast du aber nicht. Es liegt also an dir ob du das Thema hier fortführen willst.
Zum Thema GPU scheinst du immernoch nicht verstanden zu haben dass die Bildberechnung für CDNA herzlich egal ist, dieser Architektur wurde diese gestrichen da sie nur noch für Compute Karten (aus GCN heraus?) weiterentwickelt wurde. CDNA ist für den kompletten Gaming Kram irrelevant. Für den Markt der Grafikberechnungen wurde RDNA entwickelt.
Ich fürchte das du SMT nicht ganz verstanden hast denn prinzipiell ist auch eine Leistungsminderung drin, sei es durch den Overhead des zusätzlichen Verwaltungsaufwandes oder durch durch einen Cache Überlauf bei weiteren Threads. Bei ersteren Fall bringt SMT faktisch nichts weil sich mit doppelt sovielen Threads sich z.B. die Laufzeit verdoppelt und mit letzteren Effekt durfte ich ebenfalls schon Bekanntschaft machen und der Leistungsverlußt war kernig. Im übrigen sind auch nicht alle Funktionen gleichzeitig ausführbar und daran kann auch SMT nichts ändern.
Ich schreibe es gern nochmal, SMT bringt keine zusätzliche Rechenleistung sondern macht nur brach liegende Kapazitäten mit den zusätzlichen virtuellen Kernen nutzbar und gut optimierte Software läßt auf dem Kern möglichst wenig davon liegen. SMT hat keine feste Skalierung, man kann nur abschätzen was durchschnittlich an brach liegender Rechenleistung nutzbar gemacht werden kann, real ist das was am Ende rauskommt bei jedem Programm eine Wundertüte bei der du bei gleichzeitig laufenden unterschiedlichen Prio Programmen auch mit Leistungsverlußten bei den einzelnen Programmen rechnen darfst die mit jedem zusätzlichen virtuellen Kern auf dem physischen Kern entsprechend ansteigen.
Was man allerdings im Desktop Bereich durchaus erkennen kann ist die offensichtlich immer schlechtere Einheitenauslastung durch neue Software, wodurch zwangsläufig für SMT mehr übrig bleibt aber das hat herzlich wenig mit Optimierung sondern vielmehr mit "Kostenoptimierung" zu tuen.
Soll der Kunde eben neue/schnellere Hardware kaufen um das zu kompensieren.
Das kann das Marketing wiederum als "SMT Optimierung" verkaufen, der Kunde kann das eh nicht vergleichen.
SMT4 ist nur ein Nieschenprodukt das nur dort sinnvoll ist wo selbst ein zweiter virtueller Kern den Physischen Kern nicht weit genug auslasten kann und um diese zu nutzen müssen die virtuellen Kerne von der Software auch genutzt werden. Hier hast du die gleichen Multithreading Hürden wie bei entsprechend vielen physischen Kernen die echte Mehrleistung bringen. Beim Stand des Multithreading Supports der aktuellen Software können wir über den Sinn bei seitens der Software in 10 Jahren nochmal reden. Heute kannst du ja schon froh sein wenn mehr als 8 (virtuellen) Kerne sinnvoll genutzt werden.
Deinen [back on topic] Einwand hättest du dir durch das erneute aufkochen des Themas übrigens schenken können denn du hattest es gerade selbst ignoriert nachdem ich bereits schrieb das ich mich raushalten wollte.
Du hättest es per PM schreiben können, hast du aber nicht. Es liegt also an dir ob du das Thema hier fortführen willst.
Zum Thema GPU scheinst du immernoch nicht verstanden zu haben dass die Bildberechnung für CDNA herzlich egal ist, dieser Architektur wurde diese gestrichen da sie nur noch für Compute Karten (aus GCN heraus?) weiterentwickelt wurde. CDNA ist für den kompletten Gaming Kram irrelevant. Für den Markt der Grafikberechnungen wurde RDNA entwickelt.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Als "Antwort" eine Unterhaltung im PM System beginnen der man nicht antworten darf. Ganz großes Kino. ![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]")
Am besten die ganzen SMT Posts ganz entfernen.
Am besten die ganzen SMT Posts ganz entfernen.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
sompe hat so viel inhaltlichen Unsinn geschrieben und persönliche Angriffe gestartet, dass ich ihn leztlich auf ignor setzen musste. Bitte nicht wundern wenn ich nicht mehr reagiere. 
Ist auch irgendwie viel angenehmer zu lesen und einfacher beim Thema zu bleiben mit dem Filter
Ist auch irgendwie viel angenehmer zu lesen und einfacher beim Thema zu bleiben mit dem Filter
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Sehr schön, dann muss ich mich zumindest keine unbelegten Gegenbehauptungen auf meine praktischen Erfahrungen ertragen.
Screenshot deiner Nachricht ohne Antwortmöglichkeit ist übrigens erstellt.
Screenshot deiner Nachricht ohne Antwortmöglichkeit ist übrigens erstellt.
Zuletzt bearbeitet:
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Bei MLID gibt ein aktuelles Video einige weitere Infos preis.
Der Navi33 wird voraussichtlich nur 8 PCIe Lanes mit PCIe5 anbieten. Das könnte für Upgrader von älteren Mainboards mit PCIe3 vielleicht schon Einschränkungen mit sich bringen. Die Leistung soll hingegen auf Niveau Navi21 bzw. 6900XT liegen mit 128MB IF Cache, denoch nur 8GB VRAM.
Interessant sind die Andeutungen zu den Work Group Processors. Hier würde eine Neuordnung anstehen.
Womöglich könnte mit besserer Fertigung der "L0"Cache von mehr CUs geteilt werden. Das würde zusätzlich helfen effizienter zu werden. Bis zu vier CUs in einem WGP bzw. die doppelte Grösse eines WGP könnte plausibel sein. Aber so wie er er formuliert, könnte es weniger eine glatte Verdoppelung sein sondern etwas anderes. Ich würde vermuten mehr shared Units zwischen den CUs geteilt und dort wo es nötig ist mehr echte Verbreiterung.
Der L0 Cache könnte moderater anwachsen, der WGP auf 128er Wavefront durch flexible 4x 32er "CU" angepasst werden. Das würde besser für UE5 und die DX12 Fortentwicklung passen. Der Sheduler könnte für alle CUs zusammengefasst sein, vielleicht ein neues Konzept für Scalare Units als eine shared x-wide Unit für 4 CUs im WGP.
Die Kombination von 8 Lanes PCIe mit 6900XT-Leistung könnte Kunden später einmal zum Mainboard-Upgrade drängen, sobald die 8GB VRAM öfters nicht mehr genügen. Andererseits wäre mit DirectStorage künftig eher weniger Bandbreitenbedarf zu erwarten, sollten nicht gleichzeitig die Texturen-Assets sprunghaft ebenfalls grösser werden.
Eine vorab Grafik im Video deutet zu RDNA3 Chiplets ein Double-Chiplet an, wie es Apple für den M1 Ultra verknüpft hat. Sollte sich das konkretisieren wäre es eine interessante Wendung. Absolut im Bereich des möglichen im Rahmen der allgemeinen Entwicklungen rund um TSMCs Knowhow.
(Nachtrag: mir ist eben erst aufgefallen, dass MLID die Grafik im Detail schon am 12. März gebracht hatte, ich kannte die bislang noch nicht.)
Der Navi33 wird voraussichtlich nur 8 PCIe Lanes mit PCIe5 anbieten. Das könnte für Upgrader von älteren Mainboards mit PCIe3 vielleicht schon Einschränkungen mit sich bringen. Die Leistung soll hingegen auf Niveau Navi21 bzw. 6900XT liegen mit 128MB IF Cache, denoch nur 8GB VRAM.
Interessant sind die Andeutungen zu den Work Group Processors. Hier würde eine Neuordnung anstehen.
Womöglich könnte mit besserer Fertigung der "L0"Cache von mehr CUs geteilt werden. Das würde zusätzlich helfen effizienter zu werden. Bis zu vier CUs in einem WGP bzw. die doppelte Grösse eines WGP könnte plausibel sein. Aber so wie er er formuliert, könnte es weniger eine glatte Verdoppelung sein sondern etwas anderes. Ich würde vermuten mehr shared Units zwischen den CUs geteilt und dort wo es nötig ist mehr echte Verbreiterung.
Der L0 Cache könnte moderater anwachsen, der WGP auf 128er Wavefront durch flexible 4x 32er "CU" angepasst werden. Das würde besser für UE5 und die DX12 Fortentwicklung passen. Der Sheduler könnte für alle CUs zusammengefasst sein, vielleicht ein neues Konzept für Scalare Units als eine shared x-wide Unit für 4 CUs im WGP.
Die Kombination von 8 Lanes PCIe mit 6900XT-Leistung könnte Kunden später einmal zum Mainboard-Upgrade drängen, sobald die 8GB VRAM öfters nicht mehr genügen. Andererseits wäre mit DirectStorage künftig eher weniger Bandbreitenbedarf zu erwarten, sollten nicht gleichzeitig die Texturen-Assets sprunghaft ebenfalls grösser werden.
Eine vorab Grafik im Video deutet zu RDNA3 Chiplets ein Double-Chiplet an, wie es Apple für den M1 Ultra verknüpft hat. Sollte sich das konkretisieren wäre es eine interessante Wendung. Absolut im Bereich des möglichen im Rahmen der allgemeinen Entwicklungen rund um TSMCs Knowhow.
(Nachtrag: mir ist eben erst aufgefallen, dass MLID die Grafik im Detail schon am 12. März gebracht hatte, ich kannte die bislang noch nicht.)
Zuletzt bearbeitet:
enigmation
Admiral Special

Aus dem Video rauskopiert:

Es gibt also 16GB dann nur noch mit >300W? Hmm, die Entwicklung find ich nicht so gut.
Es gibt also 16GB dann nur noch mit >300W? Hmm, die Entwicklung find ich nicht so gut.
hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.824
- Renomée
- 331
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Wenn es nur ein Refresh ist, ist höhere TDP wohl unvermeidlich. Die 16 zu 32GB Vergrößerung schlägt für sich allein mit 25W zu Buche, wenn 16*16Gb Chips zum Einsatz kommen.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Für Gaming macht mehr als 16GB aus meiner Sicht kaum Sinn. Auch während der letzten Konsolengeneration hat man nicht grösseren VRAM benötigt da diese letztlich auch noch System und Anwendung dort unterbringen. Mit DirectStorage sollte es auch nicht nötig werden einen grösseren Buffer vorzuhalten. Selbst extremes Texture-Modding könnte da kaum mehr RAM notwendig machen.
Wenn der IF-Cache bei den Top-GPUs auf 256MB anwächst wäre es vielleicht möglich den VRAM mit Undervolting und moderaten Takten ohne nennenswerte Einbussen zu betreiben? Könnte ein neues Feld eröffnen.
Aber auch bei mir sind 300W für die GPU eine Grenze, die ich für das vorhandene Case für Upgrades nicht überschreiten will. Dann eher nur noch 12GB VRAM.
Wenn der IF-Cache bei den Top-GPUs auf 256MB anwächst wäre es vielleicht möglich den VRAM mit Undervolting und moderaten Takten ohne nennenswerte Einbussen zu betreiben? Könnte ein neues Feld eröffnen.
Aber auch bei mir sind 300W für die GPU eine Grenze, die ich für das vorhandene Case für Upgrades nicht überschreiten will. Dann eher nur noch 12GB VRAM.
Nosyboy
Grand Admiral Special
- Mitglied seit
- 28.11.2001
- Beiträge
- 2.627
- Renomée
- 124
- Standort
- Switzerland
- Mein Laptop
- Lenovo IdeaPad Slim 3 (16", AMD Ryzen 5 7530U, 16GB) WIN11 / Zorin OS
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 5700X / 7nm / 65W
- Mainboard
- Gigabyte B550 Aorus Elite V2
- Kühlung
- Noctua NH-U12S Chromax Black
- Speicher
- Corsair Vengeance LPX (4x, 8GB, DDR4-3200)
- Grafikprozessor
- Sapphire Radeon Pulse 9060 XT 16GB
- Display
- Samsung C27FG70
- SSD
- Samsung SSD 860 PRO 256GB / CT1000MX500SSD1 1TB / NVMe Samsung SSD 970 EVO 1TB
- HDD
- 2TB Seagate Barracuda Green (ST2000DL003-9VT166)
- Optisches Laufwerk
- Pioneer BDR-209M
- Soundkarte
- on Board
- Gehäuse
- Chieftec Midi Tower
- Netzteil
- Seasonic Core GX ATX 3 650 W
- Tastatur
- Logitech G213
- Maus
- Logitech G403 / Logitech MX Vertical
- Betriebssystem
- WIN 10 Pro
- Webbrowser
- Opera / Edge
- Internetanbindung
- ▼100 MBit ▲20 MBit
Sieht ziemlich mau aus, selbst zu meiner 5700er..
Die 7700er mit nur 8GB VRAM macht eigentlich 0 Sinn.
Aber mal abwarten, gibt ja wohl viele Faktoren zu dieser Entscheidung, die Ressourcenkanppheit wird in Zukunft auch nicht besser werden, also wird man schon dadurch gezwungen etwas kleinere Brötchen zu backen und dafür entspr. Liefermengen bieten zu können.
Aber was mich dann wiederum sehr enttäuscht ist der TGP, wenn man schon solche Abstriche macht hätte ich da viel mehr erwartet.
Da wird man wohl fast zu einer 7600er greifen/hoffen müssen.
Die 7700er mit nur 8GB VRAM macht eigentlich 0 Sinn.
Aber mal abwarten, gibt ja wohl viele Faktoren zu dieser Entscheidung, die Ressourcenkanppheit wird in Zukunft auch nicht besser werden, also wird man schon dadurch gezwungen etwas kleinere Brötchen zu backen und dafür entspr. Liefermengen bieten zu können.
Aber was mich dann wiederum sehr enttäuscht ist der TGP, wenn man schon solche Abstriche macht hätte ich da viel mehr erwartet.
Da wird man wohl fast zu einer 7600er greifen/hoffen müssen.
Night<eye>
Fleet Captain Special
- Mitglied seit
- 23.07.2006
- Beiträge
- 292
- Renomée
- 0
Mal eine frage am Rande.
Ich habe noch ein PCIe 3.0 Mainboard.
Wenn die neue sagen wir mal RX 7700XT nur als PCIe 5.0 8x raus kommt, was schätzt ihr wie viel % Leistungsverlust hätte ich dann durch mein altes PCIe Interface ?
Ich habe noch ein PCIe 3.0 Mainboard.
Wenn die neue sagen wir mal RX 7700XT nur als PCIe 5.0 8x raus kommt, was schätzt ihr wie viel % Leistungsverlust hätte ich dann durch mein altes PCIe Interface ?
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Dein Bottleneck in der Anbindung ist übr den Daumen gerundet dann knapp 8GB pro Sekunde. Ein neues Board mit 5.0 würde knapp 32GB pro Sekunde schaffen und der Roundtrip von einer Anweisung nur 1/4 der Zeit.Mal eine frage am Rande.
Ich habe noch ein PCIe 3.0 Mainboard.
Wenn die neue sagen wir mal RX 7700XT nur als PCIe 5.0 8x raus kommt, was schätzt ihr wie viel % Leistungsverlust hätte ich dann durch mein altes PCIe Interface ?
Wenn die Software nach alt hergebrachten Mustern arbeitet verlierst Du beim Ladevorgang in den grosszügigen VRAM wenige Sekunden aber sonst sollte es keine weiteren Nachteile geben. Einer onboard M.2 NVMe würden auch nur 4GB pro Sekunde Durchsatz zur Verfügung stehen, so dass auf dem direkten Weg vom Festspeicher zur GPU auch kein ernsthafter Nachteil entstünde. Auch wird bis zum Nachfolger einer 7700XT die >4GB/s bei SSD noch exotisch bleiben und sicher nicht Voraussetzung für Mainstream-Software werden. Unterschiede wird man in extremis messen können, Artikel werden geschrieben werden.
Bei der 6600XT hat der PCIe3 Bottleneck bei Titeln, die während der Szenendarstellung viel nachladen, rund 10% Verlust in den MinFPS ausgemacht. Zudem nur bei sehr hohen FPS-Zahlen (kleine Auflösungen) solch prägnante Unterschiede gezeigt. Das sollte aber durch konsequente Berücksichtigung von rBAR/SAM oder DirectStorage kompensiert werden können. Das war bei den Titeln die ich gesehen habe nicht der Fall.
Es kommt letztlich wieder auf die Entwickler an, ob die sich die Mühe machen oder nicht. Der Treiber allein bringt nicht viel, wenn die Engine das Nachladen nicht darauf anpasst. Als Anwender muss man im Zweifel die Texturdetails reduzieren, bis der VRAM wieder passt.
Sollte sich die Software rund um DirectStorage sensitiv für Latenzen via PCIe erweisen könnte der modernere Standard auch notwendig werden, bei Nutzung der GPU für generische Compute-Beschleunigung sind die Latenzen auf jeden Fall relevant. Mir ist noch nicht klar, ab wann DirectStorage voll durch GPUs unterstützt wird und zur GPU nur noch komprimierte Assets übertragen werden, dort dann erst entpackt werden. Ich hoffe wir bekommen zu RDNA3 bald mehr Infos zu diesem Thema. Nicht zu vergessen, dass moderne Methoden wie Variable Rate Shading und Sampler Feedback Streaming eigentlich diese Bandbreiten und VRAM entlasten sollen. Im Umkehrschluss könnte das schon zu mehr Hektik auf dem PCIe Interface führen wenn einmal in den kommenden Jahren unter Strich eher mehr schlanke Tiled-Assets am Limit des VRAM nachgeladen werden sollen statt den VRAM mit relativ weniger Files hoher Qualität statisch zuzumachen.
Heute kann man also keine %-Zahl nennen. In den meisten Fällen wird es wohl die kommenden Monate keinen Unterschied machen, weil der VRAM gross genug ist. In speziellen Fällen könnten beim Nachladen Leistungsverluste auftreten, umso mehr wenn am VRAM gespart werden soll. Es hilft in dieser Sache nicht auf Durchschnittswerte zu achten, man muss jeden einzelnen Softwaretitel einzeln betrachten. Allgemein reagiert doch der Softwaremarkt sehr zäh, da Gaming ein extrem grosser Massenmarkt geworden ist und Anwendungssoftware im Zweifel auch wieder mehr auf Multicore denn GPU-Compute setzt.
Night<eye>
Fleet Captain Special
- Mitglied seit
- 23.07.2006
- Beiträge
- 292
- Renomée
- 0
Vielen dank für diese sehr detailreiche Antwort.
Ich habe viel nutzen daraus gezogen.
Meine Anwendung wäre Star Citizen auf 1440p.
Meine Aktuelle RX470 liefert dort leider keine 30fps im Moment.
Ich plane nächstes Jahr eine RDNA 3 Karte für dieses Spiel zu erwerben.
Dank deiner Info weiß ich, ich muss wohl nicht so auf 8x oder 16x Anbindung achten, solange ich eine Karte mit genug Speicher auswähle.
Eine M.2 NVMe ist drin auf der das Spiel installiert werden soll. Zusätzlich habe ich dem System noch weitere 16GB Ram gegönnt, so das es jetzt 32Gb hat.
Vielleicht darf nächstes Jahr der Zen+ gegen einen neuen Ryzen 5800X3D getauscht werden, da er wohl Definitiv mehr als 50% mehr FPS in dem spiel gegenüber dem Zen+ bringen sollte.
Bei Grafikkarten will ich keine 500€ ausgeben, sondern 300-400 max, daher schaue ich mal welches RDNA 3 Modell es in einem Jahr so wird.
Ich habe viel nutzen daraus gezogen.
Meine Anwendung wäre Star Citizen auf 1440p.
Meine Aktuelle RX470 liefert dort leider keine 30fps im Moment.
Ich plane nächstes Jahr eine RDNA 3 Karte für dieses Spiel zu erwerben.
Dank deiner Info weiß ich, ich muss wohl nicht so auf 8x oder 16x Anbindung achten, solange ich eine Karte mit genug Speicher auswähle.
Eine M.2 NVMe ist drin auf der das Spiel installiert werden soll. Zusätzlich habe ich dem System noch weitere 16GB Ram gegönnt, so das es jetzt 32Gb hat.
Vielleicht darf nächstes Jahr der Zen+ gegen einen neuen Ryzen 5800X3D getauscht werden, da er wohl Definitiv mehr als 50% mehr FPS in dem spiel gegenüber dem Zen+ bringen sollte.
Bei Grafikkarten will ich keine 500€ ausgeben, sondern 300-400 max, daher schaue ich mal welches RDNA 3 Modell es in einem Jahr so wird.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Ich kenne Star Citizen selbst nicht. Womöglich ist die RX470 tatsächlich zu schwach für bessere Frameraten bei akzeptablen reduzierten Settings. Die Anwendung scheint extreme Abhängigkeit von Zugriffen auf den System-RAM zu haben. Die MinFPS sind nach dem aktuellen YT-Video stark CPU-abhängig, vermutlich sogar bei einer RX470. Falls auch die RX470 bereits bei künstlich gedrosseltem System-RAM im aktuellen Release bemerkbar niedrigere Werte liefert könnte ein vorgezogener Kauf eines 5800X3D Sinn machen, da eine künftige RDNA3 (voraussichtlich N33 schneller als die RTX3080) in diesem Titel sonst auch extrem ausgebremst werden.Meine Anwendung wäre Star Citizen auf 1440p.
Meine Aktuelle RX470 liefert dort leider keine 30fps im Moment.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Kurze Notiz an dieser Stelle, dass MLID von einer Verdopplung der StreamProzessoren je CU für RDNA3 ausgeht. Die Workgroup wäre mit 2 CUs dabei nicht in CUs sondern im SIMD durch die Anzahl der Shader Units in der Rohleistung verdoppelt. Das überrascht, weil entgegen des bisherigen Trends von GCN zu RDNA die Flexibilität in der Auslastung wieder geringer würde.
Dennoch sollte eine Verdopplung von 64 auf 128 SPs je CU durch das breitere SIMD ein 128 Thread-Modell in UE5 mit guter Auslastung unterstützen können. Durch weniger Scheduling der Threads in HW darin effizient bleiben.
Dennoch sollte eine Verdopplung von 64 auf 128 SPs je CU durch das breitere SIMD ein 128 Thread-Modell in UE5 mit guter Auslastung unterstützen können. Durch weniger Scheduling der Threads in HW darin effizient bleiben.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 5.050
- Renomée
- 496
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Samsung, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Und weniger Leistung pro SP? Die müssen enorm an Fläche pro SP einsparen um den Schritt zu gehen und so mehr davon verbauen zu können.
Gleichzeitig vergrößerter L2 Cache.
Gleichzeitig vergrößerter L2 Cache.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Beim Wechsel von GCN zu RDNA hat man sowohl die 4 Takte andauernde gestaffelte Verarbeitung einer Operaition auf einen Takt reduziert, als auch auf 32er SIMD statt 64er (fix 4x16) SIMD ausgelegt. Beides half bei den typischen Wave32 Shader-Codes beim Gaming, die öfters die Instruktion wechseln.
Dafür musste man die Skalar-Einheiten verdoppeln und der Scheduler muss jeden Takt Instruktion geben können, die müssen jeden Takt "gefetched" werden können. (empfehle Abheek Gulatis deep dive)

Sollten die Gerüchte stimmen und RDNA3 wechselt auf ein 128er SIMD, dann würde sich ja lediglich die Anzahl der SIMD verdoppeln und die Vector General-Purpose Register entsprechend vergrössern, Data-Cache müsste mehr leisten, Instruction-Cache und Scheduler nur geringfüg leistungsfähiger werden, wenn überhaupt.
Ohne viel Ahnung von Chipdesign habe ich bisher vor allem mitgenommen, dass ALUs selbst relativ wenig Platz und Energie benötigen, das Bewegen von Daten relativ viel. Von daher könnte da was dran sein, vermute ich. Für steigende Auflösungen in Polygonen und Pixel sollten doch breitere SIMD das richtige Mittel sein, für höhere zeitliche Auflösung (FPS) eher mehr Flexibilität.
Überraschend ist für mich, dass bei all den GPU-Chiplet Gerüchten momentan davon ausgegangen wird, dass im Prinzip 3 GPU "Monolithen" designt werden, bei denen die beiden grösseren Modelle das Speicherinterface und den InfinityCache in Chiplets auslagern, nicht aber, dass es wie bei CDNA zwei GPUs auf einem Interposer geben soll.

 wccftech.com
wccftech.com
Dafür musste man die Skalar-Einheiten verdoppeln und der Scheduler muss jeden Takt Instruktion geben können, die müssen jeden Takt "gefetched" werden können. (empfehle Abheek Gulatis deep dive)
Sollten die Gerüchte stimmen und RDNA3 wechselt auf ein 128er SIMD, dann würde sich ja lediglich die Anzahl der SIMD verdoppeln und die Vector General-Purpose Register entsprechend vergrössern, Data-Cache müsste mehr leisten, Instruction-Cache und Scheduler nur geringfüg leistungsfähiger werden, wenn überhaupt.
Ohne viel Ahnung von Chipdesign habe ich bisher vor allem mitgenommen, dass ALUs selbst relativ wenig Platz und Energie benötigen, das Bewegen von Daten relativ viel. Von daher könnte da was dran sein, vermute ich. Für steigende Auflösungen in Polygonen und Pixel sollten doch breitere SIMD das richtige Mittel sein, für höhere zeitliche Auflösung (FPS) eher mehr Flexibilität.
Überraschend ist für mich, dass bei all den GPU-Chiplet Gerüchten momentan davon ausgegangen wird, dass im Prinzip 3 GPU "Monolithen" designt werden, bei denen die beiden grösseren Modelle das Speicherinterface und den InfinityCache in Chiplets auslagern, nicht aber, dass es wie bei CDNA zwei GPUs auf einem Interposer geben soll.
AMD RDNA 3 "Navi 31" GPU GCD Reportedly Measures Around 350mm2, 33% Smaller on TSMC's 5nm Node
The rumored die size of AMD's RDNA 3 flagship GPU, the Navi 31, which will be fabricated on TSMC's 5nm process node has been revealed.
Zuletzt bearbeitet:
Danke für den verlinkten Artikel über die VLIW, GCN und RDNA Architekturen. Obwohl mir das meiste bekannt war, war er sehr interessant.
Wenn RDNA3 auf 4x statt 2x SIMD32 wechselt ändert sich eigentlich kaum etwas an der Verarbeitung. Sind immer noch 32er wavefronts in je einem Taktzyklus. Dadurch dass sich mehr Einheiten den L0 und ein paar andere Einheiten teilen kann vielleicht aber die Auslastung der CUs etwas verbessert werden. Und durch häufigere Cache hits auch die Effizienz.
Insgesamt sollten die Auswirkungen aber nicht so groß sein, eher eine kleine Optimierung die dank der mittlerweile sehr hohen Taktbereit ohne merkliche Einbußen möglich ist.
Wenn RDNA3 auf 4x statt 2x SIMD32 wechselt ändert sich eigentlich kaum etwas an der Verarbeitung. Sind immer noch 32er wavefronts in je einem Taktzyklus. Dadurch dass sich mehr Einheiten den L0 und ein paar andere Einheiten teilen kann vielleicht aber die Auslastung der CUs etwas verbessert werden. Und durch häufigere Cache hits auch die Effizienz.
Insgesamt sollten die Auswirkungen aber nicht so groß sein, eher eine kleine Optimierung die dank der mittlerweile sehr hohen Taktbereit ohne merkliche Einbußen möglich ist.
E555user
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 05.10.2015
- Beiträge
- 2.173
- Renomée
- 938
Aktuell werden die Informationen der Leaker-Seite Angstronomics als sehr realistisch diskutiert. Die grösste Unbekannte bleibt wohl ob Navi32 mit 30 oder 32 WGPs (60 oder 64 CUs) antritt.
Wesentlich ist wohl, dass ein MCD ein n*16MB Cache und 64bit GDDR Memory Controller ist, bei dem der Cache per Stacking mindestens verdoppelt werden kann. MALL steht dabei für Memory Attached Last Level Cache.
Die Chipdaten gemäss Angstronomics:
Ich denke AMD könnte mit verschiedenen Varianten der MCDs ungewohnt viele unterschiedliche SKUs zussätzlich zum vermutlichen Binning anbieten. Wenn man die sonst üblichen 12-15% Differenz bei Shaderanzahl anlegt könnte für Navi31 ein 48 vs 42 WGP SKU verfügbar werden, je nach Design bei Navi32 entsprechend ein 32 vs 28 WGP oder 30 vs 26 WGP SKU. Womöglich sehen wir dann ein XTX oder XTH als Bezeichnung für 1-hi MALL Cache.
Wesentlich ist wohl, dass ein MCD ein n*16MB Cache und 64bit GDDR Memory Controller ist, bei dem der Cache per Stacking mindestens verdoppelt werden kann. MALL steht dabei für Memory Attached Last Level Cache.
Die Chipdaten gemäss Angstronomics:
Navi 31
- gfx1100 (Plum Bonito)
- Chiplet - 1x GCD + 6x MCD (0-hi or 1-hi)
- 48 WGP (96 legacy CUs, 12288 ALUs)
- 6 Shader Engines / 12 Shader Arrays
- Infinity Cache 96MB (0-hi), 192MB (1-hi)
- 384-bit GDDR6
- GCD on TSMC N5, ~308 mm²
- MCD on TSMC N6, ~37.5 mm²
Navi32
- gfx1101 (Wheat Nas)
- Chiplet - 1x GCD + 4x MCD (0-hi)
- 30 WGP (60 legacy CUs, 7680 ALUs)
- 3 Shader Engines / 6 Shader Arrays
- Infinity Cache 64MB (0-hi)
- 256-bit GDDR6
- GCD on TSMC N5, ~200 mm²
- MCD on TSMC N6, ~37.5 mm²
Navi33
- gfx1102 (Hotpink Bonefish)
- Monolithic
- 16 WGP (32 legacy CUs, 4096 ALUs)
- 2 Shader Engines / 4 Shader Arrays
- Infinity Cache 32MB
- 128-bit GDDR6
- TSMC N6, ~203 mm²
Ich denke AMD könnte mit verschiedenen Varianten der MCDs ungewohnt viele unterschiedliche SKUs zussätzlich zum vermutlichen Binning anbieten. Wenn man die sonst üblichen 12-15% Differenz bei Shaderanzahl anlegt könnte für Navi31 ein 48 vs 42 WGP SKU verfügbar werden, je nach Design bei Navi32 entsprechend ein 32 vs 28 WGP oder 30 vs 26 WGP SKU. Womöglich sehen wir dann ein XTX oder XTH als Bezeichnung für 1-hi MALL Cache.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Ich für meinen Teil halte das nicht für allso realistisch und das hat vor allem 2 Gründe.
Warum sollten ausgerechnet die kleinen Chiplets mit den Shadern im gröberen Fertigungsprozess hergestellt und dann auch noch per Stacking in der Wärmeabfuhr behindert werden? OK, wenn man die Stacks unter das Chiplet packen würde dann dürften die Auswirkungen überschaubar sein, müßte dann aber beim größeren Chip für einen Höhenausgleich sorgen. Angesichts der bisher bereits verbauten 128 MB Infinity Cache für das Top Modell halte ich zudem den Cache Anteil im Chiplet für viel zu klein. War nicht mal die Rede von einer Verdoppelung? Die wäre so nur mit Stacking realisierbar, was wiederum einen zusätzlichen Mehraufwand bedeutet der ins Geld gehen würde.
Für mich zu viele Ungereimtheiten.
Warum sollten ausgerechnet die kleinen Chiplets mit den Shadern im gröberen Fertigungsprozess hergestellt und dann auch noch per Stacking in der Wärmeabfuhr behindert werden? OK, wenn man die Stacks unter das Chiplet packen würde dann dürften die Auswirkungen überschaubar sein, müßte dann aber beim größeren Chip für einen Höhenausgleich sorgen. Angesichts der bisher bereits verbauten 128 MB Infinity Cache für das Top Modell halte ich zudem den Cache Anteil im Chiplet für viel zu klein. War nicht mal die Rede von einer Verdoppelung? Die wäre so nur mit Stacking realisierbar, was wiederum einen zusätzlichen Mehraufwand bedeutet der ins Geld gehen würde.
Für mich zu viele Ungereimtheiten.
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.384
- Renomée
- 85
Das kleine 37mm² Ding einfach in der Fläche zu verdoppeln ist vermutlich viel billiger als die Verdopplung in der gleichen Diesize über Stacking zu erreichen, was nachher auch noch thermische Nachteile mit sich bringt. Ein Stacking auf dem 37mm² Ding in nur 6nm macht meines Erachtens einfach keinen Sinn.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Nicht unbedingt denn am Anfang ist die Fehlerquote und damit der Ausschuss für gewöhnlich größer und mit der Chip Größe nimmt natürlch auch die Fehleranfälligkeit zu weil ganz einfach pro Chip mehr da ist was kaputt gehen kann. Genau das ist ja der Vorteil der Chiplet Methode. Statt eines großen Chips mit entsprechender Ausfallquote setzt man sich den aus vielen kleinen Teilen zusammen und zieht so die Chip Ausbeute pro Wafer hoch. Wenn alles gut läuft überkompensiert dies die daraus resultierenden zusätzlichen Folgekosten und es lassen sich so auch Chips realisieren die sonst nicht (kostendeckend) produzierbar wären.
Genau das deutet für mich aber eher auf den 5nm Prozess anstatt des aufgebohrten 7nm Prozesses (6nm) hin welcher tendenziell durch die 7nm Erfahrungen eine höhere Ausbeute haben dürfte. Statt dessen soll damit der deutlich größere und damit auch anfälligere Chip mit dem teureren Prozess gefertigt werden?
Genau hier wird das für mich zur unglaubwürdigen Ente.
Der Navi33 klingt für mich hingegen zumindest plausibel.
Genau das deutet für mich aber eher auf den 5nm Prozess anstatt des aufgebohrten 7nm Prozesses (6nm) hin welcher tendenziell durch die 7nm Erfahrungen eine höhere Ausbeute haben dürfte. Statt dessen soll damit der deutlich größere und damit auch anfälligere Chip mit dem teureren Prozess gefertigt werden?
Genau hier wird das für mich zur unglaubwürdigen Ente.
Der Navi33 klingt für mich hingegen zumindest plausibel.
IO und SRAM skaliert schlecht bis gar nicht mit 5nm, daher nur 6nm. Während die Logik sehr gut skaliert aber sich auch nur schwer in 2 dies teilen lässt. Also entfernt man den großen Ballast von dem 5nm graphic die um es möglichst klein zu halten.
Die Mini MCD chiplets sind wohl nur wegen der daraus folgenden Modularität so klein. 3d stacking ist hier wohl generell schwierig da man dann wieder Höhenunterschiede ausgleichen müsste. Ist aber wohl auch nirgends geplant.
Klingt meiner Meinung nach alles recht vernünftig.
Nur die Größe des IF$ scheint erst einmal gering. Das könnte aber auch daran liegen dass z.b. dank größeren L0-L2$ und mehr Bandbreite einfach weniger benötigt wird.
Die Mini MCD chiplets sind wohl nur wegen der daraus folgenden Modularität so klein. 3d stacking ist hier wohl generell schwierig da man dann wieder Höhenunterschiede ausgleichen müsste. Ist aber wohl auch nirgends geplant.
Klingt meiner Meinung nach alles recht vernünftig.
Nur die Größe des IF$ scheint erst einmal gering. Das könnte aber auch daran liegen dass z.b. dank größeren L0-L2$ und mehr Bandbreite einfach weniger benötigt wird.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.735
- Renomée
- 2.493
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
@tex_
Nur dürften nach den bisherigen Gerüchten die Shader mit ihrem Teil des Speichercontrollers in den kleinen Chiplets stecken, PCIe, die Crossbar zur Lastverteilung und vermutlich auch der Infinity Cache würden dann in den anderen Chip wandern.
Wo soll auch der Sinn darin sein nur den IO und Speicher Part auszulagern und dann auch noch aufzuspalten? Der tiefere Sinn des Chiplet Prinzipes war ja eher die Chips für den anfälligeren und teureren Fertigungsprozess möglichst klein zu halten und das aus diesem Gerücht wäre praktisch das genaue Gegenteil. Da die kleineren Chips auch noch monolitisch ausfallen würden wäre die größe dieser Controller Chiplets aufgrund fehlender Wiederverwendbarkeit über die Unterprodukte hinweg auch noch völlig sinnlos. Dann hätte man das auch in 3 (je ein 128 Bit vom Speichercontroller) oder gar nur einem Chip (Verwertbarkeit vom Ausschuss mit einzelnen Controller Defekten) realisieren können. Sie in kleinere Chiplets weiter aufzuspalten wäre nur im Sinne der Ausbeute sinnvoll aber dann müßte die schon so schlecht sein dass der deutlich größere Navi33 mit diesem Fertigungsprozess fragwürdig wäre. Selbst der Ansatz des Cache Stackings erscheint mir völlig sinnlos wenn der kleinere infinity Cache ach so ausreichend wäre denn dann würde der gestackte Cache der großen GPU so gut wie nichts bringen. Auch steht es im krassen Gegensatz zu früheren Aussagen nach denen er bei Navi 3 doppelt so groß werden würde und nun faktisch halbiert wäre.
Wie gesagt, es erscheint mir völlig unlogisch zu sein.
Nur dürften nach den bisherigen Gerüchten die Shader mit ihrem Teil des Speichercontrollers in den kleinen Chiplets stecken, PCIe, die Crossbar zur Lastverteilung und vermutlich auch der Infinity Cache würden dann in den anderen Chip wandern.
Wo soll auch der Sinn darin sein nur den IO und Speicher Part auszulagern und dann auch noch aufzuspalten? Der tiefere Sinn des Chiplet Prinzipes war ja eher die Chips für den anfälligeren und teureren Fertigungsprozess möglichst klein zu halten und das aus diesem Gerücht wäre praktisch das genaue Gegenteil. Da die kleineren Chips auch noch monolitisch ausfallen würden wäre die größe dieser Controller Chiplets aufgrund fehlender Wiederverwendbarkeit über die Unterprodukte hinweg auch noch völlig sinnlos. Dann hätte man das auch in 3 (je ein 128 Bit vom Speichercontroller) oder gar nur einem Chip (Verwertbarkeit vom Ausschuss mit einzelnen Controller Defekten) realisieren können. Sie in kleinere Chiplets weiter aufzuspalten wäre nur im Sinne der Ausbeute sinnvoll aber dann müßte die schon so schlecht sein dass der deutlich größere Navi33 mit diesem Fertigungsprozess fragwürdig wäre. Selbst der Ansatz des Cache Stackings erscheint mir völlig sinnlos wenn der kleinere infinity Cache ach so ausreichend wäre denn dann würde der gestackte Cache der großen GPU so gut wie nichts bringen. Auch steht es im krassen Gegensatz zu früheren Aussagen nach denen er bei Navi 3 doppelt so groß werden würde und nun faktisch halbiert wäre.
Wie gesagt, es erscheint mir völlig unlogisch zu sein.
Zuletzt bearbeitet:
Die Shader in viele kleine Chips aufzuspalten war nie wirklich Thema in den Gerüchten. Es wurde nur über ein Doppel Navi 31/32 spekuliert mit 2 großen graphic Dies in eben 5nm. Das scheint sich so nicht zu bestätigen.
Der Sinn den Speichercontroller und Cache raus zu bekommen sieht man doch an der GCD Fläche. Diese liegt nur noch bei 300mm^2 und sollte damit im Vergleich zu einem fast doppelt so Großen gute yields erzielen.
Der MCD wäre wie gesagt eben nicht wegen yields so klein, sondern wegen Modularität. Man kann daraus mit einem Chip einfach 256/320/384 Bit controller für Navi 31 und 32 zusammensetzen.
Was an den Gerüchten stimmt und wie groß der Infinity Cache dann wirklich ist sehen wir bei der Vorstellung der Karten")
Der Sinn den Speichercontroller und Cache raus zu bekommen sieht man doch an der GCD Fläche. Diese liegt nur noch bei 300mm^2 und sollte damit im Vergleich zu einem fast doppelt so Großen gute yields erzielen.
Der MCD wäre wie gesagt eben nicht wegen yields so klein, sondern wegen Modularität. Man kann daraus mit einem Chip einfach 256/320/384 Bit controller für Navi 31 und 32 zusammensetzen.
Was an den Gerüchten stimmt und wie groß der Infinity Cache dann wirklich ist sehen wir bei der Vorstellung der Karten
Ähnliche Themen
- Antworten
- 947
- Aufrufe
- 26K
- Antworten
- 0
- Aufrufe
- 442
- Antworten
- 99
- Aufrufe
- 5K