App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
SMT/CMT-Kernzuordnen in Windows-Betriebssystemen
- Ersteller miriquidi
- Erstellt am
Hallo,
ich versuche hier mal die Diskussion zur Zuordnung der einzelnen unter Windows angezeigten Kerne auf die physischen Kerne einer CPU zusammenzufassen. Nachfolgend erstmal die bisherige Diskussion zum Problem (ohne SMT vs. CMT-Definitionsgeflame *g*).
ich versuche hier mal die Diskussion zur Zuordnung der einzelnen unter Windows angezeigten Kerne auf die physischen Kerne einer CPU zusammenzufassen. Nachfolgend erstmal die bisherige Diskussion zum Problem (ohne SMT vs. CMT-Definitionsgeflame *g*).
Eine kurze Frage zu Bulldozer und Zen: Bei einer Intel 2-Kern-CPU mit Hyperthreading hat man die logischen Kerne 0 bis 3. Die logischen Kerne 0 und 1 gehören zum ersten realen Kern, die logischen Kerne 2 und 3 zum zweiten realen Kern. Ich denke, da bin ich mir jetzt nicht ganz sicher, so ist es auch beim Atom. Hat man zwei unabhängige Programme, wäre es ideal, wenn eines auf dem logischen Kern 0 und 1 läuft, das zweite auf 2 und 3.
Wie sieht das beim Bulldozer aus und was ist dort für Zen geplant? Microsofts Windows bekommt das mit dem Aufteilen der Aufgaben ja leider nicht wirklich hin, so dass man da hin und wieder von Hand nachhelfen muss.
Die Core-Zuordnung Bulldozer-Windows hatte ich seinerzeit mit einem FX-8120 und Win7/64 getestet. Ergebnis: Sicher ist nur, das der BD-Core0 auch der Windows-Core0 ist (sog. Boot-Core). Die restliche Zuordnung wird bei jedem Rechner-Start neu "ausgewürfelt". Lässt sich z.B. mittels CPUID ermitteln (Stichwort: Initial APIC ID). Bestätigt wurden meine Tests durch AMDs PSCheck. Dort findet man unter File/Settings/CPU-Settings genau die mit CPUID ermittelten Zuordnungen. Also z.B.: Windows-Core3 (Task-Manager) ist nicht unbedingt BD-Core3, kann 1 bis 7 sein (bei 8 aktiven Cores).
ZEN werden wir sehen...
Der Windows-Sheduler verteilt die Aufgaben nicht klug auf die Kerne, deshalb mache ich's für meine Software jetzt selbst, was für meinen Rechner funktioniert. Es soll aber nicht nur auf einem Rechner funktionieren, sondern immer.
Das wäre das blödestes überhaupt, wie man die CPU-Kerne gruppieren könnte. Dann müsste jedes Programm das erst austesten.
Ich hoffe mal, du hast unrecht. Hast du das mittels eines Benchmarks validiert?
Die feste Zuordnung wäre auch bei Bulldozer sinnvoll. Der erste Kern eines Moduls wird langsamer, wenn der zweite Kern des Moduls was zu tun hat. Bei Zen ist ähnliches zu erwarten.
EDIT: Ich habe das jetzt nochmal für einen Intel Atom N570 mit Windows XP 32 Bit überprüft. Dort sieht's wie folgt aus:
Logischer Kern 0 => Rechnet auf Kern A
Logischer Kern 1 => Rechnet auf Kern B
Logischer Kern 2 => Rechnet auf Kern A
Logischer Kern 3 => Rechnet auf Kern B
Das blieb zumindest über zwei Reboots so. Dort kommen also erst die "realen" Kerne und dann die SMT-Zwillinge. Beim i7-2640M auf Windows 7 64 Bit ist es immer gerade anders herum.
Bleibt die Frage, wie bekomme ich das als Programmierer heraus, wie die Kerne miteinander verquickt sind?

Captn-Future schrieb:Die meisten vermuten ja, dass nur aktive Tasks (also gestartete Programme) CPU-Zeit benötigen und so die Kerne durch den Scheduler sinnvoll belegt werden sollten. Natürlich findet Taskhopping statt und gerade bei den AMD-APUs/Bullis oder auch Intel-CPUs mit HT sollten zuerst alle "echten Kerne" belegt werden bevor HT oder eben die zweiten Recheneinheiten eines Kernes genutzt werden. Gerade System-Tasks oder Anwendungen die im Hintergrund laufen brauchen auch, nicht viel oder jede Menge, Rechenzeit. Mitlerweile macht der Scheduler das auch unter Windows 7 sehr gut. (In der Hoffnung, dass die Kerne 1+2 sowie 3+4 meiner A10 6700 APU zusammen gehören.) Jedenfalls belegt er bei 7-Zip, wenn ich 2 Kerne nutzen will, auch nur Kern 1 und 3.
Unter dem Strich ist es aber trotzdem nicht unbedingt die Aufgabe der CPU die Tasks zu verwalten, sondern vom Betriebssystem. Sollten die Tasks erheblich springen und immer wieder den Kern wechseln, sieht es wahrscheinlich blöd aus, aber unterm Strich wird es kaum schneller gehen, wenn man den Task auf einem Kern festtackert.
Helle53 schrieb:Ist hier OT (vielleicht bei Programmieren besser aufgehoben), deshalb nur kurz: Habe eben ein kleines Progrämmchen geschrieben, das 2 Threads mit 256-Bit-Code (Float-DP) erstellt. Diese Threads werden unterschiedlichen Cores zugewiesen und dann die Ausführungszeiten gemessen. Die Zeiten, die sich signifikant (länger) von anderen Core-Kombinationen unterscheiden, repräsentieren ein "Bulldozer-Paar" (wegen FPU-Sharing 256-Bit). Im Moment sind bei mir beispielsweise die "Windows-Cores" 2 und 5 ein solches Paar. Diese Zuordnung lässt sich auch aus der InitialAPICID-Liste (CPUID) herleiten.
Getestet mit FX-8120 und Win7/64.
BoMbY schrieb:Scheint mir aber arg merkwürdig zu sein, dass Microsoft das so durch würfelt? Das hört sich ja schon fast nach Sabotage an - ich würde mal wetten, dass praktisch keine Software z.B. GetLogicalProcessorInformationEx korrekt auswertet.
Edit: Wie sieht bei solchen AMD-Prozzis der Output von coreinfo aus?
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
So, ich habe gerade mal Coreinfo von Sysinternals auf meinem i7 3770k (4c/8t) laufen lassen:
Sieht also so aus, als würden bei Intel die logischen Prozessoren schön der Reihe nach den physischen Prozessoren zugeordnet - ich denke jedenfalls mal, die Sternchen stellen die logischen Cores in der korrekten Reihenfolge dar - wobei Nummern natürlich schöner wären. Wie sieht das jetzt bei Bulldozer und Konsorten aus? Ich habe leider keinen hier, nur noch einen Jaguar ohne CMT/SMT.
Code:
C:\Test>coreinfo -scgl
Coreinfo v3.31 - Dump information on system CPU and memory topology
Copyright (C) 2008-2014 Mark Russinovich
Sysinternals - www.sysinternals.com
Logical to Physical Processor Map:
**------ Physical Processor 0 (Hyperthreaded)
--**---- Physical Processor 1 (Hyperthreaded)
----**-- Physical Processor 2 (Hyperthreaded)
------** Physical Processor 3 (Hyperthreaded)
Logical Processor to Socket Map:
******** Socket 0
Logical Processor to Cache Map:
**------ Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**------ Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**------ Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64
******** Unified Cache 1, Level 3, 8 MB, Assoc 16, LineSize 64
--**---- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**---- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**---- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64
----**-- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**-- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**-- Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64
------** Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------** Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------** Unified Cache 4, Level 2, 256 KB, Assoc 8, LineSize 64
Logical Processor to Group Map:
******** Group 0Sieht also so aus, als würden bei Intel die logischen Prozessoren schön der Reihe nach den physischen Prozessoren zugeordnet - ich denke jedenfalls mal, die Sternchen stellen die logischen Cores in der korrekten Reihenfolge dar - wobei Nummern natürlich schöner wären. Wie sieht das jetzt bei Bulldozer und Konsorten aus? Ich habe leider keinen hier, nur noch einen Jaguar ohne CMT/SMT.
Hier gibt's hoffentlich ein ruhiges Plätzchen für die Problemlösung.
Also ich habe folgendes Szenario: Ich starte ein sehr FPU-lastiges Simulationsprogramm (das single-threaded arbeitet) x-mal mit jeweils leicht anderen Parametern. An dem Programm kann man nichts umschreiben. Das Programm profitiert bei Sandy- und IvyBrigde Prozessoren praktisch kaum von Hyperthreading. Da jede gestartete Instanz viel RAM benötigt, würde ich gerne nur so viele Threads starten, wie ich physische Kerne habe.
Tue ich das, lässt Windows 7 Pro 64 Bit hin- und wieder zwei Instanzen des Programms auf den zwei logischen Prozessoren eines Kerns laufen. Bindet man die Programme an die richtigen Kerne und setzt die Priorität auf "hoch" kann man durchaus über 10 % Geschwindigkeit gewinnen. Um das aber automatisiert zu machen, muss ich wissen, welche logischen Kerne unter Windows auf dem gleichen physikalischen Kern (mit seinen zwei logischen Kernen) laufen.
@helle53: Ich habe das allmächtige Google nach APICID gefragt und bin neben vielen nutzlosen Links nur auf die Bachelorarbeit eines Herrn Robert Meier gestoßen. Wie kann ich die Liste schnell auf einem Rechner auslesen?
Könnte man evtl. auch dein Testprogramm mit dem FPU-Stresser bekommen? Ich habe es jetzt noch auf einem Core-i7 Quad erster Generation mit Windows 7 Pro 64 Bit getestet. Dort hat man das gleiche wie beim i7-2640M.
Von daher kann ich dein Ergebnis absolut nicht glauben. Mir erschließt sich die Intuition hinter einer zufälligen Verteilung nicht. Programmierer hassen Chaos, das muss ein Messfehler sein.
Ich habe mein eigenes Testprogramm für solche Dinge mal etwas überarbeitet und samt Quellcode (in C# für .NET auf Windows) online gestellt [1]. Als Entwicklungsumgebung benötigt man SharpDevelop 3.2, falls es jemand selbst kompilieren will. Man kann auch einfach die .exe-Datei ausführen, die befindet sich im Archiv unter "Newton Optimisation Bench V4\Newton Optimisation Bench\bin\Release\Newton Optimisation Bench.exe".
[1] - http://foveon.de/cp/NOB/Newton_Optimisation_Bench_V4.zip
Zur Bedienung der Software: Rechts stellt man die Priorität ein (am besten auf "Normal" lassen) und darunter an welchen Kern die Software gebunden wird. Mit "Start" startet man das Benchmark, was dann kontinuierlich einen Optimierungsalgorithmus durchläuft. Derweil bekommt man ständig die Punktzahl des letzten Durchlaufs angezeigt. Gedacht war's mal, um die real anliegende Turbotaktrate zu prüfen.
Startet man das Programm ein zweites mal, kann man mit dem Spielen anfangen. Man bindet z.B. ein Programm an Kern 0, das zweite an Kern 1 und schaut auf die erzielten Punkte. Wenn es deutlich langsamer rechnet als die Kombination 0 und 2, dann nutzen die Windows Kerne 0 und 1 die zwei logischen Kerne des gleichen physischen Prozessorkerns.
--- Update ---
Also ich habe folgendes Szenario: Ich starte ein sehr FPU-lastiges Simulationsprogramm (das single-threaded arbeitet) x-mal mit jeweils leicht anderen Parametern. An dem Programm kann man nichts umschreiben. Das Programm profitiert bei Sandy- und IvyBrigde Prozessoren praktisch kaum von Hyperthreading. Da jede gestartete Instanz viel RAM benötigt, würde ich gerne nur so viele Threads starten, wie ich physische Kerne habe.
Tue ich das, lässt Windows 7 Pro 64 Bit hin- und wieder zwei Instanzen des Programms auf den zwei logischen Prozessoren eines Kerns laufen. Bindet man die Programme an die richtigen Kerne und setzt die Priorität auf "hoch" kann man durchaus über 10 % Geschwindigkeit gewinnen. Um das aber automatisiert zu machen, muss ich wissen, welche logischen Kerne unter Windows auf dem gleichen physikalischen Kern (mit seinen zwei logischen Kernen) laufen.
@helle53: Ich habe das allmächtige Google nach APICID gefragt und bin neben vielen nutzlosen Links nur auf die Bachelorarbeit eines Herrn Robert Meier gestoßen. Wie kann ich die Liste schnell auf einem Rechner auslesen?
Könnte man evtl. auch dein Testprogramm mit dem FPU-Stresser bekommen? Ich habe es jetzt noch auf einem Core-i7 Quad erster Generation mit Windows 7 Pro 64 Bit getestet. Dort hat man das gleiche wie beim i7-2640M.
Von daher kann ich dein Ergebnis absolut nicht glauben. Mir erschließt sich die Intuition hinter einer zufälligen Verteilung nicht. Programmierer hassen Chaos, das muss ein Messfehler sein.
Ich habe mein eigenes Testprogramm für solche Dinge mal etwas überarbeitet und samt Quellcode (in C# für .NET auf Windows) online gestellt [1]. Als Entwicklungsumgebung benötigt man SharpDevelop 3.2, falls es jemand selbst kompilieren will. Man kann auch einfach die .exe-Datei ausführen, die befindet sich im Archiv unter "Newton Optimisation Bench V4\Newton Optimisation Bench\bin\Release\Newton Optimisation Bench.exe".
[1] - http://foveon.de/cp/NOB/Newton_Optimisation_Bench_V4.zip
Zur Bedienung der Software: Rechts stellt man die Priorität ein (am besten auf "Normal" lassen) und darunter an welchen Kern die Software gebunden wird. Mit "Start" startet man das Benchmark, was dann kontinuierlich einen Optimierungsalgorithmus durchläuft. Derweil bekommt man ständig die Punktzahl des letzten Durchlaufs angezeigt. Gedacht war's mal, um die real anliegende Turbotaktrate zu prüfen.
Startet man das Programm ein zweites mal, kann man mit dem Spielen anfangen. Man bindet z.B. ein Programm an Kern 0, das zweite an Kern 1 und schaut auf die erzielten Punkte. Wenn es deutlich langsamer rechnet als die Kombination 0 und 2, dann nutzen die Windows Kerne 0 und 1 die zwei logischen Kerne des gleichen physischen Prozessorkerns.
--- Update ---
So, ich habe gerade mal Coreinfo von Sysinternals auf meinem i7 3770k (4c/8t) laufen lassen:
Code:[/QUOTE] Danke für den Link. Das hilft sehr weiter. :)
Gerne, hier was zum testen:
http://www.mdcc-fun.de/k.helbing/CorePairing/CorePairing.zip
Geht für AMD und Intel.
Ist aber rel. einfach gehalten; z.B. kein Test ob AVX überhaupt verfügbar ist.
Habe eben noch einen HT (oder ...)-Test eingebaut, kann das aber für AMD zu Hause nicht testen (der FX steht im Büro).
@BoMbY: Microsoft ist da unschuldig, das Auslesen mittels CPUID würde z.B. unter Linux das gleiche Ergebnis bringen!
http://www.mdcc-fun.de/k.helbing/CorePairing/CorePairing.zip
Geht für AMD und Intel.
Ist aber rel. einfach gehalten; z.B. kein Test ob AVX überhaupt verfügbar ist.
Habe eben noch einen HT (oder ...)-Test eingebaut, kann das aber für AMD zu Hause nicht testen (der FX steht im Büro).
@BoMbY: Microsoft ist da unschuldig, das Auslesen mittels CPUID würde z.B. unter Linux das gleiche Ergebnis bringen!
Verdammt, da habe ich am falschen Ende gespart! Das Anzeigefenster war für einige Geräte zu klein bemessen, so dass nicht alles angezeigt wurde. Bitte nochmal runterladen. Sorry!
Der ausgewählte Windows-Core wird mit allen anderen Cores (zum Test auch mit sich selbst) gepaart. Jeder der beiden Cores erhält dann einen eigenen Thread und das Test-Programm (übrigens eine iterative Sinus-Berechnung 256-Bit) wird gestartet. Die längste Ausführungs-Zeit ist die Paarung mit sich selbst (logisch), die zweitlängste die Paarung mit dem "Core-Partner".
Der ausgewählte Windows-Core wird mit allen anderen Cores (zum Test auch mit sich selbst) gepaart. Jeder der beiden Cores erhält dann einen eigenen Thread und das Test-Programm (übrigens eine iterative Sinus-Berechnung 256-Bit) wird gestartet. Die längste Ausführungs-Zeit ist die Paarung mit sich selbst (logisch), die zweitlängste die Paarung mit dem "Core-Partner".
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Guten Morgen, so schaut es bei meinem FX-8350 aus
Code:
Coreinfo v3.31 - Dump information on system CPU and memory topology
Copyright (C) 2008-2014 Mark Russinovich
Sysinternals - [url]www.sysinternals.com[/url]
[Spoiler]
Microsoft Windows [Version 10.0.14393]
(c) 2016 Microsoft Corporation. Alle Rechte vorbehalten.
AMD FX(tm)-8350 Eight-Core Processor
AMD64 Family 21 Model 2 Stepping 0, AuthenticAMD
Microcode signature: 06000822
HTT * Multicore
HYPERVISOR - Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
SVM * Supports AMD hardware-assisted virtualization
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT * Supports AMD SKINIT
[/Spoiler]
Logical to Physical Processor Map:
**------ Physical Processor 0 (Hyperthreaded)
--**---- Physical Processor 1 (Hyperthreaded)
----**-- Physical Processor 2 (Hyperthreaded)
------** Physical Processor 3 (Hyperthreaded)
Logical Processor to Socket Map:
******** Socket 0
Logical Processor to NUMA Node Map:
******** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
*------- Data Cache 0, Level 1, 16 KB, Assoc 4, LineSize 64
**------ Instruction Cache 0, Level 1, 64 KB, Assoc 2, LineSize 64
**------ Unified Cache 0, Level 2, 2 MB, Assoc 16, LineSize 64
******** Unified Cache 1, Level 3, 8 MB, Assoc 64, LineSize 64
-*------ Data Cache 1, Level 1, 16 KB, Assoc 4, LineSize 64
--*----- Data Cache 2, Level 1, 16 KB, Assoc 4, LineSize 64
--**---- Instruction Cache 1, Level 1, 64 KB, Assoc 2, LineSize 64
--**---- Unified Cache 2, Level 2, 2 MB, Assoc 16, LineSize 64
---*---- Data Cache 3, Level 1, 16 KB, Assoc 4, LineSize 64
----*--- Data Cache 4, Level 1, 16 KB, Assoc 4, LineSize 64
----**-- Instruction Cache 2, Level 1, 64 KB, Assoc 2, LineSize 64
----**-- Unified Cache 3, Level 2, 2 MB, Assoc 16, LineSize 64
-----*-- Data Cache 5, Level 1, 16 KB, Assoc 4, LineSize 64
------*- Data Cache 6, Level 1, 16 KB, Assoc 4, LineSize 64
------** Instruction Cache 3, Level 1, 64 KB, Assoc 2, LineSize 64
------** Unified Cache 4, Level 2, 2 MB, Assoc 16, LineSize 64
-------* Data Cache 7, Level 1, 16 KB, Assoc 4, LineSize 64
Logical Processor to Group Map:
******** Group 0BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Interessant. Also wird AMD's CMT unter Windows 10 praktisch schon genauso behandelt als wäre es SMT. Ich schätze das könnte bei älteren Windows-Versionen noch anders aussehen? Jedenfalls sollte es so keine Probleme geben, oder stimmt die Zuordnung vielleicht nicht?
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
So intensiv wie helle53 habe ich es noch nicht getestet, daher kann ich nur berichten was mir auffällt.Interessant. Also wird AMD's CMT unter Windows 10 praktisch schon genauso behandelt als wäre es SMT. Ich schätze das könnte bei älteren Windows-Versionen noch anders aussehen? Jedenfalls sollte es so keine Probleme geben, oder stimmt die Zuordnung vielleicht nicht?
Wie geschrieben werden zuerst Core 0-3 (erste Reihe im Taskmanager CPU Diagramm) gepinnt pro Instance ein Pärchen.
Es ist aber auch CoreParking (CC6) an, mit minimum 50% der Kerne aktiv eingestellt.
4 Kerne aktiv (Single Thread) http://abload.de/img/parkcontrol-50_taskmak6ouq.jpg
6 Kerne aktiv (Desktop idle) http://abload.de/img/parkcontrol-50_taskmakdr4x.jpg
Der CPUz dump zeigt die core ID passend zur Thread ID (0-7).
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Also bei mir ist das gerade so, dass wenn ich z.B. nur einen Thread mit diesem Newton Test von @miriquidi starte, mit 'all' affinity, wird der von Windows 10 anscheinend mehr oder weniger Round Robin mäßig über die Kerne hin und her geschoben. Auch mit vier Threads sieht es ähnlich aus, auf allen logischen Cores ein bisschen Auslastung.
Ich glaube Windows macht (immer noch) überhaupt kein intelligentes Thread-Management ...
--- Update ---
Obwohl, ist auch nicht ganz korrekt. Wenn man zwei Threads pinned, dann werden zwei weitere Threads mit 'all' wenigstens nicht auf die sekundären Cores verschoben:
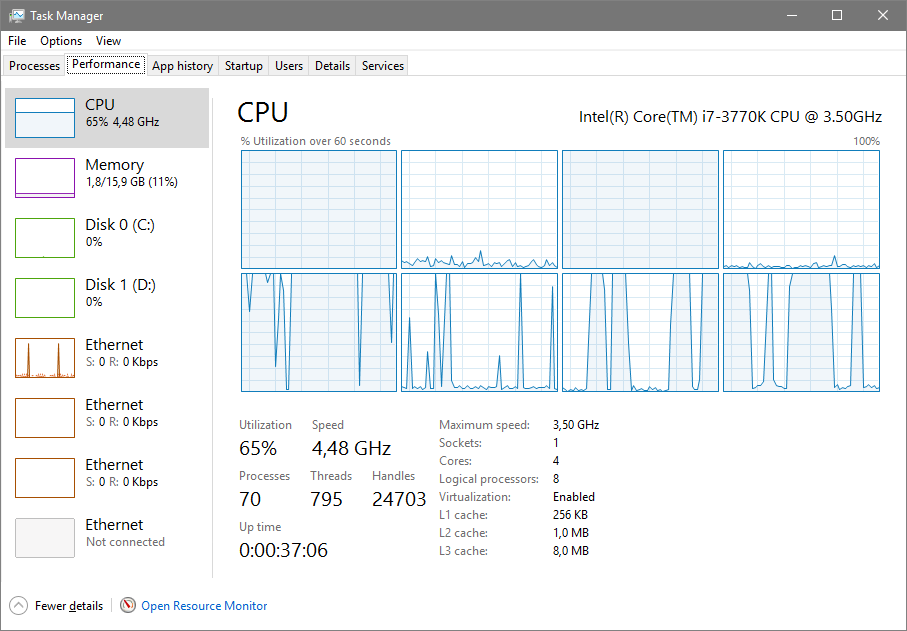
--- Update ---
Wobei, wenn ich einen Newton-Thread pinne, und dann Intel Burn Test mit 3 Threads starte, fängt irgendwas an den zweiten logischen Core zu nutzen, was in der Zeit dann den Newton ausbremst:
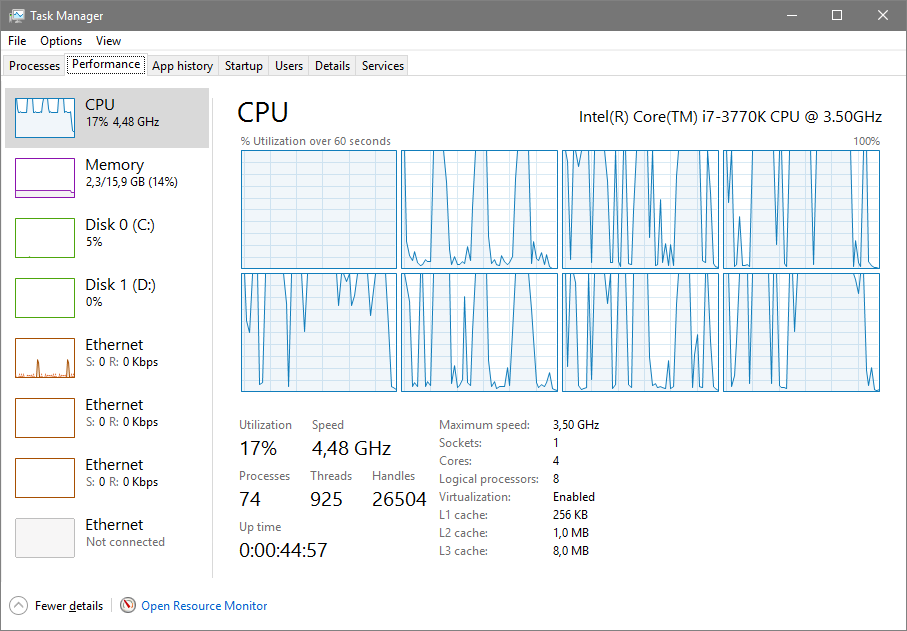
Ich glaube Windows macht (immer noch) überhaupt kein intelligentes Thread-Management ...
--- Update ---
Obwohl, ist auch nicht ganz korrekt. Wenn man zwei Threads pinned, dann werden zwei weitere Threads mit 'all' wenigstens nicht auf die sekundären Cores verschoben:
--- Update ---
Wobei, wenn ich einen Newton-Thread pinne, und dann Intel Burn Test mit 3 Threads starte, fängt irgendwas an den zweiten logischen Core zu nutzen, was in der Zeit dann den Newton ausbremst:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 15.753
- Renomée
- 2.500
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 7800X3D
- Mainboard
- MSI MPG X670E CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 32GB DDR5-6000 CL36
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Crucial T705 4TB
- HDD
- Western Digital WD Red 2TB, 3TB, 8TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Interessant. Also wird AMD's CMT unter Windows 10 praktisch schon genauso behandelt als wäre es SMT. Ich schätze das könnte bei älteren Windows-Versionen noch anders aussehen? Jedenfalls sollte es so keine Probleme geben, oder stimmt die Zuordnung vielleicht nicht?
Das wurde vor dem Sheduler Update von Windows auch mal anders gehandhabt. Seinerzeit hatte ich mal einen Screenshot von der Prozessorangabe vom Cinebench gemacht. Vor dem Update zeigte es 8 Kerne mit 8 Threads an, danach 4 Kerne mit 8 Threads.
Das dolle Update bewirkte also vor allem das die Prozessoren wie SMT Prozessoren behandelt werden um bei Teilnutzung zuerst alle Module mit einem Thread zu belasten anstatt Module zu deaktivieren und mit dem dort gesparten Strom die Taktfrequenz stärker zu erhöhen. Da gab es seinerzeit auch einen netten Test bei ht4u.
http://ht4u.net/reviews/2011/amd_bulldozer_fx_prozessoren/index51.php
http://ht4u.net/reviews/2011/amd_bulldozer_fx_prozessoren/index52.php
Mit einem ur Windows 7 ohne Updates müßte er immernoch wie ein normaler 8 Kerner behandelt werden.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@BoMbY
Nutzt du Core Parking und Turbo oder ohne?
Hab mal das Progrämmchen von hell53 angeschaut, es bestätigt eigentlich meine Annahme: http://abload.de/img/corpairring_all6wrzf.jpg
Die Zuweisung der CoreID wird 1:1 auf die Threads verlinkt.
Apropos, im CPUz dump file habe ich noch eine nette Passage gefunden, wusste ich z.B. auch nicht:
Back Bone?")
Nutzt du Core Parking und Turbo oder ohne?
Hab mal das Progrämmchen von hell53 angeschaut, es bestätigt eigentlich meine Annahme: http://abload.de/img/corpairring_all6wrzf.jpg
Die Zuweisung der CoreID wird 1:1 auf die Threads verlinkt.
Apropos, im CPUz dump file habe ich noch eine nette Passage gefunden, wusste ich z.B. auch nicht:
Code:
PCI capability
Caps class HyperTransport
Caps offset 0xC4
Caps revision 3.00
Interface type Slave/Primary
[B]Link 0[/B] width (in/out) [B]16 bits/16 bits[/B]
Link 0 frequency 2200 MHz
[B]Link 1[/B] width (in/out) [B]8 bits/8 bits[/B]
Link 1 frequency 200 MHzBack Bone?
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Kein Core Parking soweit ich weiß. Ich nutze den Turbo mit 45x für das OC, die Kerne sind synchronisiert, und der hält die 4.5 GHz permanent unter Vollast.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Kannst mit ParkControl nachschauen, ist in meiner Signatur verlinkt.Kein Core Parking soweit ich weiß. Ich nutze den Turbo mit 45x für das OC, die Kerne sind synchronisiert, und der hält die 4.5 GHz permanent unter Vollast.
Turbo bedeutet auch Kerne Parken, daher auch das Thread hoppeln.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.462
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Nein, da wird nix geparkt.
@helle53: Bei mir kommt mit CorePairing.exe auch die Zuordnung der logischen Kerne 0 bis 3 auf die physikalischen Kerne A und B folgende Reihenfolge heraus:
AA*BB* (Windows 7 Pro 64 Bit, i7-2640M)
Allerdings ist der Zeitunterschied nicht sehr drastisch. Läuft A und A*, sind es ca. 1750 ms, bei A und B sind es 1660 ms.
Gibt's hier noch Bulldozer-Nutzer mit Windows 7 oder 8?
AA*BB* (Windows 7 Pro 64 Bit, i7-2640M)
Allerdings ist der Zeitunterschied nicht sehr drastisch. Läuft A und A*, sind es ca. 1750 ms, bei A und B sind es 1660 ms.
Gibt's hier noch Bulldozer-Nutzer mit Windows 7 oder 8?
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ok, danke. Wenn dir langweilig ist, kannst es mal noch mit "Parken" probieren.Nein, da wird nix geparkt.
Ich gehe davon aus, dass damit ein Zwangszuteilung auf die "primären" Kerne geschieht.
AA entspricht dann einem Core und BB dem zweiten?@helle53: Bei mir kommt mit CorePairing.exe auch die Zuordnung der logischen Kerne 0 bis 3 auf die physikalischen Kerne A und B folgende Reihenfolge heraus:
AA*BB* (Windows 7 Pro 64 Bit, i7-2640M)
Allerdings ist der Zeitunterschied nicht sehr drastisch. Läuft A und A*, sind es ca. 1750 ms, bei A und B sind es 1660 ms.
Gibt's hier noch Bulldozer-Nutzer mit Windows 7 oder 8?
Hab leider kein Win7 mehr mit Piledriver, nur eine Athlon 5350 APU.
Eigentlich sind A und A* die zwei logischen Kernen des ersten physischen Kerns. Meine Bezeichnung ist aber nicht sehr gut, das muss irgendwie besser gehen.
A1 und A2 als logische Kerne des physischen Kerns A?
A1 und A2 als logische Kerne des physischen Kerns A?
Habe das Progrämmchen (Download s.o.) nochmal etwas überarbeitet (z.B. jetzt vergleichbare Zeiten AMD-Intel; für die Benchmark-Fans ).
Für den FX-8120 unter Win7/64 sieht es so aus:

Man beachte die mit CPUID ermittelte Core-Reihenfolge. Sicher ist da nur die 1.Postion von Core0, der Rest ist nach jedem Rechner-Start anders.
Tests ergaben, das die CPUID-Cores 0/1, 2/3 usw. immer ein "Paar" bilden (wie anzunehmen), dies aber dann im Taskmanager andere Zuordnungen ergibt (wichtig z.B. fürs Festpinnen).
Die Screenshots von WindHund zeigen aber eine "geordnete" Core-Reihenfolgen für den FX-8350. Eine Erklärung wäre, das AMD den Käse bei den 81xx-ern erkannt hat und bei Nachfolgern dies korrigierte.
).Für den FX-8120 unter Win7/64 sieht es so aus:
Man beachte die mit CPUID ermittelte Core-Reihenfolge. Sicher ist da nur die 1.Postion von Core0, der Rest ist nach jedem Rechner-Start anders.
Tests ergaben, das die CPUID-Cores 0/1, 2/3 usw. immer ein "Paar" bilden (wie anzunehmen), dies aber dann im Taskmanager andere Zuordnungen ergibt (wichtig z.B. fürs Festpinnen).
Die Screenshots von WindHund zeigen aber eine "geordnete" Core-Reihenfolgen für den FX-8350. Eine Erklärung wäre, das AMD den Käse bei den 81xx-ern erkannt hat und bei Nachfolgern dies korrigierte.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Besser, ja!Eigentlich sind A und A* die zwei logischen Kernen des ersten physischen Kerns. Meine Bezeichnung ist aber nicht sehr gut, das muss irgendwie besser gehen.
A1 und A2 als logische Kerne des physischen Kerns A?
Ok, hab jetzt auch nach einem "deep sleep state" unter Volllast nebenher laufen lassen:http://abload.de/img/boinctn-grideinstein_atrc2.jpgMan beachte die mit CPUID ermittelte Core-Reihenfolge. Sicher ist da nur die 1.Postion von Core0, der Rest ist nach jedem Rechner-Start anders.
Tests ergaben, das die CPUID-Cores 0/1, 2/3 usw. immer ein "Paar" bilden (wie anzunehmen), dies aber dann im Taskmanager andere Zuordnungen ergibt (wichtig z.B. fürs Festpinnen).
Die Screenshots von WindHund zeigen aber eine "geordnete" Core-Reihenfolgen für den FX-8350. Eine Erklärung wäre, das AMD den Käse bei den 81xx-ern erkannt hat und bei Nachfolgern dies korrigierte.
Sehe gerade die Kiste läuft schon 72h unter Last (davon 6 Stunden im 3,9W Modus)

hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.824
- Renomée
- 331
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Hier mal von meinem Kaveri Arbeitsrechner:
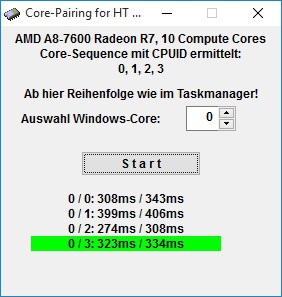
Scheint hier auch geordnet zu sein. Oder vielleicht durchs BIOS maskiert!?
Scheint hier auch geordnet zu sein. Oder vielleicht durchs BIOS maskiert!?
@hoschi_tux: Du stürzt mich in tiefe Depressionen  ! Die längste Ausführungszeit sollte die Paarung 0/0 haben (was ja wohl logisch ist). Lief da irgendein "böses" Programm im Hintergrund? Wie sieht es bei Auswahl der anderen Cores aus? Die Paarungen 1/1, 2/2 und 3/3 sollten immer die "Zeitfresser" sein.
! Die längste Ausführungszeit sollte die Paarung 0/0 haben (was ja wohl logisch ist). Lief da irgendein "böses" Programm im Hintergrund? Wie sieht es bei Auswahl der anderen Cores aus? Die Paarungen 1/1, 2/2 und 3/3 sollten immer die "Zeitfresser" sein.
! Die längste Ausführungszeit sollte die Paarung 0/0 haben (was ja wohl logisch ist). Lief da irgendein "böses" Programm im Hintergrund? Wie sieht es bei Auswahl der anderen Cores aus? Die Paarungen 1/1, 2/2 und 3/3 sollten immer die "Zeitfresser" sein.WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.263
- Renomée
- 548
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- PrimeGrid@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 5950X @ ASRock Taichi X570 & Sapphire RX 7900 XTX Nitro+
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.50
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 8l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3200 CL22 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x Sapphire Radeon RX 7900XTX OC 24GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 11 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@Helle53
Ein bisschen Farbe hat noch nie geschadet, IR und Tiefengenaugikeit (Z) lassen sich auch schön "überlagern" bei der Farbwahl.
Wenn es mal wärmer ist, dann lass ich es mal mit 5GHz fix laufen.
Ein bisschen Farbe hat noch nie geschadet, IR und Tiefengenaugikeit (Z) lassen sich auch schön "überlagern" bei der Farbwahl.
Wenn es mal wärmer ist, dann lass ich es mal mit 5GHz fix laufen.
hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.824
- Renomée
- 331
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Lief da irgendein "böses" Programm im Hintergrund? Wie sieht es bei Auswahl der anderen Cores aus? Die Paarungen 1/1, 2/2 und 3/3 sollten immer die "Zeitfresser" sein.
Das kann natürlich sein, ich simuliere nebenbei immer mal was. Bin mir gerade nicht sicher, ob da eine nebenher lief. Wenn die aktuellen Simulationen durch sind, liefere ich noch mal nach
Atombossler
Admiral Special
- Mitglied seit
- 28.04.2013
- Beiträge
- 1.423
- Renomée
- 65
- Standort
- Andere Sphären
- Mein Laptop
- Thinkpad 8
- Details zu meinem Desktop
- Prozessor
- A8-7600@3.25Ghz
- Mainboard
- Asus A88X-PRO
- Kühlung
- NoFan CR80 EH
- Speicher
- 16Gb G-Skill Trident-X DDR3 2400
- Grafikprozessor
- APU
- Display
- Acer UHD 4K2K
- SSD
- Samsung 850 PRO
- HDD
- 2xSamsung 1TB HDD (2,5")
- Optisches Laufwerk
- Plexi BD-RW
- Soundkarte
- OnBoard Geraffel
- Gehäuse
- Define R2
- Netzteil
- BeQuiet
- Betriebssystem
- Win7x64-PRO
- Webbrowser
- Chrome
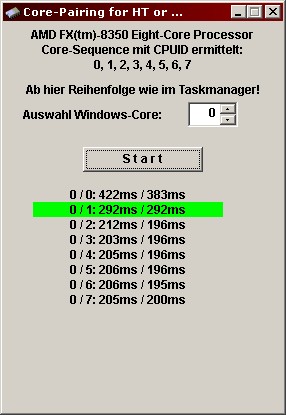
Also bei meinem FX 8350 ist auch alles schön ordentlich (System @ Idle).
Ähnliche Themen
- Antworten
- 171
- Aufrufe
- 5K
- Antworten
- 76
- Aufrufe
- 4K
- Antworten
- 585
- Aufrufe
- 28K
- Antworten
- 15
- Aufrufe
- 585