App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
- Foren
- Planet 3DNow! Community
- Planet 3DNow! Distributed Computing
- Team Planet 3DNow!
- Café Planet 3DNow!
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
16. Pentathlon 2025 - Jagdrennen (Einstein@Home)
- Ersteller FritzB
- Erstellt am
FritzB
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 25.12.2002
- Beiträge
- 3.591
- Renomée
- 2.242
- Standort
- Märkisch Kongo
- Aktuelle Projekte
- WCG, GPUGrid
- Lieblingsprojekt
- gute Frage
- Meine Systeme
- 3x Ryzen 7950X, 9950X, 4800H, 7945HX, RTX 4070 Ti, RTX 4070 Ti Super, GTX 1650 Ti, RTX 4090, Radeon Pro VII
- BOINC-Statistiken

- Mein Desktopsystem
- mehrere
- Mein Laptop
- Lenovo ideapad 3, Ryzen 7 4800H, 1650 Ti
- Details zu meinem Desktop
- Prozessor
- 7950X, 9950X, 7945HX
- Mainboard
- jeweils eins
- Kühlung
- BQ Silent Loop 2 280, Arctic Liquid Freezer II 240, Scythe Fuma 3
- Speicher
- ganz viel DDR4 und DDR5
- Grafikprozessor
- GeForce 4090, 4070 Ti Super, 4070 Ti
- Display
- LG UltraGear 27GP850-B
- SSD
- diverse
- Optisches Laufwerk
- hatter
- Gehäuse
- Nanoxia Deep Silence 5, BQ Silent Base 500/600 u.a.
- Netzteil
- Corsair, Seasonic, BQ...
- Betriebssystem
- Windows 11 x64/Pro, Linux Mint 21.x
Für alle Fragen, die zum Jagdrennen (Einstein@home) im Rahmen des Pentathlon 2025 auftreten, soll dieser Thread dienen.
Es wird zwei Tage mit Punktebonus geben. Die Tage werden jeweils am entsprechenden Tag bekanntgegeben. Daher möglichst an diesen Tagen die Ergebnisse hochladen!
1. Bonustag: 14.05.2025 - es gibt 30%
2. Bonustag: 16.05.2025 - es gibt 30%
Zeitraum:
Start: 12.05.2025 um 0:00 Uhr (UTC) bzw. 2:00 Uhr (MESZ)
Ende: 19.05.2025 um 0:00 Uhr (UTC) bzw. 2:00 Uhr (MESZ)
Ankündigung der Pentathlon-Initiatoren:
Projektseite:
 einstein.phys.uwm.edu
einstein.phys.uwm.edu
Konto erstellen:
https://einsteinathome.org/de/user/registration
Alternativ über den BOINC-Manager beim Projekt mitmachen
Unser Team mit Beitrittslink:
https://einsteinathome.org/de/community/teams/172823
Unserem Team bitte beitreten bevor die Disziplin startet bzw. bevor Punkte erzielt wurden. Dazu auf der Teamseite ins Projekt einloggen und dann "Team beitreten (join team)" wählen. Teamwechsel während des Wettkampfes sind verpönt!
Schwacher Schlüssel für den P3D-Cluster:
Der schwache Kontoschlüssel für dieses Projekt:
Lokale Dateien:
account_einstein.phys.uwm.edu.xml
Windows: C:\ProgramData\BOINC\
Linux: /var/lib/boinc-client/
Weitere Informationen in unserem DC-Wiki:
Besonderheiten:
Hostseintrag zum Bunkern:
Bunkern per Instanzen statt via Hostseintrag (empfohlen):
Es wird zwei Tage mit Punktebonus geben. Die Tage werden jeweils am entsprechenden Tag bekanntgegeben. Daher möglichst an diesen Tagen die Ergebnisse hochladen!
1. Bonustag: 14.05.2025 - es gibt 30%
2. Bonustag: 16.05.2025 - es gibt 30%
Zeitraum:
Start: 12.05.2025 um 0:00 Uhr (UTC) bzw. 2:00 Uhr (MESZ)
Ende: 19.05.2025 um 0:00 Uhr (UTC) bzw. 2:00 Uhr (MESZ)
Ankündigung der Pentathlon-Initiatoren:
SETI.Germany Forum - BOINC Pentathlon 2025: 5th project in the discipline Steeplechase
BOINC Pentathlon 2025: 5th project in the discipline Steeplechase
www.seti-germany.de
Projektseite:
Einstein@Home
Konto erstellen:
https://einsteinathome.org/de/user/registration
Alternativ über den BOINC-Manager beim Projekt mitmachen
Unser Team mit Beitrittslink:
https://einsteinathome.org/de/community/teams/172823
Unserem Team bitte beitreten bevor die Disziplin startet bzw. bevor Punkte erzielt wurden. Dazu auf der Teamseite ins Projekt einloggen und dann "Team beitreten (join team)" wählen. Teamwechsel während des Wettkampfes sind verpönt!
Schwacher Schlüssel für den P3D-Cluster:
Der schwache Kontoschlüssel für dieses Projekt:
Code:
307184_6d6bfcba5cde842632227dc5fd0b8266Lokale Dateien:
account_einstein.phys.uwm.edu.xml
Code:
<account>
<master_url>http://einstein.phys.uwm.edu/</master_url>
<authenticator>307184_6d6bfcba5cde842632227dc5fd0b8266</authenticator>
</account>Linux: /var/lib/boinc-client/
Weitere Informationen in unserem DC-Wiki:
Besonderheiten:
- Quorum=2 -> Pending (ab dem 17.05. möglichst keine frischen WUs mehr holen, sondern vorher genügend holen, damit sie bis zum Ende reichen).
- Inzwischen läuft das Projekt auf NVIDIA Karten genauso gut wie auf ATI/AMD Karten.
- Wenn möglich nicht mit CPUs berechnen, die brauchen wir bei anderen Projekten.
- Zwei WUs gleichzeitig laufen zu lassen ist in der Regel effizienter als nur eine. Dies am besten leicht versetzt, da insb. am Anfang und am Ende der WU ein großer CPU-Anteil ist. Wegen hoher CPU-Last am besten einen Kern pro WU freihalten.
- Die beste Ausbeute bringen "All-Sky Gravitational Wave search on O3 (GPU) [O3AS]", gefolgt von "Binary Radio Pulsar Search (MeerKAT, GPU) [BRP7]".
Hostseintrag zum Bunkern:
Code:
#Einstein@home
127.0.0.1 scheduler.einsteinathome.org
::1 scheduler.einsteinathome.orgEs wird nicht der Upload der fertigen WU blockiert, sondern nur das Fertigmelden. Damit werden die Ergebnisse direkt nach und nach hochgeladen und nicht alle auf einmal. Punkte gibt es erst, wenn man den Hosteintrag wieder entfernt bzw. blockiert.
Bunkern per Instanzen statt via Hostseintrag (empfohlen):
Zuletzt bearbeitet:
Mente
Grand Admiral Special
- Mitglied seit
- 23.05.2009
- Beiträge
- 3.729
- Renomée
- 152
- Aktuelle Projekte
- constalation astroids yoyo
- Lieblingsprojekt
- yoyo doking
- Meine Systeme
- Ryzen 3950x
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD 5800X3D
- Mainboard
- Asus ROG Crosshair VIII Dark Hero
- Kühlung
- Headkiller IV
- Speicher
- 3800CL14 G.Skill Trident Z silber/rot DIMM Kit 32GB, DDR4-3600, CL15-15-15-35 (F4-3600C15D-16GTZ)
- Grafikprozessor
- AMD Radeon RX 6900 XT Ref. @Alphacool
- Display
- MSI Optix MAG27CQ
- SSD
- SN8502TB,MX5001TB,Vector150 480gb,Vector 180 256gb,Sandisk extreme 240gb,RD400 512gb
- HDD
- n/a
- Optisches Laufwerk
- n/a
- Soundkarte
- Soundblaster X4
- Gehäuse
- Phanteks Enthoo Pro 2 Tempered Glass
- Netzteil
- Seasonic Prime GX-850 850W
- Tastatur
- Mountain Everest Max, DE, Logitech G19
- Maus
- Logitech G903 Lightspeed, USB
- Betriebssystem
- Win 10 pro
- Webbrowser
- IE 11 Mozilla Opera
- Verschiedenes
- Logitech PRO RENNLENKRAD DD
- Internetanbindung
- ▼500Mbit ▲55Mbit
enigmation
Admiral Special

Der Scheduler wird wohl grad in die Knie gedrückt:
Einstein@Home 09.05.2025 10:03:55 Scheduler request to https://scheduler.einsteinathome.org/EinsteinAtHome_cgi/cgi failed: Timeout was reached
FritzB
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 25.12.2002
- Beiträge
- 3.591
- Renomée
- 2.242
- Standort
- Märkisch Kongo
- Aktuelle Projekte
- WCG, GPUGrid
- Lieblingsprojekt
- gute Frage
- Meine Systeme
- 3x Ryzen 7950X, 9950X, 4800H, 7945HX, RTX 4070 Ti, RTX 4070 Ti Super, GTX 1650 Ti, RTX 4090, Radeon Pro VII
- BOINC-Statistiken
- Mein Desktopsystem
- mehrere
- Mein Laptop
- Lenovo ideapad 3, Ryzen 7 4800H, 1650 Ti
- Details zu meinem Desktop
- Prozessor
- 7950X, 9950X, 7945HX
- Mainboard
- jeweils eins
- Kühlung
- BQ Silent Loop 2 280, Arctic Liquid Freezer II 240, Scythe Fuma 3
- Speicher
- ganz viel DDR4 und DDR5
- Grafikprozessor
- GeForce 4090, 4070 Ti Super, 4070 Ti
- Display
- LG UltraGear 27GP850-B
- SSD
- diverse
- Optisches Laufwerk
- hatter
- Gehäuse
- Nanoxia Deep Silence 5, BQ Silent Base 500/600 u.a.
- Netzteil
- Corsair, Seasonic, BQ...
- Betriebssystem
- Windows 11 x64/Pro, Linux Mint 21.x
Hab keine Probleme 
enigmation
Admiral Special
Interessant, hat noch jemand dieses Verhalten?
Meine 9070 nutzt erst bei 5 WU O3AS parallel das Power Limit von 175W aus, braucht für die 5 dann 2,5h, also im Durchschnitt 25min pro WU.
Bei einer WU alleine legt sich sogar der Lüfter schlafen (ist eine Red Devil).
Meine 9070 nutzt erst bei 5 WU O3AS parallel das Power Limit von 175W aus, braucht für die 5 dann 2,5h, also im Durchschnitt 25min pro WU.
Bei einer WU alleine legt sich sogar der Lüfter schlafen (ist eine Red Devil).
MagicEye04
Grand Admiral Special
- Mitglied seit
- 20.03.2006
- Beiträge
- 23.916
- Renomée
- 2.214
- Standort
- oops,wrong.planet..
- Aktuelle Projekte
- Seti,WCG,Einstein + was gerade Hilfe braucht
- Lieblingsprojekt
- Seti
- Meine Systeme
- R7-1700+GTX1070ti,R7-1700+RadeonVII, FX-8350+GTX1050ti, X4-5350+GT1030, X2-240e+RX460
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Dell Latitude E7240
- Details zu meinem Desktop
- Prozessor
- R9-3950X (@65W)
- Mainboard
- Asus Prime B550plus
- Kühlung
- TR Macho
- Speicher
- 2x16GiB Corsair LPX2666C16
- Grafikprozessor
- Radeon VII
- Display
- LG 32UD99-W 81,3cm
- SSD
- Crucial MX500-250GB, Samsung EVO280 256GB
- HDD
- Seagate 7200.14 2TB (per eSATAp)
- Optisches Laufwerk
- LG DVDRAM GH24NS90
- Soundkarte
- onboard
- Gehäuse
- Nanoxia Deep Silence1
- Netzteil
- BeQuiet StraightPower 11 550W
- Tastatur
- Cherry RS6000
- Maus
- Logitech RX600
- Betriebssystem
- Ubuntu
- Webbrowser
- Feuerfuchs
- Verschiedenes
- 4x Nanoxia Lüfter (120/140mm) , Festplatte in Bitumenbox
O3 oder Meerkat?
Ich bin mit 2x O3 schon gut ausgelastet auf der VII.
Ich bin mit 2x O3 schon gut ausgelastet auf der VII.
enigmation
Admiral Special
O3AS für 20K Credits, hab ich mal ergänzt oben.O3 oder Meerkat?
olsen_gg
Grand Admiral Special
- Mitglied seit
- 02.03.2012
- Beiträge
- 10.868
- Renomée
- 868
- Standort
- Stralsund
- Aktuelle Projekte
- WCG SCC1, HSTB, wechselnde..
- Lieblingsprojekt
- alle medizinisch / pharmazeutischen Projekte
- Meine Systeme
- Ryzen 9 3900X, 2x Ryzen 7 3700X, ( noch vorhanden: i7-4770S, Lappy i7-3630QM, 13x ARM...)
- BOINC-Statistiken

- Details zu meinem Desktop
- Verschiedenes
- Zuviel Details, das muss nicht veröffentlicht werden.
Auf einem PC kriege ich es nicht hin. Einstein möhlt mir die Maschine mit Wuzen für CPU voll. 
Die blockieren die CPU für >6h. Nöööö.
Auf drei anderen geht es richtig mit nur GPU. Ich finde das Problem nicht.
Die blockieren die CPU für >6h. Nöööö.
Auf drei anderen geht es richtig mit nur GPU. Ich finde das Problem nicht.
Hammerhead Shark
Commodore Special
- Mitglied seit
- 22.04.2008
- Beiträge
- 450
- Renomée
- 488
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3900X
- Mainboard
- ASUS Prime X570-PRO
- Kühlung
- be quiet Dark Rock Pro 4
- Speicher
- 2x16GB G.Skill Trident Neo 3600 MHz CL16
- Grafikprozessor
- Power Color RX 9070XT Hellhound
- SSD
- Lexar NM790 4TB; XPG SX8200 PRO 1TB
- Optisches Laufwerk
- LG GGW-H20L
- Gehäuse
- Thermaltake Xaser VI
- Netzteil
- Be Quiet Dark Power 13 - 850W
- Betriebssystem
- openSUSE Tumbleweed; Windows 10 Pro
- Webbrowser
- Firefox
Falsches profil zugewiesen?
olsen_gg
Grand Admiral Special
- Mitglied seit
- 02.03.2012
- Beiträge
- 10.868
- Renomée
- 868
- Standort
- Stralsund
- Aktuelle Projekte
- WCG SCC1, HSTB, wechselnde..
- Lieblingsprojekt
- alle medizinisch / pharmazeutischen Projekte
- Meine Systeme
- Ryzen 9 3900X, 2x Ryzen 7 3700X, ( noch vorhanden: i7-4770S, Lappy i7-3630QM, 13x ARM...)
- BOINC-Statistiken
- Details zu meinem Desktop
- Verschiedenes
- Zuviel Details, das muss nicht veröffentlicht werden.
Ich habe jetzt einfach geschaut, auf welchem Profil die laufen, die laufen... und dann habe ich den, der nicht lief, neu zugewiesen. Der nicht lief, läuft jetzt auch. Mir wird ganz schwindelig...
Hammerhead Shark
Commodore Special
- Mitglied seit
- 22.04.2008
- Beiträge
- 450
- Renomée
- 488
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3900X
- Mainboard
- ASUS Prime X570-PRO
- Kühlung
- be quiet Dark Rock Pro 4
- Speicher
- 2x16GB G.Skill Trident Neo 3600 MHz CL16
- Grafikprozessor
- Power Color RX 9070XT Hellhound
- SSD
- Lexar NM790 4TB; XPG SX8200 PRO 1TB
- Optisches Laufwerk
- LG GGW-H20L
- Gehäuse
- Thermaltake Xaser VI
- Netzteil
- Be Quiet Dark Power 13 - 850W
- Betriebssystem
- openSUSE Tumbleweed; Windows 10 Pro
- Webbrowser
- Firefox
Kurz hinsetzen und ein paar mal bewusst ein- und ausatmen...
Und jetzt wieder VOLLE POWER! Zack zack")
Und jetzt wieder VOLLE POWER! Zack zack
Maverick-F1
Grand Admiral Special
Habe hier echt Probleme die Bunker-Instanzen zu füllen - einmal z.B. die Meldung "Reached daily quota" - bei gerade Mal 11 WUs? 
X_FISH
Grand Admiral Special
- Mitglied seit
- 03.02.2006
- Beiträge
- 5.127
- Renomée
- 2.925
- Aktuelle Projekte
- distributed.net (seit 2000), BOINC (seit 2017)
- BOINC-Statistiken


Wie versprochen: Ein Thread, ein Bild. Es kommt also kein weiteres Bild diesen Pentathlon auf euch zu.
Moose Records präsentiert: Die Abschiedstournee mit dem Titel »Steeplechase« wurde als live-Mitschnitt für die Ewigkeit festgehalten. Die Scheibe bietet ausschließlich neue Titel, bekannt-bewährtes Songmaterial der bisherigen Alben wurde nicht erneut aufgenommen. »Pending Emotions« scheint die Traurigkeit des finalen Abschieds vorwegnehmen zu wollen, jedoch folgt direkt darauf mit den Schurken des Scheiterns, den »Wingmen of failure« eine Abrechnung mit unzuverlässigen falschen Freunden. »If you can't handle it, leave it be« richtet sich mutmaßlich an den gleichen Personenkreis. Mit »Aïs« begeben sich die erfahrenen Musiker auf einen Trip in die Hölle. »The pursuit of gold« bildet als versöhnliche anmutende Ballade das letzte Stück des Livealbums. Gerne hätten wir noch mehr von den Künstlern erlebt, welche sich derzeit auf dem Zenit ihres Schaffens befinden. Ob sie tatsächlich in den Olymp aufsteigen werden? Sie müssen den Test der Zeit bestehen.
Fulminant-furioses Finale!
Zuletzt bearbeitet:
olsen_gg
Grand Admiral Special
- Mitglied seit
- 02.03.2012
- Beiträge
- 10.868
- Renomée
- 868
- Standort
- Stralsund
- Aktuelle Projekte
- WCG SCC1, HSTB, wechselnde..
- Lieblingsprojekt
- alle medizinisch / pharmazeutischen Projekte
- Meine Systeme
- Ryzen 9 3900X, 2x Ryzen 7 3700X, ( noch vorhanden: i7-4770S, Lappy i7-3630QM, 13x ARM...)
- BOINC-Statistiken
- Details zu meinem Desktop
- Verschiedenes
- Zuviel Details, das muss nicht veröffentlicht werden.
Kluge Entscheidung - sofort austreten, das Feuer !!!
olsen_gg
Grand Admiral Special
- Mitglied seit
- 02.03.2012
- Beiträge
- 10.868
- Renomée
- 868
- Standort
- Stralsund
- Aktuelle Projekte
- WCG SCC1, HSTB, wechselnde..
- Lieblingsprojekt
- alle medizinisch / pharmazeutischen Projekte
- Meine Systeme
- Ryzen 9 3900X, 2x Ryzen 7 3700X, ( noch vorhanden: i7-4770S, Lappy i7-3630QM, 13x ARM...)
- BOINC-Statistiken
- Details zu meinem Desktop
- Verschiedenes
- Zuviel Details, das muss nicht veröffentlicht werden.
Nee, Austreten macht mehr spaß, das spitzt so schön!

NEO83
Grand Admiral Special
- Mitglied seit
- 19.01.2016
- Beiträge
- 5.593
- Renomée
- 997
- Standort
- Wilhelmshaven
- Meine Systeme
- R9 7950X & RTX5080 | R5 9600X & RX9070XT | 7940HS & RTX4070
- BOINC-Statistiken

- Mein Desktopsystem
- Kraftzwerg | MiniMe
- Mein Laptop
- ASUS TUF A17 @R9 7940HS @RTX4070
- Details zu meinem Desktop
- Prozessor
- R9 7950X | R5 9600X
- Mainboard
- MSI MAG X870 Tomahawk WIFI | ASUS B850M-Plus WiFi
- Kühlung
- Corsair iCUE LINK H115i RGB | Noctua NH-D12L
- Speicher
- Corsair Vengeance 64GB, DDR5-6000 | TeamGroup 32GB, DDR5 7200
- Grafikprozessor
- PNY GeForce RTX 5080 OC | RX9070XT RedDevil
- Display
- MSI MAG 274UPFDE @UHD @144Hz | MSI MPG ARTYMIS 273CQRDE @WQHD
- SSD
- WD_BLACK SN850X 1TB, WD_BLACK SN850X 2TB | WD Blue 1TB, FIKWOT 2TB
- Optisches Laufwerk
- USB BD-Brenner
- Soundkarte
- Onboard
- Gehäuse
- Corsair Frame 4000D | Jonsbo D31 MESH
- Netzteil
- be quiet! Power Zone 2 1000W | ASUS ROG Loki 1000W Platinum SFX-L
- Tastatur
- Logitech G815
- Maus
- Logitech G502 SE Lightspeed
- Betriebssystem
- Windows 11 | Dualboot Windows 11 & CachyOS
- Webbrowser
- FireFox | FireFox
- Internetanbindung
-
▼600MBit
▲300MBit

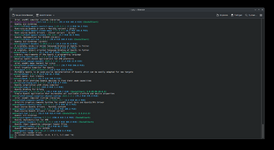
Kann mir jemand mit Ahnung von Linux sagen was hier los ist?
Code:
2025-05-09 16:16:28.5619 [PID=3126875] Request: [USER#xxxxx] [HOST#13220955] [IP xxx.xxx.xxx.137] client 8.0.2
2025-05-09 16:16:28.5620 [PID=3126875] [debug] [HOST#0] rpc_time:0 timezone:7200 d_total:999888179200.000000 d_free:429966643200.000000 d_boinc_used_total:2959765504.000000 d_boinc_used_project:529432576.000000 d_boinc_max:0.000000
2025-05-09 16:16:28.5752 [PID=3126875] [debug] have_master:0 have_working: 1 have_db: 1
2025-05-09 16:16:28.5752 [PID=3126875] [debug] using working prefs
2025-05-09 16:16:28.5753 [PID=3126875] [debug] have db 1; dbmod 1523364255.000000; global mod 1739280081.000000
2025-05-09 16:16:28.5753 [PID=3126875] [debug] sending db prefs in reply
2025-05-09 16:16:28.5753 [PID=3126875] [send] effective_ncpus 12 max_jobs_on_host_cpu 999999 max_jobs_on_host 999999
2025-05-09 16:16:28.5753 [PID=3126875] [send] effective_ngpus 1 max_jobs_on_host_gpu 999999
2025-05-09 16:16:28.5754 [PID=3126875] [send] Not using matchmaker scheduling; Not using EDF sim
2025-05-09 16:16:28.5754 [PID=3126875] [send] CPU: req 0.00 sec, 0.00 instances; est delay 0.00
2025-05-09 16:16:28.5754 [PID=3126875] [send] ATI: req 1727936.69 sec, 1.00 instances; est delay 63.31
2025-05-09 16:16:28.5754 [PID=3126875] [send] work_req_seconds: 0.00 secs
2025-05-09 16:16:28.5754 [PID=3126875] [send] available disk 197.24 GB, work_buf_min 864000
2025-05-09 16:16:28.5754 [PID=3126875] [send] active_frac 0.944324 on_frac 0.891535 DCF 0.501973
2025-05-09 16:16:28.5761 [PID=3126875] [mixed] sending locality work first (0.3973)
2025-05-09 16:16:28.5788 [PID=3126875] [send] send_old_work() no feasible result older than 336.0 hours
2025-05-09 16:16:28.6104 [PID=3126875] [send] send_old_work() no feasible result younger than 319.8 hours and older than 168.0 hours
2025-05-09 16:16:30.6203 [PID=3126875] [version] Checking plan class 'GW-opencl-ati-3'
2025-05-09 16:16:30.6242 [PID=3126875] [version] reading plan classes from file '/BOINC/projects/EinsteinAtHome/plan_class_spec.xml'
2025-05-09 16:16:30.6242 [PID=3126875] [version] parsed project prefs setting 'gpu_util_gw': 1.000000
2025-05-09 16:16:30.6242 [PID=3126875] [version] GPU RAM calculated: min: 2500 MB, use: 2200 MB, WU#898620067 CPU: 300 MB
2025-05-09 16:16:30.6243 [PID=3126875] [version] Peak flops supplied: 5e+10
2025-05-09 16:16:30.6243 [PID=3126875] [version] plan class ok
2025-05-09 16:16:30.6243 [PID=3126875] [version] Checking plan class 'GW-opencl-nvidia-3'
2025-05-09 16:16:30.6243 [PID=3126875] [version] parsed project prefs setting 'gpu_util_gw': 1.000000
2025-05-09 16:16:30.6243 [PID=3126875] [version] No CUDA devices found
2025-05-09 16:16:30.6243 [PID=3126875] [version] Checking plan class 'GW-cuda-3'
2025-05-09 16:16:30.6244 [PID=3126875] [version] parsed project prefs setting 'gpu_util_gw': 1.000000
2025-05-09 16:16:30.6244 [PID=3126875] [version] No CUDA devices found
2025-05-09 16:16:30.6246 [PID=3126875] [version] Best version of app einstein_O3AS is 1.16 ID 1480 GW-opencl-ati-3 (202.90 GFLOPS)
2025-05-09 16:16:30.6246 [PID=3126875] [send] est. duration for WU 898620067: unscaled 7096.99 scaled 4231.51
2025-05-09 16:16:30.6246 [PID=3126875] [send] [WU#898620067] deadline miss 864000 > 604800
2025-05-09 16:16:30.6246 [PID=3126875] [send] [HOST#13220955] [WU#898620067 h1_0241.80_O3aLC01Cl1In0__O3ASBu_242.00Hz_62800] using delay bound 604800 (opt: 604800 pess: 604800)
2025-05-09 16:16:30.6249 [PID=3126875] [send] stopping work search - host too slow
2025-05-09 16:16:30.6249 [PID=3126875] [send] stopping work search - host too slow
2025-05-09 16:16:30.6249 [PID=3126875] [send] stopping work search - host too slow
2025-05-09 16:16:30.6249 [PID=3126875] [send] stopping work search - host too slow
2025-05-09 16:16:30.6249 [PID=3126875] [mixed] sending non-locality work second
2025-05-09 16:16:30.6396 [PID=3126875] [send] [HOST#13220955] will accept beta work. Scanning for beta work.
2025-05-09 16:16:30.6463 [PID=3126875] [debug] [HOST#13220955] MSG(high) No work sent
2025-05-09 16:16:30.6463 [PID=3126875] [debug] [HOST#13220955] MSG(high) see scheduler log messages on https://einsteinathome.org/host/13220955/log
2025-05-09 16:16:30.6463 [PID=3126875] Sending reply to [HOST#13220955]: 0 results, delay req 60.00
2025-05-09 16:16:30.6464 [PID=3126875] Scheduler ran 2.091 secondsMente
Grand Admiral Special
- Mitglied seit
- 23.05.2009
- Beiträge
- 3.729
- Renomée
- 152
- Aktuelle Projekte
- constalation astroids yoyo
- Lieblingsprojekt
- yoyo doking
- Meine Systeme
- Ryzen 3950x
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD 5800X3D
- Mainboard
- Asus ROG Crosshair VIII Dark Hero
- Kühlung
- Headkiller IV
- Speicher
- 3800CL14 G.Skill Trident Z silber/rot DIMM Kit 32GB, DDR4-3600, CL15-15-15-35 (F4-3600C15D-16GTZ)
- Grafikprozessor
- AMD Radeon RX 6900 XT Ref. @Alphacool
- Display
- MSI Optix MAG27CQ
- SSD
- SN8502TB,MX5001TB,Vector150 480gb,Vector 180 256gb,Sandisk extreme 240gb,RD400 512gb
- HDD
- n/a
- Optisches Laufwerk
- n/a
- Soundkarte
- Soundblaster X4
- Gehäuse
- Phanteks Enthoo Pro 2 Tempered Glass
- Netzteil
- Seasonic Prime GX-850 850W
- Tastatur
- Mountain Everest Max, DE, Logitech G19
- Maus
- Logitech G903 Lightspeed, USB
- Betriebssystem
- Win 10 pro
- Webbrowser
- IE 11 Mozilla Opera
- Verschiedenes
- Logitech PRO RENNLENKRAD DD
- Internetanbindung
- ▼500Mbit ▲55Mbit
zum einen sagt er er kennt den Rechner nicht und möchte erst das er sich "beweist" und am ende meint er die Karte und deine Config wären nicht in der Lage vor ablauf der Deadline die Arbeit zu schaffen, das habe ich auch so noch nicht gesehen
NEO83
Grand Admiral Special
- Mitglied seit
- 19.01.2016
- Beiträge
- 5.593
- Renomée
- 997
- Standort
- Wilhelmshaven
- Meine Systeme
- R9 7950X & RTX5080 | R5 9600X & RX9070XT | 7940HS & RTX4070
- BOINC-Statistiken
- Mein Desktopsystem
- Kraftzwerg | MiniMe
- Mein Laptop
- ASUS TUF A17 @R9 7940HS @RTX4070
- Details zu meinem Desktop
- Prozessor
- R9 7950X | R5 9600X
- Mainboard
- MSI MAG X870 Tomahawk WIFI | ASUS B850M-Plus WiFi
- Kühlung
- Corsair iCUE LINK H115i RGB | Noctua NH-D12L
- Speicher
- Corsair Vengeance 64GB, DDR5-6000 | TeamGroup 32GB, DDR5 7200
- Grafikprozessor
- PNY GeForce RTX 5080 OC | RX9070XT RedDevil
- Display
- MSI MAG 274UPFDE @UHD @144Hz | MSI MPG ARTYMIS 273CQRDE @WQHD
- SSD
- WD_BLACK SN850X 1TB, WD_BLACK SN850X 2TB | WD Blue 1TB, FIKWOT 2TB
- Optisches Laufwerk
- USB BD-Brenner
- Soundkarte
- Onboard
- Gehäuse
- Corsair Frame 4000D | Jonsbo D31 MESH
- Netzteil
- be quiet! Power Zone 2 1000W | ASUS ROG Loki 1000W Platinum SFX-L
- Tastatur
- Logitech G815
- Maus
- Logitech G502 SE Lightspeed
- Betriebssystem
- Windows 11 | Dualboot Windows 11 & CachyOS
- Webbrowser
- FireFox | FireFox
- Internetanbindung
-
▼600MBit
▲300MBit
Könnte an der genutzten openCL version liegen aber die möchte ich jetzt ungerne wechseln ...
Dann leider kein Einstein für mich sondern nur SRBase bis das vorbei ist und dann kümmere ich mich nochmal darum ...
Ich habe auch noch das neue Netzteil für den Linux PC hier ... das müsste eigentlich dringend getauscht werden ...
Zu langsam?
Dann leider kein Einstein für mich sondern nur SRBase bis das vorbei ist und dann kümmere ich mich nochmal darum ...
Ich habe auch noch das neue Netzteil für den Linux PC hier ... das müsste eigentlich dringend getauscht werden ...
Code:
Fr 09 Mai 2025 16:31:06 CEST | | OpenCL: AMD/ATI GPU 0: AMD Radeon Graphics (driver version 3635.0 (HSA1.1,LC), device version OpenCL 2.0, 16304MB, 16304MB available, 20644 GFLOPS peak)Zu langsam?
Mente
Grand Admiral Special
- Mitglied seit
- 23.05.2009
- Beiträge
- 3.729
- Renomée
- 152
- Aktuelle Projekte
- constalation astroids yoyo
- Lieblingsprojekt
- yoyo doking
- Meine Systeme
- Ryzen 3950x
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD 5800X3D
- Mainboard
- Asus ROG Crosshair VIII Dark Hero
- Kühlung
- Headkiller IV
- Speicher
- 3800CL14 G.Skill Trident Z silber/rot DIMM Kit 32GB, DDR4-3600, CL15-15-15-35 (F4-3600C15D-16GTZ)
- Grafikprozessor
- AMD Radeon RX 6900 XT Ref. @Alphacool
- Display
- MSI Optix MAG27CQ
- SSD
- SN8502TB,MX5001TB,Vector150 480gb,Vector 180 256gb,Sandisk extreme 240gb,RD400 512gb
- HDD
- n/a
- Optisches Laufwerk
- n/a
- Soundkarte
- Soundblaster X4
- Gehäuse
- Phanteks Enthoo Pro 2 Tempered Glass
- Netzteil
- Seasonic Prime GX-850 850W
- Tastatur
- Mountain Everest Max, DE, Logitech G19
- Maus
- Logitech G903 Lightspeed, USB
- Betriebssystem
- Win 10 pro
- Webbrowser
- IE 11 Mozilla Opera
- Verschiedenes
- Logitech PRO RENNLENKRAD DD
- Internetanbindung
- ▼500Mbit ▲55Mbit
setze mal die Variablen [ active_frac 0.944324 und on_frac 0.891535 DCF 0.501973 auf 1 dann sollte das normal funktionieren, er rechnet das ja auf die Variable Verfügbarkeit vom Client und das kann komisch sein.
FritzB
Grand Admiral Special
★ Themenstarter ★
- Mitglied seit
- 25.12.2002
- Beiträge
- 3.591
- Renomée
- 2.242
- Standort
- Märkisch Kongo
- Aktuelle Projekte
- WCG, GPUGrid
- Lieblingsprojekt
- gute Frage
- Meine Systeme
- 3x Ryzen 7950X, 9950X, 4800H, 7945HX, RTX 4070 Ti, RTX 4070 Ti Super, GTX 1650 Ti, RTX 4090, Radeon Pro VII
- BOINC-Statistiken
- Mein Desktopsystem
- mehrere
- Mein Laptop
- Lenovo ideapad 3, Ryzen 7 4800H, 1650 Ti
- Details zu meinem Desktop
- Prozessor
- 7950X, 9950X, 7945HX
- Mainboard
- jeweils eins
- Kühlung
- BQ Silent Loop 2 280, Arctic Liquid Freezer II 240, Scythe Fuma 3
- Speicher
- ganz viel DDR4 und DDR5
- Grafikprozessor
- GeForce 4090, 4070 Ti Super, 4070 Ti
- Display
- LG UltraGear 27GP850-B
- SSD
- diverse
- Optisches Laufwerk
- hatter
- Gehäuse
- Nanoxia Deep Silence 5, BQ Silent Base 500/600 u.a.
- Netzteil
- Corsair, Seasonic, BQ...
- Betriebssystem
- Windows 11 x64/Pro, Linux Mint 21.x
Versuchen könntest du noch in der client_state.xml und client_state_prev.xml bei Einstein unter <duration_correction_factor>xxx</duration_correction_factor>
den Wert zu halbieren. Vorher den BM beenden.
Das hilft immer dann, wenn der BM die voraussichtliche Berechnungsdauer zu hoch einschätzt und dann nicht die gewünschte Menge an WUs runterläd. Ob das bei deinem Problem hilft, weiß ich nicht.
Dann habe ich in der gleichen Datei noch den Eintrag
Da vielleicht mal ein paar FLOPS mehr eintragen,
Ist aber beides geraten.
den Wert zu halbieren. Vorher den BM beenden.
Das hilft immer dann, wenn der BM die voraussichtliche Berechnungsdauer zu hoch einschätzt und dann nicht die gewünschte Menge an WUs runterläd. Ob das bei deinem Problem hilft, weiß ich nicht.
Dann habe ich in der gleichen Datei noch den Eintrag
Code:
<app_version>
<app_name>einstein_O3AS</app_name>
<version_num>104</version_num>
<platform>x86_64-pc-linux-gnu</platform>
<avg_ncpus>0.900000</avg_ncpus>
<flops>163718423283.362366</flops>Da vielleicht mal ein paar FLOPS mehr eintragen,
Ist aber beides geraten.
NEO83
Grand Admiral Special
- Mitglied seit
- 19.01.2016
- Beiträge
- 5.593
- Renomée
- 997
- Standort
- Wilhelmshaven
- Meine Systeme
- R9 7950X & RTX5080 | R5 9600X & RX9070XT | 7940HS & RTX4070
- BOINC-Statistiken
- Mein Desktopsystem
- Kraftzwerg | MiniMe
- Mein Laptop
- ASUS TUF A17 @R9 7940HS @RTX4070
- Details zu meinem Desktop
- Prozessor
- R9 7950X | R5 9600X
- Mainboard
- MSI MAG X870 Tomahawk WIFI | ASUS B850M-Plus WiFi
- Kühlung
- Corsair iCUE LINK H115i RGB | Noctua NH-D12L
- Speicher
- Corsair Vengeance 64GB, DDR5-6000 | TeamGroup 32GB, DDR5 7200
- Grafikprozessor
- PNY GeForce RTX 5080 OC | RX9070XT RedDevil
- Display
- MSI MAG 274UPFDE @UHD @144Hz | MSI MPG ARTYMIS 273CQRDE @WQHD
- SSD
- WD_BLACK SN850X 1TB, WD_BLACK SN850X 2TB | WD Blue 1TB, FIKWOT 2TB
- Optisches Laufwerk
- USB BD-Brenner
- Soundkarte
- Onboard
- Gehäuse
- Corsair Frame 4000D | Jonsbo D31 MESH
- Netzteil
- be quiet! Power Zone 2 1000W | ASUS ROG Loki 1000W Platinum SFX-L
- Tastatur
- Logitech G815
- Maus
- Logitech G502 SE Lightspeed
- Betriebssystem
- Windows 11 | Dualboot Windows 11 & CachyOS
- Webbrowser
- FireFox | FireFox
- Internetanbindung
-
▼600MBit
▲300MBit

Jemand eine Ahnung wie ich die Lüfter unter Linux steuern kann von der GPU ...
Der Hotspot ist mir viel zu warm ... allerdings ist er auch untypisch heiß und der RAM untypisch kühl ...
Ich könnte mir vorstellen das die beiden Werte vertauscht sind ...
Ich habe schon die eine oder andere Lüftersteuerung probiert aber bekomme damit weder die ans Mainboard angeschlossenen Lüfter noch die GPU Lüfter gesteuert
Krümel
Grand Admiral Special
- Mitglied seit
- 19.08.2003
- Beiträge
- 5.692
- Renomée
- 727
- Standort
- Schleswig-Holstein
- Aktuelle Projekte
- Rosetta, WCG, Einstein, Denis
- Lieblingsprojekt
- POEM *schnüff* R.I.P., TN-Grid
- Meine Systeme
- TR 3960x @ 150 Watt mit CashyOS, 6500XT
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- HP - 14-dk0355ng (R5 3500U 14 Zoll)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 7900x3D
- Mainboard
- Asus TUF B650-M Plus WiFi
- Kühlung
- Noctua NH-U12S
- Speicher
- 2 x 16 GB Corsair Vengeance 6.000
- Grafikprozessor
- AMD RX 6700XT
- Display
- Acer Nitro VG0 27" 1440p / 144 Hz
- SSD
- 1x Crucial P1 1 TB / 1x WB Blue 1 TB (SATA) / 1x Lexar NM790 4TB
- Optisches Laufwerk
- LG BR
- Soundkarte
- Onboardsound
- Gehäuse
- Montech Air 100
- Netzteil
- Be Quiet! System Power 9 500 Watt
- Betriebssystem
- openSUSE Tumbleweed / Win 10 (nur noch als Notfallebene da)
- Webbrowser
- Firefox / Opera
- Internetanbindung
-
▼1000
▲50

Ich nutze dafür CoolerControl.
NEO83
Grand Admiral Special
- Mitglied seit
- 19.01.2016
- Beiträge
- 5.593
- Renomée
- 997
- Standort
- Wilhelmshaven
- Meine Systeme
- R9 7950X & RTX5080 | R5 9600X & RX9070XT | 7940HS & RTX4070
- BOINC-Statistiken
- Mein Desktopsystem
- Kraftzwerg | MiniMe
- Mein Laptop
- ASUS TUF A17 @R9 7940HS @RTX4070
- Details zu meinem Desktop
- Prozessor
- R9 7950X | R5 9600X
- Mainboard
- MSI MAG X870 Tomahawk WIFI | ASUS B850M-Plus WiFi
- Kühlung
- Corsair iCUE LINK H115i RGB | Noctua NH-D12L
- Speicher
- Corsair Vengeance 64GB, DDR5-6000 | TeamGroup 32GB, DDR5 7200
- Grafikprozessor
- PNY GeForce RTX 5080 OC | RX9070XT RedDevil
- Display
- MSI MAG 274UPFDE @UHD @144Hz | MSI MPG ARTYMIS 273CQRDE @WQHD
- SSD
- WD_BLACK SN850X 1TB, WD_BLACK SN850X 2TB | WD Blue 1TB, FIKWOT 2TB
- Optisches Laufwerk
- USB BD-Brenner
- Soundkarte
- Onboard
- Gehäuse
- Corsair Frame 4000D | Jonsbo D31 MESH
- Netzteil
- be quiet! Power Zone 2 1000W | ASUS ROG Loki 1000W Platinum SFX-L
- Tastatur
- Logitech G815
- Maus
- Logitech G502 SE Lightspeed
- Betriebssystem
- Windows 11 | Dualboot Windows 11 & CachyOS
- Webbrowser
- FireFox | FireFox
- Internetanbindung
-
▼600MBit
▲300MBit
Also laut dem was installiert ist, nutze ich rocm was vllt das Problem ist
vllt kann damit ja jemand was anfangen
Code:
Number of platforms 1
Platform Name AMD Accelerated Parallel Processing
Platform Vendor Advanced Micro Devices, Inc.
Platform Version OpenCL 2.1 AMD-APP.dbg (3635.0)
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd cl_amd_event_callback
Platform Extensions function suffix AMD
Platform Host timer resolution 1ns
Platform Name AMD Accelerated Parallel Processing
Number of devices 1
Device Name gfx1201
Device Vendor Advanced Micro Devices, Inc.
Device Vendor ID 0x1002
Device Version OpenCL 2.0
Driver Version 3635.0 (HSA1.1,LC)
Device OpenCL C Version OpenCL C 2.0
Device Type GPU
Device Board Name (AMD) AMD Radeon Graphics
Device PCI-e ID (AMD) 0x7550
Device Topology (AMD) PCI-E, 0000:03:00.0
Device Profile FULL_PROFILE
Device Available Yes
Compiler Available Yes
Linker Available Yes
Max compute units 32
SIMD per compute unit (AMD) 4
SIMD width (AMD) 32
SIMD instruction width (AMD) 1
Max clock frequency 2520MHz
Graphics IP (AMD) 12.0
Device Partition (core)
Max number of sub-devices 32
Supported partition types None
Supported affinity domains (n/a)
Max work item dimensions 3
Max work item sizes 1024x1024x1024
Max work group size 256
Preferred work group size (AMD) 256
Max work group size (AMD) 1024
Preferred work group size multiple (kernel) 32
Wavefront width (AMD) 32
Preferred / native vector sizes
char 4 / 4
short 2 / 2
int 1 / 1
long 1 / 1
half 1 / 1 (cl_khr_fp16)
float 1 / 1
double 1 / 1 (cl_khr_fp64)
Half-precision Floating-point support (cl_khr_fp16)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Single-precision Floating-point support (core)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations Yes
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Address bits 64, Little-Endian
Global memory size 17095983104 (15.92GiB)
Global free memory (AMD) 15978496 (15.24GiB) 15978496 (15.24GiB)
Global memory channels (AMD) 8
Global memory banks per channel (AMD) 4
Global memory bank width (AMD) 256 bytes
Error Correction support No
Max memory allocation 14531585632 (13.53GiB)
Unified memory for Host and Device No
Shared Virtual Memory (SVM) capabilities (core)
Coarse-grained buffer sharing Yes
Fine-grained buffer sharing Yes
Fine-grained system sharing No
Atomics No
Minimum alignment for any data type 128 bytes
Alignment of base address 2048 bits (256 bytes)
Preferred alignment for atomics
SVM 0 bytes
Global 0 bytes
Local 0 bytes
Max size for global variable 14531585632 (13.53GiB)
Preferred total size of global vars 17095983104 (15.92GiB)
Global Memory cache type Read/Write
Global Memory cache size 32768 (32KiB)
Global Memory cache line size 256 bytes
Image support Yes
Max number of samplers per kernel 16
Max size for 1D images from buffer 134217728 pixels
Max 1D or 2D image array size 8192 images
Base address alignment for 2D image buffers 256 bytes
Pitch alignment for 2D image buffers 256 pixels
Max 2D image size 16384x16384 pixels
Max 3D image size 16384x16384x8192 pixels
Max number of read image args 128
Max number of write image args 8
Max number of read/write image args 64
Max number of pipe args 16
Max active pipe reservations 16
Max pipe packet size 1646683744 (1.534GiB)
Local memory type Local
Local memory size 65536 (64KiB)
Local memory size per CU (AMD) 65536 (64KiB)
Local memory banks (AMD) 32
Max number of constant args 8
Max constant buffer size 14531585632 (13.53GiB)
Preferred constant buffer size (AMD) 16384 (16KiB)
Max size of kernel argument 1024
Queue properties (on host)
Out-of-order execution No
Profiling Yes
Queue properties (on device)
Out-of-order execution Yes
Profiling Yes
Preferred size 262144 (256KiB)
Max size 8388608 (8MiB)
Max queues on device 1
Max events on device 1024
Prefer user sync for interop Yes
Number of P2P devices (AMD) 0
Profiling timer resolution 1ns
Profiling timer offset since Epoch (AMD) 0ns (Thu Jan 1 01:00:00 1970)
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Thread trace supported (AMD) No
Number of async queues (AMD) 8
Max real-time compute queues (AMD) 8
Max real-time compute units (AMD) 32
printf() buffer size 4194304 (4MiB)
Built-in kernels (n/a)
Device Extensions cl_khr_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_gl_sharing cl_amd_device_attribute_query cl_amd_media_ops cl_amd_media_ops2 cl_khr_image2d_from_buffer cl_khr_subgroups cl_khr_depth_images cl_amd_copy_buffer_p2p cl_amd_assembly_program
NULL platform behavior
clGetPlatformInfo(NULL, CL_PLATFORM_NAME, ...) AMD Accelerated Parallel Processing
clGetDeviceIDs(NULL, CL_DEVICE_TYPE_ALL, ...) Success [AMD]
clCreateContext(NULL, ...) [default] Success [AMD]
clCreateContextFromType(NULL, CL_DEVICE_TYPE_DEFAULT) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx1201
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CPU) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_GPU) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx1201
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ACCELERATOR) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CUSTOM) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ALL) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx1201
ICD loader properties
ICD loader Name OpenCL ICD Loader
ICD loader Vendor OCL Icd free software
ICD loader Version 2.3.2
ICD loader Profile OpenCL 3.0vllt kann damit ja jemand was anfangen
Anhänge
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 85
- Aufrufe
- 3K
- Antworten
- 276
- Aufrufe
- 7K
- Antworten
- 171
- Aufrufe
- 5K
Aktuelle Aktionen
Pentathlon 2025
Forumsthread
Webseite SG Pentathlon
Marathon 26.05 22:00 - 29.05. 21:59
Projekt: World Community Grid
Forumsthread
Forumsthread
Webseite SG Pentathlon
Marathon 26.05 22:00 - 29.05. 21:59
Projekt: World Community Grid
Forumsthread