App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
- Foren
- Planet 3DNow! Community
- Planet 3DNow! Distributed Computing
- Team Planet 3DNow!
- Café Planet 3DNow!
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
15. Pentathlon 2024 - Jagdrennen (Milkyway@Home)
- Ersteller FritzB
- Erstellt am
Pegasushunter
Admiral Special
- Mitglied seit
- 09.11.2004
- Beiträge
- 1.226
- Renomée
- 380
- Standort
- Berlin
- Aktuelle Projekte
- Pentathlon
- Lieblingsprojekt
- WCG
- Meine Systeme
- Ryzen R9 5950 64GB 1x Intel Arc A770 LE 16GB,MSI X570-A-PRO, !bequiet Straight Power 11 Platinum 850W, ASUS VA27DQSB-W, AMD FX 8350 @ 4 GHZ 32GB 1x R9 280X,3GB, Notebook
- BOINC-Statistiken

- Mein Laptop
- Notebook mit A10 5750 4C ,8GB RAM, 1TB HDD,+ Notebook Core2Duo T6600 2C/4HT 4GB RAM
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5950X , AMD FX 8350 @ 4GHZ
- Mainboard
- MSI X570-A Pro (Rev. 3.0), GA-990X-Gaming SLI (Rev. 1.0)
- Kühlung
- be quiet! Dark Rock Pro 4, Coolink Corator DS CPU-Kühler +Enermax Storm
- Speicher
- G.Skill DIMM 64GB DDR4-3200 Quad-Kit, Patriot CL10 4x8GB DDR3 1866
- Grafikprozessor
- 1x R9 280X VaporX, 1x Intel ARC 770 LE 16GB
- Display
- Asus VA27DQSB Full HD
- SSD
- Crucial_CT275MX300SSD4 M.2, 2x 256GB Intenso, M2 NVMe SSD SAMSUNG 980
- Optisches Laufwerk
- DVD-RW in Notebook
- Soundkarte
- On Board Optical Digital
- Gehäuse
- Bequiet , Chieftec
- Netzteil
- be quiet! STRAIGHT POWER 11 Platinum 850W ; EVGA G2 750W
- Tastatur
- AKKO 3098B Plus Black&Orange Wireless Gaming Tastatur, V3 Cream Yellow
- Maus
- Roccat Burst Pro Air
- Betriebssystem
- Alle Win 10, Kubuntu 24.04.x
- Webbrowser
- Firefox 113.XX
- Verschiedenes
- Noble Chairs Hero Genuine Leather Black
- Internetanbindung
- ▼313MBit ▲28,8 Mbit
Bunker sind egal. Wir bleiben auf jeden Fall in der Gesamtwertung auf Platz 2. 

gruenmuckel
Grand Admiral Special
- Mitglied seit
- 17.05.2001
- Beiträge
- 29.663
- Renomée
- 1.809
- Standort
- Gerry-Weber - Stadt
- Aktuelle Projekte
- Collatz, Milkyway, POEM
- Lieblingsprojekt
- POEM & QMC etwa gleich
- Meine Systeme
- C2Q8400@3,2Ghz I7-3770K C2DE6750
- BOINC-Statistiken

- Mein Laptop
- Dell Studio 1749 @ work / Medion Erazer X7826 @ play
- Details zu meinem Desktop
- Prozessor
- Intel Core i7 6700K
- Mainboard
- Asrock Z270 Extreme4
- Kühlung
- EKL Alpenföhn Matterhorn PURE
- Speicher
- 1x 16GB G.Skill Aegis DDR4-2400 DIMM CL15-15-15-35
- Grafikprozessor
- Sapphire AMD Radeon RX 480 NITRO 8GB
- Display
- LG Ultrawide 21:9 "29UM67-P & FullHD Packard-Bell-TV
- SSD
- 1TB 840 EVO, Mushkin Reactor1TB, Sandisk Extreme 480GB
- HDD
- 1xMD04ACA400, 2x Seagate Archive 8TB
- Optisches Laufwerk
- LG GH22NS40, Sony Optiarc BD-5300S Blu-Ray Brenner
- Soundkarte
- Creative Recon3D PCIe
- Gehäuse
- Corsair Obsidian 650D (2x 140mm Vegas Duo + 1x 120mm Vegas Trio)
- Netzteil
- Corsair RM650i
- Betriebssystem
- Windows 7 64 SP1
- Webbrowser
- Firefox aktuelle Version
- Verschiedenes
- Hauppauge WinTV USB , Scythe Kaze Master Ace Lüfte
- Schau Dir das System auf sysprofile.de an
Neuzugang. 
I7-3770K. Und auch Ironman konnte zur Zusammenarbeit bewegt werden.
Macht 2 WUs paralell mit je 4 Threads.
Auch ne Dampflok zieht einen Zug und bringt die Passagiere ans Ziel. Also: Alteisen ausgraben.

I7-3770K. Und auch Ironman konnte zur Zusammenarbeit bewegt werden.
Macht 2 WUs paralell mit je 4 Threads.
Auch ne Dampflok zieht einen Zug und bringt die Passagiere ans Ziel. Also: Alteisen ausgraben.
Zuletzt bearbeitet:
NEO83
Grand Admiral Special
- Mitglied seit
- 19.01.2016
- Beiträge
- 4.527
- Renomée
- 629
- Standort
- Wilhelmshaven
- BOINC-Statistiken

- Mein Desktopsystem
- Kraftprotz
- Mein Laptop
- ASUS TUF A17 @R9 7940HS @RTX4070 @EndeavourOS
- Details zu meinem Desktop
- Prozessor
- AMD R7 7800X3D
- Mainboard
- GIGABYTE B650E AORUS Master
- Kühlung
- Endorfy Navis F360 ARGB All-in-One
- Speicher
- Corsair Vengeance RGB Kit 32GB, DDR5-6000, CL30-36-36-76
- Grafikprozessor
- PNY GeForce RTX 4080 XLR8 Gaming Verto Epic-X
- Display
- MSI MAG 274UPFDE @UHD @144Hz
- SSD
- WD_BLACK SN850X 1TB, WD_BLACK SN850X 2TB
- Optisches Laufwerk
- USB BD-Brenner
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design Meshify 2 XL
- Netzteil
- ASUS ROG Loki 1000W Platinum SFX-L
- Tastatur
- Logitech G815
- Maus
- Logitech G502 SE Lightspeed
- Betriebssystem
- Garuda Dr460nized Gaming Edition / Windows 11 64Bit
- Webbrowser
- FireFox
- Internetanbindung
- ▼1,15GBit ▲56MBit
Ich habe bei beiden 8 Kernern auch 4er Bestückung führt zu einer akzeptablen Auslastung aber sie bleibt dennoch mist bei MW
seTTam
Vice Admiral Special
- Mitglied seit
- 16.08.2009
- Beiträge
- 908
- Renomée
- 88
- Mitglied der Planet 3DNow! Kavallerie!
- BOINC-Statistiken

- Folding@Home-Statistiken
Bacardi Oakheart-Cola finde ich auch superJa, seltsam.....Sind das da drei normale N-Body Wus? Bekomme hier nur Orbit-Fitting obwohl beide eingestellt im ProjektHöre ich hier etwa einen Ruf nach mehr Power?
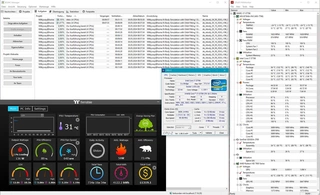
Bitte schön:
Anhang anzeigen 55444
4 x Opteron 6272 mit jeweils 16 Kernen bzw. Modulen.
Brachiale Power !!!!
Doppelposting wurde automatisch zusammengeführt:
Edit:
Aktuell lutscht er ca. 580 Watt aus der Steckdose.
In der Aufgabenübersicht gibt es aber nur die "with Orbit-Fitting"
Doppelposting wurde automatisch zusammengeführt:
Mensch, was ein Glück!
Der Server ist nicht nur fies laut, nein - er ist dafür wenigstens auch noch schön heiß.
Ich mach mal den FritzB - ist zwar kein Cuba Libre aber Bacardi Oakheart-Cola.
Anhang anzeigen 55449

enigmation
Admiral Special

Die Richtung stimmt, jetzt nicht nachlassen:

erde-m
Grand Admiral Special
- Mitglied seit
- 23.03.2002
- Beiträge
- 3.277
- Renomée
- 460
- Standort
- TF
- Mitglied der Planet 3DNow! Kavallerie!
- Lieblingsprojekt
- LHC
- Meine Systeme
- AMD Ryzen9 5950X+64 GB DDR3600+RX6900XT, AMD Epyc 7V12+256 GB ECC DDR3200+R VII, AMD Ryzen 5 2500U
- BOINC-Statistiken

- Mein Laptop
- HP Envy x360 15-bq102ng Ryzen 5 2500U
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen9 5950X
- Mainboard
- Asus Prime X470-Pro
- Kühlung
- be quiet Silent Loop 280mm
- Speicher
- 64GB (4x16GB) G.Skill TridentZ Neo F4-3600C16-64GTZNC Quad Kit
- Grafikprozessor
- AMD Radeon RX 6900XT
- Display
- Acer Pro Designer PE320QK
- SSD
- M2:Samsung 990Pro 2TB + 970Evo Plus 1TB
- HDD
- WDC WD100EFAX
- Soundkarte
- Onboard
- Gehäuse
- Fractal Define 7 Clear Tempered Glass White
- Netzteil
- bequiet Dark Power 12 1000W
- Tastatur
- Logitech G815
- Maus
- Logitech G402
- Betriebssystem
- Linux Mint 21.2; Win11Pro-64Bit
- Webbrowser
- Firefox
- Verschiedenes
- Qnap Single-port Aquantia AQC107 10GbE
- Internetanbindung
- ▼225 MBit ▲45 MBit
typisch P3DN, wenn der Tanker einmal Fahrt aufgenommen hat, kannst du auf der Bugwelle surfen 
Mit den ganzen ATI/AMD-Grakas würde unser Output bei MW brutal sein, da wäre es noch eng für TAAT geworden
Doppelposting wurde automatisch zusammengeführt:
Mit den ganzen ATI/AMD-Grakas würde unser Output bei MW brutal sein, da wäre es noch eng für TAAT geworden
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Dann hätte ich auch meinen DP Cruncher mit den 4x Radeon VIIs mitrechnen lassen. ")

sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Automatisch fertig gemeldet werden die meist erst später. Bleiben sie auch wenn du selbst aktualisierst?
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Bei mir läuft das Hochladen und Melden einwandfrei (arbeite nur mit minimalen Puffer), vielleicht Verbindungsprobleme oder ne Bunker Leiche in der Config?
enigmation
Admiral Special
Netzwerkzugriff angehalten?Die »schwarze 0« greift um sich... Und wieso sind auch die »_1« und »_2« nur meldebereit? Server? Was ist los?
X_FISH
Grand Admiral Special
- Mitglied seit
- 03.02.2006
- Beiträge
- 4.554
- Renomée
- 2.290
- Aktuelle Projekte
- distributed.net (seit 2000), BOINC (seit 2017)
- BOINC-Statistiken

Nein. Habe manuell aktualisiert um neue WU zu bekommen. Da wäre mir aufgefallen wenn etwas nicht passt.Netzwerkzugriff angehalten?Die »schwarze 0« greift um sich... Und wieso sind auch die »_1« und »_2« nur meldebereit? Server? Was ist los?
Maverick-F1
Grand Admiral Special
Läuft bei mir auch problemlos - hab' gerade die ganzen "Nuller-WUs" aussortiert, nachdem die meisten Rechner deutlich zuviele WUs gezogen haben...
enigmation
Admiral Special
Top 6 Stundencredits:

Wir mit einem höheren Stundenoutput als TAAT?
Wir mit einem höheren Stundenoutput als TAAT?
Mit den ganzen ATI/AMD-Grakas würde unser Output bei MW brutal sein, da wäre es noch eng für TAAT geworden
I wish Milkyway had the GPU app still. For you guys, it sadly wouldn't have been this close. Most of our team have very, very good GPUs for doing Milkyway specifically. I was doing over 20M PPD alone on my setup before the GPU app disappeared and others on my team were able to do 10M+ easily. I suspect TAAT would have been doing 50M+ PPD with the GPU app.
Monthly progression since 2007: Notice that section around 06-2022 till the end of the GPU app 06-2023.

We did roughly 10B points per year that year (and that wasn't even running it full time 24/7)
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
I also have a system that is designed for this and ensures plenty of credits.(Threadripper 1950X, 4x Radeon VII, 1 CPU thread per WU + 4 WUs per GPU)
However, due to the hunger for energy and the waste heat, it normally only ran in a few races, but it still generated around 70 million credits.
Übersetzung per google translator.
However, due to the hunger for energy and the waste heat, it normally only ran in a few races, but it still generated around 70 million credits.
Übersetzung per google translator.
I also have a system that is designed for this and ensures plenty of credits.(Threadripper 1950X, 4x Radeon VII, 1 CPU thread per WU + 4 WUs per GPU)
However, due to the hunger for energy and the waste heat, it normally only ran in a few races, but it still generated around 70 million credits.
Übersetzung per google translator.
I got two systems with 6x Nvidia Tesla P100s, AMD EPYC 7V12 that each do around 12M PPD.
and some other cards that do it well as well, but those were my two biggest producers.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Unfortunately I don't have any exact numbers anymore, but I assume that the last two WUs that remained in the history ran for around 30 seconds and 16 of them were finished at once. That would be around 10 million credits per day.I got two systems with 6x Nvidia Tesla P100s, AMD EPYC 7V12 that each do around 12M PPD.
Übersetzung per google translator.
Unfortunately I don't have any exact numbers anymore, but I assume that the last two WUs that remained in the history ran for around 30 seconds and 16 of them were finished at once. That would be around 10 million credits per day.I got two systems with 6x Nvidia Tesla P100s, AMD EPYC 7V12 that each do around 12M PPD.
Übersetzung per google translator.
Total 54M credits. I think you are right in that 4x Radeon VII can do around 2M PPD each so 10M PPD for the whole host seems about right.
For reference I was running 6x tasks on my P100s, but I don't remember the how quickly it returned the results.
One of my hosts: https://milkyway.cs.rpi.edu/milkyway/show_host_detail.php?hostid=923718
I ran the host with multiple instances because Milkyway would only send 600 tasks at a time and not send anymore until all 600 was done and reported. So I ran multiple instances to make sure the GPUs was always crunching and to allow multiple WUs to run in parallel.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.717
- Renomée
- 2.125
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
The biggest problem was the no-load computing time at the end of the WU, which is why, given the short GPU computing time, one had to rely on several WUs per GPU to bridge the gap.
Übersetzung per google translator.
Übersetzung per google translator.
Crashtest
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2008
- Beiträge
- 9.311
- Renomée
- 1.436
- Standort
- Leipzig
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Collatz, yoyo, radac
- Lieblingsprojekt
- yoyo
- Meine Systeme
- Ryzen: 2x1600, 5x1700, 1x2700,1x3600, 1x5600X; EPYC 7V12 und Kleinzeuch
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Lenovo IdeaPad 5 14ALC05
- Details zu meinem Desktop
- Prozessor
- Ryzen 7950X / Ryzen 4750G
- Mainboard
- ASRock B650M PGRT / X570D4U
- Kühlung
- be quiet! Dark Rock Pro4 / Pure Rock Slim 2
- Speicher
- 64GB DDR5-5600 G Skill F5-5600J3036D16G / 32 GB DDR4-3200 ECC
- Grafikprozessor
- Raphael IGP / ASpeed AST-2500
- Display
- 27" Samsung LF27T450F
- SSD
- KINGSTON SNVS2000G
- HDD
- - / 8x Seagate IronWolf Pro 20TB
- Optisches Laufwerk
- 1x B.Ray - LG BD-RE BH16NS55
- Soundkarte
- onboard HD?
- Gehäuse
- zu kleines für die GPU
- Netzteil
- be quiet! Pure Power 11 400W / dito
- Tastatur
- CHERRY SECURE BOARD 1.0
- Maus
- Logitech RX250
- Betriebssystem
- Windows 10 19045.4780 / Server 20348.2655
- Webbrowser
- Edge 127.0.2651.105
- Verschiedenes
- U320 SCSI-Controller !!!!
- Internetanbindung
- ▼1000 MBit ▲82 MBit
Milkyway@Home GPU was cool for AMD Excavator APUs (Bulldozer Gen4) with 1:2 ratio of FP64
My A12-9800 could do 0,5TFlopps FP64
My A12-9800 could do 0,5TFlopps FP64
enigmation
Admiral Special
*Auf die Uhr schau* Ist der Drops gelutscht oder kommt da noch was?
Gesamt-P3 hat SG sicher und wird auch nicht mehr besser dieses Jahr.
Gesamt-P3 hat SG sicher und wird auch nicht mehr besser dieses Jahr.
Sightus
Grand Admiral Special
- Mitglied seit
- 01.12.2006
- Beiträge
- 3.078
- Renomée
- 285
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Einige
- Meine Systeme
- Neumodische Taschenrechner mit grafischer Oberfläche
- BOINC-Statistiken

Ja, dürfte ziemlich sicher durch sein. Wenn es passt, dann lasse ich noch alle WU durchrechnen.
The biggest problem was the no-load computing time at the end of the WU, which is why, given the short GPU computing time, one had to rely on several WUs per GPU to bridge the gap.
Übersetzung per google translator.
That was an issue but so was the fact that you had to return ALL WUs before you could get new WUs. It's why running multiple tasks at the same time as well as multiple instances at the same time was the only way to ensure the GPUs stay crunching work 100% of the time.
Ähnliche Themen
- Antworten
- 263
- Aufrufe
- 10K
- Antworten
- 133
- Aufrufe
- 5K
- Antworten
- 195
- Aufrufe
- 12K
- Antworten
- 76
- Aufrufe
- 3K